

インターネットにはデータがあふれています。量が多すぎて、今では現代ビジネスを動かす血液のような存在と言っても大げさではありません。営業、Eコマース、不動産、あるいは競合の動向を追いたいときでも、必要なデータをすぐ使える形で手元に置けるかどうかで結果は大きく変わります。ただ、正直なところ、ウェブサイトの情報をひたすらコピペしてスプレッドシートに貼り付ける作業をしたい人なんていませんよね。そこで登場するのがウェブスクレイピングです。しかも、見た目ほど難しくありません。
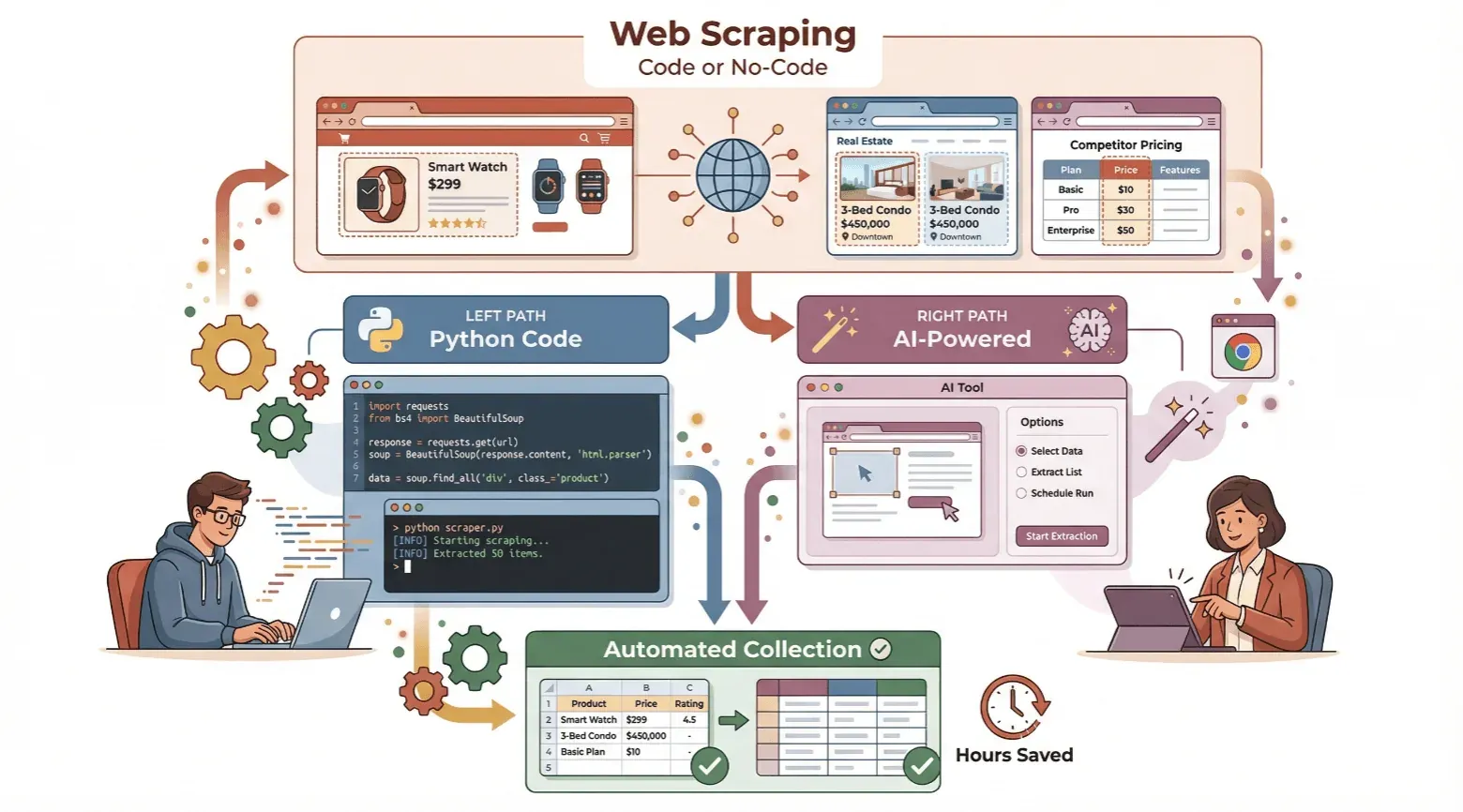
このガイドでは、ウェブスクレイパーの作り方を順を追って解説します。Pythonでのコーディングに挑戦したい初心者の方にも、コードを書かずにThunderbitのようなAI搭載のノーコードツールを使いたい方にも役立つ内容です。基本を整理し、2つの方法をステップごとに紹介しながら、あなたに合うやり方を見極めるお手伝いをします。時間を節約して、自動データ収集の力を最大限に活用する準備はできましたか? それでは始めましょう。
ウェブスクレイパーとは? 基本を理解しよう
ウェブスクレイパーとは、ウェブサイトから情報を自動で抽出するツール、つまりソフトウェアやサービスのことです。たとえば、街中のコーヒーショップを住所や電話番号付きで一覧にしたいとします。各ページをクリックして手作業で情報をコピーすることもできますが(Ctrl+C疲れ、わかります)、ウェブスクレイパーに面倒な作業を任せることもできます。
ウェブスクレイパーは、ウェブページを読み取り、価格、商品名、連絡先情報など必要なデータを見つけて、スプレッドシートやデータベースにきれいに整理してくれるデジタルアシスタントのようなものです。ブラウザのタブとExcelを行き来しながら手作業する代わりに、スクレイパーが取得、解析、保存を自動化してくれるので、短時間で処理できます。
仕組みは裏側でこう動いています。
- リクエスト:スクレイパーがウェブページにリクエストを送り、HTMLの生データをダウンロードします。
- 解析:HTMLを分析し、目的のデータを探します(たとえば、
<span>タグの中にある価格など)。 - 抽出:データを取り出し、CSV、Excel、Google Sheetsなどの構造化された形式で保存します。
手作業のコピペは、スプーンで穴を掘るようなものです。ウェブスクレイピングは、ショベルカーを持ち込むようなものです。
ウェブスクレイパーを作ることがビジネスに重要な理由
ウェブスクレイピングは、技術者やデータサイエンティストだけのものではありません。信頼できる最新情報を必要とする人にとって、今では必須の手段になっています。現在、大規模組織の97%近くがデータドリブンな意思決定に投資しており、ウェブスクレイピング市場に関するアナリストの見通しでも、今後数年にわたる継続的な成長が一貫して示されています。
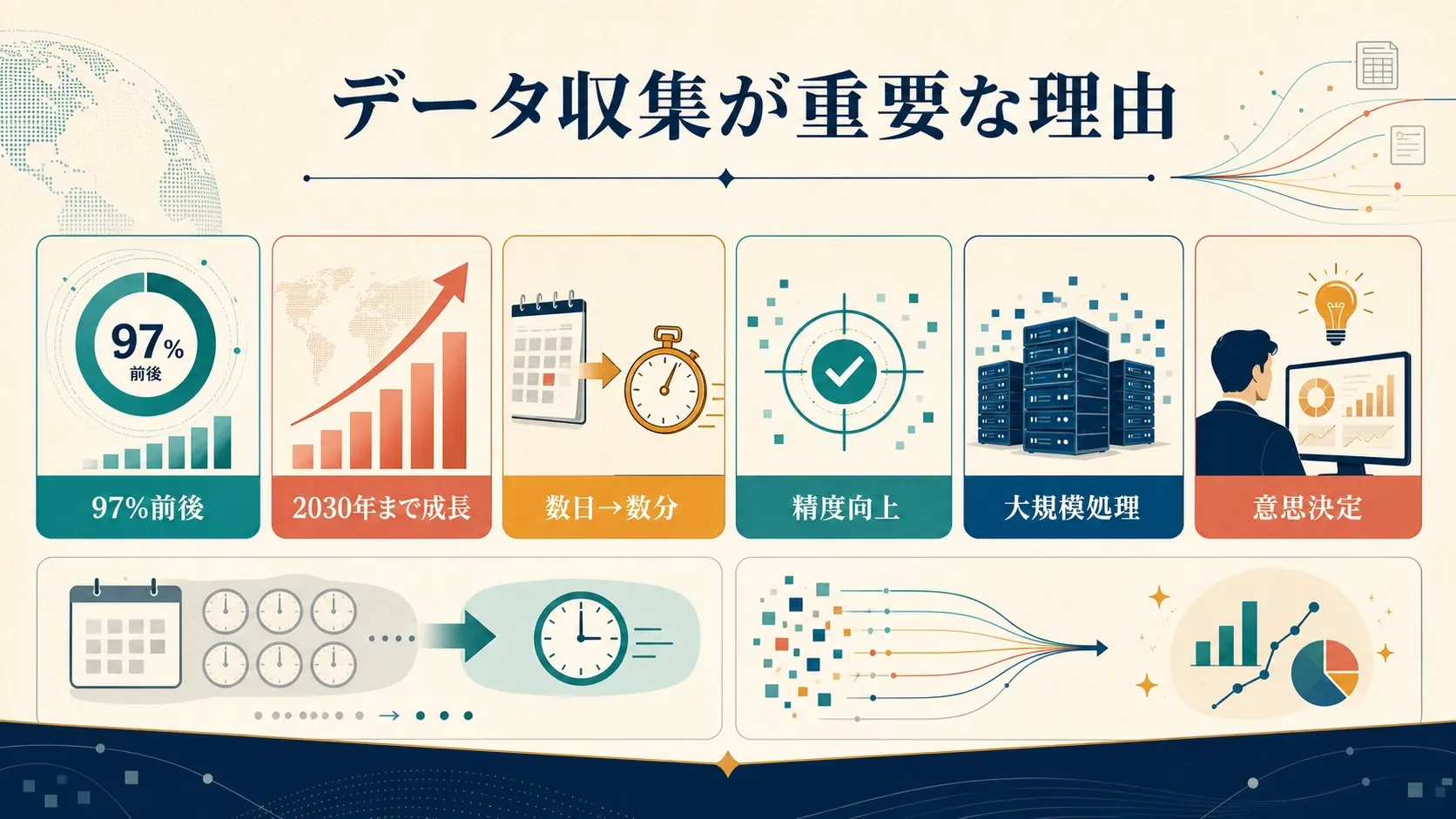
規模を問わず多くの企業がウェブスクレイピングを取り入れている理由は次のとおりです。
- 時間を節約できる:手作業で何日もかかる仕事が、数分で終わります。
- 精度が向上する:ソフトウェアは疲れませんし、タイプミスもしません。
- 大規模に対応できる:数件どころか、何千ページでもスクレイピングできます。
- より良い意思決定につながる:最新データがあれば、価格調整、リード獲得、トレンド把握などで、より賢い判断ができます。
実際の活用例を見てみましょう。
| ユースケース | 恩恵を受ける人 | 典型的な成果 |
|---|---|---|
| ディレクトリから営業リードを抽出する | 営業チーム | リード数が10倍に増え、見込み客開拓にかかる時間を削減 |
| ECサイト上の競合価格を監視する | Eコマース担当者 | リアルタイムで価格調整、利益率を保護 |
| 不動産掲載情報を集約する | 不動産会社 | 案件発見の迅速化、市場データの最新化 |
| Web/ソーシャルメディアからマーケティングデータを収集する | マーケティングチーム | より的確なキャンペーン、改善されたパフォーマンス追跡 |
| 日次のWebデータレポートを自動化する | オペレーション、アナリスト | 人件費削減、エラー減少、一貫性のあるタイムリーなレポート |
要するに、最も優れた、そして最も新しいデータを持つ人が勝つのです。
初心者向けガイド:Pythonでシンプルなウェブスクレイパーを作る方法
ウェブスクレイピングが「裏側でどう動いているのか」に興味があるなら、Pythonから始めるのがおすすめです。コーディング初心者でも、数ステップで基本的なスクレイパーを作れます。手順は次のとおりです。
環境を整える
まず、パソコンにPythonをインストールする必要があります。python.orgから最新バージョンをダウンロードし、使っているOS(WindowsまたはMac)向けの手順に従ってください。インストール時には「Add Python to PATH」に必ずチェックを入れましょう。
次に、ターミナルまたはコマンドプロンプトを開いて、必要なライブラリをインストールします。
pip install requests
pip install bs4
pip install pandas
requestsはウェブページの取得に使います。bs4(Beautiful Soup)はHTMLの解析を助けます。pandasはCSVやExcelへの保存に便利です。
ウェブサイトの構造を確認する
コードを書く前に、HTMLのどこにデータがあるのかを把握する必要があります。Chromeで対象サイトを開き、欲しいデータ(たとえば職種名)を右クリックして「検証」を選びます。すると、HTML要素がハイライト表示されます。たとえば、jobtitleのようなクラス名が付いた<a>タグかもしれません。こうしたタグやクラス名をメモしておきましょう。スクレイパーに何を探させるかを指定する際に使います。
スクレイパーを書いて実行する
求人一覧ページから職種名と会社名を抽出したいとします。以下のようなシンプルなスクリプトで始められます。
import requests
from bs4 import BeautifulSoup
import pandas as pd
URL = "https://example.com/jobs" # 対象URLに置き換えてください
response = requests.get(URL)
soup = BeautifulSoup(response.text, 'html.parser')
# すべての職種名と会社名を取得(必要に応じてセレクターを調整)
titles = [t.get_text().strip() for t in soup.find_all('a', class_='jobtitle')]
companies = [c.get_text().strip() for c in soup.find_all('div', class_='company')]
# CSVに保存
df = pd.DataFrame({'Job Title': titles, 'Company': companies})
df.to_csv('jobs.csv', index=False)
print("スクレイピングが完了しました! データは jobs.csv に保存されました")
- URLやクラス名は対象サイトに合わせて調整してください。
- ターミナルでスクリプトを実行します:
python yourscript.py jobs.csvを開いて結果を確認しましょう。
ワンポイント: より複雑なサイト(ページネーションや動的コンテンツがある場合)では、ループを追加したりSeleniumのようなツールを使ったりする必要があります。ただし、多くの静的ページではこの方法で十分に対応できます。
ノーコードで簡単に:Thunderbitでウェブスクレイパーを作る方法
では、まったくコードを書きたくない場合はどうでしょうか? そこで登場するのがThunderbitです。ビジネスユーザー向けに設計された、ノーコードのAI搭載ウェブスクレイパーです。構造がはっきりしたシンプルなページなら、Thunderbitを使えば「このデータが欲しい」と思ってから数クリックで、すぐ使えるスプレッドシートまで到達できます。ログインが必要なサイト、ボット対策が厳しいサイト、レイアウトが特殊なサイトでは多少の調整が必要なこともありますが、手作業でパーサーを書くよりはずっとハードルが低いです。
AIであらゆるウェブサイトからデータをスクレイピング Get Started Free
使い方は次のとおりです。
ステップ 1:ThunderbitのChrome拡張機能をインストールする
Thunderbit Chrome Extensionのダウンロードページにアクセスし、ブラウザに追加してください。無料アカウントに登録すれば、まずは数ページをスクレイピングして試せます。
ステップ 2:対象サイトを開く
Chromeでスクレイピングしたいページを開きます。必要ならログインし、動的コンテンツが読み込まれるまで下までスクロールしてください。
ステップ 3:欲しいデータを伝える
Thunderbitのアイコンをクリックしてサイドバーを開きます。方法は2つあります。
- **「AIで項目を提案」**をクリックすると、ThunderbitのAIがページを解析し、「商品名」「価格」「画像」などの列を提案します。
- あるいは、自然な日本語でプロンプトを入力します(例:「このページの本のタイトルと著者をすべて抽出して」)。
ThunderbitのAIが自動で項目とデータ型を提案します。必要に応じて、項目名の変更、追加、削除ができます。
ステップ 4:最初のスクレイピングを実行する
項目の設定ができたら、**「スクレイプ」を押すだけです。Thunderbitがデータを抽出し、必要に応じてページネーションも処理し、見やすい表に表示します。サブページ(個別の商品ページなど)からさらに詳細を取りたい場合は、「サブページをスクレイプ」**をクリックしてください。Thunderbitが各リンク先を巡回して追加情報を取得します。
ステップ 5:結果を確認してエクスポートする
Thunderbitの表でデータを確認します。問題なければ**「エクスポート」**をクリックし、Excel、CSV、Google Sheets、Airtable、Notion、JSONから形式を選びます。エクスポートは無料で無制限です。
これで完了です。コードも、テンプレートも、面倒ごともありません。
従来型とノーコードのウェブスクレイパーを比較する
2つの方法を比べてみましょう。
| ソリューション | セットアップ時間 | 必要なスキル | メンテナンス | 柔軟性 | エクスポート形式 |
|---|---|---|---|---|---|
| Python + Beautiful Soup | 数時間〜数日 | コーディング、HTMLの基礎 | 高い(壊れやすい) | 非常に高い | CSV、Excel、JSON(コード経由) |
| 従来型ノーコードツール | 30〜60分 | ある程度の技術知識 | 中程度(手動修正) | 静的サイト向き | CSV、Excel |
| Thunderbit(AIノーコード) | 数分 | 不要(自然な日本語) | 低い(AIが適応) | 高い(動的サイト) | Excel、CSV、Sheets、Notion... |
ThunderbitのAI主導のアプローチなら、スクレイパーの設定や修正にかける時間を減らし、実際にデータを使うことにもっと時間を使えます。
従来型ウェブスクレイパーの課題を乗り越える
従来型のスクレイパーには、いくつか有名な弱点があります。
- サイトの変更:サイトのレイアウトが変わると、コードが壊れることがあります。ThunderbitのAIは多くの変更に自動で対応するため、書き直しは不要です。
- ボット対策:多くのサイトは自動スクリプトをブロックします。Thunderbitは、ブラウザ上で(ログインやセッションを使って)実行することも、速度重視でクラウドで実行することもできます。
- 動的コンテンツ:無限スクロールや「もっと見る」ボタンがあるページは、基本的なスクレイパーでは対応しづらいことがあります。ThunderbitのAIは自動スクロールやインタラクティブ要素に標準対応しています。
- ログインが必要なデータ:Thunderbitのブラウザモードなら、Chromeで見えるものはそのままスクレイピングできます。
要するに、Thunderbitは現代のウェブサイトが持つ厄介な現実に対応できるよう設計されています。あなたが面倒を見る必要はありません。
効率を高める:Thunderbitの高度なウェブスクレイピング機能
Thunderbitは、単にデータを取るだけではありません。速く、きれいに、すぐ使える形で取得することに強みがあります。特に気に入っている機能をいくつか紹介します。
自動ページネーションとサブページスクレイピング
複数ページにわたる数百件の商品をスクレイピングしたいですか? Thunderbitはページネーション(次へボタン、無限スクロール)を検出し、まとめて取得します。サブページからさらに詳細を取りたい場合は、「サブページをスクレイプ」をクリックすると、各リンク先から出品者情報や製品仕様などの追加項目を取得します。
AIによる項目提案とデータ構造化
ThunderbitのAIは、単に列を推測するだけではありません。文脈を理解します。列名の付与、データ型の割り当て(テキスト、数値、画像、メールなど)、さらには独自の指示(「100ドル以上の価格だけ」「説明文を英語に翻訳」など)にも対応できます。スクレイピングしながら、分類、要約、整形のためのプロンプトを追加することも可能です。
テンプレートと即時スクレイピング
Amazon、Zillow、Google Maps、Instagramのような人気サイトには、Thunderbitの即時テンプレートがあります。サイトを選ぶだけで、項目はあらかじめ設定済みです。セットアップは不要です。
スケジューリングと自動化
毎日最新データが必要ですか? スケジュール(「毎週月曜の午前9時」など)を設定すれば、Thunderbitが自動でスクレイピングし、Google Sheetsやデータベースを手を動かさずに更新してくれます。
クラウドとローカルの使い分け
ブラウザで実行するか(ログインが必要なサイトや操作が多いサイトに最適)、クラウドで実行するか(公開データ向けで高速、最大50ページを同時処理)を選べます。
データスクレイピングとは? 2025年版のやり方 Get Started Free
Thunderbitの高度な機能は、信頼性が高く、拡張性があり、使いやすいウェブスクレイピングを求めるビジネスユーザーにとって最適な選択肢です。
ステップごとのガイド:Thunderbitでウェブスクレイパーを作る方法
すぐ始められるチェックリストはこちらです。
- Thunderbitをインストール:Chrome拡張機能を追加して登録します。
- 対象サイトを開く:必要ならログインし、スクロールしてコンテンツを読み込みます。
- Thunderbitのサイドバーを開く:拡張機能のアイコンをクリックします。
- 欲しいデータを伝える:「AIで項目を提案」をクリックするか、プロンプトを入力します。
- 項目を確認:必要に応じて列名の変更、追加、削除を行います。
- 「スクレイプ」をクリック:あとはThunderbitに任せます。
- (任意)サブページをスクレイプ:より深いデータが必要なら「サブページをスクレイプ」をクリックします。
- 結果を確認:表の内容が正しいか確認します。
- データをエクスポート:Excel、CSV、Google Sheets、Notion、Airtable、JSONから選びます。
- 保存/テンプレート化/スケジュール設定:次回のために設定を保存するか、定期スクレイピングを予約します。
トラブルシューティングのヒント:
- データが足りない場合は、プロンプトを言い換えるか、カスタム指示を使ってみてください。
- 動的コンテンツの場合は、ブラウザモードになっているか確認してください。
- 無料プランの上限に達したら、より多くのページを扱えるプランへのアップグレードを検討しましょう。
まとめと重要ポイント
ウェブスクレイパーを作るのは、もはやコーダーだけのものではありません。自分でPythonを書く方法を選んでも、AIに面倒な部分を任せても、今では使えるツールがこれまで以上に身近になっています。
覚えておきたいポイント:
- ウェブスクレイピングは時間を節約し、精度を高め、データドリブンな意思決定を可能にします。
- Pythonは学習や独自プロジェクトに最適ですが、コーディングと保守が必要です。
- Thunderbitは高速なノーコード解決策です。欲しいものを伝えて「スクレイプ」をクリックするだけです。
- 自動ページネーション、サブページスクレイピング、AIによる項目提案などの高度な機能により、Thunderbitはビジネスユーザー向けの強力なツールになります。
- Thunderbitは無料で試せて、数分で結果を確認できます。
コピペ作業をやめて、自動化を始める準備はできましたか? Thunderbitをダウンロードして、ウェブスクレイピングがどれだけ簡単か体験してみてください。さらに詳しく知りたい方は、Thunderbitブログでほかのチュートリアルやヒントもチェックできます。
Thunderbit AIウェブスクレイパーを無料で試す Get Started Free
よくある質問
1. ウェブスクレイパーを作るにはコーディングの知識が必要ですか?
いいえ。Python + Beautiful Soupのようなコーディングは完全な制御ができますが、Thunderbitのようなノーコードツールなら、自然な日本語のプロンプトと数クリックで誰でも強力なウェブスクレイパーを作れます。
2. Thunderbitではどんなデータをスクレイピングできますか?
Thunderbitは、テキスト、数値、画像、メールアドレス、電話番号などを、ほぼあらゆるウェブサイトから抽出できます。ページネーション付きの一覧やサブページにも対応しています。人気サイト向けのテンプレートも使えます。
3. レイアウトが変わるサイトにはThunderbitはどう対応しますか?
ThunderbitのAIは、多くのレイアウト変更に自動で適応します。サイト更新のたびに壊れやすい従来型スクレイパーとは違い、Thunderbitは意味を理解して動くため、最小限の調整で継続できます。
4. ウェブスクレイピングは合法で安全ですか?
公開されているデータを収集し、サイトの利用規約を守る限り、ウェブスクレイピングは合法です。Thunderbitは責任ある利用を推奨し、コンプライアンスを支援する機能も備えています。
5. 定期スクレイピングやエクスポートの自動化はできますか?
はい。Thunderbitでは、毎日、毎週など任意の間隔でスクレイピングを予約でき、結果をGoogle Sheets、Notion、Airtable、Excel、CSVに直接エクスポートできます。手作業は不要です。
データ収集の自動化を始める準備はできましたか? Thunderbitを無料で試すして、ウェブスクレイピングが誰にとってもどれだけ簡単か体験してください。
詳しく知る




