ウェブ上のデータは「新しい石油」とも呼ばれるほど価値がありますが、実際には無数のウェブサイトに散らばっていて、複雑なHTMLやCAPTCHA、巧妙なボット対策でしっかりガードされています。もし商品価格や競合情報、リード情報を手作業でコピペしたことがあるなら、その大変さやチャンスロスを痛感したはず。だからこそ、Go ウェブスクレイピングは現代ビジネスに欠かせないスキルになっています。実際、ウェブスクレイピングを含むオルタナティブデータ市場はに到達し、今も勢いよく成長中です。

Pythonが初心者向けとして人気を集めている一方で、実はGolang ウェブスクレイピングは世界中の高速・安定なスクレイパーの裏側を支えています。Goの強みは、圧倒的な並列処理、堅牢な標準ライブラリ、そしてバックエンドエンジニアも納得のパフォーマンス。Goに切り替えただけでスクレイピングの処理時間が半分になった、なんて話も珍しくありません。しかも、特別なエンジニアじゃなくても、適切なツールを使えばすぐに始められます。
Goでウェブスクレイピングの力を手に入れたい人のために、セットアップから応用まで、実践的なコードや現場で役立つコツ、さらにのようなAIツールを活用したワークフローまで、5つのステップで分かりやすく解説します。
なぜGoでウェブスクレイピング?ビジネス視点でのメリット
大量のページをスクレイピングするなら、1秒の差が大きな違いを生みます。Goはまさにこうした大規模処理のために設計された言語。多くの企業がGoを選ぶ理由は以下の通りです:
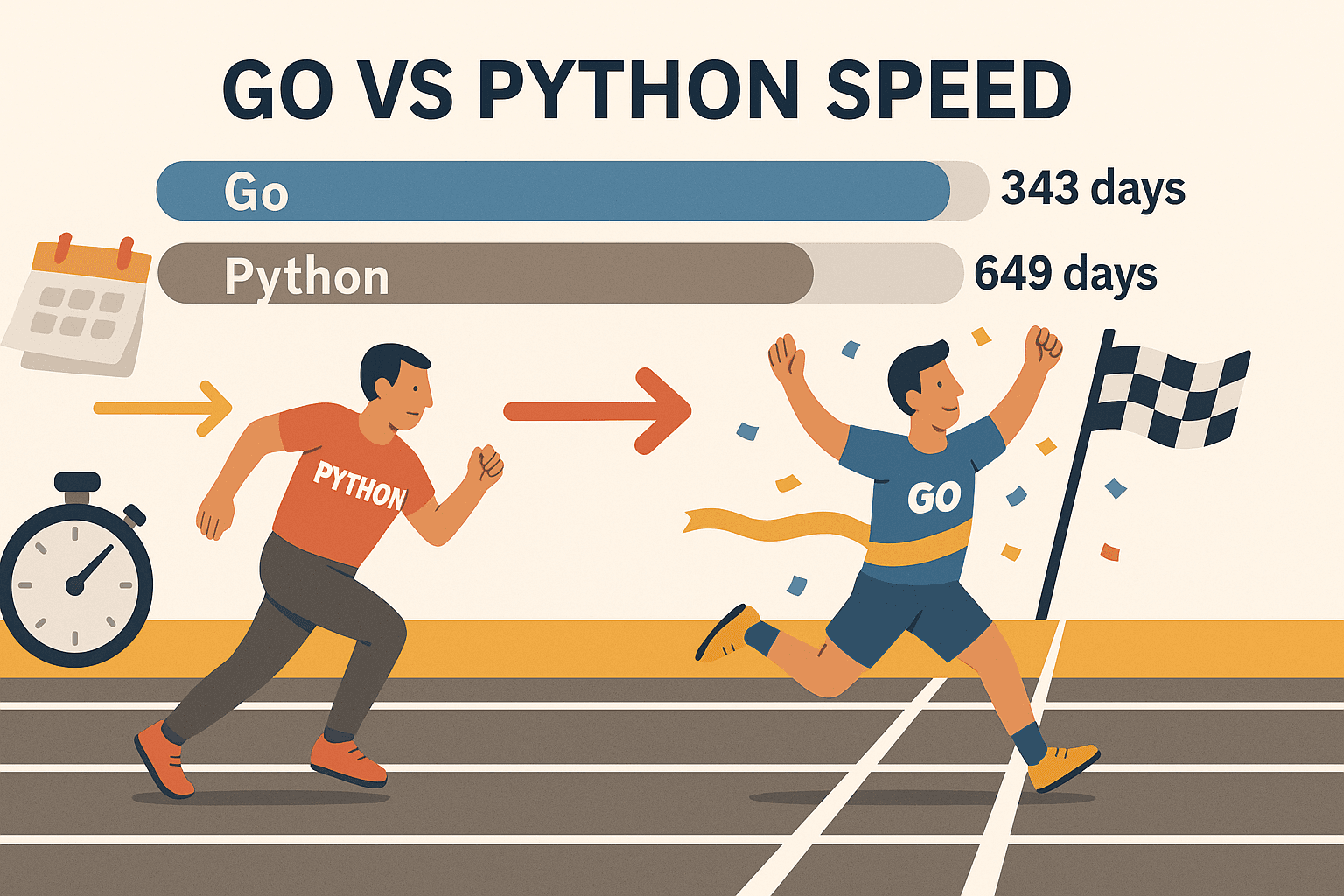
- 圧倒的な並列処理: Goのゴルーチン(軽量スレッド)を使えば、数百ページを同時に処理してもPCが悲鳴を上げません。あるベンチマークでは、Goは、Pythonは同じ量に649日かかりました。まさに次元が違います。
- 高い安定性: 強い型付けと効率的なメモリ管理で、長時間・大規模なクローラーでも安心して運用できます。夜中にスクリプトが落ちていた…なんて心配も減ります。
- ネットワーク機能が充実: HTTPリクエストやHTML解析、JSON処理など、標準ライブラリだけでほとんどの作業が完結。余計なパッケージ探しは不要です。
- 簡単なデプロイ: Goは単一バイナリにコンパイルできるので、どこでも動作。仮想環境や依存関係のトラブルとも無縁です。
- 業界での採用実績: Goは今や(Node.jsを超え)、GoogleやUber、Netflixなど大手も信頼しています。
もちろん、Pythonは手軽なタスクや機械学習用途では今も強力です。でも、速度・スケール・信頼性を重視するならGoが有力な選択肢。CollyやGoqueryと組み合わせれば、さらに強力です。
ステップ1:Go環境のセットアップ
まずはGoの開発環境を整えましょう。手順はとてもシンプルです。
1. Goのインストール
- からOS(Windows/macOS/Linux)に合ったインストーラーをゲット。
- インストーラーの指示に従ってインストール。Linuxならパッケージマネージャーも使えます。
- ターミナルで以下を実行:
1go versiongo version go1.21.0 darwin/amd64のような表示が出ればOK!
トラブルシューティング: goコマンドが見つからない場合は、PATH設定を確認。Linux/macOSなら~/.bash_profileや~/.zshrcにexport PATH=$PATH:/usr/local/go/binを追加しましょう。
2. 新しいGoプロジェクトの作成
- スクレイパー用のディレクトリを作成:
1mkdir my-scraper && cd my-scraper - Goモジュールを初期化:
これで依存管理用の1go mod init github.com/yourname/my-scrapergo.modファイルが作成されます。
3. エディタの選択
- (Go拡張機能付き)が初心者にもおすすめ(補完・Lint・デバッグ対応)。
- JetBrains GoLandは本格派向け。
- Vim/Neovim+GoプラグインもOK。
4. 動作確認
main.goを作成:
1package main
2import "fmt"
3func main() {
4 fmt.Println("Go is installed and working!")
5}実行:
1go run main.goメッセージが表示されれば準備完了!
ステップ2:GoでHTTPリクエストを送る
いよいよウェブページの取得です。Goのnet/httpパッケージを使えば簡単です。
基本のHTTP GET例:
1package main
2import (
3 "fmt"
4 "io"
5 "net/http"
6)
7func main() {
8 resp, err := http.Get("https://example.com")
9 if err != nil {
10 fmt.Println("Error fetching the URL:", err)
11 return
12 }
13 defer resp.Body.Close()
14 body, err := io.ReadAll(resp.Body)
15 if err != nil {
16 fmt.Println("Error reading the response body:", err)
17 return
18 }
19 fmt.Println(string(body))
20}ポイント:
http.Getの後は必ずエラーチェック。defer resp.Body.Close()でリソースリーク防止。io.ReadAllでレスポンス全体を取得。
プロのコツ:
- ユーザーエージェントなどヘッダーを設定したい場合は
http.NewRequestを使う:1req, _ := http.NewRequest("GET", "https://example.com", nil) 2req.Header.Set("User-Agent", "Mozilla/5.0") 3client := &http.Client{} 4resp, err := client.Do(req) resp.StatusCodeも必ず確認(200なら成功、403や404はブロックやページ未存在)。
ステップ3:GoでHTMLを解析しデータを抽出
HTMLを取得したら、次は欲しい情報(商品名や価格、リンクなど)を抜き出します。
Goqueryの登場: jQuery風のセレクタでHTML解析ができるGo用ライブラリです。
Goqueryのインストール:
1go get github.com/PuerkitoBio/goquery例:商品名と価格の抽出
1package main
2import (
3 "fmt"
4 "net/http"
5 "github.com/PuerkitoBio/goquery"
6)
7func main() {
8 resp, err := http.Get("https://example.com/products")
9 if err != nil {
10 panic(err)
11 }
12 defer resp.Body.Close()
13 doc, err := goquery.NewDocumentFromReader(resp.Body)
14 if err != nil {
15 panic(err)
16 }
17 doc.Find("div.product").Each(func(i int, s *goquery.Selection) {
18 name := s.Find("h2").Text()
19 price := s.Find(".price").Text()
20 fmt.Printf("Product %d: %s - %s\n", i+1, name, price)
21 })
22}仕組み:
doc.Find("div.product")で商品ブロックを全て選択。- それぞれの中で
s.Find("h2").Text()で商品名、s.Find(".price").Text()で価格を取得。
正規表現: メールアドレスなど単純なパターン抽出にはGoのregexpも便利ですが、複雑なHTML解析はGoqueryが最適です。
ステップ4:Goの強力ライブラリ(Colly & Gocolly)でスクレイパーを強化
さらに効率化したいなら、が定番。クロールや並列処理、クッキー管理などを自動化し、データ取得に集中できます。
Collyの魅力:
- シンプルなAPI: 欲しい要素ごとにコールバックを登録。
- 並列処理:
colly.Async(true)で大量ページも高速処理。 - 自動クロール: リンク追跡やページネーションも簡単。
- アンチボット対策: ヘッダー設定やユーザーエージェントのローテーション、クッキー管理も可能。
- エラーハンドリング: 失敗時のフックも標準装備。
Collyのインストール:
1go get github.com/gocolly/colly/v2Collyの基本例:
1package main
2import (
3 "fmt"
4 "github.com/gocolly/colly/v2"
5)
6func main() {
7 c := colly.NewCollector(
8 colly.AllowedDomains("example.com"),
9 colly.Async(true),
10 )
11 c.OnHTML(".product-list-item", func(e *colly.HTMLElement) {
12 name := e.ChildText("h2")
13 price := e.ChildText(".price")
14 fmt.Printf("Product: %s - %s\n", name, price)
15 })
16 c.OnRequest(func(r *colly.Request) {
17 r.Headers.Set("User-Agent", "Mozilla/5.0")
18 })
19 c.OnError(func(r *colly.Response, err error) {
20 fmt.Println("Request failed:", r.Request.URL, "->", err)
21 })
22 c.Visit("https://example.com/products")
23 c.Wait()
24}GoqueryとCollyの機能比較
| 機能 | Goquery | Colly |
|---|---|---|
| HTML解析 | あり | あり(内部でGoquery使用) |
| HTTPリクエスト | 手動 | 標準搭載 |
| 並列処理 | 手動(ゴルーチン) | 簡単(Async(true)) |
| クロール/リンク追跡 | 手動 | 自動 |
| アンチボット対策 | 手動 | 標準搭載 |
| エラーハンドリング | 手動 | 標準搭載 |
Collyは本格的なスクレイピングには欠かせない時短ツールです。
ステップ5:Goウェブスクレイピングの現場で役立つテクニック
実際のウェブスクレイピングでは、いろんな壁にぶつかります。主な対策を紹介します:
1. IPブロック対策
- Goの
http.TransportやCollyのプロキシ機能でIPをローテーション。 - リクエスト間にランダムな遅延を入れる。
2. ユーザーエージェント・ヘッダー
- ChromeやFirefoxなど実際のブラウザに近いUser-Agentを設定。
- Accept-Languageなど他のヘッダーも模倣。
3. CAPTCHA対策
- CAPTCHAが出る場合は、アクセス頻度や挙動が目立ちすぎている可能性。
- JavaScriptや画面操作が必要な場合はなどヘッドレスブラウザを活用。
- 強力なアンチボット対策にはCAPTCHA自動解決サービスの導入も検討。
4. ページネーション
- Collyなら「次へ」リンクを自動で辿ることも可能:
1c.OnHTML("a.next", func(e *colly.HTMLElement) { 2 e.Request.Visit(e.Attr("href")) 3})
5. 動的コンテンツ(JavaScript)
- GoのHTTPライブラリはJSを実行できません。Rodやchromedpなどヘッドレスブラウザを使うか、APIエンドポイントを直接叩く方法も。
6. どうしても難しい場合はThunderbitを活用
動的なサイトや、すぐにデータが必要な場合はが便利です。ThunderbitはAI搭載のウェブスクレイパーChrome拡張で、
- AIが自動でフィールドを検出し、「AIで列を提案」ボタンで簡単抽出
- サブページやページネーションも自動対応
- 実際のブラウザ(またはクラウド)上で動作し、JavaScriptや多くのアンチボット対策にも強い
- Excel、Google Sheets、Airtable、Notionへ直接エクスポート可能(ノーコード)
- 定期実行やチームでの自動データ収集もOK
Thunderbitは、ビジネスユーザーや営業チーム、ノーコードで構造化データが欲しい人にぴったり。実際、僕たち自身も現場の課題を解決するために開発しました。
GoとThunderbitの組み合わせで生産性を最大化
実は、GoとThunderbitはどちらか一方を選ぶ必要はありません。両方を組み合わせることで最強のワークフローが実現します。
おすすめの活用例:
- Go(Colly)で大量のURLリストや基本データを一括収集
- そのURLをThunderbitに渡し、詳細な構造化データを抽出(サブページや動的コンテンツ、アンチボット対策も対応)
- ThunderbitからGoogle SheetsやCSVにエクスポート
- 必要に応じてGoでデータの加工・分析・統合
このハイブリッド運用なら、Goのスピードと制御性、Thunderbitの柔軟性とAIの力を両取りできます。
Goウェブスクレイピングの選択肢比較:純正Go vs. Colly vs. Thunderbit
用途に合わせて最適なツールを選ぶための比較表です:
| 観点 | 純正Go(net/http + html) | Go + Colly(ライブラリ) | Thunderbit(AIノーコード) |
|---|---|---|---|
| セットアップ・学習コスト | 高(コーディング必須) | 中(APIが簡単) | 最も簡単(ノーコード・AI主導) |
| 並列処理 | 手動(ゴルーチン) | 標準搭載(Async(true)) | クラウド/ブラウザ並列処理 |
| 動的コンテンツ(JS) | ヘッドレスブラウザが必要 | 一部JS対応、またはRod | フルブラウザでJSも標準対応 |
| アンチボット対策 | 手動(プロキシ・ヘッダー) | 標準機能あり | ほぼ自動、クラウドIP利用 |
| データ構造化 | カスタム実装 | コールバック・構造体で柔軟 | AI提案・自動整形 |
| エクスポート | カスタム(CSV、DB等) | カスタム | Excel、Sheets、Notion、Airtable |
| メンテナンス | 高(頻繁なコード修正) | 中 | 低(AIがサイト変化に自動対応) |
| おすすめ用途 | 開発者・独自パイプライン | 開発者・プロトタイピング | ノーコード・ビジネスユーザー |
プロのコツ: 大規模・カスタム・バックエンド連携にはGo/Colly、手軽さや複雑なフロントエンド対応にはThunderbitが最適です。
まとめ:Goでウェブスクレイピングを始めよう
- Goはウェブスクレイピングの強力な武器—特に速度・並列処理・信頼性が求められる場面で真価を発揮します。
- まずは基本から: Go環境構築、HTTPリクエスト、GoqueryでHTML解析をマスター。
- Collyでパワーアップ: クロールや並列処理、アンチボット対策も簡単。
- 現場の課題も対応: プロキシやヘッダー設定、難しいサイトはヘッドレスブラウザやThunderbitを活用。
- ツールの組み合わせも有効: GoとThunderbitを併用すれば、柔軟かつ効率的なデータ収集が可能です。
ウェブスクレイピングは営業・業務・リサーチの生産性を大きく高める武器。Goと適切なライブラリ、そしてAIの力を活用して、単純作業を自動化し、ビジネスを前進させましょう。
Goウェブスクレイピングのおすすめリソース
さらに深く学びたい人は、以下のリソースも参考にしてみてください:
快適なスクレイピングライフを!データはいつも構造化されて、スクレイパーは爆速、コーヒーは熱々でありますように。
よくある質問(FAQ)
1. なぜPythonやJavaScriptではなくGoでウェブスクレイピングするの?
Goは並列処理・速度・信頼性に優れ、大規模・長時間のスクレイピングに最適です。大量ページを高速に処理したい、コンパイル済みのポータブルなバイナリが欲しい場合に特におすすめです。
2. GoでHTMLを簡単に解析する方法は?
ライブラリを使えば、jQuery風のセレクタでDOMを簡単に操作・データ抽出できます。
3. JavaScriptで描画されるサイトをGoでスクレイピングするには?
やなどのヘッドレスブラウザライブラリを利用しましょう。ノーコードで対応したい場合はを使えば、ブラウザ上でJSも自動処理できます。
4. スクレイピング時にブロックされないコツは?
User-Agentのローテーション、プロキシ利用、リクエスト間の遅延、本物のブラウザ挙動の模倣が有効です。Collyならこれらの対策も簡単、Thunderbitなら多くのアンチボット対策を自動で処理します。
5. GoとThunderbitを組み合わせて使えますか?
もちろん可能です。Goは大規模クロールやバックエンド連携、ThunderbitはAIによる抽出やサブページ対応、ビジネスツールへのエクスポートに最適。開発者もビジネスユーザーも活用できる強力な組み合わせです。
ウェブスクレイピングをさらに極めたい人は、やで最新情報・チュートリアル・AI活用術をチェックしてみてください。