
私が最初に取り組んだスクレイピング案件は、Pythonで手書きしたスクリプト、共有プロキシ、そして祈りで成り立っていました。3日ごとに壊れていました。
2026年の今、スクレイピングAPIは、プロキシ、レンダリング、CAPTCHA、リトライといった面倒な部分を引き受けてくれます。だから、こちらで気にする必要はありません。価格監視からAI学習用データのパイプラインまで、あらゆる仕組みの土台になっています。
ただし、ここでひとつ大きな変化があります。ThunderbitのようなAI駆動のツールによって、開発者でない人にとっては、これまで多くのAPIユースケースが不要になりつつあるのです。この点は後ほど詳しく触れます。
ここでは、私が使ったもの、あるいは評価したスクレイピングAPIを10個紹介します。各ツールの得意分野、弱点、そしてそもそもAPIが不要なケースまで見ていきましょう。
なぜ従来型のウェブスクレイピングAPIではなく、Thunderbit AIを検討すべきなのか?
APIの一覧に入る前に、まずは本題に触れておきましょう。AIを活用した自動化です。私は長年、チームの面倒な作業の自動化を支援してきましたが、コード依存のAPIを飛ばしてThunderbitのようなAIエージェントに直接行く企業が増えているのには、ちゃんと理由があります。
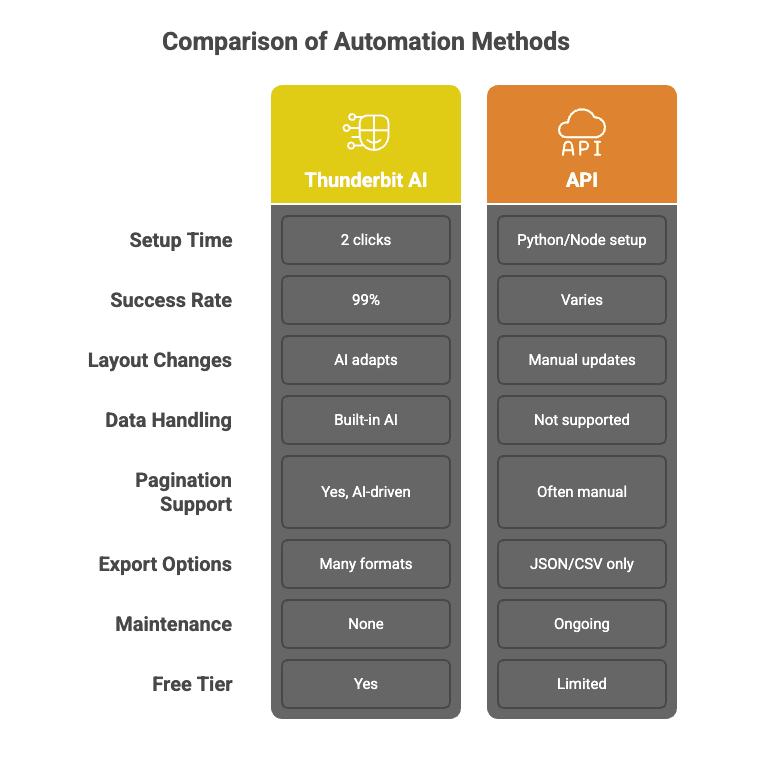
Thunderbitが従来のウェブスクレイピングAPIと違う点は次のとおりです。
-
99%の成功率を実現するウォーターフォール型API呼び出し
ThunderbitのAIは、単一のAPIを呼んでうまくいくことを祈るだけではありません。ウォーターフォール方式を採用し、ジョブごとに最適なスクレイピング手法を自動で選び、必要に応じて再試行し、99%の成功率を保証します。手に入るのはデータであって、頭痛の種ではありません。
-
ノーコード、2クリックで完了するセットアップ
Pythonスクリプトを書いたり、APIドキュメントを読み込んだりする必要はありません。Thunderbitなら「AIで項目を提案」と「スクレイプ」をクリックするだけ。それで終わりです。うちの母でも使えるはずです(いまだに「クラウド」は悪天候のことだと思っていますが)。
-
バッチスクレイピング:高速かつ高精度
ThunderbitのAIモデルは、何千もの異なるウェブサイトを並列で処理し、それぞれのレイアウトにその場で適応します。まるで大量のインターンを雇ったようなものですが、コーヒーブレイクを求められることはありません。
-
メンテナンス不要
Webサイトはしょっちゅう変わります。従来のAPIはどうでしょう。壊れます。Thunderbitなら、AIが毎回ページを新しく読み取るので、サイトのレイアウト変更やボタン追加のたびにコードを修正する必要がありません。
-
個別最適化されたデータ抽出と後処理
データのクレンジング、ラベル付け、翻訳、要約が必要ですか? Thunderbitなら抽出の一部としてそれらを実行できます。イメージとしては、1万ページのWebページをChatGPTに放り込み、完全に整ったデータセットとして返してもらうようなものです。
-
サブページとページネーションのスクレイピング
ThunderbitのAIはリンクをたどり、ページネーションを処理し、サブページのデータで表を充実させることもできます。しかもカスタムコードなしで可能です。
-
無料のデータエクスポートと各種連携
Excel、Google Sheets、Airtable、Notionへエクスポートしたり、CSV/JSONとしてダウンロードしたりできます。課金の壁も、面倒もありません。
ざっくり比較すると、こんな感じです。
実際の動きを見たい方は、をチェックしてみてください。
データスクレイピングAPIとは?
基本に少し戻りましょう。データスクレイピングAPIとは、ゼロからスクレイパーを自作しなくても、Webサイトからデータをプログラム経由で抽出できるツールのことです。最新の価格、レビュー、掲載情報などを取得するロボットを送り出し、整った構造化データ(通常はJSONかCSV)として回収してくれる、と考えると分かりやすいでしょう。
どう動くのでしょうか? 多くのスクレイピングAPIは、回転プロキシ、CAPTCHA解決、JavaScriptレンダリングといった厄介な部分を処理してくれます。なので、こちらは本当に必要なデータに集中できます。URLなどを指定してリクエストを送ると、APIがコンテンツを返し、そのまま業務フローに使える状態にしてくれます。
主なメリット:
- 速度: 1分あたり何千ページものスクレイピングが可能です。
- 拡張性: 1万件の商品を監視したい? 問題ありません。
- 連携性: CRM、BIツール、データウェアハウスに最小限の手間で組み込めます。
ただし、後で見るように、すべてのAPIが同じ品質というわけではありませんし、どれも「設定したら放置」で済むほど単純ではありません。
これらのAPIをどう評価したか
私は現場でかなりの時間を費やしてきました。テストして、壊して、ときにはうっかり自分のサーバーをDDoSしてしまったこともあります(昔のITチームには内緒です)。今回の一覧では、次の点を重視しました。
- 信頼性: 難しいサイトでも実際に動くか
- 速度: 大規模運用時にどれだけ速く結果を返せるか
- 価格: スタートアップにとって手頃か、エンタープライズでもスケールできるか
- 拡張性: 数百万件のリクエストに耐えられるか、それとも100件で落ちるのか
- 開発者向けの使いやすさ: ドキュメントは分かりやすいか。SDKやコード例はあるか
- サポート: 何か問題が起きたときに助けは得られるか(そして、問題は起きます)
- ユーザーフィードバック: マーケティング文句ではなく、実際の利用者の声
また、実機テスト、レビュー分析、Thunderbitコミュニティからのフィードバックもかなり重視しました(かなり目が肥えています)。
2026年に検討する価値がある10のAPI
メインイベントに入りましょう。2026年時点で、ビジネスユーザーと開発者向けにおすすめできるウェブスクレイピングAPIとプラットフォームを、最新の内容でまとめました。
1. Oxylabs
 概要:
概要:
Oxylabsは、エンタープライズ向けウェブデータ抽出の重量級チャンピオンです。巨大なプロキシプールと、SERPからECまで何でもそろう専用APIを備えており、Fortune 500企業や、規模が大きくても安定性を求める人たちの定番です。
主な機能:
- 195か国以上をカバーする巨大なプロキシネットワーク(住宅用、データセンター、モバイル、ISP)
- 反ボット、CAPTCHA解決、ヘッドレスブラウザレンダリング付きのスクレイパーAPI
- ジオターゲティング、セッション維持、高精度データ(成功率95%超)
- OxyCopilot:パース用コードやAPIクエリを自動生成するAIアシスタント
価格:
単一APIは月額約49ドルから、オールインワンアクセスは月額149ドルから。最大5,000リクエストまで使える7日間の無料トライアル付き。
ユーザーフィードバック:
G2でと高評価で、信頼性とサポートが特に評価されています。難点は、価格が高めなこと。ただし、払うだけの価値はあります。
2. ScrapingBee
 概要:
概要:
ScrapingBeeは開発者の強い味方です。シンプルで、手頃で、用途が絞られています。URLを送れば、ヘッドレスChrome、プロキシ、CAPTCHAを処理し、レンダリング済みページ、あるいは必要なデータだけを返してくれます。
主な機能:
- ヘッドレスブラウザレンダリング(JavaScript対応)
- IPローテーションとCAPTCHA解決の自動化
- 厳しいサイト向けのステルスプロキシプール
- 最小限のセットアップでOK。APIを呼ぶだけ
価格:
月約1,000回の呼び出しまで使える無料枠あり。有料プランは5,000リクエストで月額約29ドルから。
ユーザーフィードバック:
G2では安定してを獲得しています。開発者はシンプルさを気に入っていますが、非エンジニアには少し機能がそぎ落とされすぎていると感じるかもしれません。
3. Apify
 概要:
概要:
Apifyは、ウェブスクレイピングのスイスアーミーナイフです。JavaScriptやPythonでカスタムスクレイパー(「Actor」)を作ることもできますし、人気サイト向けの膨大な既成Actorライブラリを使うこともできます。必要に応じて、どこまでも柔軟に使えます。
主な機能:
- ほぼあらゆるサイト向けのカスタム/既成スクレイパー(Actor)
- クラウド基盤、スケジューリング、プロキシ管理を標準搭載
- JSON、CSV、Excel、Google Sheetsなどへのデータ出力
- 活発なコミュニティとDiscordサポート
価格:
月5ドル分のクレジットが付いた永久無料プランあり。有料プランは月額39ドルから。
ユーザーフィードバック:
G2/Capterraでを獲得。開発者には柔軟性が好評ですが、初心者には学習コストがあります。
4. Decodo(旧Smartproxy)
 概要:
概要:
Decodo(Smartproxyからリブランド)は、コストパフォーマンスと使いやすさが売りです。堅牢なプロキシ基盤と、一般Web、SERP、EC、SNS向けのスクレイピングAPIをひとつのサブスクリプションにまとめています。
主な機能:
- すべてのエンドポイントをまとめた統合スクレイピングAPI(個別アドオン不要)
- Google、Amazon、TikTokなど向けの専用スクレイパー
- プレイグラウンドとコード生成機能を備えた使いやすいダッシュボード
- 24時間365日のライブチャットサポート
価格:
25,000リクエストで月額約50ドルから。1,000リクエスト付きの7日間無料トライアルあり。
ユーザーフィードバック:
「価格に対する価値」と迅速なサポートが高く評価されています。G2では。
5. Octoparse
 概要:
概要:
Octoparseは、ノーコード分野の王者です。コードが苦手でもデータが好きなら、このポイント&クリック型のデスクトップアプリ(クラウド機能付き)で、スクレイパーを視覚的に組み立て、ローカルでもクラウドでも実行できます。
主な機能:
- ビジュアルなワークフロー構築。データ項目はクリックで選択するだけ
- クラウド抽出、スケジューリング、自動IPローテーション
- 人気サイト向けテンプレートと、カスタムスクレイパー用マーケットプレイス
- Octoparse AI:RPAとChatGPTを統合し、データクレンジングやワークフロー自動化に対応
価格:
ローカルタスク最大10件まで使える無料プランあり。有料プランは月額119ドルから(クラウド機能、無制限タスク)。プレミアム機能は14日間無料で試せます。
ユーザーフィードバック:
G2でを獲得。非エンジニアに人気ですが、上級者には物足りない場面もあります。
6. Bright Data
 概要:
概要:
Bright Dataはまさに大本命です。規模、速度、あらゆる機能を求めるなら、このプラットフォームが最有力です。世界最大級のプロキシネットワークと強力なスクレイピングIDEを備え、エンタープライズ用途に向けて作られています。
主な機能:
- 1億5,000万超のIP(住宅用、モバイル、ISP、データセンター)
- WebスクレイパーIDE、既製データコレクター、すぐ購入できるデータセット
- 高度な反ボット機能、CAPTCHA解決、ヘッドレスブラウザ対応
- コンプライアンスと法務を重視(Ethical Web Data initiative)
価格:
従量課金制で、1,000リクエストあたり約1.05ドル。プロキシは3〜15ドル/GB。多くの製品で無料トライアルあり。
ユーザーフィードバック:
性能と機能は高評価ですが、価格と複雑さが小規模チームにはハードルになることがあります。
7. WebAutomation
 概要:
概要:
WebAutomationは、非開発者向けに設計されたクラウドベースのプラットフォームです。既成抽出ツールのマーケットプレイスとノーコードビルダーを備えており、コードではなくデータが欲しいビジネスユーザーに最適です。
主な機能:
- 人気サイト向けの既成抽出ツール(Amazon、Zillowなど)
- クリック操作で使えるノーコード抽出ビルダー
- クラウドベースのスケジューリング、データ配信、保守を標準搭載
- 行単位の料金体系(抽出した分だけ支払い)
価格:
プロジェクトプランは月額74ドル(年間約40万行)、従量課金は1,000行あたり1ドル。1,000万クレジット付きの14日間無料トライアルあり。
ユーザーフィードバック:
使いやすさと分かりやすい価格設定が好評です。サポートも親切で、保守はチーム側が対応してくれます。
8. ScrapeHero
 概要:
概要:
ScrapeHeroは、もともとカスタムスクレイピングのコンサルティング会社として始まり、現在はセルフサービス型のクラウドプラットフォームを提供しています。人気サイト向けの既成スクレイパーを使うことも、完全運用代行の案件を依頼することもできます。
主な機能:
- ScrapeHero Cloud:Amazon、Google Maps、LinkedInなど向けの既成スクレイパー
- ノーコード運用、スケジューリング、クラウド配信
- 独自要件向けのカスタムソリューション
- プログラム連携用のAPIアクセス
価格:
クラウドプランは月額5ドルから。カスタム案件は1サイトあたり550ドルから(買い切り)。
ユーザーフィードバック:
信頼性、データ品質、サポートが高く評価されています。DIYから運用代行へスケールしたい場合に向いています。
9. Sequentum
 概要:
概要:
Sequentumは、エンタープライズ向けのスイスアーミーナイフです。コンプライアンス、監査性、大規模運用を前提に設計されています。SOC-2認証、監査証跡、チームコラボレーションが必要なら、これが本命です。
主な機能:
- ローコードのエージェントデザイナー(クリック操作+スクリプト)
- クラウドSaaSまたはオンプレミス展開
- プロキシ管理、CAPTCHA解決、ヘッドレスブラウザを標準搭載
- 監査証跡、ロールベースアクセス、SOC-2対応
価格:
従量課金制(実行時間6ドル/時間、エクスポート0.25ドル/GB)、Starterプランは月額199ドル。登録時に5ドル分の無料クレジット付き。
ユーザーフィードバック:
企業ユーザーには、コンプライアンス機能と拡張性が特に好評です。学習コストはありますが、サポートとトレーニングは非常に充実しています。
10. Grepsr
 概要:
概要:
Grepsrは、運用代行型のデータ抽出サービスです。必要なものを伝えるだけで、スクレイパーの構築、実行、保守まで全部任せられます。技術的な手間をかけずにデータが欲しい企業にぴったりです。
主な機能:
- 運用代行抽出(「Grepsr Concierge」)— 設定から保守まで一式対応
- スケジューリング、監視、データダウンロード用のクラウドダッシュボード
- 複数の出力形式と連携(Dropbox、S3、Google Drive)
- リクエスト単位ではなく、データレコード単位で課金
価格:
Starter packは350ドル(1回限りの抽出)。継続サブスクリプションは個別見積もりです。
ユーザーフィードバック:
手放しで使える点と