
インターネットにはとんでもない量のデータが転がっていて、世界のウェブスクレイピングソフトウェア市場はなんだって。ビジネスアナリストやマーケター、データに興味がある人なら、ウェブサイトからデータを取得するスキルはもう必須レベル。僕みたいに手作業でコピペするのはもう卒業して、すぐに使えるインサイトや整理されたスプレッドシート、さらには自動化までやりたい人も多いはず。
そこで頼りになるのがPython。Pythonはデータ分野の万能選手で、初心者でも扱いやすいし、1ページだけのスクレイピングから大規模なクロールまで幅広く対応できる。この記事では、Pythonを使ったウェブスクレイピングの基本から、動的なウェブサイトへの対応方法、さらにみたいなAI搭載・ノーコードのウェブスクレイパーまで紹介するよ。コードを書いて学びたい人も、手軽にデータを取りたい人も、きっと役立つ内容になってる。
ウェブスクレイピングって何?Pythonでデータを取る理由
ウェブスクレイピングは、ウェブサイト上の情報を自動で集めて、スプレッドシートやCSV、データベースみたいな構造化データに変換する技術()。人が手作業でコピペする代わりに、ウェブスクレイパーが高速かつ大量にデータを取ってきてくれる。
なんでこれが大事なのか?今のビジネスはデータに基づく意思決定が当たり前。が、価格戦略や市場調査、リード獲得などにスクレイピングで得たデータを活用してる。競合の価格を毎日チェックしたり、不動産情報をまとめたり、独自リストを作ったり、いろんな場面で大活躍。
じゃあ、なんでPythonが選ばれるの?理由はこれ!
- 読みやすくてシンプル:Pythonの文法は直感的で、初心者でもウェブスクレイピングのスクリプトが書きやすい()。
- ライブラリが豊富:
requests、BeautifulSoup、Scrapy、Seleniumなど、スクレイピングや解析、自動操作に便利なツールが揃ってる。 - コミュニティが活発:Pythonはの一つで、情報やサンプルコードが山ほどある。
- スケーラビリティ:小さなスクリプトから大規模なクローラーまで柔軟に対応できる。
つまり、Pythonは初心者からプロまで、ウェブデータ活用の最初の一歩にぴったりな言語!
まずはここから:Pythonウェブスクレイピングの基本フロー
実際にコードを書く前に、Pythonでウェブサイトからデータを取得する基本の流れを整理しよう。
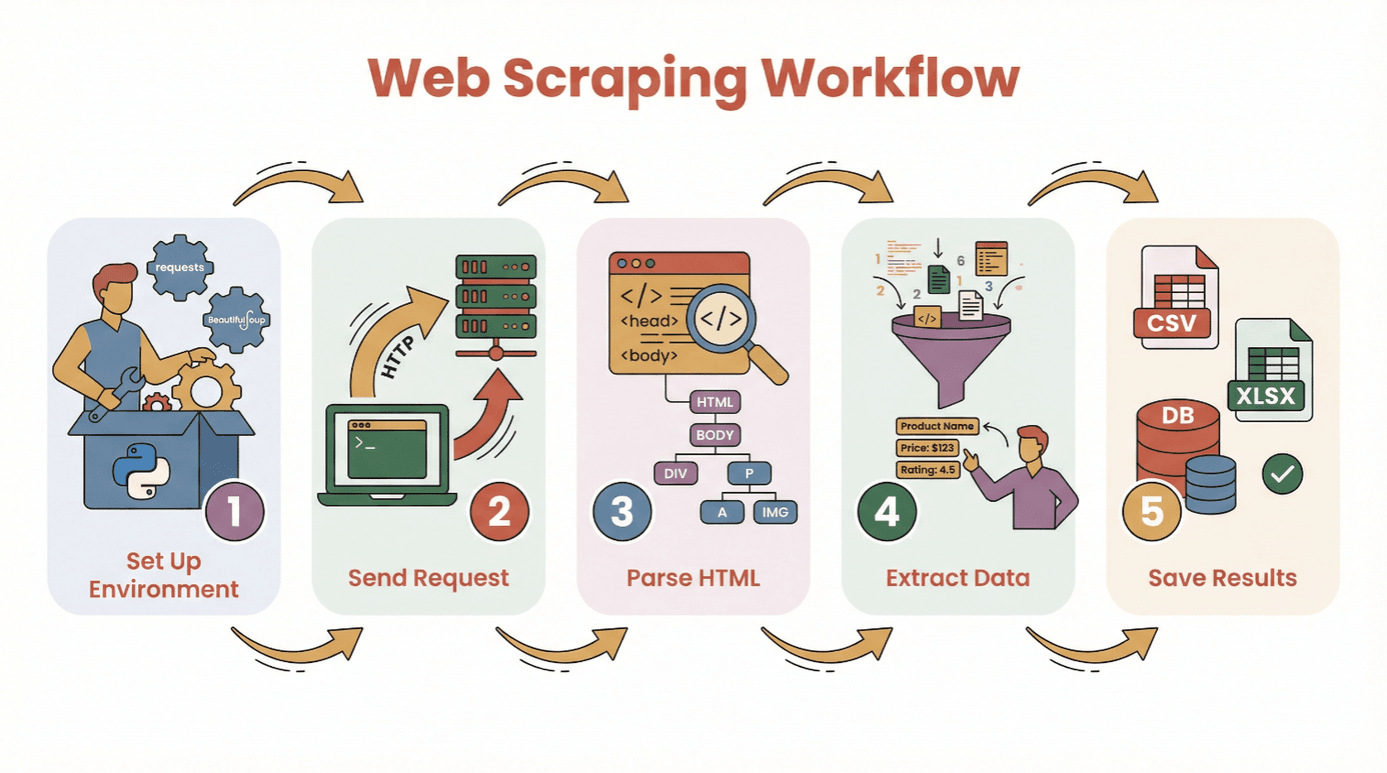
- 環境構築:Pythonと必要なライブラリ(
requests、BeautifulSoupなど)をインストール - リクエスト送信:Pythonで対象ページのHTMLを取得
- HTML解析:パーサーでページ構造を解析
- データ抽出:必要な情報をピックアップ
- 保存:CSVやExcel、データベースに保存
難しい知識は不要。Pythonのインストールとスクリプトの実行ができれば、もう半分はクリア!初心者はやJupyterノートブックを使うのもおすすめ。
主なライブラリ:
requests— ウェブページの取得BeautifulSoup— HTML解析pandas— データの保存やクリーニング(おすすめ)
Pythonウェブスクレイピングの代表的なライブラリ比較:BeautifulSoup、Scrapy、Selenium
Pythonのウェブスクレイピングツールにはそれぞれ特徴がある。代表的な3つを比較してみよう。
| ツール | 得意な用途 | 強み | 注意点 |
|---|---|---|---|
| BeautifulSoup | シンプルな静的ページ・初心者向け | 使いやすく、セットアップが簡単、ドキュメントも充実 | 大規模クロールや動的コンテンツには不向き |
| Scrapy | 大規模・多ページのクロール | 高速・非同期・パイプラインやデータ保存機能も内蔵 | 学習コストがやや高い、小規模用途にはオーバースペック、JavaScriptは非対応 |
| Selenium | 動的/JavaScript主体のサイト・自動操作 | JSレンダリング対応、ユーザー操作の再現、ログインやクリックも可能 | 動作が重く、セットアップが複雑 |
BeautifulSoup:シンプルなHTML解析に最適
BeautifulSoupは初心者や小規模プロジェクトにぴったり。HTMLを数行のコードで解析して、要素を抽出できる。対象サイトが静的(JavaScriptで動的にデータを読み込まない)なら、requestsとBeautifulSoupだけで十分。
例:
1import requests
2from bs4 import BeautifulSoup
3url = "https://example.com"
4response = requests.get(url)
5soup = BeautifulSoup(response.text, 'html.parser')
6titles = [h2.text for h2 in soup.find_all('h2', class_='product-title')]
7print(titles)使いどころ:単発のデータ取得、ブログや商品ページ、ディレクトリなど
Scrapy:大規模・構造化クロール向け
Scrapyはウェブサイト全体のクロールや大量ページの処理に最適なフレームワーク。非同期処理で高速、データの保存やクレンジングも自動化できる。
例:
1import scrapy
2class ProductSpider(scrapy.Spider):
3 name = "products"
4 start_urls = ["https://example.com/products"]
5 def parse(self, response):
6 for item in response.css('div.product'):
7 yield {
8 'name': item.css('h2::text').get(),
9 'price': item.css('span.price::text').get()
10 }使いどころ:大規模プロジェクト、定期クロール、高速処理が必要なとき
Selenium:動的・JavaScript主体のサイト対応
Seleniumは実際のブラウザ(ChromeやFirefox)を操作できるから、JavaScriptでデータが後から表示されるサイトや、ログイン・クリックが必要な場合に大活躍。
例:
1from selenium import webdriver
2from selenium.webdriver.common.by import By
3driver = webdriver.Chrome()
4driver.get("https://example.com/login")
5driver.find_element(By.NAME, "username").send_keys("myuser")
6driver.find_element(By.NAME, "password").send_keys("mypassword")
7driver.find_element(By.XPATH, "//button[@type='submit']").click()
8dashboard = driver.find_element(By.ID, "dashboard").text
9print(dashboard)
10driver.quit()使いどころ:SNS、株価サイト、無限スクロール、ソース表示でデータが見つからないとき
実践:Pythonでウェブサイトからデータを取得する手順(初心者向け)
ここではrequestsとBeautifulSoupを使って、書籍リストサイトからタイトル・著者・価格を取得する例を紹介。
ステップ1:Python環境の準備
まず必要なライブラリをインストール:
1pip install requests beautifulsoup4 pandasスクリプトでインポート:
1import requests
2from bs4 import BeautifulSoup
3import pandas as pdステップ2:ウェブサイトにリクエスト送信
HTMLを取得:
1url = "http://books.toscrape.com/catalogue/page-1.html"
2response = requests.get(url)
3if response.status_code == 200:
4 html = response.text
5else:
6 print(f"Failed to retrieve page: {response.status_code}")ステップ3:HTMLの解析
BeautifulSoupオブジェクトを作成:
1soup = BeautifulSoup(html, 'html.parser')書籍のコンテナを抽出:
1books = soup.find_all('article', class_='product_pod')
2print(f"Found {len(books)} books on this page.")ステップ4:必要なデータの抽出
各書籍から詳細を取得:
1data = []
2for book in books:
3 title = book.h3.a['title']
4 price = book.find('p', class_='price_color').text
5 data.append({"Title": title, "Price": price})ステップ5:データの保存
DataFrameに変換して保存:
1df = pd.DataFrame(data)
2df.to_csv('books.csv', index=False)これで分析用のCSVファイルが完成!
トラブルシューティングのコツ:
- 結果が空なら、データがJavaScriptで後から読み込まれていないか確認
- ブラウザの開発者ツールでHTML構造をチェック
- 欠損データは
get_text(strip=True)や条件分岐で対応
動的コンテンツへの対応:JavaScriptで生成されるデータの取得方法
最近のウェブサイトはJavaScriptを多用していて、データが初期HTMLに含まれていないことも。ウェブスクレイパーでデータが取れない場合、動的コンテンツの可能性大。
対処法:
- Selenium:実際のブラウザを操作して、コンテンツの読み込みを待ってからデータを取得
- Playwright/Puppeteer:さらに高度なヘッドレスブラウザ操作も可能
Seleniumのミニガイド:
- Seleniumとブラウザドライバー(例:ChromeDriver)をインストール
- 明示的な待機でコンテンツの読み込みを待つ
- レンダリング後のHTMLをBeautifulSoupで解析
例:
1from selenium import webdriver
2from selenium.webdriver.common.by import By
3from selenium.webdriver.support.ui import WebDriverWait
4from selenium.webdriver.support import expected_conditions as EC
5driver = webdriver.Chrome()
6driver.get("https://example.com/dynamic")
7WebDriverWait(driver, 10).until(
8 EC.presence_of_element_located((By.CLASS_NAME, "dynamic-content"))
9)
10html = driver.page_source
11soup = BeautifulSoup(html, 'html.parser')
12# ここからデータ抽出
13driver.quit()Seleniumが必要なケース
requests.get()で取得したHTMLにデータがないけど、ブラウザでは見える場合- 無限スクロールやポップアップ、ログインが必要なサイト
AIでウェブスクレイピングをもっと簡単に:Thunderbitでデータ取得
「とにかくデータだけ欲しい、コードは面倒…」そんなときはの出番。ThunderbitはAI搭載のChrome拡張で、数クリックでどんなウェブサイトからもデータを取得できる。Pythonの知識は一切不要。
Thunderbitの使い方:
- をインストール
- 取得したいウェブサイトを開く
- Thunderbitアイコンをクリックして「AIでフィールドを提案」を選択。AIがページを解析して、商品名や価格、メールアドレスなど抽出候補を自動で提示してくれる。
- 必要に応じてフィールドを調整し、「スクレイピング開始」
- データをExcel、Google Sheets、Notion、Airtableなどに直接エクスポート
Thunderbitの強み:
- コード不要。パソコンが苦手な人でも直感的に使える
- サブページやページ送りも自動対応。複数ページの商品情報もまとめて取得
- 自然言語で指示可能。「商品名と価格を抽出して」と伝えるだけでOK
- 人気サイト用テンプレートも充実。Amazon、Zillow、LinkedInなどはワンクリックで完了
- データエクスポート無料。CSVやExcel、各種ツールにすぐ連携
Thunderbitはしていて、無料プランでも6ページ(トライアルで10ページ)までウェブスクレイピング可能。ビジネスの時短はもちろん、エンジニアのプロトタイピングにも最適。
スクレイピング後のデータ整理・分析:pandasとNumPyの活用
データを取得したら、次は整理と分析。ウェブから取った生データは重複や欠損、フォーマットの乱れがつきもの。PythonのpandasやNumPyがここで大活躍。
よく使うデータ整形:
- 重複削除:
df.drop_duplicates(inplace=True) - 欠損値処理:
df.fillna('Unknown')やdf.dropna() - 型変換:
df['Price'] = df['Price'].str.replace('$','').astype(float) - 日付変換:
df['Date'] = pd.to_datetime(df['Date']) - 外れ値除外:
df = df[df['Price'] > 0]
基本的な分析例:
- 要約統計量:
df.describe() - カテゴリごとの集計:
df.groupby('Category')['Price'].mean() - 簡単なグラフ:
df['Price'].hist()やdf.groupby('Category')['Price'].mean().plot(kind='bar')
より高度な数値計算や配列操作にはNumPyが便利だけど、ビジネス用途ならpandasだけで十分なことが多い。
参考: pandas初心者にはガイドがおすすめ。
Pythonウェブスクレイピング成功のコツ・注意点
ウェブスクレイピングは強力だけど、マナーとルールも大事。トラブルを避けるためのチェックリスト:
- robots.txtや利用規約を必ず確認()
- サーバーに負荷をかけない。リクエスト間に
time.sleep(2)などで間隔を空ける - User-Agentヘッダーを設定して、実際のブラウザを装う
- エラー処理を丁寧に。try/exceptやリトライ処理を活用
- 大規模スクレイピング時はプロキシを活用。IPブロック対策に
- 倫理・法令遵守。許可なく個人情報やログイン後のデータは取得しない
- 作業記録を残す。何を・どこから・いつ取得したかメモ
- 公式APIがあればそちらを優先。HTMLスクレイピングより安全・確実な場合も
さらに詳しいノウハウはも参考にしてみて。
まとめ・ポイント
Pythonによるウェブスクレイピングは、ウェブ上の膨大な情報を整理して、ビジネスや分析に活かすための強力な武器。requests、BeautifulSoup、Scrapy、Seleniumなどのコード派も、ノーコードの派も、目的に合わせて最適な方法を選ぼう。
ポイント:
- まずは1ページのウェブスクレイピングから始めてみよう
- BeautifulSoup(基本)、Scrapy(大規模)、Selenium(動的)、Thunderbit(ノーコード)など用途で使い分け
- pandasやNumPyでデータを整理・分析
- いつもマナーと法令を守ってウェブスクレイピングを実施
まずは小さなプロジェクトから始めて、今日のニュースや商品リストを取ってみよう。コードが苦手な人はして、AIにお任せするのもおすすめ。
さらに詳しいチュートリアルやノウハウはでチェック!
よくある質問(FAQ)
1. ウェブスクレイピングって何?なんでPythonが人気?
ウェブスクレイピングはウェブサイトからデータを自動取得する技術。Pythonは文法が分かりやすく、BeautifulSoupやScrapy、Seleniumなど強力なライブラリが揃っていて、コミュニティも活発だから人気()。
2. Pythonでどのライブラリを使えばいい?
静的なページにはBeautifulSoup、大規模・多ページクロールにはScrapy、動的・JavaScript主体のサイトにはSeleniumが向いてる。用途に合わせて選ぼう()。
3. JavaScriptでデータが表示されるサイトはどう対応?
Selenium(またはPlaywright)でブラウザを自動操作して、コンテンツの読み込みを待ってからデータを取得。場合によってはネットワーク通信からAPIエンドポイントを見つけられることも。
4. Thunderbitって何?どんなメリットがある?
はAI搭載のChrome拡張で、コード不要でどんなウェブサイトからもデータを取得できる。AIがフィールド提案やサブページ・ページ送りも自動対応、ExcelやGoogle Sheets、Notion、Airtableに直接エクスポート可能。
5. Pythonで取得したデータの整理・分析方法は?
pandasで重複削除や欠損値処理、型変換、集計分析ができる。数値計算にはNumPy、グラフ作成にはpandasとMatplotlibの連携が便利()。
データがいつもきれいで、すぐに使える状態であることを願ってるよ。
さらに学ぶ