
先週、営業チームのメンバーのひとりが、データベンダーから購入した4,000件のコンタクトが入ったスプレッドシートを見せてくれました。2週間アプローチした結果の返信率は0.3%、バウンス率は12%超。かなりの費用をかけたのに、ほとんど成果はありませんでした。
2026年のリードリストの多くは、最初から役に立たないことが少なくありません。 によると、2025年に送信された3,100万通のメールを分析した結果、コールドメールのシーケンス全体の平均返信率はわずか4.5%。しかもこれは“平均”なので、実際にはそれを下回るキャンペーンがたくさんあります。一方、 では、営業担当者が実際に販売活動に使える時間は週の40%だけで、残りの60%は管理、リサーチ、そして——ご想像の通り——見込み客探しに費やされるとされています。
だからこそ、時間をかけてリストを作るなら、きちんと返信が返ってくるものにする必要があります。このガイドでは、ICPの定義、LinkedIn以外でのリード探索、正しいテンプレートの作成、バウンス率を下げるためのデータ検証、送信前のリードスコアリング、そして継続的な鮮度維持まで、2026年版のワークフローを丸ごと解説します。さらに予算別に整理しているので、今日0ドルから始められます。
- 難易度: 初級
- 所要時間: 最初の50〜100件を作るのに約2〜3時間
- 必要なもの: Chromeブラウザ、、Google Sheetsまたはスプレッドシート、そして書き出したICP
リードリストとは何か?なぜ多くのリストは失敗するのか?

リードリストとは、見込み顧客となる個人や企業を整理した構造化データです。通常は、個人情報(名前、役職、メール、電話番号、LinkedIn URL)と企業情報(業界、規模、売上、所在地)を含みます。アウトバウンド営業の土台になるものです。
多くのチームが間違えるのは、リードリストと単なる連絡先の寄せ集めを混同してしまうことです。価値のあるリードリストは、「なぜこの会社なのか」「なぜ今この人なのか」に答えます。一方、どこかのベンダーから買ったリストは、せいぜい「まだ存在しているか分からないメールアドレスがここにあります」と言っているようなものです。この差は、結果に大きく響きます。
リードリストは、より大きな営業プロセスの一部でもあります。リードは市場に合う可能性のある相手、MQL(Marketing Qualified Lead)はある程度の適合や関心を示した相手、SQL(Sales Qualified Lead)は直接フォローできる状態の相手、Opportunity は進行中の商談です。リードリストはこのファネルの最上流にあり、上流が雑だと下流すべてに悪影響が出ます。
リードリストが失敗する主な理由は次のとおりです。
- データが古い: では、メールリストは少なくとも とされています。つまり、12か月ごとにコンタクトの約4分の1が使えなくなるということです。
- 対象がズレている: info@ や sales@ のような役割共有メールばかりで、直接の連絡先ではない。あるいは "Staff" のように意思決定権がまったく見えない曖昧な役職。
- 絞り込み基準がない: 戦略に見せかけた大量収集。あるフォーラムのユーザーが言っていたように、「量と質を混同してしまうことがよくある」。
- 検証していない: では、 が「CRMデータの半分未満しか正確かつ完全ではない」と答え、 と回答しています。
- 量を質より優先している: によると、21〜50件を対象にしたキャンペーンの平均返信率は、一方で501件以上では にとどまります。大きくて雑なリストより、小さくて精度の高いリストのほうが強いのです。
リードリストのテンプレート:スプレッドシートは本当はどうあるべきか
私は「リードリストの作り方」系の記事を何十本も見てきましたが、気になる点があります。どれも「連絡先情報、企業属性、リードスコアを入れましょう」と言うだけで、実際のスプレッドシートの形を見せてくれないのです。そこで、みんなが見落としている実物をここで提示します。
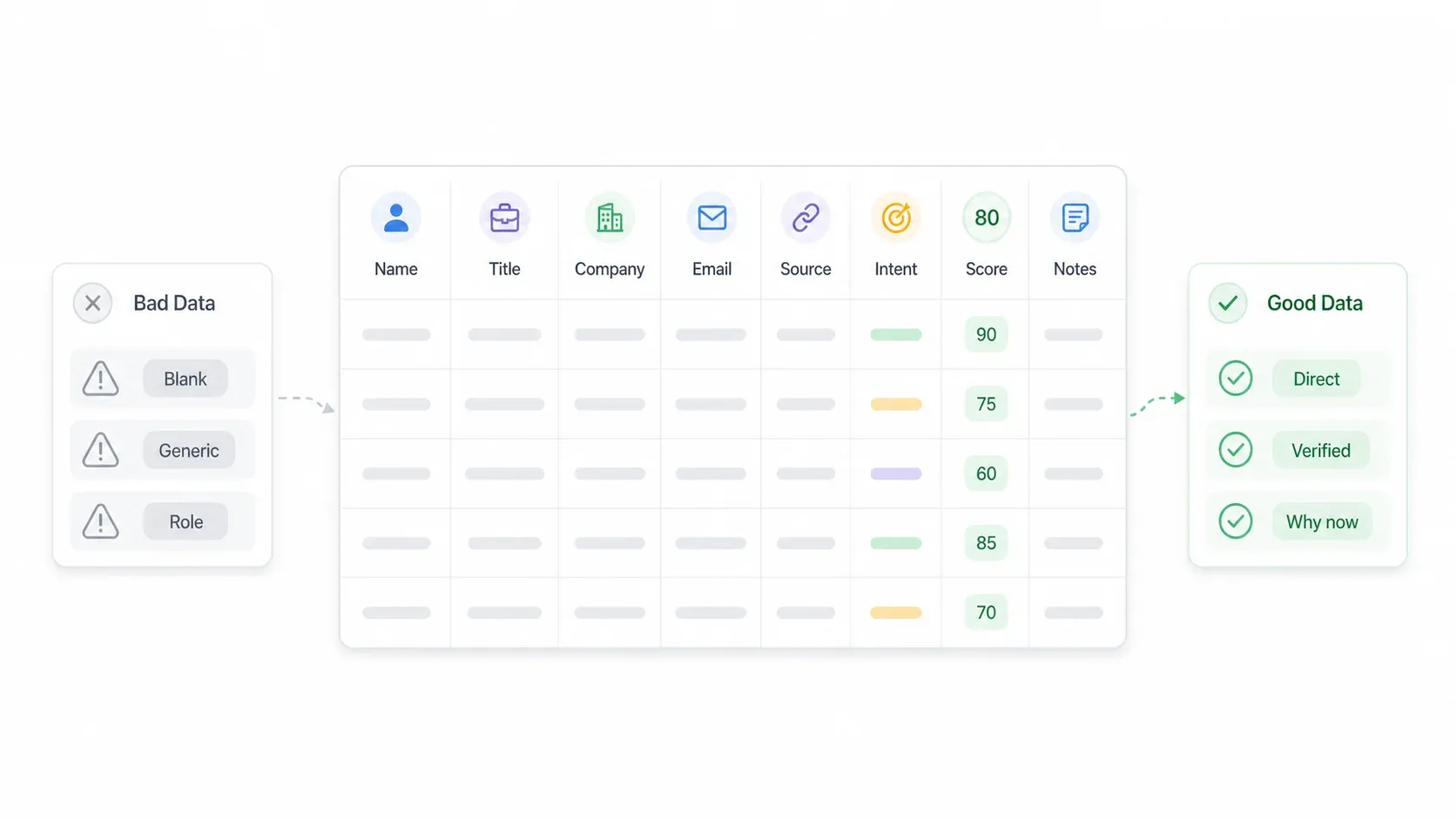
まず入れるべき列
リードリストのスプレッドシートは、最初から次の列を持っているべきです。
| 列 | 入れる内容 | 良いデータ | 悪いデータ |
|---|---|---|---|
| 氏名 | 実際の名前 | "Jordan Lee" | "Sales Team" |
| 役職 | 具体的な現在の役割 | "VP of Sales" | "Staff" |
| 会社名 | 法人名または通称 | "Acme Logistics" | "Acme?" |
| 業界 | 標準化されたカテゴリ | "B2B SaaS" | "Tech-ish" |
| 会社規模 | 従業員規模の区分 | "51-200" | 空欄 |
| メール | 直接の業務用メール | "jordan@acme.com," 検証済み | "info@acme.com" |
| 電話番号 | 直通または代表番号、整形済み | E.164形式 | 形式が混在 |
| LinkedIn URL | プロフィールまたは会社ページ | 完全なURL | 検索結果URL |
| リードソース | どこから取得したか | "G2のカテゴリページ、2026年5月" | "Internet" |
| インテントシグナル | 今まさに狙う理由 | "SDRを3人採用中"、"資金調達" | 空欄 |
| リードスコア | 数値で優先度をつける | ルール付き70/100 | 勘 |
| 最終接触日 | アプローチした日付 | "2026-05-26" | "Recently" |
| メモ | 関連する補足情報 | "Shopify Plusを利用" | 長文の未整理メモ |
サンプルのリードリスト(匿名化)
実際に埋まったリストはこんな見た目です。異なるペルソナをカバーした10件の例です。
| 氏名 | 役職 | 会社 | 業界 | 規模 | メール | ソース | インテントシグナル | スコア |
|---|---|---|---|---|---|---|---|---|
| Alex M. | VP Sales | Mid-market SaaS vendor | SaaS | 201-500 | direct verified | G2 category | SDR採用中 | 78 |
| Priya S. | Head of Ops | DTC apparel brand | Ecommerce | 51-200 | direct verified | Shopify showcase | 物流拡大 | 72 |
| Marcus T. | Founder | Local agency | Professional services | 11-50 | direct verified | Clutch | 新しいレビュー増加 | 66 |
| Elena R. | Revenue Ops Manager | Cybersecurity startup | SaaS | 51-200 | catch-all flagged | Conference speakers | Series A | 61 |
| Ben C. | Owner | HVAC contractor | Local services | 11-50 | main office email | Google Business | 高評価レビュー多数 | 48 |
| Mina K. | Director of Partnerships | Marketplace company | Ecommerce | 201-500 | direct verified | Event agenda | イベント協賛 | 74 |
| Diego P. | Real Estate Broker | Regional brokerage | Real estate | 11-50 | direct verified | Association directory | 新しいオフィスページ | 58 |
| Sarah N. | Customer Support Lead | B2B software company | SaaS | 51-200 | role-based removed | Capterra | サポートレビューが少ない | 44 |
| Omar A. | IT Manager | Manufacturing firm | Manufacturing | 501-1000 | direct verified | Company team page | ERP移行の言及 | 69 |
| Lena W. | Growth Marketing Lead | Fintech startup | SaaS | 51-200 | direct verified | Product Hunt | 新規ローンチ | 71 |
各列の意味と「良い」データの見方
特に説明が必要な列をいくつか挙げます。
- 役職: "VP of Sales" なら、その人に予算の決裁権があると分かります。"Staff" では何も分かりません。意思決定権や影響力が見える、具体的な役職を狙いましょう。
- メール: 個人用の業務メール(jordan@acme.com)は非常に価値があります。役割共有のアドレス(sales@acme.com)は、コールドアウトリーチではほぼ価値がありません。誰も見ていない共有受信箱に届くだけだからです。
- リードソース: 多くの人が飛ばしがちな列ですが、長期的には最重要です。各リードがどこから来たかを追跡すれば、どのチャネルが“行”ではなく“返信”を生んでいるのかが分かります。"G2のカテゴリページ、2026年5月" は有効ですが、"Internet" では意味がありません。
- インテントシグナル: これが「今なぜ狙うべきか」を示す列です。直近でSeries Aを調達した、SDRを3件採用している、新製品を出した——こうした会社は、静かに何も動いていない会社よりずっと温かいリードです。インテントシグナルが見つからないなら、優先順位は低いかもしれません。
ThunderbitのAI Suggest Fieldsでテンプレートを自動作成する方法
の中でも、特に気に入っている機能があります。それは、どの列を作るべきか迷わなくていいことです。ディレクトリ一覧、会社のチームページ、カンファレンスの登壇者一覧のような見込み客が多いページをThunderbitで開き、「AI Suggest Fields」 をクリックすると、AIがページ内容を読み取って適切な列名とデータ型を自動で提案してくれます。名前、メール、役職、会社情報があれば、Thunderbitはそのままそれらを列として提案します。
これは、空白のスプレッドシートを見て「何を取ればいいんだろう」と悩む初心者に特に便利です。Thunderbitは、元ページに実際にあるデータをもとに答えを出してくれます。あとは 「Scrape」 を押して、、Excel、Airtable、Notion に直接エクスポートするだけです。
リードリストを作る前に、理想顧客像(ICP)を定義する方法
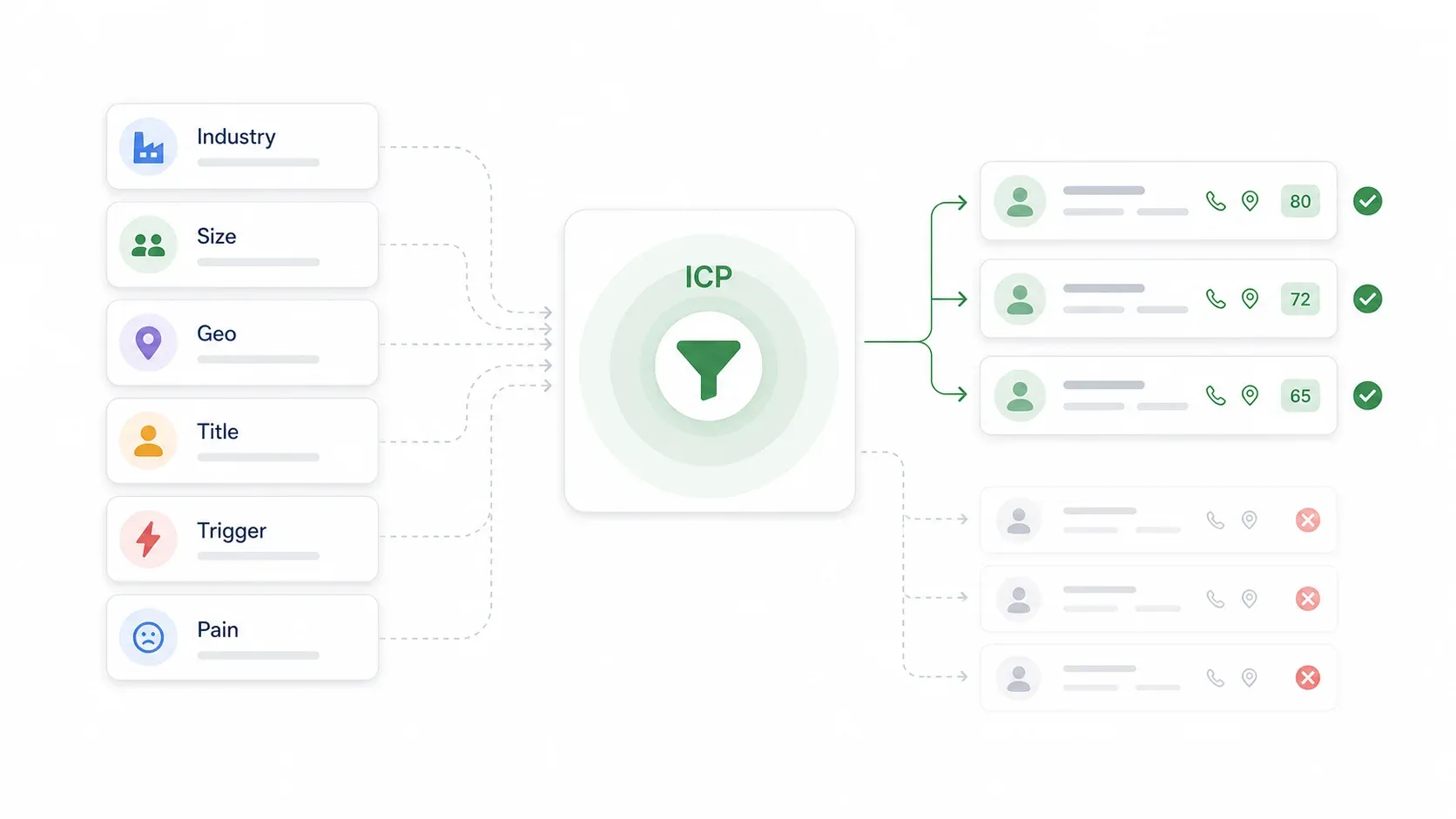
私が見てきた中で、チームが最もよくやる失敗——そして私自身もやったことがある失敗——は、誰を対象にするか決める前にリストを作り始めてしまうことです。その結果、名前だけが並んだスプレッドシートができあがり、誰にとってなぜ必要なのかが全く見えなくなります。
ICPとは、あなたの商品から最も価値を得られ、実際に購入し、長く使ってくれる会社や人物の条件です。ペルソナ作りではなく、ターゲティングのフィルターです。
ICPの構成要素
| ICP項目 | 考えること | 例 |
|---|---|---|
| 業界 | どのカテゴリに課題があるか | B2B SaaS、ecommerce、professional services |
| 会社規模 | どの層が今すぐ買えるか | 従業員51〜500人 |
| 地域 | どこなら販売・支援しやすいか | 米国、カナダ、英国 |
| 売上レンジ | どの売上帯が合うか | ARR 500万〜1億ドル |
| 購買者の役職 | 誰が課題や予算を持つか | VP Sales、RevOps、Head of Ops |
| トリガー | 何が緊急性を高めるか | 採用、資金調達、移行、低評価レビュー |
| 課題 | どんな問題を感じているか | 手動のリスト作成、古いデータ、遅いエンリッチメント |
| 除外条件 | 誰を外すべきか | 学生、趣味の事業、競合 |
実践演習: 既存のベスト顧客5〜10社を見てください。共通点は何でしょうか? 業界? 規模? 契約にサインした人物の役職? 3〜5個の共通項を書き出せば、それがICPのたたき台です。
Firmographics と Demographics:どちらが重要か?
Firmographics は企業単位のデータです。業界、規模、売上、所在地などが含まれます。Demographics はB2B文脈では個人単位のデータで、役職、シニアリティ、職能、部門などを指します。B2Bのリードリストでは、Firmographics で会社を絞り、Demographics で人を絞ります。両方必要です。会社は完璧でも相手が違えば、その行は無駄です。相手が完璧でも会社が違えば、同じく意味がありません。
もうひとつ付け加えると、 では、 を分析した結果、意思決定に関わるステークホルダーの平均は約 でした。つまり、良いリードリストは1アカウントにつき複数のコンタクトを含むことが多いですが、多すぎるとスパムっぽくなるので要注意です。
LinkedIn以外でリードを見つける場所:Webサイト、ディレクトリ、SNS
このテーマを調べて驚いたのは、上位表示されている「リードリストの作り方」記事6本のうち5本が、主要なリードソースとして LinkedIn Sales Navigator に誘導していたことです。もちろんSales Navigatorは強力です。ただし高額でもあり(Coreプランで)、実際のユーザーはエクスポート制限、重いUI、スクレイピングの手間に不満を漏らしがちです。
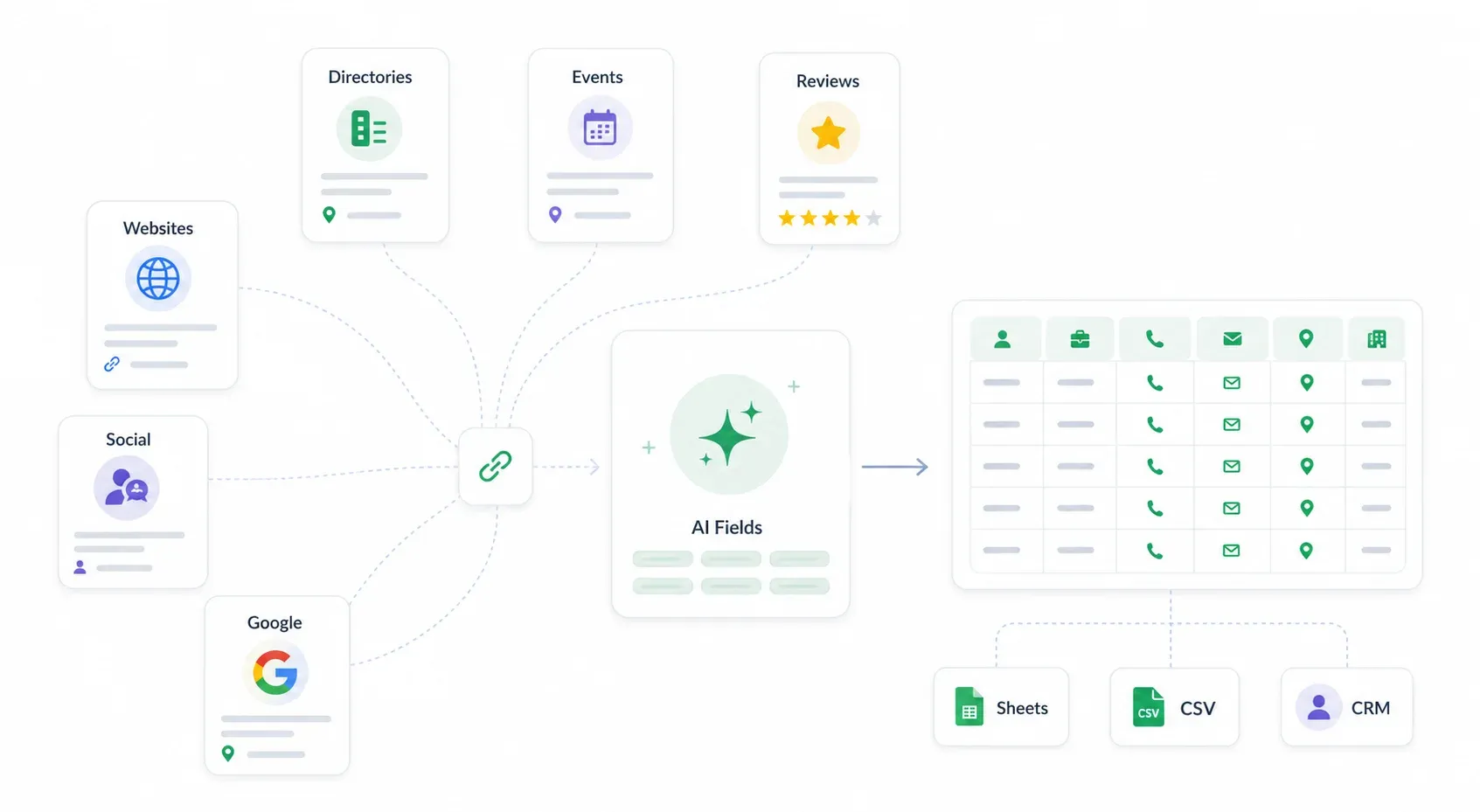
2026年の現実では、リードはLinkedInだけにいません。企業サイト、業界ディレクトリ、イベントページ、レビューサイト、さらにはSNSプロフィールまで、連絡先データの宝庫です。しかも、買ったデータベースより鮮度が高く、情報も具体的なことがよくあります。
リードソース比較
| リードソース | 向いている用途 | 方法 | 費用 |
|---|---|---|---|
| 企業サイト / Aboutページ | ニッチなB2B、地域密着サービス、代理店 | チーム/問い合わせページを見て、氏名・メール・電話を抽出 | 無料 |
| 業界ディレクトリ(Clutch、G2、Yelp) | サービス系リード、業界別エコシステム | カテゴリや地域で絞り込み、掲載情報をスクレイプ | 無料〜低コスト |
| イベント参加者 / 登壇者リスト | 購買意欲の高いB2B見込み客 | カンファレンス日程、スポンサーページ、ウェビナー登録情報 | 無料〜有料イベント参加費 |
| レビューサイト(G2、Capterra、Google Business) | SaaS、ローカルビジネス | カテゴリを閲覧し、企業情報を抽出 | 無料 |
| SNS(Instagram、X) | B2C、パーソナルブランド、地域ビジネス | 公開プロフィール、ビジネスページ | 無料 |
| Googleの site: 検索 | ロングテール発見、特定の問い合わせページ探し | 高度な検索クエリ | 無料 |
| LinkedIn(基本検索) | ビジネス向け検索 | 手動検索、公開プロフィール | 無料 |
| LinkedIn Sales Navigator | 成熟したアウトバウンドチーム | 高度なフィルター、保存リード、TeamLink | 月額99ドル以上 |
業界別に使えるディレクトリ
| 業界 | スクレイピング候補 |
|---|---|
| SaaS | G2、Capterra、Product Hunt、SaaSworthy、AWS Marketplace、Chrome Web Storeのカテゴリ |
| Ecommerce | Shopifyストア / showcase、BuiltWithのリスト、Klaviyoのパートナーディレクトリ |
| 不動産 | Realtorディレクトリ、仲介会社のオフィスページ、地域MLSの公開ページ、商工会ページ |
| Professional services | Clutch、DesignRush、UpCity、GoodFirms、地域の弁護士会 / 会計士ディレクトリ |
| ローカルビジネス | Google Businessの検索結果、Yelp、Yellow Pages、BBB、地域商工会ページ |
| イベント | スポンサー / 出展者ページ、登壇者一覧、アジェンダページ、ウェビナーLP |
リード発見に使える Google の高度検索演算子
これらは無料で、しかも驚くほど強力です。例をいくつか挙げます。
site:clutch.co/agencies "B2B SaaS" "United States"— Clutch上の代理店一覧をカテゴリと地域で絞って見つけるsite:company.com ("email" OR "contact") "VP Sales"— ある企業サイト内で VP Sales に触れている問い合わせページを探すintitle:"sponsors" "SaaS" "2026" "conference"— 2026年のSaaS関連カンファレンスのスポンサー頁を探すsite:g2.com/categories "sales engagement" "mid-market"— G2でミッドマーケット向け営業支援ツールのカテゴリページを探す
には、完全一致の引用符や site: などの演算子が説明されているので、構文の確認にも使えます。
AI Web Scraper であらゆるWebサイトから連絡先を抽出する方法
ここでThunderbitがワークフローに自然に入ってきます。上のどのソースでも——Clutchのディレクトリ、企業のチームページ、カンファレンスの登壇者一覧——手順は同じです。
- を入れたChromeでページを開く。
- 「AI Suggest Fields」 をクリックする。ThunderbitのAIがページを読み取り、Name、Email、Phone、Title、Company のような列を提案する。
- 提案されたフィールドを確認し、必要に応じて追加・削除する。
- 「Scrape」 をクリックする。
- Google Sheets、Excel、Airtable、Notion にエクスポートする。
最大の利点は、Thunderbitが、あらかじめ決め打ちのスクレイパーテンプレートでは対応しきれない、バラバラで非標準なサイトにも対応できることです。AIが毎回実際のページを読み込むので、構造が違っていても柔軟に合わせてくれます。Thunderbitの無料 は、どのページからでもワンクリックで抽出でき、無料枠でも無制限です。
サブページスクレイピングでリードリストを充実させる
私がよく使うワークフローがあります。まずディレクトリ一覧ページ(たとえばClutchの企業一覧)をスクレイプし、その後ThunderbitのSubpage Scraping を使って各企業の個別ページを巡回し、メール、電話番号、従業員数、技術スタック、説明などを追加取得します。
これで、単なるディレクトリ一覧が、手作業のクリックなしでリサーチ可能な充実リードリストに変わります。「会社名が50件あります」から「連絡先メール、チーム規模、説明付きの50社があります」へ、一気に進めるわけです。 についてもっと知りたい方は、詳しい解説も用意しています。
2026年版:リードリストを段階的に作る方法
以下は、非エンジニアの営業担当やオペレーション担当でも今日から実践できる、完全版のワークフローです。
ステップ1:ICPを明確にする
ツールを開く前に、ICPの条件を書き出します(上のICPセクションを参照)。業界、会社規模、地域、買い手の役職、トリガー、除外条件です。これに15〜30分かけるだけで、無駄なスクレイピングを何時間も防げます。
ステップ2:リードソースを選ぶ
ICPと予算に合わせて、比較表から2〜3のソースを選びます。おすすめは、まず無料ソースから始めることです。SaaS企業を狙うなら、G2のカテゴリページや企業のチームページ。ローカルビジネスなら Google Business の検索結果や Yelp から始めましょう。有料のSales Navigatorは、無料ソースを使い切ってからで十分です。
ステップ3:AIスクレイピングまたは手動検索で抽出する
ソースごとの抽出方法は次のとおりです。
- Webサイトとディレクトリ: ThunderbitのAI web scraper を使います。ページを開き、「AI Suggest Fields」をクリックし、列を確認して、「Scrape」を押します。人気サイトには、フィールドを自動設定してくれる もあります。
- LinkedIn: Sales Navigatorで検索してエクスポートするか、Thunderbitで します。
- Google: 高度な検索演算子を使って検索し、結果ページをスクレイプするか、個別ページを見に行きます。
エクスポート先は Google Sheets、Excel、Airtable、Notion、CSV、JSON です。
ステップ4:データを検証・整形する
この工程は必須です。詳細な検証フローは後半の専用セクションで扱いますが、簡単に言うと、役割共有メールを除外し、重複を削除し、検証ツールを通し、catch-all ドメインをフラグ付けし、キャンペーン前に再検証します。
ステップ5:リードにスコアをつける
アウトリーチを始める前に、シンプルなスコアリングモデルを適用します(後で詳しく解説します)。こうすることで、たまたまスプレッドシートの上にある人からではなく、最も価値の高い相手から優先して連絡できます。
ステップ6:CRMまたはアウトリーチツールへエクスポートする
整形してスコアを付けたリストを、CRM(HubSpot、Salesforce、Pipedrive)またはアウトリーチプラットフォーム(lemlist、Mailshake、Apollo)へ移します。Thunderbitは Sheets、Airtable、Notion に直接出力でき、ネイティブ連携や Zapier 経由でCRMと同期できます。
ステップ7:アウトリーチを開始し、結果を追跡する
集めたデータをもとに、メッセージをパーソナライズします。相手の業界に触れ、インテントシグナル("SDRを採用しているのを見ました" など)を参照し、課題に合わせて価値提案を調整しましょう。返信率、バウンス率、成約率を追跡し、そのデータを次回のICPとスコアモデルに反映させます。
予算優先で考える:0ドルからエンタープライズまでのリードリスト作成法
創業初期の起業家や小規模営業チームから最もよく聞く悩みは、「高価なツールを買わずにどうやってリードリストを作ればいいの?」です。もっともな疑問です。ZoomInfo の契約は年間数万ドル規模から始まります。Sales Navigator は月額99ドル以上。Apollo と Lusha は無料枠があるものの、良い機能は有料の壁の向こうです。
正直な答えは、無料でもかなり遠くまで行ける、です。ただし、スケールには多少の投資が必要になります。レベル別に考えてみましょう。
| 段階 | 費用 | 方法 | ツール |
|---|---|---|---|
| 無料($0) | $0 | Google演算子、手動LinkedIn、企業サイト、Thunderbit無料枠(6ページ + 無料のメール/電話抽出) | Thunderbit Free、Google、LinkedIn基本版 |
| 低コスト(<$50/月) | $0-50 | 大量のAIスクレイピング、基本エンリッチメント、メール検証 | Thunderbit Starter/Pro、Hunter Starter(月$34)、Bouncer/NeverBounceの従量課金 |
| 中価格帯($50-200/月) | $50-200 | Sales Navigator、より詳細なフィルター、CRM連携 | Sales Navigator Core(約$99/月)、有料Apollo、Lusha |
| エンタープライズ($200+/月) | $200+ | インテントデータ、エンリッチメントスイート、コンプライアンスワークフロー | ZoomInfo(見積もり制)、Cognism(見積もり制)、Clearbit |
価格は2026年5月時点のものです。購入前に最新料金を確認してください。
無料でどこまでできるか、どこで限界が来るか
Thunderbitの無料枠(月6ページのAIスクレイピング)、無料のEmail ExtractorとPhone Number Extractor(無制限・ワンクリック)、Googleの検索演算子、そして基本的なLinkedIn検索を組み合わせれば、個人の起業家でも午後のうちに50〜100件のリードリストを作るのは現実的です。実際に社内でもそのように作っている人を見てきました。
限界が来るのは、量(無料枠でのページ数)、エンリッチメントの深さ(有料ツールなしではインテントデータや技術スタック情報が取れない)、そして大規模なメール検証(無料ツールは件数制限がある)です。そこが苦しくなってきたら、低コスト帯に移るタイミングです。 では、サブページスクレイピング、一括スクレイピング、ページネーション、スケジュールスクレイパーが使えるようになります。
バウンス率を下げる:ちゃんと機能するデータ検証フロー
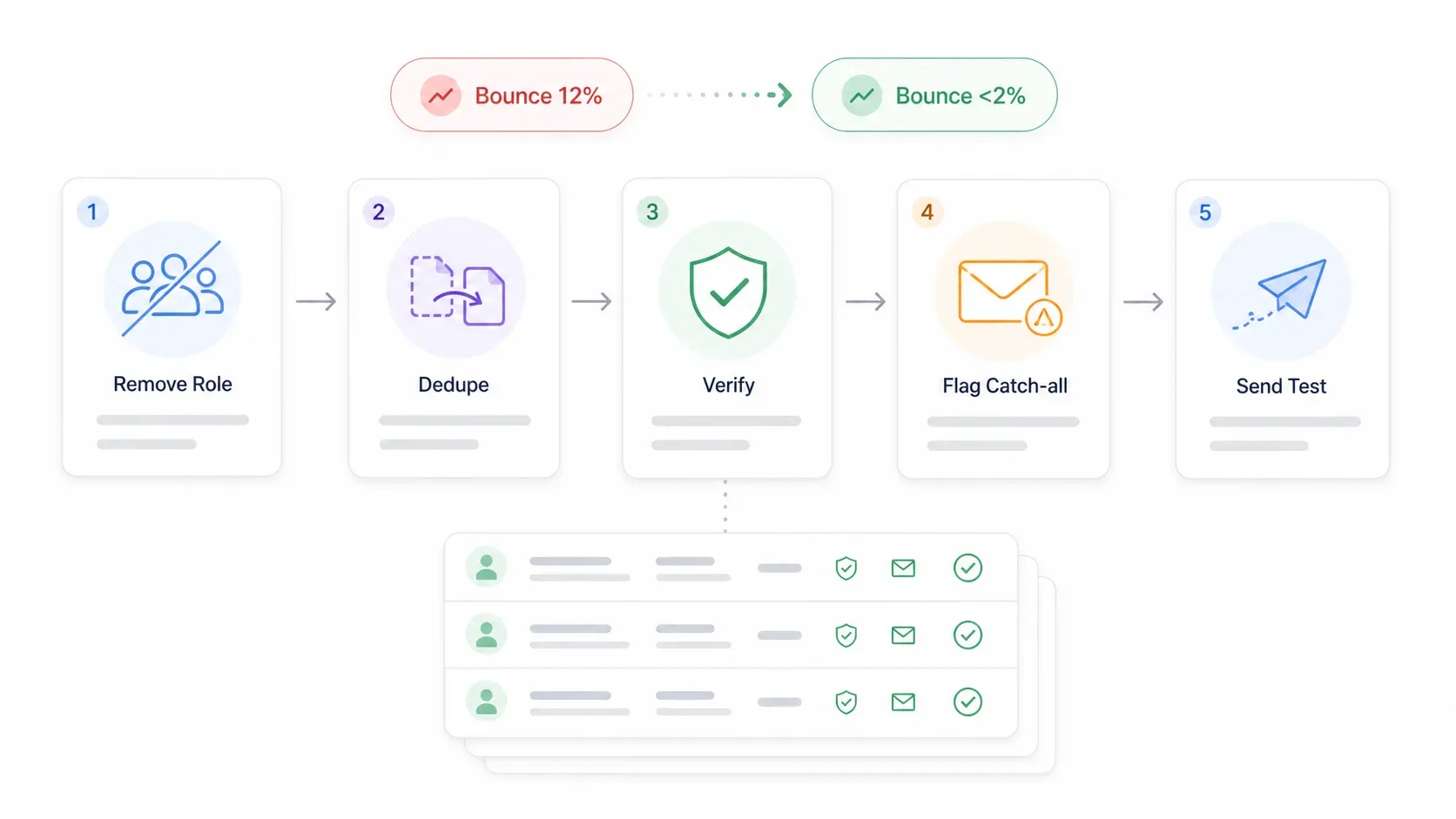
購入したリストで だったというユーザーの投稿を見たことがあります。これは単なる無駄ではなく、かなり危険です。高いバウンス率は送信者レピュテーションを傷つけるため、良いメールまでスパムに入るようになります。
では、健全なバウンス率は2%未満、1%未満なら優秀とされています。 では、送信者の約半数が2〜5%のバウンス率を報告し、 でした。5%を超えるなら、送信者レピュテーションに問題が出始めています。
おすすめの検証フローは次のとおりです。
- 役割共有メールを削除する: info@、sales@、support@、admin@ などは、共有受信箱を意図的に狙う場合を除き削除します(コールドアウトリーチではまれです)。
- 書式エラーを削除する: 重複、 টাইपो、ドメイン欠落、死んでいるドメインなど。スプレッドシートで簡単に並べ替え・フィルターするだけで、ほとんどは見つかります。
- メール検証ツールを通す: Hunter、ZeroBounce、NeverBounce、Bouncer、Kickbox などを使います。これらはメールを送らずにメールサーバーへ照会し、受信箱が存在するか確認します。
- catch-all ドメインをフラグ付けまたは削除する: では、catch-all は大きなリスクカテゴリで、個別の受信箱の存在を確認しないままサーバー側で受信を許可することがあるとされています。個別受信箱を確認できない場合は、記録にフラグを立て、信頼度が低いものとして扱いましょう。
- 毎回のキャンペーン前に再検証する: データはすぐ古くなります。リストが30〜90日以上前のものなら、送信前に再検証してください。
- 最初は少数ずつ送る: 最初の50〜100通でバウンス率と苦情率を確認し、品質が保たれている場合のみ拡大します。
リードソースがデータ品質に与える影響
すべてのリードデータが同じではありません。企業の公開チームページから取得したメール——その人が自分で連絡先を掲載しているページ——は、何か月も更新されていない集約データベースのメールより、たいてい新しく正確です。
だから私は、静的なデータベースだけに頼るのではなく、公開されているライブページからスクレイプすることを重視しています。ThunderbitのAIは毎回実際のWebサイトを新しく読み込むため(古いデータベースではなく)、抽出されるメールや電話番号は最新であることが多いのです。Phone Number Extractor は番号を E.164 標準に整形してくれるので、CRMへ取り込んだ後のフォーマットエラーも減らせます。
鮮度の高いソースから取得することは、検証の代わりにはなりません。ただ、最初からよりきれいな素材で始められるという意味はあります。
キャンペーン前チェックリスト
送信ボタンを押す前に、次を確認してください。
- [ ] すべてのメールが30日以内に検証済み
- [ ] 送信リストに役割共有アドレス(info@、sales@)がない
- [ ] 重複がない
- [ ] 前回キャンペーンのバウンス率を確認済み
- [ ] 配信停止 / オプトアウト手段を設置済み
- [ ] サプレッションリストが同期されている(過去のオプトアウトを必ず尊重)
作成してからスコアを付ける:小規模チーム向けのシンプルなリードスコアリング
私が読んできたガイドはどれも「リードを優先しましょう」と言うだけで、どうやるかは教えてくれません。

もしあなたがソロ起業家、または3人規模の営業チームなら、Salesforce Einstein や予測スコアリングエンジンは不要です。必要なのは、透明性のあるルールを持ったスプレッドシートの列です。
スコアリングの枠組み
| シグナル | 点数 | 例 |
|---|---|---|
| ICPの業界に一致 | +20 | SaaS、ミッドマーケット |
| 会社規模が合う | +10 | 従業員51〜500人 |
| 意思決定者の役職 | +15 | VP Sales、Head of Ops |
| 明確なインテントシグナル | +15 | 採用、資金調達、ツール移行 |
| メールが検証済み | +10 | 検証通過 |
| 直接ソースの品質が高い | +10 | 会社ページ、登壇者ページ |
| コンテンツに反応済み | +10 | ガイドDL、ウェビナー参加 |
| catch-all / 未検証メール | -10 | リスクの高い検証状態 |
| 役割共有メール | -10 | info@、sales@ |
| 一般的すぎる役職(役割不明) | -5 | "Staff" |
実例
リードA: 120人規模のSaaS企業のVP Sales。SDRを採用中。メールは検証済み。会社の採用ページ / チームページから取得。
スコア: 20(業界)+ 10(規模)+ 15(役職)+ 15(インテント)+ 10(検証済み)+ 10(ソース)= 80 → 今週のアウトリーチ対象として優先。
リードB: 5人の趣味ビジネスにいる "Staff"。役割共有メール。インテントシグナルなし。
スコア: 0 + 0 + 0 + 0 + 0 - 10(役割共有) - 5(一般的な役職)= -15 → スキップまたは削除。
これは Google Sheets にそのまま入るシンプルな式で十分です。たとえばこんな感じです。
1=IF(D2="SaaS",20,0)+IF(AND(E2>=51,E2<=500),10,0)+IF(REGEXMATCH(B2,"VP|Head|Director|Founder"),15,0)+IF(J2<>"",15,0)+IF(K2="Verified",10,IF(K2="Catch-all",-10,0))Salesforceは不要です。
スクレイピング中にAIでリードへラベル付け・スコア付けする方法
Thunderbitに組み込んだ機能の中で、スコアリングに本当に役立つと感じているのが Field AI Prompts です。スクレイプ設定時に任意の列へプロンプトを追加でき、たとえば 「役職とページ文脈をもとに、このリードのシニアリティを Decision-Maker、Influencer、Individual Contributor のいずれかに分類して」 のように指示できます。
Thunderbitは抽出時点でラベル付けを行うので、Sheetsへ出力した時点でシニアリティ分類、企業タイプ、業界タグがすでに入っています。あとはそれをスコア計算式に差し込むだけです。手作業のタグ付け工程が消えるので、スコアリングが面倒に感じにくくなります。
さらに Subpage Scraping を使えば、元の一覧データを拡張できます。まずディレクトリをスクレイプし、その後各社ページを訪れて従業員数、資金調達状況、技術スタックを取得する。これらはすべてスコアモデルの材料になります。
スコアを見直すタイミング
リードスコアは一度つけたら終わりではありません。毎月、または大きなキャンペーンの後に再スコアリングしましょう。リードが前向きに返信したなら、その時点で“冷たい見込み客”ではなく“進行中の会話”になります。メールがバウンスしたなら、それに応じて調整します。6か月前に採用していた会社がその後レイオフしていたなら、インテントシグナルは変わっています。
リードリストを新鮮に保つ方法(自動化とメンテナンス)
リードリストは一度作って終わりではありません。
先ほども述べたように、 とされています。連絡先は転職し、会社は方向転換し、メールは古くなります。5月に良いリストを作って10月まで放置すれば、そのかなりの部分はすでに使えません。
メンテナンスの頻度
| 作業 | 頻度 | 理由 | |---|---|---|---| | メール検証 | 毎キャンペーン前(少なくとも毎月) | ハードバウンスを防ぐ | | 連絡先の重複削除 | सक्रियな開拓中は毎週 | 重複送信を避ける | | インテントシグナル更新 | 毎月 | 採用 / 資金調達 / レビューはすぐ変わる | | 会社属性の更新 | 四半期ごと、または半年ごと | 規模、売上、技術スタックは変化する | | サプレッションリスト同期 | 毎日またはリアルタイム | 配信停止を尊重し、苦情を減らす | | ソース別パフォーマンス確認 | 毎月 | どのチャネルが“行”ではなく“返信”を生むかを把握する |
継続的なリード生成のために定期スクレイプを設定する
ここでThunderbitのScheduled Scraper が活躍します。毎月ディレクトリを手動で見直す代わりに、定期スクレイプを設定できます。設定はシンプルで、"毎週月曜の午前8時" のように間隔を自然言語で書き、対象のWebサイトURLを入れて、「Schedule」をクリックするだけ。ThunderbitのAIがあなたの言葉をスケジュールに変換し、自動でスクレイプを実行して、更新された結果を接続済みのGoogle SheetやAirtableに送ります。
うまくいった事例としては、次のようなものがあります。
- 営業チームが毎月 Clutch のカテゴリページを再スクレイプして、新しく市場に入ってきた代理店を拾う。
- Ecommerceのオペレーションチームが毎週、競合ディレクトリを監視して新商品の掲載を確認する。
- SaaS創業者が毎月のアウトバウンド送信前に G2 のカテゴリページを更新し、新しく掲載された企業を見つける。
Thunderbitのクラウドモードでは できるので、大きなディレクトリでも素早く更新できます。設定方法の詳細は、 のガイドを参照してください。
コンプライアンスとデータプライバシーに関する注意
このガイドの主題ではないので簡潔にしますが、非常に重要です。
- CAN-SPAM(米国): B2Bを含むすべての商用メールに適用されます。、違反メール1通ごとに最大 の罰則が発生し得ます。必要条件は、正確なヘッダー、誤解を招かない件名、有効な郵送先住所、明確な配信停止手段、そして10営業日以内の配信停止対応です。
- GDPR(EU/UK): 会社名付きの業務用メールでも個人データに該当し得ます。 、B2Bマーケティングでは身元を隠してはいけず、有効なオプトアウトを提供し、異議申し立てを尊重する必要があります。
- CCPA/CPRA(カリフォルニア): 通知、目的限定、データ最小化、消費者の権利を重視します。 に最新情報があります。
- Google / Yahoo の送信者ルール: 大量送信者に対し、スパム率を0.30%未満に保つこと、SPF/DKIM/DMARCで認証すること、ワンクリック配信停止をサポートすることを求めています。 を適用しています。
要するに、公開されているデータだけをスクレイプし、許可なくログイン必須の壁を越えず、必ずオプトアウト手段を入れ、サプレッションリストを維持し、各地域の法的要件を確認してください。Thunderbit は公開ページをスクレイプするツールであり、そのデータをどう使うかの責任はユーザー側にあります。
まとめと重要ポイント
2026年版のリードリストワークフローは、名前をより多く集めることではありません。返信が返ってくる、小さくて新しく、検証済みで、ソースを把握できるアウトリーチ用データセットを作ることです。
全体の流れをまとめると、次のとおりです。
- ツールに触る前にICPを定義する。
- 2〜3のリードソースを選ぶ — まずは無料のディレクトリ、企業ページ、Google演算子から始め、データベースは後回し。
- AIスクレイピングでリードを抽出する — Thunderbit の2クリック処理は、ほぼすべての公開ページで使えます。
- きちんとしたテンプレートを作る — ソース追跡、インテントシグナル、スコア列を入れる。
- 検証して整える — 役割共有メールの削除、重複除去、検証、catch-all のフラグ付け。
- スコアを付けて優先順位をつける — 勘ではなく、透明なスプレッドシートのモデルを使う。
- CRM / アウトリーチへ出力する — 集めたデータに基づいてパーソナライズする。
- 結果を追跡する — バウンス、返信、成約をリードソース別に見る。
- 継続的に更新する — キャンペーン前に再検証し、価値の高いソースは定期的に再スクレイプする。
データもそれを裏づけています。 のです。検証済みの200件のリストは、5,000件の古いデータベースより、ほぼ確実に良い結果を出します。
最初のリストを作る準備はできましたか? なら、月6ページのAIスクレイピング、無制限の無料メール / 電話抽出、Google Sheets または Excel へのエクスポートができます。今日の午後に最初の50〜100件を作るには十分です。
よくある質問
最初のリードリストは何件くらいにすべき?
最初は、条件に合った検証済みのリードを50〜100件に絞るのがおすすめです。何千件もの資格不十分なコンタクトを集めるよりずっと良いです。Hunterのデータでは、21〜50件のような小さく絞られた受信者リストのキャンペーンは平均6.2%の返信率で、501件以上のキャンペーンのほぼ3倍です。質は積み上がりますが、量は薄まります。
リードリストは買うべき?それとも自分で作るべき?
ほとんどの場合、自分で作るほうが良いです。購入リストには、古いデータ、スパムトラップ、不透明なソース、コンプライアンス上のリスクがつきものです。AIスクレイピングと手動リサーチで作る自作リストは、公開ページの最新データを使うため、より新しく、より関連性の高い情報が得られます。購入する場合は、収集日、検証日、同意の根拠、更新プロセスの透明性を必ず確認してください。
一番よい無料のリードリスト作成方法は?
Googleの高度検索演算子(site:、intitle:、完全一致クエリ)と、Thunderbitの無料枠——月6ページのAIスクレイピングと無制限の無料メール / 電話抽出——、そして基本的なLinkedIn検索を組み合わせることです。この組み合わせで、企業ページ、ディレクトリ、イベント一覧、プロファイルを無料でカバーできます。
リードリストはどのくらいの頻度で更新すべき?
メールは各キャンペーン前に再検証してください。特に、リストが30日以上古い場合は重要です。完全な更新——ソースの再スクレイプ、企業属性の更新、使えないリードの削除——は少なくとも四半期ごとに行いましょう。ZeroBounceによると、メールリストは1年で少なくとも23%劣化します。つまり、「作って終わり」はバウンス率上昇の原因になります。
リードリストからのコールドアウトリーチで良い返信率は?
2025〜2026年のベンチマークでは、前向きな返信率が3〜5%なら良好、5〜8%なら強い、8%以上なら非常に優秀です。最も大きな要因はリストの質です。つまり、ターゲティング、検証、パーソナライズです。検証済みメール、明確なインテントシグナル、個別化されたメッセージを備えたよく作られたリストは、一般的なコンタクトと定型文だけの大きなリストを一貫して上回ります。
さらに詳しく知る