
ウェブ上にはデータがあふれており、それを取得したいという需要も急速に高まっています。ただし、市場規模を1つの数字で見積もろうとすると、ソフトウェア、サービス、プロキシ、あるいはそのすべてを含めるかで結果が大きく食い違うことがあります。率直に言えば、ウェブスクレイピングはデータ基盤の中で「地味だけれど欠かせない」領域として定着しています。
ビジネスアナリストでも、マーケターでも、あるいは好奇心旺盛な初心者でも、ウェブサイトからデータを取得する力はすぐに必須スキルになりつつあります。私のように、延々とコピー&ペーストを繰り返す作業は飛ばして、すぐに価値のあるところ、つまり実行可能なインサイト、きれいなスプレッドシート、そして少しの自動化の魔法にたどり着きたい人も多いはずです。
そこで登場するのがPythonです。Pythonはデータの世界の万能ナイフのような存在で、初心者にも扱いやすく、それでいて1ページのスクレイピングから数千ページのクロールまでこなせるほど強力です。この実践的なチュートリアルでは、Pythonを使ったウェブスクレイピングの基本から、動的サイトへの対応方法まで順を追って解説し、さらにデータ抽出を宅配を頼むくらい簡単にしてくれる、AI搭載・ノーコードのウェブスクレイパーも紹介します。コードを学びたい人も、近道が欲しい人も、ここがぴったりの出発点です。
ウェブスクレイピングとは? Pythonでウェブサイトからデータを取得する理由
ウェブスクレイピングとは、ウェブサイトから情報を自動で抽出し、スプレッドシート、CSV、データベースなどの構造化された形式に変換して、分析や業務利用に役立てる方法です()。人が手作業でコピー&ペーストする代わりに、スクレイパーが人間の操作を真似しながら、圧倒的な速度と規模で処理します。
なぜこれほど価値があるのでしょうか。今日のビジネスでは、データドリブンな意思決定が当たり前だからです。規模が大きくなるほど、感覚ではなく実データで裏付けたい意思決定も増えます。そして、そのデータの多くは誰かのウェブページ上で最初に生まれています。
競合価格を毎日チェックしたり、不動産情報をまとめて集約したり、独自の見込み客リストを作成したり——そんなことが、ほとんど手間なくできるとしたらどうでしょう。
では、なぜPythonなのでしょうか。ウェブスクレイピングでPythonが選ばれる理由は次のとおりです。
- 読みやすさとシンプルさ: Pythonの構文はすっきりしていて初心者にも親しみやすく、スクレイピング用スクリプトを書いたり理解したりしやすいです()。
- 豊富なエコシステム:
requests、BeautifulSoup、Scrapy、Seleniumなどのライブラリが、スクレイピング、解析、ブラウザ操作の自動化をぐっと簡単にしてくれます。 - 強力なコミュニティ: Pythonは一貫してとして上位にあり、無数のチュートリアル、フォーラム、コード例が見つかります。
- 拡張性: Pythonは、簡単な単発スクリプトから大規模クロールまで対応できます。
要するに、Pythonはウェブデータの世界への入場券です。まったくの初心者でも、経験豊富なアナリストでも同じように使えます。
まずは基本から:Pythonウェブスクレイピング入門の流れ
コードに入る前に、Pythonでウェブサイトからデータを取得する基本の流れを整理しておきましょう。
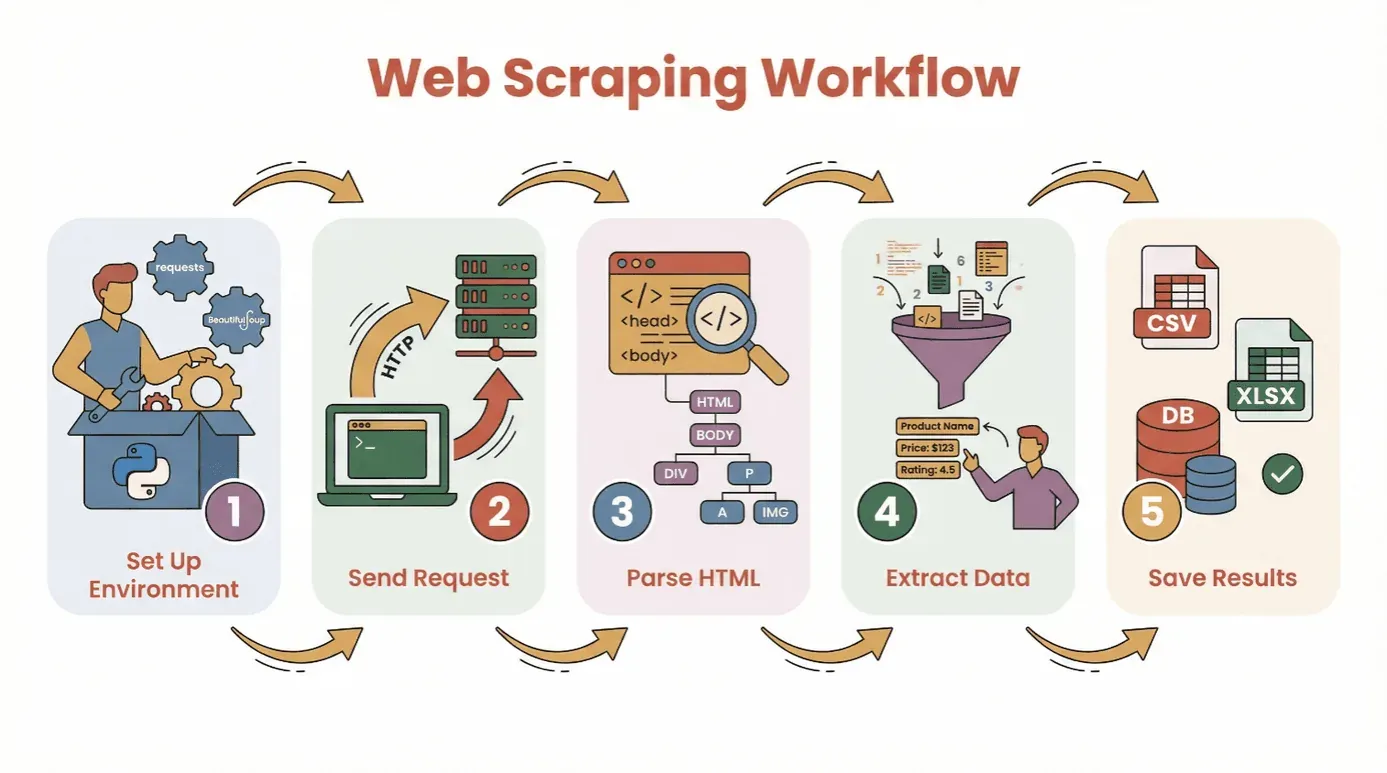
- 環境を準備する: Pythonと必要なライブラリ(
requests、BeautifulSoupなど)をインストールします。 - リクエストを送る: Pythonを使って対象ページのHTMLを取得します。
- HTMLを解析する: パーサーを使ってページの構造をたどります。
- データを抽出する: 必要な情報を見つけて取り出します。
- 結果を保存する: CSV、Excelファイル、またはデータベースに保存して分析に使います。
コードの達人である必要はありません。Pythonをインストールしてスクリプトを実行できれば、もう半分はクリアです。完全な初心者なら、やJupyter Notebookの利用をおすすめしますが、基本的なテキストエディタでも問題ありません。
必須ライブラリ:
requests— Webページの取得用BeautifulSoup— HTML解析用pandas— データの保存・整形用(任意ですが、かなりおすすめです)
どのPythonウェブスクレイピングライブラリを選ぶべき? BeautifulSoup、Scrapy、Seleniumの比較
Pythonのスクレイピングツールはどれも同じではありません。ここでは、特に人気の高い3つを簡単に見ていきます。
| ツール | 最適な用途 | 強み | 弱み |
|---|---|---|---|
| BeautifulSoup | シンプルで静的なページ、初心者向け | 使いやすい、導入が簡単、ドキュメントが充実 | 大規模クロールや動的コンテンツにはあまり向かない |
| Scrapy | 大規模・複数ページのクロール | 高速、非同期、パイプライン内蔵、クロールと保存処理に対応 | 学習コストが高め、小規模作業にはやや大げさ、JavaScriptは実行しない |
| Selenium | 動的サイト、JavaScriptが多いサイト、自動操作 | JSを描画できる、ユーザー操作を再現できる、ログインやクリックに対応 | 遅い、リソースを多く使う、設定がやや複雑 |
BeautifulSoup:シンプルなHTML解析の定番
BeautifulSoupは、初心者や小規模プロジェクトに最適です。数行のコードでHTMLを解析し、要素を抽出できます。対象サイトがほぼ静的で、複雑なJavaScript読み込みがないなら、BeautifulSoupとrequestsだけで十分です。
例:
1import requests
2from bs4 import BeautifulSoup
3url = "https://example.com"
4response = requests.get(url)
5soup = BeautifulSoup(response.text, 'html.parser')
6titles = [h2.text for h2 in soup.find_all('h2', class_='product-title')]
7print(titles)使いどころ:単発の取得、シンプルなブログ、商品ページ、ディレクトリなど。
Scrapy:大規模・構造化クロール向け
Scrapyは、サイト全体のクロールや数千ページ規模の処理に対応できる本格的なフレームワークです。非同期処理なので高速で、データの整形・保存用パイプラインも備えており、リンクを自動でたどることもできます。
例:
1import scrapy
2class ProductSpider(scrapy.Spider):
3 name = "products"
4 start_urls = ["https://example.com/products"]
5 def parse(self, response):
6 for item in response.css('div.product'):
7 yield {
8 'name': item.css('h2::text').get(),
9 'price': item.css('span.price::text').get()
10 }使いどころ:大規模プロジェクト、定期クロール、速度と構造が必要な場合。
Selenium:動的サイトやJavaScript中心のサイトへの対応
SeleniumはChromeやFirefoxのような実ブラウザを操作するため、JavaScriptでデータを読み込むサイト、ログインが必要なサイト、ボタンのクリックが必要なサイトにも対応できます。
例:
1from selenium import webdriver
2from selenium.webdriver.common.by import By
3driver = webdriver.Chrome()
4driver.get("https://example.com/login")
5driver.find_element(By.NAME, "username").send_keys("myuser")
6driver.find_element(By.NAME, "password").send_keys("mypassword")
7driver.find_element(By.XPATH, "//button[@type='submit']").click()
8dashboard = driver.find_element(By.ID, "dashboard").text
9print(dashboard)
10driver.quit()使いどころ:SNS、株価サイト、無限スクロールのページ、「ページのソースを表示」すると空っぽに見えるサイトなど。
手順付き:Pythonでウェブサイトからデータを取得する方法(初心者向け)
ここでは、requests と BeautifulSoup を使って実例を見ていきましょう。書籍一覧サイトから、タイトル、著者、価格をスクレイピングします。
ステップ1:Python環境を準備する
まず、必要なライブラリをインストールします。
1pip install requests beautifulsoup4 pandasその後、スクリプトに読み込みます。
1import requests
2from bs4 import BeautifulSoup
3import pandas as pdステップ2:ウェブサイトにリクエストを送る
HTMLを取得します。
1url = "http://books.toscrape.com/catalogue/page-1.html"
2response = requests.get(url)
3if response.status_code == 200:
4 html = response.text
5else:
6 print(f"ページの取得に失敗しました: \{response.status_code\}")ステップ3:HTMLを解析する
BeautifulSoupオブジェクトを作成します。
1soup = BeautifulSoup(html, 'html.parser')すべての書籍コンテナを見つけます。
1books = soup.find_all('article', class_='product_pod')
2print(f"このページで {len(books)} 冊見つかりました。")ステップ4:必要なデータを抽出する
各書籍をループして詳細を取得します。
1data = []
2for book in books:
3 title = book.h3.a['title']
4 price = book.find('p', class_='price_color').text
5 data.append({"タイトル": title, "価格": price})ステップ5:分析用に保存する
DataFrameに変換して保存します。
1df = pd.DataFrame(data)
2df.to_csv('books.csv', index=False)これで、分析に使えるきれいなCSVファイルができました。
トラブルシューティングのヒント:
- 結果が空なら、データがJavaScriptで読み込まれていないか確認してください(次のセクションを参照)。
- ブラウザの開発者ツールでHTML構造を必ず確認しましょう。
- 欠損データは
get_text(strip=True)と条件分岐で処理します。
動的コンテンツへの対処:JavaScriptで描画されるサイトからデータを取得する
最近のサイトはJavaScriptを多用しています。ページが表示されたあとにデータを読み込むため、最初のHTMLには欲しい情報が入っていないこともあります。スクレイパーが何も取れない場合は、動的コンテンツが原因かもしれません。
対処方法:
- Selenium: 実ブラウザをシミュレートし、コンテンツの読み込みを待って、ボタン操作やスクロールもできます。
- Playwright / Puppeteer: さらに高度ですが、考え方は同じです(ヘッドレスブラウザ)。
Seleniumミニガイド:
- Seleniumとブラウザドライバー(例:ChromeDriver)をインストールします。
- 明示的な待機を使って、コンテンツが読み込まれるのを待ちます。
- 描画後のHTMLを取得し、必要ならBeautifulSoupで解析します。
例:
1from selenium import webdriver
2from selenium.webdriver.common.by import By
3from selenium.webdriver.support.ui import WebDriverWait
4from selenium.webdriver.support import expected_conditions as EC
5driver = webdriver.Chrome()
6driver.get("https://example.com/dynamic")
7WebDriverWait(driver, 10).until(
8 EC.presence_of_element_located((By.CLASS_NAME, "dynamic-content"))
9)
10html = driver.page_source
11soup = BeautifulSoup(html, 'html.parser')
12# ここまでと同じようにデータを抽出
13driver.quit()Seleniumが必要になるのはどんなとき?
requests.get()ではデータなしのHTMLが返るのに、ブラウザでは見えている場合。- 無限スクロール、ポップアップ、ログイン必須のサイト。
AIでウェブスクレイピングをもっと簡単に:Thunderbitでウェブサイトからデータを取得する
正直なところ、コードではなくデータだけ欲しいという場面もあります。そんなときに役立つのがです。ThunderbitはAI搭載のChrome拡張機能で、数回クリックするだけでどんなウェブサイトからでもデータを取得できます。Pythonは必要ありません。
Thunderbitの使い方:
- をインストールします。
- 対象サイトを開きます。
- Thunderbitのアイコンをクリックして「AIで項目を提案」を押します。 ThunderbitのAIがページを解析し、どのデータを抽出すべきか提案します(例:商品名、価格、メールアドレス)。
- 必要に応じて項目を調整し、「スクレイプ」をクリックします。
- データをExcel、Google Sheets、Notion、Airtableへ直接エクスポートします。
Thunderbitが優れている理由:
- コーディング不要。 私の母でも使えます(今でもWi-Fiの不調があると私に電話してきます)。
- サブページやページネーションに対応。 複数ページの商品詳細を取得したいですか? Thunderbitならページを順番にたどって、データをまとめてくれます。
- 自然言語の指示に対応。 「すべての商品タイトルと価格を抽出して」と伝えるだけで、あとはAIが処理します。
- 人気サイト向けの即使用テンプレート。 Amazon、Zillow、LinkedInなど、ワンクリックで完了します。
- データを書き出しやすい。 CSV、Excelでダウンロードするか、好きなツールへそのまま送れます。
Thunderbitは世界中でに利用されています。無料プランもあり、まずは料金を払わずに試せます。利用枠は変わることがあるため、最新の上限はで確認してください。ビジネス利用者にとっては時間短縮の強い味方であり、Pythonユーザーにとっては、自作スクレイパーを書く価値があるか判断する前に、作業の見積もりを取るのにも便利です。
スクレイピング後:PandasとNumPyでデータを整形・分析する
データ取得は最初の一歩にすぎません。生のWebデータは、重複、欠損値、変な形式などで散らかっていることが多いです。そこで役立つのが、PythonのpandasとNumPyです。
よくある整形作業:
- 重複を削除する:
df.drop_duplicates(inplace=True) - 欠損値を処理する:
df.fillna('Unknown')またはdf.dropna() - データ型を変換する:
df['Price'] = df['Price'].str.replace('$','').astype(float) - 日付を解析する:
df['Date'] = pd.to_datetime(df['Date']) - 外れ値を除外する:
df = df[df['Price'] > 0]
基本的な分析:
- 要約統計:
df.describe() - カテゴリ別集計:
df.groupby('Category')['Price'].mean() - 簡単な可視化:
df['Price'].hist()またはdf.groupby('Category')['Price'].mean().plot(kind='bar')
より高度な数値計算や高速な配列処理には、NumPyが便利です。ただし、多くのビジネス用途では、pandasだけで必要な作業の95%はカバーできます。
参考資料: pandasが初めてなら、 をチェックしてみてください。
Pythonでウェブスクレイピングを成功させるためのベストプラクティスとヒント
ウェブスクレイピングは強力ですが、責任も伴います。ブロックされたり訴えられたりしない、プロらしいスクレイピングのために、私のチェックリストを紹介します。
- robots.txtと利用規約を尊重する。 サイトがスクレイピングを許可しているか必ず確認しましょう()。
- サーバーに負荷をかけすぎない。 リクエストの間隔を空け(
time.sleep(2)など)、人間らしい速度で取得します。 - 自然なヘッダーを使う。 User-Agentを設定してブラウザのように見せます。
- エラーを丁寧に処理する。 try/except を使い、失敗したリクエストは再試行します。
- 必要ならプロキシを使う。 大規模スクレイピングでは、IPブロック回避のためにプロキシプールの利用を検討します。
- 倫理と法令を守る。 許可なく個人データやログインの裏側にあるコンテンツを取得しないでください。
- 作業を記録する。 何を、どこから、いつ取得したのかをメモしておきます。
- 公式APIがあるなら優先する。 HTMLをスクレイピングするより、もっと良い方法があることもあります。
さらに詳しいヒントは、をご覧ください。
まとめと重要ポイント
Pythonを使ったウェブスクレイピングは、ウェブの混沌を構造化された実用データに変えるための強力な武器です。requests、BeautifulSoup、Scrapy、Selenium を使ったコードでも、のようなノーコードツールでも、ウェブサイトからデータを取得して新しいインサイトを引き出すための手段がそろっています。
覚えておきたいこと:
- まずはシンプルに始める——大きなプロジェクトに挑む前に、1ページだけをスクレイピングしてみましょう。
- 目的に合ったツールを選ぶ(基本はBeautifulSoup、規模ならScrapy、動的サイトはSelenium、ノーコードならThunderbit)。
- pandasとNumPyでデータを整形・分析する。
- 常に責任と倫理を持ってスクレイピングする。
さあ、自分で試してみませんか? まずは小さなプロジェクトから始めてみましょう。たとえば、今日のニュース見出しや商品リストをスクレイピングして、未加工のウェブページからきれいなスプレッドシートにどれくらい早く変えられるか確かめてみてください。コードを飛ばしたいなら、して、重い作業はAIに任せましょう。
さらに多くのチュートリアル、ヒント、ウェブスクレイピングの知識は、でチェックできます。
よくある質問
1. ウェブスクレイピングとは何ですか? なぜPythonが人気なのですか?
ウェブスクレイピングとは、ウェブサイトからデータを自動で抽出することです。Pythonが人気なのは、読みやすい構文、BeautifulSoup・Scrapy・Seleniumのような強力なライブラリ、そして充実したコミュニティサポートがあるからです()。
2. ウェブスクレイピングにはどのPythonライブラリを使えばいいですか?
シンプルで静的なページにはBeautifulSoup、大規模または複数ページのクロールにはScrapy、動的サイトやJavaScriptが多いサイトにはSeleniumを使いましょう。用途に応じて、それぞれに強みがあります()。
3. JavaScriptでデータを読み込むサイトはどう処理すればいいですか?
JavaScriptで描画されるコンテンツには、Selenium(またはPlaywright)を使ってブラウザをシミュレートし、データが読み込まれるのを待ってから抽出します。ネットワーク通信を確認すると、裏側のAPIエンドポイントが見つかることもあります。
4. Thunderbitとは何ですか? どうやってウェブスクレイピングを簡単にするのですか?
は、コードなしでどんなウェブサイトからでもデータを取得できるAI搭載のChrome拡張機能です。AIが抽出項目を提案し、サブページやページネーションを処理し、データをExcel、Google Sheets、Notion、Airtableへ直接エクスポートします。
5. Pythonで取得したデータはどうやって整形・分析すればいいですか?
pandasを使えば、重複削除、欠損値処理、データ型変換、分析ができます。NumPyは数値計算に便利です。可視化には、pandasとMatplotlibを組み合わせると簡単にグラフを作れます()。
楽しくスクレイピングを。データがいつもきれいで、構造化され、すぐ使える状態になりますように。
さらに詳しく