オンラインで見かける「Bright Data レビュー」は、星だけ付けた商品カタログみたいなものがほとんどです。400M超のIPプールに触れて、「$4/GB」のキャンペーン価格を載せて、それでおしまい。でも、本当に知りたいのは「このプラットフォーム、予算に見合うのか?」のはずです。そこで私は数週間かけて、実際の料金体系を掘り下げ、Trustpilot、G2、Capterra、Reddit にある何百件ものユーザーレビューを読み込み、Bright Data の各製品が保護されたサイトでどこまで使えるのかを検証しました。そこで見えてきたのは、エンタープライズ向けのプロキシ基盤としては確かにトップクラスな一方で、見えにくいコストの罠、難易度の高い対象サイトでの信頼性のブレ、そして「ただWebサイトから構造化データがほしいだけ」の多くのチームには明らかに過剰な複雑さを抱えたプラットフォームだということでした。この記事は、私が調査を始めた当時にあってほしかった、率直な Bright Data レビューです。
Bright Data とは? 非エンジニア向けに簡単に解説
Bright Data は、プレミアムなプロキシネットワーク兼ウェブデータ収集プラットフォームです。かんたんに言うと、世界中の何百万もの異なるIPアドレスを経由して Web リクエストを送ることで、ブロックされにくい形で大規模にサイトへアクセスできる仕組みです。データ収集のための巨大なグローバル「変装ネットワーク」だと思うと分かりやすいでしょう。
もともとは Luminati Networks という名前で、2021年3月にリブランディングされました。2017年には に2億ドルで買収されています。本社はイスラエルのネタニアにあり、ニューヨークや欧州各地にも拠点を構えています。現在は を支援しており、その中には上位20の LLM ラボのうち14社も含まれます。年間売上は とされています。
製品ラインナップは、もう単なるプロキシにとどまりません。
- Proxy networks — residential、datacenter、ISP(static)、mobile
- Web Unlocker — アンチボット対策を自動で処理する API
- Scraping Browser — JavaScript が多いサイト向けのクラウドブラウザ
- Web Scraper API — 437以上のサイト向けの事前構築済みスクレイパー
- Pre-collected datasets — 120以上のドメイン向け完成済みデータ
- AI tools — Browser.AI、MCP Server、Deep Lookup(詳細は後述)
まずは仕様をざっと見てみましょう。
主な対象ユーザーは、企業規模のチームや技術チームです。社内に開発者がいて、月間のスクレイピング予算が5桁ドル規模なら、Bright Data はまさにそのために作られています。もしあなたが「金曜までにWebサイトから200件のリードがほしい」営業マネージャーなら、この先をもう少し読んでみてください。
Bright Data の料金:"$4/GB" だけでは終わらない全体像
Bright Data のレビューがここで崩れがちなのは、宣伝用の residential 料金だけを見て、そのまま話を終えてしまうからです。実際の料金は、マーケティングの印象よりずっと複雑で、かなり高くつくことがあります。
Residential Proxies(GB課金)
| プラン | GB単価 | 月額コミット | 含まれるGB |
|---|---|---|---|
| Pay-As-You-Go | $8.00 | なし | なし |
| Growth | $7.00 | $499 | 約71 GB |
| Business | $6.00 | $999 | 約166 GB |
| Enterprise | $5.00 | $1,999 | 約399 GB |
あちこちで見かける「$4/GB」は? それは です(コード RESIGB50、3か月間50%オフ)。キャンペーンが終われば通常価格に戻ります。背景も大事です。PAYG の residential は2023年9月以前は $10.50、2024年3月以降に $8.40 まで下がり、現在は $8.00 になっています。
Datacenter Proxies
いちばん手頃な選択肢です。共有プールは の PAYG。専用プールは、標準で $0.90〜$1.40/IP/月、プレミアムで $1.30〜$2.20/IP/月。各 IP には のフェアユース枠が含まれ、それを超えると PAYG 料金で超過分が請求されます。
ISP(Static Residential)Proxies

共有は、利用量に応じて $1.30〜$1.80/IP/月。専用は $2.50〜$3.50/IP/月。帯域プランは residential と同じ体系です。こちらも のフェアユース上限が適用されます。
Mobile Proxies
2024年4月に residential と価格が統一され、それまでは $14/GB でしたが、現在は です。プラン構成は residential と同じです。
Web Unlocker API(成功したリクエスト1,000件あたり)
| プラン | CPM(1K結果あたり) | 月額費用 |
|---|---|---|
| Pay-As-You-Go | $1.50 | なし |
| Growth | $1.30 | $499(約38万件) |
| Business | $1.10 | $999(約90万件) |
| Scale | $1.00 | $1,999(約200万件) |
この課金モデルには要注意です。Bright Data は Web Unlocker を「成功した分だけ支払う」方式として打ち出しています。デフォルトではその通りです。でも には重要な例外があります。「カスタム Web Unlocker API 機能を有効にすると、成功・失敗を問わず全リクエストの100%が課金対象になります。」カスタム機能には、手動ヘッダー、cookies、"expect" 要素などが含まれます。つまり、より細かい制御が必要になった瞬間に——実際には難しいスクレイピングほどそうなりがちですが——成功ベース課金の保護が外れてしまうのです。
Scraping Browser(GB課金)
料金体系は residential と同じで、$8.00/GB PAYG、Enterprise で $5.00/GB まで下がります。Web Unlocker と違い、 失敗したリクエストの帯域が課金されるかが明記されていません。実質的には、失敗分も含めたすべての帯域が課金対象だと考えるのが自然です。
Web Scraper API
PAYG は 。Scale は $1.30/1K($499/月で約38.4万件)。Amazon、LinkedIn、Glassdoor、Walmart、Zillow など向けに が含まれます。課金対象は、正常に取得できた結果のみです。1K件の無料レコード試用あり。
2025年1月の再編にも触れておきます。Bright Data は する一方で、Web Scraper API は50%値上げし、料金を $1.50/1K CPM に揃える方向へ動きました。2024年時点の料金前提で予算を組んでいるなら、再計算が必要です。
Pay-Per-GB と Pay-Per-IP:どちらを選ぶべきか
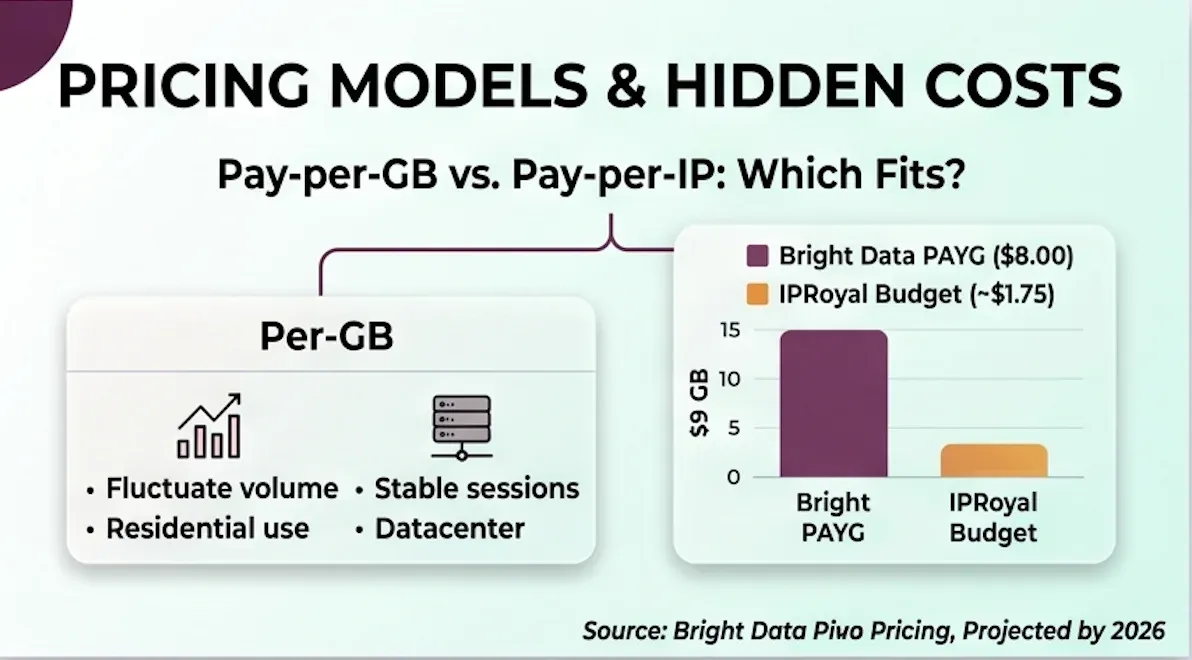
月ごとにスクレイピング量が大きく変動するなら、GB課金が向いています。住宅系やモバイル系のように、多数の異なるサイトへアクセスする用途に合っています。一方、安定した長時間セッションが必要なら IP課金の方が向いています。たとえば、アカウント管理、広告検証、SEO監視など、datacenter や ISP プロキシで同じ IP を継続利用するケースです。
ざっくりした判断基準はこうです。IP数は予測できるけど帯域は変動する? なら IP課金。帯域は予測できるけどローテーション IP が必要? なら GB課金。
細かい注意書きに出てこない隠れコスト
- 失敗リクエスト課金: Web Unlocker はカスタム機能を有効にすると全リクエストが課金対象。Scraping Browser は帯域ベースで、失敗分も含めて課金されます。
- 帯域超過料金: ISP プロキシには 100 GB/IP のフェアユース上限があります。あるレビューでは、23日で割当を使い切り「想定外の $300 超過請求」が発生したと報告されていました。
- 中間帯がない: の通り、「$1.50/1K の従量課金(大量利用には高すぎる)と $499/月のコミットの間に、現実的な選択肢がない」のです。
- キャンペーン終了時の価格ショック: 50%オフは3か月で終わり、その後は通常価格に戻るため、4か月目に請求額が跳ね上がります。
コストシナリオ:月50GBの residential スクレイピング
| 手段 | GB単価 | 月額費用 |
|---|---|---|
| Bright Data PAYG | $8.00 | $400 |
| Bright Data Growth Plan | $7.00 | $499(71 GB 含む) |
| IPRoyal(低価格代替) | $1.75 | $87.50 |
| Thunderbit Pro | 定額 | $38/月(クレジット制、約3,000行) |
これだけで4〜10倍の価格差です。最終目的がスプレッドシート上の構造化データであって、ローレベルのプロキシ基盤ではないチームにとって、Bright Data のコスト計算が有利になる場面はあまりありません。
Bright Data のコストを下げる方法:実際に効く対策
すでに Bright Data を使っている、あるいは契約上やめられない場合でも、請求額を動かせる現実的な手段があります。
対象が許すなら、residential より datacenter を使う。 datacenter の共有は $0.60/GB、residential は $8.00/GB で、13倍の差があります。ニュース、公開ディレクトリ、政府系データなど、多くの非保護サイトは datacenter で問題なく動きます。
ダッシュボードでゾーンごとの支出上限を設定する。 Bright Data の管理画面では、 を設定できます。上限の再計算は15分ごとなので、ゾーンによっては最大15分分の使用量だけ超過する可能性があります。アカウント残高の85%消費時にはメール通知が届きます。
Full Access を使いたいなら、KYC は早めに完了する。 Immediate Access(KYC不要)は GET のみ、約200の承認済みドメイン、そしてプロバイダー側のスロットリングがかかります。その結果、402 エラーが増え、無駄な帯域消費も増えます。Full Access なら全メソッドが使え、ドメイン制限も大幅に減るため、成功率が上がり、無駄な出費も減ります。
不要なリソースをブロックして帯域を 削減する。 画像、CSS、フォント、広告、トラッキングスクリプトを、リクエストインターセプトや CDP のルートブロックで止めます。これだけで請求額は半分になることがあります。 ことで、更新頻度の低いページでは帯域を最大90%削減できる場合もあります。
Web Unlocker でカスタム機能は、必要なとき以外は有効にしない。 手動ヘッダーや cookies を設定した時点で、成功ベース課金から「全リクエスト課金」に切り替わります。失敗率の高い対象では、その差はかなり大きくなります。
そもそも別の手段へ切り替える判断を持つ。 商品一覧、連絡先、物件情報のような構造化データを、独自のスクレイピング基盤を組まずに取りたいなら、 のようなツールでプロキシスタック全体を置き換えられます。帯域課金も、プロキシ設定も、KYC も不要です。
信頼性の実態チェック:Bright Data が苦戦しやすい場面
Bright Data は 99%以上の稼働率と高い成功率をうたっています。簡単な対象なら、その通りです。問題は、誰も「簡単な対象」をスクレイピングするためにエンタープライズ向けプロキシを買わないことです。
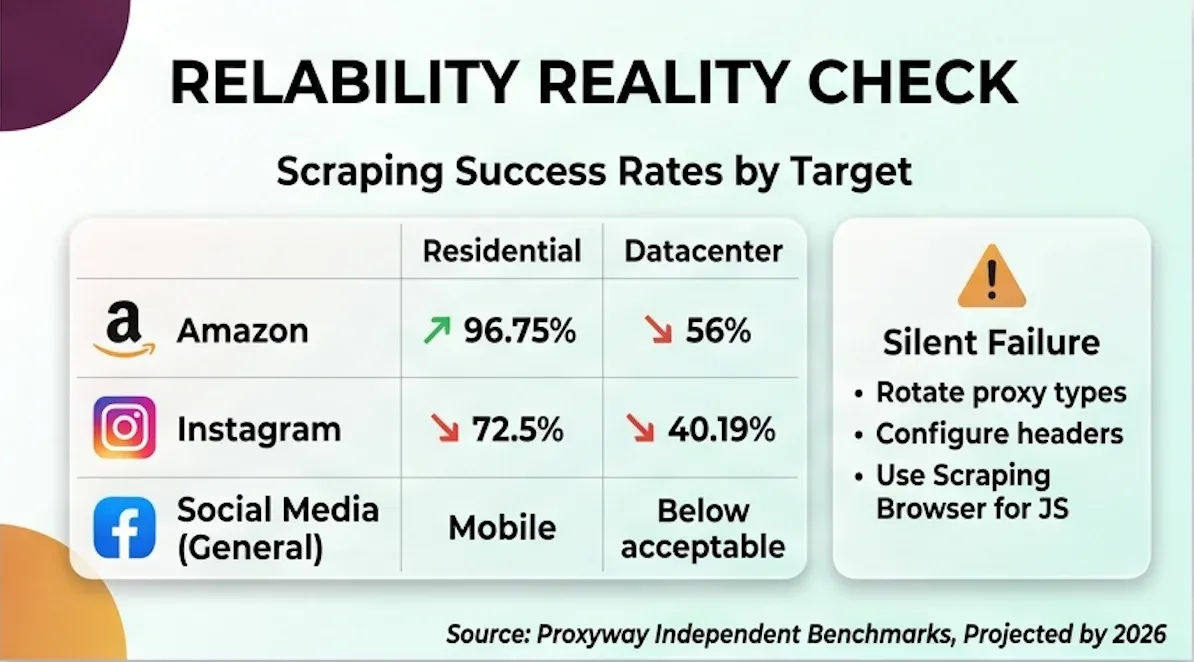
対象カテゴリ別の成功率
| 対象 | プロキシ種別 | 成功率 | 出典 |
|---|---|---|---|
| 多くの商用サイト | Residential | 98〜99% | Proxyway |
| Amazon | Residential | 96.75% | Proxyway |
| Amazon | Datacenter(共有) | 56% | Proxyway |
| Amazon | Datacenter(専用) | 65% | Proxyway |
| Residential | 72.5%(応答12.56秒) | webscraping.blog | |
| Mobile | 40.19%(17.58秒) | webscraping.blog | |
| Web Unlocker | 99.3% | 各種 | |
| ソーシャルメディア全般 | Mobile | 十分ではない | Proxyway: 「成功より失敗の方が多く、遅い」 |
Residential プロキシは多くの商用サイトでよく機能します。でも、保護の強い EC サイト(Amazon を datacenter で扱うと56%)、ソーシャルメディア(Instagram を mobile で扱うと40%)、Cloudflare や PerimeterX のような強力な WAF の背後にあるサイトでは成功率が大きく落ちます。
も補足的な示唆を与えています。Bright Data は 400M 超の residential IP をうたっていますが、テストでは Proxyway が見つけられた英国プロキシは約3,000、オーストラリアは1,000未満でした。つまり、地域ごとの厚みにはかなり差があるということです。
サイレント失敗の問題
これはかなり見落としやすいリスクです。明確な「ブロック」エラーではなく、対象サイトが一見すると正しいデータを返してくることがあります。ただしそれは不完全だったり、古かったりします。Bright Data 自身のドキュメントでもこの現象に触れており、「対象サイトが防御を更新すると、スクレイパーは静かに失敗し、空欄や古いデータを返しながら正常に動いているように見える」と説明しています。パイプラインに流し込んだ後で初めて、データが壊れていたと気づくこともあります。
成功率を上げる実践的な方法
IP だけでなく、プロキシ種別も切り替える。 residential でうまくいかないなら、ISP や mobile を試してください。プロキシ種別が変わると、検知パターンも変わります。
適切な request headers と user-agent を設定する。 実ブラウザの動きをまねるのが大事です。デフォルト設定は、アンチボットシステムが最初にチェックするポイントです。
JavaScript が重い対象には Web Unlocker ではなく Scraping Browser を使う。 Web Unlocker は JavaScript を描画しません。一方、Scraping Browser はクラウド上で完全な Chrome インスタンスを動かします。クライアントサイド描画が必要なサイト(今どきの SPA の多く)では、この違いが成功と失敗を分けます。
Bright Data のリアルタイムネットワークステータスページを確認する。 障害中にジョブを流さないためです。地味に見えますが、ネットワーク品質が落ちている時間帯に、数百ドルを失敗リクエストで溶かしたチームを何度も見てきました。
プロキシ設定のトラブルシュートを一切したくないチームなら、 のようなノーコード代替が、プロキシ種別の選定、ヘッダー設定、リトライロジックの管理をせずに、AI エンジンでアンチボット対策を処理してくれます。
500人超の実ユーザーは何を言っているか:Bright Data レビューの集約傾向
Trustpilot、G2、Capterra、Reddit にある何百件ものレビューを読み込み、都合のいい抜粋ではなく、実際の傾向を特定しました。
各プラットフォームの評価
| プラットフォーム | 評価 | レビュー数 | 注目点 |
|---|---|---|---|
| Trustpilot | 4.4/5 | 約969件 | 5つ星85%、1つ星9%(評価が二極化) |
| G2 | 4.7/5 | 約295件 | Proxy Network カテゴリで1位 |
| Capterra | 4.7/5 | 68件 | 検証済みレビュー |
Trustpilot の分布はかなり二極化しています。専任のアカウントマネージャーが付く企業チームは5つ星レビューを残しがちです。一方で、コストと複雑さの壁にぶつかった小規模チームは1つ星レビューを書きます。その中間はあまり多くありません。
カテゴリ別の評価傾向
This paragraph contains content that cannot be parsed and has been skipped.
ユーザーが Bright Data を高く評価する点
IPプールの大きさとグローバルなカバレッジは、一貫して高評価です。 次のように報告しています。「Bright Data 導入前は、無料プロキシでの成功率は68%でした。導入後は99.2%まで上がり、1日あたりの取得ページ数は約2,000から約18,000へ増えました。」
企業向けサポートも高く評価されています。専任アカウントマネージャー、支払い顧客への平均14分のメール応答、そして先回りした監視体制です。Proxy Manager ツールは、ローテーション、ターゲティング、セッション管理を細かく制御したい技術チームに重宝されています。
コンプライアンスと倫理的ソーシングは法人顧客にとって重要であり、Bright Data の SOC 2 Type II、ISO 27001、第三者監査は実際に安心材料となります。
ユーザーが不満を感じる点
最大の不満は価格です。 ユーザーは代替手段より「3〜10倍高い」と表現します。 次のように書かれていました。「競合の価格データを集めたいだけの個人起業家が Bright Data を使うと、その複雑さと料金体系は、観葉植物に消火ホースで水をやるようなものに感じる。」
オンボーディングの負担は現実的です。 KYC では政府発行IDのアップロードが必要で、完全な認証を完了できるのは登録済み企業のみです。フリーランスは英語でのビデオ通話が必要です。ある Trustpilot レビューでは、「英語を話す面接官とのビデオセッションを求められる」のは国際ユーザーにとって大きな障壁だと指摘されていました。公式には承認まで「48時間」とされていますが、ユーザー報告では3日〜3週間かかることがあります。
サポート品質は二極化しています。 企業アカウントは迅速な対応を受けられますが、無償トライアルのアカウントは 。電話サポートは月額 $5K 超のティアに限定されています。ある G2 レビューでは、「Bright Data の web unlocker 製品は、難易度の高いサイトを解除できると謳っていたが、実際は失敗率が非常に高く、失敗した問い合わせにも課金された」と書かれていました。
ダッシュボードの複雑さは非技術者を遠ざけます。 UI は強力ですが、同時に圧倒されるほど複雑です。複数のレビューで、慣れるまでの学習期間は「数日〜数週間」と表現されていました。Capterra のレビュアー(Emiliano G., 2025年9月)は、「製品の劣化が急速に進み、今ではデータ取得の失敗率が高い」と記しています。
Bright Data の AI シフト:Browser.AI、MCP Server、Deep Lookup
2025年7月2日、Bright Data は3つの AI 製品を同時に発表し、明確に「プロキシ提供会社」から「AIデータインフラ」へとポジションを再定義しました。CEO の Or Lenchner は、「今日の LLM の限界は知能ではなく、アクセスにある」と述べています。
は、AI エージェント向けのサーバーレス・クラウドベース自律ブラウザです。"Amazon に行って、ワイヤレスヘッドホンを検索し、上位20件を集めて" のように自然文で指示すると、Bright Data のクラウド上で本物の Chrome を起動し、人間のように操作し、CAPTCHA を処理し、構造化データを返します。 では、難易度の高い7つのドメインを通じて98.44%の成功率が示されました。料金は、無料(2 GB)、Starter $39/月(10 GB)、PAYG $8/GB です。
は、Anthropic の Model Context Protocol 標準上に構築されたオープンソースのブリッジです。Claude、Cursor、Windsurf、LangChain、LlamaIndex などの AI アシスタントが、Bright Data の30以上のスクレイピングツールへ直接アクセスできます。15,000人の開発者による3か月の限定ベータを経て、2025年8月に公開されました。 です。戦略的には、これが Bright Data にとって最重要製品かもしれません。AI エージェントのエコシステム全体における、デフォルトの Web データ層としての立ち位置を作るからです。
は、1,000以上の公開ソースを検索し、引用付きの構造化データを表形式で返す自然言語リサーチエンジンです。まだベータ版で、クレジットカード不要の無料検索は5回まで。マッチした結果だけに課金されるモデルです。リード獲得や競合インテリジェンスで90〜100%のマッチ率が報告されています。
Bright Data の AI 機能は本当に必要か?
AI モデルを構築している、LLM を Web データで学習させている、機械学習向けのリアルタイムデータパイプラインを組んでいる——そういう場合には、これらのツールは本当に強力で、検討する価値があります。
でも、Webサイトから構造化データがほしいビジネスチーム——営業リード、商品価格、物件一覧、競合分析——にとっては、AIインフラは価値に対して複雑さとコストを増やしすぎることがあります。AI 製品にはそれぞれ異なる課金モデルがあり、総コストの予測はどんどん難しくなります。
そうしたチームには、 の方が本質的にシンプルです。AI がページを読み取り、抽出項目を自動提案し、2クリックで構造化データを出力します。Excel、Google Sheets、Airtable、Notion へエクスポートできます。MCP プロトコルも、クラウドブラウザ基盤も、帯域課金もありません。これはプロキシの代替というより、インフラ抜きでほしい「最終結果」そのものです。
Bright Data vs. Oxylabs vs. Smartproxy vs. Thunderbit:どれを選ぶべきか
私が見つけた Bright Data レビューの多くは、比較表を飛ばしてしまっています。そこで、抽象的な順位ではなく、用途との相性を基準にした比較を用意しました。
| 機能 | Bright Data | Oxylabs | Decodo (Smartproxy) | ScraperAPI | Thunderbit |
|---|---|---|---|---|---|
| 最適用途 | 大規模エンタープライズ向けプロキシ基盤 | エンタープライズ向けプロキシ + スクレイピング API | ミッドマーケット向けプロキシチーム | APIベースのスクレイピング(開発者向け) | ノーコードAIデータ抽出 |
| Residential IPs | 400M+ | 175M+ | 125M+ | N/A(APIサービス) | N/A(ブラウザベース) |
| ノーコード対応 | 限定的(Scraper IDE) | 限定的(Web Scraper API) | 事前構築済みスクレイパー | APIのみ | はい(中核機能) |
| 学習コスト | 高い | 中〜高 | 中程度 | 低い | 非常に低い |
| 無料枠 | 7日間トライアル(KYC必須) | 2K件の無料結果 | 7日間トライアル | 月1Kクレジット無料 | 月6ページ無料 |
| 開始価格 | residential 約$8/GB | residential 約$4/GB | PAYG 約$8.50/GB | $49/月 | 無料枠 + $38/月 Pro |
| 主な強み | 最大級のIPプール、最も広い製品群 | 99.95% のスクレイパー成功率、OxyCopilot AI | 最も分かりやすい UX | 最も簡単な API 連携 | 2クリックAIスクレイピング、無料エクスポート |
| 主な弱点 | 複雑、高価、学習曲線が急 | アンブロッカーが弱め(40〜50%)、導入コスト高 | ビジュアルスクレイパーなし、エンタープライズ要件に弱い | ソーシャルサイトで成功率0% | プロキシ基盤ではない |
Bright Data と Oxylabs の比較
どちらもエンタープライズ級です。 しており、Bright Data の 400M+ には及びません。Oxylabs は residential のエントリー価格がやや高め(約 $4/GB のボリューム価格帯に対し、Bright Data は $8 の PAYG)ですが、mobile プロキシの性能はより安定しています(90〜98% 対、Bright Data の結果は不安定)。Bright Data は製品の広さで勝ち、Oxylabs は焦点を絞った実行力とシンプルな UX で勝ちます。プロキシとスクレイピング API の両方が必要なら、Oxylabs の Web Scraper API は平均 99.95% の成功率を誇りますが、応答時間はやや遅め(約17.5秒)です。
Bright Data と Smartproxy(Decodo)の比較
(2025年4月に Smartproxy からリブランディング)は、ミッドマーケット向けによりシンプルで安価な選択肢です。 はかなり強いシグナルです。PAYG は $8.50/GB からですが、ボリューム価格は競争力があります(エンタープライズ 1TB で $1.50/GB)。ダッシュボードはよりシンプルで、導入も速い(Bright Data の KYC と比べて3日間の無料トライアル)。Bright Data の製品迷路を避けつつ、十分なプロキシを使いたいチームにとって、Decodo は本気で検討する価値があります。
Thunderbit のようなノーコード AI スクレイパーが向いているケース
結局はこの1点に尽きます。必要なのはプロキシ基盤ですか? それともデータですか?
このレビューを読む多くの人——営業、オペレーション、マーケットリサーチ、EC 分析担当——がほしいのはデータです。IPプールではありません。帯域管理でもありません。プロキシローテーションのアルゴリズムでもありません。
データです。
100件の商品一覧を取得する場合のワークフローを比べてみましょう。
| ステップ | Bright Data(技術寄りの手順) | Thunderbit |
|---|---|---|
| セットアップ | アカウント作成、支払い登録、ダッシュボード操作、KYC 完了 | Chrome 拡張機能 をインストール |
| 設定 | 製品を選ぶ(Unlocker? Browser? Scraper?)、適合性を調査 | 対象ページを開く |
| 作成 | スクレイパーを書くかテンプレートを選び、セレクタを設定 | AI Suggest Fields をクリック |
| 実行 | 実行、失敗のデバッグ、セレクタ調整 | Scrape をクリック |
| エクスポート | CSV/JSON をダウンロード | Export → Sheets/Excel/Airtable/Notion |
| 所要時間 | 1〜2時間(経験豊富な開発者) | 約5分(誰でも) |
| コスト | API費用 約$1〜5 + 開発時間 | 無料枠または $38/月 Pro |
Thunderbit は、まさにこのギャップを埋めるために作られました。AI がページ構造を読み取り、適切な列を提案し、ページ送りやサブページにも対応し、構造化データとして出力します。プロキシ、ヘッダー、リトライロジックを考える必要はありません。Bright Data のエンタープライズ基盤の代替ではなく、「自分はエンタープライズ基盤が必要だ」と思い込ませる問題群そのものの代替です。
どう判断するか:シンプルなフレームワーク
| あなたの状況 | 最適解 | 理由 | |---|---|---|---| | 独自パイプライン用に大規模なプロキシ基盤が必要 | Bright Data または Oxylabs | 最大級のIPプール、企業向けSLA、コンプライアンスの厳格さ | | エンタープライズの複雑さなしで信頼できるミッドマーケット向けプロキシが必要 | Decodo (Smartproxy) | シンプルなUX、適正価格、125M+ IP | | AI/LLM向けデータパイプラインをリアルタイムWebフィードで構築している | Bright Data AI tools | Browser.AI、MCP Server、データセットマーケットプレイス | | Webサイトから構造化データがほしい — コーディング不要、プロキシ管理不要 | Thunderbit | 2クリックAIスクレイピング、無料エクスポート、インフラ不要 | | スクレイピング用に単一APIを使いたい開発者 | ScraperAPI | 最もシンプルなAPI連携、無料枠あり | | 単発で1回だけ素早くスクレイピングしたい | Thunderbit の無料枠 または ScraperAPI の無料枠 | しがらみなし、すぐ結果が出る |
適切なツールは、チームの技術力、予算、そして実際にデータで何をするかで決まります。ML モデルを動かすデータウェアハウスに流すなら、Bright Data の基盤は理にかなっています。営業用スプレッドシートを埋めたいだけなら、違います。
コンプライアンスと倫理的データ収集についての補足
Bright Data はコンプライアンスをかなり重視しています。これは競合よりも徹底していて、強みでもあり、同時に摩擦の原因でもあります。
認証: SOC 2 Type II(公開ダウンロード可能な SOC 3 あり)、ISO 27001:2022(27017、27018 も含む)、CSA STAR Level 1。インフラは AWS の multi-AZ、通信中は TLS 1.3、保存時は AES-256。 されています。
倫理的なIPソーシング: Residential IP は、パートナーアプリに組み込まれた を通じて提供されます。ユーザーは、広告なしまたはプレミアム体験と引き換えに、待機中の帯域を共有することへ明確に同意します。これは、ユーザーへの説明が不十分だった初期の Hola VPN モデル(2014〜2015年)より、かなり改善されています。
2024年の重要な法的勝利を2つ挙げておく価値があります。
- (2024年1月): Facebook/Instagram の利用規約は、ログアウト状態での公開データのスクレイピングを禁じないと判断。
- (2024年5月): 訴えは棄却。Alsup 判事は、ソーシャルネットワークに公開データの支配権を与えると「情報独占が生まれる恐れがある」と警告しました。
ただし代償として、KYC は丁寧である一方、オンボーディングの負担は実際に存在します。認証を完了できるのは登録済み企業のみ。フリーランスには英語でのビデオ通話が必要です。承認には48時間から3週間かかることがあります。今すぐデータが必要なチームにとっては、かなりのハードルです。
Thunderbit もまた、営業、EC、リサーチのための公開データ収集という正当なビジネス用途に特化しており、KYC や ID 提出は不要です。
2026年に Bright Data は本当に価値があるのか? 正直な結論
Bright Data は最大級の IP プール(400M超)、最も幅広い製品群、最も厳格なコンプライアンス体制、そして運用の正当性を支える2つの重要な法的勝利を持っています。この組み合わせに匹敵する競合はありません。技術リソースがあり、月数万ドル規模の予算を持ち、複雑なスクレイピング基盤が必要な企業チームにとっては、デフォルトの選択肢になる理由があります。
でも、「いちばん大きいツール群」と「自分に最適」は別の話です。
Bright Data が向いているのはこういう場合です。
- 195か国にまたがる都市レベルのジオターゲティングを含む、大規模なプロキシ基盤が必要
- プロキシ設定、リトライロジック、スクレイパー保守を管理する専任の技術スタッフがいる
- 月額 $500 超の最低コミットに対応できる予算がある
- リアルタイム Web データフィードを必要とする AI/LLM データパイプラインを構築している
Bright Data があまり向いていないのはこういう場合です。
- Webサイトから構造化データがほしいだけの小〜中規模チーム
- プロキシ設定や失敗のデバッグを担当する開発者がいない
- 主な重視点が使いやすさとコスト効率である
- 5分でデータを取る方が、5時間かけてインフラを組むよりいい
営業、オペレーション、リサーチのチームで、Webサイトからスプレッドシートまで最短でたどり着きたいなら、 はまったく別のアプローチを取ります。
2クリックの AI 抽出。Excel、Google Sheets、Airtable、Notion への無料エクスポート。KYC なし、プロキシ設定なし、帯域課金なし。
必要なのは、ただデータだけ。
今すぐ を試せます。月6ページまで無料、クレジットカード不要。エンタープライズ向けプロキシ基盤に投資する前に、よりシンプルな方法で必要なものが得られるか確認してみてください。
よくある質問
Bright Data は Web スクレイピングの価格に見合いますか?
400M超の IP、都市レベルのジオターゲティング、コンプライアンス水準のインフラが必要な大規模エンタープライズ運用なら、答えは yes です。Bright Data は、他社が完全には揃えられない機能を提供します。一方で、プロキシ基盤を管理せずに Web サイトからデータを抽出したいだけなら、答えは no です。Thunderbit、ScraperAPI、あるいは IPRoyal のような低価格プロバイダの方が、コストと複雑さの何分の一かで同じ結果にたどり着けます。
Bright Data は正規のサービスで、安全に使えますか?
はい。Bright Data は、SOC 2 Type II 認証、ISO 27001 準拠、(Fortune 500 企業を含む)、そして公開Webデータ収集の合法性を確認した2つの重要な判例(Meta v. Bright Data、X Corp. v. Bright Data)を持つ、実績ある企業です。KYC は正当な利用を担保するための仕組みで、厳格ですが、その分オンボーディングは少し面倒になります。
Bright Data は失敗したリクエストにも課金しますか?
製品によります。Web Unlocker はデフォルトでは成功ベース課金ですが、(手動ヘッダー、cookies、"expect" 要素など)を有効にすると、成功・失敗に関係なくすべて課金されます。Scraping Browser は失敗した試行分も含めた転送帯域で課金されます。SERP API は失敗リクエストには課金しません。
この課金の細かな違いは、ユーザーから最もよく挙がる不満のひとつで、しかも Bright Data は登録時にあまり分かりやすく説明していません。
Bright Data で最も安いプロキシ種別は何ですか?
共有の datacenter プロキシで、 です。ニュースサイト、公開ディレクトリ、政府データなど、保護の弱いサイトに向いています。保護されたサイト向けには、residential は PAYG で $8.00/GB から(現在のプロモーションコード適用時は $4.00/GB、3か月間有効)。datacenter の専用 IP は $0.90/IP/月からで、100 GB のフェアユースが含まれます。
非技術者にとって最良の Bright Data 代替は何ですか?
です。2クリックで任意の Web サイトから構造化データを抽出できる AI 搭載の Chrome 拡張機能です。"AI Suggest Fields" をクリックすると、AI がページを読み取って列を提案します。"Scrape" をクリックするとデータが取れます。Excel、Google Sheets、Airtable、Notion へ無料でエクスポートできます。プロキシ管理も、コーディングも、KYC も不要です。 では月6ページまで試せ、Pro プランは月額 $38 から。Bright Data の最低コミットよりずっと低コストです。
もっと知る