ちょっとした裏話をしましょう。インターネットは世界最大級の図書館みたいなものですが、その本の多くは“糊付け”されていて、簡単にはページをめくれません。日々、ビジネスオーナーやマーケター、営業担当の方々と話していると、「ウェブページにはお宝情報が眠っている」とよく聞きます。たとえば商品スペック、競合の価格、顧客レビュー、連絡先など。でも、そのテキストを取り出すのは意外と骨が折れる作業です。SaaSや自動化の現場で長年働いてきた私も、“コピペ地獄”や“Python自作チャレンジ”の苦労話を何度も見てきました。でも今は、AIウェブスクレイパーや高機能なブラウザ拡張のおかげで、ウェブサイト テキスト抽出は驚くほど手軽になっています。
このガイドでは、シンプルなコピペからのようなAI搭載の本格的な方法まで、実践的な手順をすべて紹介します(Thunderbitは私たちのプロダクトですが、良い点もイマイチな点も正直にお伝えします)。エクセルが得意な人も、プログラミングができる人も、「もうウェブページを読むのに疲れた…」という人も、自分に合ったやり方がきっと見つかります。さあ、デジタルの本棚を開いて、必要なテキストを手に入れましょう。
ウェブサイトからテキストを抽出するとは?
「ウェブサイトからテキストを抽出する」とは、ウェブページ上に表示されている(時には見えない)情報を、自分が使いやすい形で取り出すことを指します。たとえば、スプレッドシートやデータベース、Wordファイルなどにまとめるイメージです。ただし、ウェブ上のテキストにはいくつか種類があります:
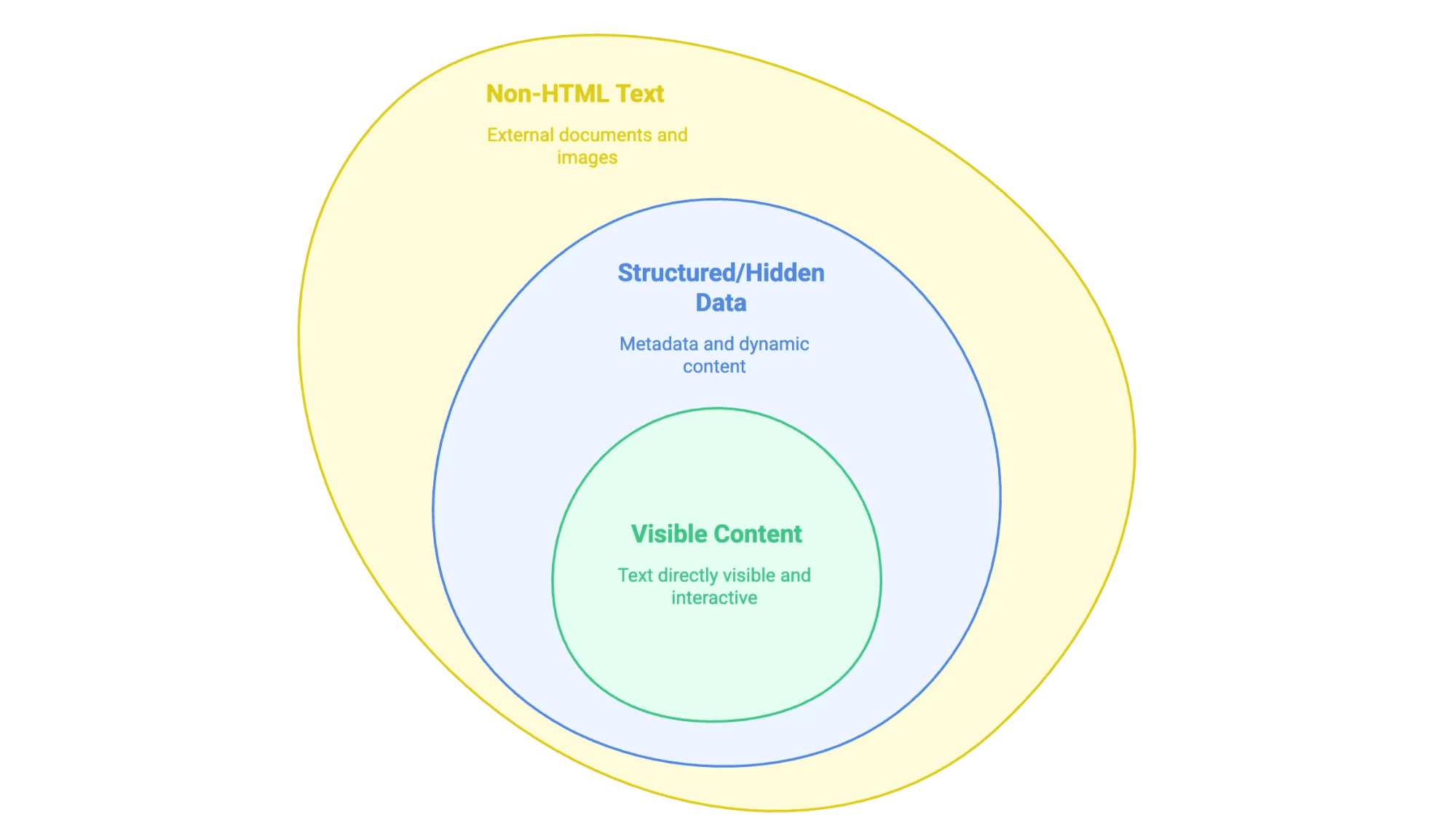
- 見えるコンテンツ:マウスで選択できる本文、見出し、リスト、テーブル、商品説明、ブログ記事など。
- 構造化データや隠れた情報:
<meta>タグのメタデータ、JSON-LDスクリプト、JavaScriptで後から表示される情報など。 - 非HTMLテキスト:PDFやWordファイル、画像内のテキスト(スキャンした契約書やインフォグラフィックなど)も含まれます。
どのタイプのテキストを抽出したいかによって、最適な方法が変わってきます。
なぜウェブサイトからテキストを抽出するのか?ビジネスでの活用例
正直、趣味でウェブサイト テキスト抽出をする人はほとんどいません。ビジネスで使うからこそ、その価値が際立ちます。ウェブスクレイパーの市場規模はし、今後も拡大が見込まれています。その理由は以下の通りです:
| チーム | 活用例 | メリット |
|---|---|---|
| 営業 | ディレクトリからリードや連絡先を抽出 | 見込み客リスト作成が高速化・高品質に |
| マーケティング | 競合ブログやSEOデータの抽出 | コンテンツギャップ分析・トレンド把握 |
| オペレーション | ECサイトの価格監視 | 動的な価格設定・在庫管理 |
| 不動産 | 物件情報の一括取得 | 市場分析・リード獲得 |
| サポート | レビューやQ&Aの収集 | 顧客の声分析・早期課題発見 |
実際の事例もいくつかご紹介します:

- リード獲得:ある飲食業向け企業は、。
- 競合モニタリング:John Lewisのような小売業者は、スクレイピングで得た価格データを活用し。
- SEO分析:メタタグやキーワードを抽出し、。
さらに、AIウェブスクレイパーのようなツールを使うことで、従来よりもできるケースも増えています。
手作業でのテキスト抽出:コピペの基本
まずは一番シンプルな方法から。ちょっとしたデータを取り出すだけなら、特別なツールは不要です。
手動でテキストを抽出する方法
- コピー&ペースト:ページを開き、必要なテキストを選択してCtrl+C(または右クリック→コピー)。そのままドキュメントやスプレッドシートに貼り付けます。
- ページを保存:ブラウザの「ファイル」→「名前を付けてページを保存」。HTML形式やテキスト形式で保存できます。
- PDFとして印刷:ブラウザの印刷機能で「PDFとして保存」。PDFリーダーで開いてテキストをコピー、または「テキストとして保存」機能を使います。
- 開発者ツール:右クリック→「検証」またはF12キーでDevToolsを開き、HTMLソースやメタタグ、隠れたJSONなどを確認・コピーできます。
手作業の限界
手動抽出は単発なら問題ありませんが、量が増えると大変です。。実際、インターンが何日もかけてテーブルを1行ずつコピペしているのを見たことがありますが、誰もやりたがらない作業です。
ブラウザ拡張機能やオンラインツールでウェブサイトのテキストを抽出
もう少し効率的にやりたい方には、ブラウザ拡張機能やオンラインツールがおすすめです。プログラミング不要で、直感的に操作できます。
こうしたツールを使うメリット

- 手作業より圧倒的に速い
- プログラミング知識が不要
- テーブルやリスト、場合によってはファイルも対応
- ExcelやGoogleスプレッドシート、CSVなどにエクスポート可能
代表的なツールをいくつかご紹介します。
Thunderbit:AIウェブスクレイパーで素早く正確にテキスト抽出
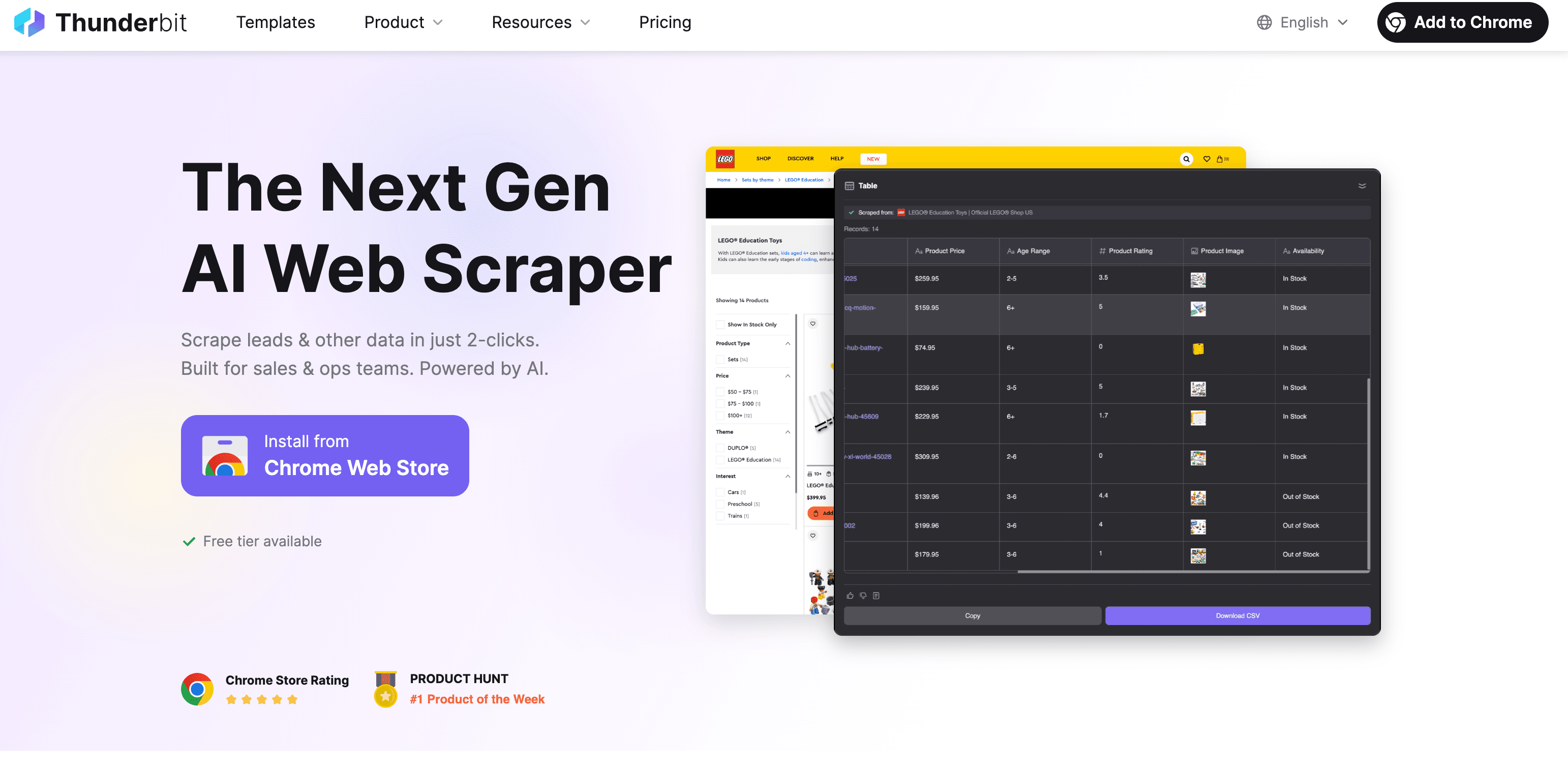
ちょっと自慢になりますが、は「ウェブからテキストを抜き出す作業を、まるで出前を頼むくらい簡単に」を目指して開発しました。使い方は以下の通りです:
Thunderbitでテキストを抽出する手順
- Chrome拡張機能をインストール:します。
- 抽出したいウェブページを開く
- 「AIフィールド提案」をクリック:ThunderbitのAIがページを解析し、商品名や価格、説明など抽出すべき項目を自動で提案します。
- 内容を確認・調整:提案された項目を編集したり、自分で追加も可能です。
- 「スクレイピング」を実行:必要に応じてサブページやページ送りにも自動対応。
- エクスポート:Excel、Googleスプレッドシート、Airtable、Notion、CSV/JSON形式でデータをダウンロード。エクスポートに追加料金はかかりません。
Thunderbitの特長
- AIによるフィールド自動提案:セレクタやコードの知識は不要。AIが重要な情報を自動で見つけます。
- サブページやページ送りも自動対応:カテゴリ内の全商品ページなども自動で巡回。
- PDFや画像、ドキュメントからも抽出:PDFマニュアルや商品画像からも、内蔵OCRでテキストを抽出可能。
- 多言語対応:34言語に対応(クリンゴン語はまだですが、開発中です)。
- データエクスポート無料:データの取り出しに追加料金はありません。
- 活用例:商品説明、連絡先、ブログ記事、リードリストなど幅広く対応。
実際の使い方はでも詳しく解説しています。たとえばなどをご覧ください。
その他のブラウザ拡張機能・オンラインツール
他にも便利なツールがいくつかあります:
- Web Scraper ():無料で使えるポイント&クリック型。やや学習コストはありますが、技術に強い方にはおすすめ。サイトマップやセレクタの設定が必要。ページ送り対応、PDFや画像は非対応。。
- CopyTables:HTMLテーブルをそのままクリップボードやExcelにコピーできる超シンプルなツール。1ページずつ、テーブル限定ですが、手早く使いたい時に便利。。
- ScraperAPI ():開発者向け。URLを送るとHTMLを返してくれるAPI(プロキシやブロック回避も対応)。ただし、テキストの解析は自分で行う必要があります。。
どのツールを使うべき?
- Thunderbit:スピード重視、AIサポート、PDFや画像も含めて多様な形式に対応したい場合。
- Web Scraper:細かくカスタマイズしたい、技術に自信がある場合。
- CopyTables:テーブルだけを素早く取り出したい時。
- ScraperAPI:自作のスクレイパーを開発したいエンジニア向け。
自動化によるウェブスクレイピング:プログラミングでのテキスト抽出
開発者の方や、エンジニアが身近にいる場合は、自作のスクレイパーで柔軟に対応できます。基本的な流れは以下の通りです:
- HTTPリクエスト送信:Pythonの
requestsなどでページを取得。 - HTML解析:
BeautifulSoupやlxml、Scrapyで必要なテキストを抽出。 - 抽出&エクスポート:テキストを取り出し、整形してCSVやJSON、データベースに保存。
サンプル:Python + Beautiful Soup
1import requests
2from bs4 import BeautifulSoup
3url = "<http://quotes.toscrape.com>"
4response = requests.get(url)
5soup = BeautifulSoup(response.text, 'html.parser')
6quotes = [q.get_text() for q in soup.find_all("span", class_="text")]
7for qt in quotes:
8 print(qt)メリット・デメリット
- メリット:柔軟性が高く、どんなサイトやデータ形式にも対応可能。自社システムとの連携も容易。
- デメリット:プログラミング知識が必要。メンテナンスやアンチボット対策も必要。
こんな場合におすすめ
- 数千〜数百万ページ規模の大量データを扱う場合
- ログインや複雑なフォームなど、特殊なサイト構造の場合
- スクレイピングを自社アプリや業務フローに組み込みたい場合
非HTML形式からのテキスト抽出:PDF・Word・画像など
ウェブサイトにはHTML以外にも、PDFやWord、画像内のテキストなど多様なデータが含まれています。これらを抽出する方法もご紹介します:
- テキスト型PDF:Adobe Acrobatや
PDFMiner、PyPDF2などのライブラリでテキスト抽出。 - スキャンPDF:Tesseractや、などOCRツールを利用。
Word/Excelファイル
- Word:
python-docxで.docxファイルを読み込み。 - Excel:
openpyxlやpandasで.xlsxファイルを処理。
画像
- OCRツール:Tesseract(オープンソース)やクラウドサービスで高精度抽出。画像は150〜300DPI程度が理想。
Thunderbitのアプローチ
「画像・ドキュメントパーサー」機能を使えば、PDFや画像、ドキュメントをアップロードまたはリンクするだけで、AIがテキストを抽出し、テーブルがあれば自動でカラムも提案します。複数のツールを使い分ける必要はありません。
各方法の比較:あなたに最適なテキスト抽出ソリューションは?
どの方法が自分に合っているか、簡単に比較できる表を用意しました:
| 方法 | 使いやすさ | 拡張性 | 技術スキル | 対応データ形式 | おすすめ用途 |
|---|---|---|---|---|---|
| 手動(コピペ) | 非常に簡単 | 低 | 不要 | 表示テキストのみ | 単発・小規模作業 |
| ブラウザ拡張/ツール | 簡単〜普通 | 中 | 低〜中 | HTML・一部テーブル | 非技術者・中規模作業 |
| AIツール(Thunderbit) | 非常に簡単 | 高 | 不要 | HTML・PDF・画像など | ビジネス利用・多様なデータ |
| プログラミング | 難しい | 非常に高い | 高 | ほぼ全て(ライブラリ次第) | 開発者・大規模案件 |
| 非HTML抽出(OCR) | 普通 | 低〜中 | 中 | PDF・画像・ドキュメント | ファイルや画像が中心の場合 |
ビジネス用途で「速さ・柔軟性・手軽さ」を重視するなら、ThunderbitのようなAIツールが最適です。逆に、完全なカスタマイズや大規模な自動化が必要な場合は、プログラミングによる自作も選択肢となります。
まとめ:今すぐウェブサイトからテキスト抽出を始めよう
- ウェブ上には価値あるテキストデータが溢れていますが、簡単に取り出せるとは限りません。
- 手作業は小規模ならOKですが、規模が大きくなると非効率です。
- ブラウザ拡張やAIウェブスクレイパー(など)を使えば、誰でも素早く正確にテキスト抽出が可能。コーディング不要です。
- PDFや画像など非HTMLデータには、OCRやドキュメント解析機能付きのツールを選びましょう。
- チームのスキルやプロジェクト規模、必要なデータ形式に合わせて最適な方法を選んでください。
もうコピペ作業に追われる時代は終わりです。適切なツールを使えば、ウェブデータの抽出は自動化でき、もっと価値ある仕事に時間を使えるようになります。手作業のストレスから解放されて、効率的な未来を一緒に目指しましょう!
よくある質問
Q1: どんなウェブサイトでもデータを抽出できますか?
A1: すべてのサイトで可能とは限りません。スクレイピングを禁止しているサイトや、技術的にブロックされる場合もあるので、必ず利用規約を確認しましょう。
Q2: AI搭載ウェブスクレイパーの精度は?
A2: ThunderbitのようなAI搭載ツールは高精度ですが、複雑なページや動的なサイトでは微調整が必要な場合もあります。
Q3: ウェブスクレイピングツールの利用にプログラミングスキルは必要ですか?
A3: いいえ。Thunderbitや他のブラウザ拡張機能は非技術者向けに設計されており、コーディング不要です。
Q4: PDFや画像からどんなデータを抽出できますか?
A4: OCRツールを使えば、スキャンPDFや画像からテキストやテーブル、隠れた情報まで抽出でき、データ活用の幅が広がります。
さらに詳しく知りたい方へ