
2026年、企業に足りないのはデータではありません。足りないのは、データと業務フローのかみ合わせです。世界経済フォーラムは、世界のデータ生成量が2025年に181ゼタバイトに達すると予測しています。一方でIBMによると、企業データの推定68%は使われずに眠っているとのこと。このギャップこそが、データマイニングソフトウェアがいまだ重要であり続ける理由です。バズワードとしてではなく、生データ、文書、Webデータ、イベントストリームを「実際に使えるパターン」へと変換する実用レイヤーとして必要とされている、ということです。
IBMの定義は今でも最もわかりやすい部類です。機械学習と統計分析を使って、大規模データセットから有用な情報を見つけ出すこと。それがデータマイニングです。ただ実務の現場では、買い手が見るポイントは昔の教科書的な定義よりずっと広くなっています。視覚的なモデリングツールを求めるチームもあれば、統制されたエンタープライズ分析が必要なチームもある。クラウド規模の機械学習やストリーミング基盤が必要なケースもあれば、分析の前段として、まずはやっかいなWebデータを集めるだけで十分というケースもあります。
ワークフロー別のクイックピック
- 分析の前にWebデータをパッと集めたい? まずはThunderbitをどうぞ。
- ノーコードで使える視覚的なデータサイエンス基盤が必要? Altair AI Studio と KNIME を候補に。
- 学習や試作にいちばん始めやすいオープンソースが欲しい? Orange と Weka を見てみてください。
- ガバナンス付きのエンタープライズ予測分析が必要? IBM SPSS Modeler、SAS Enterprise Miner、Spotfire Statistica を比較しましょう。
- クラウドネイティブな機械学習とデプロイが必要? Microsoft Azure Machine Learning、Dataiku、H2O.ai を確認しましょう。
- 大規模パイプラインやインデータベース分析が必要? Teradata と Google Cloud Dataflow に注目を。
Thunderbit が自社のデータワークフローに合うか確認する
2026年のデータマイニングソフトウェアの対象範囲とは?
このキーワードは今や、4つの異なる購買ニーズをひとくくりにしています。
- データ取得ツール: 分析を始める前に、生データの収集や構造化を支えてくれる製品。
- 視覚的ワークフローツール: ほぼコードを書かずに、データの整形、モデル作成、結果スコアリングまで一気通貫でこなせるプラットフォーム。
- エンタープライズ向け統計・予測スイート: 大企業や規制対象のチーム向けに、統制された運用ができるシステム。
- クラウド・基盤レイヤー: 大規模学習、デプロイ、リアルタイム処理を下支えするプラットフォーム。
このリストにあえて毛色の違う製品を混ぜているのは、それぞれが解く課題が違うからです。今もWebサイトから項目を何時間もコピペしているなら、使い切れない高機能モデリングスイートより、ブラウザ起点のデータ取得ツールのほうが圧倒的にビジネス価値を生むこともあります。逆に、ボトルネックがガバナンス付きのモデルデプロイやDWH規模の処理にあるなら、話はまるで逆になります。
比較を始める前に解説動画を一本見たい、という方には、こちらのIBMの概要動画が今でも最も情報密度の高い入門編です。データマイニングが、分析、機械学習、業務改善の中でどの位置にあるかをコンパクトに説明してくれます。
比較表:2026年のおすすめデータマイニングソフトウェア
| ツール | 最適な用途 | 際立つポイント | 価格の目安 |
|---|---|---|---|
| Thunderbit | 分析前に生のWebデータが必要なビジネスチーム | AIによる項目提案、サブページ、ページネーション、Sheets / Excel / Airtable / Notion へエクスポート | 無料プラン、セルフサービスの有料プラン、ビジネスプラン |
| Altair AI Studio | コードを多用せずに使えるビジュアルMLワークフロー | ドラッグ&ドロップ設計、AutoML、対話型データ準備。旧RapidMiner Studio | 無料トライアル、商用版 |
| KNIME | オープンソースのワークフロー分析と自動化 | ノードベースのパイプライン、強いコミュニティ、豊富な拡張機能 | 無料プラットフォーム、有料のビジネス製品 |
| Orange | 初心者や教育向けの視覚的マイニング | とても分かりやすいビジュアルウィジェットと探索ワークフロー | 無料・オープンソース |
| Weka | アルゴリズムの試行と教育 | 軽量GUIで使える古典的ML手法の豊富なライブラリ | 無料・オープンソース |
| IBM SPSS Modeler | エンタープライズ予測分析チーム | 視覚的なストリーム、テキスト分析、ガバナンスに適したデプロイ | 要見積もり/エンタープライズ向け |
| SAS Enterprise Miner | 規制産業やSAS中心のチーム | 熟成したモデリングの深さ、大規模データ処理、SAS連携 | 要見積もり/エンタープライズ向け |
| Azure Machine Learning | Microsoft中心のクラウド分析とML | AutoML、MLOps、Azure連携、マネージドデプロイ | 従量課金のクラウド料金 |
| Alteryx | 前処理とセルフサービス分析を自動化したいアナリスト | ドラッグ&ドロップの前処理、再利用可能なワークフロー、幅広い導入実績 | トライアルあり+エンタープライズ価格 |
| Spotfire Statistica | 統計の深さとエンタープライズ管理を両立したい場合 | 高度な分析、再利用可能なワークフロー、コンプライアンス重視の監視 | 要見積もり/エンタープライズ向け |
| Teradata | 超大規模なインデータベース分析 | 巨大なエンタープライズデータセットと統制されたデータ基盤での高い性能 | エンタープライズ/契約制 |
| Rattle | Rベースの学習と低コストの試作 | RワークフローをGUI化し、コードも見える | 無料・オープンソース |
| Dataiku | 部門横断のデータサイエンスチーム | ノーコードとコードの協働、自動化、ガバナンス | 無料版、エンタープライズ価格 |
| H2O.ai | AutoMLと大規模モデル構築 | 高速モデリング、説明可能性、強力なMLエコシステム | オープンソース+エンタープライズ提供 |
| Google Cloud Dataflow | リアルタイム処理と大規模バッチ処理 | マネージドApache Beamパイプライン、自動スケーリング、ストリーミング対応 | 従量課金のクラウド料金 |
2026年のビジネス向けデータマイニングソフトウェア15選
高速なデータ収集と視覚的ワークフローマイニングに最適
1. Thunderbit
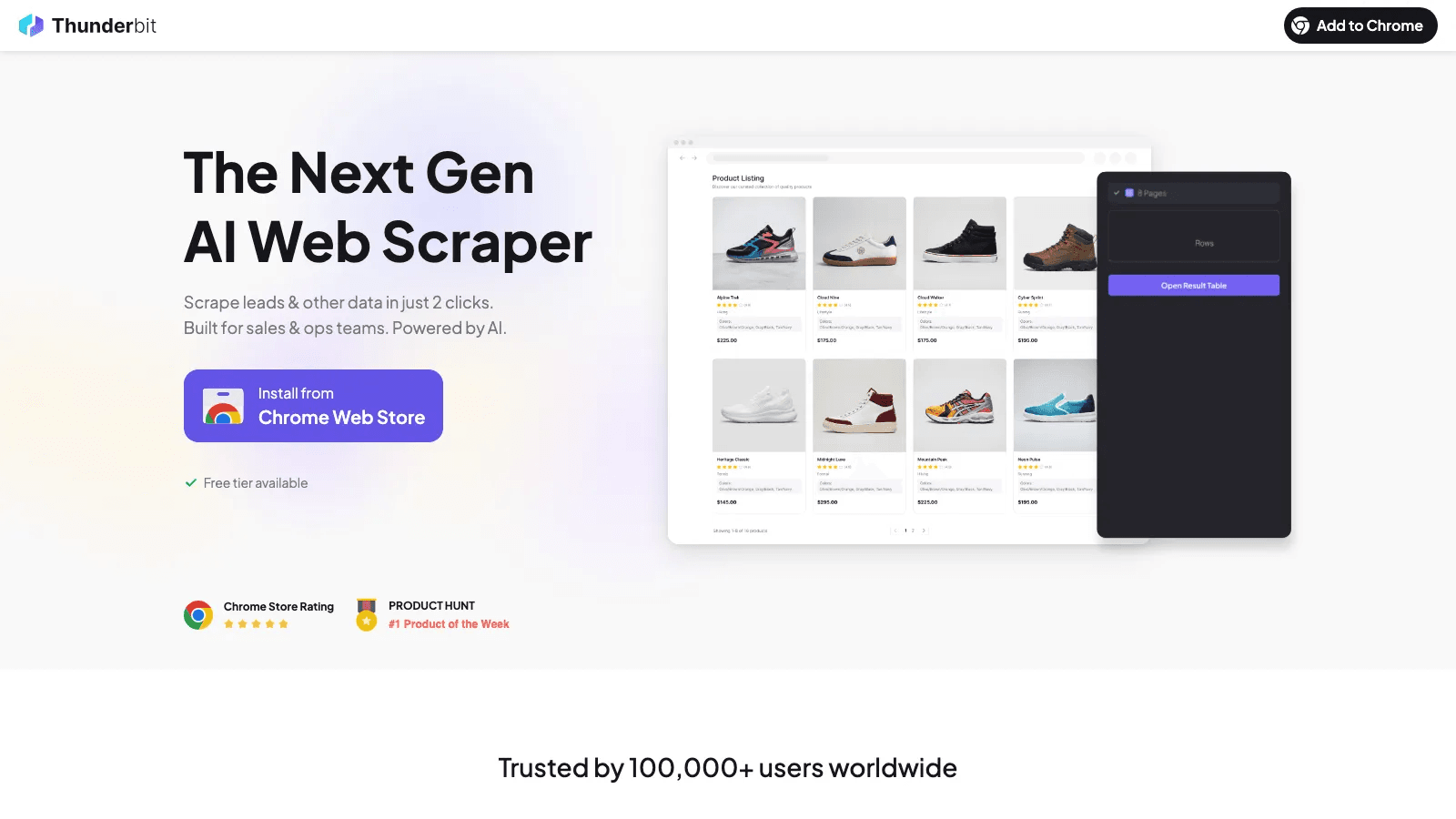
Thunderbit をこのリストに入れたのは、多くのビジネス向けデータマイニング案件が、モデリングに入る前の段階で頓挫してしまうからです。データはWebサイト、PDF、社内調査ページ、ポータル、画像だらけの掲載情報の中にある。きれいに掬い上げられなければ、その先の分析基盤がどれほど優秀でも、全部宝の持ち腐れになります。
Thunderbit が最も強いのは、作業のスタート地点がブラウザにあり、構造化された出力を素早く欲しいときです。AIによる項目提案、サブページの取得、ページネーション対応、直接エクスポート。これらが揃っているので、自前のスクレイピング基盤を組み立てる前段の手間を一切かけずに、営業、EC、オペレーション、人材採用、市場調査の各チームに馴染みます。
- 最適な用途: ビジネスユーザー向けのWeb起点データ取得。
- 際立つポイント: AI項目提案、サブページの拡張取得、ブラウザまたはクラウド実行、Sheets / Excel / Airtable / Notion へのエクスポート。
- 採用理由: 下流の分析を妨げる「収集のボトルネック」を、きれいに解消できるからです。
- 価格の目安: 無料プラン、セルフサービスの有料プラン、ビジネスオプションあり。
Thunderbit AI Web Scraperを無料で試す
2. Altair AI Studio
Altair AI Studio は、この分野を昔から知っている人ほど見落としやすい、重要な変化のひとつです。なぜなら、多くの買い手が今でも RapidMiner Studio として記憶しているあの製品の、現行ブランド名だからです。Altair はこれを、AutoML、対話型データ準備、新世代のAIワークフローと従来型機械学習の両方を備えた、視覚的なドラッグ&ドロップ型データサイエンス設計ツールとして位置づけ直しています。
ノートブック中心ですべてを書き起こさなくても、本格的なモデリング機能が欲しいチームには、今でも有力な候補です。純粋な教育向けツールに比べると、実務で繰り返し使うワークフローへの移行もしやすい、というメリットがあります。
- 最適な用途: ガイド付きの視覚的MLワークフローを使いたいアナリストやドメインエキスパート。
- 際立つポイント: ドラッグ&ドロップのキャンバス、AutoML、対話型準備、広いデータ接続性。
- 注意点: オープンソース製品より商用色が強く、調達面の重みが大きくなります。
3. KNIME Analytics Platform

KNIME は、いまもこのリストで最も汎用性の高いオープンソースのワークフローツールです。ノードベースのインターフェースはアナリストにも取っつきやすく、データ準備、統計分析、機械学習、自動化、拡張機能をひとつの再利用可能なパイプラインにまとめたいチームにとっては、機能の深さも十分です。
透明性が問われる場面では、KNIME はとくに頼りになります。ユーザーはワークフローの各ステップを確認し、共有し、Python、R、データベース、その他のツールとの連携を加えて拡張できます。
- 最適な用途: オープンソース優先のチームや、ワークフロー重視のアナリスト。
- 際立つポイント: 再利用可能なパイプライン、巨大な拡張エコシステム、強いコミュニティ採用。
- 注意点: 柔軟性は抜群ですが、UIは軽量な初心者向けツールよりエンジニア寄りに感じられることがあります。
4. Orange
Orange は、見ながら学びたい人にとって、最も親しみやすいデータマイニング環境です。ウィジェットベースのインターフェースのおかげで、分類、クラスタリング、可視化、テキストマイニングが、コマンドライン中心のツールよりぐっと理解しやすくなっています。
ビジネスチームにとっては、重厚なガバナンス付きエンタープライズ基盤というより、試作や学習用のツールとして使うのがハマります。
- 最適な用途: 初心者、教育、ワークショップ、初期探索。
- 際立つポイント: 親しみやすい視覚インターフェースと、強い探索用可視化。
- 注意点: エンタープライズデプロイや本格運用には、あまり向いていません。
5. Weka
Weka がいまも定番なのには、ちゃんと理由があります。軽量なインターフェースの中に、機械学習アルゴリズムの定番が一通り揃っており、試行、比較、教育用途にうってつけだからです。
ビジネス用途での出番は以前ほど多くないものの、素早い検証、学習、小規模データで幅広いアルゴリズムを試したいときには、いまでも実用的です。大きなプラットフォームを立ち上げるまでもなく、サクッと触れる。これが意外と効くんです。
- 最適な用途: アルゴリズム比較、教育、小規模な試行。
- 際立つポイント: 古典的MLの幅広い対応と軽量GUI。
- 注意点: 新しいワークフロー製品と比べるとどうしても古さが目立ち、現代的なMLOpsには向きません。
ここで一度立ち止まって、現代の視覚的ワークフロー製品がどんな見た目なのか押さえておきたい場合は、こちらの Altair AI Studio 公式GUI解説が中盤の確認ポイントとして役立ちます。
エンタープライズ予測分析と統制されたモデリングに最適
6. IBM SPSS Modeler
IBM SPSS Modeler は、すべてのアナリストにコード中心のツールを強制せずにエンタープライズ予測分析を始めたい組織にとって、いまも最も安全な候補です。視覚的なストリームUIは、モデル作成、準備、スコアリングを、ビジネス関係者にもわかる形に保ってくれます。これは今でも十分に通用する強みです。
- 最適な用途: ガバナンス付きの、親しみやすい予測分析を求める大企業。
- 際立つポイント: 視覚的ストリーム、テキスト分析対応、エンタープライズ向けデプロイオプション。
- 注意点: 気軽に試すチーム向けではなく、プラットフォーム導入として捉えるべきです。
7. SAS Enterprise Miner
SAS Enterprise Miner は、規制業界やSAS中心の環境においていまも重要な存在です。このカテゴリで最も流行りのツールではありませんが、監査性、組織の信頼、既存のSAS基盤が判断軸になる場面では、いまも十分に説得力があります。
- 最適な用途: 金融、医療、保険、その他の規制対応ワークフロー。
- 際立つポイント: 熟成したモデリングの深さ、SASエコシステムとの親和性、大規模データ処理。
- 注意点: SASへの既存投資がないチームには、新しいプラットフォームのほうが導入しやすいかもしれません。
8. Microsoft Azure Machine Learning
Azure Machine Learning は、すでにMicrosoftのクラウド基盤で仕事を回しており、試行、AutoML、デプロイ、監視をひとつの環境にまとめたいチームにフィットします。
- 最適な用途: Azure中心で、クラウドMLと運用の両方をまとめたい組織。
- 際立つポイント: AutoML、モデル管理、デプロイ機能、Microsoftエコシステムとの統合。
- 注意点: クラウドの柔軟性は強みですが、利用量が増えるとコスト管理が課題になります。
9. Alteryx

Alteryx が選ばれるのは、多くのビジネス向けデータマイニングの正体が、実はスプレッドシートに閉じていたデータ作業の整形、統合、運用化だからです。毎週同じ面倒な変換を手で繰り返すのに嫌気がさしたアナリストが、長年選び続けてきたツールでもあります。
- 最適な用途: 前処理中心のワークフローを自動化したいビジネスアナリスト。
- 際立つポイント: ドラッグ&ドロップの前処理、再現性のある分析ワークフロー、強いビジネスユーザー定着率。
- 注意点: 高機能ではあるものの、小規模チームには最も安い選択肢とは限りません。
10. Spotfire Statistica
Spotfire Statistica は、深い統計手法と統制された運用利用の両方が必要な組織にとって、いまも有力な選択肢です。現行のSpotfireは、高度な分析、再利用可能なワークフロー、コンプライアンスに配慮したガバナンスを前面に押し出しています。
- 最適な用途: 製造、医療、品質、コンプライアンス重視の分析チーム。
- 際立つポイント: 熟成した統計の深さ、再利用可能なモデルワークフロー、監視とガバナンス。
- 注意点: 軽い試行というより、整ったエンタープライズプログラム向けの製品です。
高度なデータ基盤、協働、スケールに最適
11. Teradata
Teradata がここに残っている理由はシンプルです。巨大で統制されたデータ基盤の上でデータマイニングを回すなら、アルゴリズムと同じくらい性能とアーキテクチャが効いてくるからです。Teradata は、インデータベース分析、大規模DWH、そして小ぶりな個別ツールでは受け止めきれないエンタープライズワークロードで、いまも欠かせない存在です。
- 最適な用途: 超大規模な企業データセットとインデータベース分析。
- 際立つポイント: スケール、性能、エンタープライズデータ基盤との適合性。
- 注意点: 中小企業やミドルマーケットの多くには、明らかに過剰です。
12. Rattle
Rattle は、R のモデリングエコシステムを、コードを書く量を抑えて使いたいチームや学習者にとって、いまも便利な橋渡し役です。現代的な協働プラットフォームというより、低コストの学習・試作環境と割り切るのがちょうどいいです。
- 最適な用途: Rの学習者と軽量な試作。
- 際立つポイント: RワークフローのGUI化とコードの可視性。
- 注意点: 新しい視覚的協働製品と比べると、世代差は否めません。
13. Dataiku
Dataiku は、協働とスケールの両方が必要なときに、このリストでもっともバランスのとれた製品のひとつです。ノーコード派と上級者のあいだに無理やり線を引かないところが効いている。ビジネスユーザーはレシピやダッシュボードで作業でき、技術者は必要なところでコードレベルの制御を握ったままでいられます。
- 最適な用途: 部門横断の分析・データサイエンスチーム。
- 際立つポイント: ノーコードとコードの協働、強いガバナンス、自動化、デプロイ対応。
- 注意点: ユースケースが限定的な小規模チームには、必要以上に大きなプラットフォームかもしれません。
14. H2O.ai
H2O.ai は、スケーラブルなモデリング、AutoML、説明可能性を重視する組織で、いまも上位に食い込んできます。とくに、すべてをゼロから組み立てるより、速度とモデル反復の回転数を上げたい場合に魅力的です。
- 最適な用途: 高速な反復とスケーラブルな自動化を求めるMLチーム。
- 際立つポイント: AutoML、モデル速度、説明可能性、強力なエコシステム。
- 注意点: 実際のビジネスチームから見ると、ML色が強すぎる場合があります。
15. Google Cloud Dataflow
Google Cloud Dataflow は、いわゆる「データマイニング用デスクトップツール」ではありません。それでも最後の枠に入れる価値があるのは、現代のマイニング案件の多くが、分析の前段としてリアルタイムまたは大規模バッチのデータパイプラインを前提にしているからです。ストリーミングデータ、イベント処理、大規模な特徴量準備が要るなら、Dataflow は事実上、マイニング基盤の一部になります。
- 最適な用途: ストリーミングパイプラインと大規模バッチ準備。
- 際立つポイント: マネージドApache Beam、自動スケーリング、GCPとの強い統合。
- 注意点: 基盤主導の製品であり、ビジネスユーザー最優先の分析ツールではありません。
過剰購入しないための選び方
よくある失敗は、摩擦の原因を取り違えることです。
- 課題がデータアクセスなら、Thunderbitのような収集ツールから始めましょう。
- 課題がアナリストの生産性なら、まず Altair AI Studio、KNIME、Alteryx、Orange を比べてみてください。
- 課題がエンタープライズガバナンスなら、SPSS Modeler、SAS Enterprise Miner、Spotfire Statistica、Dataiku を候補に。
- 課題がクラウドML運用なら、Azure Machine Learning、H2O.ai、Dataiku から検討を始めましょう。
- 課題がストリーミングや超大規模アーキテクチャなら、Teradata や Dataflow に寄せていきましょう。

シンプルな原則があります。実際にボトルネックを解消できる、いちばん複雑でないツールを買うこと。これだけです。多くのチームは、巨大なデータサイエンス基盤を必要としていません。本当に要るのは、より良いデータ収集、より清潔な前処理、そしてアナリストが本当に使う再現可能なワークフローです。
候補にWeb起点のデータ取得が含まれているなら、こちらのThunderbitクイックスタート動画が最も実用的な例になります。やっかいなページが、エンジニアリングの手間ほぼゼロで構造化テーブルに変わっていく様子が見て取れるはずです。
チームタイプ別の最終候補

- 営業、EC、ブラウザ作業が多いオペレーションチーム: Thunderbit、Alteryx、KNIME。
- 深いコード依存なしで視覚的ワークフローを使いたいアナリスト: Altair AI Studio、KNIME、Alteryx、Orange。
- エンタープライズ予測分析チーム: IBM SPSS Modeler、SAS Enterprise Miner、Spotfire Statistica。
- 部門横断のデータサイエンス組織: Dataiku、Azure Machine Learning、H2O.ai。
- データエンジニアリングと基盤チーム: Teradata、Google Cloud Dataflow、Azure Machine Learning。
- 予算重視の学習者や試作担当: Orange、Weka、Rattle、KNIME。
2026年の多くのビジネス購入者向けに、このリストを最小限の実用候補まで絞るなら、次の5つです。
- Thunderbit — 分析前のWebサイトと文書データの高速取得。
- Altair AI Studio — ノートブック中心の流儀に縛られない視覚的データサイエンスとAutoML。
- KNIME — オープンソースのワークフロー柔軟性。
- IBM SPSS Modeler — ビジネスに優しいUIで使えるエンタープライズ予測分析。
- Dataiku — 協働、ガバナンス、スケールを同時に必要とするチーム。
結論
本当に大事なのは、どの製品が最も多くの機能を持っているか、ではありません。生データから、少ない摩擦で「説明できる意思決定」までたどり着けるのはどのツールか、です。2026年には、収集、前処理、モデリング、デプロイをきちんと切り分け、ひとつの購入で全層を同じように解決できるフリをしないこと。ここが鍵になります。
業務の出発点が公開Webサイト、PDF、非構造化ページなら、まずはThunderbitから。出発点が統制されたエンタープライズモデリングなら、SPSS Modeler、Dataiku、Azure Machine Learning のような上位レイヤーから始めるべきです。そして、どの種類のプラットフォームが必要なのかまだ学んでいる最中なら、KNIME、Orange、Altair AI Studio が、手応えを素早くつかむのに最適です。
関連記事
FAQ
1. 平たく言うと、データマイニングソフトウェアとは何ですか?
データマイニングソフトウェアは、チームが生データの中からパターン、セグメント、異常、トレンド、予測シグナルを見つけ出すのを支援するツールです。実際の業務フローでは、データ収集、クレンジング、モデル構築、スコアリング、レポーティングがひとつなぎになっていることがほとんどです。
2. データマイニングソフトウェアはデータサイエンティスト専用ですか?
いいえ。市場はいま、技術系と非技術系の購入者にきれいに分かれています。Thunderbit、Altair AI Studio、KNIME、Orange、Alteryx はアナリストやビジネスチームのハードルを下げており、Dataiku、Azure ML、H2O.ai のようなプラットフォームは、より上級のユーザーにもしっかり対応しています。
3. 非技術チームに最適なデータマイニングソフトウェアは何ですか?
データの出発点がWebなら、Thunderbit が最速の第一歩です。もっと広い分析やワークフローモデリングが必要なら、Altair AI Studio、KNIME、Orange、Alteryx が、このリストで最も強いノーコード/ローコードの選択肢です。
4. オープンソースツールとエンタープライズプラットフォームのどちらを選ぶべきですか?
柔軟性、低い導入コスト、試行錯誤の余地が必要ならオープンソース。ガバナンス、サポート、デプロイ管理、コンプライアンス、部門横断の標準化が、ライセンス価格のわかりやすさより重要ならエンタープライズプラットフォームを選びましょう。
5. これらのツールを複数組み合わせて使えますか?
はい、しかも多くのチームはむしろそうすべきです。よくある構成は、Thunderbit でデータを集め、KNIME や Alteryx で前処理やモデリングを行い、クラウドやエンタープライズプラットフォームで運用化・監視する、という流れです。最適なスタックは、ひとつのツールに全部を押し付けるのではなく、ワークフローの異なる層をそれぞれ専用の道具で解いていきます。




