ウェブの進化スピードって、朝のコーヒーを一気飲みするよりも速いんだよね(しかも自分、結構早飲み派)。2026年の今、ウェブデータの抽出はもう一部のエンジニアだけの特権じゃなくて、営業リスト作成、ECの価格チェック、市場リサーチ、不動産調査など、どんなビジネス現場でも欠かせない武器になってる。し、ピッタリのライブラリやツールを選べば、手作業のムダな時間を一気に短縮して、ライバルよりも早く価値あるデータをゲットできる。
面白いのは、2026年のウェブスクレイピングライブラリは、ノーコードのAI拡張からガチ開発者向けのフレームワークまで、選択肢がめちゃくちゃ豊富なこと。営業がExcelにリードを集めたい時も、オペレーション担当が500SKUを追いかけたい時も、Pythonで自作クローラーを作りたい時も、必ずベストなツールが見つかる。SaaSや自動化の現場で色々なライブラリを試してきた自分が、2026年に知っておきたい注目のウェブスクレイピングライブラリ10選と、選び方のコツを紹介するよ。
2026年に「強い」ウェブスクレイピングライブラリって?
ランキングに入る前に、どんな基準でライブラリを選ぶべきか整理しよう。2026年の優秀なツールには、こんな共通点があるんだ:
- 使いやすさ:プログラミング未経験でも数分で結果が出せる?それともPythonマスターじゃないと無理?
- 動的コンテンツ対応力:JavaScriptで動く最新サイトも抽出できる?静的HTMLだけ?
- 言語・プラットフォーム対応:Python、JavaScript、Javaなど、好きな言語やブラウザで使える?
- スケーラビリティ:数百・数千ページの大量データも安定して処理できる?
- 連携・エクスポート:ExcelやGoogle Sheets、Notionなど、普段使ってるツールと簡単に連携できる?
- AI・自動化:2026年はAI搭載で自然言語から操作できるツールが大きな強み。ビジネスユーザーには特に重要。
現場で求められるのは、スピード・正確さ・手間の少なさ。壊れたスクレイパーの修正や複雑なコードに時間を取られるより、すぐにデータを活用できる方が圧倒的に価値がある。AIやブラウザ自動化の進化で、今や非エンジニアでも開発者の手を借りずにデータ抽出ができる時代だよ(も参考に)。
それじゃ、注目のライブラリを見ていこう!
2026年注目のウェブスクレイピングライブラリ10選
- :ノーコード&AIでブラウザから簡単スクレイピング
- :Pythonで手軽にHTML解析&データ整形
- :大規模・高速クロール&パイプライン構築に最適
- :動的サイトやログイン対応のブラウザ自動化
- :Pythonで超高速XML/HTMLパース
- :jQuery風セレクタでPythonからHTML操作
- :HTTP取得・HTML解析・JSレンダリングを一括で
- :フォーム自動化や簡単なブラウザ操作に
- :Node.jsでヘッドレスChrome自動化
- :Javaで堅牢なHTMLパース
1. Thunderbit
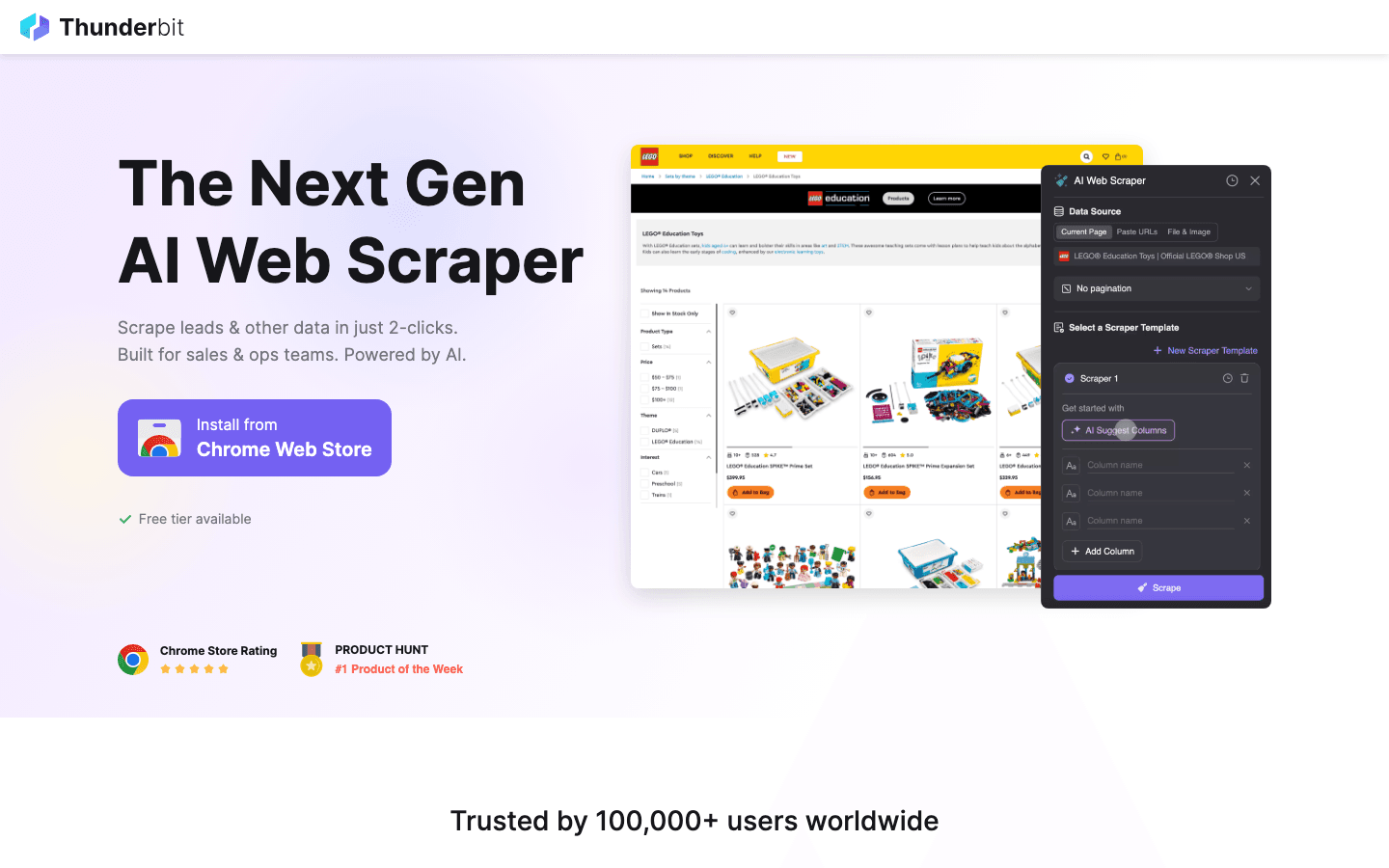
は、コードを書かずにウェブデータを抽出したい人にピッタリなAIウェブスクレイパー。AI搭載のChrome拡張を使えば、「このページの商品名・価格・画像を取りたい」みたいに自然な言葉で伝えるだけ。AIが自動で最適な抽出項目を提案してくれるから、「AIで項目を提案」→必要なら微調整→「スクレイピング開始」をクリック、これだけでOK。
Thunderbitが2026年に選ばれる理由:
- ノーコード&自然言語操作:営業・オペレーション・マーケ・不動産など、誰でも直感的に使える。Python不要。
- AIによる項目自動提案:AIがページを解析して、最適なカラムを自動で抽出。
- サブページ自動巡回:商品やプロフィールなど詳細ページも自動で回ってデータを拡充(もチェック)。
- 人気サイト用テンプレート:Amazon、Zillow、Shopifyなどはワンクリックで抽出OK。
- Excel・Google Sheets・Notion・Airtable連携:抽出データをそのままチームのワークフローに投入できる。
- 34言語対応:グローバルチームにも最適。
- クラウド/ブラウザ両対応:公開サイトはクラウドで高速抽出、ログインが必要な場合はブラウザモードで柔軟に対応。
Thunderbitは世界で3万人以上が利用中。無料プランでも6ページ(トライアルで最大10ページ)までスクレイピングできる。最新のウェブスクレイピングを体験したいなら、まずはここから始めてみて!
2. Beautiful Soup

は、データサイエンティストやアナリストに長年愛されてきたPython用HTMLパースライブラリ。タグが壊れてたり、フォーマットが崩れてるページからでも柔軟にデータを抽出できる。
Beautiful Soupの強み:
- 不規則なHTMLも解析可能:「汚い」ウェブページのデータ整形や抽出に最適(も参考に)。
- 学習コストが低い:Python初心者でもすぐに使いこなせる。
- 柔軟性:RequestsなどのHTTPクライアントと組み合わせて使える。lxmlと併用すれば高速化も。
- 主な用途:静的ページのデータ抽出、データ整形、小規模スクリプトとの連携。
静的ページや複雑なHTMLの整形が必要な時におすすめ。
3. Scrapy

は、Pythonで大規模なクローラーやデータパイプラインを構築できる本格派フレームワーク。数千ページのクロールやリンク追跡、大量データの処理が必要な時に最適。
Scrapyが選ばれる理由:
- 高いモジュール性:複雑なスパイダーやパイプライン、ミドルウェアの構築が可能(も参考に)。
- 大規模案件に強い:市場調査や競合分析など、多数サイトのクロールに最適。
- 非同期&高速:効率的なデータ収集ができる。
- 活発なコミュニティ:プラグインやチュートリアルも豊富。
学習コストはちょっと高めだけど、大規模案件には欠かせない存在。
4. Selenium

は、ブラウザ自動化の定番ツール。ウェブアプリのテストから、ログインやクリック、ポップアップ対応が必要な動的サイトのスクレイピングまで幅広く使われてる。JavaScriptで動くサイトや複雑な操作が必要な時、Seleniumなら実際のユーザーみたいに操作できる(も参考に)。
Seleniumの特徴:
- 実ブラウザを自動操作:Chrome、Firefox、Safari、Edgeなど幅広く対応。
- ログイン・ポップアップ・ユーザー操作もOK:認証後のデータ取得や複数ステップのワークフローにも強い。
- 多言語対応:Python、Java、C#など。
- おすすめ用途:シンプルなスクレイパーがブロックされるサイトや、ユーザー操作の再現が必要な時。
HTTPベースのライブラリより重めだけど、必要な場面では頼れる存在。
5. lxml
は、Pythonで高速にXMLやHTMLをパースできるライブラリ。大量の大きなファイルを高速処理したい時に最適(も参考に)。
lxmlの強み:
- 圧倒的な高速性:大規模データや大きなファイルの処理で他のPythonパーサーを圧倒。
- 堅牢性:XML/HTML両対応で、他ツールとの連携も簡単。
- おすすめ用途:大規模データセットの処理や、Beautiful SoupやScrapyとの併用でさらにパワーアップ。
大量データの高速処理には必須のライブラリ。
6. PyQuery
は、jQueryのセレクタ構文をPythonで使えるようにしたライブラリ。jQueryの$('.class')みたいな直感的な要素選択が、Pythonスクリプトでもできる(も参考に)。
PyQueryのポイント:
- jQuery風セレクタ:フロントエンド経験者には特に分かりやすい。
- 簡潔で読みやすいコード:複雑な選択もシンプルに書ける。
- lxmlと連携:内部的に高速処理を実現。
- おすすめ用途:jQuery感覚でHTML操作したいPython案件に。
ウェブ開発からデータ抽出に移りたい人にもおすすめ。
7. Requests-HTML
は、HTTPリクエスト・HTMLパース・JavaScriptレンダリングまで一括でこなせるPythonライブラリ。
Requests-HTMLの特徴:
- オールインワン:ページ取得、HTML解析、JSレンダリングまで1つで完結。
- 初心者にも優しい:小〜中規模のスクレイピングに最適。
- おすすめ用途:手軽なスクリプトや、動的要素を含むサイトの抽出。
これから始めたい人や、柔軟なツールを探してる人にぴったり。
8. MechanicalSoup

は、ウェブフォームの自動入力や簡単なブラウザ操作をPythonで実現するライブラリ。Beautiful SoupとRequestsの上に作られていて、ログインやフォーム送信などの基本操作が簡単にできる(も参考に)。
MechanicalSoupの便利な点:
- フォーム・ログイン自動化:認証が必要なデータ抽出に最適。
- シンプルなAPI:初心者でもすぐに使える。
- おすすめ用途:繰り返しのブラウザ作業や、フルブラウザ自動化が不要な時。
Seleniumほどのパワーはないけど、軽量で手軽に使える。
9. Puppeteer
は、Node.jsでヘッドレスChrome/Chromiumを操作できるライブラリ。JavaScriptで動的に生成されるサイトや、インタラクティブなページのスクレイピングに最適(も参考に)。
Puppeteerの強み:
- 本格的なブラウザ自動化:クリック・スクロール・フォーム入力など、ユーザー操作を完全再現。
- 動的コンテンツ対応:JavaScriptでデータが生成されるサイトもOK。
- おすすめ用途:EC・SNSなど、従来のスクレイパーが苦手な「現代的」ウェブサイト。
JavaScript開発者や、最新ウェブのデータ抽出には必須。
10. Jsoup
は、JavaでHTMLを解析・抽出する定番ライブラリ。Beautiful SoupのJava版みたいな存在で、Java開発者には欠かせない(も参考に)。
JsoupがJavaチームに選ばれる理由:
- シンプルかつ強力なAPI:数行のコードでデータ抽出・操作ができる。
- 崩れたHTMLも解析:フォーマットが乱れたページもきれいにパース。
- おすすめ用途:Javaベースの業務アプリやバックエンドでのデータ抽出。
Java環境なら迷わず選びたいライブラリ。
ウェブスクレイピングライブラリ比較表
10ライブラリの特徴を一覧で比較:
| ライブラリ | 言語 | 使いやすさ | 動的コンテンツ対応 | AI/ノーコード | 主な用途 | おすすめユーザー |
|---|---|---|---|---|---|---|
| Thunderbit | Chrome拡張 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | あり | 営業、オペ、リサーチ、不動産 | 非エンジニア、ビジネスユーザー |
| Beautiful Soup | Python | ⭐⭐⭐⭐ | ⭐ | なし | HTML解析、データ整形 | Python初心者、アナリスト |
| Scrapy | Python | ⭐⭐⭐ | ⭐⭐ | なし | 大規模クロール、パイプライン | 開発者、大規模データ案件 |
| Selenium | 複数 | ⭐⭐ | ⭐⭐⭐⭐⭐ | なし | ブラウザ自動化、ログイン対応 | QA、動的サイトの抽出 |
| lxml | Python | ⭐⭐⭐ | ⭐ | なし | 高速パース、大容量ファイル | パワーユーザー、大規模データ |
| PyQuery | Python | ⭐⭐⭐⭐ | ⭐ | なし | jQuery風セレクタ | ウェブ開発者、簡潔なスクリプト |
| Requests-HTML | Python | ⭐⭐⭐⭐ | ⭐⭐ | なし | 簡易スクリプト、JSレンダリング | 初心者、小規模案件 |
| MechanicalSoup | Python | ⭐⭐⭐⭐ | ⭐⭐ | なし | フォーム自動化、ログイン | 簡単なブラウザ作業 |
| Puppeteer | Node.js | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | なし | JS中心サイト、自動化 | JS開発者、動的ウェブ抽出 |
| Jsoup | Java | ⭐⭐⭐⭐ | ⭐ | なし | JavaでのHTML解析 | Javaチーム、バックエンド |
ビジネスに最適なウェブスクレイピングライブラリの選び方
どのライブラリを選ぶか迷ったら、自分の経験からこのポイントを参考にしてみて:
- 非エンジニア・ビジネスユーザー:Thunderbitがベスト。AI/ノーコードで数分で結果が出せる。ExcelやSheetsにデータを入れたいだけなら、複雑なツールは不要。
- Python開発者:小規模ならBeautiful SoupやRequests-HTML、大規模ならScrapy。lxmlやPyQueryと組み合わせるとさらに強力。
- ログインや動的コンテンツ対応が必要? Selenium(多言語)やPuppeteer(Node.js)が最適。
- Javaチーム:Javaアプリに組み込むならJsoup一択。
- フォーム自動化や簡単なワークフロー:MechanicalSoupが軽量で使いやすい。
選定時のポイント:
- 技術レベル:Thunderbitみたいなノーコードは非技術者向け。開発者はコードベースの柔軟性を重視。
- データの複雑さ:静的ページならBeautiful SoupやJsoup、動的サイトならSeleniumやPuppeteer。
- 規模感:大規模・高速処理ならScrapyやlxml。
- 連携性:ThunderbitはSheetsやNotion、Airtableへの直接エクスポートで業務効率化。
もっと詳しく知りたい人はも参考にしてみて。
まとめ:最適なツールでウェブデータをフル活用しよう
2026年、ウェブスクレイピングはもうエンジニアやデータサイエンティストだけのものじゃない。AI搭載やノーコードツールの普及で、営業からリサーチまでどんなチームでもウェブのデータ資源を活用できる時代。ピッタリのライブラリを選べば、年間数百時間の業務効率化(も参考)、精度アップ、ビジネスの競争力強化が実現できる。
まずは自分のニーズ(スピード・規模・技術レベル)を整理して、いくつか試してみるのがオススメ。で気軽に始めるのもアリだし、Beautiful SoupやScrapyなどのオープンソースで本格的に挑戦するのもアリ。
さらに詳しいガイドはや、の実践動画もぜひチェックしてみて。
みんなのデータ抽出が、いつもクリーンで構造化されて、すぐに活用できるものになりますように!
よくある質問(FAQ)
1. 2026年、非エンジニアに一番カンタンなウェブスクレイピングライブラリは?
が一番おすすめ。AI搭載のChrome拡張で、自然言語で指示するだけでデータ抽出ができる。コードは一切不要。
2. JavaScript中心や動的サイトのスクレイピングに最適なライブラリは?
(Node.js)や(多言語対応)が最適。実際のブラウザを自動操作して、複雑な動的ページにも対応。
3. Beautiful SoupとScrapyの違いは?
は1ページや小規模案件向けで、特にHTMLが崩れてる時に便利。は大規模クロールや大量データ処理に特化したフレームワーク。
4. 抽出したデータをGoogle SheetsやNotionに直接エクスポートできる?
はい。ならGoogle Sheets、Notion、Airtable、Excelに直接エクスポート可能。他のコード系ライブラリは自分でエクスポート処理を書く必要あり。
5. 自社に最適なウェブスクレイピングライブラリの選び方は?
技術レベル、対象サイトの複雑さ、データ量、連携先などを考慮しよう。ノーコードのThunderbitはビジネスチームに最適。開発者ならScrapy、Beautiful Soup、Puppeteerなどで細かく制御できる。
さらに詳しく知りたい人へ