

営業でもオペレーションでもマーケティングでも、「このサイトのデータ、勝手に取ってきても法的に大丈夫なんですか」と聞かれる頻度が、ここ最近はっきり上がりました。リード集めにせよ競合の動向把握にせよ、Web スクレイピングはもう特別な技術ではなく、日々の業務を回す前提のひとつになっています。だからこそ「合法か違法か」をスパッと知りたくなる――その気持ちはよく分かります。ところが現実は、そんなに割り切れません。同じ「公開データの取得」でも、ある裁判では問題なしとされ、別のケースでは違法な収集だと突きつけられる。これでは線引きが見えず、足が止まってしまうのも当然です。
しかも背景となる数字も無視できません。いまや分析や AI 用途で Web スクレイピングを取り入れている組織は 3 分の 2 を超え、E コマースに絞れば 78% が価格インテリジェンス目的で活用している という調査もあります。その一方で、LinkedIn 対 hiQ Labs のような大型訴訟がたびたび話題になり、リスクの存在を強く意識させられる。つまり、価値はあるけれど怖さもある。この両方とどう折り合いをつければいいのか。本記事では、知っておきたい法的枠組み、着手前のチェック項目、そして現場で効くベストプラクティスをまとめます。あわせて、Thunderbit がどんな設計でコンプライアンスを後押ししているのかにも触れていきます。
Web スクレイピングは合法なのか? まず押さえたい法的な考え方
Web Scraping Legal Implications Learn more about the legal side of web scraping and how to stay compliant. Get Started Free
先に結論を言ってしまうと、Web スクレイピングが合法かどうかは「対象」「手段」「場所」の組み合わせで決まります。「これさえ守れば全部 OK」という万能の一条文は存在しません。実態としては、不正アクセスを扱う法律、プライバシー規制、著作権、そしてサイトの利用規約――これらが幾重にも折り重なっているのです(Thunderbit Blog)。
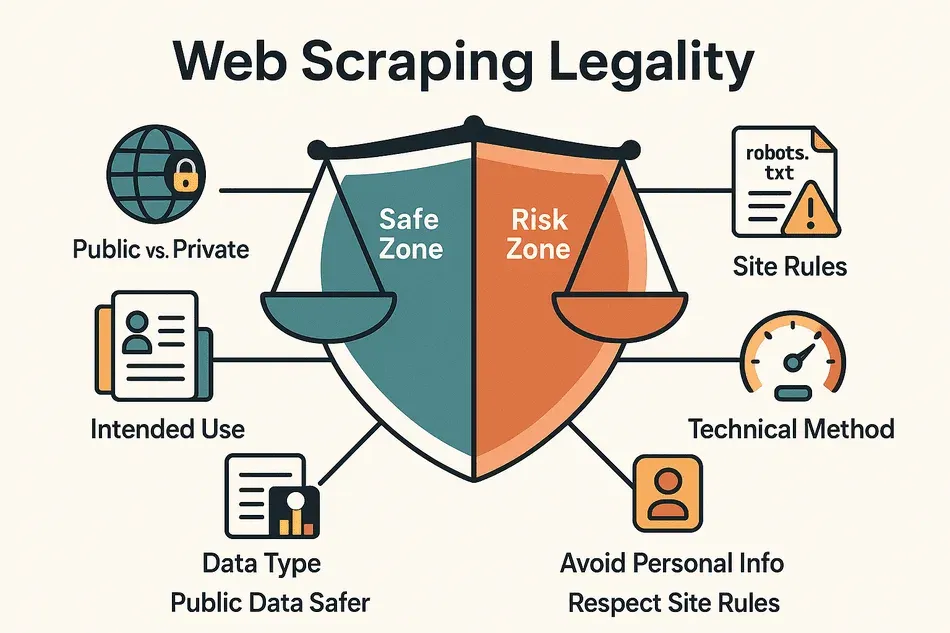
問題化するかどうかを分ける主な論点は、次のように整理できます。
- 公開データか、非公開データか: ログインも課金も不要で誰でも閲覧できる情報なら、リスクは比較的低めです。逆に、ログインの内側にある情報へ手を伸ばした瞬間、話は一気にきな臭くなります。
- どんな種類のデータか: 氏名・メールアドレス・SNS プロフィールといった個人データ、記事や画像のような著作物は、価格・スペック・事業者一覧のような事実情報よりも、扱いに神経を使う必要があります。
- 利用目的は何か: 社内の分析や調査に留めるのか、それとも再公開・再販するのか。この違いで、背負うリスクの重さがまるで変わります。
- サイト側のルールに従っているか: たとえデータが公開されていても、利用規約違反や robots.txt の無視が火種になることがあります。
- 技術的な取り方が適切か: 人がブラウザで見るのに近いペースを守り、CAPTCHA や IP ブロックといった防御を力ずくで突破しない――これが肝心です。
 (https://strapi.thunderbit.com/uploads/webscrapinglegalitysafevsriskzones_6ee3935a34.png)
ざっくり言えば、公開された非個人データを社内利用のために取得する――この範囲なら、多くの国・地域で比較的受け入れられています。ただし、プライバシー・著作権・取得方法の強引さについては、引き続き油断できません(Thunderbit Blog)。
(https://strapi.thunderbit.com/uploads/webscrapinglegalitysafevsriskzones_6ee3935a34.png)
ざっくり言えば、公開された非個人データを社内利用のために取得する――この範囲なら、多くの国・地域で比較的受け入れられています。ただし、プライバシー・著作権・取得方法の強引さについては、引き続き油断できません(Thunderbit Blog)。
世界の主要ルールをざっくり整理:データスクレイピングの法的枠組み
 スクレイピングと関わりが深い主要地域について、ポイントだけ押さえておきましょう。
スクレイピングと関わりが深い主要地域について、ポイントだけ押さえておきましょう。
米国:CFAA、著作権、契約
- Computer Fraud and Abuse Act(CFAA): もともとは不正アクセスを取り締まる法律で、「権限なく」システムへアクセスする行為を違法とします。とはいえ公開サイトの情報取得については、「そもそも許可がいらない領域だから CFAA には引っかかりにくい」と裁判所が整理してきました(California Lawyers Association)。
- 代表的な判例: hiQ Labs v. LinkedIn では、公開状態の LinkedIn プロフィールを取得しても CFAA 違反には当たらない、と Ninth Circuit が判断しました。ただし LinkedIn 側には、利用規約違反や著作権侵害を主張する道が残されています。
- そのほかのリスク: eBay v. Bidder’s Edge のように、1 日 10 万回規模でリクエストを浴びせる強引な取得は、「trespass to chattels(動産侵害)」として咎められることがあります。相手のサーバー運用に支障を与えた、とみなされるわけです(Wikipedia)。
欧州連合:GDPR とデータベース権
- GDPR: たとえ公開されている個人データであっても、個人を特定できる情報を扱うなら GDPR の射程に入ります。利用には、同意や正当な利益といった法的根拠が前提になります。
- Database Directive: EU では、個々の事実そのものに著作権が及ばなくても、データベースの構成や蓄積に対して権利が認められる場合があります。たとえば不動産サイトの全件リストのように、構造化データベースの「相当部分」を取り込むと、問題に発展しかねません(Thunderbit Blog)。
英国:UK GDPR と Data Protection Act
- UK GDPR: Brexit 後も、考え方の骨格は EU GDPR にかなり近いままです。公開された非個人データなら比較的安全ですが、個人データには厳しい目が向けられます。
- Computer Misuse Act: CFAA と似た性格を持ち、無権限アクセスが刑事責任につながる可能性があります。
中国:PIPL と Data Security Law
- Personal Information Protection Law(PIPL): 個人データの収集には同意が必須です。許可なく個人情報を取得するのは、かなり危ない橋になります。
- Data Security Law: データ保有者への損害や不公正競争を招く取得行為を取り締まる、根拠法として援用されます。
そのほかの地域
- カナダ、オーストラリア、APAC: 不正アクセス規制やプライバシー保護の発想は、EU・英国に近い地域が多いです。とはいえ細部は国ごとに異なるため、対象地域ごとの確認は省けません。
ここでの指針はシンプルです。まずは「公開された非個人データを、社内利用のために取得する」という安全圏に身を置く。これが現実的な出発点になります(Thunderbit Blog)。
事前に確認したいコンプライアンスチェックリスト
着手する前に、最低限ここだけは見ておきたい、という項目を挙げておきます。
- サイトの利用規約を読む: ToS に「スクレイピング禁止」とはっきり書かれているなら、そこは一度立ち止まる場面です。場合によっては許可を取りにいく判断も求められます(Thunderbit Blog)。
- 公開データだけに絞る: ログインの内側や有料エリアの情報は、明確な許可がない限り対象から外しておくのが無難です。
- robots.txt を確認する:
site.com/robots.txtを開き、狙うエリアがボット拒否になっていないかを見ます。常に法的拘束力があるわけではありませんが、軽視しないほうが賢明です。 - 個人データを避ける: 氏名やメールアドレスなどの個人識別情報に触れるなら、法的根拠とプライバシー対応がセットで必要です。
- 創作性の高いコンテンツを丸ごと取らない: 記事本文・画像・大量のクリエイティブ素材の再利用は、著作権の地雷になりがちです。まずは事実情報に寄せましょう。
- 公式 API があるなら優先する: API が提供されているなら、それを使うのが法的にも運用的にも安定しやすい選択です。
- 負荷をかけすぎない: サーバーを圧迫しないよう、人の閲覧に近いペースを守り、技術的制限の突破は避けます。
- 取得プロセスを記録する: 何を、いつ、何のために取ったか。残しておけば、後から説明を求められても困りません。
- 停止要請に備える: Cease-and-desist が届いたら即座に止め、状況を見直せる――そんな体制を用意しておきます。
Thunderbit が実践する、コンプライアンスに配慮したスクレイピング
Thunderbit を設計する段階で、私たちが何より気を配ったのが、まさにこのコンプライアンスでした。Thunderbit には、リスクを下げるための工夫が随所に組み込まれています。
- ブラウザベースのスクレイピング: Thunderbit が扱うのは、ブラウザ上で現に見えている情報だけです。隠れた API を直接叩いたり、ログイン制限を裏口から回避したりはしません。見えないものは取れない――そう割り切った設計です(Thunderbit Blog)。
- 警告表示: スクレイピングに厳しい方針のサイトでは、Thunderbit が注意を促します。法務チェックの代わりにはなりませんが、うっかりの見落としを減らせます。
- AI Suggest Fields: AI がページを読み、本当に必要な項目だけを提案します。余計なセンシティブ情報を巻き込んでしまうリスクを抑えやすくなります(Thunderbit Blog)。
- 人に近い取得速度: ローカルでもクラウドでも、サーバーへ過大な負荷をかけにくいペースで動きます。
- 取得データをサーバー保存しない: スクレイピング結果は利用者の手元へ直接届き、Thunderbit 側には残しません。プライバシー面でも扱いやすくなります。
- 社内利用向けのエクスポート: Google Sheets、Excel、Airtable、Notion へ出しやすく、内部分析へ自然につながる導線を用意しています。
- Subpage と Pagination への対応: ページ遷移も実際のユーザーに近い形で進め、無理にエンドポイントを叩くような動きはしません。
- Scheduled Scraping も節度ある運用前提: 定期取得は適切な間隔で組めるようにし、毎分叩き続けるような運用になりにくく配慮しています。
- 34 言語対応: UI が多言語に対応しているため、各国チームでもガイダンスをそのまま理解できます。
要するに Thunderbit は、コンプライアンスを「後付けで考えるもの」ではなく、製品の設計そのものに組み込む という発想で作られています(Thunderbit Blog)。
Try Thunderbit for Compliant Web Scraping
データを取ることと、取ったデータを使い回すことは別問題
 意外と見落とされがちなのが、この区別です。データを取得する行為と、そのデータを再公開・再販・再配布する行為は、法的にはまったく別のテーマとして扱われます。
意外と見落とされがちなのが、この区別です。データを取得する行為と、そのデータを再公開・再販・再配布する行為は、法的にはまったく別のテーマとして扱われます。
- 社内利用: 公開データを社内分析に使うだけなら、リスクはおおむね低めに収まります。もっとも、個人データやプライバシー規制が絡む場合は別途確認が要ります。
- 再配布・再販売: 取得したデータを自社サイトに載せる、製品に組み込む、外部へ売る――こうした用途では、著作権・データベース権・契約違反の論点が一気に表に出てきます。
- 著作権とデータベース権: 米国では、事実そのものは著作権の対象外でも、その選択や配列に保護が及ぶことがあります。EU・英国では、データベースの「相当部分」の取り込みが問題視され得ます。
- Fair Use: 米国法にはフェアユースの概念がありますが、本文やコンテンツを大量にそのまま貼り付ける行為は、まず安全とは言えません。
- 出典表示: 公開して使うなら出典を示すのは大切です。ただし、出典を添えれば合法になる、という話ではありません。
- 生データをそのまま売らない: 加工前の生データを商品として販売するのは、とりわけリスクが高い行為です。データそのものより、そこから引き出した示唆へ変換するほうが安全です。
現場で回すなら順番はこうです。取得したデータは、まず社内のインテリジェンスや意思決定に使う。外部に出す必要が出てきたら、集計・加工・変換を施したうえで、許可が要るかどうかを確認する。この流れを基本に据えるのが堅実です(Thunderbit Blog)。
判例から学ぶ、法的リスクの避け方
実際の裁判例をたどると、どこで地雷を踏みやすいのかが具体的に見えてきます。
LinkedIn vs. hiQ Labs
- 何が起きたか: hiQ Labs は、公開状態の LinkedIn プロフィールを取得し、従業員の離職予測サービスを展開していました。LinkedIn は差し止めを狙いましたが、裁判所は「公開データの取得は CFAA 違反ではない」と結論づけました。
- 学べること: 米国では、公開データの取得に一定の防御余地があります。ただし、利用規約違反やプライバシーの論点は、別問題として残り続けます(California Lawyers Association)。
eBay vs. Bidder’s Edge
- 何が起きたか: Bidder’s Edge は eBay のオークション情報を、1 日 10 万リクエストという極端な頻度で取得していました。eBay の利用規約や robots.txt に反していたこともあり、差止めが認められています。
- 学べること: たとえ公開データでも、取得があまりに攻撃的だったり、明示されたルールを破っていたりすれば、違法と判断される余地が生まれます(Wikipedia)。
Facebook(Meta)vs. Power Ventures
- 何が起きたか: Power Ventures は、ユーザー同意を根拠に Facebook のデータを取得していました。ところが Facebook がアクセス停止を求めて IP ブロックした後も取得を続け、裁判所はこれを「無権限アクセス」と判断しました。
- 学べること: 運営者から「やめてほしい」と明確に告げられた後の続行は、リスクを跳ね上げる行為です。
コンプライアンスを守って運用されている例
EU の価格比較サイトには、事実情報のみを取得し、オプトアウトに配慮し、データベース全体を丸ごと持ち出さない形で運用しているところがあります。大きな訴訟に発展していないこと自体が、公開・非個人・節度ある取得 が現実的な一線であることを物語っています。
Thunderbit ならどう防げるか
Thunderbit の警告表示、レート制御、ブラウザベースの設計は、こうしたありがちな失敗を未然に減らしてくれます。危ういサイトに気づける仕掛けがあり、最初の設定段階から丁寧な取得へ誘導できるからです。
ビジネス利用前に回したいセルフチェック
次の案件に取りかかる前に、簡単でいいので、このセルフチェックは一通り回しておきたいところです。
- 対象データは公開情報か。(ログイン不要か)
- サイト利用規約は確認したか。(スクレイピング禁止条項はないか)
- robots.txt を見たか。(対象エリアが拒否されていないか)
- 個人データを扱っていないか。(扱うならプライバシー対応があるか)
- サイトの大部分を丸ごと取得していないか。(データベース全体取得は避ける)
- 利用目的は明確か。(社内利用か、外部再利用か)
- 取得方法は穏当か。(人に近い速度で、技術的回避をしていないか)
- 公式 API を確認したか。(使えるなら API を優先する)
- 停止要請に応じられる体制か。(Cease-and-desist を受けたら止められるか)
- データの保管方法は適切か。(アクセス制限、保護体制があるか)
- 取得記録を残しているか。(いつ、何を、何のために取得したか)
ひとつでも「ここは曖昧だな」と感じる項目があれば、いったん手を止めて確認する。それが結局は近道になります(Thunderbit Blog)。
Thunderbit を使った、コンプライアンスに配慮した実務フロー
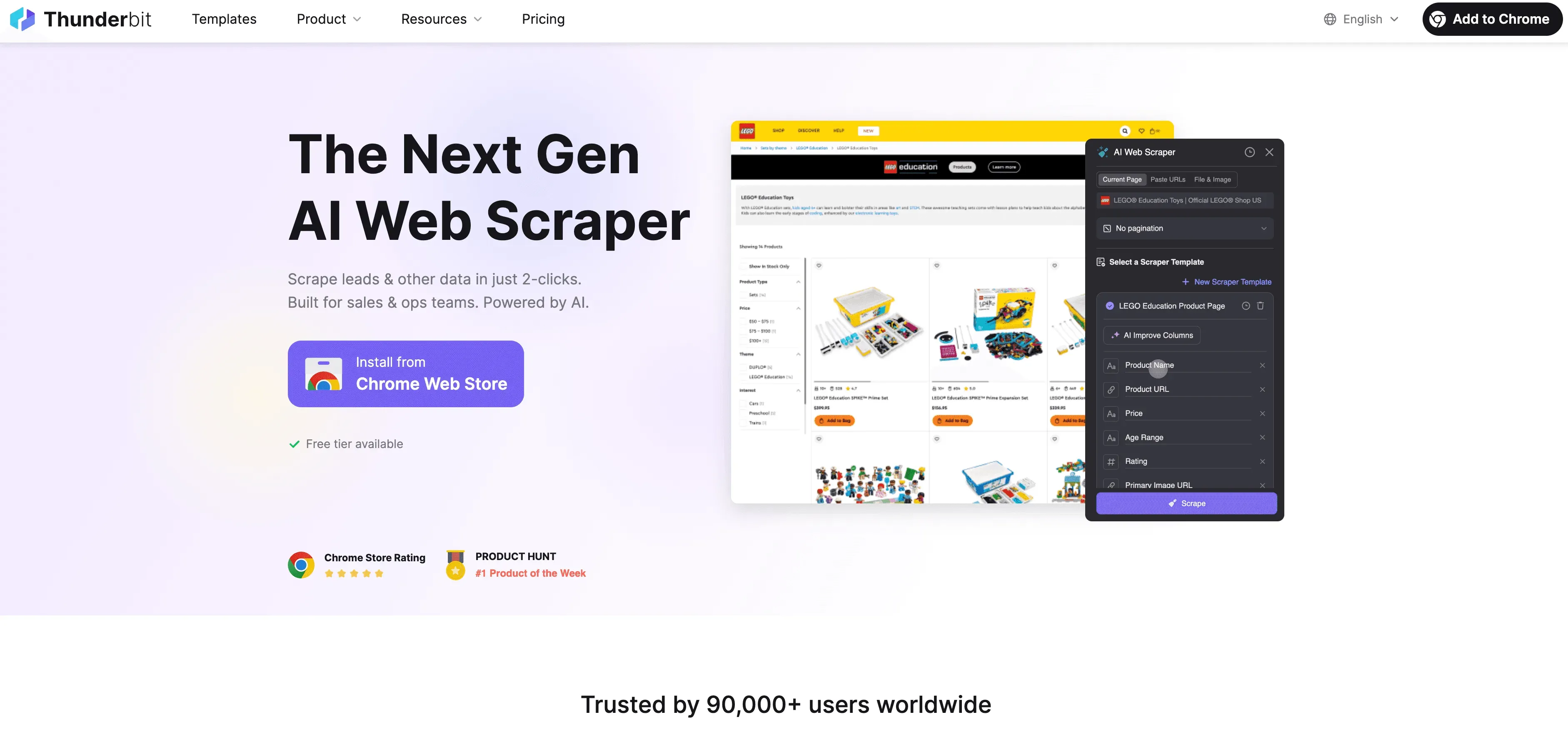 Thunderbit で進める場合の、比較的安全な手順も整理しておきます。
Thunderbit で進める場合の、比較的安全な手順も整理しておきます。
- 事前確認: robots.txt と利用規約に目を通します。明確な禁止が見当たらなければ、次へ進みます。
- Thunderbit を起動: 対象ページを開き、Thunderbit Chrome Extension を立ち上げます。
- AI Suggest Fields を使う: 必要そうな項目を AI に提案してもらいます。個人データが紛れていないかは、必ず自分の目で確認します。
- 項目を調整する: 本当に要る列だけに絞ります。集めすぎないことも、立派な対策のひとつです。
- スクレイピングを実行する: 「Scrape」を押せば、Thunderbit がページ構造に沿って、人に近いペースでデータを取得します。
- 必要なら下層ページも取得する: Subpage 機能で情報を補えますが、ここでも対象は公開情報に限るのが原則です。
- エクスポートする: Google Sheets、Excel、Airtable、Notion へ出力し、社内分析へ回します。
- 必要に応じてスケジュール設定: 極端に短い間隔ではなく、適切な頻度で定期取得を組みます。
- 記録を残す: 何を、いつ、何のために取得したかを残しておきます。
Thunderbit は、各ステップでコンプライアンス上の注意点があれば気づけるよう設計されています。何も分からないまま突き進む、という状態にはなりにくいはずです。
Learn More About Thunderbit Compliance Features
Web データの価値は大きい。ただし、ルールを前提に使うことが欠かせない
Web スクレイピングは、事業の成長に直結する強力な手段です。とはいえ、何をやっても許される世界ではありません。法律の全体像こそ込み入っていますが、押さえるべき原則は意外なほど明快です。
- まずは公開された非個人データを、社内利用のために取得することを基本にする。
- 始める前に、利用規約、robots.txt、関係法令を確認する。
- 個人データや創作性の高いコンテンツは、法的根拠とプライバシー対応がない限り避ける。
- Thunderbit のようなコンプライアンス配慮型ツールを使い、実務フローの中でリスクを下げる。
- 取得プロセスを記録し、停止要請があればすぐに対応できる状態にしておく。
コンプライアンスを「特別な作業」ではなく「日々の運用習慣」に落とし込めれば、Web データの価値はしっかり享受しつつ、余計な法的トラブルは避けやすくなります。どれくらい手軽に進められるのか実感したいなら、Thunderbit を試してみる のが手っ取り早いでしょう。後で法務に説明する立場の人も、きっと胸をなで下ろすはずです。
Web スクレイピングやコンプライアンス、自動化についてもっと深掘りしたいなら、Thunderbit Blog も参考にしてみてください。
Try AI Web Scraper for Compliant Data Extraction Get Started Free
FAQs
1. どの Web サイトでも自由にスクレイピングしてよいのでしょうか。
そうとは限りません。公開された非個人データを社内利用のために取得する分には、多くの地域で許容されやすい一方、個人データ・著作物・ログインの内側にある情報の取得は高リスクです。着手の前に、利用規約と地域の法令を確かめておく必要があります(Thunderbit Blog)。
2. スクレイピングと、取得データの再利用はどう違うのでしょうか。
スクレイピングは「データを集める」行為、再利用は「それを公開・販売・配布する」行為を指します。社内利用に留めるほうが安全性は高く、再公開や販売に踏み込むと、著作権・データベース権・契約違反の論点が浮上しやすくなります(Thunderbit Blog)。
3. Thunderbit は、どのようにコンプライアンス対応を助けてくれますか。
Thunderbit は、ブラウザ上で見えている情報だけを対象にし、リスクの高いサイトでは警告を出し、関連性の高い項目だけを提案し、サーバーへ過度な負荷をかけないペースで処理します。取得データを保持しない点も、社内利用に向いた特徴です(Thunderbit Blog)。
4. Cease-and-desist を受け取ったら、どうすればよいですか。
まずはスクレイピングを直ちに止め、案件全体を見直してください。明確な停止要請の後に続行すると、不正アクセス関連法や契約違反の論点で、立場がかなり不利になります(Thunderbit Blog)。
5. 公開されている個人データなら、取得しても問題ないのでしょうか。
そのまま自由に使える、というわけではありません。GDPR や CCPA のようなプライバシー規制は、公開済みの個人データにも及びます。同意や正当な利益などの法的根拠が要り、取得後の取り扱いにも注意が必要です(Thunderbit Blog)。
This guide is for informational purposes only and does not constitute legal advice. For complex or high-stakes projects, consult a qualified attorney familiar with data and privacy law in your jurisdiction.
関連リンク




