商品価格やライバルのレビュー、リードリストなどをウェブから集めた経験がある人なら、あの単調な繰り返し作業のしんどさ、きっと身に覚えがあるはずです。クリックして、コピーして、ペーストして…気づけばコーヒーも根気も底をついてしまう。実は、ウェブデータ抽出は今や営業やオペレーション、マーケティング現場の“隠れた必殺技”。単なる時短だけじゃなく、インサイト発見や面倒な作業の自動化、そしてライバルよりも早い意思決定を実現してくれます。
自分自身、しっかり設計されたウェブデータ抽出のワークフローが、1週間かかる手作業をたった5分で終わらせるのを何度も目の当たりにしてきました。初心者も、もっとスキルアップしたい人も、このガイドでは基本から落とし穴、実践的な手順まで、従来のやり方とAI搭載ツールの両方を使って分かりやすく解説します。ウェブを自分専用のデータ資源に変えていきましょう。
ウェブデータ抽出とは?基本をおさらい
ウェブデータ抽出(ウェブスクレイピングとも呼ばれる)は、ウェブサイトから必要な情報を自動で集めて、スプレッドシートやデータベースなどに整理してくれる技術です。手作業でコピー&ペーストする代わりに、ウェブスクレイパーがデジタルアシスタントのようにページを巡回し、価格や商品名、メールアドレス、レビューなど必要なデータを見つけてまとめてくれます()。
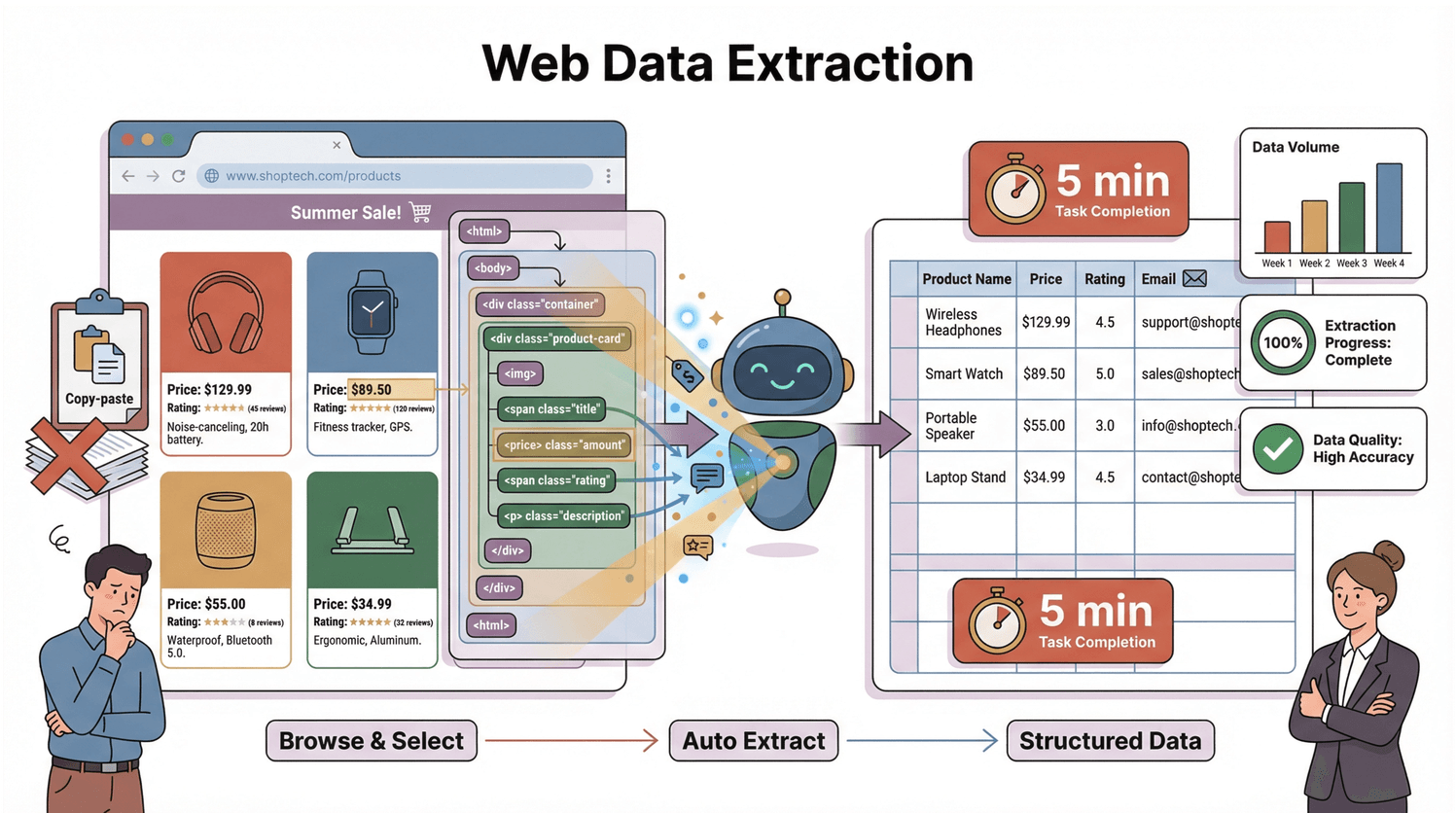
じゃあ、どうやって動いてるの?というと、すべてのウェブページはDOM(ドキュメントオブジェクトモデル)という構造でできています。これは、ブラウザやスクレイパーに「どこに何があるか」を示す設計図みたいなもの。スクレイパーはこの設計図を読み取って、必要な要素を特定し、行や列にきれいに並べてくれます。まるで、疲れ知らずの超優秀なアシスタントがそばにいる感覚です。
営業・業務部門でウェブデータ抽出が重宝される理由
正直言って、ウェブデータ抽出はオタクの趣味じゃなく、ビジネスの強力な武器です。営業・オペレーション・マーケティングの現場で導入が進む理由はこんな感じ:
ROIだけじゃありません。データ収集を自動化すれば、チームは戦略立案に集中できて、単純作業から解放されます。実際、データ収集コストを40%削減した企業もあり()、ウェブスクレイピング市場は2023年の50億ドルから2032年には1,400億ドル超へと急成長が予想されています()。膨大なデータが新しいビジネスチャンスを生み出しているんです。
ウェブデータ抽出の仕組み:DOMからデータテーブルへ
仕組みをざっくり分解すると、こんな流れです:
- リクエスト: スクレイパーがウェブサイトにアクセスしてHTMLデータを取得。
- 解析: ページのDOM(ツリー構造)を読み取り、各要素を把握。
- 抽出: 必要なデータ(価格、名前、メールなど)を特定し、CSVやExcel、Google Sheetsなどの表形式に整理()。
DOMの理解:ウェブデータ抽出の基礎
DOMはウェブページの「家系図」みたいなもの。最上位にドキュメントがあって、そこから<html>、<head>、<body>…と枝分かれし、各<div>や<span>、テキストに至ります()。このツリーの各ノードがターゲットです。
たとえば商品の価格を取りたい場合、スクレイパーは<body>内の<div>、さらにその中の<span class="price">を探します。まるで「キッチンに行って冷蔵庫を開けて牛乳を取ってきて」と指示する感じ。DOMが地図、スクレイパーが探検者です。
ただ、最近のウェブサイトはJavaScriptで動的にデータを表示することが多く、最初のHTMLには欲しい情報が入っていないことも。ページの読み込みやスクリプト実行後のレンダリング済みDOMを取得できるツールが必要です()。ここが従来型スクレイパーの弱点であり、最新ツールの強みです。
ウェブデータ抽出でよくある落とし穴と対策
ウェブスクレイピングは一見簡単そうで、意外とつまずきやすいもの。主な課題とその回避策をまとめました:
- 動的コンテンツ・無限スクロール: 多くのサイトはデータを動的に表示したり、スクロールで追加表示します。初期HTMLだけを取得するツールでは不十分。JavaScriptレンダリングやスクロールのシミュレーションができるツール(Thunderbitは自動対応)が必要です()。
- ページ分割・サブページ: データが複数ページや詳細ページに分かれている場合、「次へ」ボタンやリンクをたどれる機能が必須。Thunderbitの「サブページ抽出」機能が役立ちます()。
- サイト構造の変化: サイトのレイアウトが少し変わるだけで従来型スクレイパーは動かなくなります。ThunderbitのようなAI搭載ツールなら自動で適応し、修正の手間が激減します()。
- アンチスクレイピング対策: CAPTCHAやIPブロック、リクエスト制限などに注意。リクエスト間隔を空けたり、ランダム化したり、ブラウザベースのツールで実際のユーザーのように振る舞いましょう。サイトの利用規約も必ず確認を()。
- データの乱れや不統一: サイトによってはデータ構造がバラバラ。AIプロンプトやカスタムルールで柔軟に抽出できるThunderbitの「フィールドAIプロンプト」が便利です。
動的ページ・JavaScriptレンダリングへの対応
一部のページは、スクロールやクリックで初めてデータが表示されます。従来型スクレイパーは見逃しがちですが、Thunderbitのようなブラウザ拡張なら、ユーザーと同じ画面を見てすべてのデータを取得できます()。
アンチスクレイピング対策の回避法
ブロックやCAPTCHAが出たら、リクエスト速度を落としたり、IPをローテーションしたり、実際のユーザーに近い動作を心がけましょう。robots.txtや利用規約も必ず確認を()。
ウェブデータ抽出ツール比較:Thunderbitと従来型ソリューション
データ抽出の方法はいろいろありますが、主なアプローチを比較すると:
| ソリューション | セットアップ時間 | 必要スキル | メンテナンス | 機能・エクスポート |
|---|---|---|---|---|
| 手動コピー&ペースト | 不要 | 不要 | 常に手作業 | 自動化なし・ミスが多い |
| カスタムコード(Python等) | 数時間〜数日 | コーディング+HTML | 高い | 柔軟・どこでも出力可・習得難易度高 |
| 従来型ノーコードツール | サイトごと約1時間 | 多少の技術知識 | 中程度 | ビジュアル設定・ページ分割対応・中程度の学習コスト |
| Thunderbit(AIノーコード) | 数分 | 不要(日本語でOK) | 低(AIが自動対応) | AIフィールド検出・サブページ・スケジューリング・Sheets/Excel/Notion出力 |
Thunderbitは、ビジネスユーザー向けに設計されているので、コード不要で直感的に使えます。やりたいことを日本語で伝えるだけで、AIが自動で設定してくれます()。
Thunderbitがビジネスユーザーに選ばれる理由
- 2クリックの簡単操作: 「AIフィールド提案」→「抽出」だけ。
- AIによるフィールド認識: ページをAIが解析し、最適なカラムを自動提案。
- ノーコード・自然言語対応: 「商品名と価格をすべて取得」など、日本語で指示するだけ。
- サブページ・ページ分割も自動化: すべてのページや詳細リンクもワンクリックで抽出。
- 即エクスポート: データをExcel、Google Sheets、Notion、Airtableに直接出力。追加料金なし。
- クラウド・ブラウザ両対応: クラウドで高速抽出、ログインが必要なページはブラウザで対応。
Thunderbitは、サイト構造の変化やデータの乱れにも強く、ビジネス現場で「すぐに使える」実用性を重視しています。
Thunderbitを使ったウェブデータ抽出の流れ
実際にThunderbitでウェブデータを抽出する手順を紹介します。
ステップ1:Thunderbit Chrome拡張機能をインストール
からThunderbitを追加し、無料アカウントを作成。無料プランでも複数ページのテストができます。
ステップ2:抽出したいウェブサイトにアクセス
対象サイトを開き、必要ならログイン。欲しいデータが全部表示されているか確認しましょう。
ステップ3:Thunderbitを開き、抽出内容を指示
Thunderbitアイコンをクリックして、
- **「AIフィールド提案」**でAIにカラムを自動検出させる
- または「商品名、価格、レビューを抽出」などカスタムプロンプトを入力
AIが抽出候補をプレビュー表示。不要なカラムの削除や名前変更もOK。
ステップ4:抽出を実行
**「抽出」**をクリック。データがテーブル形式で取得されます。複数ページやサブページがある場合は「すべて抽出しますか?」と聞かれるので「はい」を選択。
ステップ5:結果を確認しエクスポート
抽出結果を確認し、抜けがあればプロンプトを調整したり、ページを再読み込み。問題なければ**「エクスポート」**でCSVダウンロード、またはGoogle Sheets、Excel、Notion、Airtableに直接送信できます。
実例:ThunderbitでAmazon商品レビューを抽出
たとえば、競合商品のAmazonレビューを分析したい場合:
- Amazonの商品ページで「すべてのレビューを見る」をクリック。
- Thunderbitを起動。 Amazonレビュー用テンプレートが表示されたら利用(必要なフィールドが事前設定済み)()。
- **「抽出」**をクリック。レビュワー名、評価、本文、日付などを全ページから取得。
- エクスポート。 そのまま感情分析や競合比較、「顧客が本当に気にしていること」レポート作成に活用できます。
カスタマイズしたい場合は「レビュワー名、星評価、日付、レビュー本文を抽出」など自然言語で指示すれば、AIが自動で対応。Amazonのレイアウトが変わっても安心です。
応用編:Thunderbitで抽出をカスタマイズ&自動化
基本操作に慣れたら、Thunderbitの高度な機能でさらに効率化できます:
- フィールドAIプロンプト: 各カラムごとに「星1・2のレビューのみ抽出」「レビュー本文を英訳」など細かく指示可能。
- 定期抽出(スケジューリング): 日次・週次など自動実行で常に最新データを取得。価格監視やリード獲得に最適()。
- AIオートフィル: フォーム入力や複数ステップの自動化も可能。検索やログインが必要なサイトにも対応。
- クラウド抽出: 大量データもクラウドで高速・安定して取得。
- 即時テンプレート: Amazon、Zillow、Yelp、LinkedInなど人気サイト用テンプレートも豊富()。
Google Sheets連携やチーム共有、他ツールとの自動連携も簡単です。
ウェブデータ抽出の未来:AIの進化とビジネスインパクト
AIの進化でウェブデータ抽出はどんどん進化中:
- 高い適応力: AI搭載スクレイパーはサイト構造の変化にも自動対応し、保守コストやダウンタイムを大幅削減()。
- エージェント型抽出: ボットが人間のようにクリックや操作を行い、これまで取得できなかったデータも収集可能に。
- リアルタイムデータ: 単発抽出から、常時最新データを取得するパイプラインへと進化。
- 誰でも使える: Thunderbitのようなノーコード・自然言語ツールで、非エンジニアでも簡単にデータ抽出が可能に。
- 即時インサイト: 今後は抽出と同時にAI分析も実現。例えば競合レビューを集めて、主要な課題を自動要約することも。
まとめると、AI搭載ウェブデータ抽出は、スプレッドシートやCRMと同じくらいビジネスに欠かせない存在へ。これを使いこなすチームが、ライバルより一歩先を行けるはずです。
まとめ・ポイント
- ウェブデータ抽出でインターネットを自分専用のデータベースに。リード、価格、レビューなどを自動収集。
- DOMはすべてのウェブページの設計図。これを理解することが効率的な抽出のカギ。
- よくある課題(動的コンテンツ、アンチボット対策、データの乱れ)は、適切なツールと知識で回避可能。
- Thunderbitなら誰でも簡単にウェブデータ抽出。2クリック、AIフィールド検出、サブページ抽出、主要ツールへの即時エクスポート。
- AIが未来を切り拓く—より速く、賢く、信頼性の高いデータ抽出がビジネスユーザーにも身近に。
今すぐして、ウェブデータ抽出の手軽さを体感してみてください。さらに詳しい使い方や事例はでチェックできます。
よくある質問
1. ウェブデータ抽出とは?どんな仕組み?
ウェブデータ抽出(ウェブスクレイピング)は、ウェブサイトから情報を自動収集し、スプレッドシートなどの構造化データに変換する技術です。ウェブサイトのDOM(ドキュメントオブジェクトモデル)を解析し、必要なデータを特定してエクスポートします()。
2. ウェブデータ抽出でよくある課題は?
主な課題は、動的コンテンツ(JavaScriptで表示されるデータ)、アンチスクレイピング対策(CAPTCHAやIPブロック)、データ構造の乱れなどです。Thunderbitのような最新ツールはAIやブラウザベースの抽出でこれらを解決します()。
3. Thunderbitは他のウェブスクレイピングツールと何が違う?
ThunderbitはAI搭載・ノーコードのウェブスクレイパーで、ビジネスユーザー向けに設計されています。2クリックでセットアップ、自然言語プロンプト、サブページ抽出、ExcelやGoogle Sheets、Notion、Airtableへの即時エクスポートが特徴です()。
4. Thunderbitで動的・複数ページのサイトも抽出できる?
もちろん可能です。Thunderbitは無限スクロールやJavaScriptで表示されるデータ、複数ページやサブページも自動で抽出します()。
5. ウェブデータ抽出は合法?
公開データの抽出は一般的に合法ですが、必ずサイトの利用規約やrobots.txtを確認しましょう。個人情報や非公開データの抽出は避け、サイトに負荷をかけないよう配慮してください()。
快適なスクレイピングライフを!スプレッドシートがいつも新鮮なデータでいっぱいになり、コピー&ペースト作業が過去のものになりますように。
さらに詳しく知りたい人はこちら