Firecrawlは、AI開発者の世界で最も注目されているウェブスクレイピングAPIの1つです。、Y Combinatorの支援、そしてShopify、Zapier、Appleを含むクライアント一覧を見ると、たしかに勢いがあります。ですが、料金ドキュメント、ユーザーの不満、独立ベンチマーク、実運用のコストモデルを掘り下げると、派手な見出しと実際の体験にはかなり差があります。
このFirecrawlレビューは、単なる機能一覧ではありません。すでに登録していくつかテストスクレイピングを実行し、「実際、規模が大きくなったらいくらかかるのか?」と気になっている方、あるいはそもそもFirecrawlが自分のチームに合うのかを見極めたい方に向けた内容です。ここでは、実際のコスト(多くのレビューが省きがちな二重課金の落とし穴も含めて)、Firecrawlが本当に強いところ、弱いところ(特にボット対策の厳しいサイト)、そしてのようなノーコード選択肢を含めた、まったく別のツールに切り替えるべきタイミングまで解説します。目的はただひとつ、想定外のクレジットカード請求を防ぐことです。
Firecrawlとは何か、誰のためのものか?
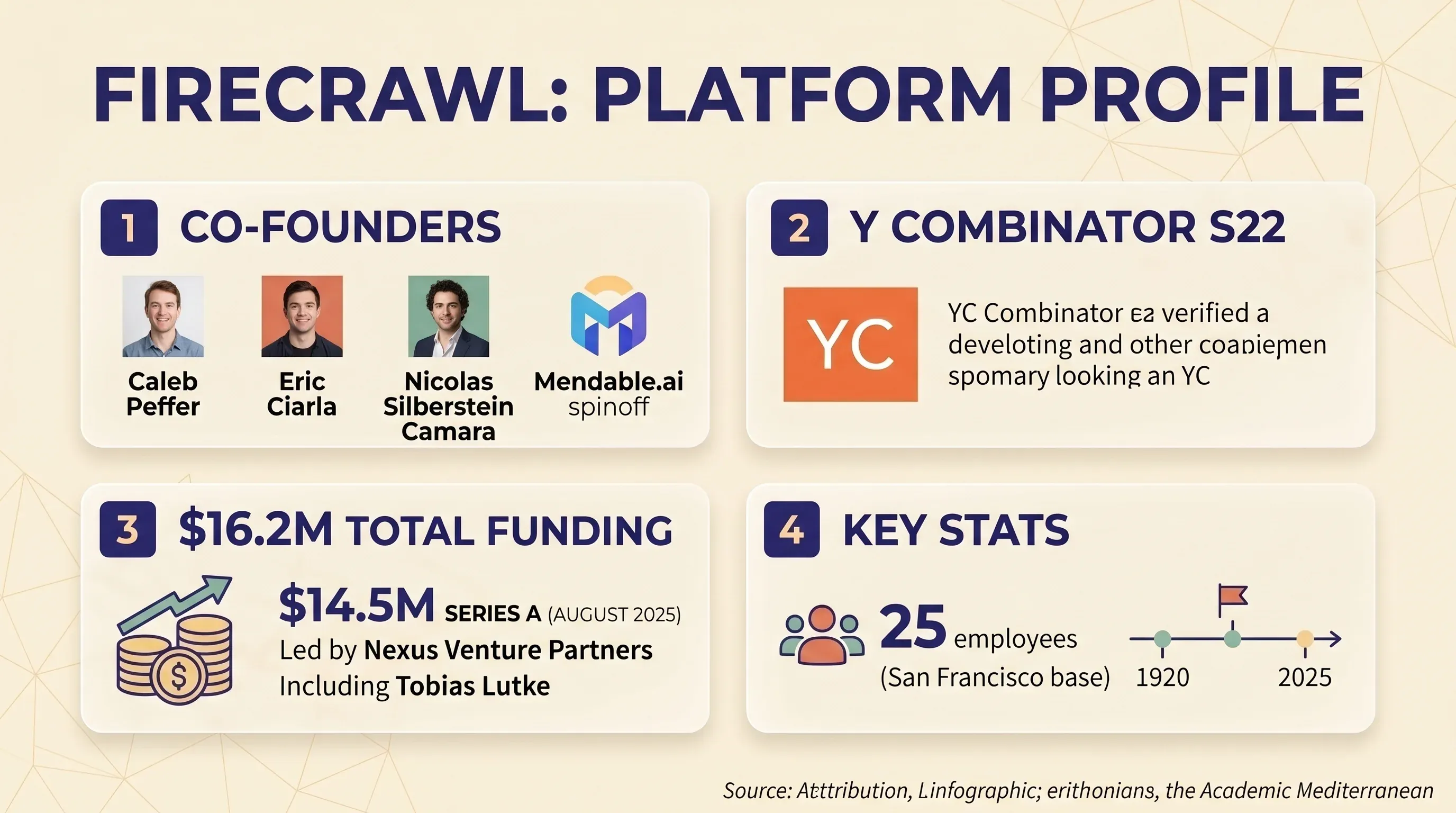
Firecrawlは、APIファーストのウェブスクレイピング/クロール基盤で、WebサイトをきれいなMarkdownまたは構造化JSONに変換します。主に、AIやLLMアプリケーションを開発するエンジニア向けに設計されており、RAGパイプライン、チャットボットのナレッジベース、AIエージェントのワークフローなどを想定しています。同社はMendable.aiのスピンオフとして、Caleb Peffer、Eric Ciarla、Nicolas Silberstein Camaraによって設立されました。を経て、2025年8月にはNexus Venture Partners主導でを調達し、Shopify CEOのTobias Lutkeも参加しています。累計調達額は$16.2M。サンフランシスコを拠点に、チームは25人です。
Firecrawlには4つの基本モードに加え、最近追加された2つの機能があります。
| モード | できること |
|---|---|
| Scrape | 1つのURLをMarkdown、JSON、またはスクリーンショットに変換 |
| Crawl | 1つのURLとその配下のページをすべて巡回 |
| Map | Webサイト上のすべてのURLを数秒で発見(最大10万URL) |
| Search | ページ本文を丸ごと取得しながらWeb検索 |
| Extract | プロンプトやスキーマを使ったAI駆動の構造化抽出 |
| Agent(Research Preview) | URLを指定せずに自律的にWeb調査を実行 |
最初にはっきり言っておきます。Firecrawlは開発者向けツールです。API呼び出し、コーディングの知識、技術的なセットアップが必要になります。コードを書かずにWebサイトからデータを取りたいビジネスユーザー向けには作られていません(代替案は後ほど紹介します)。ただし、AIアプリを作る開発チームにとっては、最小限のインフラ負担で、きれいでLLMにすぐ使えるWebデータを得られるという点が大きな魅力です。
Firecrawlレビュー:料金プランをひと目で確認
表面上、Firecrawlの料金体系はシンプルに見えます。料金ページ()に掲載されている内容は以下の通りです。
| プラン | 月額料金 | クレジット/月 | 同時実行数 | 年額料金 |
|---|---|---|---|---|
| Free | $0 | 500(買い切りで、月次ではない) | 2 | — |
| Hobby | $19/月 | 3,000 | 10 | 年払いで$16/月 |
| Standard | $99/月 | 100,000 | 50 | 年払いで$83/月 |
| Growth | $399/月 | 500,000 | 100 | 年払いで$333/月 |
| Scale | $749/月 | 1,000,000 | 1,000 | 年払いで$599/月 |
すぐに気づく点がいくつかあります。Freeプランの500クレジットは月次ではなく買い切りです。ここを見落として、1回のテストで使い切ってしまうユーザーは少なくありません。そして各プラン自体は分かりやすく見えても、実際の費用はどの機能を使うかで大きく変わります。掲載価格はあくまで出発点。本当の請求額は? それが次のセクションのテーマです。
Firecrawlの本当のコスト:利用ケース別のクレジット計算
Firecrawlの実ユーザーの悩みで、最も大きいのが料金です。"めちゃくちゃ高い"、"自分の利用量なら$99/月プランが必要"、"法外に高い" といった声が、Hacker NewsやRedditのスレッドに実際に上がっています。その理由は、多くのFirecrawlレビューが完全に無視している二重課金システムにあります。
落とし穴はこうです。FirecrawlのクレジットプランでカバーされるのはScrape、Crawl、Map、Searchです。しかし、Firecrawlの主力機能の1つであるAI駆動の構造化抽出Extractは、まったく別のトークン制サブスクリプションで動きます。
| Extractプラン | 月額料金 | トークン/年 | トークン/月(概算) |
|---|---|---|---|
| Starter | $89/月 | 18M | 約1.5M |
| Standard | $189/月 | 48M | 約4M |
| Growth | $389/月 | 108M | 約9M |
| Pro | $719/月 | 192M | 約16M |
そのため、Standardクレジットプラン($99/月)を使っていて、さらに抽出も必要なスタートアップは、クレジット倍率がかかる前でも**$99 + $89 = 最低$188/月**になります。ここが、想定外の請求を生む二重課金の落とし穴です。
多くのユーザーが見落とす隠れたクレジット倍率
「1ページ1クレジット」という説明は、実態を正確に表していません。実際の機能別コストはこうです。
| 機能 | クレジット消費 | 実質倍率 |
|---|---|---|
| 基本Scrape/Crawl | 1クレジット/ページ | 1倍 |
| Search | 10件の結果で2クレジット | 結果セットあたり2倍 |
| JSON抽出(Scrape経由) | +4クレジット/ページ | 合計5倍 |
| Enhanced Mode | +4クレジット/ページ | 合計5倍 |
| JSON + Enhanced Mode | +8クレジット/ページ | 合計9倍 |
| ブラウザインタラクション | 2クレジット/分 | 可変 |
| Agentモード(spark-1-mini) | 動的、約100~500/クエリ | 100~500倍 |
| Agentモード(spark-1-pro) | 動的、約200~1,500+/クエリ | 200~1,500倍 |
さらに重要な点がいくつかあります。クレジットは翌月に繰り越されません。失敗したリクエストでもクレジットは消費されます(不安定なサイトでは20~30%が無駄になる、という報告があります)。Agentモードには事前のコスト見積もりがありません。maxCreditsパラメータは設定できますが、結局はかなりの अनुमान頼みです。Freeプランの500クレジットは、抽出を有効にするとおおよそ56ページ分に相当します。これはトライアルというより、ちょっとした試食です。
ユーザープロフィール別の月額コスト例
| ユーザープロフィール | 月間ページ数 | 使用機能 | 推定クレジット消費 | 推定月額コスト |
|---|---|---|---|---|
| 趣味・サイドプロジェクト | 500 | 基本スクレイプ + クロール | 約500クレジット | $19/月(Hobbyプラン) |
| 趣味 + JSON抽出 | 500 | Scrape + Extract | 約2,500クレジット + Extract $89 | $108/月 |
| スタートアップ / AIアプリ | 5,000 | Scrape + Extract + Search | 約30,000クレジット + Extract $89 | $188/月(Standard + Extract) |
| エンタープライズ / データパイプライン | 50,000 | フルスタック + Agent | 約250,000~450,000クレジット + Extract $389 | $788~$1,138/月 |
Hacker Newsのある開発者は、毎月$190を払っていたにもかかわらず、この体験を「高いし、未完成に感じた」と表現し、Firecrawlを2,700行の独自Elixirコードに置き換えました。かなり強いシグナルです。
自前運用のFirecrawl:本当に無料な部分とクラウド限定の部分
「Firecrawlを自前でホストすれば無料で使えるの?」という質問は、よく見かけます。答えは、半分はYesですが、たぶん期待している形ではありません。
Firecrawlにはオープンソースのコア(AGPL-3.0ライセンス)がありますが、重要な機能のいくつかはクラウド限定です。内訳は次の通りです。
| 機能 | 自前ホスト(無料) | クラウド(有料) |
|---|---|---|
| 基本Scrape/Crawl to Markdown | ✅ | ✅ |
| Map(URL発見) | ✅ | ✅ |
| LLM駆動のExtract | ⚠️(自分のLLMキーが必要) | ✅(管理済み) |
| Agentモード | ❌ | ✅ |
| Browser Sandbox | ❌ | ✅ |
| Actions/Interact | ❌ | ✅ |
| ボット対策 / プロキシローテーション(Fire-engine) | ❌(固定IPを使用) | ✅ |
| バッチ処理 | ❌ | ✅ |
| ダッシュボード / 分析 | ❌ | ✅ |
| 管理されたインフラ | ❌(Docker + PostgreSQL + Redisが必要) | ✅ |
Firecrawl独自のボット対策システムであるFire-engineは、。自前ホストではボット対策機能は一切使えず、独自のプロキシを用意する必要があります。
それでも自前ホストが有効なケース
自前ホストが向いているのは、基本的な「クロールしてMarkdown化する」パイプラインが欲しくて、5以上のサービスを含むDocker Composeの運用に慣れている開発者です。最低要件は、4GB RAM、2 CPUコア、さらに抽出用のLLM APIキー($0.01~$0.10/ページ)、必要に応じてプロキシサービスです。すべて込みの自前ホスト運用コストは**$90~$340/月**で、中程度の利用量ならクラウドプランとほぼ同等になることが多いです。
ユーザーが自前ホスト版に不満を感じる理由
実際のユーザーの声を見ると、かなり厳しい印象です。RedditやGitHubの複数スレッドで、機能がクラウド限定に移っていくにつれて自前ホスト版の価値が落ちていく様子が語られています。あるユーザーは率直に、「会社が全ユーザーを今すぐ有料に誘導して、自前ホストを使い物にならなくしようとしている」と要約しました。コミュニティはこの問題に対処するため、firecrawl-simple というフォークまで作っています。自前ホストを長期的な無料解決策として期待しているなら、期待値は調整した方がいいでしょう。試すための出発点としては優秀ですが、規模が大きくなったときに有料クラウド製品の代わりにはなりません。
Firecrawlのボット対策性能:効くサイト、効かないサイト
ここは、「実際に自分がスクレイピングしたいサイトでFirecrawlは使えるのか?」と気になっている人にとって最重要のセクションです。
短く言えば、答えはサイト側の防御レベル次第です。
ベンチマークの数値
は、ボット対策が非常に厳しい15サイトに対して10個のWebスクレイピングAPIを独自テストしました。Firecrawlの結果は次の通りです。
| 提供元 | 成功率(2 req/s) | 成功率(10 req/s) |
|---|---|---|
| Zyte | 93.14% | 89.2% |
| ScrapFly | 91.8% | 88.5% |
| Bright Data | 88.7% | 84.9% |
| Firecrawl | 33.69% | 26.69% |
Firecrawlは、保護されたサイトでは10社中でした。平均7.92秒という高速応答は、部分的には「失敗したらすぐ返す」戦略によるものです。リトライを重ねるのではなく、早めに失敗を返しています。
によるより広い継続ベンチマークでは、Firecrawlは総合成功率65.4%(業界平均59.5%を上回る)を記録しており、簡単な対象には強い一方、保護の厳しい対象には弱いことが分かります。
サイト難易度別:簡単・中程度・難しい対象
| 難易度 | 例 | Firecrawl成功率 | 推奨 |
|---|---|---|---|
| 簡単 | ブログ、ドキュメント、公開SaaSページ | 85~98% | 安心してFirecrawlを使える |
| 中程度 | 商品カタログ、基本的なボット対策があるニュースサイト、Etsy、Realtor.com | 53~65% | 慎重にテスト、失敗を想定 |
| 難しい | Amazon、LinkedIn、Instagram、Cloudflareが強いページ | 0~33% | Firecrawlに頼らない。専用のボット対策プロバイダーを使う |
Cloudflareで保護されたサイトが、最も多く失敗報告が上がるポイントです。複数のGitHub issueでこの問題が記録されており、IPローテーションを使っていてもCloudflareのフィンガープリント検出にFirecrawlが弾かれるケースがあります。特に自前ホスト版は、Fire-engineのプロキシ基盤がないため、最も影響を受けます。
Firecrawlで足りないときはどうするか
保護の厳しいサイトでは、ScrapFlyやBright Dataのような専用プロキシサービス、あるいはステルス設定を組み込んだヘッドレスブラウザ系のツールに切り替えるのが一般的です。プロキシローテーションや成功率の計算に時間をかけたくないビジネスユーザーなら、のようなノーコードツールが裏側でボット対策を処理してくれます。あなたはクリックするだけで、データが手に入ります。
Firecrawlの長所と短所:率直なまとめ
Firecrawlが得意なこと
- きれいでLLM向けのMarkdown出力 — 見出し構造も整っていて、常に高品質。これがFirecrawlの最大の強みです。
- クラウド利用ならインフラ負担ゼロ — ブラウザ設定、プロキシ管理、ヘッドレスブラウザの構成が不要。
- 幅広いフレームワーク連携 — LangChain、LlamaIndex、CrewAI、AutoGPT、Dify、、Flowise(AIパイプライン向けに7以上の連携)。
- Mapエンドポイントによる高速なURL発見 — サイトマップ全体を2~3秒で取得。
- を持つオープンソースコア — 透明性があり、コミュニティ貢献も活発。
- MCPサーバー対応 と FIRE-1モデルによるAIエージェントワークフロー。
- をうたう、JavaScript中心のページ(React、Vue、AngularのSPA)への対応力。
Firecrawlの弱いところ
- 二重料金体系(クレジット + 別途Extractサブスク)が、誰も想定しない請求の驚きを生む。
- クレジット倍率により、実コストは見た目の価格の5~9倍に膨らむ。
- ボット対策性能は最下位 — Proxywayベンチマークではで、トップの93.14%に大きく差をつけられている。
- Agentモードは、事前コスト見積もりがなく、クレジット消費が予測しづらい。
- 失敗したリクエストでもクレジットを消費 — 不安定なサイトでは20~30%の無駄が発生。
- 自前ホスト版にはAgent、Browser Sandbox、Fire-engineのボット対策、ダッシュボードがない。
- ネイティブなCAPTCHA解決がない — Bright DataやZyteと比べて大きな欠点。
- 非技術者には使いにくい — コーディングとAPIの知識が必要。
- Freeプランの500クレジットは買い切りで、月次ではないため、本格的な検証には足りない。
開発者ツールの枠を超えて:Firecrawlレビューでほとんど触れられないノーコード代替案
私が読んだFirecrawlレビューは、Crawl4AI、Scrapy、Playwright、Apifyのような他の開発者向けツールとの比較ばかりです。開発者ならそれで理にかなっています。ただ、Webスクレイピングの解決策を探している人の大半は非開発者です。営業チームが見込み客リストを作り、EC運用が競合価格を監視し、マーケターがコンテンツデータを集め、不動産エージェントが物件情報を追う——そういう人たちです。
そこにこそ、埋めるべきギャップがあります。
Firecrawl代替ツール比較表
| ツール | 向いている人 | コードは必要? | LLM向け出力 | 開始価格 |
|---|---|---|---|---|
| Firecrawl | AIアプリを作る開発者 | はい(API) | ✅ Markdown/JSON | $19/月 |
| Crawl4AI | 無料・OSSを重視する開発者 | はい(Python) | ✅ Markdown | 無料 |
| Apify | 大規模運用とマーケットプレイスが必要な開発者 | はい(SDK) | ⚠️ 設定次第 | $39/月 |
| Thunderbit | ビジネスユーザー(ノーコード) | いいえ(Chrome拡張) | ✅ 構造化データ | 無料プランあり |
| ScrapingBee | プロキシが必要な開発者 | はい(API) | ❌ 生HTML | $49/月 |
| Bright Data | エンタープライズのデータチーム | はい(API/SDK) | ⚠️ 設定次第 | $500+/月 |
非技術チームにThunderbitが向いている理由
私はThunderbitチームで働いているので、その点は正直にお伝えします。Thunderbitがこの比較に入るのは、Firecrawlとは別の課題を、別の利用者向けに、しかもコード不要で解決するからです。
Thunderbitの作業フローは2クリックです。を開いて「AI Suggest Fields」をクリックし、次に「Scrape」をクリックするだけ。AIがページを読み取り、適切な列を提案し、構造化データをテーブルに抽出します。APIキーもセレクタもコーディングも不要です。Excel、Google Sheets、Airtable、Notionへ無料でエクスポートできます。
ビジネスユーザー向けの主な差別化ポイントは以下です。
- サブページ強化 — 詳細ページに入り、追加項目を自動で取得
- レイアウト変更に適応するAI — サイトリニューアル時のメンテナンス不要
- データラベリングと翻訳機能を内蔵 — 多言語データセットで便利
- 人気サイト向けの即利用テンプレート — Amazon、Zillow、LinkedInなど
API代替を求める開発者向けには、Thunderbitもを提供しており、Firecrawlの二重クレジット/トークン制よりシンプルな料金体系です。LLMパイプライン開発者にとってFirecrawlの完全な代替になるわけではありませんが、営業、EC、マーケティング、オペレーションの各チームが、コードを書かずに構造化データを必要とするなら、より速く、より安く進められます。
自作か購入か:Firecrawlが元を取れるケース、取れないケース
「自分でWebスクレイパーを書こうかと思ったけど……Firecrawlよりは単純だし、少なくとも安いはず。」こう考えるユーザーは少なくありません。主観ではなく、ここでは構造化した判断軸を示します。
判断フレームワーク表
| 要素 | 自作(Scrapy/Playwright) | Firecrawl Cloudを購入 | Thunderbitを使う(ノーコード) |
|---|---|---|---|
| 導入時間 | 10~40時間以上 | 約30分 | 約5分 |
| 継続メンテナンス | 高い(セレクタが壊れる) | ほぼゼロ(管理済み) | ゼロ(AIが適応) |
| ボット対策 | 手動(プロキシ、ヘッダー、リトライ) | 内蔵(部分的。保護サイトには弱い) | 内蔵(ブラウザ+クラウドモード) |
| 月1,000ページ時のコスト | $50~150(サーバー + プロキシ) | $19~$108(機能次第) | $0~$15 |
| 月5万ページ時のコスト | $500~$1,500(インフラ) | $399~$1,138 | $39~$249 |
| LLM向け出力 | 独自実装が必要 | 内蔵(Markdown/JSON) | 構造化テーブル(エクスポート可) |
| 向いている用途 | 完全制御、ニッチサイト、DevOpsチーム | AI/LLM開発、RAGパイプライン | 営業、EC、マーケティング、オペレーション |
多くの組織では、自作は3年間でAPIより。自作の方が安くなる分岐点は、およそ月1,000万ページ以上。そこまでの規模に実際に到達するチームはごくわずかです。
正直な結論:どの道が自分に合うか?
Firecrawlが元を取れるのはこんなとき:
- チームがすでにPython/JSで開発していて、LLM/RAGパイプライン向けにきれいなMarkdownが必要
- 対象サイトの多くが未保護、または保護が軽い
- DevOpsの手間なしで管理されたインフラを使いたい
- 利用量が月約5万ページ未満に収まる
Firecrawlが元を取りにくいのはこんなとき:
- 開発チームなしで抽出を行うビジネスユーザー → Thunderbitの方が簡単で速い
- Amazon、LinkedIn、Cloudflareが強いサイトなど、保護の厳しい対象を狙う → Bright DataかZyte
- 大規模でも予測可能な料金が欲しい → クレジット倍率のせいで費用が読みにくい
- フル機能の自前ホストを望む → Agent、Browser Sandbox、Fire-engineはクラウド限定
自作が向いているのは次の場合だけ:
- 専任のDevOps体制がある
- 規模が非常に大きい(月1,000万ページ以上)
- ニッチでクセのあるサイトへの対応を完全に制御したい
- セレクタの継続保守に抵抗がない
Firecrawlレビュー:比較表でまとめる
全体を並べて見てみましょう。
| ツール | 種類 | 向いている用途 | コード必要 | ボット対策 | LLM向け出力 | 自前ホスト可 | 開始価格 |
|---|---|---|---|---|---|---|---|
| Firecrawl | API | AI/LLM開発者 | はい | 保護サイトに弱い | ✅ Markdown/JSON | ✅(限定的) | $19/月 |
| Crawl4AI | Pythonライブラリ | OSS重視の開発者 | はい | なし(自前対応) | ✅ Markdown | ✅ | 無料 |
| Apify | クラウド基盤 | 大規模運用 + マーケットプレイス | はい | 中程度 | ⚠️ 設定次第 | ✅ | $39/月 |
| Thunderbit | Chrome拡張 + API | ビジネスユーザー、ノーコード | いいえ | 内蔵 | ✅ 構造化データ | ❌ | 無料プラン |
| ScrapingBee | API | プロキシ重視の開発者 | はい | 強い | ❌ 生HTML | ❌ | $49/月 |
| Bright Data | API + プロキシネットワーク | エンタープライズのデータチーム | はい | 最強(約99.9%) | ⚠️ 設定次第 | ❌ | $500+/月 |
最終評価:Firecrawlは買う価値があるのか?
Firecrawlは、特定の用途には十分優れたツールです。つまり、LLMアプリ、RAGパイプライン、AIエージェントを作る開発チームが、中程度の規模で、APIベースのワークフローに慣れている場合です。Markdown出力の品質は本当にトップクラスで、LangChain、LlamaIndex、CrewAIといったフレームワーク連携も成熟しています。チームがすでにPythonやJavaScriptで開発していて、対象サイトのボット対策がそこまで厳しくないなら、Firecrawlはかなりの実装時間を節約してくれます。
とはいえ、弱点も本物です。二重料金体系(クレジット + 別途Extractサブスク)は、予想外の請求を生みます。保護サイトでのでは、Amazon、LinkedIn、Cloudflareが強い対象に頼ることはできません。自前ホスト版は、無料代替としては機能不足が多すぎます。そして、営業、EC、マーケティングのような非技術ユーザーには、そもそも向いていません。
まずはFirecrawlの無料500クレジットで、出力品質が自分のパイプラインに合うか試してみてください。ただし、有料プランに進む前に、上の計算式で月額の実コストを見積もることをおすすめします。コードを書かずにWebサイトから構造化データだけ欲しいビジネスユーザーなら、まずはから始める方がよいでしょう。数時間ではなく、数分でデータ抽出を始められます。は今すぐ試せますし、でチームの規模に合うプランも確認できます。動画で見たい方は、に手順付きデモがあります。
FAQ
Firecrawlは1ページあたりいくらかかりますか?
基本のScrapeまたはCrawlは1ページ1クレジットです。JSON抽出を使うとさらに4クレジット/ページ追加され、合計5になります。Enhanced Modeもさらに4クレジット追加で、合計最大9です。Searchは10件の結果ごとに2クレジット、Agentモードは1クエリあたり100~1,500以上のクレジットを消費することがあります。さらに、Extract機能には月$89からの別トークンサブスクリプションが必要です。実際的な見積もりは、上のコスト計算セクションをご覧ください。
Firecrawlを無料で自前ホストできますか?
はい、オープンソースのコア(AGPL-3.0)は無料で自前ホストできます。ただし、Agentモード、Browser Sandbox、ボット対策/プロキシローテーション(Fire-engineはクローズドソース)、バッチ処理、管理ダッシュボードは使えません。抽出には自分のLLMキーが必要で、Docker、PostgreSQL、Redisも自分で運用する必要があります。自前ホストは基本的なクロールしてMarkdown化する用途には向いていますが、本番規模のクラウド製品の代替にはなりません。
FirecrawlはAmazon、LinkedIn、その他の保護サイトのスクレイピングに向いていますか?
では、Firecrawlの保護サイトでの成功率は33.69%で、10社中最下位でした。保護のないページ(ブログ、ドキュメント、SaaSサイトでは85~98%)には強いものの、大手ECやソーシャルプラットフォームでは信頼性が高くありません。こうした対象には、Bright DataやZyteのような専用ボット対策プロバイダー、あるいは裏側でボット対策を処理するThunderbitのようなノーコードツールを検討してください。
非技術ユーザーに最適なFirecrawl代替は何ですか?
が最有力のノーコード代替です。Chrome拡張機能で、「AI Suggest Fields」をクリックしてから「Scrape」を押すだけ。API呼び出しも、コーディングも、セレクタ設定も不要です。データはExcel、Google Sheets、Airtable、Notionに無料でエクスポートできます。開発者なしで構造化Webデータが欲しい、営業、EC、マーケティング、オペレーションの各チーム向けに作られています。
Firecrawlには無料トライアルがありますか?
Firecrawlは、クレジットカード不要でを提供しています。これは少数ページで基本的なScrape/Crawl機能を試すには十分ですが、本番利用には足りません。特に抽出を有効にすると、1ページあたり5クレジット消費するためです。Freeプランのクレジットは毎月更新されません。
詳しく見る