
ウェブクローラーは、Web上のページを自動で巡回し、検索や分析に必要な情報を収集するプログラムです。レシピの検索、スニーカーの価格確認、旅行先のホテル比較など、日常的に使うサービスの裏側でも、クローラーが収集・整理した情報が活用されています。実際、インターネットのトラフィック全体のおよそ半分は、人間ではなくボットやクローラーが生み出していると見られています。最近の業界調査でも、その割合は49〜51%と報告されています。
ウェブクローラーは、企業の市場調査や価格監視、研究者によるデータ収集など、最新情報を継続的に扱う業務でも使われています。この記事では、ウェブクローラーの定義、動作の仕組み、代表的な活用例、利用時の注意点を整理します。また、Thunderbitのようなツールによって、専門的な開発経験がない担当者がWebデータを収集する方法も紹介します。私は長年、自動化やAIツールの開発に携わり、ウェブクローラーが専門的な技術から日々の業務で使われる仕組みへと広がる過程を見てきました。その経験も踏まえ、2026年のデータ活用を考えるうえで押さえておきたい要点を解説します。
ウェブクローラーはWebページを巡回して情報を収集するプログラム
AIを使って、あらゆるサイトからデータを抽出 Get Started Free
ウェブクローラー(スパイダーやボットとも呼ばれます)は、インターネット上のページを体系的に巡回し、ページ間のリンクをたどりながら情報を集める自動プログラムです。設計や処理能力によっては、1日に何百万ページもの情報を取得できます。
ウェブクローラーは、最初にウェブアドレスの一覧(「シード」と呼ばれます)を受け取ります。各ページを取得してリンクを抽出し、未訪問のページを巡回対象へ追加します。収集したコンテンツをインデックス化することで、変化し続けるWeb上の情報を検索や比較に使える形に整理します(Cloudflare)。この仕組みにより、Googleのような検索エンジンはWeb上のページを把握でき、価格比較サイトや市場調査ツールは必要なデータを更新できます。
つまり、ウェブクローラーは、Web上の情報を検索・比較・分析できる状態に整えるための収集基盤です。
ウェブクローラーの多様な姿:種類と基本機能
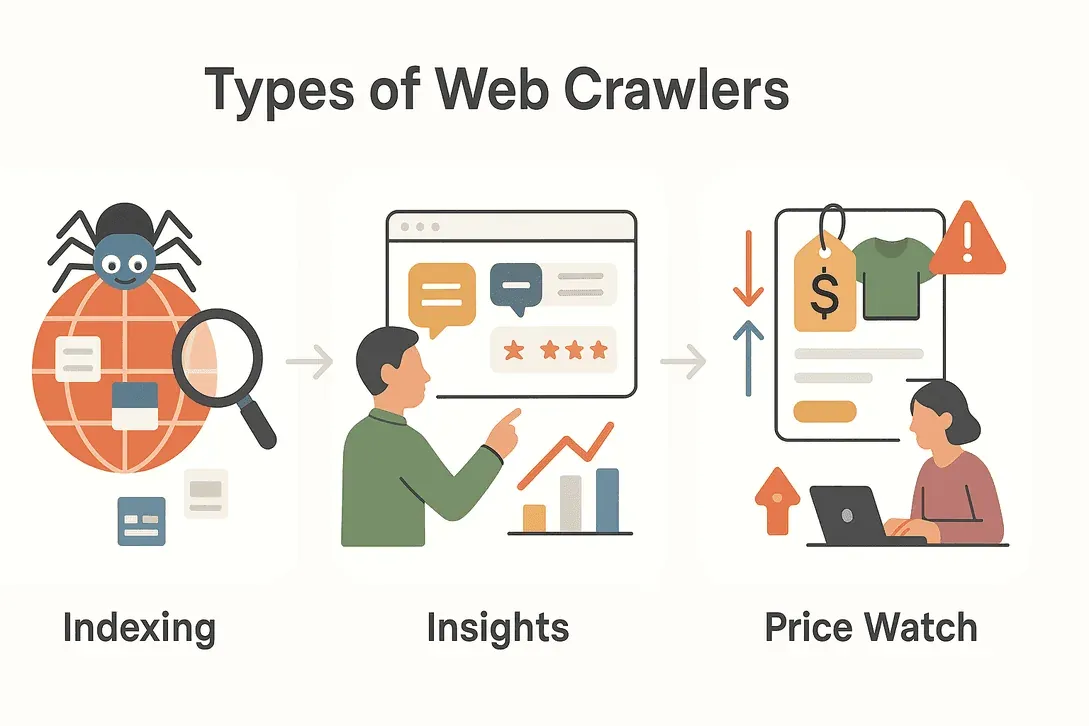 すべてのウェブクローラーが同じ役割を担うわけではありません。目的に応じていくつかの種類があり、それぞれ得意分野が違います。代表的なタイプを以下に整理します。
すべてのウェブクローラーが同じ役割を担うわけではありません。目的に応じていくつかの種類があり、それぞれ得意分野が違います。代表的なタイプを以下に整理します。
| 種類 | 主な機能 | 典型的な用途 |
|---|---|---|
| 検索エンジンクローラー | 検索結果のためにウェブをインデックス化する | Googlebot、Bingbotによる新規サイトのインデックス化 |
| データマイニングクローラー | 分析用の大規模データセットを収集する | 市場調査、学術研究 |
| 価格監視クローラー | 商品価格と在庫状況を追跡する | Eコマースの価格比較、動的価格設定 |
| コンテンツ集約クローラー | 記事、ニュース、投稿を集約する | ニュースポータル、コンテンツキュレーション |
| リード獲得クローラー | 連絡先情報や企業データを抽出する | 営業開拓、B2Bディレクトリ |
続いて、それぞれの用途を説明します。
検索エンジンクローラー
Googleなどで検索するときは、検索エンジンクローラーが収集・整理した情報が使われています。これらのボットは24時間365日Webを巡回し、新しいページの発見、既存情報の更新、検索結果に表示するコンテンツのインデックス化を行います。クローラーがなければ、検索エンジンは新規ページや更新内容を継続的に把握できません(TechTarget)。
データマイニングと市場調査用クローラー
企業や研究者は、分析に必要な大量のデータを収集するためにクローラーを利用します。たとえば、競合ブランドが言及された回数や新製品への反応を調べる場合、データマイニングクローラーでフォーラム、レビュー、SNSなどを横断して情報を取得し、分析しやすい構造化データに整理できます(DataHut)。
価格監視と商品追跡クローラー
ECサイトでは、価格、在庫、商品情報が頻繁に変化します。価格監視クローラーは、競合商品の値下げ、在庫の増減、新商品の発売などを継続的に取得します。収集した情報は、動的価格設定や商品戦略を見直す際の判断材料として利用できます(AIMultiple)。
ウェブクローラーが現代のデータ活用を支える理由
Web上の情報量は、人が手作業だけで継続的に追跡できる規模を超えています。現在は14億を超えるウェブサイトがあり、毎日およそ100万件が新たに加わっているとされています。ウェブクローラーを利用すると、次の処理を自動化できます。
- 大規模なデータ収集:数時間で何百万ページも巡回できる場合があり、手作業より短い期間で情報を集められます。
- 更新情報の継続的な取得:ページの変更、新しいコンテンツ、速報を設定した頻度で追跡します。
- 変化の速い情報への対応:市場の変化、価格変動、トレンドに関するデータを取得し、判断までの時間を短縮します。
- データに基づく判断の支援:検索エンジン、市場調査、リスク管理、金融モデリングなどの情報収集を支えます(DEV Community)。
データがデジタルビジネス戦略の土台である現在、ウェブクローラーは、必要な情報を継続的に収集する手段の一つです。
業界横断で見るウェブクローラーの代表的な活用例
ウェブクローラーは、テクノロジー企業や検索エンジンに限らず、複数の業界でデータ収集に利用されています。代表的な用途を以下に整理します。
| 業界 | 用途 | メリット |
|---|---|---|
| 営業 | リード獲得 | ディレクトリからターゲット候補リストを作成 |
| Eコマース | 価格監視 | 競合の価格、在庫、商品変化を追跡 |
| マーケティング | コンテンツ集約 | ニュース、記事、SNS上の言及を整理 |
| 不動産 | 物件情報の集約 | 複数ソースの掲載情報を統合 |
| 旅行 | 運賃・ホテル比較 | 価格、空室状況、ポリシーを監視 |
| 金融 | リスク監視 | 投資判断のためにニュース、開示資料、感情動向を追跡 |
活用例:
不動産会社では、複数の物件掲載サイトから物件情報、写真、設備情報を取得し、顧客へ提供する市場情報を更新する用途でクローラーが使われています(DataHut)。
ECチームでは、競合のSKUや価格を監視するようクローラーを設定し、取得した変化を価格・商品戦略の見直しに利用しています(AIMultiple)。
ウェブクローラーの仕組み:ステップごとの流れ
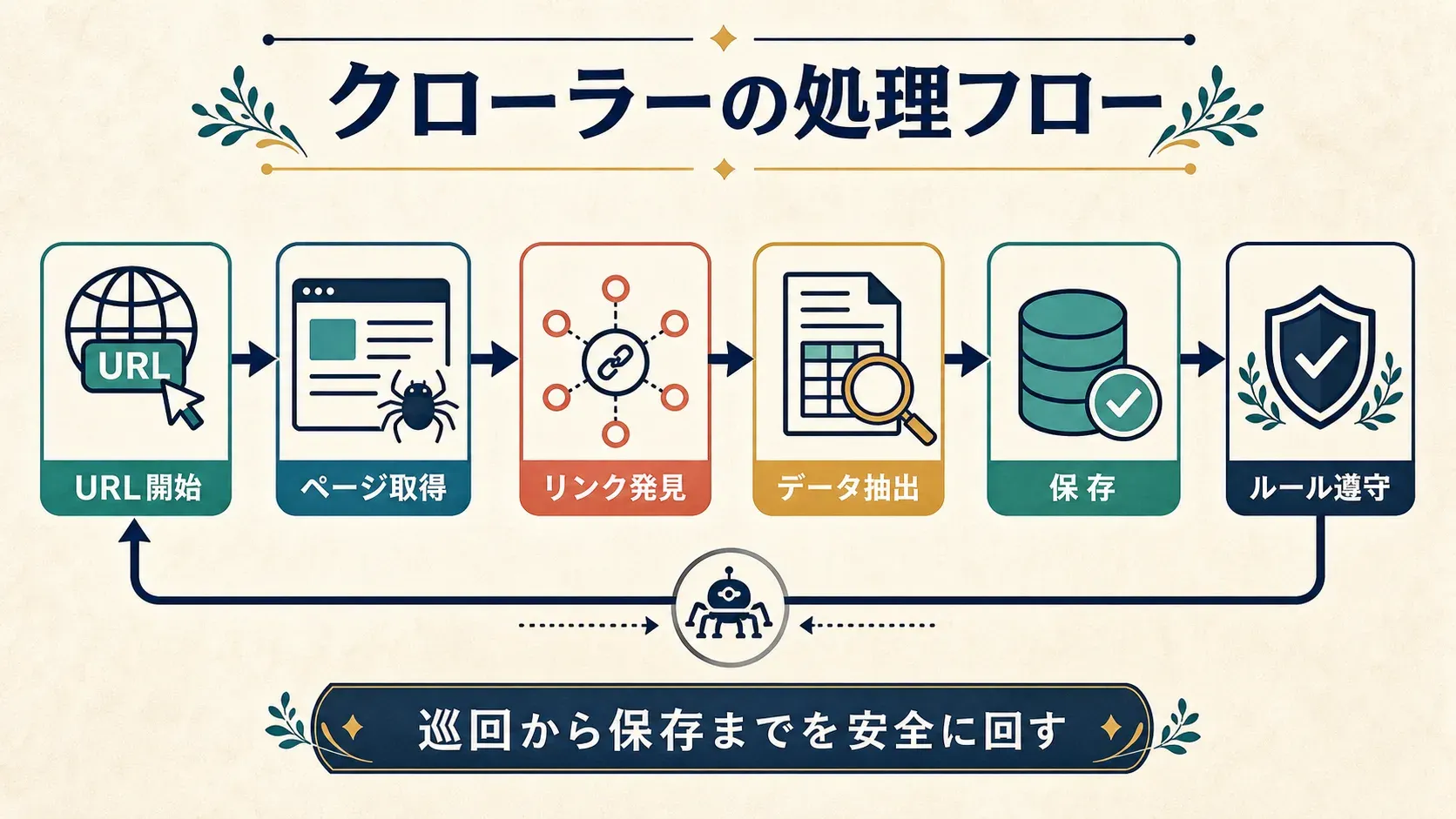 典型的なウェブクローラーは、次の順序でページを取得し、必要なデータを保存します。
典型的なウェブクローラーは、次の順序でページを取得し、必要なデータを保存します。
- シードを指定する:出発点となるURLの一覧を設定します。
- ページを取得する:各URLへリクエストを送り、コンテンツをダウンロードします。
- リンクを抽出する:取得したページ内のリンクを識別します。
- 巡回対象を追加する:未訪問のリンクをキューへ加えます。
- 必要なデータを抽出する:テキスト、画像、価格などを取り込み、用途に応じて構造化します。
- 結果を保存する:データベースに保存するか、分析用の形式でエクスポートします。
- 巡回ルールを設定する:各サイトの
robots.txtを参照し、クローラーに示された巡回方針を把握します(Cloudflare)。ただし、robots.txtだけで利用の可否を判断せず、対象サイトの利用規約や権利関係も別途照合する必要があります。
運用時の基本事項:
- アクセス間隔や同時実行数を調整し、サーバーに過度な負荷をかけない。
- 取得対象と利用目的について、プライバシー、著作権、利用規約などの条件を調べる。
- 訪問済みURLを管理し、重複取得や不要なリクエストを避ける。
ウェブクローラー利用時の課題と注意点
ウェブクローリングを運用する際は、取得処理だけでなく、アクセス負荷、重複取得、データの取り扱い、対象サイトの技術仕様も考慮する必要があります。
- サーバー負荷:短時間にリクエストを集中させると、対象サイトの応答が遅くなったり、利用に影響したりする可能性があります。
- 重複コンテンツ:URLの表記違いやページ内リンクの循環により、同じコンテンツを繰り返し取得することがあります。
- プライバシーと法的な問題:取得できるデータが、そのまま自由に利用できるとは限りません。対象サイトの利用規約、取得データの権利関係、個人情報の取り扱いを用途ごとに照合する必要があります。
- 技術的な制約:CAPTCHA、動的コンテンツ、ボット対策などにより、自動取得が制限されるサイトもあります(DEV Community)。
運用時の対策:
- 対象サイトへの影響を見ながら、アクセス間隔と同時実行数を設定する。
- HTML構造や取得結果を記録し、サイト変更による抽出エラーを検知する。
- 適用されるデータ保護規制や社内ルールを定期的に見直す。
Thunderbit:非エンジニア向けのウェブデータ収集
従来型のウェブクローラーでは、コードの作成、取得条件の設定、動作確認や修正に時間がかかる場合があります。Thunderbitは、こうした初期設定の負担を減らし、Webページ上の情報を表形式で取得したいビジネスユーザー向けのAI搭載ウェブスクレイパー Chrome拡張機能です。コードを書かずに利用でき、主に次の機能を備えています。
- 自然言語の指示:「このページから商品名と価格を全部取って」のように取得したい項目を伝えると、ThunderbitのAIが抽出設定を支援します。
- AIによる項目提案:「AIで列を提案」をクリックすると、ページを読み取り、抽出候補となる列を提案します。必要な列に整えてから実行できます。
- サブページのスクレイピング:商品詳細やLinkedInプロフィールなどのサブページを訪問し、追加情報をデータセットへ含める用途に利用できます。
- 即時テンプレート:Amazon、Zillow、Shopifyなどの人気サイト向けに、ワンクリック抽出用のテンプレートが用意されています。
- 簡単エクスポート:Excel、Google Sheets、Airtable、Notionへ直接送れます。
- 無料データエクスポート:結果はCSVまたはJSONで、完全無料でダウンロードできます。
Thunderbitは、営業リスト作成、ECの商品情報取得、不動産情報の整理など、非エンジニアがWebページを表データにしたい場面に向いています。一方、大規模な収集基盤、特殊な認証、複雑な処理が必要な場合は、APIやコードベースの方法も比較対象になります。現在、営業チーム、EC運営担当、不動産の担当者など、世界中で20万人を超えるユーザーに使われています。
Thunderbit AI Web Scraperを無料で試す
Thunderbitと従来型ウェブクローラーの比較
Thunderbitと従来型クローラーでは、設定方法、必要なスキル、保守方法、適した処理規模が異なります。選定時の主な観点を整理します。
| 機能 | Thunderbit | 従来型クローラー |
|---|---|---|
| 設定時間 | 2クリック(AIが設定を支援) | 要件によって数時間〜数日(手動設定、コーディング) |
| 必要な技術スキル | コーディング不要(平易な英語で指示) | コーディング、セレクター、スクリプトの知識が必要 |
| 柔軟性 | サイト構造に応じて利用でき、変更への対応をAIが支援 | 詳細なカスタマイズが可能だが、レイアウト変更時に修正が必要な場合がある |
| サブページのスクレイピング | 標準搭載(対象ページと設定に応じて利用) | 要件に応じたスクリプト設定が必要 |
| エクスポート形式 | Excel、Sheets、Airtable、Notion、CSV、JSON | 実装に応じてCSV、JSON、データベースなどへ出力 |
| 保守 | ページ変更への対応をAIが支援 | 仕様変更に応じて手動修正が必要 |
Thunderbitは、技術的な設定に時間をかけず、まずWebページ上のデータを表形式で取得したい場合に向いています。大規模処理、複雑な条件分岐、社内システムとの深い連携が必要な場合は、従来型クローラーも比較対象になります(Thunderbit Blog)。
Thunderbitでウェブクローラーを始める方法
Thunderbitの基本的な操作は、次の手順で試せます。対象ページの構造や取得項目によって所要時間は異なりますが、単純なページであれば数分で設定を始められます。
- Thunderbit Chrome拡張機能をインストールします。
- クロールしたいWebサイトを開きます。
- Thunderbitのアイコンをクリックし、「AIで列を提案」を押します。 AIがページ内容をもとに列を提案します。
- 必要に応じて項目を整え、「スクレイプ」をクリックします。 指定すれば、Thunderbitがサブページも含めてデータを抽出します。
- 結果をエクスポートします。Excel、Google Sheets、Airtable、Notionに送るか、CSV/JSONとしてダウンロードします。
データスクレイピングとは何か、2025年にどう行うか Get Started Free
最初は、取得結果を目視できる1ページで試し、必要な列が正しく抽出されているか、欠損や重複がないか、希望する形式で出力できるかを検証すると導入判断がしやすくなります。価格追跡、リードリスト作成、ニュース集約などでは、対象サイトや件数によって、非エンジニアでも半日程度で初期作業を終えられる場合があります。継続運用へ移す前に、対象サイトの利用規約、アクセス頻度、抽出精度を見直してください。
まとめ:ウェブクローラーを業務データ収集に活用する
ウェブクローラーは、Webページを巡回し、検索、比較、分析に必要な情報を収集する仕組みです。検索エンジンだけでなく、営業、EC、不動産、市場調査など、最新情報を継続的に扱う業務で利用できます。
ThunderbitのようなAI搭載ツールを使うと、専門的なコードを書かずに、Webページ上の情報を構造化データへ変換しやすくなります。ただし、対象サイトや処理規模によって適した方法は異なります。取得精度、利用規約、個人情報、著作権、アクセス負荷を検討し、複雑な要件ではコードやAPIを使う方法とも比較することが重要です。
導入を検討する場合は、まず実際の業務で使う1ページを選び、必要な項目、抽出精度、出力形式を検証してください。そのうえで、Thunderbitをダウンロードし、価格確認やリスト作成など対象を限定した作業から試すと、運用条件を判断しやすくなります。さらに詳しいコツや深掘り記事は、Thunderbit Blogをご覧ください。
AIウェブスクレイパーを試す Get Started Free
よくある質問
1. ウェブクローラーとは具体的に何ですか?
ウェブクローラーとは、ウェブページを体系的に巡回し、リンクをたどり、インデックス化や分析のために情報を集める自動プログラムです。スパイダーやボットと呼ばれることもあります。
2. ウェブクローラーとウェブスクレイパーの違いは何ですか?
ウェブクローラーは、リンクをたどって複数のページを発見・巡回することを主な目的とします。一方、ウェブスクレイパーは、特定のページから必要な項目を抽出し、表やデータベースで扱える形に整えることに重点を置きます。実務では両方を組み合わせることがあり、Thunderbitのような新しいツールの多くも、ページ巡回とデータ抽出の機能を備えています。
3. なぜウェブクローラーはビジネスに重要なのですか?
ウェブクローラーは、競合価格の監視、コンテンツの集約、リードリスト作成など、更新される情報を継続的に収集する用途で使えます。取得頻度や対象範囲を適切に設定すれば、市場や商品情報の変化を把握し、業務上の判断を支える材料になります。
4. ウェブクローラーの使用は合法ですか?
合法かどうかは、対象サイト、取得方法、データの種類、利用目的、適用される法令や契約条件によって異なるため、一概には判断できません。対象サイトの利用規約、著作権、個人情報の取り扱い、サーバーへの負荷を調べ、必要に応じて法務担当者や専門家へ相談してください。robots.txtはクローラー向けの巡回方針を示すものですが、それだけでデータ利用の法的な許可を判断することはできません。
5. Thunderbitはどうやってウェブクローリングを簡単にするのですか?
Thunderbitは、AIによる設定支援、項目提案、データ抽出を通じて、コードを書かずにWebページ上の情報を表形式へ整理しやすくします。自然言語の指示や即時テンプレートを利用でき、抽出したデータはExcel、Google Sheets、Airtable、Notionへ直接エクスポートできます。まず対象ページで必要な列が正しく取得できるかを検証し、大規模処理や複雑な連携が必要な場合は、APIやコードベースの方法も比較してください。詳細はこちら




