
エグゼクティブサマリー
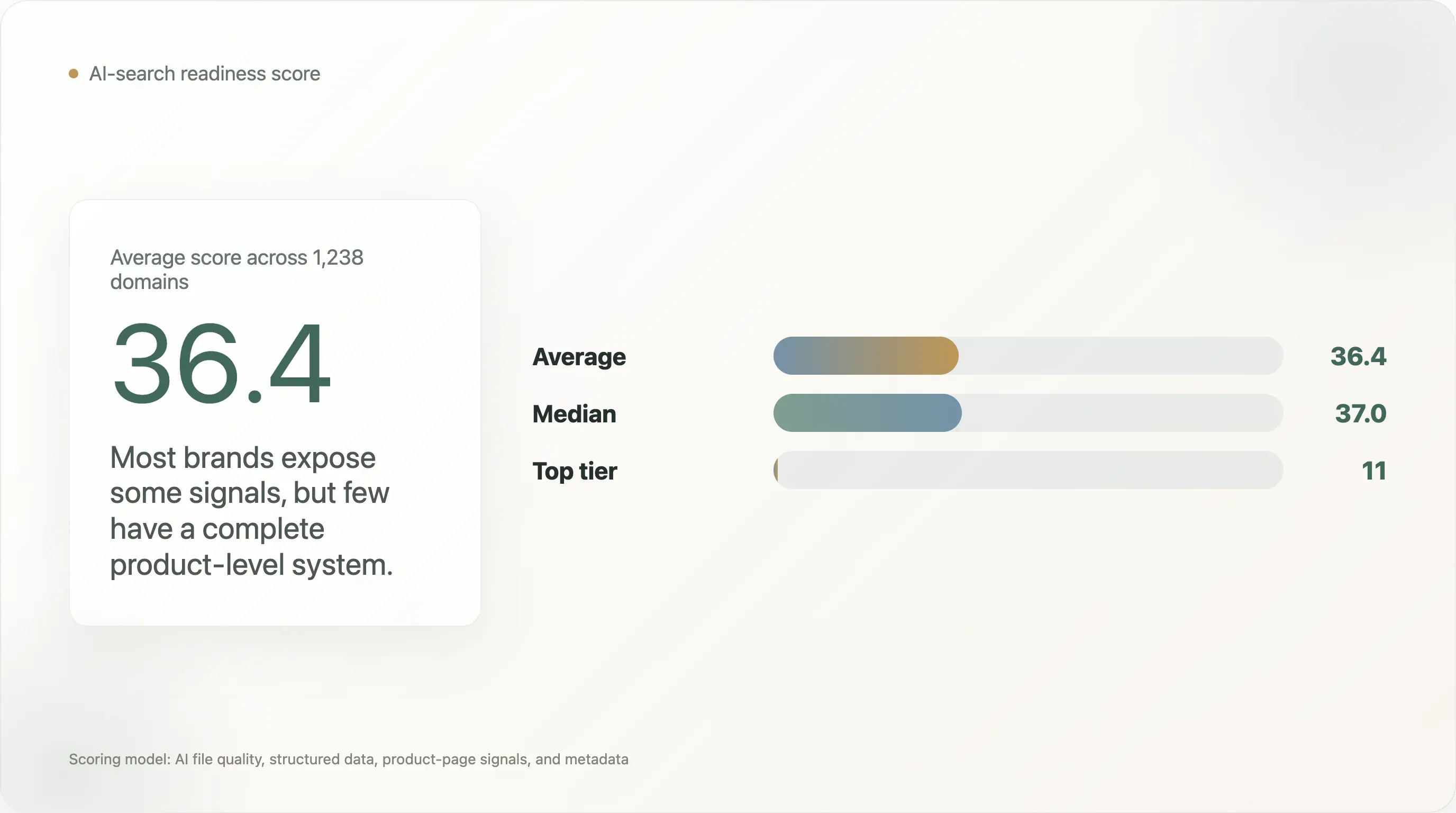
この調査では、1,238のDTCドメインを対象に、AI検索対応を4層で評価しました。評価対象は、AIファイルの品質、一般的な構造化データ、商品ページの構造化シグナル、そしてメタデータです。平均スコアは100点中36.4点、中央値は37.0点でした。このスコアモデルでai_readyティアに到達したのは、わずか11ドメインです。
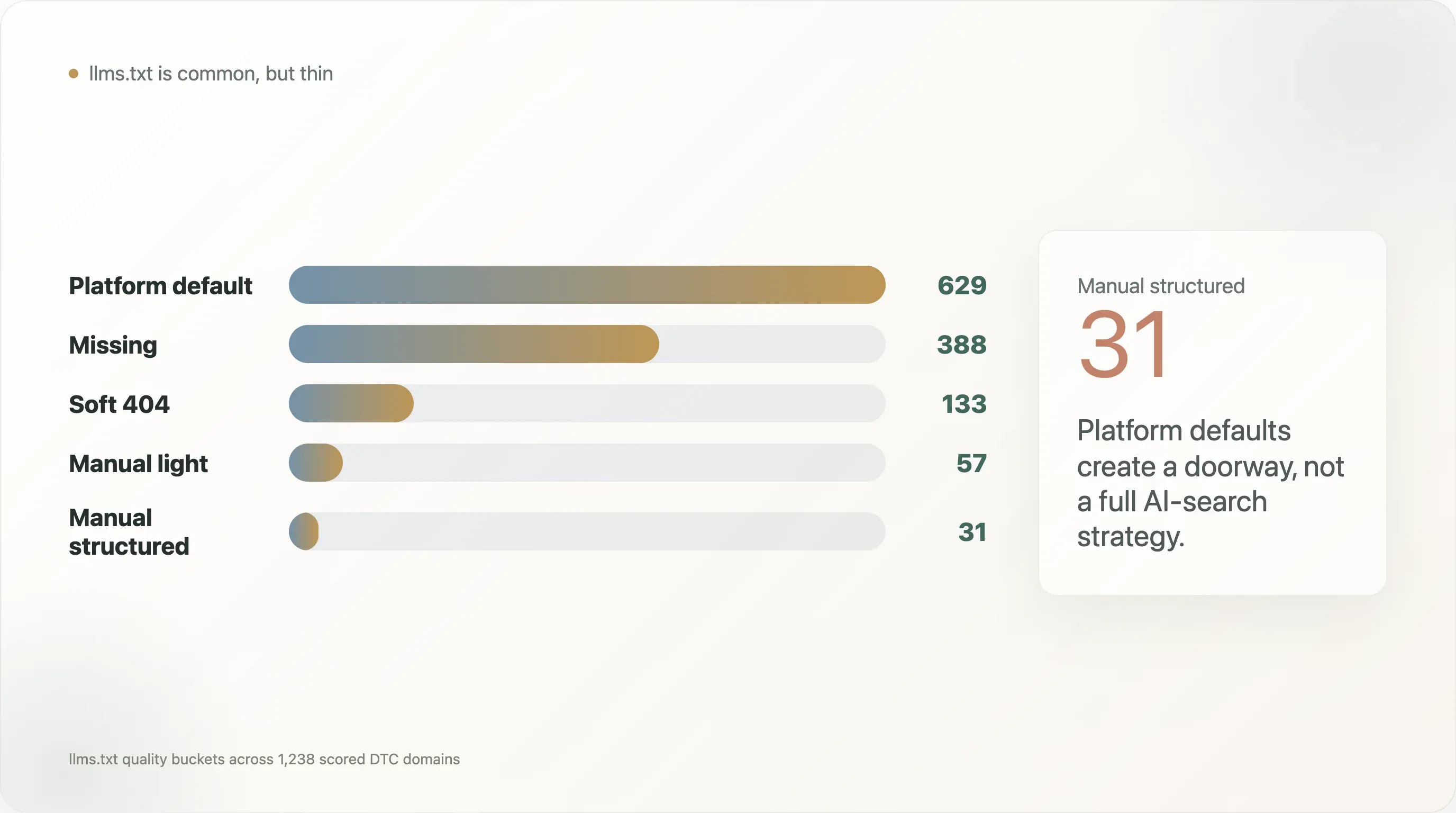
最大の発見は、表面的な発見可能性と商品レベルの理解との間にある大きなギャップです。llms.txtの品質バケットで最も多かったのはplatform_defaultで、629ドメインでした。つまり、多くのブランドは利用中のプラットフォームが自動生成した、基本的なAI可読ファイルを持っているということです。しかし、ホームページにProduct schemaがあるのはスコア対象ドメインの0.9%だけでした。さらに、商品ページのProduct schemaは、商品ページの取得を試みた対象のうち39.2%にとどまります。商品ページの価格シグナルは48.1%、レビューまたは評価シグナルは**43.5%**でした。
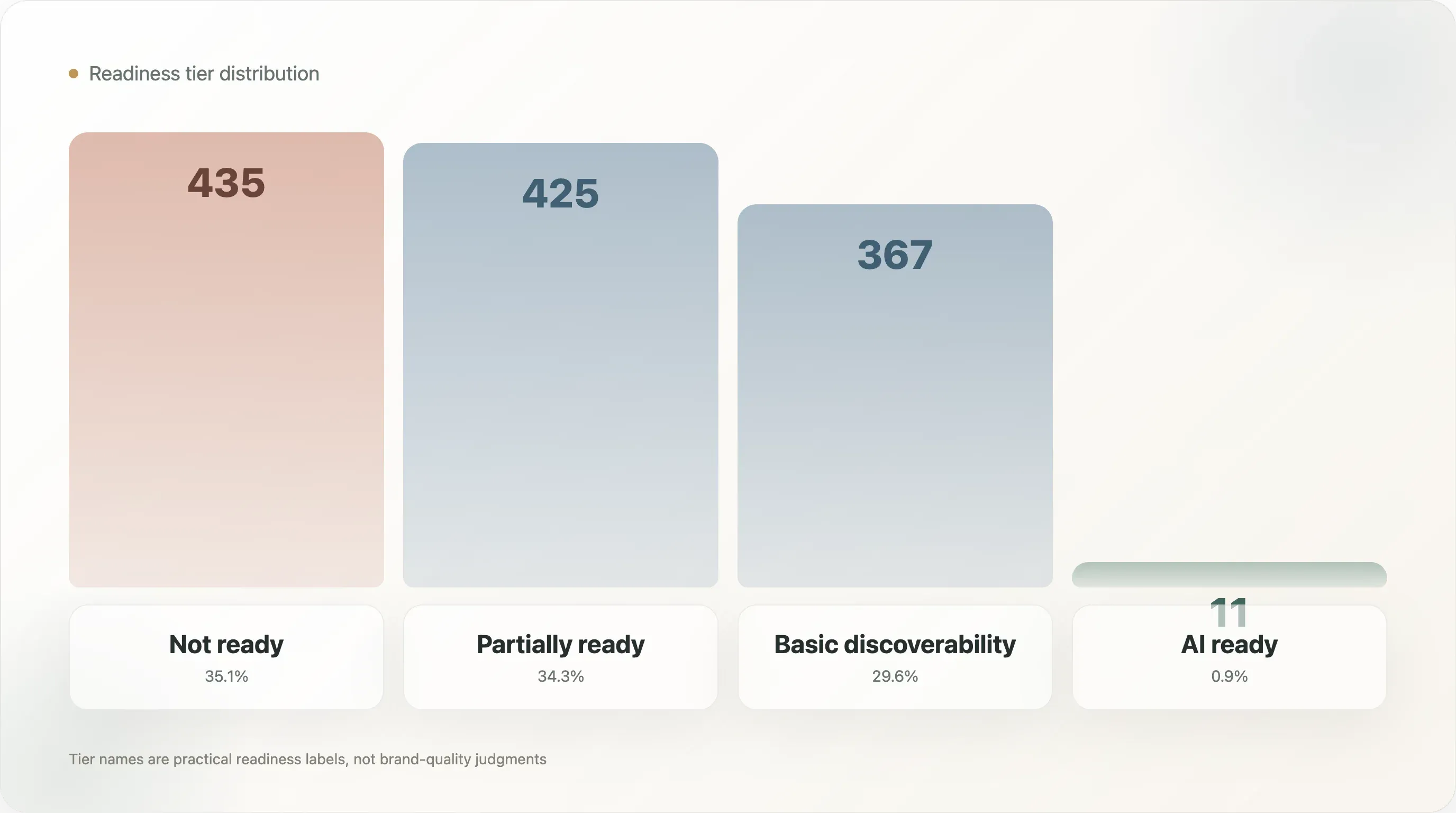
ティア分布を見ると、市場がまだかなり初期段階にあることが分かります。
| AI対応ティア | ドメイン数 |
|---|---|
| 未対応 | 435 |
| 部分的に対応 | 425 |
| 基本的な発見可能性 | 367 |
| AI対応 | 11 |
この分布が有用なのは、しばしば混同されがちな3つの概念を切り分けられるからです。ブランドは見つけやすいかもしれません。メタデータを持っているかもしれません。llms.txtもあるかもしれません。でも、見つけやすいことと、商品レベルで理解できることは同じではありません。
llms.txtの品質分布を見ると、その違いがさらに明確になります。
| llms.txtの品質バケット | ドメイン数 |
|---|---|
| プラットフォーム標準 | 629 |
| 欠如 | 388 |
| ソフト404 | 133 |
| 手動・軽量 | 57 |
| 手動・構造化 | 31 |
したがって、このレポートで最も伝わりやすい切り口は「DTCブランドはllms.txtを持っている」というものではありません。それでは浅すぎます。より良い切り口は、プラットフォームの標準機能によってAIの初期的な発見可能性は生まれた一方で、ほとんどのDTCブランドは、AIショッピングや回答エンジンに必要な商品レベルの構造化データ層を構築していない、というものです。
良い事例を見ると、どのような状態がより高い対応レベルなのかが分かります。ai_readyティアには、Mokobara、Magic Mind、Le Petit Ballon、Maine Lobster Now、Yo Mama's Foods、La Maison Convertible、Unbloat、NuRange Coffee、Three Ships Beauty、Manukoraといったブランドが含まれます。これらの例が重要なのは、AI対応が特定のカテゴリや特定のブランド形態に限定されないことを示しているからです。食品、美容、ウェルネス、家具、アパレル、専門商材のECでも、機械可読な商品レイヤーは改善できます。
もっとも共有されやすい発見
-
DTCのAI対応スコアの平均は、わずか36.4/100です。
-
1,238件の対象ドメインのうち、
ai_readyティアに到達したのは11件だけでした。 -
llms.txtは一般的ですが、その多くはプラットフォーム自動生成です。 最も多い品質バケットは
platform_defaultで、629ドメインでした。 -
手動で構造化されたllms.txtは稀です。 このバケットに入るのは31ドメインだけでした。
-
ホームページのProduct schemaはほとんど見られません。 対象ドメインのわずか0.9%にしかありませんでした。
-
商品ページのProduct schemaは改善されているものの、まだ不十分です。 商品ページの取得を試みた対象のうち、39.2%にしか存在しませんでした。
-
AIショッピング対応には、クローラーへのアクセスだけでなく商品情報が必要です。 価格、オファー、レビュー、在庫、Product schemaのシグナルは、薄いファイル単体よりも重要です。
1. AI検索対応がSEOの基本と違う理由
従来のSEOでは、ページがクロールされ、インデックスされ、順位が付き、クリックされるかを見ます。AI検索では別の層が加わります。つまり、システムがブランド、商品、オファー、価格、レビュー、在庫、ポリシー、そしてエンティティ同士の関係を、質問に答えたり商品を提案したりできる程度に理解できるかどうか、です。
この違いはDTCにとって重要です。というのも、ECページには、人間には簡単でも機械には扱いにくい情報が詰まっているからです。購入者は商品ページを見れば、商品名、価格、サイズ、定期購入オプション、割引、レビュー、在庫状況、返品ポリシーを理解できます。しかしクローラーやAIエージェントは、そうした事実が一貫した形で表現されている必要があります。
メタデータは役立ちます。Open Graphも役立ちます。canonicalタグも役立ちます。llms.txtは、クローラーが重要なコンテンツを見つける助けになるかもしれません。ですが、本当の試金石は商品レベルの構造です。AIショッピングアシスタントが、たんぱく質パウダー、スキンケア製品、キャンドル、ドレス、コーヒーの定期購入を5つ比較するなら、必要なのは構造化された事実です。その事実がなければ、ブランドは見えていても、確実には理解されません。
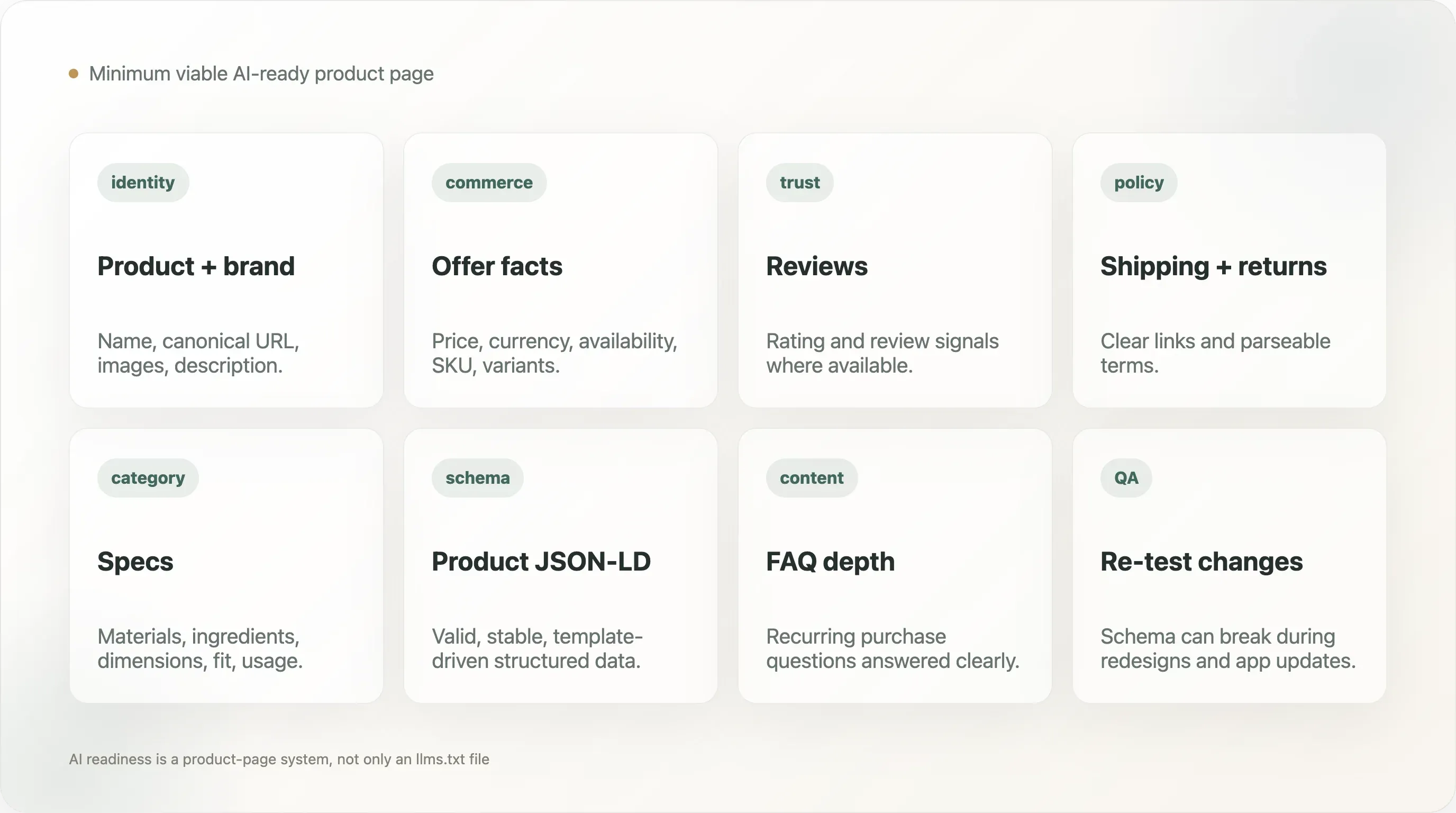
このレポートでは、対応状況を4つの層に分けています。
- AIファイル層: llms.txtが存在するか、また欠如、ソフト404、プラットフォーム標準、手動・軽量、手動・構造化のどれに当たるか。
- 一般的な構造化データ層: JSON-LD、Organization、WebSite、BreadcrumbList、Product schema。
- 商品ページ層: Product schema、オファーまたは価格シグナル、レビューまたは評価シグナル、在庫シグナル。
- メタデータ層: canonical、meta description、Open Graph画像、Twitterカード、hreflangなどの機械可読な文脈。
この階層モデルが重要なのは、浅い結論を防げるからです。llms.txtがあっても商品情報がないブランドは、見た目ほど対応していません。逆に、llms.txtがなくても商品ページのschemaが充実していれば、ファイル層だけで見た印象よりも機械にとっては理解しやすいかもしれません。
2. llms.txtの実態: 主にプラットフォームが作る薄い層
llms.txtの監査では、次の5つの品質バケットが確認されました。
| 品質バケット | ドメイン数 | 解釈 |
|---|---|---|
| プラットフォーム標準 | 629 | 通常は薄いが有効な、標準的なプラットフォーム生成ファイル |
| 欠如 | 388 | 利用可能なファイルが見つからない |
| ソフト404 | 133 | 誤解を招く、または実質的に役に立たない応答 |
| 手動・軽量 | 57 | 人手で作成された、またはカスタムのファイルだが、構造は限定的 |
| 手動・構造化 | 31 | 見出し、リンク、商品またはポリシー用語を含む、より充実した手動ファイル |
これがこのレポートで最も重要なニュアンスです。表面的には、プラットフォーム標準のファイルが多いため、llms.txtの普及はかなり進んでいるように見えます。しかし、プラットフォーム標準は、慎重に設計されたAI検索戦略と同じではありません。多くの場合、単なる導線レイヤーにすぎません。
とはいえ、プラットフォーム標準のファイルが無価値というわけではありません。クローラーが重要なパスを見つける助けになる可能性がありますし、プラットフォーム側の判断がいかに早く市場を動かせるかも示しています。ブランドチームがAI検索の運用を話し合う前に、プラットフォームは数百のストアに機械可読な新しいファイルを提供できるのです。
しかし、手動・構造化バケットはずっと小規模で、31ドメインしかありません。監査対象には、Dermalogica、Ad Hoc Atelier、DKNY、そしてMagic Mind、Le Petit Ballon、Maine Lobster Now、Yo Mama's Foods、Three Ships Beautyのようなai_ready事例に見られる手動・構造化ファイルが含まれています。これらは、デフォルトファイルを超えるとはどういうことかを示す、非常に参考になる事例です。リンクが増え、見出しが増え、商品用語が増え、ポリシー用語が増え、意図的な構造が加わります。
ソフト404のバケットも重要です。ソフト404とは、リクエストには何らかの応答が返るものの、実際には役立つllms.txtファイルではない状態を指します。こうした状態は、単純な監査を誤らせることがあります。AI検索対応では、存在確認だけでは不十分です。品質の確認が必要です。
3. 本当のギャップは商品レベルの構造にある
データの中で最も大きいギャップは、Product schemaです。
ホームページのProduct schemaは、対象ドメインの0.9%にしかありません。商品ページのProduct schemaは、商品ページの取得を試みた対象のうち39.2%にあります。商品ページの価格シグナルは48.1%、レビューまたは評価シグナルは**43.5%**です。
この数字は明確なストーリーを示しています。ECストアを持っていても、基本的な商品情報が一貫して機械可読になっているとは限りません。
これは、AI検索やAIショッピングが明快さを重視する可能性が高いからです。商品ページがProduct schema、オファー、価格、在庫、レビューのシグナル、ポリシーへのリンクを明示していれば、機械はより信頼できる事実を得られます。もしそれらの情報がJavaScript、ばらばらのテンプレート、画像、動的ウィジェットに埋もれていれば、機械は誤解したり、無視したりするかもしれません。
対応ギャップは、順位だけの問題ではありません。表現の問題です。AIシステムが商品カテゴリを要約し、選択肢を比較し、「こんな人におすすめ」を答えたり、買い物の提案を生成したりするとき、より整った商品情報を持つブランドの方が、正確に取り込まれやすくなります。
ai_readyグループの好例が、それを示しています。
- Mokobaraは、出力中で最も高い83点でした。
- Magic Mind、Le Petit Ballon、Maine Lobster Nowはいずれも81点でした。
- Yo Mama's Foodsは80点でした。
- La Maison Convertible、Unbloat、Vinocheepo、NuRange Coffeeは79点でした。
- Three Ships Beautyは77点でした。
- Manukoraは75点でした。
これらの例は、複数カテゴリにまたがっています。AI対応は美容業界だけの話でも、テック業界だけの話でもありません。食品、ウェルネス、家具、アパレル、専門商材など、AIにおすすめや比較、説明を求めるあらゆるカテゴリに関係します。
4. AI対応ティア: 多くのブランドはまだ基準線を下回る
ティア分布は次のとおりです。
| ティア | ドメイン数 | サンプルに占める割合 |
|---|---|---|
| 未対応 | 435 | 35.1% |
| 部分的に対応 | 425 | 34.3% |
| 基本的な発見可能性 | 367 | 29.6% |
| AI対応 | 11 | 0.9% |
この名称は意図的に実務的です。Not readyはブランドが悪いという意味ではありません。このモデルで使う公開シグナルからは、AI検索対応が十分に見えないという意味です。Partially readyは、いくつかの要素はあるものの、重要な層が欠けている状態を指します。Basic discoverabilityは、機械にとって見つけやすくはなっているが、商品レベルの完全性はまだ不足している状態です。AI readyは、ファイル品質、構造化データ、商品情報、メタデータの組み合わせがより強いことを示します。
最上位ティアに到達したのは、11ドメインだけでした。それが見出しになるのは確かですが、より役立つのは中間層の形です。サンプルは、未対応、部分的に対応、基本的な発見可能性の3層にほぼ均等に分かれています。市場は空白ではなく、移行期にあります。多くのブランドは何らかのシグナルを持っていますが、完全なシステムを持つブランドは少数です。
これは短期的な機会を生みます。AI検索対応はまだ初期段階なので、比較的実務的な作業で平均以上から強い状態へ移行できます。llms.txtの改善、schemaの検証、商品情報の公開、メタデータの整理、商品ページを機械が解析しやすくすることです。
5. カテゴリ傾向: 美容とアパレルが先行しているが、完成しているカテゴリはない
カテゴリ分類は厳密なものではなく、あくまで方向性を示すものです。それでも、カテゴリ表には有益なパターンがあります。
| カテゴリ | サンプル数 | 平均AI対応スコア | 手動または構造化llms | 商品ページschema | 商品ページschema率 |
|---|---|---|---|---|---|
| 美容・スキンケア | 98 | 46.2 | 3 | 56 | 57.1% |
| アパレル・フットウェア | 149 | 45.7 | 6 | 79 | 53.0% |
| ジュエリー・アクセサリー | 34 | 44.5 | 0 | 20 | 58.8% |
| ペット | 15 | 43.5 | 0 | 8 | 53.3% |
| ベビー・キッズ | 27 | 42.6 | 1 | 15 | 55.6% |
| 食品・飲料 | 118 | 42.5 | 5 | 58 | 49.2% |
| ホーム・家具 | 48 | 42.3 | 0 | 23 | 47.9% |
| ヘルス・ウェルネス | 58 | 40.7 | 6 | 27 | 46.6% |
| アウトドア・スポーツ | 49 | 39.8 | 1 | 23 | 46.9% |
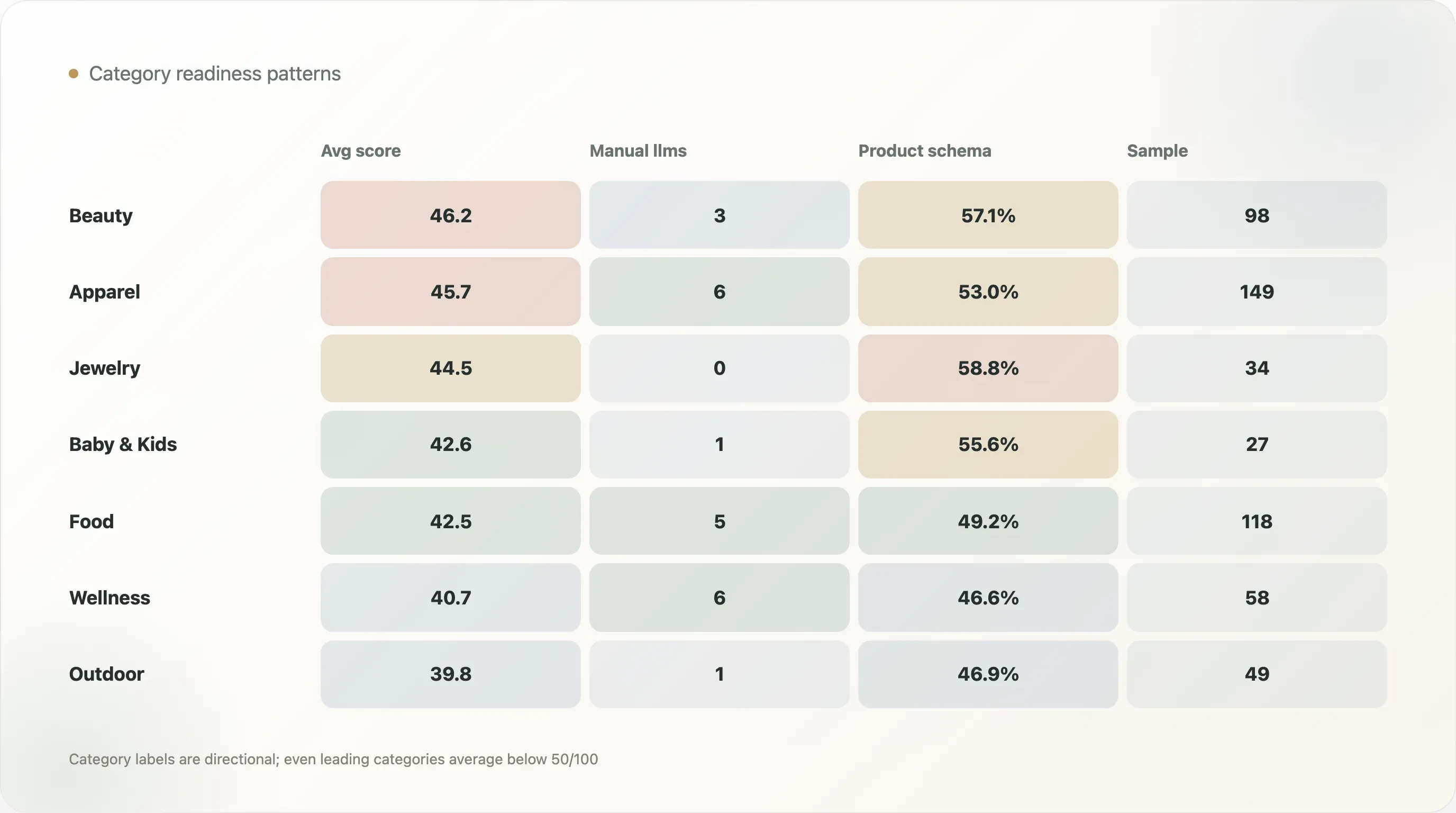
美容・スキンケアは、平均AI対応スコアが46.2で最も高く、アパレル・フットウェアが45.7で続きます。これらのカテゴリは、ECテンプレートが整っていることが多く、豊富な商品カタログ、レビュー、バリエーション、ビジュアル素材、コンテンツ需要を抱えています。そのため、構造化された商品対応の恩恵を受けやすい傾向があります。
ジュエリー・アクセサリーは商品ページschema率が**58.8%**と高い一方で、カテゴリ表では手動または構造化されたllms.txtの検出がありません。これは、対応が階層的に見る必要があることを示しています。あるカテゴリは商品schemaに強くても、AIファイル品質が弱い場合があるのです。
食品・飲料には、Maine Lobster Now、Yo Mama's Foods、NuRange Coffee、Manukoraなど、強い好例が含まれます。食品・飲料は、原材料、栄養、1回分の量、定期購入、原産地、配送、保存方法、レビュー、在庫など、明確な事実が特に重要なカテゴリだからです。AIシステムがそれらを正確に表現するには、サイト側がきれいな形で情報を出している必要があります。
ヘルス・ウェルネスは、表中で手動または構造化llms率が10.3%と主要カテゴリ中で最も高い一方、平均スコアは40.7です。これは、このカテゴリの一部ブランドがAI可読ファイルの導入を積極的に試している一方で、商品ページ構造にはまだ改善余地があることを示しています。信頼と教育の負担が大きいウェルネス領域では、構造化された事実への投資を最も積極的に進めるべきです。
完成しているカテゴリはありません。先行しているカテゴリですら、平均は50/100を下回っています。そのため、カテゴリ別のAI対応コンテンツは、SEOライターやコンサルタントにとって大きな機会になります。
6. 良い状態の例: AI対応ブランドに見られる好パターン
ai_readyグループは小規模ですが、再現したいパターンを示す点で非常に有用です。
Mokobaraは83点で、出力中最上位でした。これは単一シグナルの勝利というより、複数要素がそろった強い対応の例です。
Magic Mind、Le Petit Ballon、Maine Lobster Nowはいずれも81点で、手動・構造化llmsバケットに入っています。これは、単なるプラットフォーム標準ではなく、意図的なファイルレベルの作業が行われていることを示す重要な例です。
Yo Mama's Foodsは80点で、同じく手動・構造化llmsです。食品ブランドは、AIシステムから原材料、味、用途、レシピ、食事制限との相性、比較などを問われる可能性があるため、AI可読な構造の恩恵を受けやすいです。
Three Ships Beautyは77点で、手動・構造化llmsでした。美容は、肌質、成分、ルーティン、テクスチャ、レビュー、代替品についての質問が多いため、構造化されたAI対応に最適なカテゴリです。
Manukoraは75点でした。はちみつやウェルネス寄りの食品は、原産地、品質、効能、認証、使い方などの説明が必要になることが多く、構造化された商品・ポリシーシグナルが特に価値を持ちます。
ここでの教訓は、すべてのブランドが同じ見た目を目指す必要はない、ということです。AI対応はシステムです。
- 役立つllms.txtファイル
- きれいなメタデータ
- 構造化されたOrganizationおよびWebSiteデータ
- 商品ページschema
- 価格とオファーのシグナル
- レビューまたは評価シグナル
- 在庫シグナル
- ポリシーとサポートの明確さ
どれか1つだけでも役に立ちますが、組み合わせてこそ対応が成立します。
7. llms.txtだけでは不十分な理由
llms.txtは、AI対応を示す便利な略称になっています。それは、見える、確認しやすい、新しくて戦略的に感じられる、という理由から理解できます。しかし、この調査は、それだけで全体像とみなすべきではない理由を示しています。
プラットフォーム標準のllms.txtファイルは、基本的な入口を作ることができます。クローラーを重要なページに導き、サイトにAI可読の入り口があることを機械に伝えられるかもしれません。ただし、商品ページが商品情報を明確に出していなければ、その入口の先は散らかった部屋です。
AI検索の問題は、単に「クローラーがサイトを見つけられるか」だけではありません。次のような問いも含まれます。
- クローラーは商品を識別できるか?
- ブランドを識別できるか?
- 価格を解析できるか?
- 在庫を解析できるか?
- レビューや評価を識別できるか?
- 商品コンテンツとマーケティングコンテンツを区別できるか?
- ポリシーを理解できるか?
- バリエーションを比較できるか?
- 正しいcanonicalページを参照できるか?
llms.txtは、ナビゲーションと優先順位付けに役立ちます。構造化された商品データは、理解を助けます。AI対応にはその両方が必要です。
8. 運用担当者向けプレイブック: AI検索対応をどう改善するか
DTCおよびECチームにとって、実務フローはシンプルです。
ステップ1: AIファイル層を確認する。 ドメインにllms.txtはあるか。存在しても実体があるか、それともソフト404か。プラットフォーム標準か、手動・軽量か、構造化か。役立つページを指しているか。
ステップ2: メタデータを監査する。 canonicalタグ、meta description、Open Graph画像、Twitterカード、必要に応じてhreflang、モバイルviewportを確認します。派手ではありませんが、機械が文脈を組み立てる助けになります。
ステップ3: JSON-LDを検証する。 Organization、WebSite、BreadcrumbList、Product schemaを確認します。ECで最も重要なギャップはProduct schemaです。
ステップ4: ホームページだけでなく商品ページを監査する。 AIショッピングが重視するのは商品ページです。商品名、説明、画像、価格、オファー、在庫、SKU、レビュー、評価、バリエーション、返品ポリシーを確認します。
ステップ5: 商品情報を安定させる。 重要な商品情報を画像だけに閉じ込めたり、きれいにレンダリングされないタブや、クローラーが解析しにくいJavaScriptウィジェットだけに依存したりしないようにします。
ステップ6: ポリシーの明確さを高める。 配送、返品、定期購入の条件、保証、認証、安全性の主張は、見つけやすく、解析しやすい必要があります。
ステップ7: テンプレート変更後に再テストする。 schemaは、リデザイン、テーマ変更、アプリ変更、ヘッドレス移行の際に壊れやすいです。構造化データはQAの一部として扱いましょう。
ステップ8: 責任の所在を明確にする。 AI対応はSEOだけの担当ではありません。EC、商品、コンテンツ、エンジニアリング、法務、カスタマーサポートにも関わります。
9. SEOチームとコンテンツチームが引用できるポイント
この調査からは、次のような強い引用ポイントが得られます。
「1,238のDTC対象ドメインのうち、AI対応ティアに到達したのは11件だけでした。」 これが最も広い対応状況のフックです。
「llms.txtは一般的ですが、その多くはプラットフォーム自動生成です。」 platform_defaultバケットには629ドメインがあり、手動・構造化ファイルは31件しかありません。
「ホームページのProduct schemaは、対象ドメインのわずか0.9%にしかありません。」 これが最も鋭い構造化データのギャップです。
「商品ページのProduct schemaは、商品ページの取得を試みた対象の39.2%にあります。」 これは補足的なニュアンスを加えます。ホームページよりは良いものの、まだ不十分です。
「美容とアパレルがカテゴリ表を先行していますが、それでも平均は50/100未満です。」 これはカテゴリ別の切り口を作れます。
「AI対応は階層的です。」 これは、llms.txtさえあれば対応済みだと考えがちな読者にとって、最も重要な教育ポイントです。
ただし、重要な但し書きがあります。このデータは、このサンプルにおける公開サイトのシグナルを反映したものであり、業界全体の普及率でも、内部検索パフォーマンスでもありません。
10. AIショッピングがDTCチームにもたらす変化
従来のECでの発見は、ページ、順位、広告、クリックを中心に設計されていました。購入者は検索し、結果を比較し、ページを開き、レビューを読み、意思決定していました。AIショッピングや回答エンジンは、その流れを圧縮します。購入者は、「平日のパスタに合う低糖質ソースのベストは?」「レビューの良い200ドル以下の機内持ち込み用バックパックは?」「香料なしで敏感肌にやさしい洗顔料は?」と尋ねるかもしれません。AIシステムは、購入者がブランドのページを見る前に、候補を要約してしまう可能性があります。
それによって、商品ページの役割が変わります。ページは依然として人間を説得する必要がありますが、同時に機械が比較できる程度に商品を明確に記述しなければなりません。ブランドトーンだけでは足りません。美しい画像だけでも足りません。巧みな商品名だけでも足りません。機械が必要とするのは事実です。何の商品か、誰向けか、いくらか、在庫があるか、どんなバリエーションがあるか、レビューは何と言っているか、どんな主張が裏付けられているか、どんな原材料や素材が重要か、どのポリシーが適用されるか、です。
だからこそ、一般的なAIファイルよりも商品レベルの構造が重要なのです。llms.txtは、クローラーに見る場所を伝える助けになります。Product schemaと整った商品ページ情報は、見つけた内容を理解する助けになります。
DTCブランドにとってのリスクは、除外されることだけではありません。誤って表現されることでもあります。商品ページが不明瞭だと、AIの回答が誤った特徴を要約したり、重要な差別化要素を見落としたり、重要なポリシーを省いたり、より整った競合と比べて不公平に扱ったりするかもしれません。その意味で、AI対応はブランド保護の問題でもあります。
検討プロセスが複雑なカテゴリほど、その重要性は高まります。美容の購入者は、肌質、成分、ルーティン、敏感性、効果を尋ねます。食品の購入者は、栄養、アレルゲン、原産地、味、レシピ、食事制限との相性を尋ねます。アパレルの購入者は、フィット感、サイズ、素材、返品、コーディネートを尋ねます。ウェルネスの購入者は、エビデンス、使い方、安全性、信頼性を尋ねます。ホーム商品の購入者は、寸法、素材、配送、組み立て、耐久性を尋ねます。これらはすべて、マーケティング課題であると同時に、機械可読なコンテンツ課題でもあります。
希望はあります。ほとんどのブランドはまだ初期段階だからです。平均対応スコアは36.4/100にすぎず、ai_readyティアに到達したのは11ドメインだけでした。完全なサイト再構築を待つ必要はありません。テンプレート、schema、ポリシーの明確化、商品情報から始められます。
11. 部門別のAI対応プラン
AI対応はSEOだけの責任ではありません。複数のチームにまたがります。
SEOは発見可能性とschema検証を担います。 SEOチームは、canonicalタグ、メタデータ、構造化データ、Product schema、パンくず、hreflang、クロール可能性を監査すべきです。また、テーマ変更やアプリ更新後にProduct schemaが残っているかも確認する必要があります。
ECは商品ページの事実を担います。 商品名、価格、バリエーション、在庫、セット販売、定期購入、レビュー、配送条件、返品情報は、明確で一貫していなければなりません。これらの情報がウィジェット、タブ、画像、スクリプトに分散していると、機械は苦戦します。
コンテンツは説明の深さを担います。 AIシステムは、質問に明確に答えるページを評価します。購入ガイド、比較表、成分解説、用途別ページ、サイズガイド、FAQセクションは、人間にも機械にも役立ちます。
エンジニアリングは実装品質を担います。 schemaは有効で、安定しており、テンプレート駆動であるべきです。商品情報を脆弱なクライアントサイドレンダリングだけに依存させるべきではありません。商品ページテンプレートはリリース後にテストする必要があります。
法務・コンプライアンスは表現を担います。 健康、サステナビリティ、安全性、原材料、性能に関する主張がある場合、それらは正確で、裏付けが可能で、解釈しやすいものでなければなりません。AIシステムは曖昧な主張を増幅する可能性があります。
カスタマーサポートは繰り返し質問を担います。 サポートチケットには、購入者やAIシステムが何を尋ねるかが表れます。配送日数、フィット感、原材料、互換性、返品、定期購入の解約、手入れ方法、商品比較などです。こうした質問は商品ページのコンテンツに反映させるべきです。
経営層は優先順位付けを担います。 AI対応は他の多くのプロジェクトと競合します。経営層に伝えるべき論点はシンプルです。構造化された商品情報は、SEO、AI検索、商品フィード、広告ショッピング、サイト内検索、サポート、コンバージョンを支えます。これは単なるAIプロジェクトではありません。
12. 最低限必要なAI対応商品ページ
実用的なDTCの商品ページには、少なくとも次の情報が必要です。
- 商品名
- ブランド名
- canonical URL
- 商品説明
- 商品画像
- 価格
- 通貨
- 在庫状況
- バリエーション情報
- 該当する場合の商品SKUまたは識別子
- 利用可能なレビューまたは評価シグナル
- オファー詳細
- 配送・返品ポリシーへのリンク
- カテゴリに応じた素材、原材料、仕様情報
- よくある購入質問に対するFAQまたはサポート情報
ページには有効なProduct schemaも含め、重要な情報を画像や、クローラーが解析しにくいスクリプトの中にだけ隠さないようにする必要があります。これは、退屈な商品ページを作るという意味ではありません。説得力のあるデザインと、信頼できる構造化された事実を分ける、という意味です。
多くのブランドにとって、最速の成果は長いAI戦略文書を書くことではありません。まずは重要な商品ページを10件検証し、schemaを修正し、最も重要な商品情報がHTMLと構造化データの両方で見えるようにすることです。
方法論
この調査は、2026年5月11日に収集されたDTC dual-reportデータセットを使用しています。master.csv、detection.csv、seo_signals.csv、生のllms.txtファイル、そして取得可能な場合は生の商品ページHTMLを用いて、1,238ドメインを採点しました。
スコアモデルは4つの層を分けています。
- AIファイル層: llms.txtの存在と品質。
- 一般的な構造化データ層: JSON-LD、Organization、WebSite、BreadcrumbList、Product、および関連する構造化シグナル。
- 商品ページ層: Product schema、オファーまたは価格シグナル、レビューまたは評価シグナル、在庫シグナル。
- メタデータ層: canonical、meta description、Open Graph画像、Twitterカード、hreflang、および関連ページコンテキスト。
このモデルは0〜100のAI対応スコアを算出し、ドメインを未対応、部分的に対応、基本的な発見可能性、ai_readyの4ティアのいずれかに分類します。
留意点
-
AI対応はAIトラフィックではありません。 このスコアは、AI検索システムやショッピングエージェントからの実際の流入を測定しているわけではありません。
-
公開シグナルは下限値です。 一部の構造化データは動的に読み込まれたり、クロールで取得できない形で表示されたりする可能性があります。
-
llms.txtの品質判定はヒューリスティックです。 手動・構造化ファイルは、見出し、リンク、商品用語、ポリシー用語などの観測可能な特徴から識別しています。
-
商品ページの検出は、試行した商品ページ取得に依存します。 商品ページschemaの割合は、商品ページの取得を試み、かつ利用可能だったケースに適用されます。
-
サンプルはDTC全体の完全な国勢調査ではありません。 ECツールのエコシステムや公開DTCリストで可視性の高いブランドに偏っています。
-
カテゴリラベルは方向性を示すものです。 大まかな比較には有用ですが、厳密な分類体系ではありません。
-
AI検索の基準はまだ進化しています。 このスコアモデルは、恒久的な定義ではなく、2026年時点の実用的なベンチマークとして設計されています。
再現性メモ
納品フォルダには次のファイルが含まれています。
analyze_ai_search_readiness.py—llms.txt、構造化データ、商品ページシグナル、メタデータシグナルを横断してDTCドメインを評価するためのスコアリングスクリプト。ai_search_readiness_scores.csv— ドメイン単位のAI対応スコア、ティア、各種コンポーネントシグナル。llms_quality_audit.csv— プラットフォーム標準、ソフト404、欠如、手動・軽量、手動・構造化の分類を含む、ドメイン単位のllms.txt品質監査。category_ai_readiness.csv— カテゴリ単位のAI対応比較。top_ai_ready_brands.csv— 編集レビューと事例選定のための高得点ドメイン。lowest_ai_ready_brands.csv— ギャップ分析と編集レビューのための低得点ドメイン。summary.json— サンプルサイズ、ティア数、平均スコア、中央値、商品ページシグナル率を含む、このレポートで引用した主要集計値。
方法論の修正、データセットの問題、追加分析のご要望は support@thunderbit.com までお寄せください。本レポートはThunderbitの商業的立場とは独立して公開されています。私たちはAI搭載のウェブスクレイパーを開発しており、公開ECサイトが人間、検索エンジン、AIエージェントにとって正確に理解しやすくなることに構造的な関心を持っています。このベンチマークは、2026年5月11日に収集した公開サイトシグナルに基づく1,238件のDTCドメインを対象としています。本レポートのデータはそれ自体で成立しています。— Thunderbitリサーチチーム、2026年5月。