インターネット上には役立つデータが山ほどありますが、その多くは簡単にダウンロードできる形ではありません。2025年の今、ウェブスクレイピングは一部の技術者だけのものから、価格調査や求人、不動産、競合リサーチなど幅広い分野で欠かせないスキルへと進化しています。ただ、Githubには無数のウェブスクレイピング関連プロジェクトがあり、完成度やメンテ状況もバラバラ。特にエンジニアでない人にとっては、どれを選べばいいのか迷ってしまいますよね。
この記事では、2025年におすすめしたいGithubのウェブスクレイピングプロジェクト15選を、ただ並べるだけでなく、導入のしやすさ・用途の合致度・動的コンテンツ対応・メンテ状況・データ出力形式・想定ユーザーなどの観点から徹底比較します。「もうコードと格闘したくない!」という方には、のようなノーコード&AI搭載ツールがどのように業務ユーザーや非エンジニアの常識を変えているかも紹介します。
Githubウェブスクレイピングプロジェクトの選定基準
正直なところ、Githubのプロジェクトはピンキリです。何万人も使っているものもあれば、週末の実験で終わったものも。今回の選定では、以下のポイントを重視しました:
- Githubスター数&コミュニティ:数千〜9万超のスターがあり、活発なコントリビューターがいること
- 最近の更新状況:2025年時点でメンテナンスされていること
- ドキュメント&使いやすさ:分かりやすい説明やサンプルコード、学習コストの低さ
- 実運用実績:実際のビジネスや研究で使われていること
さらに、スクレイピングの用途やユーザー層は多様なので、各プロジェクトを以下の観点で比較しています:
- 導入・セットアップ難易度:すぐ始められるか、環境構築が必要か
- 用途適合性:EC、ニュース、研究など、どの分野向きか
- 動的ページ対応:JavaScript主体の現代的なサイトに対応できるか
- プロジェクトの健全性:今もメンテナンスされているか
- データ出力形式:業務で使えるデータ形式か、HTMLのままか
- 想定ユーザー:Python初心者、データエンジニア、非エンジニアなど
各プロジェクトにはこれらの観点でタグを付けているので、コーディング好きな方も「Googleスプレッドシートにデータが欲しいだけ!」という方も、自分に合ったものがすぐ見つかります。

導入・セットアップのしやすさ:どれだけ早く始められる?
多くの人にとって一番のハードルは「とにかく動かすまでが大変」という点。ここでは導入難易度を3段階で整理します:
- Plug & Play(すぐ使える):インストールしてすぐ使える。初心者向き。
- 中級(コマンドライン・簡単なコーディング):多少のスクリプトやCLI操作が必要。経験者なら問題なし。
- 上級(ドライバ・アンチボット・本格コーディング):環境構築やドライバ設定、Python/JSの深い知識が必要。
主なプロジェクトの分類は以下の通り:
- Plug & Play:MechanicalSoup(Python)、Nokogiri(Ruby)、Maxun(エンドユーザー向け)
- 中級:Scrapy、Crawlee、Node Crawler、Selenium、Playwright、Colly、Puppeteer、Katana、Scrapling、WebMagic
- 上級:Heritrix、Apache Nutch(Javaや大規模データ基盤が必要)
非エンジニアの方は「Plug & Play」やノーコード系が安心。中級は多少のコーディング経験があれば十分対応できます。
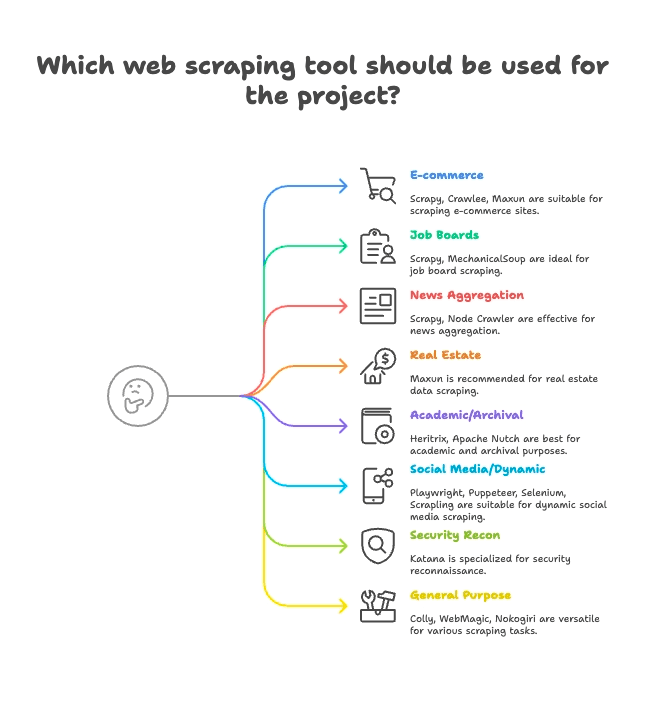
用途別グルーピング:業界・目的に合ったウェブスクレイパーを探す
スクレイパーは用途によって最適なものが異なります。ここでは主な15プロジェクトを得意分野ごとに分類します:
EC・価格監視
- Scrapy:大規模な商品データ収集に最適
- Crawlee:静的・動的ECサイト両対応の万能型
- Maxun:ノーコードで商品リスト抽出が簡単
求人・リクルーティング
- Scrapy:ページネーションや構造化リストに強い
- MechanicalSoup:ログインが必要な求人サイトにも対応
ニュース・コンテンツ集約
- Scrapy:大規模なニュースサイトのクロールに最適
- Node Crawler:静的ニュースの高速収集
不動産
- Thunderbit:AIでリスト+詳細ページも自動取得
- Maxun:物件データのビジュアル選択が可能
学術研究・ウェブアーカイブ
- Heritrix:サイト全体のアーカイブ(WARC形式)
- Apache Nutch:分散クロールで研究データセット作成
SNS・動的コンテンツ
- Playwright, Puppeteer, Selenium:動的フィードやログイン対応
- Scrapling:アンチボット対策サイトのステルススクレイピング
セキュリティ・リコン
- Katana:高速なURL発見やセキュリティクロール
汎用・マルチパーパス
- Colly:Go言語で高速・汎用的なスクレイピング
- WebMagic:Javaベースで多用途に対応
- Nokogiri:Rubyでのカスタムパースに
動的ページ対応力:現代的なサイトもスクレイピングできる?
最近のウェブサイトはJavaScriptで動的にデータを表示するものが主流。ReactやVue、無限スクロール、AJAXなど、普通にスクレイピングすると「何も取れない…」という経験をした方も多いはず。
各プロジェクトの動的コンテンツ対応状況は以下の通り:
- フルJS対応(ヘッドレスブラウザ):
- Selenium:実ブラウザ操作で全JS実行
- Playwright:複数ブラウザ・多言語対応で堅牢
- Puppeteer:Chrome/Firefoxのヘッドレス操作
- Crawlee:HTTPとブラウザ(Puppeteer/Playwright)を切替
- Katana:オプションでJSパース対応
- Scrapling:Playwright連携でステルスJSスクレイピング
- Maxun:内部的にブラウザを利用し動的対応
- JS非対応(静的HTMLのみ):
- Scrapy:Selenium/Playwrightプラグインで拡張可
- MechanicalSoup, Node Crawler, Colly, WebMagic, Nokogiri, Heritrix, Apache Nutch:HTMLのみ取得、JSは不可
ThunderbitのAIはここが強み。動的コンテンツも自動検出・自動取得でき、面倒な設定やプラグイン、セレクタ指定も不要。「AIでフィールド提案」をクリックするだけで、React系サイトでもラクラクデータ取得できます。詳しくはもご覧ください。
プロジェクトの健全性・信頼性:来年も使える?
せっかくワークフローを組んでも、ツールが放置されてしまうと困ります。主なプロジェクトのメンテ状況は:
- 活発にメンテナンス中:
- Scrapy:
- Crawlee:
- Playwright:
- Puppeteer:
- Katana:
- Colly:
- Maxun:
- Scrapling:
- 安定だが更新は緩やか:
- MechanicalSoup:
- Node Crawler:
- WebMagic:
- Nokogiri:
- 専門用途・メンテ緩やか:
- Heritrix:
- Apache Nutch:
ThunderbitはSaaS型なので、コードの放置やメンテ切れの心配は不要。AIやテンプレート、連携機能も常に最新で、オンボーディングやサポートも充実しています。
データ出力・活用:業務で使えるデータ形式に変換できる?
データを取得するだけでなく、チームで使いやすい形式(CSV、Excel、Google Sheets、Airtable、Notion、APIなど)で出力できるかも重要です。
- 構造化出力に対応:
- Scrapy:CSV、JSON、XMLエクスポート
- Crawlee:柔軟なデータセット・ストレージ
- Maxun:CSV、Excel、Google Sheets、JSON API
- Thunderbit:
- 手動でデータ処理が必要:
- MechanicalSoup, Node Crawler, Selenium, Playwright, Puppeteer, Colly, WebMagic, Nokogiri, Scrapling:コードで保存・出力処理が必要
- 特殊な出力:
- Heritrix:WARC(ウェブアーカイブ)
- Apache Nutch:生データをストレージやインデックスへ
Thunderbitの構造化エクスポート&各種連携は、業務ユーザーにとって大きな時短メリット。面倒なCSV整形やコード不要で、すぐにデータ活用できます。
想定ユーザー:どのプロジェクトが誰向き?
全てのツールが全員向けではありません。おすすめのユーザー層は:
- Python初心者:MechanicalSoup、Scrapling(やや上級)
- データエンジニア:Scrapy、Crawlee、Colly、WebMagic、Node Crawler
- QA・自動化担当:Selenium、Playwright、Puppeteer
- セキュリティ研究者:Katana
- Rubyユーザー:Nokogiri
- Java開発者:WebMagic、Heritrix、Apache Nutch
- 非エンジニア・業務チーム:Maxun、Thunderbit
- グロースハッカー・アナリスト:Maxun、Thunderbit
「コードは苦手」「とにかく早く結果が欲しい」ならThunderbitやMaxunが最適。それ以外は自分の言語や用途に合ったものを選びましょう。
Githubウェブスクレイピングプロジェクト15選:詳細比較
ここからは用途別に、各プロジェクトの特徴やタグをまとめてご紹介します。
EC・価格監視・汎用クロール
— 57,100スター、2025年6月更新

- 概要:大規模クロール・スクレイピング向けの非同期Pythonフレームワーク
- 導入:中級(Pythonコーディング、非同期処理)
- 用途:EC、ニュース、研究、複数ページのスパイダー
- JS対応:なし(Selenium/Playwrightプラグインで拡張可)
- メンテ状況:活発
- データ出力:CSV、JSON、XML対応
- ユーザー層:開発者、データエンジニア
- 特徴:拡張性・堅牢性抜群。初心者にはやや難易度高め。
— 17,900スター、2025年

- 概要:静的・動的両対応のNode.js用スクレイピングライブラリ
- 導入:中級(Node/TSコーディング)
- 用途:EC、SNS、業務自動化
- JS対応:あり(Puppeteer/Playwright連携)
- メンテ状況:非常に活発
- データ出力:柔軟なデータセット・ストレージ
- ユーザー層:JS/TS開発チーム
- 特徴:アンチブロック機能、HTTP/ブラウザ切替が簡単
— 13,000スター、2025年6月

- 概要:オープンソースのノーコード型ウェブデータ抽出プラットフォーム
- 導入:中級(サーバー設置)、エンドユーザーは簡単
- 用途:汎用、EC、業務スクレイピング
- JS対応:あり(内部ブラウザ利用)
- メンテ状況:活発
- データ出力:CSV、Excel、Google Sheets、JSON API
- ユーザー層:非エンジニア、アナリスト、チーム
- 特徴:ポイント&クリック操作、階層データもOK、セルフホスト可
求人・リクルーティング・簡易操作
— 4,800スター、2024年

- 概要:フォーム送信や簡単なナビゲーション自動化用Pythonライブラリ
- 導入:Plug & Play(Python、最小限のコード)
- 用途:ログイン必須の求人サイト、静的ページ
- JS対応:なし
- メンテ状況:安定運用
- データ出力:なし(手動)
- ユーザー層:Python初心者、簡易スクリプト
- 特徴:数行でブラウザセッションを再現。動的サイトには非対応。
ニュース集約・静的コンテンツ
— 6,800スター、2024年

- 概要:Cheerioパース搭載の高速サーバーサイドクローラー
- 導入:中級(Nodeコールバック/非同期)
- 用途:ニュース、高速静的スクレイピング
- JS対応:なし(HTMLのみ)
- メンテ状況:中程度(v2ベータ)
- データ出力:なし(ユーザー定義)
- ユーザー層:Node.js開発者、高並列処理ニーズ
- 特徴:非同期クロール、レート制限、jQuery風API
不動産・リスト+詳細ページ取得

- 概要:AI搭載・ノーコード型ウェブスクレイパー(業務ユーザー向け)
- 導入:Plug & Play(Chrome拡張、2クリックで開始)
- 用途:不動産、EC、営業、マーケティング、あらゆるサイト
- JS対応:あり(AIが動的コンテンツ自動検出)
- メンテ状況:常時アップデート、SaaS型
- データ出力:ワンクリックでSheets、Airtable、Notion、CSV、JSON
- ユーザー層:非エンジニア、業務チーム、営業・マーケ担当
- 特徴:AI「フィールド提案」、サブページ取得、即エクスポート、テンプレート、
学術研究・ウェブアーカイブ
— 3,000スター、2023年

- 概要:Internet Archive公式の大規模アーカイブクローラー
- 導入:上級(Javaアプリ、設定ファイル)
- 用途:ウェブアーカイブ、ドメイン全体クロール
- JS対応:なし(取得のみ)
- メンテ状況:安定運用
- データ出力:WARC(ウェブアーカイブファイル)
- ユーザー層:アーカイブ、図書館、研究機関
- 特徴:大規模・堅牢・標準準拠。ターゲット絞り込みには不向き。
— 3,000スター、2024年

- 概要:ビッグデータ・検索エンジン向けオープンソースクローラー
- 導入:上級(Java+Hadoopなど大規模基盤)
- 用途:検索エンジン、ビッグデータ収集
- JS対応:なし(HTTPのみ)
- メンテ状況:活発(Apache)
- データ出力:生データをストレージやインデックスへ
- ユーザー層:エンタープライズ、研究機関
- 特徴:プラグイン構造、分散クロール
SNS・動的コンテンツ・自動化
— 約30,000スター、2025年

- 概要:主要ブラウザ対応の自動操作・スクレイピング&テストツール
- 導入:中級(ドライバ設定、多言語対応)
- 用途:JS主体サイト、テストフロー、SNS
- JS対応:あり(フルブラウザ自動化)
- メンテ状況:活発・成熟
- データ出力:なし(手動)
- ユーザー層:QAエンジニア、開発者
- 特徴:多言語対応、実ユーザー挙動の再現
— 73,500スター、2025年

- 概要:最新ブラウザ自動化・E2Eテスト用フレームワーク
- 導入:中級(多言語スクリプト)
- 用途:モダンWebアプリ、SNS、自動化
- JS対応:あり(ヘッドレス・実ブラウザ両対応)
- メンテ状況:非常に活発
- データ出力:なし(ユーザー実装)
- ユーザー層:堅牢なブラウザ制御が必要な開発者
- 特徴:クロスブラウザ、自動待機、ネットワークインターセプト
— 90,900スター、2025年

- 概要:Chrome/Firefox自動化用の高機能API
- 導入:中級(Nodeスクリプト)
- 用途:ヘッドレスChromeスクレイピング、動的コンテンツ
- JS対応:あり(Chrome/Firefox)
- メンテ状況:活発(Chromeチーム)
- データ出力:なし(コードで実装)
- ユーザー層:Node.js開発者、フロントエンド
- 特徴:豊富なブラウザ制御、スクリーンショット、PDF、ネットワーク制御
— 5,400スター、2025年6月

- 概要:アンチボット機能搭載のステルス高速スクレイピング
- 導入:中級(Pythonコード)
- 用途:ステルススクレイピング、アンチボット、動的サイト
- JS対応:あり(Playwright連携)
- メンテ状況:活発・最先端
- データ出力:なし(手動)
- ユーザー層:Python開発者、ハッカー、データエンジニア
- 特徴:ステルス、プロキシ、アンチブロック、非同期
セキュリティリコン
— 13,800スター、2025年

- 概要:セキュリティ・自動化・リンク発見用の高速クローラー
- 導入:中級(CLIツールまたはGoライブラリ)
- 用途:セキュリティクロール、エンドポイント発見
- JS対応:あり(ヘッドレスモード)
- メンテ状況:活発(ProjectDiscovery)
- データ出力:テキスト(URLリスト)
- ユーザー層:セキュリティ研究者、Go開発者
- 特徴:高速・並列・JSパース対応
汎用・マルチパーパススクレイピング
— 24,300スター、2025年

- 概要:Go言語向けの高速・エレガントなスクレイピングフレームワーク
- 導入:中級(Goコード)
- 用途:高性能・汎用スクレイピング
- JS対応:なし(HTMLのみ)
- メンテ状況:活発・最近も更新
- データ出力:なし(ユーザー実装)
- ユーザー層:Go開発者、パフォーマンス重視
- 特徴:非同期、レート制限、分散クロール
— 11,600スター、2023年

- 概要:Scrapy風の柔軟なJavaクローラーフレームワーク
- 導入:中級(Java、シンプルAPI)
- 用途:Javaでの汎用ウェブスクレイピング
- JS対応:なし(Seleniumで拡張可)
- メンテ状況:コミュニティ活発
- データ出力:プラグインパイプライン
- ユーザー層:Java開発者
- 特徴:スレッドプール、スケジューラ、アンチブロック
— 6,200スター、2025年

- 概要:Ruby向けの高速・ネイティブHTML/XMLパーサー
- 導入:Plug & Play(Ruby gem)
- 用途:RubyアプリでのHTML/XMLパース
- JS対応:なし(パースのみ)
- メンテ状況:活発・Rubyの進化に追従
- データ出力:なし(Rubyで整形)
- ユーザー層:Rubyist、Rails開発者
- 特徴:高速・標準準拠・セキュア
一目で分かる機能比較表
Thunderbitも含め、主要プロジェクトの比較表はこちら:
| プロジェクト | 導入難易度 | 用途 | JS対応 | メンテ状況 | データ出力 | ユーザー層 | Githubスター数 |
|---|---|---|---|---|---|---|---|
| Scrapy | 中級 | EC、ニュース | なし | 活発 | CSV, JSON, XML | 開発者、データエンジニア | 57.1k |
| Crawlee | 中級 | 万能、業務自動化 | あり | 非常に活発 | 柔軟なデータセット | JS/TS開発チーム | 17.9k |
| MechanicalSoup | Plug & Play | 静的、フォーム | なし | 安定 | なし(手動) | Python初心者 | 4.8k |
| Node Crawler | 中級 | ニュース、静的 | なし | 中程度 | なし(手動) | Node.js開発者 | 6.8k |
| Selenium | 中級 | JS主体、テスト | あり | 活発 | なし(手動) | QAエンジニア、開発者 | ~30k |
| Heritrix | 上級 | アーカイブ、研究 | なし | 安定 | WARC | アーカイブ、機関 | 3k |
| Apache Nutch | 上級 | ビッグデータ、検索 | なし | 活発 | 生データ | 企業、研究 | 3k |
| WebMagic | 中級 | Java、汎用 | なし | コミュニティ活発 | プラグインパイプライン | Java開発者 | 11.6k |
| Nokogiri | Plug & Play | Rubyパース | なし | 活発 | なし(手動) | Rubyist | 6.2k |
| Playwright | 中級 | 動的、自動化 | あり | 非常に活発 | なし(手動) | 開発者、QA | 73.5k |
| Katana | 中級 | セキュリティ、発見 | あり | 活発 | テキスト出力 | セキュリティ、Go開発者 | 13.8k |
| Colly | 中級 | 高速、汎用 | なし | 活発 | なし(手動) | Go開発者 | 24.3k |
| Puppeteer | 中級 | 動的、自動化 | あり | 活発 | なし(手動) | Node.js開発者 | 90.9k |
| Maxun | 簡単(ユーザー) | ノーコード、業務 | あり | 活発 | CSV, Excel, Sheets, API | 非エンジニア、アナリスト | 13k |
| Scrapling | 中級 | ステルス、アンチボット | あり | 活発 | なし(手動) | Python開発者、ハッカー | 5.4k |
| Thunderbit | Plug & Play | ノーコード、業務 | あり | SaaS型・常時更新 | Sheets, Airtable, Notion | 非エンジニア、業務ユーザー | N/A |
Thunderbitが非エンジニア・業務ユーザーに最適な理由
正直、Githubの多くのオープンソースプロジェクトは「開発者のための開発者向け」。導入や運用、トラブル対応も自己責任です。もしあなたが業務担当者やマーケター、営業、もしくは「とにかく結果が欲しい!」という方なら、Thunderbitはまさに理想的な選択肢です。
Thunderbitが選ばれる理由:
- ノーコード&AIの手軽さ: をインストールし、「AIでフィールド提案」をクリックするだけ。Pythonもセレクタも「pip install」も不要。
- 動的ページも自動対応:ThunderbitのAIはReactやVue、AJAXなど最新サイトも自動で解析・抽出。
- サブページも一括取得:商品やリストの詳細ページもAIが自動で巡回し、1つの表にまとめてくれます。
- 業務向けエクスポート:Google Sheets、Airtable、Notion、CSV、JSONにワンクリックで出力。リード獲得や価格調査、コンテンツ集約に最適。
- 常時アップデート&サポート:SaaS型なので「放置される」心配なし。オンボーディングやチュートリアル、テンプレートも充実。
- 想定ユーザー:非エンジニア、業務チーム、スピードと信頼性重視の方に最適。
Thunderbitは世界3万人以上のユーザーに支持され、Accenture、Grammarly、Pumaなどのチームでも導入実績あり。Product Huntでも「今週のNo.1プロダクト」に選ばれました。
「スクレイピングってこんなに簡単だったの?」と驚きたい方は、。
まとめ:2025年に最適なウェブスクレイピングの選び方
結論として、Githubには強力なウェブスクレイピングツールが揃っていますが、その多くは開発者向け。コーディングが得意ならScrapy、Crawlee、Playwright、Collyなどが最強。学術やセキュリティ分野ならHeritrix、Nutch、Katanaが定番です。
一方、「業務で使いたい」「分析や営業でデータがすぐ欲しい」なら、Thunderbitが圧倒的におすすめ。セットアップ不要、メンテ不要、ノーコードで即結果が得られます。
まずは自分のスキルや用途に合ったGithubプロジェクトを試してみるのも良いでしょう。あるいは、学習コストを省いてすぐに成果を出したいなら、して今日から始めてみてください。
さらにウェブスクレイピングを深く知りたい方は、の他の記事もおすすめです。例えばや、など。
みなさんのスクレイピングが、いつも構造化され、クリーンで、すぐに使えるデータでありますように。もし困ったら、Githubに頼るのも良し、ThunderbitのAIに任せるのもアリですよ。