
ウェブ上にはデータがあふれています。とはいえ、1,000件もの商品一覧や競合の価格ページをひたすらコピー&ペーストして回る時間なんて、誰にもありません。Linuxを使っているなら(私も自動化や開発作業の大半はLinuxです)、このプラットフォームがデータドリブンなチームにとって強力な基盤だということは、すでにご存じのはずです。実際、、さらに。ただ、ここで難しいのは、自分のワークフローに本当に合うLinux向けのウェブスクレイパーを見つけることです。非技術系のビジネスユーザーでも、筋金入りの開発者でも、干し草の山から針を探すような感覚になるはずです。
そこで今回は、2026年版・Linux向けウェブスクレイピングツール18選をまとめました。Thunderbit(そう、私たちのチームが作ったあのツールです)のようなAI搭載・ノーコード製品から、ScrapyやBeautiful Soupのような定番の開発者向けフレームワークまで、この一覧を見れば、試行錯誤のストレスなしで、自分に最適なLinux向けウェブスクレイパーをすばやく選べます。
Linux向けウェブスクレイピングツールがビジネスユーザーに重要な理由
はっきり言いましょう。手作業のデータ収集は、生産性を大きく削ります。調査によると、コピペに頼るチームは毎週何時間も失い、エラー率は5%近くまで膨らみます。これは、コストの高いミスや機会損失につながる典型例です()。Linuxは安定性、セキュリティ、柔軟性に優れているため、デスクトップでもサーバーでもクラウドでも、24時間365日動かす必要があるスクレイパーの実行基盤として最適です。
Linux向けウェブスクレイピングツールの代表的なビジネス用途:
- リード獲得: 営業チームがディレクトリ、SNS、レビューサイトから新しい連絡先を取得し、手作業の入力を省けます()。
- 価格監視: ECチームが競合の価格や在庫データを自動取得し、自社価格を常に最適化できます。
- 競合調査: マーケティングやオペレーション部門が、商品リリース、レビュー、SEOキーワードを追跡し、「勘頼み」から脱却できます。
- 市場インテリジェンス: アナリストがニュース、フォーラム、SNSデータを集約して、トレンドをリアルタイムで把握します。
- ワークフロー自動化: 一部のツール、特にAI搭載ツールは、Linuxマシン上からフォーム入力やダッシュボード操作まで自動化できます。
最大の利点は、適切なLinux向けウェブスクレイピングツールが、開発者だけでなく非技術系ユーザーにも力を与えられることです。ウェブデータを活用して、より賢く、より速い意思決定ができるようになります。
Linux向けに最適なウェブスクレイパーの選び方
Linux上では、すべてのスクレイパーが同じというわけではありません。私が重視したのは次のポイントです。
- Linux対応: ここで紹介するツールはすべて、Linux上でネイティブ実行できるか、ブラウザ経由で使えるか、Wineやクラウドアクセスなどの簡単な回避策で動作します。
- 使いやすさ: 自然言語のAIプロンプトから、視覚的なクリック操作UIまで、非エンジニアでも素早く成果を出せるツールを優先しました。ただし、完全な制御を求めるパワーユーザーも見逃していません。
- データ抽出力: 動的コンテンツ、ページネーション、サブページ、さまざまなデータ型に対応できるか。スクレイピング対策を突破できるか。
- 拡張性と自動化: スケジューリング、クラウドスクレイピング、分散クロールは、本格的なデータプロジェクトに欠かせません。
- 連携とエクスポート: CSV、Excel、Google スプレッドシート、APIに出力できるか。データを外に出せなければ意味がありません。
- 価格とライセンス: 無料、オープンソース、有料まで、個人創業者から大企業チームまで、あらゆる予算帯に合う選択肢があります。
- コミュニティとサポート: アクティブなユーザーベース、充実したドキュメント、素早いサポートは、トラブル発生時に大きな差を生みます。
実際のユーザーフィードバック、業界レビュー、そして私自身がこれらのツールを使ってきた経験も織り込みました。では、一覧を見ていきましょう。
1. Thunderbit
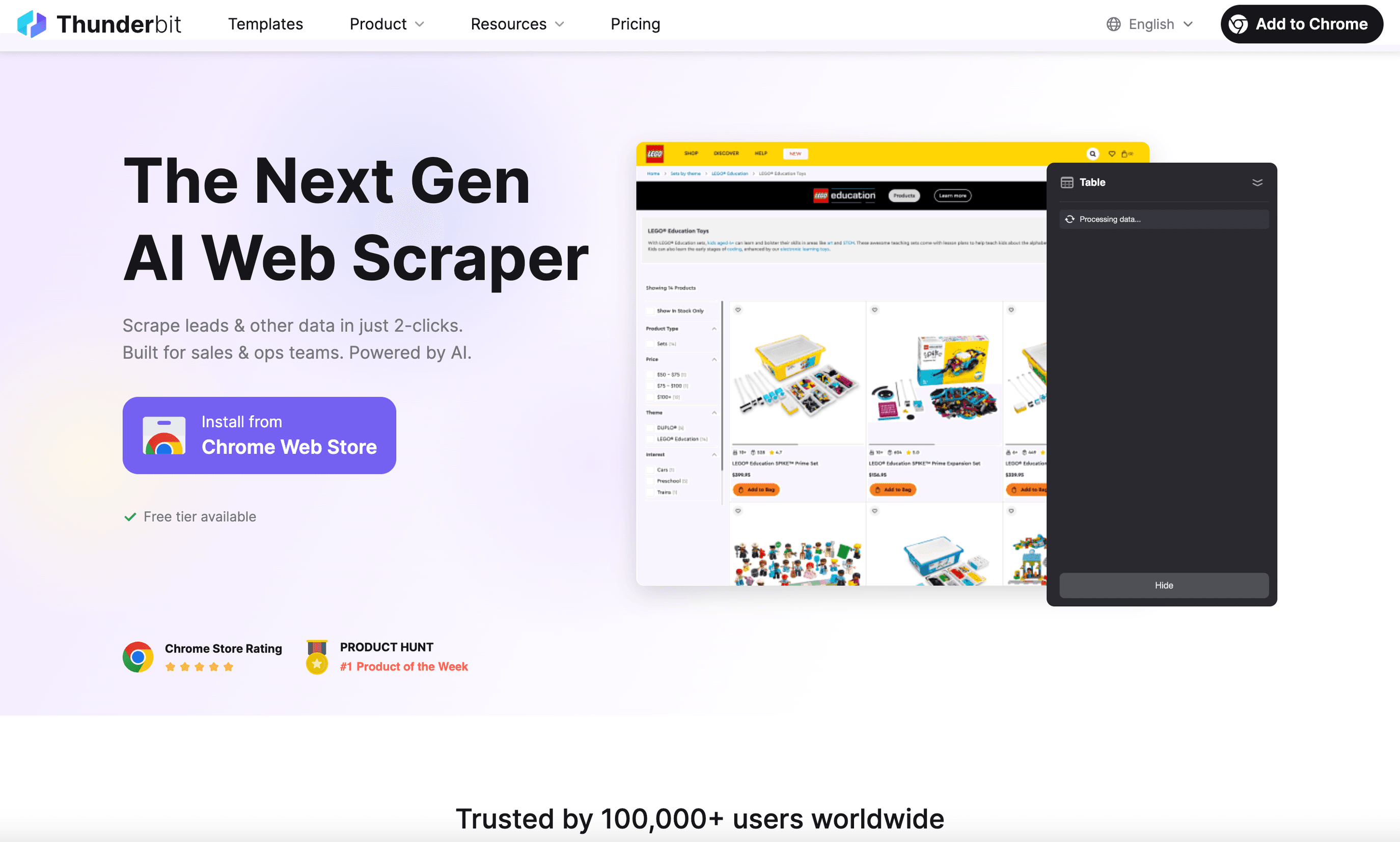 は、Linux向けのウェブスクレイパーを探しているビジネスユーザーにとって、私の最有力候補です。というのも、実際に使いやすいからです。として動作し、Linux上でも問題なく使えます(ChromeまたはChromiumを開くだけです)。しかも、たった2クリックであらゆるWebサイトからデータを抽出できます。
は、Linux向けのウェブスクレイパーを探しているビジネスユーザーにとって、私の最有力候補です。というのも、実際に使いやすいからです。として動作し、Linux上でも問題なく使えます(ChromeまたはChromiumを開くだけです)。しかも、たった2クリックであらゆるWebサイトからデータを抽出できます。
Thunderbitが際立つ理由:
- 自然言語プロンプト: 「このページから商品名と価格をすべて抽出して」のように欲しい内容を伝えるだけで、あとはThunderbitのAIが処理します。
- AIによる項目提案: 1回クリックするだけでページを解析し、列やデータ型を提案してくれます。手動で項目を選ぶ必要はありません。
- サブページ・ページネーションのスクレイピング: もっと詳細が必要ですか? Thunderbitなら各サブページ(商品詳細ページなど)を巡回して、表を自動で拡張できます。
- クラウドまたはローカルでのスクレイピング: クラウドでは一度に最大50ページまで取得でき、ログインが必要なサイトではブラウザモードも使えます。
- 即時エクスポート: Excel、Google スプレッドシート、Airtable、Notion、CSV、JSONへワンクリックで出力できます。しかも常に無料です。
- 便利な追加機能: メールアドレス、電話番号、画像を1クリックで抽出できます。AIオートフィルでフォーム入力も自動化できます。
価格: 無料プランあり(6〜10ページを取得可能)。有料プランは500行で月額15ドルからです()。ユーザーからは「学習コストがほぼない」「何時間もの作業を数分に変えてくれる」と高く評価されています()。大量処理では分割実行が必要になる場合がありますが、ほとんどのビジネス用途では非常に大きな時短効果があります。
Linux互換性: 100%。LinuxデスクトップやサーバーでChrome/Chromiumを使うだけです。
おすすめの用途: できるだけ早く、簡単に始めたい非技術系ビジネスユーザー(営業、マーケティング、オペレーション)。
2. Scrapy
 は、柔軟でスケーラブルなLinux向けウェブスクレイパーを求めるPython開発者にとっての定番です。オープンソースで、非常に高速な非同期クロールができ、小規模なスクレイピングから大規模な分散クロールまで対応できます。
は、柔軟でスケーラブルなLinux向けウェブスクレイパーを求めるPython開発者にとっての定番です。オープンソースで、非常に高速な非同期クロールができ、小規模なスクレイピングから大規模な分散クロールまで対応できます。
主な機能:
- 非同期・高速クロールで、数千ページ規模の取得に最適です。
- 拡張性が高い: プロキシ、CAPTCHA対応などのプラグインがあります。
- Pythonのデータスタックと連携しやすい: JSON、CSV、データベース、pandasへ出力できます。
- Cookie、セッション、自動スロットリングに対応。
価格: 100%無料のオープンソースです。
Linux互換性: ネイティブ対応(pipでインストール可能)。サーバーやコンテナでも快適に動きます。
おすすめの用途: カスタムの大規模スクレイパーを作る開発者。
注意: 非エンジニアには学習コストがありますが、Pythonを使えるならScrapyは非常に強力です。
3. Beautiful Soup
 は、HTMLとXMLの解析に使う軽量なPythonライブラリです。手早くスクレイピングしたいときや、扱いづらいWebページを整形したいときの定番です。
は、HTMLとXMLの解析に使う軽量なPythonライブラリです。手早くスクレイピングしたいときや、扱いづらいWebページを整形したいときの定番です。
主な機能:
- シンプルで人にやさしいAPIなので、初心者にも向いています。
- requestsと相性が良いため、ページ取得と組み合わせやすいです。
- 壊れたHTMLも柔軟に処理します。
価格: 無料のオープンソースです。
Linux互換性: 100%(純粋なPython)
おすすめの用途: 小〜中規模のスクレイピングや解析を行う開発者、データサイエンティスト。
制限: JavaScriptや動的コンテンツには対応しません。必要に応じてSeleniumやPuppeteerと組み合わせてください。
4. Selenium
 は、昔からある定番のブラウザ自動化フレームワークです。Chrome、Firefox、その他のブラウザを操作して、動的でJavaScriptの多いサイトをスクレイピングできます。
は、昔からある定番のブラウザ自動化フレームワークです。Chrome、Firefox、その他のブラウザを操作して、動的でJavaScriptの多いサイトをスクレイピングできます。
主な機能:
- 実ブラウザを自動操作できるため、ログイン、クリック、スクロールなど、人間のような操作が可能です。
- Python、Java、C#などをサポート。
- ヘッドレスモードでLinuxサーバー上でも実行できます。
価格: 無料のオープンソースです。
Linux互換性: 完全対応(適切なブラウザドライバーを入れるだけです)。
おすすめの用途: QAエンジニア、スクレイピング開発者、ユーザー行動の再現が必要な人。
注意: HTTPベースのスクレイパーより重くて遅いですが、必要なデータを取るには唯一の方法になることもあります。
5. Puppeteer
 は、Google製のNode.jsライブラリで、ヘッドレスChrome/Chromiumを制御できます。Seleniumに似ていますが、よりモダンなJavaScript APIを備え、Chromeの機能と密接に統合されています。
は、Google製のNode.jsライブラリで、ヘッドレスChrome/Chromiumを制御できます。Seleniumに似ていますが、よりモダンなJavaScript APIを備え、Chromeの機能と密接に統合されています。
主な機能:
- JavaScriptの実行、動的コンテンツの処理、スクリーンショット撮影ができます。
- 高速・安定・使いやすいため、Node.js開発者に向いています。
- ネットワークリクエストの傍受や不要リソースのブロックが可能です。
価格: 無料のオープンソースです。
Linux互換性: Chromiumを自動でインストールし、デフォルトでヘッドレス動作します。
おすすめの用途: モダンなWebアプリやシングルページサイトを扱う開発者。
6. Octoparse
 は、ドラッグ&ドロップ式のインターフェースと豊富なテンプレートを備えたノーコードのウェブスクレイパーです。デスクトップアプリはWindows/Mac限定ですが、Linuxユーザーはブラウザ経由でOctoparseのクラウドプラットフォームを使うか、WineでWindows版を動かせます。
は、ドラッグ&ドロップ式のインターフェースと豊富なテンプレートを備えたノーコードのウェブスクレイパーです。デスクトップアプリはWindows/Mac限定ですが、Linuxユーザーはブラウザ経由でOctoparseのクラウドプラットフォームを使うか、WineでWindows版を動かせます。
主な機能:
- Amazon、eBay、Zillowなど向けの既製スクレイピングテンプレートが100以上あります。
- 視覚的なワークフロー設計で、クリック操作だけでスクレイパーを作れます。
- クラウドスクレイピングとスケジューリングで、処理はOctoparseのサーバーに任せられます。
- Excel、CSV、JSON、データベースへ出力可能。
価格: 無料プランあり(機能制限あり)。有料プランは月額75〜89ドルからです。
Linux互換性: クラウド/ウェブアクセス、デスクトップアプリはWine経由。
おすすめの用途: ECやマーケットプレイスのデータをすぐに取りたい非エンジニア。
7. PhantomJS
 は、かつて軽量なブラウザ自動化の定番だったヘッドレスWebKitブラウザです。現在は非推奨ですが、レガシー用途や簡単な作業ではLinux上でも今なお動作します。
は、かつて軽量なブラウザ自動化の定番だったヘッドレスWebKitブラウザです。現在は非推奨ですが、レガシー用途や簡単な作業ではLinux上でも今なお動作します。
主な機能:
- JavaScriptでスクリプト化可能。
- ある程度のJavaScriptを処理でき、スクリーンショットやPDFも出力できます。
- GUI不要。
価格: 無料のオープンソースです。
Linux互換性: ネイティブバイナリ。
おすすめの用途: レガシープロジェクト、またはChromeをインストールできない環境。
注意: もうメンテナンスされていないため、最新のサイトではうまく動かないことがあります。
8. ParseHub
 は、Linuxネイティブアプリを備えた視覚的なクロスプラットフォーム型ウェブスクレイパーです。複雑で動的なサイトをスクレイピングしたい非エンジニアに最適です。
は、Linuxネイティブアプリを備えた視覚的なクロスプラットフォーム型ウェブスクレイパーです。複雑で動的なサイトをスクレイピングしたい非エンジニアに最適です。
主な機能:
- ポイント&クリックのインターフェースで、要素を選び、ワークフローを視覚的に構築できます。
- 動的コンテンツ、地図、無限スクロールなどに対応。
- クラウド実行とスケジューリング。
- CSV、JSON、API経由での出力に対応。
価格: 無料プラン(5プロジェクト)あり。有料プランは月額189ドルからです。
Linux互換性: Linux、Windows、Mac向けのネイティブアプリがあります。
おすすめの用途: コードを書かずに制御したいアナリストや、やや技術寄りのユーザー。
9. Kimurai
 は、LinuxをネイティブサポートするRuby向けウェブスクレイピングフレームワークです。Ruby開発者向けのScrapyのような存在です。
は、LinuxをネイティブサポートするRuby向けウェブスクレイピングフレームワークです。Ruby開発者向けのScrapyのような存在です。
主な機能:
- マルチブラウザ対応: Headless Chrome、Firefox、PhantomJS、通常のHTTPを利用できます。
- 高い同時実行性を実現する非同期処理。
- スパイダーを記述しやすい洗練されたRuby DSL。
価格: 無料のオープンソースです。
Linux互換性: 100%(Ruby)
おすすめの用途: Ruby開発者やRailsチームで、カスタムかつ高同時実行のスクレイピングが必要な場合。
10. Apify
 は、オープンソースSDKと、すぐ使える「actor」のマーケットプレイスを備えたクラウドベースのウェブスクレイピングプラットフォームです。スクレイパーはLinuxマシン上でもクラウド上でも実行できます。
は、オープンソースSDKと、すぐ使える「actor」のマーケットプレイスを備えたクラウドベースのウェブスクレイピングプラットフォームです。スクレイパーはLinuxマシン上でもクラウド上でも実行できます。
主な機能:
- Node.js、Pythonなど向けのSDK。
- 既製スクレイパーのマーケットプレイス。
- クラウド実行、スケジューリング、API連携。
価格: 無料プランあり。クラウド利用は従量課金です。
Linux互換性: CLI/SDKはLinuxで動作し、クラウドプラットフォームはブラウザ経由で使えます。
おすすめの用途: カスタム開発とクラウド基盤の両方を使いたい開発者。
11. Colly
 は、速度と効率を重視して作られたGoベースのウェブスクレイピングフレームワークです。Go開発者なら、まずこれを検討するとよいでしょう。
は、速度と効率を重視して作られたGoベースのウェブスクレイピングフレームワークです。Go開発者なら、まずこれを検討するとよいでしょう。
主な機能:
- 超高速かつ並列なスクレイピングで、1コアあたり毎秒1,000件以上のリクエストも可能です。
- 丁寧なクロール(robots.txtを尊重)、セッション/Cookie管理。
- メモリ使用量が少ない。
価格: 無料のオープンソースです。
Linux互換性: ネイティブなGoバイナリ。
おすすめの用途: 高性能なスクレイピングが必要なGo開発者。
12. PySpider
 は、Web UI付きのPythonクローラーシステムです。ブラウザからクロールの管理、スケジューリング、監視ができます。
は、Web UI付きのPythonクローラーシステムです。ブラウザからクロールの管理、スケジューリング、監視ができます。
主な機能:
- スクリプト作成と監視のためのWebベースUI。
- 分散クロール、スケジューリング、リトライ。
- データベースやメッセージキューと連携可能。
価格: 無料のオープンソースです。
Linux互換性: Linuxでの導入向けに設計されています。
おすすめの用途: Web UIで複数のスクレイピング案件を管理したいチーム。
13. WebHarvy
 は、Windows向けの視覚的なポイント&クリック型スクレイパーですが、LinuxユーザーはWine経由で実行できます。パターン検出機能と買い切りモデルで知られています。
は、Windows向けの視覚的なポイント&クリック型スクレイパーですが、LinuxユーザーはWine経由で実行できます。パターン検出機能と買い切りモデルで知られています。
主な機能:
- ブラウズしてクリックするだけでデータを選択でき、コーディング不要。
- リストのパターンを自動検出。
- CSV、JSON、XML、SQLへ出力。
価格: 約139ドルの買い切りライセンス。
Linux互換性: WineまたはVMで動作。
おすすめの用途: すぐ使える視覚的なスクレイパーが欲しい初心者や個人事業主。
14. OutWit Hub
 は、ウェブスクレイピング向けのLinuxネイティブGUIアプリケーションです。データパターンを自動認識し、強力な抽出・自動化機能を備えています。
は、ウェブスクレイピング向けのLinuxネイティブGUIアプリケーションです。データパターンを自動認識し、強力な抽出・自動化機能を備えています。
主な機能:
- リンク、画像、表、メールなどを自動検出。
- カスタム抽出用のスクリプトエディタ。
- マクロ自動化とスケジューリング。
価格: 無料版(機能制限あり)、Proライセンスは約50〜100ドル。
Linux互換性: Linux、Windows、Mac向けのネイティブアプリ。
おすすめの用途: 多少の技術知識がある非エンジニアで、デスクトップGUIのスクレイパーを使いたい人。
15. Portia
 は、Scrapinghubによるオープンソースの視覚的ウェブスクレイパーです。ブラウザ上で動作し、ページに注釈を付けてスクレイパーを学習させられます。
は、Scrapinghubによるオープンソースの視覚的ウェブスクレイパーです。ブラウザ上で動作し、ページに注釈を付けてスクレイパーを学習させられます。
主な機能:
- 視覚的抽出のためのブラウザベースUI。
- カスタムプロジェクトでScrapyと連携。
- オープンソースで拡張可能。
価格: 無料のオープンソースです。
Linux互換性: ブラウザベースなので、どのOSでも使えます。
おすすめの用途: Scrapy連携付きのオープンソース視覚スクレイピングを求めるユーザー。
16. Content Grabber
 は、Windows向けのエンタープライズ級の視覚スクレイパーですが、Wineまたは仮想化を使えばLinuxでも動かせます。
は、Windows向けのエンタープライズ級の視覚スクレイパーですが、Wineまたは仮想化を使えばLinuxでも動かせます。
主な機能:
- 高度なロジック用のビジュアルエディタとC#スクリプト。
- 複数エージェントの管理とスケジューリング。
- データベース、APIなどと連携可能。
価格: ライセンスは数千ドル規模。サーバー版は月額69ドルから。
Linux互換性: WineまたはVM経由。
おすすめの用途: 多数のスクレイピング案件を管理する代理店や大規模チーム。
17. Helium
 は、Seleniumによる自動化を簡単にするPythonライブラリです。ブラウザ操作をより人間らしく、扱いやすくするために設計されています。
は、Seleniumによる自動化を簡単にするPythonライブラリです。ブラウザ操作をより人間らしく、扱いやすくするために設計されています。
主な機能:
click("Login")やwrite("email")のような直感的なコマンド。- ChromeとFirefoxを自動操作。
- 手早いスクリプト作成や自動化タスクに最適。
価格: 無料のオープンソースです。
Linux互換性: Linuxで動作します(Seleniumベース)。
おすすめの用途: Seleniumが少し面倒に感じるPythonユーザー。
18. Dexi.io
 は、クラウドベースのデータ抽出・自動化プラットフォームです。ブラウザ経由で利用できるため、Linuxユーザーはインストール不要で使えます。
は、クラウドベースのデータ抽出・自動化プラットフォームです。ブラウザ経由で利用できるため、Linuxユーザーはインストール不要で使えます。
主な機能:
- スクレイピングと自動化のための視覚的ワークフロー設計。
- スケジューリング、データ変換、API連携。
- エンタープライズ級の拡張性とサポート。
価格: スタンダードは月額119ドルから。大規模利用向けには上位プランがあります。
Linux互換性: Webアプリなので、どのOSでも動作します。
おすすめの用途: スケーラブルで統合性の高いWebデータ抽出を必要とするプロフェッショナルや企業。
Linux向けウェブスクレイピングツールの比較表
| ツール | タイプ / 主な機能 | 最適な用途 | 価格 | Linux互換性 |
|---|---|---|---|---|
| Thunderbit | AI Chrome拡張、2クリック、サブページ、クラウド/ローカル | 非技術系ビジネスユーザー | 無料、月額15ドル〜 | ✔ Linux上のChrome |
| Scrapy | Pythonフレームワーク、非同期、CLI、高い拡張性 | 開発者、大規模なカスタムスクレイパー | 無料 | ✔ ネイティブ |
| Beautiful Soup | Pythonライブラリ、シンプルなHTML/XML解析 | 開発者、データサイエンティスト、小規模タスク | 無料 | ✔ ネイティブ |
| Selenium | ブラウザ自動化、JavaScriptの多いサイト対応 | QA、開発者、動的コンテンツ | 無料 | ✔ ネイティブ |
| Puppeteer | Node.js、ヘッドレスChrome、JSレンダリング | Node開発者、モダンWebアプリ | 無料 | ✔ ネイティブ |
| Octoparse | ノーコード、ドラッグ&ドロップ、クラウドテンプレート | 非エンジニア、EC | 無料、月額75ドル〜 | ◐ クラウド/Wine |
| PhantomJS | ヘッドレスWebKit、JavaScriptでスクリプト化可能 | レガシー、軽量、Chrome不要 | 無料 | ✔ ネイティブ |
| ParseHub | 視覚的、クロスプラットフォーム、ポイント&クリック | アナリスト、やや技術寄りのユーザー | 無料、月額189ドル〜 | ✔ ネイティブ |
| Kimurai | Rubyフレームワーク、マルチブラウザ、非同期 | Ruby開発者、高同時実行 | 無料 | ✔ ネイティブ |
| Apify | クラウドプラットフォーム、SDK、マーケットプレイス | 開発者、カスタムとクラウドの併用 | 無料枠、従量課金 | ✔ ネイティブ/クラウド |
| Colly | Goフレームワーク、高速、並列 | Go開発者、高性能 | 無料 | ✔ ネイティブ |
| PySpider | Python、Web UI、スケジューリング、分散 | チーム、複数プロジェクト | 無料 | ✔ ネイティブ |
| WebHarvy | 視覚的、パターン検出、買い切りライセンス | 初心者、個人事業主 | 約139ドル買い切り | ◐ Wine/VM |
| OutWit Hub | ネイティブGUI、データ自動検出、スクリプト機能 | 非エンジニア、デスクトップGUI | 無料、Proは50〜100ドル | ✔ ネイティブ |
| Portia | オープンソース、視覚的、ブラウザベース | オープンソース、Scrapy連携 | 無料 | ✔ ブラウザ |
| Content Grabber | エンタープライズ、視覚的、スクリプト、マルチエージェント | 代理店、大規模チーム | $$$、月額69ドル〜 | ◐ Wine/VM |
| Helium | Python、簡略化されたSelenium、直感的API | Pythonユーザー、手早い自動化 | 無料 | ✔ ネイティブ |
| Dexi.io | クラウド、視覚的ワークフロー、スケジューリング、API | エンタープライズ、拡張性の高い自動化 | 月額119ドル〜 | ✔ ブラウザ |
Linux向けに最適なウェブスクレイパーの選び方: 重要な検討ポイント
自分に合ったツールを選ぶには、必要なこととスキルを照らし合わせるのが基本です。
- 技術スキルのレベル: 非エンジニアならThunderbit、ParseHub、Octoparse、OutWit Hubが有力です。開発者ならScrapy、Puppeteer、Colly、Kimuraiでより高い自由度を得られます。
- データの複雑さ: 静的ページならBeautiful SoupやCollyが高速でシンプルです。動的でJavaScriptの多いサイトなら、Selenium、Puppeteer、またはJavaScript対応の視覚ツールが必要です。
- 規模と頻度: 単発作業ならノーコードツールやクラウドスクレイパーで十分です。定期実行や大規模クロールには、Scrapy、PySpider、Apifyが向いています。
- 連携要件: Excel、Sheets、データベースへ出力したいなら、ツールがワークフローに合っているか確認してください。
- 予算: 開発者向けには無料・オープンソースの選択肢が豊富です。ビジネスユーザー向けにはThunderbitやParseHubが手頃な入口になり、エンタープライズチームならDexi.ioやContent Grabberへの投資も選択肢になります。
- サポートとコミュニティ: オープンソースツールには大規模なコミュニティがあり、商用ツールには専任サポートがあります。
プロのヒント: ツールを組み合わせることを恐れないでください。Thunderbitで試作してデータパターンを見極め、その後Scrapyに切り替えて本番規模のクロールを行う、といった使い方ができます。あるいは、SeleniumでログインしてセッションCookieを取得し、その後はCollyやScrapyに引き継いで高速スクレイピングする方法もあります。
結論: 2026年に最適なLinux向けウェブスクレイピングツールを見つけよう
2026年のLinuxユーザーは、選択肢に恵まれています。数分で成果を出せるノーコード・AI搭載ツール(Thunderbit)、堅牢な開発者向けフレームワーク(Scrapy、Colly)、エンタープライズ級プラットフォーム(Dexi.io)など、用途やワークフローに合うLinux向けウェブスクレイパーがきっと見つかります。
要点まとめ:
- Linuxは現代のデータ基盤の土台であり、主要なスクレイパーの多くはネイティブまたはブラウザ経由で動作します。
- AIとノーコードツールが、ビジネスユーザーにもウェブスクレイピングを広げています。
- 柔軟性、速度、拡張性では、今も開発者向けフレームワークが強いです。
- 購入前に試すのが大切です。ほとんどのツールには無料プランやトライアルがあります。
始める準備はできましたか? するか、でウェブスクレイピング、自動化、データドリブン成長に関する他の記事もチェックしてみてください。
よくある質問
1. コーディングができない場合、Linuxで一番簡単なウェブスクレイパーはどれですか?
非技術系ユーザーにはが最有力です。Linux上でChrome拡張機能として動作し、AIですべてを自動化し、たった2クリックでデータを抽出できます。
2. 大規模なカスタム案件に最適なLinux向けウェブスクレイパーはどれですか?
開発者向けの定番はです。高速で、拡張性が高く、自由度も十分にあるため、大規模で定期的なクロールに向いています。
3. LinuxでJavaScriptの多い動的サイトをスクレイピングできますか?
はい。やを使えば、実ブラウザを操作して動的コンテンツを取得できます。ParseHubやThunderbitのような視覚ツールも動的サイトに対応しています。
4. ビジネス用途で使える無料のLinux向けウェブスクレイピングツールはありますか?
もちろんあります。Scrapy、Beautiful Soup、Selenium、Colly、PySpider、Kimuraiはすべて無料のオープンソースです。ThunderbitとParseHubも、小規模案件向けの無料プランを提供しています。
5. ノーコードとコードベースのLinuxスクレイパーはどう使い分ければよいですか?
速度とシンプルさを重視するなら、ノーコード(Thunderbit、ParseHub、Octoparse)がおすすめです。柔軟性、自動化、他システムとの連携が必要なら、コードベースのツール(Scrapy、Puppeteer、Colly)が最適です。
快適なスクレイピングを。そして、Linuxの力を借りたデータプロジェクトが、真新しいUbuntuのインストールよりもスムーズに動きますように。さらにウェブスクレイピングのコツを知りたい方は、をご覧いただくか、を登録して、実践的なチュートリアルをチェックしてください。
もっと詳しく知る