

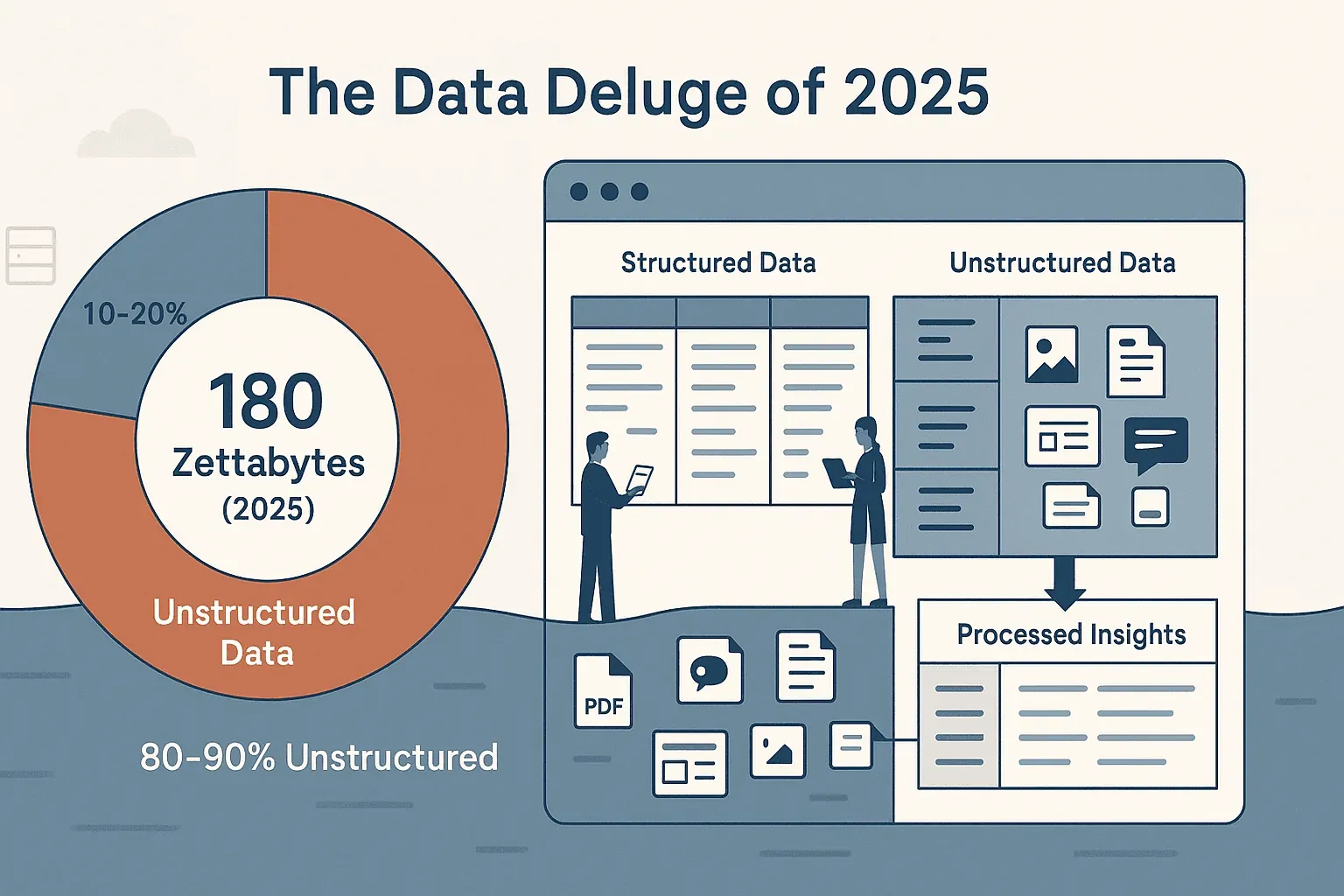
売上リードの収集、競合価格の把握、あるいは煩雑な商品カタログの整理など、ウェブサイトからデータを集めようとしたことがあるなら、ウェブが簡単なコピペ向けに作られていないことはよくご存じでしょう。オンラインデータの量は驚異的です。IDCとStatistaによると、世界のデータ総量は2025年に約180ゼタバイトに達し、2026年には約221ゼタバイトに向かっています。本当に厄介なのは量ではなく、形です。その約80%は非構造化データで、Webページ、PDF、画像、動的フィードの中に埋もれています。多くのビジネスチームは、私自身も含めて、この混乱と格闘することにあまりにも多くの時間を費やし、結局は中途半端なスプレッドシートと既視感だけが残る、という経験をしてきました。
AIでどんなウェブサイトからでもデータを抽出 Get Started Free
だからこそ、私は効率的なウェブサイトクロールに夢中なのです。このガイドでは、ThunderbitというAI搭載のウェブクローラーを使って、コード不要・ストレス不要で、どんなウェブサイトでもクロールする実践的な手順をステップごとに紹介します。営業、オペレーション、あるいは手作業のデータ入力にうんざりしている方でも、複雑なレイアウト、ページネーション、サブページへの対応方法、さらにPDFや画像からのデータ抽出までカバーします。ウェブ上の混沌を、次のビジネス優位につなげましょう。
ウェブサイトを効率的にクロールするとはどういうことか?
簡単に言うと、ウェブサイトをクロールするとは、自動化ツール(ロボットのアシスタントのようなもの)を使ってWebページを体系的に巡回し、名前、価格、メールアドレス、製品仕様など、必要な情報を抽出することです。効率的なクロールは、単に速いだけではありません。正確性、手作業の最小化、そしてページネーションやサブページ、非構造化データといった実際のWeb上の障害に対応できることが重要です(Wikipedia)。
効率的なクロールと、ひたすらコピペする作業の違いはどこにあるのでしょうか。重要なのは次の点です。
- 速度: 数時間ではなく、数分で何百ページ、何百件ものレコードを取得できること。
- 正確性: 必要なデータを漏れなく、タイプミスもなく正確に取得すること。
- 自動化: 「次へ」をクリックしたり詳細ページへリンクをたどったりする反復作業をツールに任せられること。
- 堅牢性: 複雑なレイアウト、動的コンテンツ、サイト構造の変更にも対応できること。
- 最小限の設定: コーディング不要、セレクタの調整不要、継続的なメンテナンス不要。
現実のWebは、きれいな表だけでできているわけではありません。今どきのサイトには、無限スクロール、複数ステップのナビゲーション、ログイン要件、PDFや画像に埋もれたデータが普通にあります。効率的なクロールとは、それらをすべて乗り越え、面倒な作業に費やす時間を減らし、分析やアクションにもっと時間を使えるようにすることです(AIMultiple)。
売上とオペレーションにとって効率的なウェブサイトクロールが重要な理由
なぜビジネスチームはこんなにもWebクロールを重視するのでしょうか。適切なデータを、必要なタイミングで得られれば、次のキャンペーン、製品ローンチ、営業四半期の成否を左右するからです。私が毎週目にする、最も一般的でROIの高いユースケースをいくつかご紹介します。
| ユースケース | メリットとROI | 成果例 |
|---|---|---|
| リード獲得 | 営業ファネルをすばやく埋め、見込み顧客調査の時間を節約し、手作業ミスを減らす | 一晩で5,000件のターゲットリードを抽出し、2週間早くキャンペーンを開始、アポイントを30%増加 |
| 競合価格モニタリング | ダイナミックプライシングを実現し、市場変化にリアルタイムで反応し、利益率を守る | 小売業者が毎日価格を調整し、4%の売上増加を確認 |
| 商品カタログ/在庫抽出 | 掲載情報を最新に保ち、手入力を削減し、売り越しや価格設定ミスを防ぐ | ECチームが毎日10,000 SKUを更新し、更新時間を90%削減 |
| 市場調査・レビュー分析 | 顧客の感情やトレンドを大規模に把握し、競合より先に機会を見つける | 10,000件以上のレビューを分析し、新しい商品機会を特定、マーケティングメッセージを改善 |
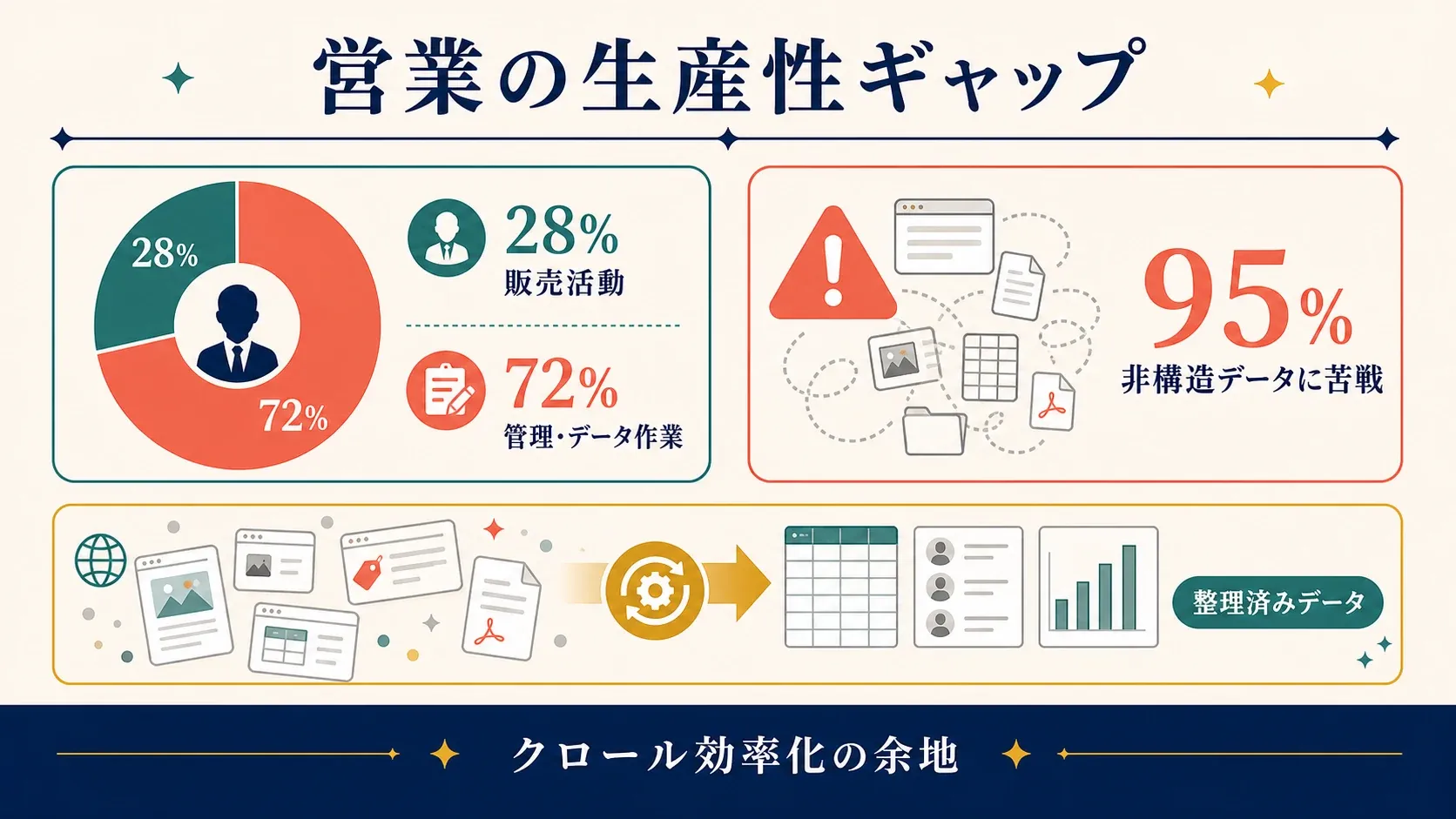
要するに、効率的なクロールは、より速く、より賢い意思決定を可能にし、コピペに費やす時間を大幅に減らします。実際、95%の企業が非構造化Webデータの活用に苦労していると認めており、営業担当者が実際に「売る」ことに使える時間は全体の28%にすぎません。残りは手入力と事務作業に消えていきます。
Thunderbit: ウェブサイトをクロールする最も簡単な方法
正直に言うと、ほとんどのWebスクレイピングツールは開発者向けに作られており、ビジネスユーザー向けではありません。だからこそ私たちは、Thunderbitという、出前を注文するくらい簡単なAI搭載ウェブクローラーを作りました。Thunderbitの特長は次のとおりです。
- 自然言語プロンプト: 欲しいデータをそのまま説明するだけで(「このページから商品名と価格をすべて取得して」など)、あとはThunderbitのAIが処理します。
- AIによるフィールド提案: 「AIフィールド提案」をクリックすると、Thunderbitがページを解析し、抽出に最適な列を提案し、クローラーを自動で設定します。
- 2クリックのワークフロー: フィールドに満足したら、「抽出」をクリックするだけ。コードもテンプレートも、セレクタとの格闘も不要です。
- ページネーションとサブページに対応: Thunderbitは複数ページの一覧を自動検出して移動し、詳細ページ(サブページ)へのリンクもたどってデータを充実させます。
- 即時エクスポート: データをExcel、Google Sheets、Airtable、Notionに直接送信するか、CSV/JSONとしてダウンロードできます。すべて無料です。
- PDF・画像向けOCR: PDF、画像、スキャン文書からデータが必要ですか? Thunderbit内蔵のOCRが、その内容も抽出・構造化します。
Thunderbitは非技術系ユーザー向けに設計されています。Webを閲覧して文章を入力できるなら、プロのようにウェブサイトをクロールできます。もちろん、リスクなしで試せる無料プランもあります。
ウェブサイトクロールソリューションの比較: Thunderbit vs. 従来の方法
Thunderbitを、よくある手法と並べて見てみましょう。
| アプローチ | セットアップ時間と複雑さ | 必要なスキル | 保守性と信頼性 |
|---|---|---|---|
| 手作業のコピペ | 非常に高く、拡張性がない | 不要だが、ミスが起きやすい | 完全に手動。更新のたびにやり直し |
| カスタムコード(Pythonなど) | 初期設定が大変で、1サイトごとに数時間〜数日かかる | プログラミング必須 | サイト変更で壊れやすく、継続的な修正が必要 |
| 従来型のノーコードツール | 中程度、クリック中心で設定 | 低〜中 | レイアウト変更時に更新が必要で、動的サイトに対応できないことがある |
| Thunderbit(AI搭載) | 非常に低く、2クリックで設定 | 不要 | AIが変更に適応し、保守は最小限 |
従来のツールは途中までうまくいくこともありますが、動的コンテンツやページネーションで止まりがちで、変更のたびに手をかける必要があることも多いです。ThunderbitのAIは、人間のようにサイトを読み取り、新しいレイアウトにも適応し、面倒な部分を処理してくれます。だから、あなたは何もしなくて大丈夫です(Thunderbit Blog)。
ステップ1: Thunderbitでウェブサイトクロールをセットアップする
始め方はとても簡単です。
- Thunderbit Chrome拡張機能をインストールします。 無料アカウントに登録してください。
- 対象のWebサイトに移動します。 クロールしたいページを開きます。商品一覧、ディレクトリ、PDFでもかまいません。
- Thunderbitを開きます。 ChromeツールバーのThunderbitアイコンをクリックします。
- 必要なデータを伝えます。 「AIフィールド提案」をクリックしてThunderbitに列を提案させるか、自然言語でプロンプトを入力します(例: 「各項目の製品名、価格、画像URLを抽出して」)。
- プレビューして調整します。 Thunderbitがプレビュー表を表示するので、必要に応じてフィールド名の編集、不要項目の削除、カスタム指示の追加を行えます。
ワンポイント: プロンプトは具体的かつ簡潔にしましょう。サイト上で使われている表現そのままに(「価格」「住所」など)データ項目を挙げれば、あとはThunderbitのAIに任せられます。
ステップ2: ウェブサイトクロール中のページネーションとサブページの処理
ここでThunderbitの真価が発揮されます。実際のデータは1ページに収まっているとは限らず、ページ分割された一覧やサブページの中に分散していることがほとんどです。
- ページネーション: Thunderbitは「次へ」ボタン、ページ番号、無限スクロールを自動で検出します。「抽出」をクリックすると、必要なデータがそろうまでページを読み込み続けます。URLを手入力したり、各ページを順番にクリックしたりする必要はありません。
- サブページクロール: もっと詳しい情報が必要ですか? メイン一覧の抽出後に「サブページを抽出」をクリックしてください。Thunderbitはリンク(商品詳細ページや企業プロフィールなど)をたどり、追加情報を抽出して表に統合します。
例: ECサイトを抽出する場合、Thunderbitは商品一覧を取得したあと、各商品の詳細ページを訪問して仕様、レビュー、画像を引き出します。すべて一度で完了します。
ベストプラクティス: まずThunderbitにメインのクロールを完了させ、その後でサブページ抽出を使ってより深いデータを取得しましょう。進行状況の更新を確認でき、抜けている項目も把握できます。
ステップ3: Thunderbitによる非構造化データのスマート抽出
すべてのデータが整った表で提供されるわけではありません。商品説明、レビュー、混在形式のフィールドは、従来のスクレイパーにとって悪夢のような存在です。ThunderbitのAIは、そこに真正面から取り組みます。
- データの整形とフォーマット: 通貨記号を削除し、数値を解析し、複雑なフィールドを分割します(例: 「USD 299(50%オフ!)」を「299」と「50%オフ」に分ける)。
- 複雑なテキストを解析: 段落から構造化情報を抽出します(例: 求人票から「所在地: New York」を見つける)。
- 分類とラベル付け: 内容に応じてカテゴリやタグを追加します(例: 「電子機器」か「衣料品」かを判定)。
- 不整合への対応: 欠損フィールドやレイアウト変更に適応し、データの整合性と正確性を保ちます。
- 要約や翻訳: 一文要約や翻訳が必要ですか? カスタム指示を追加すれば、ThunderbitのAIが対応します。
その結果、すぐに使えるきれいなデータが手に入ります。Excelで何時間もクリーニングする必要はもうありません。
ステップ4: クラウドクロールとブラウザクロールの選び方
Thunderbitには、用途に応じて2つのクロール方法があります。
- ブラウザクロール: Chromeブラウザ上で、ログイン済みセッションを使って実行されます。認証が必要なサイトや、強力なボット対策があるサイトに最適です。クロールの様子をその場で確認でき、人間のブラウジングに近い動きになります。
- クラウドクロール: 処理をThunderbitのクラウドサーバーに任せます。最大50ページを並列で処理できるため、大規模ジョブや定期実行に向いています。ノートPCを閉じて、Thunderbitに重い作業を任せられます。
使い分けの目安:
- ログインが必要なサイトや、ページ操作が必要な場合はブラウザモードを使います。
- 公開サイト、大量処理、速度と自動化を重視する場合はクラウドモードを使います。
モードの切り替えは簡単です。クロールを始める前に、好みを選ぶだけです。
ステップ5: OCRを使って文書や画像からデータを抽出する
ときには、必要なデータがPDF、画像、スキャン文書の中に閉じ込められていることがあります。Thunderbit内蔵のOCR(光学文字認識)が、その状況を一変させます。
- PDF: レポート、請求書、カタログから表、メールアドレス、テキストを抽出します。
- 画像: スクリーンショット、商品ラベル、インフォグラフィックから文字を取り出します。
- スキャンしたフォーム: 領収書、契約書、名刺の入力作業を自動化します。
PDFや画像のURLをThunderbitに指定するだけで、内容を抽出して構造化してくれます。別のソフトは不要です。さらに、OCRとAIプロンプトを組み合わせて高度な抽出もできます(「このPDF内のすべてのメールアドレスを見つけて」など)。
ステップ6: クロールしたデータのエクスポートと活用
クロールが終わったら、そのデータを実際に活用する段階です。
- エクスポート方法: CSVやJSONでダウンロードするか、Google Sheets、Excel、Airtable、Notionに直接エクスポートできます。基本プランでも、すべて無料です。
- 営業とCRM: リード一覧をCRMに取り込み、アウトリーチ施策を始めたり、既存顧客情報を補強したりできます。
- マーケティングと分析: 競合価格を分析し、市場トレンドを追跡し、ダッシュボードで可視化します。
- オペレーションと在庫管理: 在庫を監視し、カタログを更新し、重要な変化に対するアラートを発火させます。
- 自動化: ZapierやGoogle Apps Scriptなどの連携を使って、フォローアップ、レポート、データ補完を自動化できます。
Thunderbitの構造化出力があれば、クロールからアクションまで数分で進めます。何日もかかることはありません。
まとめと重要ポイント
ウェブサイトを効率的にクロールすることは、単なる技術者の夢ではなく、ビジネスの強力な武器です。Thunderbitがあれば、誰でも次のことができます。
- 自然言語やAI提案フィールドを使って、数秒でクロールを設定できます。
- ページネーション、サブページ、動的コンテンツを含む複雑なサイトにも対応でき、コードは不要です。
- 乱雑なWebページ、PDF、画像から、きれいで構造化されたデータを抽出できます。
- 速度、規模、セキュリティに応じて、最適なモード(ブラウザ/クラウド)を選択できます。
- お気に入りのツールやワークフローへ、データを即時エクスポートできます。
終わりのないコピペや壊れやすいスクレイパーの時代は、もう終わりです。Thunderbitをダウンロードして、無料クロールを試し、どれだけ時間と集中力を節約できるか実感してください。次の大きなインサイト、あるいは営業成果は、ほんの1クリック先にあるかもしれません。
もっと多くのヒントや詳しい解説を知りたい方は、チュートリアル、ユースケース、最新のAI搭載ウェブクロール情報が満載のThunderbit Blogをご覧ください。
よくある質問
1. WebクロールとWebスクレイピングの違いは何ですか?
Webクロールは、Webサイトを体系的に巡回してページやリンクを見つけることを指し、Webスクレイピングは、そのページから特定のデータを抽出することを指します。Thunderbitはこの両方を組み合わせ、必要な情報の発見、移動、抽出までを行います。
2. Thunderbitはログインが必要なWebサイトにも対応できますか?
はい。認証が必要なサイトをクロールするには、Thunderbitのブラウザモードを使ってください。ログイン済みのChromeセッションを利用するため、ログインの先やペイウォールの向こう側にあるデータにもアクセスできます(サイトの利用規約の範囲内である限り)。
3. Thunderbitはページネーションや無限スクロールをどう扱いますか?
Thunderbitは、ページ分割された一覧や無限スクロールページを自動で検出し、移動します。「次へ」をクリックしたり、スクロールしたり、追加コンテンツを読み込んだりして、すべてのデータを取得します。手動設定は不要です。
4. Thunderbitはどんな種類のデータを抽出できますか?
Thunderbitは、テキスト、数値、日付、URL、メールアドレス、電話番号、画像、さらにはOCRを使ったPDFや画像内のデータまで抽出できます。フィールドをカスタマイズし、AIプロンプトで高度な構造化や整形も可能です。
5. Thunderbitは無料で使えますか?
Thunderbitには無料プランがあり、限られたページ数までクロールできます。CSV、Excel、Google Sheets、Airtable、Notionなどのエクスポート形式はすべて無料で利用できます。有料プランは、より大きな処理量と高度な機能向けに月額15ドルからです。
もっと賢くクロールしたいですか?今すぐThunderbitを試して、次のWebデータプロジェクトではAIに重い作業を任せましょう。 詳しく見る
- How to Web Crawl A Site? A Beginner's Guide
- How to Crawl Websites: A Step-by-Step Beginner’s Guide
- How to Crawl All Links on Website: A Comprehensive Guide
無料でAIウェブスクレイパーを試す Get Started Free




