スプレッドシートを見て「この『Acme Inc.』と『Acme Incorporated』って同じ会社なのかな?」と悩んだ経験、みんな一度はあるんじゃない?こういう重複やバラバラなデータって、ただ面倒なだけじゃなくて、会社にとってはかなりの損失につながるんだよね。アメリカの企業は毎年もの損失を「悪いデータ」で出していて、1社あたり年間約1,300万ドルも重複レコードや不一致な連絡先、間違った分析に使ってるっていうから驚き。データの流入元やシステムが増えるほど、この問題はどんどん深刻に。だからこそ、データマッチングのスキルはビジネスをスムーズに回すために欠かせないんだ。

そもそもデータマッチングって何?なんで営業やマーケ、オペレーションの人たちが注目してるの?このガイドでは、データマッチングの基本から実際の使い方、みたいな最新ツールで誰でも簡単にデータマッチングできる方法まで、分かりやすく紹介するよ。データのごちゃごちゃをスッキリ片付けよう!
データマッチングとは?ざっくり解説
データマッチングは、違うデータセットの中から同じ人や会社、商品などを見つけてつなげる作業のこと()。いわば、データの中の名探偵みたいなもの。たとえば営業CRMの「John Doe」とサポートシステムの「Jonathan Doe」が同じ人かどうかを見抜く感じ。
ビジネスの現場だと、
- 顧客データの照合:マーケや営業、サポートなど複数のデータベースをまたいで顧客情報をまとめる
- 商品リストの統一:ちょっとずつ違う商品名やSKUをまとめる
- 取引先や仕入先の重複排除:表記ゆれや入力ミスで二重登録されたものを発見
データマッチングは、ただの「完全一致」だけじゃなくて、ルールや賢い比較で表記ゆれやニックネーム、フォーマット違いも見抜けるのがポイント。たとえば「Jon Smith」と「Jonathan Smith」、「555-123-9988」と「(555) 123-9988」も同じと判断できる()。
最終的なゴールは、顧客や商品、取引先ごとに「一元化された正しい情報」を持つこと。バラバラな断片や重複データとはおさらばしよう。
なぜデータマッチングがビジネスに必須なのか
きれいに統合されたデータは、理想じゃなくてビジネスの土台。データマッチングの主なメリットは:
- コストと時間の削減:重複データは無駄なマーケ費や二重対応、手作業の増加を招く。ある調査では、重複データが年間につながることも。
- 顧客体験の向上:同じメールが2回届いたり、別人扱いされると顧客は離れていく。実際、するというデータも。
- 正確な分析ができる:間違ったデータは間違った意思決定を生む。は重複や不一致データが原因。
- コンプライアンスリスクの低減:データの不統一はGDPRやHIPAAなどの規制対応を難しくする。
データマッチングがビジネスにもたらす価値をざっくりまとめるとこんな感じ:
| 活用シーン | データマッチングの効果 |
|---|---|
| リードの重複排除(営業) | 重複リードを統合し、同じ相手への二重アプローチを防止。パイプラインの精度向上。 |
| 顧客プロファイルの統合 | 複数システムの顧客情報をつなげて360°ビューを実現。パーソナライズやサービス向上に貢献。 |
| 商品・在庫データのクレンジング | 重複商品をまとめ、在庫や価格情報の一貫性を確保。 |
| 取引先・仕入先の照合 | 重複した取引先や請求書を発見し、二重支払い防止や支出分析を効率化。 |
| 連絡先データの整理(マーケティング) | 連絡先情報を照合・標準化し、メールコスト削減や配信精度向上。 |
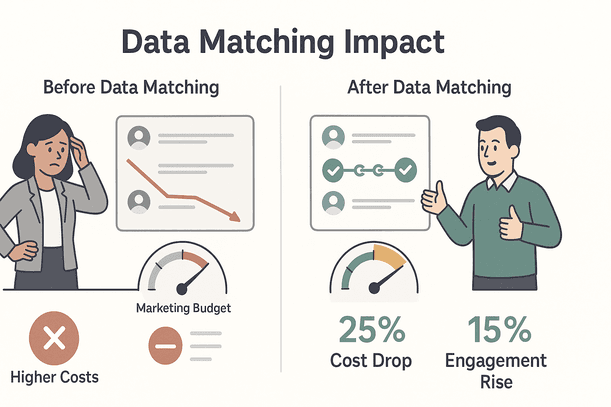
データマッチングに投資した会社は、マーケコストが最大25%削減、顧客エンゲージメントが約15%向上した事例もあるよ()。データ部門だけじゃなく、全社的にメリットがあるんだ。
データマッチングの流れと主なやり方
データマッチングの流れはざっくりこんな感じ:
- データの準備:まずはデータをきれいに整える。誤字修正やフォーマット統一(日付・電話番号など)、比較しやすい形にする()。
- 照合基準の設定:どの項目(氏名・メール・電話番号など)を比較するか決める。メールみたいな一意項目もあれば、あいまい比較が必要な項目も。
- 比較とスコアリング:アルゴリズムでレコード同士を比較し、類似度スコアを出す。「Jonathan Smith」と「Johnathan Smithe」なら0.92/1みたいな感じ。
- 判定ルール:スコアが90%以上なら一致、50%未満なら不一致、間は人の目で確認など、しきい値を決める。
- グループ化・統合:一致したレコードをまとめて、1つの正しい情報に統合。
ファジーマッチングなどの賢い技
現実のデータはきれいじゃないから、こんな工夫も使われてるよ:
- ファジーマッチング:スペルミスや表記ゆれ(例:「Jon Smyth」と「John Smith」)も検出()。
- 音声類似マッチング:発音が似てる名前(例:「Katherine」と「Catherine」)も一致。
- パターン・正規表現マッチング:電話番号などフォーマット違いも認識。
- データフィンガープリント:住所などをデジタル署名化して、表記違いも同一視。
- AIによるマッチング:機械学習でパターンを学習し、ルールでは見逃す一致も発見()。
最先端のデータマッチングは、これらを組み合わせて高精度を実現してるよ。
データマッチングが活躍する現場
データマッチングはIT部門だけの話じゃない。いろんな現場で役立ってるんだ:
- 顧客データ統合:Web・アプリ・店舗など複数チャネルの顧客情報を一元化。ある小売業者は重複プロファイルを40%削減、メール反応率も15%向上()。
- 営業リードの重複排除:複数ソースのリードを整理し、同じ相手への二重アプローチを防止。優良企業は重複率1%未満をキープ()。
- マーケティングリストのクレンジング:メールリストの重複を除去し、無駄な配信やコストを削減。
- EC商品カタログ管理:商品リストの統合で在庫ミスや誤集計を防止。
- 財務データの照合:仕入先や請求書の重複を発見し、二重支払いを防止。中小企業は重複請求で1万2千ドル超の損失リスクも()。
- 医療現場の患者記録照合:患者情報の重複を防ぎ、安全性を確保。病院では10%前後の重複率も()。
業種問わず、複数のデータソースがあるならデータマッチングは必須!
データマッチングで意思決定が変わる
「ゴミデータからはゴミしか生まれない」ってよく言うよね。重複やミスだらけのデータで分析しても、正しい判断はできない。データマッチングで得られる主な効果は:
- 信頼できる分析:重複がなくなり、正確なレポートが可能に。実際は8万人の顧客なのに10万人と誤認することも防げる。
- 戦略立案の精度アップ:統合データで本当のトレンドが見えて、投資判断も的確に。
- 迅速な意思決定:きれいなデータなら、変化にもすぐ対応できる。人気商品や離反リスク顧客もすぐ把握。
- 顧客理解の深化:全体像が見えるから、セグメントやクロスセルも最適化。
- KPIの正確な把握:重複で水増しされない、本当の数字で評価できる。
データマッチングを重視する会社は、キャンペーンROIが最大15%向上し、より自信を持った意思決定ができるようになってる()。
従来型データマッチングツールの限界
データマッチングが大事なのに、なぜ多くの会社が苦戦してるのか?従来のツールにはこんな課題があるんだ:
- 手作業が多い:ExcelのVLOOKUPや自作スクリプトだと時間がかかるし、大規模化に対応できない。データ担当者はをクレンジングに使ってることも。
- 複雑なルール設定:古いツールは技術的なルールや保守が大変。
- 柔軟性が低くエラーが多い:データ形式が変わるとすぐ壊れるし、新しいソース追加も難しい。
- 大規模・非構造データに弱い:Excelは大容量データで重くなるし、従来ツールは非構造データに弱い。
- バッチ処理のみ:定期的なクレンジングの間に重複がたまる。リアルタイム対応不可。
- 非IT部門には使いにくい:多くのツールはIT向けで、現場ユーザーには難しい。
そのせいでが重複データに悩んでるんだ。
AIデータマッチングの進化:もっと賢く、速く、正確に
ここでAIの出番!最新のデータマッチングツールは、機械学習や自然言語処理で作業を自動化してくれる:
- 面倒な作業を自動化:AIは数ヶ月で重複レコードを30〜40%削減()。
- 複雑なデータもOK:AIはパターンや文脈を理解し、ルールでは見逃す一致も発見。
- 大規模処理も余裕:数百万件のデータも短時間で処理。
- 学習して進化:使うほど精度がアップ。
- リアルタイム対応:多くのAIツールはデータ流入時に即時マッチング可能。
たとえばは、「John Smith」と「Jonathan S. Smith」の一致を数分で判定できるよ。
Thunderbit:誰でも使えるデータマッチング
Thunderbitは、データエンジニアだけじゃなく誰でも簡単にデータマッチングできるのが目標。なら、数クリックでクリーンなデータが手に入る:
- AIフィールド提案:Webページを開いて「AIフィールド提案」をクリックするだけで、ThunderbitのAIが最適なカラム(氏名・会社名・メールなど)を自動抽出し、統一フォーマットでデータ化()。
- サブページ・ページネーション対応:詳細ページも自動で巡回し、情報をメインテーブルに統合。手作業の結合や抜け漏れを防止()。
- AIによるデータ型認識・標準化:日付や電話番号などのデータ型を自動判別し、異なる言語でも統一フォーマットに変換()。
- 自然言語インターフェース:やりたいことを日本語や英語で入力するだけで、Thunderbitが自動で処理()。
- ワンクリックエクスポート:Excel、Google Sheets、Airtable、Notionなどに直接エクスポート。追加料金や隠れコストなし()。
- 人気サイト用テンプレート:Amazon、Zillow、Shopifyなどの即時テンプレートで、毎回一貫したデータ取得が可能。
- 定期スクレイピング:スケジュール設定で常に最新・統合済みデータを維持()。
Thunderbitでデータマッチングする手順(ミニガイド)
- を開く
- 対象のWebページにアクセス
- 「AIフィールド提案」をクリックしてThunderbitにカラムを選ばせる
- 「スクレイプ」をクリック。Thunderbitがデータ抽出・標準化・マッチング(サブページも自動対応)
- クリーンで重複排除されたデータを好きなツールにエクスポート
めちゃくちゃ簡単!実際の動きはでも見られるよ。
チームに合ったデータマッチングツールの選び方
データマッチングツールを選ぶときは、こんなポイントをチェックしよう:
| 選定基準 | 注目ポイント |
|---|---|
| 使いやすさ | 直感的なUI、自然言語コマンド、コーディング不要 |
| 連携性 | Excel、Google Sheets、CRMなど既存ツールとの入出力が簡単 |
| 拡張性 | 小規模リストから数百万件までスムーズに処理 |
| AI機能 | ファジーマッチング、AIフィールド提案、フィードバック学習 |
| データクレンジング機能 | 標準化・検証・データ補完が内蔵 |
| カスタマイズ性 | マッチングルールやしきい値の柔軟な調整 |
| 監査性・コンプライアンス | ログ・元に戻す・プライバシー配慮機能 |
| サポート・コミュニティ | 充実したドキュメント、導入サポート、迅速な対応 |
Thunderbitは、特に非エンジニアでもすぐに使い始められるのが強み。
どんなに良いツールでも、データマッチングには課題もある。主な対策は:
- データ形式の不統一:日付や電話番号などのフィールドを事前に標準化。Thunderbitなら自動でやってくれる。
- 欠損データ:複数項目で照合し、不足情報は補完。
- 誤検出・見逃し:しきい値を調整し、微妙なケースは人の目で確認。
- 複数システム間の統合:マスターデータ管理やクロスシステム対応ツールを活用。
- プライバシー配慮:照合時は匿名化、監査ログを残し、ポリシー遵守。
- 継続的なデータ品質維持:定期的なマッチングと、全社的な品質意識の徹底。
まとめ:データマッチングが現代ビジネスに不可欠な理由
- データマッチングは「唯一の正しい情報源」を作ること。重複や断片化を解消できる。
- クリーンなデータがビジネス成果を左右:ROIアップ、顧客満足度アップ、意思決定の精度向上。
- 手作業では限界。AI搭載ツール(Thunderbitなど)がこれからの主流。
- Thunderbitなら誰でも簡単にデータマッチング:AIフィールド提案、サブページ対応、簡単エクスポート。
- データマッチングへの投資は競争力の源泉。データを「負債」から「資産」へ。
クリーンで統合されたデータが、あなたのビジネスをどう変えるか。ぜひしたり、でさらに学んでみて!
よくある質問(FAQ)
1. データマッチングって簡単に言うと?
違うデータセットの中から、同じ顧客や商品など実在の対象を特定・リンクする作業。細かい部分が完全一致してなくてもOK。
2. なんでビジネスにデータマッチングが大事なの?
重複排除や顧客プロファイル統合、分析精度アップ、無駄な作業削減など、意思決定や顧客満足度に直結するから。
3. AIはデータマッチングをどう楽にしてくれる?
AIが面倒な作業を自動化し、複雑なデータも高精度で照合。使うほど賢くなって、スピードも大幅アップ。
4. Thunderbitは他のデータマッチングツールと何が違う?
ThunderbitはAIでフィールド提案・データ標準化・サブページも含めた照合を自動化。非エンジニアでも使いやすく、主要ビジネスツールと連携できる。
5. チームでデータマッチングを始めるには?
まず主要なデータソースを特定して、Thunderbitみたいなツールでデータ抽出・標準化・定期的なマッチングをやってみよう。詳しくはもチェックしてみて!