

公開サイトから競合価格や仕入先の連絡先を収集し、スプレッドシートに整理したい場面では、「公開情報ならスクレイピングしても問題ないのか」が実務上の論点になります。数か月前にも、営業チームの同僚から「公開サイトから競合の価格をスクレイピングしたら、本当にまずいことになるの?」と尋ねられました。対象は、仕入先の連絡先と価格が並ぶ公開ディレクトリでした。判断をためらうのは自然なことです。
英国には、単独の「Webスクレイピング法」はありません。その代わり、4つの重なり合う法的枠組みが、スクレイピング行為の適法性を左右します。結論は案件ごとに異なりますが、対象データ、アクセス方法、利用規約、取得後の用途を順に整理すれば、主なリスクを切り分けられます。本記事では、各法的枠組み、実務上のケース、想定される罰則、コンプライアンス上の確認事項を解説します。
私はThunderbitのチーム向けにこのテーマを調べてきました。ここでは、調査内容を実務で参照しやすい判断順序にまとめています。個別案件の結論は事実関係によって変わるため、リスクが高い用途では専門家による法的レビューも必要です。
Webスクレイピングとは何か(そして英国企業が使う理由)
Webスクレイピングとは、ソフトウェアを使ってWebサイトからデータを自動収集することです。Webページからスプレッドシートへ繰り返しコピー&ペーストする作業を置き換えるために使われます。
この手法自体は中立です。最初から合法でも違法でもありません。重要なのは、何をスクレイピングするのか、どうやって取得するのか、その後データをどう使うのかです。
英国企業では、次のような目的でスクレイピングが利用されています。
- 価格比較: たとえばPriceSpy UKは、自動Webスクレイピングを使って1日3〜5回製品価格を更新しています。
- リード獲得: 営業チームが公開ディレクトリから会社名、メールアドレス、電話番号を取得するケースがあります。
- 市場調査: 分析担当者が不動産掲載情報、求人サイト、競合製品のラインナップを監視するケースがあります。
- 学術研究: 英国国家統計局は、2014年から2015年にかけてスーパーマーケットのWebサイトから220万件以上の価格情報を収集しました。
- AIモデルの学習: 利用が拡大している一方、法的な判断には複数の論点があります。
Bright Data/Vanson Bourneの調査では、英国の200人を含む500人の意思決定者のうち、89%が公開Webデータを世界経済にとって重要、または非常に重要と回答し、38%が少なくとも毎日利用していました。
一方、同じ調査で73%が、規制の不明確さに自社が不安を感じていると回答しています。本記事では、この不安を具体的な確認項目に分けて整理します。
英国でWebスクレイピングの適法性を判断する4つの要素
英国法には、Webスクレイピングを一律に禁止する法律はありません。ただし、実施方法は複数の法律や契約条件の対象となり、個々のプロジェクトのリスクは主に4つの要素で変わります。
- どんなデータをスクレイピングするか(個人データか、事実ベースの非個人データか)
- どうやってアクセスするか(公開ページか、ログイン制御やCAPTCHAを回避するか)
- サイトの利用規約に何が書かれているか(自動アクセスを禁止しているか)
- 取得後にデータをどう使うか(社内分析か、商用再販か)
Webスクレイピングは、公共の場での写真撮影にたとえられることがあります。公共の場で撮影すること自体が直ちに違法になるわけではありませんが、被写体、場所、方法、利用目的によってリスクは変わります。同様に、データが公開されていることは重要な判断材料ですが、それだけで適法性が決まるわけではありません。
ICOの生成AIに関する協議では、生成AIモデルの学習にWebスクレイピングした個人データを使う場合について、正当な利益を適法根拠とするには厳格な3要件テストを満たす必要があるとの見解が示されています。これは生成AI学習という文脈での規制当局の説明であり、すべてのスクレイピング案件に同じ結論が自動的に当てはまるわけではありません。個別案件では、目的、必要性、対象者への影響を具体的に評価する必要があります。
Webスクレイピングに適用される英国の4つの法律
4つの重なり合う観点があります。どのスクレイピング案件も、そのうち1つ、2つ、または4つすべてに引っかかる可能性があります。
UK GDPR と 2018年データ保護法
氏名、メールアドレス、電話番号、IPアドレス、SNSプロフィールなど、個人を識別できるデータをスクレイピングする場合、UK GDPRが適用される可能性があります。「公開されている」ことだけで、自由な利用が認められるわけではありません。
公開されている個人データも、依然として個人データです。
商用スクレイピングでは、正当な利益(第6条)が検討されることがあります。ただし、名称を示すだけでは足りず、少なくとも次の点を具体的に評価する必要があります。
- 具体的で正当な目的を特定する
- その目的のために処理が必要であることを示す
- 自分の利益と、収集対象者の権利を比較衡量する
ICOの生成AIに関する協議回答は、広範な社会的便益だけで足りると考えるべきではないこと、スクレイピング以外の代替手段が不適切である理由を証拠で示すべきこと、そして個人が自分の権利を理解し行使できる透明性の仕組みを用いるべきことを説明しています。出典: ICOの生成AIに関する取り組み。
B2Bのリード獲得でも、業務用連絡先に個人データが含まれる場合は同様の検討が必要です。公開されている業務用連絡先情報の収集について正当な利益に依拠できる場合でも、その根拠を文書化し、収集項目を最小限に抑え、特別なカテゴリのデータを避け、適切な透明性措置とオプトアウト手段を設ける必要があります。
著作権、データベース権、TDM例外
著作権は、テキスト、画像、商品説明、記事などのオリジナルなWebサイトコンテンツを保護します。価格のような事実データは、単体では通常、著作権の影響を受けにくいと考えられます。ただし、保護された表現をコピーして再公開すれば、侵害が問題になる可能性があります。
データベース権も、スクレイピング案件で検討すべき論点です。英国はEU型の独自データベース権をBrexit後も維持しており、保護されたデータベースの「実質的部分」を抽出すると、個々のデータが事実情報であっても侵害になる可能性があります。キュレーションされたディレクトリ、商品カタログ、マーケットプレイス掲載情報などが典型例です。
CDPA第29A条の下でのテキスト・データマイニング(TDM)例外は、利用者が適法にアクセスしており、目的が非商用研究である場合に限って、複製を認めます。この例外の範囲は限定されており、商用スクレイピング、商用AI学習、商用データセット再販には通常適用されません。
英国政府はAI学習向けにこの例外を拡張することを検討しましたが、2026年3月の著作権とAIに関する報告書の時点では、創作者、AI開発者、英国経済の各目的を十分に満たせると確信できるまで改革は導入しないと判断しました。記事執筆時点では、既存の例外が適用されない場合、AI学習のために保護作品をコピーするには許可が必要となる可能性があります。
Webサイト利用規約と契約法
多くのWebサイトには、自動スクレイピングを禁止または制限する利用規約があります。サイトにアクセスした時点で、すでにその規約に同意したことになる場合があります。特に、同意画面をクリックする方式(clickwrap)ではその傾向が強いです。フッターリンクの奥にある規約(browsewrap)は事実関係への依存度が高いものの、英国裁判所はスクレイピングに対する利用規約制限を執行する姿勢を示しています。Ryanair対Billigfluegeの紛争では、裁判所は表示されたWebサイト規約をスクリーンスクレイピングの文脈で拘束力あるものとして扱いました。
robots.txtは法律ではありません。サイト所有者からの機械可読なシグナルです。典型的なファイルは次のようになります。
User-agent: *
Disallow: /account/
Disallow: /checkout/
Disallow: /private/
Crawl-delay: 10
robots.txtを無視しても、直ちに違法になるわけではありません。ただし、裁判所やICOはこれをサイト所有者の意思を示す証拠として扱います。これを無視すると、特に利用規約違反や大量アクセスが重なる場合、法的リスクは高まります。
1990年コンピュータ不正使用法
これは多くの人を不安にさせる法律で、理由があります。刑事罰を定めているからです。第1条は、コンピュータ情報への無権限アクセスを規定し、最高懲役2年です。第3条は、コンピュータの動作を妨げる無権限行為を規定し、最高懲役10年です。
CMAのリスクが最も低いのは、データが本当に公開されていて、スクレイパーが技術的障壁を回避しない場合です。次のような場合はリスクが上がります。
- ログイン制御、CAPTCHA、IPブロックを回避する
- 盗まれた認証情報を使う、または偽アカウントを作成する
- 対象サービスを妨害するほどのトラフィックを送る
英国には、米国のような「公開データなら自由に使ってよい」という明確なルールはありません。そのため、英国での助言はより慎重になります。公開アクセスはCMAリスクを大幅に下げますが、利用規約、技術的制御、そしてスクレイパーが制限を知っていたかどうかは、依然として重要です。
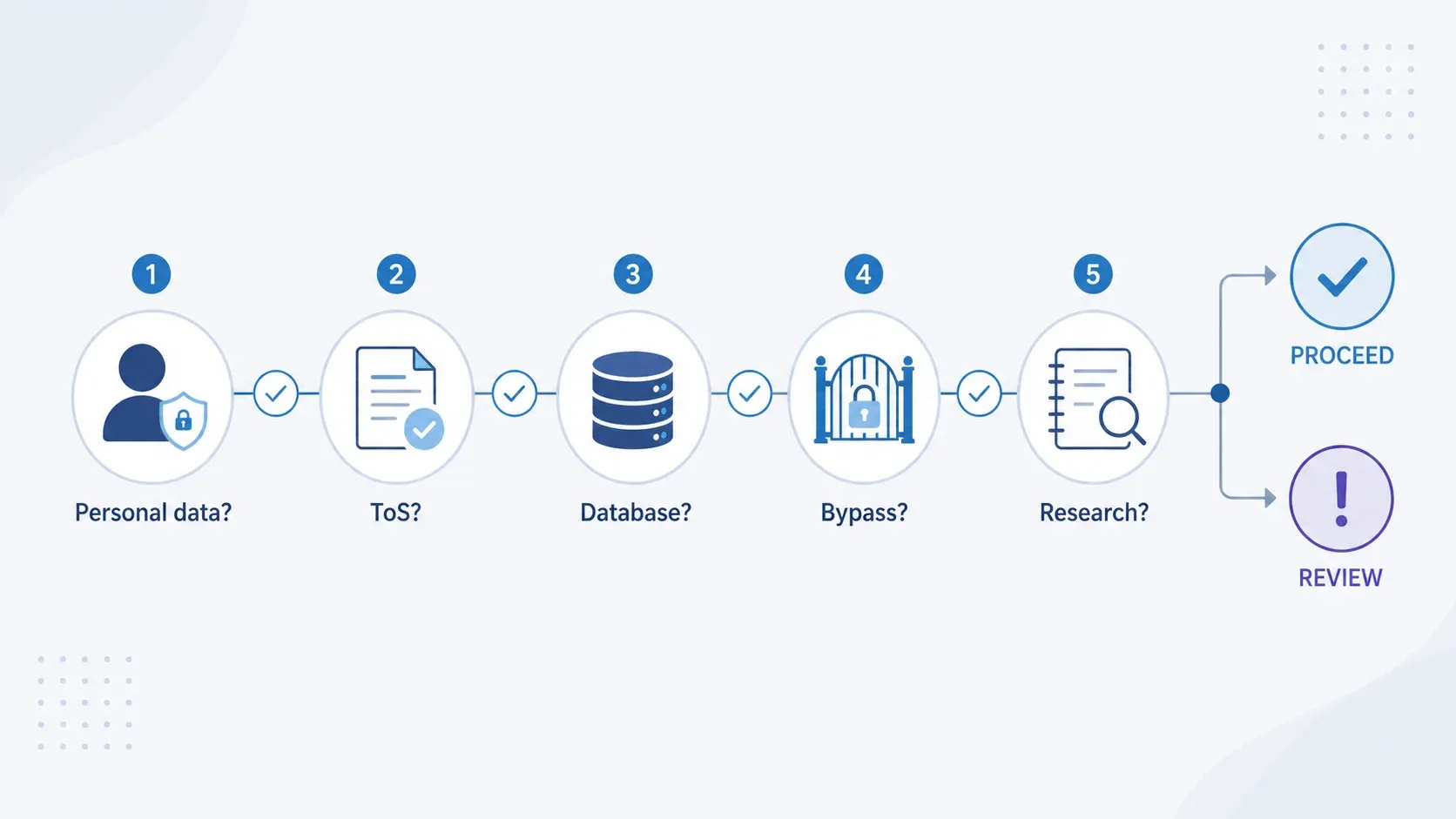
スクレイピング前の簡易判断フロー
スクレイピングを始める前に、次の5つの判断ポイントを整理します。これは法律相談の代替ではなく、法務レビューが必要な案件を早期に仕分けるためのチェックです。
| 判断ポイント | YESなら | NOなら |
|---|---|---|
| データは個人データ(氏名、メールなど)か? | UK GDPRが適用されます。適法根拠を特定し、LIAを実施し、項目を最小化し、透明性の計画を立てます。 | GDPRの層は適用されない可能性がありますが、他の確認は続けてください。 |
| サイトの利用規約でスクレイピングが明示的に禁止されているか? | 契約違反リスクがあります。API、ライセンス、または法的レビューを検討してください。 | 契約リスクは低めですが、robots.txtを確認してください。 |
| データベースの実質的部分を抽出するか? | 独自データベース権を侵害している可能性が高いです。ライセンス取得か、より限定的な抽出を検討してください。 | それでも、個別にコピーしたコンテンツには著作権が及ぶ可能性があります。 |
| ログイン、CAPTCHA、アクセス制御を回避しているか? | 1990年CMA上の刑事罰に該当する可能性があります。中止して法的レビューを受けてください。 | アクセスが本当に公開されているなら、CMAリスクは下がります。 |
| 目的は非商用研究か? | 適法アクセスがあるなら、第29A条のTDM例外が適用される可能性があります。 | 英国には商用TDMの広いセーフハーバーはありません。IPと契約の全面的な分析が必要です。 |
このフローを使うと、個人データ、契約、データベース権、アクセス制御、利用目的の順に論点を記録できます。いずれかで高いリスクが示された場合は、実行前に対象範囲を見直すか、法的レビューへ引き継ぎます。
英国でよくある5つのスクレイピング用途とリスク
法律上の原則だけでは、自社案件の判断に結びつけにくい場合があります。そこで、英国でよく見られる5つのスクレイピング用途について、主なリスクと対応策を整理します。
以下のリスクレベルは一般的な目安であり、対象データ、アクセス方法、利用規約、利用目的によって変わります。
商品価格を比較用にスクレイピングする
価格比較で使われることが多く、条件によっては比較的リスクを抑えやすい業務用途です。価格は事実データとして扱われる場合が多く、PriceSpyのような価格比較サービスでは自動価格収集が利用されています。
ただし、リスクがなくなるわけではありません。対象サイトの利用規約でスクレイピングが禁止されている場合、商品説明や画像をコピーしている場合、あるいはキュレーションされた商品データベースの実質的部分を抽出している場合には、契約、著作権、データベース権の問題が生じる可能性があります。
リスクレベル: 低〜中
重要な対応策: 事実ベースの価格項目だけを収集し、商品説明をそのままコピーしない、利用規約とrobots.txtを尊重する、レート制限をかける、競合カタログの生データをそのままミラー再公開しない。
データを商用再販するためにスクレイピングする
商用利用の中でも、リスクが高くなりやすいシナリオです。他者が整備したデータを販売用の商品へ転用するため、4つの法的枠組みが同時に関係する可能性があります。
リスクレベル: 高
重要な対応策: 実行前に法務レビューを行い、データ所有者とのライセンス契約が必要かを判断してください。商品に個人データが含まれるなら、データ保護影響評価の要否も検討します。
リード獲得のために業務連絡先情報を抽出する
私がこれまでに話した営業チームでは、ディレクトリからメールアドレス、電話番号、会社名を収集する運用が見られました。ここで注意したいのは、業務連絡先にも個人データが含まれる場合があることです。公開されていても、特定の従業員にひもづくメールアドレスは個人データとして扱われる可能性があります。
リスクレベル: 中
重要な対応策: 正当な利益評価を実施する、可能な限り業務用の連絡先データのみに限定する、適法根拠を文書化する、オプトアウト手段を用意する。Thunderbitのようなツールを使う場合も、Chrome拡張機能がユーザーのブラウザセッション内で動作する構成か、対象データへアクセスする権限があるかを分けて判断する必要があります。アクセス制御を回避せず、ユーザーが正当に閲覧できる範囲を対象にする運用が前提です。
学術研究やポートフォリオ向けのデータ分析
非商用研究に該当し、対象データへ適法にアクセスしている場合は、第29A条のCDPAに基づく著作権例外を検討できます。ただし、研究名目だけで適用が決まるわけではなく、実際の目的や利用方法が判断材料になります。
リスクレベル: 低(本当に非商用なら)
重要な対応策: 非商用目的であることを記録する、出典を明記する、可能なら匿名化または集計する、著作権コンテンツや個人データを再配布しない。
AIモデル学習のためにコンテンツをスクレイピングする
2026年時点でも、法的な整理が続いているテーマです。ICOは、Webスクレイピングした個人データを学習に使うことについて、本人から見えにくく、高いリスクを伴い得る処理として説明しています。英国政府の2026年報告書でも、商用TDMの広い例外は導入されませんでした。
リスクレベル: 中〜高
重要な対応策: ライセンス取得、データセットの出所確認、著作権分析、個人データのフィルタリング、適法根拠の文書化、英国の政策変更を継続監視すること。
シナリオ要約表
| シナリオ | 主に関係する法律 | リスクレベル | 重要な対応策 |
|---|---|---|---|
| 商品価格の監視 | 利用規約、データベース権、著作権 | 低〜中 | 事実項目のみ収集し、サイトのシグナルを尊重する |
| 商用データ再販 | 4つすべて | 高 | 法務レビューを行い、ライセンス取得の要否を判断する |
| B2Bリード獲得 | UK GDPR、利用規約 | 中 | LIAを実施し、個人データを最小化する |
| 学術研究 | 著作権(TDM例外)、個人データがあればGDPR | 低 | 非商用目的を維持し、再公開しない |
| AIモデル学習 | UK GDPR、著作権、データベース権 | 中〜高 | データをライセンス取得し、適法根拠を文書化し、政策を監視する |
英国・米国・EUでWebスクレイピング法はどう違うか
英国だけで運用しているなら、この節は飛ばして構いません。ただ、多くの企業は私が話す限り国際的にスクレイピングしているか、少なくとも他法域にホストされたWebサイトをスクレイピングしています。違いは思った以上に重要です。
| 法的論点 | 🇬🇧 英国 | 🇺🇸 米国 | 🇪🇺 EU |
|---|---|---|---|
| 主なデータ保護法 | UK GDPR + DPA 2018 | 連邦法の同等規定なし(州法はまちまち) | EU GDPR |
| 主要なスクレイピング判例 | Clearview AI(ICOによる750万ポンドの罰金) | hiQ対LinkedIn(公開データのスクレイピングは可、9巡回区。ただしhiQは恒久的差止めを受け、最終同意判決で50万ドルを支払った) | Ryanair対PR Aviation(CJEU, C-30/14、データベース権) |
| コンピュータアクセス法 | 1990年コンピュータ不正使用法 | CFAA(2021年のVan Burenで範囲縮小) | 加盟国ごとに異なる |
| 著作権 / TDM例外 | 狭い:非商用研究のみ(第29A条) | フェアユース理論(より広く、個別判断) | DSM指令第3条・第4条(権利留保付きのより広いTDM権) |
| データベース権 | あり(EUデータベース指令から継承) | 連邦レベルの同等権利なし | データベース指令に基づく独自権 |
| 利用規約の執行可能性 | 契約法が適用、browsewrapは議論あり | 混在:browsewrapは執行困難なことが多い | 変動あり。Ryanairで利用規約の立場が強化された |
実務上の要点はこうです。複数法域にまたがってスクレイピングするなら、適用される中で最も厳しい法律に従ってください。米国はhiQ判例の下で公開データアクセスに比較的寛容ですが、hiQが包括的な許可証だったわけではありません(最終的にLinkedInのスクレイピングを差し止められ、50万ドルを支払いました)。EUはDSM指令によって、TDMの仕組みがより広くなっています。英国はその中間です。広い商用TDM例外はなく、強いデータベース権があり、規制当局も活発です。
罰則と執行:法的枠組み別に見る影響
「罰金」や「法的トラブル」という曖昧な警告だけでは、リスクの大きさを判断できません。ここでは、法的枠組みごとに罰則や民事上の影響を整理します。
UK GDPRの罰金
法令上の上限として、1,750万ポンドまたは年間世界売上高の4%のいずれか大きい方が示されています。
Clearview AIの事例では、英国のSNSから顔画像をスクレイピングしたことを理由に、2022年にICOが7,552,800ポンドの罰金を科しました。第一審審判所は管轄を理由にこれを取り消しましたが、2025年10月の上級審はICOの控訴を認め、事件を差し戻しました。ICOは、2025年12月時点でClearviewが控訴院への上訴許可を得ていたと説明しています。この事案は手続が継続しているため、最終的な法的結論と当初の制裁内容を分けて読む必要があります。
1990年コンピュータ不正使用法の刑事罰
技術的な回避を伴わない公開ページのスクレイピングは、無権限アクセスやシステム障害を伴う行為に比べ、刑事リスクが相対的に低いと考えられます。
一方、行為がハッキング、認証情報の不正使用、CAPTCHA回避、サービス妨害に近づくと、評価は大きく変わります。アクセス権限と対象システムへの影響を個別に検討する必要があります。
著作権とデータベース権
民事上の損害賠償と差止命令です。故意の商用侵害では刑事罰の可能性もありますが、多くのスクレイピング紛争は民事請求として進みます。
契約違反(利用規約違反)
利用規約違反が問題になると、民事上の損害賠償、アカウント停止、IPブロックなどにつながる可能性があります。実務では、訴訟に至る前にアカウント停止やアクセス制限が行われる場合もあります。
罰則の重さのまとめ
| 法的枠組み | 最大罰則 | 一般的な業務用スクレイピングでの起こりやすさ | 実例 |
|---|---|---|---|
| UK GDPR | 1,750万ポンドまたは世界売上高の4% | 個人データを大量に扱う場合は中、非個人データなら低 | Clearview AIへの750万ポンドの罰金 |
| CMA 第1条 | 懲役2年 | 公開ページでは低いが、回避行為があると高くなる | 無権限アクセスに関するCPSのガイダンス |
| CMA 第3条 | 懲役10年 | システムを妨害するほどのトラフィックがなければ低い | DDoS型の障害事例 |
| 著作権 / データベース権 | 損害賠償と差止命令 | 保護コンテンツやキュレーション済みDBのコピーで中 | RyanairやBHBの一連の判例 |
| 利用規約違反 | 損害賠償、アカウント停止、ブロック | 実務上の執行手段としては高い | Ryanairのスクリーンスクレイピング紛争 |
ツール選定で管理できるスクレイピングの運用リスク
ツールを選んだからといって、違法なスクレイピングが合法になるわけではありません。一方で、アクセス方法、取得頻度、出力先を管理しやすいツールを選ぶことで、運用上避けられるリスクを減らせる場合があります。
重要なのは、ツール名だけで安全性を判断せず、対象サイトのシグナル、アクセス権限、レート制限、データの保存方法を案件ごとに設定することです。
robots.txt とサイトのシグナルを尊重する
責任あるツールは、スクレイピング前にrobots.txtを確認し、尊重しやすくするべきです。法的拘束力はないものの、robots.txtに従うことは、裁判所やICOから誠実性の証拠として見られます。Thunderbitのドキュメントでは、公開されているデータをスクレイピングし、robots.txtと利用規約を守るよう案内しています。
ブラウザスクレイピングとクラウドスクレイピングの使い分け
この違いは、アクセス方法を評価するうえでも重要です。ブラウザスクレイピングは、ユーザーのブラウザセッションで閲覧できるページを対象に、手作業で行う操作の一部を自動化します。クラウドスクレイピングはサーバーからリクエストを送るため、公開サイトでは高速に処理できる場合がある一方、サイト側では自動アクセスとして識別されやすくなります。
Thunderbitでは、対象サイトや利用条件に応じてブラウザモードとクラウドモードを使い分けます。ログインが必要なサイトでは、ユーザーが正当にアクセスできる範囲をブラウザモードで扱う方法が候補になります。公開されているECページなどでクラウドモードを使う場合も、利用規約、robots.txt、アクセス頻度を別途評価する必要があります。モードを選ぶだけで法的リスクが解消されるわけではありません。
アクセス制御を回避しない
ブラウザ内で動作し、CAPTCHAの突破やログイン制御の迂回を前提としないツールは、技術的な回避を行う構成に比べ、コンピュータ不正使用法上の懸念を抑えやすいと考えられます。ただし、ブラウザで表示できることだけでアクセス権限が確定するわけではありません。ThunderbitのChrome拡張機能を使う場合も、ユーザーが正当に閲覧できる範囲を対象とし、対象サイトの利用規約とアクセス制御を尊重する運用が前提です。
透明なデータ出力(GDPR対応を支える)
Thunderbitは、利用するプランや連携条件に応じて、Excel、Google Sheets、Airtable、Notionへの出力に対応します。出力先を利用者側で選べることは、収集した項目と保存先を記録する運用に役立ちます。ただし、出力機能だけでGDPR対応が完了するわけではありません。データ保持、処理範囲、各連携先での保存条件については、対象プランの仕様、プライバシー文書、社内の保持方針を照合する必要があります。
レート制限と責任あるアクセス
過度なリクエストによって対象システムの動作を妨げると、CMA第3条を含む法的リスクが問題になる可能性があります。レート制限は、対象サーバーへの負荷とIPブロックの可能性を抑えるための運用上の対策です。ただし、レート制限を設定しただけで適法性が保証されるわけではありません。対象サイトの許容範囲、同時実行数、取得間隔を記録し、相手側への影響を見ながら設定を見直します。

英国でのWebスクレイピングに向けた実践的コンプライアンスチェックリスト
何かをスクレイピングする前に、次を確認してください。
- 対象サイトの利用規約と利用可能範囲ポリシーを読む。
- robots.txtファイルを確認し、関連パスが禁止されているか記録する。
- 欲しいデータが個人データかどうかを判断する。該当するなら、UK GDPR上の適法根拠を特定する。
- データベースの「実質的部分」を抽出していないかを評価する。
- 技術的アクセス制御(CAPTCHA、ログイン、レート制限)を回避していないことを確認する。
- 目的が非商用研究なら、TDM例外の適用を受けられるよう、その事実を文書化する。
- レート制限を使う。 対象サーバーに過負荷をかけない。
- すべてを文書化する: 適法根拠、利用規約の確認内容、収集データ項目、出力先、保持期間。
- 迷ったら、 データ保護と知的財産を専門とする弁護士に相談する。
このチェックリストは弁護士の意見に代わるものではありませんが、確かな出発点になり、何か聞かれたときにも誠実に対応していたことを示せます。
重要なポイント
- Webスクレイピングは英国で一律に禁止されているわけではありません。ただし、UK GDPR、著作権・データベース権、契約法、1990年コンピュータ不正使用法という4つの法的枠組みが関係します。
- リスクは、何をスクレイピングするか、どうアクセスするか、サイト規約に何が書かれているか、その後データをどう使うかによって変わります。
- 個人データを扱う場合は、適法根拠、必要性、対象者の権利、透明性措置を文書化します。正当な利益を用いる場合も、案件ごとの衡量テストが必要です。
- 英国では商用TDMに広く適用できる例外が限定されているため、商用AI学習やデータセット再販では、対象コンテンツと利用目的に応じてライセンスの要否を評価します。
- 上の判断フローとシナリオ表を使い、開始前に論点と担当者を記録してください。
- ツールを選ぶ際は、ブラウザベースのアクセス、アクセス制御の扱い、データ出力、レート制限を比較します。Thunderbitを使う場合も、対象サイト、モード、プラン、設定によって利用条件が異なり、コンプライアンス責任はユーザー側にあります。
- 判断に迷う場合は、検討理由を記録し、データ保護と知的財産に詳しい弁護士へ相談してください。
導入時は、まず1つの公開ページを対象に、アクセス権限、取得項目、出力先、リクエスト頻度を検証してから運用範囲を広げると、問題を早期に見つけやすくなります。
ThunderbitでAIウェブスクレイパーを試す Get Started Free
よくある質問
英国で公開されているデータをスクレイピングするのは合法ですか?
公開データであることだけでは、適法性を一律に判断できません。アクセス制限のあるデータや非公開データに比べるとリスクを抑えやすい場合がありますが、UK GDPRは公開された個人データにも適用される可能性があります。また、著作権はコピーされた表現、データベース権は保護対象となるデータの集合、利用規約は自動アクセスに関係します。対象データ、アクセス方法、規約、利用目的を個別に評価してください。
英国のWebサイトからメールアドレスや電話番号をスクレイピングしてもよいですか?
メールアドレスや電話番号が特定の個人にひもづく場合は、UK GDPR上の適法根拠が必要になります。B2Bリード獲得では正当な利益が検討されることがありますが、目的と必要性を示し、衡量テストを行い、収集データを最小限にし、オプトアウト手段を用意する必要があります。業務用ディレクトリに掲載された情報であっても一律に利用できるわけではなく、携帯番号や個人メールなど私生活に近い連絡先は、対象者への影響が大きくなりやすい点に注意が必要です。
英国法上、WebスクレイピングとWebクローリングの違いは何ですか?
名称だけで法的な扱いが決まるわけではありません。クローリングは通常、ページの発見や索引作成を指し、スクレイピングは構造化データの抽出を指します。ただし、実際の評価では、自動アクセスの方法、取得するデータ、技術的制御、利用目的が重視されます。名称が異なっても、行為の内容に応じて同じ法的枠組みが関係する可能性があります。
robots.txt があると、スクレイピングは違法になりますか?
robots.txtが存在することだけで、スクレイピングが直ちに違法になるわけではありません。ただし、そこに示された制限を無視すると、サイト所有者の意思を認識していたかどうかを判断する材料になる可能性があります。利用規約でもスクレイピングが禁止され、さらに技術的制御や大量アクセスが重なる場合は、複数のリスク要因をまとめて評価する必要があります。
英国でWebスクレイピングが刑事問題になる主なケース
刑事責任のリスクは、アクセス制御(CAPTCHA、ログイン、IPブロック)を回避する行為や、1990年コンピュータ不正使用法上の無権限アクセス、コンピュータシステムへの障害に当たり得る行為がある場合に高まります。公開されているデータを、技術的回避を行わず、対象システムへ過度な負荷をかけない方法で取得する場合は、これらの行為に比べて刑事リスクを抑えやすいと考えられます。ただし、公開表示されていることだけで権限の有無が決まるわけではなく、個別の事実関係を評価する必要があります。
さらに詳しく知る




