

火曜日の昼前、OpenRouter のダッシュボードを見て思わず固まりました。すでに47ドル使っていたのです。こなしたコーディング作業はせいぜい十数件。大げさなことは何もしていません。ちょっとしたリファクタリングと、いくつかのバグ修正だけです。そこで気づいたのが、OpenClaw のデフォルト設定では、バックグラウンドの heartbeat ping まで含めて、あらゆるやり取りが Claude Opus に流れており、1百万トークンあたり15ドル超の料金が発生していたという事実でした。
似たような「え、そんなに?」という経験がある方も多いはずです。フォーラムを見ても、同じ驚きを感じている人は少なくありません(あるユーザーは「そんなに使っていないのにもう40ドルかかった」と書いていました)。この記事では、私が月額コストを約90%削減するために実践した、監査と最適化の全手順を紹介します。単に「安いモデルに変える」だけではなく、どこで実際にトークンが消費されているのか、どう監視するのか、本当にエージェント作業に耐えうる低コストモデルはどれか、そして今日そのまま使える3つのコピペ設定まで、体系的に解説します。作業全体は半日で完了しました。
OpenClaw のトークン使用量とは? なぜデフォルトでこんなに高いのか?
トークンとは、OpenClaw でのあらゆる AI 互动の課金単位です。ざっくり言えば、文字の小さなかたまりのようなもの。英語ならおよそ4文字で1トークン程度です。送信するメッセージも、受け取る応答も、バックグラウンドで動く処理も、すべてトークンとして課金されます。
問題は、OpenClaw の初期設定が「最安」ではなく「最高性能」を優先していることです。最初から主要モデルは anthropic/claude-opus-4-5 に設定されており、これは使える中で最も高価な選択肢です。heartbeat ping も Opus。サイドタスク用のサブエージェントも Opus。heartbeat ping に Opus を使うのは、絆創膏を貼るだけの作業に脳神経外科医を呼ぶようなものです。能力的には問題なくても、コストは完全にやりすぎです。
多くのユーザーは、単純なバックグラウンド処理にまでプレミアム料金を払っていることに気づいていません。デフォルト構成は、実質的に「何でも常に最高モデルを使う」前提で動いており、その分しっかり請求されます。
OpenClaw のトークン使用量を減らすと、節約できるのはお金だけではない
もちろん一番わかりやすい効果はコスト削減です。ただ、それ以外にも積み上がるメリットがあります。
安いモデルはしばしば速いです。Gemini 2.5 Flash-Lite は 1秒あたり約214トークン で処理できるのに対し、Opus は約51トークン。つまり約4倍の速度差があります。Cerebras 上の GPT-OSS-120B は 1秒あたり1,917トークン に達し、Opus よりおよそ35倍高速です。50回以上の tool-calling を含むエージェントループでは、この差が積み重なり、Opus の重い初回応答遅延 13.6 秒を何度も待つ代わりに、数分で終わるようになります。
さらに、レート制限に引っかかりにくくなり、セッションの throttling も減り、請求額を気にして胃が痛くなることなく利用を拡大できます。
利用規模別の節約イメージは以下のとおりです。
| ユーザー像 | 月額推定コスト(デフォルト) | 最適化後 | 月間削減率 |
|---|---|---|---|
| ライトユーザー(1日約10件) | 約$100 | 約$12 | 約88% |
| 中程度(1日約50件) | 約$500 | 約$90 | 約82% |
| ヘビーユーザー(1日200件以上) | 約$1,750 | 約$220 | 約87% |
これは机上の空論ではありません。ある開発者は、月600〜750ドルから1日3〜4ドルへ と、実に90%近い削減に成功しました。モデルのルーティングに加え、この後紹介する“見えない消費”対策を組み合わせた結果です。
OpenClaw のトークン使用量の内訳:実際にどこで消費されているのか
多くの最適化記事が飛ばしているのが、ここであり、実は最重要ポイントでもあります。見えないものは改善できません。
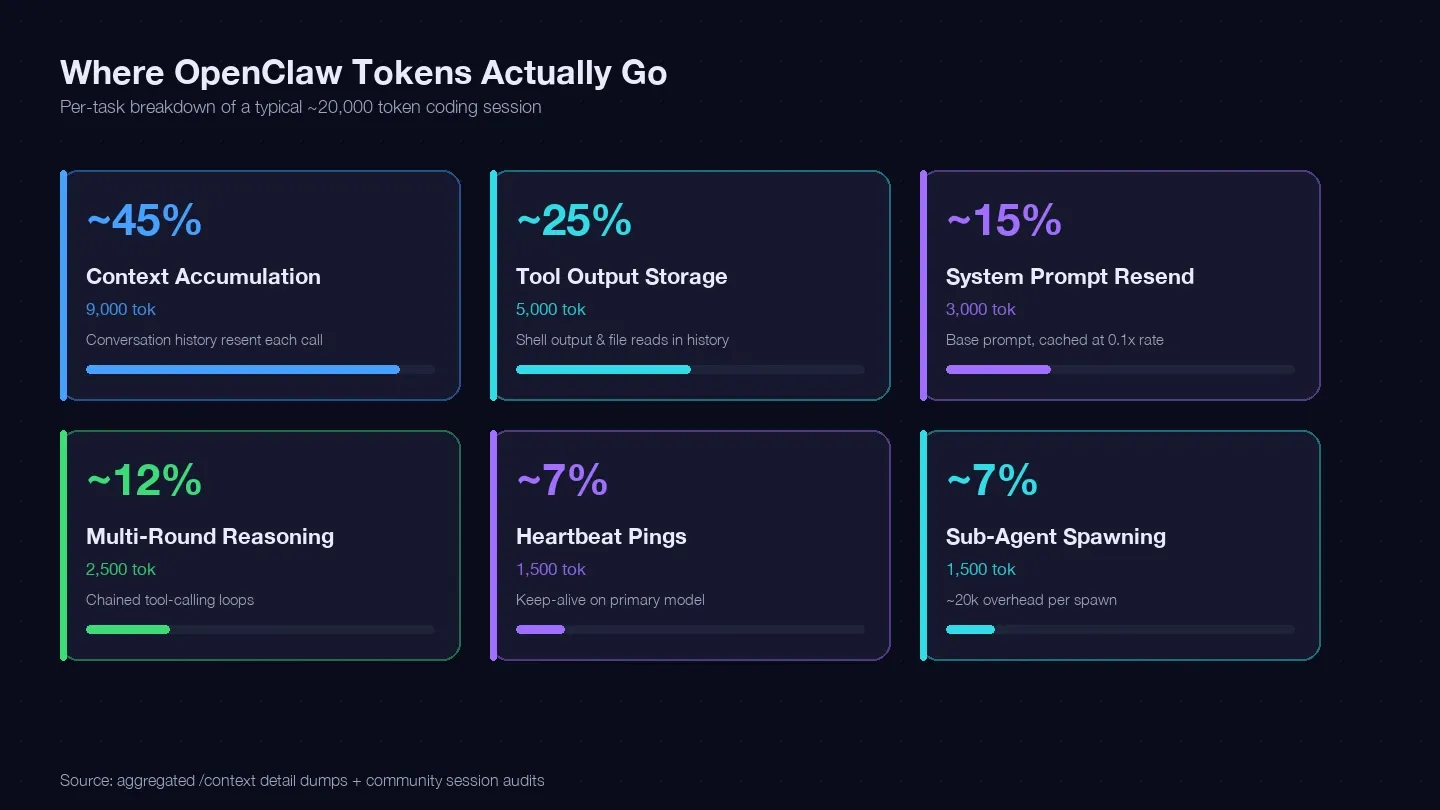
私は複数のセッションを監査し、LaoZhang のコスト最適化ガイド とコミュニティの /context ダンプを突き合わせて、一般的な1件のコーディング作業におけるトークン台帳を作成しました。おおよそ2万トークンが、次のように消費されていました。
| トークンカテゴリ | 全体に占める典型割合 | 例(1件のコーディング作業) | 制御できるか? |
|---|---|---|---|
| コンテキスト蓄積(会話履歴を毎回再送) | 約40〜50% | 約9,000トークン | はい — /clear、/compact、短いセッション |
| ツール出力の保持(shell 出力やファイル読み込みを履歴に残す) | 約20〜30% | 約5,000トークン | はい — 読み取りを小さく、ツール範囲を狭く |
| システムプロンプトの再送(約15Kのベース) | 約10〜15% | 約3,000トークン | 一部可能 — cache read は0.1倍課金 |
| 複数ラウンド推論(tool-calling の連鎖ループ) | 約10〜15% | 約2,500トークン | モデル選択 + より良いプロンプト |
| heartbeat / keep-alive ping | 約5〜10% | 約1,500トークン | はい — 設定変更 |
| サブエージェント呼び出し | 約5〜10% | 約1,500トークン | はい — モデルルーティング |
最大の消費源はコンテキスト蓄積です。つまり、会話履歴が毎回の API 呼び出しで再送されているということです。ある実際のセッションダンプ では、モデルがまだ一言も返す前の段階で、Messages バケットだけで 185,400トークン が記録されていました。さらにその上に、システムプロンプトとツールで約35,800トークンの固定オーバーヘッドが乗っていました。
つまり、関係のない作業のたびにセッションを切り替えずにいると、毎ターンごとに会話履歴全体を再送するコストを払い続けることになります。
OpenClaw のトークン使用量を監視する方法(見えなければ削れない)
何かを変える前に、まずトークンがどこへ消えているかを見える化しましょう。監視なしで「安いモデルに変える」だけでは、体重計に一度も乗らずにダイエットしようとするようなものです。
OpenRouter ダッシュボードを確認する
OpenRouter 経由でルーティングしているなら、Activity ページ が最も手軽で、セットアップ不要のダッシュボードです。モデル、プロバイダー、APIキー、期間で絞り込みができます。Usage Accounting では、各リクエストの prompt、completion、reasoning、cached tokens を分解して確認できます。長期分析用に CSV または PDF でエクスポートも可能です。
見るべきポイントは、どのモデルが最もトークンを消費しているか、そして heartbeat やサブエージェントのリクエストが想定外に大きな行として出ていないかです。
ローカル API ログを監査する
OpenClaw はセッションデータを ~/.openclaw/agents.main/sessions/sessions.json に保存しており、ここにはセッションごとの totalTokens が含まれます。さらに openclaw logs --follow --json を実行すれば、リクエスト単位のログをリアルタイムで追えます。
注意点として、sessions.json の totalTokens は compaction 後に更新されません。そのため、ダッシュボード上では compaction 前の古い数値が残ることがあります。保存値よりも /status や /context detail を信頼してください。
サードパーティの追跡ツールを使う(中〜ヘビーユーザー向け)
LiteLLM proxy は、100以上のプロバイダーの前段に置ける OpenAI互換エンドポイントで、仮想キー、モデル、ユーザー、チームごとの支出を自動記録 します。強力なのは、キーごとの厳格な予算上限を設定できること。/clear を使っても消えず、暴走したサブエージェントが上限を超えるのを防げます。
Helicone はさらにシンプルです。ベースURLを1行差し替えるだけ で、関連リクエストをまとめた Sessions ビューが使えます。たとえば「このバグを直して」という1つの指示から8回以上サブエージェントが派生した場合でも、1つのセッション行に実コストがまとまって表示されます。無料枠は月10,000リクエスト です。
OpenClaw 内での簡単な確認コマンド
日々の監視には、セッション内で次の4コマンドが役立ちます。
/status— コンテキスト使用量、直近の入力/出力トークン、推定コストを表示/usage full— 各応答のフッターに使用量を表示/context detail— ファイル別、skill 別、ツール別のトークン内訳を表示/compact [guidance]— 必要に応じた指示付きで compaction を強制
設定変更の前後で /context detail を実行してください。最適化が本当に効いているかを測るための基準になります。
OpenClaw の最安モデル比較:実際にエージェント作業をこなせる低価格LLMはどれか
多くのガイドはここで間違えます。価格表を出して一番安い行を指差し、「はい終わり」です。しかしベンチマークだけでは、実際のエージェント性能は予測できません。これはコミュニティでも何度も強く指摘されている点です。あるユーザーは「どれがエージェントAIに本当に向いているかを理解するのに、ベンチマークは全然役に立っていない」と言っていました。
重要なのは、最安モデルが最安の結果になるとは限らないということです。失敗して4回やり直すモデルは、1回で成功する中価格帯モデル より高くつきます。実運用のエージェントでは、5〜10%のリトライ率 を前提に考えるべきです。しかも5回のLLM呼び出しが鎖のようにつながり、4段目で失敗すると、単純な再試行では5ステップ全部をやり直すことになります。
以下は、合成ベンチマークではなく実際のユーザー報告をもとにした「Real Agentic Score」を含む、私の能力マトリクスです。
| モデル | 入力 $/100万 | 出力 $/100万 | tool-calling の安定性 | 多段推論 | Real Agentic Score(1〜5) | 最適用途 |
|---|---|---|---|---|---|---|
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | ばらつきあり — たまにループ | 基本的 | ⭐2.5 | heartbeat、簡単な参照 |
| GPT-OSS-120B | $0.04 | $0.19 | まずまず | まずまず | ⭐3.0 | 低予算での検証、速度重視 |
| DeepSeek V3.2 | $0.26 | $0.38 | 不安定(未解決 issue 6件) | 良好 | ⭐3.0 | 推論重視、tool-calling 少なめ |
| Kimi K2.5 | $0.38 | $1.72 | 良好(:exacto 経由) | まずまず | ⭐3.5 | 簡単〜中程度のコーディング |
| MiniMax M2.5 / M2.7 | $0.28 | $1.10 | 良好 | 良好 | ⭐4.0 | 日常使いの一般的なコーディング |
| Claude Haiku 4.5 | $1.00 | $5.00 | 非常に優秀 | 良好 | ⭐4.5 | 安定した中位フォールバック |
| Claude Sonnet 4.6 | $3.00 | $15.00 | 非常に優秀 | 非常に優秀 | ⭐5.0 | 複雑な多段タスク |
| Claude Opus 4.5/4.6 | $5.00 | $15.00 | 非常に優秀 | 非常に優秀 | ⭐5.0 | 最難関の問題専用 |
DeepSeek と Gemini Flash の tool-calling に関する注意点
DeepSeek V3.2 は表面上かなり優秀に見えます。SWE-Bench で72〜74%、Sonnet より11〜36倍安いとも言われます。しかし実際には、Cline、Roo Code、Continue、NVIDIA NIM にまたがる6件の GitHub issue が、tool-calling の破綻を記録しています。Composio の比較では、「DeepSeek V3.2 はアプリの一部は作れたが、実行、速度、信頼性でつまずいた」という結論でした。Zvi Mowshowitz の一言も象徴的です。「まあまあ安い、でも」。
Gemini 2.5 Flash にも同様のギャップがあります。Google AI Developers Forum の「Gemini 2.5 function calling performance で非常にフラストレーションを感じる」というスレッドは、「Gemini モデルの function calling は完全に不安定で予測不能になってしまった」という書き出しで始まります。
OpenRouter は重要な注意点も示しています。「同じ重みのモデルでも、どのホスト上で動くかによって tools を呼ぶ傾向とその精度は大きく変わりうる」。安価なモデルを OpenRouter 経由で使うなら、:exacto タグを確認してください。プロバイダーが静かに切り替わると、昨日まで安定していた低コストモデルが、突然高価な retry ループに変わることがあります。
モデルごとの使い分け
- Gemini Flash-Lite: heartbeat、keep-alive ping、簡単な Q&A。複数ステップの tool-calling には使わない。
- MiniMax M2.5/M2.7: 一般的なコーディングの主力。Sonnet より大幅に安く、SWE-Pro 56.22、Terminal-Bench 2 57.0% を記録。
- Claude Haiku 4.5: 安いモデルが tool call で詰まったときの信頼できる逃げ道。Sonnet より約3倍安く、tool-calling の安定性が高い。
- Claude Sonnet 4.6: 複雑な多段エージェント作業向け。ここでこそ費用対効果が出ます。
- Claude Opus: 最難関の問題だけに使う。何でもかんでもデフォルトにしない。
(モデル価格は頻繁に変わるため、設定前に OpenRouter または各プロバイダーの公式ページで最新料金を確認してください。)
多くのガイドが見落とす“見えない”トークン消費
フォーラムでは、特定機能を無効化するとコストが大きく下がるという報告が多くありますが、実際のトークン影響まで含めて整理した統合チェックリストは、私が見つけた限りありませんでした。そこで、見落とされがちな消費源を一気に分解します。
| 見えない消費源 | 1回あたりのトークンコスト | 対策 | 設定キー |
|---|---|---|---|
| デフォルト heartbeat が Opus | 分離なしだと約100,000トークン/回 | Haiku へ上書き + isolatedSession | heartbeat.model, heartbeat.isolatedSession: true |
| サブエージェント生成 | 作業前に約20,000トークン/生成 | サブエージェントを Haiku にルーティング | subagents.model |
| コードベース全体のコンテキスト読み込み | 自動探索1回で約3,000〜15,000トークン | node_modules、dist、lockfile を .clawignore で除外 | .clawrules + .clawignore |
| メモリの自動要約 | 1セッションあたり約500〜2,000トークン | 無効化、または頻度を下げる | memory: false または memory.max_context_tokens |
| 会話履歴の蓄積 | 1ターンあたり約500トークン以上(累積) | 関係ない作業の前後で新規セッションにする | /clear 徹底 |
| MCP サーバーのツールオーバーヘッド | 4サーバーで約7,000トークン、5個以上で50,000超 | MCP は最小限に | 未使用 MCP を削除 |
| skill / plugin 初期化 | ロードされた skill ごとに200〜1,000トークン | 使わない skill を無効化 | skills.entries.<name>.enabled: false |
| Agent Teams(plan モード) | 標準セッションの約7倍 | 本当に並列が必要な時だけ使う | 可能なら逐次処理 |
heartbeat の消費は特に重要です。デフォルトでは、heartbeat は30分ごとに主要モデル(Opus)で実行されます。isolatedSession: true を設定すると、1回あたり約100,000トークンだった消費が約2,000〜5,000トークン まで下がり、単体で95〜98%の削減になります。
2分以内でできる、最も効果の大きい3つの改善
以下の3つはすべてリスクゼロで、しかも2分以内にできます。
-
関係ない作業の間で
/clearを使う(5秒)。 これが最も大きな節約になります。フォーラムでは、50〜70%削減 が見込めるという意見が多く、新しい作業を始める前にセッション履歴を消すだけで効果が出ます。先ほどの /context ダンプにあった185kトークンの Messages バケットを思い出してください。/clearはそれを消します。 -
雑務には
/model haiku-4.5を使う(10秒)。 用途に応じてモデルを切り替えるだけで、定型作業のコストを60〜80%削減 できます。Haiku なら、単純なコーディング、ファイル検索、コミットメッセージ作成は十分こなせます。 -
.clawrulesを200行未満に削り、.clawignoreを追加する(90秒)。 ルールファイルは、メッセージのたびに毎回読み込まれます。200行なら1ターンあたり約1,500〜2,000トークン、1,000行なら毎リクエストに8,000〜10,000トークンの恒久的な負担になります。これにnode_modules/、dist/、lockfile、生成コードを除外する.clawignoreを組み合わせると、ある開発者はこの工夫だけで92%のトークン削減 を達成したと報告しています。
手順つき:OpenClaw のトークン使用量を一気に削る、すぐ使える3つの設定

以下に、完全注釈付きの openclaw.json 設定を3種類示します。「まずは始めたい」レベルから「完全最適化スタック」までをカバーしており、それぞれインラインコメントと月額コストの見積もり付きです。
始める前に:
- 難易度: 初級(Config A)→ 中級(Config B)→ 上級(Config C)
- 所要時間: Config A で約5分、Config C で約15分
- 必要なもの: OpenClaw のインストール、テキストエディタ、
~/.openclaw/openclaw.jsonへのアクセス
Config A: 初級 — とにかく節約したい人向け
5行だけ。複雑さはゼロ。デフォルトモデルを Opus から Sonnet に変え、メモリのオーバーヘッドを切り、heartbeat を Haiku に分離します。
// ~/.openclaw/openclaw.json
{
"agents": {
"defaults": {
"model": { "primary": "anthropic/claude-sonnet-4-6" }, // Opus から変更 — すぐに3〜5倍節約
"heartbeat": {
"every": "55m", // 1時間の cache TTL に合わせてキャッシュヒット最大化
"model": "anthropic/claude-haiku-4-5", // ping は Haiku、Opus ではない
"isolatedSession": true // 約10万 → 2〜5千トークン/回
}
}
},
"memory": { "enabled": false } // 約500〜2,000トークン/セッションを節約
}
適用後に見るべき点: /status を適用前後で実行してください。1リクエストあたりのコストがはっきり下がり、OpenRouter の Activity ページ上の heartbeat も Opus ではなく Haiku になっているはずです。
| 利用規模 | デフォルト(Opus) | Config A(Sonnet + Haiku heartbeat) | 削減率 |
|---|---|---|---|
| ライト(1日約10件) | 約$100 | 約$35 | 65% |
| 中程度(1日約50件) | 約$500 | 約$250 | 50% |
| ヘビー(1日約200件) | 約$1,750 | 約$900 | 49% |
Config B: 中級 — 3段階の賢いルーティング
主要作業は Sonnet。サブエージェントと compaction は Haiku。Claude が throttling された場合の格安フォールバックとして Gemini Flash-Lite。フォールバックチェーンで、プロバイダー障害にも自動的に対応します。
{
"agents": {
"defaults": {
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"fallbacks": [
"anthropic/claude-haiku-4-5", // Sonnet が throttled されたら
"google/gemini-2.5-flash-lite" // 最後の切り札として超低コスト
]
},
"models": {
"anthropic/claude-sonnet-4-6": {
"params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
}
},
"heartbeat": {
"every": "55m", // 55分 < 1時間の cache TTL = キャッシュヒット
"model": "google/gemini-2.5-flash-lite", // ping 1回あたり数円レベル
"isolatedSession": true,
"lightContext": true // heartbeat では最小限のコンテキストのみ
},
"subagents": {
"maxConcurrent": 4, // デフォルト8から削減
"model": "anthropic/claude-haiku-4-5" // サブエージェントに Sonnet は不要
},
"compaction": {
"mode": "safeguard",
"model": "anthropic/claude-haiku-4-5", // compaction 要約は Haiku で
"memoryFlush": { "enabled": true }
}
}
}
}
期待される結果: ログ上のサブエージェントは Haiku の料金になり、heartbeat はほぼゼロに近いコストになります。フォールバックチェーンにより、Claude の障害でセッションが止まることなく、Gemini に自動で切り替わります。
| 利用規模 | デフォルト | Config B | 削減率 |
|---|---|---|---|
| ライト | 約$100 | 約$20 | 80% |
| 中程度 | 約$500 | 約$150 | 70% |
| ヘビー | 約$1,750 | 約$500 | 71% |
Config C: 上級者向け — 完全最適化スタック
サブエージェントごとのモデル指定、Haiku 固定のコンテキスト compaction、画像処理を Gemini Flash にルーティング、.clawrules と .clawignore の最適化、未使用 skill の無効化。これで 85〜90% 削減の領域に入れます。
{
"agents": {
"defaults": {
"workspace": "~/clawd",
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"fallbacks": [
"openrouter/anthropic/claude-sonnet-4-6", // 別プロバイダーをバックアップに
"minimax/minimax-m2-7", // 安い日常用フォールバック
"anthropic/claude-haiku-4-5" // 最後の砦
]
},
"models": {
"anthropic/claude-sonnet-4-6": {
"params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
},
"minimax/minimax-m2-7": {
"params": { "maxTokens": 8192 }
}
},
"heartbeat": {
"every": "55m",
"model": "google/gemini-2.5-flash-lite",
"isolatedSession": true,
"lightContext": true,
"activeHours": "09:00-19:00" // 夜間は heartbeat しない
},
"subagents": {
"maxConcurrent": 4,
"model": "anthropic/claude-haiku-4-5"
},
"contextPruning": { "mode": "cache-ttl", "ttl": "1h" },
"compaction": {
"mode": "safeguard",
"model": "anthropic/claude-haiku-4-5",
"identifierPolicy": "strict",
"memoryFlush": { "enabled": true }
},
"bootstrapMaxChars": 12000, // デフォルト20000から削減
"imageModel": "google/gemini-3-flash" // 画像系タスクは低コストモデルへ
}
},
"memory": { "enabled": true, "max_context_tokens": 800 }, // メモリは最小限
"skills": {
"entries": {
"web-search": { "enabled": false },
"image-generation": { "enabled": false },
"audio-transcribe": { "enabled": false }
}
}
}
サブエージェントごとの上書き例 — ~/.openclaw/agents/lint-runner/SOUL.md に貼り付けてください。
---
name: lint-runner
description: lint/format チェックを実行し、軽微な修正を適用する
tools: [Bash, Read, Edit]
model: anthropic/claude-haiku-4-5
---
最低限の .clawignore — これだけでも、通常150k文字規模の bootstrap を30〜50k文字程度まで削れます。
node_modules/
dist/
build/
.next/
coverage/
.venv/
vendor/
*.lock
package-lock.json
yarn.lock
pnpm-lock.yaml
*.min.js
*.min.css
**/__snapshots__/
**/*.snap
| 利用規模 | デフォルト | Config C | 削減率 |
|---|---|---|---|
| ライト | 約$100 | 約$12 | 88% |
| 中程度 | 約$500 | 約$90 | 82% |
| ヘビー | 約$1,750 | 約$220 | 87% |
これらの数字は、2つの独立した実例とも整合します。Praney Behl の記録では月600〜750ドル → 1日3〜4ドル(90%削減)、また LaoZhang のケーススタディでは、部分的な最適化で943ドル → 347ドル(63%)、1,750ドル → 1,000ドル(64%)、200ドル → 70ドル(65%) が示されています。
/model コマンドで OpenClaw のトークン使用量をその場で制御する
/model コマンドは、会話コンテキストを保持したまま次のターンで使うモデルを切り替えます。リセットなし、履歴消失なし。これを日常習慣にすることで、節約効果が積み上がります。
実用的な使い方:
- 厄介な複数ファイルのリファクタリング中? Sonnet のまま。
- 「この正規表現って何してる?」のような軽い確認?
/model haikuで質問して、終わったら/model sonnetで戻す。 - コミットメッセージや文章の整え?
/model flash-liteで十分。
openclaw.json の commands.aliases にエイリアスを設定して、haiku、sonnet、opus、flash のような短い名前を正式なプロバイダ文字列に割り当てられます。切り替えのたびの入力が少し楽になります。
計算してみると、1日50件をすべて Sonnet で処理すると約3ドル/日です。同じ50件でも、Haiku/Sonnet/Opus を70/20/10で使い分けると約1.10ドル/日になります。1か月換算では、90ドル → 33ドル。ツールは同じでも、習慣を変えるだけで63%安くなります。
おまけ:Thunderbit で OpenClaw のモデル価格をプロバイダー横断で追跡する
AI でプロバイダー横断のモデル価格を追跡 Get Started Free
OpenRouter、Anthropic 直契約 API、Google AI Studio、DeepSeek、MiniMax など、モデルもプロバイダーも非常に多く、価格は頻繁に変動します。Anthropic はある日突然、Opus の出力価格を約67%引き下げました。Google も 2025年12月に Gemini の無料枠制限を 50〜80% 調整しました。静的な価格スプレッドシートを手作業で追い続けるのは、ほぼ負け戦です。
Thunderbit は、スクレイピングコードなしでこの問題を解決します。こうした構造化データ抽出のために作られた Chrome 拡張機能 型の AI web scraper です。
私が使っている流れは次のとおりです。
- Chrome で OpenRouter のモデル一覧ページを開き、Thunderbit の「AI Suggest Fields」をクリック。 ページを読み取り、モデル名、入力価格、出力価格、コンテキストウィンドウ、プロバイダーなどの列を提案してくれます。
- Scrape を実行し、そのまま Google Sheets にエクスポート。
- 自然文でスケジュールスクレイプを設定。 たとえば「毎週月曜9時に OpenRouter のモデル一覧を再取得」と書くだけで、クラウド上で自動実行されます。
これで、個人用の価格トラッカーが自動更新されるようになります。あるモデルが突然30%安くなったり、あるプロバイダーに Exacto タグが付いたりしても、月曜朝のスプレッドシートに自動で反映されます。私たちはブログで AI による業務データ抽出 の活用例も紹介しています。
Anthropic、Google、DeepSeek のような直提供ページ間で価格を比較したい場合も、Thunderbit のサブページスクレイピングなら各モデルリンク先の詳細ページまでたどって、プロバイダーごとの料金を抽出できます。たとえば、Kimi K2.5 を OpenRouter 経由で使う方が、NVIDIA Build 直結より安いかを確認したいときに便利です。Thunderbit の料金ページ で無料枠やプランの詳細を確認できます。
OpenClaw のトークン使用量を減らすための重要ポイント
基本の流れは 理解する → 監視する → ルーティングする → 最適化する です。
効果が大きい順に並べると、次のとおりです。
- デフォルトを Opus にしない。 主要モデルを Sonnet か MiniMax M2.7 に変えるだけで、コストが3〜5倍下がります。
- heartbeat を分離する。
isolatedSession: trueにして、heartbeat は Gemini Flash-Lite に回す。これで約10万トークンの消費が約2〜5千トークンになります。 - サブエージェントは Haiku に回す。 生成のたびに約2万トークン分のコンテキストが載るので、それを Opus でやらない。
/clearを習慣化する。 無料で5秒。コミュニティでも、単独で最も効果が大きい対策だと一致しています。.clawignoreを追加する。node_modules、lockfile、build artifacts を除外するだけで、bootstrap のコンテキストを大きく削れます。- 変更前後で
/context detailを見る。 測れないものは改善できません。
最安モデルはタスク次第です。heartbeat なら Gemini Flash-Lite。日常のコーディングなら MiniMax M2.7。信頼性の高い tool-calling なら Haiku。複雑な多段処理なら Sonnet。本当に難しい問題だけ Opus。それ以外には使いません。
多くの読者は、Config A か B を使えば、たった半日で50〜70%の節約を実感できます。85〜90%の完全削減には、モデルルーティング、見えない消費源の対策、.clawignore、セッション運用の徹底をすべて積み重ねる必要がありますが、十分に実現可能で、効果も長続きします。
FAQ
1. OpenClaw の月額コストはいくらですか?
設定、利用量、モデル選択で大きく変わります。ライトユーザー(1日約10件)は、最適化すれば月5〜30ドル程度、デフォルトのままだと100ドル超になることが多いです。中程度のユーザー(1日約50件)は月90〜400ドル程度。ヘビーユーザーはデフォルトだと 月600〜2,000ドル超 に達することもあり、記録上の極端な例では1か月で5,623ドルというケースもありました。Anthropic の内部テレメトリによると、中央値は 1人の開発者あたり稼働日1日13ドル だとされています。
2. コーディングで十分使える、OpenClaw の最安モデルは何ですか?
MiniMax M2.5/M2.7 が、総合的には最も使いやすい日常用モデルです。tool-calling の安定性も高く、SWE-Pro 56.22、価格はおよそ $0.28 / $1.10(100万トークンあたり)です。heartbeat や簡単な参照なら、$0.10 / $0.40 の Gemini 2.5 Flash-Lite もかなり有力です。Claude Haiku 4.5 は、Sonnet の価格を払わずに高い tool-calling 性能が欲しいときの、信頼できる中位フォールバックです。
3. OpenClaw で無料枠のモデルは使えますか?
技術的には使えます。GPT-OSS-120B は OpenRouter の :free タグや NVIDIA Build で無料です。Gemini Flash-Lite にも無料枠があります(15 RPM、1日1,000リクエスト)。DeepSeek も登録時に 500万無料トークン を提供しています。ただし無料枠はレート制限が厳しく、速度も遅めで、提供状況も安定しません。日常利用なら、100万トークンあたり数円レベルの有料低価格モデルの方が、はるかに信頼できます。
4. /model で会話途中にモデルを切り替えると、コンテキストは消えますか?
いいえ。/model はセッションの文脈をすべて保持したまま、次のターンのモデルだけを切り替えます。履歴はそのまま残ります。これは OpenClaw の概念ドキュメントでも確認されており、Claude Code でも同じ挙動です。短い質問には Haiku、複雑な作業には Sonnet、というふうに自由に行き来しても問題ありません。
5. 今日すぐに OpenClaw の請求額を下げる最速の方法は?
関係ない作業の間で /clear を使うことです。無料で、5秒ででき、API 呼び出しのたびに再送される会話履歴を消せます。ある実際のセッションでは、18万5,000トークン もの履歴が蓄積されており、それが毎ターン再送・再課金されていました。新しい作業を始める前にこれを消すのが、最も費用対効果の高い習慣です。
Thunderbit で AI Web Scraping を試す Get Started Free




