

「ダッシュボードが重い」という声が最初に飛んでくるのは、たいていリスト周りを触っている人のところです。Apollo のリストクエリをチューニングする作業は、単なる技術的な腕試しではありません。リアルタイムのニュースデータや自動収集、あるいはテンポの速い営業・オペレーション業務を回している人にとっては、もはや日々の生命線に近い話です。少し重いリストクエリがひとつ混じっただけで、見た目のいいダッシュボードが一気に詰まり、営業はぐるぐる回るローディングを眺めるだけになり、オペレーション担当はスプレッドシートで応急処置に追われる——そんな光景を何度も見てきました。しかも営業担当者の時間の 60% は、すでに売上につながらない作業に消えているとも言われます。1 ミリ秒だって無駄にはできません。
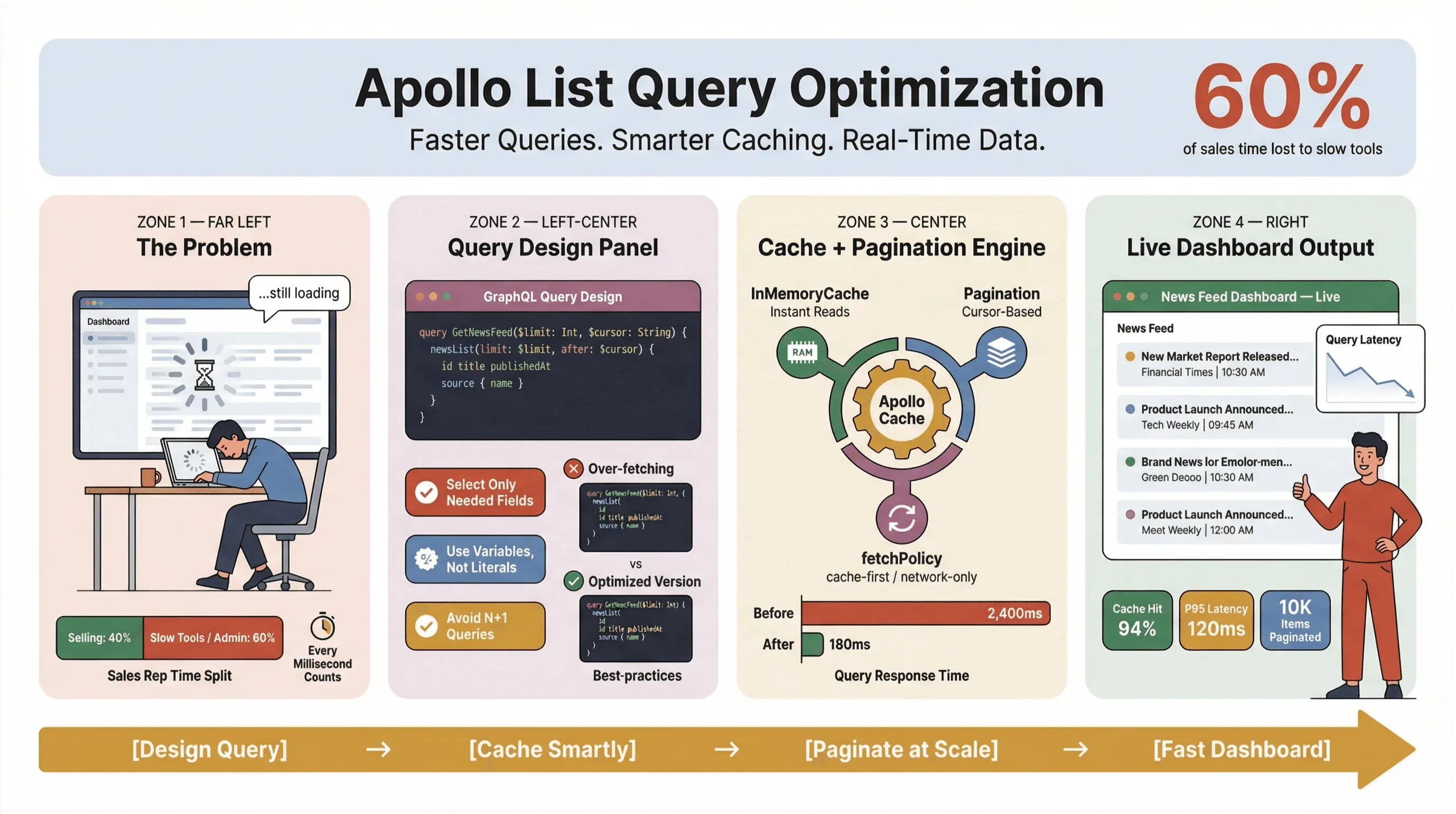
ニュースをスクレイピングするにせよ、リードを追いかけるにせよ、業務の根幹を支えるダッシュボードを回すにせよ、Apollo Client のリストクエリをどうすればもっと速く、安定して、一貫性のある形で動かせるのか。この記事では、実務でそのまま使える視点から、クエリ設計・キャッシュ・ページネーション、そして Thunderbit のようなノーコードツールを組み合わせて、ニュース収集の面倒な部分を自動化する方法までまとめて紹介します。
--- 開発者でも、プロダクトマネージャーでも、「とにかく画面が遅い」という苦情を真っ先に受け取る立場でも、ここで扱う内容は Apollo GraphQL のリスト性能を底上げするための実践ガイドです。
なぜ Apollo のリストクエリを最適化すべきなのか (apollo client list performance, optimize apollo list queries)
正直なところ、ニュースの見出しや営業リードが表示されるのを延々と待ちたい人なんていません。ビジネスの現場、とくにニュースの自動収集やリアルタイムデータに依存する環境では、遅い Apollo リストクエリの被害はユーザーのイライラだけにとどまりません。コストを膨らませ、意思決定を遅らせ、最後は結局また手作業へ逆戻りさせます。Slack Workforce Lab の継続的な調査でも、ナレッジワーカーが労働時間のおよそ 3 分の 1、直近のレポートでは**ほぼ 40%**を、価値の低い繰り返し作業に費やしている実態が一貫して示されています。遅い画面と分断されたツール環境が、その大きな原因です。
リストクエリが最適化されていないと、こんなことが起こります。
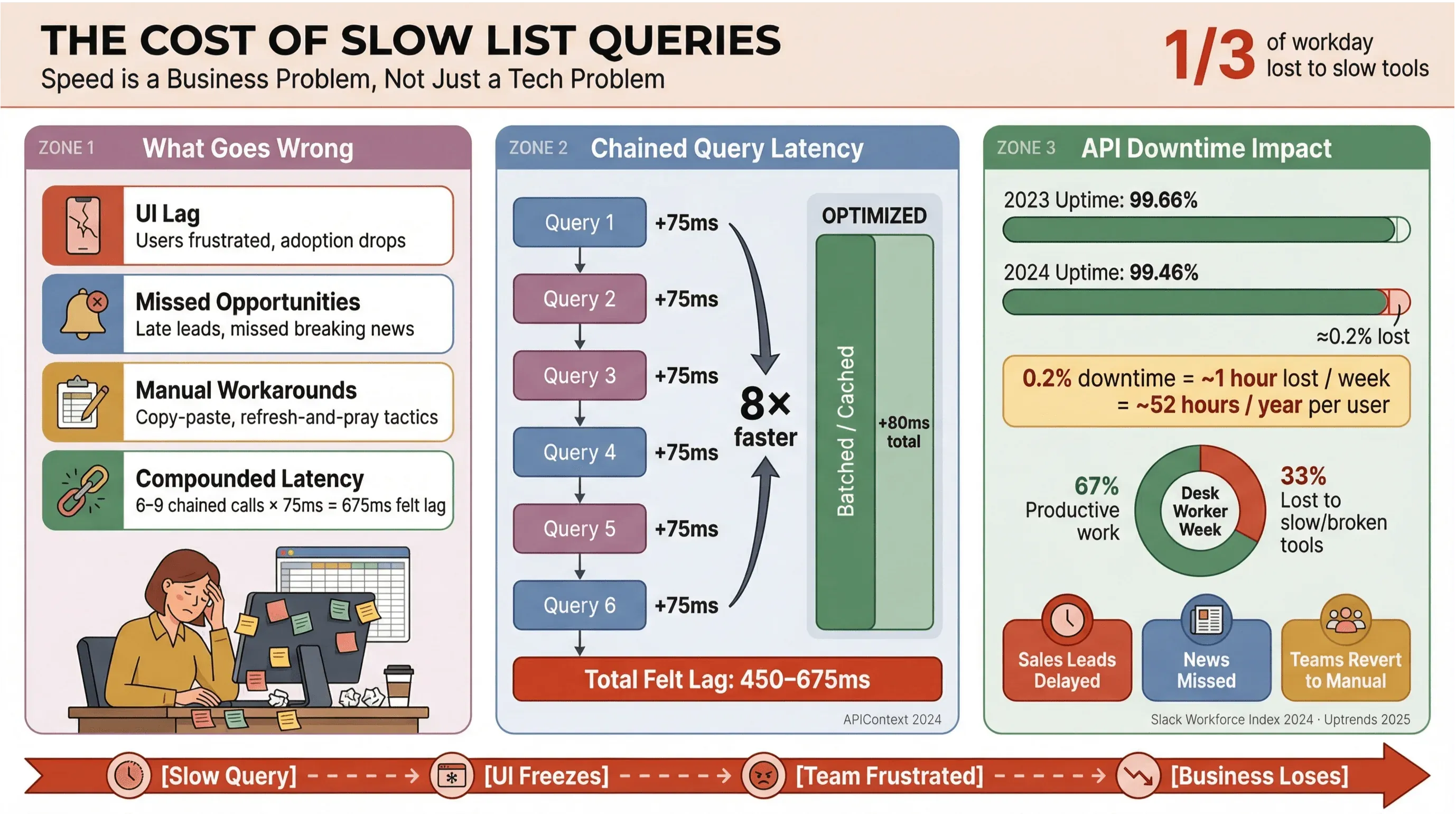
- UI がもたつく: 画面の表示が遅れ、不満や離脱につながります。
- 機会損失: 営業やニュース監視では、数秒の遅延がそのまま有望リードの取りこぼしや速報の見逃しに直結します。
- 手作業への逆戻り: チームはコピペ、スプレッドシート、あるいは「とりあえず再読み込みして祈る」運用へと戻ってしまいます。
- 遅延の積み重なり: 遅い API 呼び出しがひとつ増えるたびに、ワークフロー全体が重くなります。仮に依存関係のあるクエリが 6〜9 本も連鎖していれば、1 本あたり75msの遅れが、体感では450〜675msのもたつきに膨れ上がります(APIContext)。
問題は速度だけではありません。API のダウンタイムは増加傾向にあり、平均稼働率はわずか 1 年で 99.66% から 99.46% へ下落しました。リスト中心のアプリでは、これが週あたり 1 時間近い生産性の損失につながりかねません。リアルタイムのニュースデータが事業の生命線なら、このリスクは決して軽く見られません。
適切なデータ構造とフィールドを選ぶ (apollo graphql list best practices)
ありがちな失敗のひとつが、すべてのリストクエリを詳細表示用のクエリのように扱ってしまうことです。GraphQL は必要なデータだけを正確に取得できるのが強みなのですから、その利点を活かさない手はありません。取りすぎ、いわゆるオーバーフェッチは性能の天敵です。ニュースのスクレイピングツールやリアルタイムのダッシュボードでは、なおさら致命的になります。
ニュースの自動収集に合わせてフィールドを絞る
たとえばニュースフィードを作るとしましょう。一覧画面で本文まるごと、すべてのタグ、コメント、執筆者プロフィールまで、本当に必要でしょうか。おそらく不要です。違いはこう出ます。
効率的なリストクエリ:
query NewsFeed($after: String, $first: Int) {
newsFeed(after: $after, first: $first) {
edges {
cursor
node {
id
title
url
sourceName
publishedAt
}
}
pageInfo { endCursor hasNextPage }
}
}
非効率なリストクエリ(これは避けましょう):
query NewsFeedTooHeavy($after: String, $first: Int) {
newsFeed(after: $after, first: $first) {
edges {
node {
id title url publishedAt
fullText
summary
entities { ... }
relatedArticles { ... }
}
}
}
}
前者は軽くて無駄がなく、並べ替え・絞り込み・行のレンダリングにきれいに収まります。後者は見た目こそ一覧ですが、中身は実質的に詳細クエリです。大きなペイロードを引きずってきて、全体を遅くします(GraphQL specification, Apollo best practices)。
ひとつコツを挙げるなら: 2 段構えで考えてください。一覧では軽いフィールドだけを取り、本文や NLP による拡張情報といった重いデータは、ユーザーが項目を開いたりホバーしたりしたタイミングで読み込む。そのほうがずっと賢いやり方です。
Apollo Client のキャッシュでクエリ速度を引き上げる (apollo client list performance)
Apollo Client のキャッシュは、リスト性能を左右する最大のレバーです。きちんと設定すれば、こんな恩恵があります。
- 同じクエリは即座に返せます。 ネットワーク往復は不要です。
- サーバー負荷と API コストを抑えられます。
- 戻る・進む・フィルタ切り替えの操作が一気になめらかになります。
ただしキャッシュは万能ではありません。それなりの設計と運用ルールが要ります。
効果的なキャッシュポリシーを設定する
Apollo にはいくつかの fetch policy が用意されています。
| ポリシー | 動作 | ニュース一覧での適切な使いどころ |
|---|---|---|
| cache-first | まずキャッシュを見て、なければネットワークから取得 | 一覧の再訪問、フィルタ切り替え、戻る/進む |
| network-only | 毎回ネットワークから取得 | 手動更新、常に「最新の見出し」を表示すべきとき |
| cache-and-network | まずキャッシュを表示し、その後ネットワークの結果で更新 | 初回画面をすばやく表示しつつ裏で更新したいとき(ニュースフィードに最適) |
| no-cache | 毎回取得するがキャッシュには保存しない | 1回限りの機密クエリ(一覧ではまれ) |
リアルタイムのニュースデータなら、私はよく cache-and-network を選びます。最初に結果をすぐ見せて、そのあとバックグラウンドで更新できるからです。ただし更新の最中に並び順が変わると UI がわずかにちらつくことがあるので、その点だけ気をつけてください(GitHub issue)。
キャッシュ設定のコツ:
- 正規化のために安定した ID(
idまたは_id)を使ってください(Apollo cache docs)。 - 大きなリストに合わせてキャッシュサイズとガベージコレクションを調整してください(memory management)。
ROOT_QUERYの下に巨大な非正規化データをため込まないでください。アプリが固まる原因になります(community report)。
ページネーションを実装し、取得件数を絞る (apollo graphql list best practices)
ニュース記事や営業リードを一度に数百、数千件も読み込むのは危険です。ページネーションは単なる UX 上の飾りではなく、性能を保つための必須条件です。
Apollo は offset ベースと cursor ベース、どちらのページネーションにも対応しています。違いは次のとおりです。
| ページネーション方式 | メリット | デメリット | 適した用途 |
|---|---|---|---|
| Offset-based | シンプルで実装が簡単 | データが動くと抜けや重複が生じやすい | 変化の少ない小規模な一覧 |
| Cursor-based | 安定していてデータの変動に強い | 実装がやや複雑 | ニュースフィード、大規模な一覧 |
リアルタイムのニュース一覧やリード一覧なら、たいていは cursor ベースのページネーションがいちばん合います。新しい項目が増えても古い項目が消えても、データの一貫性を保ちやすいからです(GraphQL Foundation)。
Apollo ページネーション設定のコツ:
- ページネーション対象フィールドのキャッシュキーを制御したいなら
keyArgsを設定してください(docs)。 - ページをキャッシュ上でつなぎ合わせる
merge関数を実装してください。 - 既存の結果を上書きせず追加で読み込むには
fetchMoreを使ってください。
ニューススクレイピングツールでの実践ページネーション
典型的なニュース収集 UI は、こんな流れで動きます。
- 最新の見出しを 20〜50 件だけ表示
- スクロールや「次へ」ボタンで追加読み込み
- 必要なときだけ詳細を取得
こうしておけば UI は軽快、API は安定、ユーザーは作業に集中できます。
Thunderbit でニュースの自動収集をつなぐ
ここで核心の問いに移りましょう。そもそも、こうした構造化されたニュースデータはどこからやってくるのか、という話です。その答えが Thunderbit です。
Thunderbit Chrome拡張機能を入手 Get Started Free
Thunderbit は、ノーコードで使える AI ウェブスクレイパーの Chrome 拡張機能です。ほぼどんなサイトからでも、ニュースの見出し、URL、配信元、執筆者、公開日、要約、画像を抽出できます。コーディングは要りません。実際、多くのチームが Thunderbit でニュース収集の全工程を自動化し、雑然としたウェブページを、データベースや GraphQL API にそのまま流し込める整った構造化データへ変えています。
Thunderbit と Apollo を組み合わせてリアルタイムなニュースデータを作る
営業チームやオペレーションチームが最新ニュースを必要としているなら、私は次のワークフローをおすすめします。
- 抽出レイヤー: Thunderbit の News Scraper テンプレートで、対象サイトから定期的にニュースデータを取得します。
- 保存レイヤー: 抽出したデータを、高速に検索できるデータベースに保存します。
- GraphQL レイヤー: API を通じて、一覧用の
newsFeedフィールドと詳細用のnewsArticle(id)フィールドを提供します。 - クライアントレイヤー: Apollo Client で一覧を取得し(軽いフィールドとページネーション付き)、詳細は必要なときだけ取りに行きます。
この「スクレイピング → 保存 → クエリ」の流れを作れば、Apollo クエリは常に新鮮で構造化されたデータを扱えます。手でコピペする必要も、すぐ壊れるスクリプトも要りません。
ボーナス: Thunderbit は AI によるフィールド提案を通じて、感情分析やカテゴリといった追加フィールドもニュースフィードに付与できます。フィードをもう一段賢くできるわけです。
ステップ別ガイド: Apollo リストクエリを最適化する
実践に移す準備はできましたか。私がいつも使っている、Apollo リストクエリ最適化のチェックリストはこちらです。
-
クエリをスリムにする
- 一覧の描画に必要なフィールドだけを取る(title、URL、timestamp など)。
- 本文、画像、拡張情報といった重い項目は詳細クエリに回す。
-
ページネーションを実装する
- 大きい一覧や変動の多い一覧には cursor ベースを使う。
- キャッシュの整合性のために
keyArgsとmergeを設定する。
-
Apollo キャッシュを活用する
- 安定した ID でエンティティを正規化する。
- 状況に合った fetch policy を選ぶ。ニュースなら
cache-and-networkが便利。 - データ量に合わせてキャッシュサイズとガベージコレクションを調整する。
-
自動抽出をつなぐ
- Thunderbit でニュースのスクレイピングを自動化し、データを常に最新に保つ。
- 構造化データをそのままデータベースやスプレッドシートへ書き出す。
-
監視して原因を追う
- Apollo Client Devtools でクエリ、キャッシュ、性能を確認する。
- 大きなキャッシュ書き込み、過剰な watch query、UI の引っかかりに目を光らせる。
- p95/p99 のレイテンシとエラー率を追う(New Relic, Uptrends)。
クエリ性能の監視とトラブルシューティング
Apollo Devtools はここで大きな助けになります。次のことが見えてきます。
- 実行中のクエリとキャッシュの状態
- 重複クエリや過剰なウォッチャー
- 大きなキャッシュの塊や正規化の問題
UI がもたついたり更新が遅かったりするときは、まず以下を疑ってください。
- リストクエリが大きすぎる: フィールドを減らす
- キャッシュの正規化が足りない: ID を見直す
- ページネーションの merge に問題がある:
keyArgsとmergeを確認する
そして平均値だけを見ないこと。テールレイテンシも必ずチェックしてください。ユーザーが本当に体感する問題は、そちらに潜んでいることが多いものです。
従来手法と AI 主導のニューススクレイピングを比べる
正直に言えば、昔のニュースデータ収集は、独自スクリプトを書き、ヘッドレスブラウザと格闘し、サイトのレイアウトが一晩で変わらないことを祈る作業でした。いまは Thunderbit のような AI ベースのツールのおかげで、コーディングなしにその全工程をまるごと自動化できます。
| 方式 | メリット | ビジネスユーザー視点での限界 |
|---|---|---|
| スクリプトベースのスクレイピング | 自由度が高く大規模でもコストが低い | 保守が難しくエンジニアのリソースが必要 |
| マネージド型スクレイピング基盤 | 導入が速くボット対応を任せやすい | それでも設定が必要で利用量に応じてコストが増える |
| AI主導の抽出(Thunderbit) | レイアウトが変わったページにも強くノーコードで使える | 出力の検証と自社スキーマへの統合が必要 |
| ノーコードのビジュアルスクレイパー | 非開発者でも扱いやすい | UI変更に弱く大規模処理には限界がある |
| プロキシ/ブロック解除ベース | ブロック回避と高スループットに強い | それでも抽出ロジックが必要で、コンプライアンスのリスクがある |
法的メモ: 公開データのスクレイピングは一般的に合法ですが、利用規約とアクセス頻度の制限は必ず守ってください(Reuters)。
Apollo GraphQL リスト最適化で押さえておきたいこと
要点だけ整理すると、こうなります。
- 速度と読みやすさを最優先に: リストクエリを絞り、ページネーションを入れ、キャッシュを積極的に使う。
- 構造が肝心: 必要なものだけを取り、重いフィールドは詳細クエリに送る。
- キャッシュは味方: Apollo の正規化と fetch policy を活かして、データを即座に見せられるようにする。
- 抽出は自動化する: Thunderbit のようなツールで、ニュースのスクレイピングと一覧の拡張を誰でも扱えるものにする。
- 監視しながら磨く: Devtools とオブザーバビリティのダッシュボードでボトルネックを早く見つける。
営業、オペレーション、ニュースのチームにとって、こうしたベストプラクティスは「待つ時間」を減らし「動く時間」を増やしてくれます。おまけに「なんでこんなに遅いの?」という Slack メッセージもかなり減ります。
おわりに: Apollo リストクエリ最適化の次の一手
いまもなお、重くて、ページネーションもなく、キャッシュにやさしくないリストクエリを使っているなら、手を入れるべきはまさに今です。大きく始める必要はありません。まずフィールドを絞り、ページネーションを足し、キャッシュを調整する。そのうえで Thunderbit のような自動抽出ツールをつなぎ、データを常に最新かつすぐ使える状態に保ちましょう。
もっと深く知りたいなら、Apollo ドキュメント、Thunderbit Blog、あるいは Apollo Community をのぞいてみてください。実践的なコツとトラブル解決のヒントが見つかります。そしてニュース収集の自動化を本気でやってみたいなら、Thunderbit の News Scraper テンプレートを試してみてください。リアルタイムのデータを手軽に扱いたい人にとっては、状況を一変させる一手になります。
ThunderbitのNews Scraperテンプレートを使う
この記事を読んで何もしないつもりなら、せめてこの三つだけはやってください。リストクエリのフィールドを絞ること、cursor ベースのページネーションを入れること、そして適切な fetch policy を選ぶこと。この三つだけでも、リストクエリは「イライラするほど遅い」状態から「ほとんど気にならない」状態へ変わることが多く、ローディング表示ではなくデータそのものに集中できるようになります。
FAQ
1. なぜ Apollo のリストクエリは、リアルタイムニュースや営業ダッシュボードで遅くなるのですか?
取得するデータが多すぎたり、ページネーションがなかったり、キャッシュがきちんと設定されていなかったりすると遅くなります。ニュース監視のように頻度の高いワークフローでは、小さな遅延が積み重なり、UI のもたつきと生産性の低下につながります。
2. ニュースの自動収集向けに Apollo リストクエリを組む、いちばん良い方法は?
一覧に本当に必要なフィールドだけを取ってください(たとえば title、URL、timestamp)。本文まるごとや画像のような重い項目は詳細クエリに回し、結果はページネーションで分けて軽く保ちます。
3. Apollo Client のキャッシュは、どうやってリスト性能を高めるのですか?
Apollo キャッシュは過去に取得したデータを保持しておくため、同じクエリには即座に応えられます。適切な正規化と fetch policy(たとえば cache-and-network)を使えば、一覧表示を大幅に速くしつつサーバー負荷も下げられます。
4. Thunderbit は、ニューススクレイピングと Apollo 連携にどう役立ちますか?
Thunderbit は、どんなウェブサイトからでも構造化されたニュースデータを抽出できる、ノーコードの AI ウェブスクレイパーです。ニュース収集を自動化し、そのデータをデータベースや GraphQL API へ流し込んでから、Apollo Client でそのまま使えます。
5. Apollo リストクエリの性能を監視・調査するには、どんなツールを使えばいいですか?
Apollo Client Devtools を使えば、クエリ、キャッシュ状態、性能をリアルタイムで確認できます。New Relic や Uptrends のようなオブザーバビリティのダッシュボードと併用すれば、レイテンシとエラー率を追いながら、より良いクエリ設計へ継続的に改善できます。
ウェブスクレイピング、自動化、リアルタイムデータのワークフローに関するコツをもっと知りたいなら、Thunderbit Blog で踏み込んだ記事やチュートリアル、AI 活用の最新ノウハウを確認してみてください。
Thunderbit AI Web Scraperを使ってみる Get Started Free
もっと知りたい方へ




