

モダンなウェブサイト、たとえば不動産ポータルやECサイト、あるいはいつも見ているSNSのフィードからデータを取得しようとして、壁にぶつかったことはありませんか? ページを開いてHTMLを確認してみても……何もない。欲しい肝心な情報(価格、掲載情報、レビューなど)が見当たらないのです。これは、今のウェブがもはやHTMLだけで動いているわけではなく、JavaScriptで構築されているからです。2026年時点では、**全ウェブサイトの約98.9%**がクライアントサイド言語としてJavaScriptを使っており、総数は約5,100万サイトにのぼります(Radixweb)。従来のクローラーは、映画の台本だけ読んで作品を理解しようとするようなもの。実際に起きている動きを見逃してしまいます。
私はSaaSと自動化の分野で長年働いてきましたが、この変化によって、ビジネスユーザー、営業チーム、研究者が途方に暮れている様子を何度も見てきました。でも、朗報があります。JavaScriptクロールをマスターするのは、もう開発者だけのものではありません。適切な方法と、Thunderbit のようなAIツールの少しの助けがあれば、最も動的でインタラクティブなサイトからでも誰でもデータを抽出できます。ここでは、JavaScriptクロールとは何か、なぜ重要なのか、そしてコード不要でどう始めるかを整理していきます。
JavaScriptクロールとは? モダンなウェブデータ抽出でなぜ重要なのか?
まずは基本から。JavaScriptクロールとは、ウェブページを読み込み、すべてのJavaScriptを実行したうえで、スクリプト実行後に表示されるコンテンツを抽出できるツールやボットを使うことを指します。これは、サーバーから送られてくる生のソースコードだけを取得する従来型のHTMLスクレイピングからすると、大きな進化です。今のウェブでは、その生のHTMLは単なる骨組みにすぎず、本当のコンテンツ(商品一覧、レビュー、価格など)はJavaScriptによって埋め込まれます。しかも、スクロールやクリック、操作の後になって初めて表示されることも少なくありません。
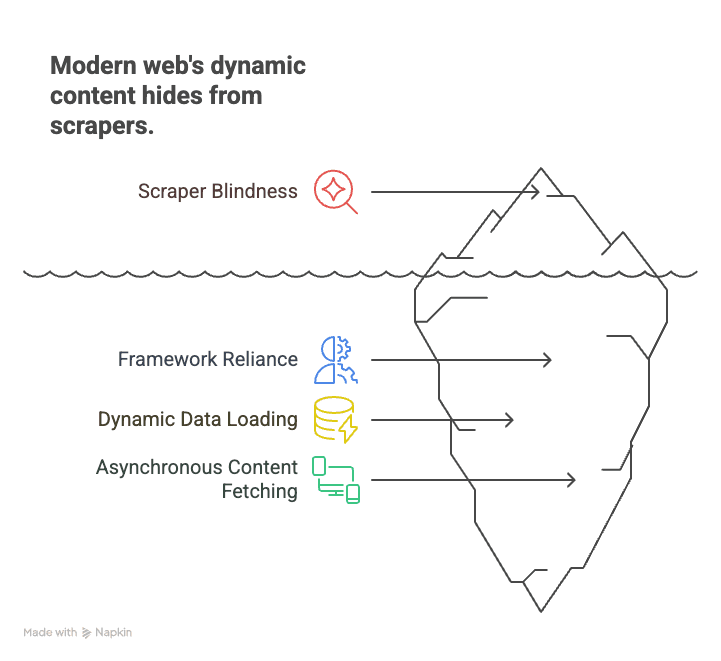
なぜ重要なのでしょうか? それは、現代のウェブがReact、Angular、Vueのようなフレームワークの上に成り立っているからです。これらのシングルページアプリケーション(SPA)はデータを随時読み込むため、静的なスクレイパーにはほとんどのコンテンツが見えません。たとえば:
- ECサイト:商品価格や在庫数は、スクロールやフィルター選択の後に読み込まれる。
- 不動産:物件一覧はスクロールに応じて表示され、詳細は動的に読み込まれる。
- SNS:投稿、コメント、いいねは非同期で取得され、初期HTMLには表示されない。
従来のクローラーはページを取得すると空の殻しか見つけられず、重要な情報を取りこぼします。一方、JavaScriptクロールはChromeでページを開き、すべてのスクリプトを実行させてから、人間が見るのと同じように表示内容を取得するイメージです。
要するに:2026年にほぼあらゆるモダンなウェブサイトからデータを取得したいなら、JavaScriptクロールをマスターする必要があります。そうでないと、実際の動きの大半を逃してしまいます。Reactだけでも現在は全ウェブサイトの6.2%を支えており、その上にVue、Angular、Next.jsが積み重なっています(W3Techs)。
6.2%の出典について:2026-05-13にw3techs.com/technologies/details/js-reactを取得したところ、ページには「This is 6.2% of all websites.」とありました。元の引用ハッシュは「7.4%」に固定されていましたが、ページ本文と一致しなくなっていたため、その断片は削除しました。
JavaScriptクロールの主な課題と、その乗り越え方
JavaScriptクロールは、単に「スクレイピングの手順が増えただけ」ではありません。独自のハードルがあります。ここでは、何が壁になるのか、そしてどう突破するのかを見ていきましょう。
動的コンテンツのレンダリング
課題:多くのコンテンツはHTMLの中に最初から入っていません。ページを開いたあと、JavaScript経由で読み込まれます。スクロールやクリック、ネットワーク呼び出しの後に表示されることもあります。HTMLをそのまま取得するだけでは、プレースホルダーか空のコンテナしか得られません。
解決策:ヘッドレスブラウザを使いましょう。これは実際のブラウザを模倣し、すべてのスクリプトを実行して、コンテンツが表示されるまで待ってくれるツールです。Puppeteer や Playwright は、この分野での業界標準です。これらを使うと、次のことができます。
- ページを開いてJavaScriptを実行させる。
- 「.product-list」のような特定要素が読み込まれるまで待つ。
- DOMから完全にレンダリングされた内容を抽出する。
この方法は、今や動的サイトをスクレイピングする際のゴールドスタンダードです(AIMultiple)。
アンチボットと自動化の障壁
課題:ウェブサイト側もボット対策を賢くしています。たとえば次のようなものがあります。
- CAPTCHA
- IP禁止やレート制限
- ブラウザフィンガープリント(本物のユーザーかの判定)
- ホネーポットトラップ(ボットを捕まえるための偽リンク)
解決策:責任あるクロールを行い、人間らしい振る舞いを再現しましょう。
- robots.txt と利用規約を尊重する。
- リクエストを抑制する。ランダムな遅延を入れ、サーバーに負荷をかけすぎない。
- 大規模に取得するなら IPをローテーション する(ただし倫理的に行う)。
- 実際のブラウザのヘッダーを使い、あからさまなボット署名は避ける。
- ログインの裏側をスクレイピングしない、許可なくCAPTCHAを回避しない。
Web Scrapingの法的影響 データを責任を持って取得し、Webスクレイピング関連法を順守する方法を学びましょう。 Get Started Free
たとえばThunderbitは、公開アクセス可能なデータのみを取得することを推奨し、コンプライアンスのベストプラクティスを標準で組み込んでいます(Thunderbit Blog)。
無限スクロールとユーザー操作イベント
課題:多くのサイトは無限スクロールを採用していたり、追加データの読み込みにクリックを必要としたりします。スクレイパーが最初に見えている部分しか取得しないなら、コンテンツの大半を見逃します。
解決策:ブラウザ自動化で次のことを行います。
- スクロールを再現する(ユーザーと同じように結果を追加読み込みする)。
- 「もっと見る」ボタンやタブをクリックする。
- 抽出前に新しいコンテンツが表示されるまで待つ。
ThunderbitのAIはこうしたパターンを検知し、スクロールやページネーションを自動で処理してくれるので、カスタムスクリプトを書く必要がありません(Thunderbit Docs)。
パフォーマンスとスケールの維持
課題:ページごとにヘッドレスブラウザを動かすのは、かなりリソースを使います。数百、数千ページのスクレイピングは、遅くてPCにも重い負荷がかかります。
解決策:並列クロールを使い、複数のブラウザやタブを同時に動かしましょう。あるいは、さらに良いのは、処理をクラウドにオフロードすることです。Thunderbitのクラウドスクレイピング加速機能(Lightning Network)は、一度に最大50ページまで取得でき、大規模ジョブの処理速度を大幅に高めます(Thunderbit Blog)。
Thunderbit:JavaScriptクロールをシンプルかつ強力にする
正直に言えば、ほとんどのビジネスユーザーはコードを書いたり、セレクタをデバッグしたり、スクリプトの面倒を見るのは望んでいません。だからこそ、私たちは Thunderbit を作りました。Thunderbitは、動的でJavaScriptの多いサイトからデータを取りたい非開発者向けの、AI搭載ウェブスクレイパーです。
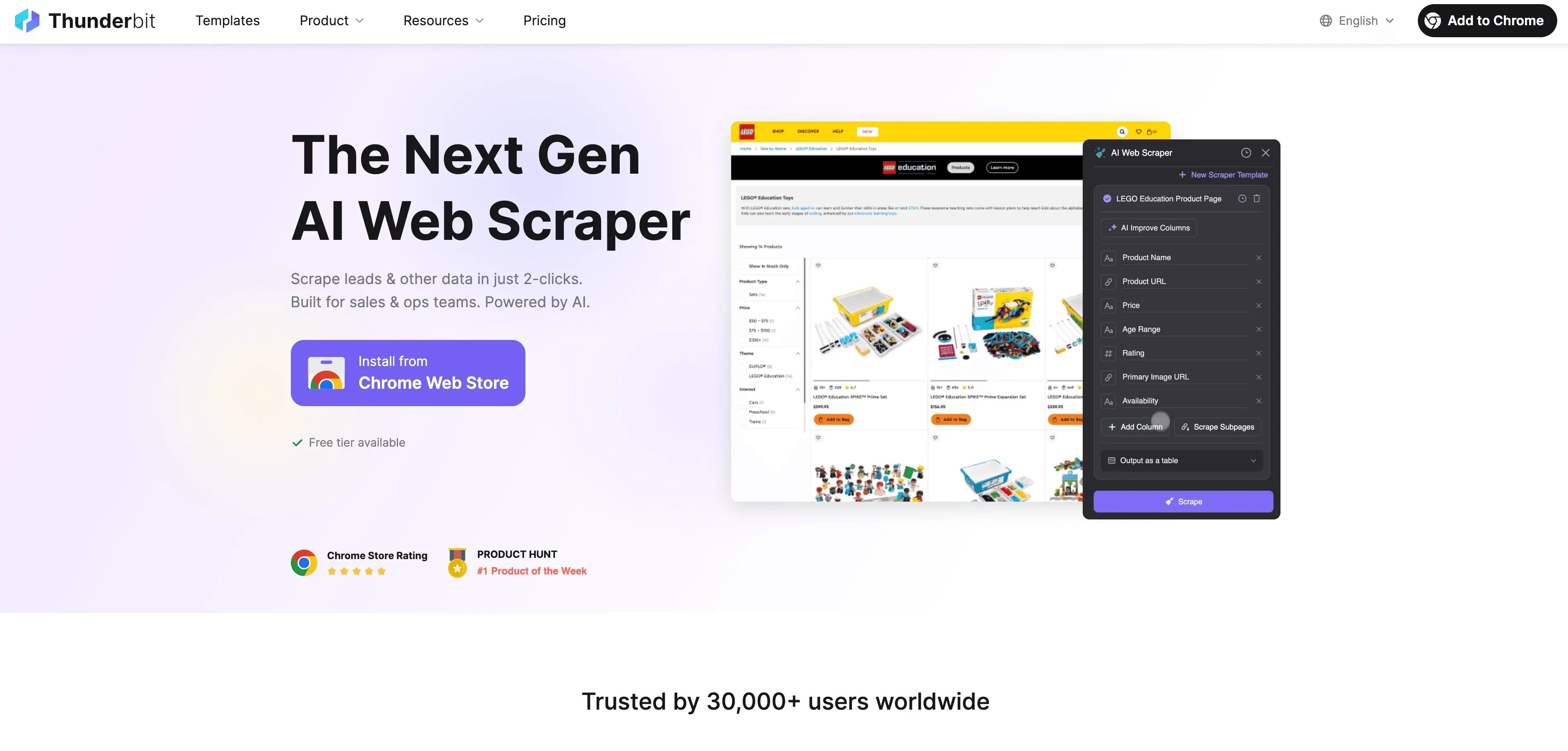
Thunderbitは、JavaScriptクロールの面倒を次のように解消します。
- AIによる項目提案: 「AI Suggest Fields」をクリックするだけで、ThunderbitのAIがページを解析し、抽出すべき最適な列を提案し、適切なデータ型を設定します。もう推測や試行錯誤は不要です。
- 自然言語での抽出: 「商品名、価格、評価を取得して」のように、欲しい内容を平易な英語で書くだけで、Thunderbitが取得方法を判断します。
- 動的コンテンツに対応: Thunderbitは実際のブラウザ(Chromeまたはクラウド)上で動作するため、すべてのJavaScriptを実行し、コンテンツが読み込まれるまで待ちます。まるで人間のようです。
- サブページとページネーションに対応: 複数ページをまたいだ取得や、商品詳細のようなサブページへの追跡も可能です。Thunderbitが自動で処理し、すべてのデータを1つの表にまとめます。
- クラウド加速: 大きなジョブでは、ThunderbitのLightning Networkがクラウド上で最大50ページを同時に取得するため、PCに負荷がかかりません。
- ノーコードで使いやすいUI: Excelが使えるなら、Thunderbitも使えます。ポイント&クリックで操作でき、技術的なセットアップは不要です。
- 無料エクスポート: データはExcel、Google Sheets、Airtable、Notion、JSONにエクスポートでき、追加料金はかかりません。
Thunderbitは、営業チームからEC運営担当、不動産のプロまで、世界中で10万人以上のユーザーに信頼されています(Thunderbit Official Website)。
AIによる項目提案と自然言語抽出
ここがThunderbitの真骨頂です。HTMLをあちこち探ったり、XPathセレクタを書いたりする代わりに、ボタンをクリックするだけで、ThunderbitのAIが重い作業を肩代わりしてくれます。ページを読み取り、構造を理解し、何を抽出すべきかを的確に提案します。欲しいものが具体的なら、平易な英語でそのまま入力するだけでOK。ThunderbitのAIがリクエストを適切な要素に対応づけます。
初心者にとっては、まさにゲームチェンジャーです。HTML、CSS、JavaScriptについて何も知らなくても大丈夫。欲しいものを伝えるだけで、残りはAIに任せられます(Futurepedia)。
ページネーションとサブページクロール
Thunderbitは1ページだけで終わるツールではありません。次のことができます。
- ページネーションを検知して処理する(「次へ」をクリックしたり、スクロールで続きを読み込んだりする)。
- サブページをスクレイピングする(商品詳細、著者プロフィール、レビューなど)そしてデータをメイン表に統合する。
- 無限スクロールを処理するためにユーザー操作を再現し、最初に見えているものだけでなく、すべてのデータを取得する。
たとえば、20ページあるECカテゴリの商品を取得する場合でも、Thunderbitが自動で各ページを順番に開き、結果をまとめます。各商品の詳細ページから情報が必要ですか? サブページスクレイピングを使えば、Thunderbitが各リンクを巡回し、追加情報を取得して、データセットを充実させます(Thunderbit Docs)。
Lightning Networkとクラウド加速:JavaScriptクロールを拡張する
数百、数千ページを取得する必要があるとき、1ページずつ処理するのは現実的ではありません。そこでThunderbitのLightning Networkが役立ちます。
- クラウドスクレイピング: 重い処理はThunderbitのクラウドサーバー(米国、EU、アジア)に任せましょう。クラウドなら一度に最大50ページを取得でき、大規模ジョブを大幅に高速化できます。
- 並列クロール: 各ページがブラウザで読み込まれるのを待つ代わりに、Thunderbitのクラウドが仕事を複数のワーカーに分散します。1,000件の商品ページの取得ですか? クラウドなら数時間ではなく数分で終えられます。
- スケジュールスクレイピング: 価格や掲載情報を毎日監視したいですか? 「毎朝9時」のように平易な言葉でスケジュールを設定すれば、Thunderbitが自動で実行し、データをGoogle Sheetやデータベースにエクスポートしてくれます(Thunderbit Blog)。
開発者を雇ったりサーバーを運用したりせずに、常に新しいデータを大量に必要とする営業、EC、オペレーションチームにとって、これは大きな助けになります。
複数ページと一括データ抽出
Thunderbitなら、次のような作業も簡単です。
- ディレクトリやカタログ全体を取得する(例:カテゴリ内の全商品、地域内の全掲載情報)。
- 結果をExcel、Google Sheets、Airtable、Notionにワンクリックでエクスポートする。
- 手作業を何時間、あるいは何日も節約する。あるユーザーは、担当者情報まで含む不動産掲載情報を数百件、10分以内で取得しました。
ステップごとのガイド:ThunderbitでJavaScriptクロールを始める方法
試してみる準備はできましたか? ここでは、これまで一度もウェブサイトをスクレイピングしたことがない人でも始められるThunderbitの使い方を紹介します。
最初のクロールをセットアップする
- Thunderbitをインストール: Thunderbit Chrome拡張機能 をダウンロードし、無料アカウントに登録します。
- 対象サイトを開く: スクレイピングしたいウェブサイトに移動します。ログインが必要なら先にログインしてください(Thunderbitはブラウザの文脈で動作します)。
- Thunderbitを開く: ChromeツールバーのThunderbitアイコンをクリックします。データソース(現在のページ、URLのリスト、ファイルアップロード)のいずれかを選びます。
- 実行モードを選ぶ: 小規模な作業やログインが必要なサイトでは Browser mode を使います。大規模ジョブでは Cloud mode に切り替えて並列スクレイピングを行います。
- AIによる項目提案: 「AI Suggest Fields」をクリックします。ThunderbitのAIがページをスキャンし、抽出する列(「商品名」「価格」「画像URL」など)を提案します。
- 列を調整: 必要に応じて項目名の変更、追加、削除を行います。データの整形や分類をしたい場合は、カスタムのAI指示も追加できます。
- ページネーション/スクロールを設定: サイトがページネーションや無限スクロールを使っているなら、Thunderbitの設定で該当オプションを有効にします。
- 「Scrape」をクリック: Thunderbitがページを読み込み、すべてのJavaScriptを実行し、データを表に抽出します。
データの抽出とエクスポート
- 結果をプレビュー: Thunderbitがデータを表形式で表示します。内容が十分か、正確かを部分的に確認しましょう。
- エクスポート: 「Export」をクリックしてExcel、CSV、JSONとしてダウンロードするか、Google Sheets、Airtable、Notionに直接送信します。
- 検証: いくつかの行をライブサイトと照合し、すべて一致しているか確認します。
- トラブルシューティング: データが不足している場合は、先にページをスクロールする、AI指示を調整する、あるいはCloud modeに切り替えて性能を上げてみましょう。
より詳しい手順は、Thunderbit Docs や Thunderbit YouTube Channel をご覧ください。
安全かつコンプライアンスを守ってJavaScriptクロールを行うためのベストプラクティス
強力なスクレイピングには、それに見合う責任が伴います。法令と倫理の両面で正しい位置にいるために、次の点を守りましょう。
- robots.txt と利用規約を尊重する: そのサイトがスクレイピングを許可しているか必ず確認しましょう。「ボット禁止」と書かれているなら、無理に進めないでください(Thunderbit Blog)。
- 個人データのスクレイピングを避ける: GDPRやCCPAでは、名前、メールアドレス、プロフィールは公開されていても保護対象とみなされます。正当な理由と同意がある場合にのみ個人情報を取得してください。
- ログイン突破やCAPTCHA回避はしない: 法的にグレー、あるいはそれ以上の問題になり得ます。公開データに絞りましょう。
- リクエストを抑制する: サーバーに負荷をかけないでください。ThunderbitのCloud modeはリクエスト間隔を空け、IPをローテーションしてBANを避けます。
- データを倫理的に使う: 著作権保護コンテンツを再公開したり、取得データを不適切に利用したりしないでください。
- 削除依頼には応じる: 誰かが自分のデータ削除を求めてきたら、対応しましょう。
Thunderbitは、コンプライアンスを促す設計になっています。公開データのみ、ハッキングなし、責任ある利用のための明確なエクスポート機能を備えています。
法的リスクを避けるために
- 公開されていて、個人情報ではないデータに限定する。
- 明示的に禁止しているサイトは取得しない。
- 迷う場合は、許可を取るか公式APIを使う。
- 何を、いつ取得したかのログを残す。
- 差止め要求が来たら、すぐに従う。
より深く知りたい方は、Web Scrapingは違法か?法的影響を理解する をご覧ください。
JavaScriptクロールソリューションの比較:Thunderbit vs. 従来ツール
| 項目 | Puppeteer/Playwright(コード) | Sitebulb(SEOクローラー) | Thunderbit(AIノーコード) |
|---|---|---|---|
| セットアップ時間 | 数時間(コーディングが必要) | 中程度(設定が必要) | 数分(ポイント&クリック) |
| 必要スキル | 高い(開発者向け) | 中程度 | 低い(誰でも使える) |
| JavaScriptコンテンツ対応 | あり(手動でスクリプト化) | あり(SEO用途) | あり(AIで自動) |
| ページネーション/サブページ | 手動でスクリプト化 | 限定的 | 自動(AIが検知) |
| 保守 | 高い(変更に弱い) | 中程度 | 低い(AIが適応) |
| 拡張性 | 手動(コードを書く) | 限定的 | クラウド標準搭載(50倍) |
| エクスポート方法 | 手動(コードを書く) | CSV/Excel | Excel、Sheets、Notion |
| 最適な用途 | 開発者、独自フロー | SEO監査 | ビジネスユーザー、分析担当者 |
Thunderbitは、技術的な悩みなく素早く結果を得たいビジネスユーザーにとって、明らかな勝者です(Thunderbit Blog)。
まとめと重要ポイント
AIでJavaScriptサイトをスクレイピング ThunderbitのAI搭載ウェブスクレイパーで、動的なウェブデータを解放しましょう。 Get Started Free
JavaScriptクロールは、もはやニッチなスキルではありません。2026年にウェブデータが必要な人にとって、必須の能力です。
--- 2026年には98.9%のウェブサイトがクライアントサイドスクリプトを動かしており、従来のスクレイピングだけではもはや不十分です(Radixweb)。
--- 朗報は、これをマスターするのに開発者である必要はないということです。
覚えておくべきこと:
- 動的コンテンツはどこにでもある: モダンなサイトからデータを取得するなら、JavaScriptを実行できるツールが必要です。
- 課題は現実的だが、解決できる: ヘッドレスブラウザ、賢い待機処理、クラウド加速によって、最も扱いにくいデータも抽出可能です。
- Thunderbitなら簡単: AIによる項目提案、自然言語抽出、サブページとページネーション対応、クラウド加速によって、強力なJavaScriptクロールを誰でも使える形で提供します。
- コンプライアンスを守る: いつでもサイトのルール、プライバシー法、倫理ガイドラインを尊重しましょう。
- 今日から始める: Thunderbitをインストールし、対象サイトを選び、数クリックでどれだけのデータを引き出せるか試してみてください。
さらに詳しく知りたい方は、より多くのガイドが載っている Thunderbit Blog や、ステップごとのデモが見られる YouTubeチュートリアル をご覧ください。
楽しいクロールを。そして、あなたのデータがいつも動的で、完全で、すぐに使えるものでありますように。
FAQ
1. JavaScriptクロールとは何ですか? 従来のスクレイピングとどう違うのですか?
JavaScriptクロールは、ウェブページを読み込み、すべてのJavaScriptを実行し、スクリプト実行後に現れるコンテンツを抽出するツールを使います。従来のスクレイピングは生のHTMLを取得するだけなので、モダンサイトの大半のコンテンツを取り逃します。
2. ビジネスデータ抽出にJavaScriptクロールが必要なのはなぜですか?
ほぼすべてのモダンなウェブサイトが、コンテンツを動的に読み込むためにJavaScriptを使っているからです。JavaScriptクロールがなければ、商品一覧、レビュー、価格、その他の重要データを見逃してしまいます。
3. Thunderbitは、初心者向けにJavaScriptクロールをどう簡単にするのですか?
ThunderbitはAIを使って項目を提案し、動的コンテンツを処理し、ページネーションやサブページ取得を自動化します。欲しい内容を平易な英語で説明するだけでよく、コーディングは不要です。
4. JavaScriptクロールは合法ですか? 何に注意すべきですか?
JavaScriptクロールは、公開データのみを対象にし、robots.txt と利用規約を尊重し、同意なしに個人情報を取得しないなど、責任を持って行えば合法です。Thunderbitはコンプライアンスと責任ある利用を推奨しています。
5. 大規模ジョブ向けにJavaScriptクロールをどう拡張できますか?
ThunderbitのLightning Network(クラウドスクレイピング)なら、一度に最大50ページを取得できるため、何千ページにもまたがる価格監視やリード獲得のような大きな作業にも対応しやすくなります。
さらに詳しく見る:
- JavaScriptを使ったWebスクレイピング:ステップバイステップガイド
- JavaScriptを使ったWebスクレイピングのステップバイステップガイド
- JavaScriptとNode.jsで行うWebスクレイピング完全ガイド
- JavaScriptサイトのクロール方法
AIウェブスクレイパーを試す Get Started Free




