2026年にウェブスクレイピングツールを比較するとき、必要なのは哲学講義ではないはずです。信頼できる候補を素早く絞り込み、ビジネスユーザー向けのツールとエンジニア向けの重たい構成をちゃんと見分け、間違った製品を買わないために十分な判断材料を揃える — このページはまさにそれだけを目的にまとめました。
まず結論
ルーティングの判断だけ知りたい、という方はこう考えてください。
- セットアップを最小限に抑えて、サイトからスプレッドシートへ最短距離で進みたいなら AIウェブスクレイパーを。
- コードは書かずに、もう少し細かなタスク制御、スケジュール実行、クラウド実行がほしいなら ノーコードスクレイパーを。
- レンダリング、プロキシ切り替え、ボット対策、社内プロダクトへの組み込みが必要なら APIプラットフォームを。
- 完全な制御が必要で、保守、セレクタ、インフラ、障害対応まで自分たちで担えるなら オープンソースライブラリを。
本記事では20本すべて紹介していきますが、推奨ロジックはあえてシンプルに揃えています。基本は「いまの業務を安定してこなせる、いちばん軽いツールから始める」。保守、ブロック、スケールの問題が顕在化してきたタイミングで、より下のレイヤーに降りる — この順番で十分です。
2026年版 Webスクレイピングツールの簡易比較表
以下の価格とプラン形態は、2026年5月8日時点で各製品の公式ページか料金ページを直接確認しています。従量課金や個別エンタープライズ見積もりを採るベンダーについては、存在しない一律価格をでっち上げるのではなく、料金モデル自体を説明しています。
| ツール | タイプ | 最適な用途 | 2026年版リストに入った理由 | 料金モデル(2026年5月確認) |
|---|---|---|---|---|
| Thunderbit | AIウェブスクレイパー | 営業、オペレーション、EC、不動産 | 非エンジニアにとって最速の導入ルート。AIの項目提案、サブページ取得、エクスポート、ブラウザ+クラウドのワークフロー | 無料枠、有料プラン、法人向け個別価格 |
| Browse AI | AIウェブスクレイパー | Webサイトを監視するビジネスユーザー | ノーコードのロボット、監視、スプレッドシート/API風の出力が強い | 無料プラン、有料プラン、プレミアム管理プラン |
| Bardeen | AI自動化+スクレイピング | Revenue Ops とブラウザ業務フロー | スクレイピングが、より広い自動化フローの一工程にあるときに真価を発揮 | 無料プランと有料プラン |
| Diffbot | AI抽出プラットフォーム | エンタープライズとデータチーム | AI抽出と大規模な構造化データ運用を両立したい場合に最適 | エンタープライズ向け料金 |
| Instant Data Scraper | 軽量ブラウザスクレイパー | カジュアルユーザー、簡単な表の取得 | 目に見えるリストや表をCSVにすばやく取り込む最も手軽な方法のひとつ | 無料 |
| Octoparse | ノーコードスクレイパー | 定常ジョブが多い分析担当、オペレーションチーム | クラウド抽出、ブロック対策、テンプレートが揃った成熟したビジュアルビルダー | 無料プラン、有料は月額69ドルから、法人向け個別対応 |
| ParseHub | ローコードスクレイパー | ロジックとデスクトップ制御が必要な分析担当 | 柔軟なプロジェクトロジックとネストしたナビゲーション。AI先行型の新しいツールより学習コストは高め | 無料プランと有料プラン |
| Web Scraper | ノーコードスクレイパー | 初心者、軽量なクラウドジョブ | サイトマップベースのスクレイピングとブラウザ起点のセットアップが好きなら入り口として優秀 | 無料拡張機能、有料クラウドプラン |
| Data Miner | ブラウザスクレイパー | リサーチャー、グロース担当 | ブラウザ内での簡単なレシピ型抽出に今でも役立つ | 無料プランと有料プラン |
| Apify | API+Actorプラットフォーム | 技術チーム、ハイブリッド運用 | ブラウザ拡張の限界を超えたときに使える、再利用可能なActor群と独自ランタイムのエコシステムが優秀 | 無料プラン、月額29ドルから+従量課金、上位有料プラン |
| ScrapingBee | スクレイピングAPI | JSが重いサイトを扱う開発者 | レンダリングやプロキシ処理を、自前でブラウザ層を作らずに済ませたいときに良い選択 | 無料トライアルと有料プラン |
| ScraperAPI | スクレイピングAPI | リクエストを高速にスケールしたい開発者 | シンプルなAPI、試用クレジット、構造化製品、インフラ負担の軽減が魅力 | 7日間のトライアルで5,000クレジット、月額49ドルから |
| Bright Data | エンタープライズAPI+プロキシプラットフォーム | 大量処理、コンプライアンス重視の案件 | ブロック回避、プロキシ、マネージド取得が重要なときに最も広いデータ収集スタックを提供 | 従量課金+製品別料金 |
| Oxylabs | エンタープライズAPI+プロキシプラットフォーム | スクレイピングをインフラとして買うチーム | 大規模収集、特に価格、SEO、市場調査のワークロードに強い | Web Scraper API は月額49ドルから、プロキシは別料金で変動 |
| Zyte | API+ボット対策スタック | 開発者とデータチーム | API起点での抽出に、強いブラウザ処理、回転、検知回避の仕組みを求めるなら好相性 | 5ドル分の無料クレジット付きトライアル、従量課金ベースの契約 |
| Selenium | オープンソースのブラウザ自動化 | QA系自動化、難しい操作フロー | ユーザー操作の忠実度がスクレイピングのスループットより重要なときに今でも有効 | 無料、オープンソース |
| BeautifulSoup4 | オープンソースのパーサー | 初心者、軽量な解析 | 本格的なスクレイピング基盤ではなく、シンプルな構成のパーサーとして最適 | 無料、オープンソース |
| Scrapy | オープンソースのクローリングフレームワーク | 本番向けのカスタムクローラー | 自分でパイプラインを管理したいなら、機能と成熟度のバランスが最も良い | 無料、オープンソース |
| Puppeteer | オープンソースのブラウザ自動化 | Node中心のスクレイピング、ブラウザスクリプト | チームがすでにChrome/Nodeの環境に慣れているなら非常に相性が良い | 無料、オープンソース |
| Playwright | オープンソースのブラウザ自動化 | モダンなマルチブラウザ自動化 | 現代的なブラウザ自動化では、開発体験の良さも含めて最有力候補になりやすい | 無料、オープンソース |
ツールをどう評価したか
評価では、次の4つの観点を使いました。
- 最初のスクレイピング成功までの時間
非技術者がすぐに有用なデータを取れないなら、その時点で大きなマイナスです。 - 保守の負担
サイトが変わるたびに壊れるようでは、導入の速さは意味を持ちません。 - スケールの上限
週50ページの用途には最適でも、月500万リクエストには付き合えないツールもあります。 - 業務フローとの適合性
Revenue Ops に最適なツールが、データプラットフォームチームにも最適とは限りません。
これは普遍的なランキングではなく、まず適切な「種類」を選んで、同じレイヤー内で製品同士を比較するための判断ページ — そう思って使ってください。
自分に必要なWebスクレイピングツールのタイプはどれ?
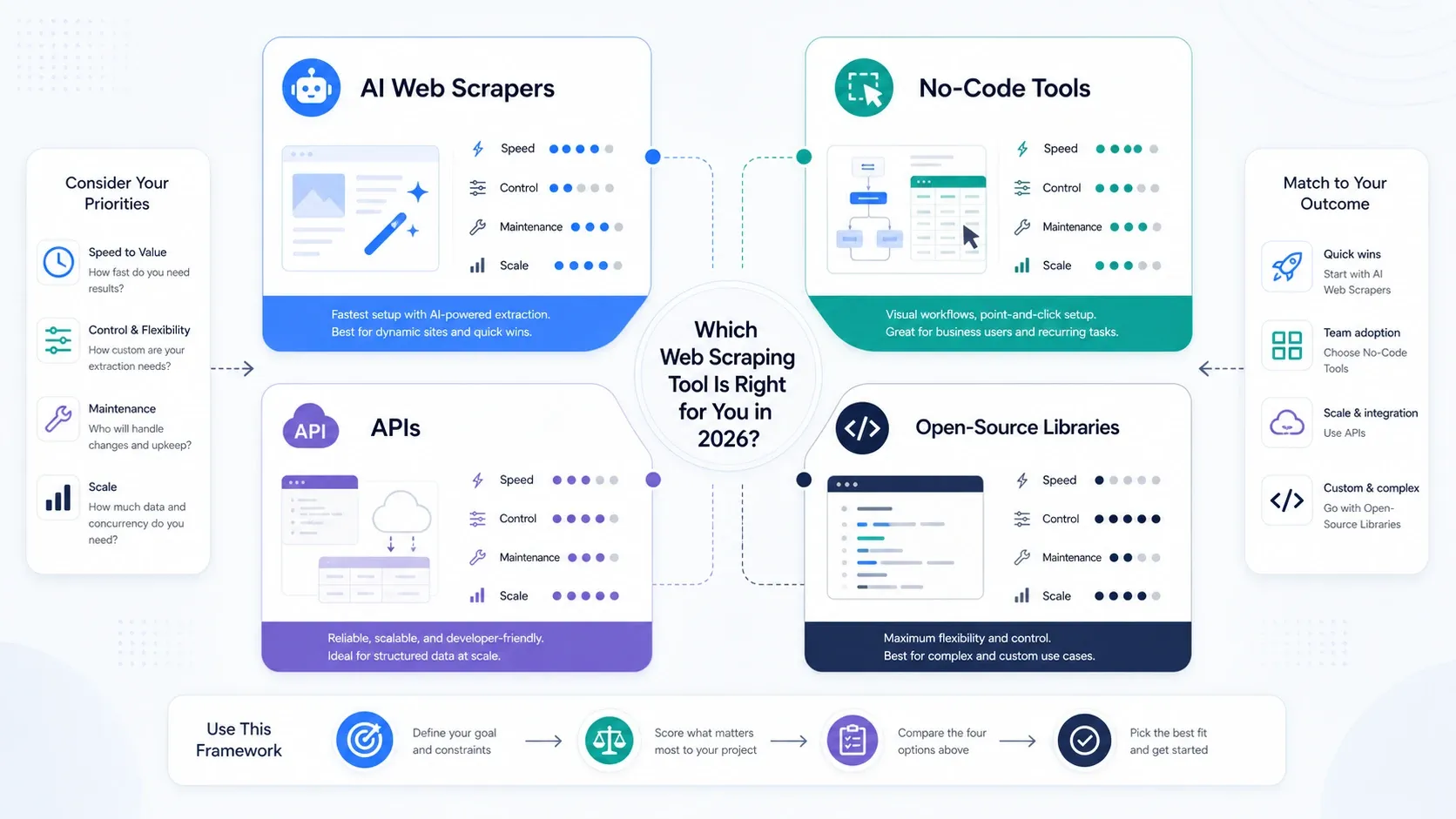
- 主目的が業務スピードなら AIウェブスクレイパー。
- ページネーション、スケジュール実行、繰り返し可能なタスク制御が必要なら ノーコードツール。
- レンダリング、回転、ブロック回避がボトルネックなら API とスクレイピングプラットフォーム。
- チームが利便性より制御を重視し、スタックを自社で支えられるなら オープンソースライブラリ。
スクレイピングをオペレーション側に置くべきか、エンジニアリング側に置くべきか — このあたりでまだ悩んでいるなら、まずは AI ツールかノーコードツールから始めるのがおすすめです。最初からスタックを作り込みすぎるよりも、実ジョブを回したほうが「何が本当に重要か」をずっと早く学べます。
ビジネスチーム向けのおすすめAIウェブスクレイパー
最小限のセットアップで、即スプレッドシートに使えるデータが欲しい、という方が真っ先に確認したいツール群です。
1. Thunderbit
Thunderbit は、セレクタ、ブラウザスクリプト、スクレイピング基盤をわざわざ学ばずに構造化データを抽出したい、というチームにとって、このリストで最も手軽な選択肢です。AI による項目提案、サブページの補完、ビジネスユーザーが普段使っているツールへの直接エクスポート — このあたりを中心に設計されています。
- 最適な用途: 営業、オペレーション、EC、不動産 — ブラウザを中心に仕事を回しているチーム全般。
- 優れている点: 非エンジニア向けのセットアップ時間が、このリストでも飛び抜けて短いこと。
- 注意点: 深いカスタムクローラーロジックや、相当に専門的なエンジニア制御が必要なら、いずれはより下のレイヤーへ移ることになります。
- 料金モデル: 無料枠、セルフサービスの有料プラン、法人向け料金。
比較検討に入る前に、まず最速の実ワークフローを目で見ておきたい、という方には、このチュートリアルからどうぞ。費用対効果の高い15分になるはずです。
2. Browse AI
Browse AI は、クリック操作で組み立てるセットアップと、継続的な監視を両方ほしいビジネスユーザーにとって、いまも有力な選択肢です。スクレイピングと変更検知を同じ温度で扱いたい場面で、ロボットモデルが特に効いてきます。
- 最適な用途: 価格ページ、競合ページ、繰り返し使うリスト抽出の監視。
- 優れている点: こなれた初期導入、事前構築済みロボット、ウェブサイトからスプレッドシートまたは API 風の出力までの明確な導線。
- 注意点: 複雑で大規模なジョブでは、API 先行型の構成に比べてコスト高や運用面の手間が早めに顔を出します。
- 料金モデル: 無料プラン、有料プラン、プレミアム/マネージドプラン。
3. Bardeen
Bardeen が特に効くのは、スクレイピングがより広いブラウザ自動化フローの中の1アクションでしかない、というケース。データを CRM、スプレッドシート、アウトバウンド業務フローに流し込むなら、純粋な抽出の深さよりも、自動化の強さが効いてきます。
- 最適な用途: Revenue Ops、リード業務、ブラウザネイティブなタスク自動化。
- 優れている点: 純粋な抽出ツールよりも、ワークフロー自動化のストーリーがしっかりしていること。
- 注意点: スクレイピング自体が複雑でミッションクリティカルな用途には、最適解ではありません。
- 料金モデル: 無料プランと有料プラン。
4. Diffbot
Diffbot は、安く済ませたい・簡単に済ませたい人向けではなく、エンタープライズ規模で AI 抽出を必要とするチーム向けの製品。構造化データの品質や大規模取り込みのほうが、手元での細かな制御より重要、という場面でこそ意味が出ます。
- 最適な用途: エンタープライズデータチーム、コンテンツインテリジェンス、大規模抽出案件。
- 優れている点: コンピュータビジョン的な抽出と、構造化出力への強い志向。
- 注意点: 小規模チームには過剰、軽量ユースケースでは扱いづらく感じます。
- 料金モデル: エンタープライズ向けプランと個別営業。
5. Instant Data Scraper
Instant Data Scraper がいまだに外せないのは、目の前の表、ディレクトリ、リストを「いま」取りたい場面が現場には溢れているから。プラットフォームではありませんが、これで十分、というケースは本当に多いんです。
- 最適な用途: 単発抽出、簡易なリード一覧、シンプルなディレクトリ、目に見える表の取得。
- 優れている点: 対応ページなら、ほぼ摩擦なく動くこと。
- 注意点: 自動化は限定的で、深さも足りず、高度なワークフローには不向き。
- 料金モデル: 無料。
繰り返し作業向けのおすすめノーコードWebスクレイピングツール
定期的に回すスクレイピングに踏み込むと、ビジュアルビルダーとクラウド実行のありがたみがぐっと増してきます。
6. Octoparse
Octoparse は、クラウド実行、テンプレートの充実、ブラウザ拡張より一段高度なタスク管理がほしいなら、いまでも最も強力なノーコード基盤のひとつです。
- 最適な用途: 分析担当、価格チーム、定常収集を回すオペレーター。
- 優れている点: 成熟したタスクビルダー、クラウド抽出、ブロック対策、層の厚いテンプレート群。
- 注意点: AI 先行型のブラウザツールより強力ですが、その分、セットアップの手間も増えます。
- 料金モデル: 無料プラン、有料は月額69ドルから、法人向け個別対応。
7. ParseHub
ParseHub は、AI スクレイパーよりも細かく制御したいけれど、コードベースまでは持ちたくない、というユーザーにいまも十分役立ちます。速さよりも、丁寧さが報われる系のツールです。
- 最適な用途: 学習コストの高さを許容できる分析担当や、少し技術寄りのオペレーター。
- 優れている点: 柔軟なナビゲーションロジックと、軽量なブラウザツールより高い制御性。
- 注意点: 動きの速いビジネスチームには、新しい製品より重く感じられがちです。
- 料金モデル: 無料プランと有料プラン。
8. Web Scraper
Web Scraper は、サイトマップ方式が肌に合う方、最初はブラウザで始めて、あとからクラウドスケジューリングへ広げたい方には、いまも妥当な入り口です。
- 最適な用途: 初心者、趣味のプロジェクト、小規模な定常ジョブ。
- 優れている点: とっつきやすいサイトマップワークフローと、ブラウザ起点で始められる気軽さ。
- 注意点: より適応的な抽出ロジックが必要になった瞬間、すぐ制約が見えてきます。
- 料金モデル: 無料のブラウザ拡張機能と有料のクラウドプラン。
9. Data Miner
Data Miner は、完全なスクレイピングプラットフォームというより、すばやく抽出するための便利ユーティリティと捉えるのが筋。それでも採用する価値があるのは、レシピ駆動の作業がリサーチや見込み客開拓で役に立つから。
- 最適な用途: リサーチャー、グロースチーム、ブラウザ上でのサクッとした書き出し作業。
- 優れている点: レシピモデル、低い導入摩擦、簡単なブラウザエクスポート。
- 注意点: 本格的なプラットフォーム規模のスクレイピングには向きません。
- 料金モデル: 無料プランと有料プラン。
スケールとブロック対策が本当の課題になったときのおすすめAPIプラットフォーム
このレイヤーに入ると、エンジニアチームの問いは「このページをどうスクレイピングするか」から「どうすれば大規模でも安定して動くか」へと変わります。
10. Apify
Apify は、再利用可能なスクレイパーのマーケットプレイスと、自前コードを動かす場所の両方がほしいなら、このグループでいちばん柔軟。ノーコードでの発見と、開発者による実行を、多くの競合より上手に橋渡ししてくれます。
- 最適な用途: ハイブリッドチーム、開発者主導のスクレイピング、再利用可能な自動化ワークフロー。
- 優れている点: Actor エコシステムとカスタムランタイムの組み合わせによる、対応範囲の広さ。
- 注意点: カスタム実装に踏み込むと再びエンジニアリングの世界に戻り、シンプルさの利点は薄れます。
- 料金モデル: 無料プラン、月額29ドルから+従量課金、より大きな利用枠とエンタープライズ。
11. ScrapingBee
ScrapingBee は、「レンダリング済みのページが返ってきてくれればそれでいい。面倒なインフラは全部任せたい」というニーズに刺さります。JavaScript が重い対象との相性も良好。
- 最適な用途: インフラ作業に余力がないまま動的サイトを扱う開発者。
- 優れている点: レンダリング、プロキシ、ブラウザ自動化をまとめたシンプルな API。
- 注意点: インフラサービスである以上、解析、リトライロジック、その後のデータ品質は自分で持つ必要があります。
- 料金モデル: トライアルと有料プラン。
12. ScraperAPI
ScraperAPI は、プロキシ管理やリクエスト成功率の負担を外注しつつ、素早くスケールさせたいときに、いまも最も気軽な選択肢のひとつです。
- 最適な用途: 試作から大量処理へ一気に橋渡ししたい開発者。
- 優れている点: わかりやすい API、試用クレジット、構造化製品、伸ばしやすい料金帯。
- 注意点: 他の API ファースト製品と同じく、解析やデータ検証に関するエンジニア判断は依然必要です。
- 料金モデル: 7日間トライアルで5,000クレジット、月額49ドルから。
13. Bright Data
Bright Data は、ブロック回避、プロキシ在庫、マネージド取得が、ツールのわかりやすさより重要になるシーンで選ぶ、重量級の選択肢です。
- 最適な用途: エンタープライズ案件、コンプライアンス重視の大規模収集、マネージドデータ取得。
- 優れている点: プロキシ、スクレイパー、ブラウザ、データセット製品の幅広さ。
- 注意点: 価格は高く、基本ワークフローがまだシンプルな場合は、過剰導入になりがち。
- 料金モデル: API、プロキシ、マネージドサービス全体で従量課金+製品別料金。
14. Oxylabs
Oxylabs は、ブラウザツールではなく、スクレイピングを「インフラとして買う」チームにとって、いまも有力な選択肢。特に信頼性と調達体制の成熟度が要件のときに、強い存在感を見せます。
- 最適な用途: エンタープライズ収集、価格監視、SEO 監視、市場調査。
- 優れている点: 堅牢なインフラ面、豊富なプロキシ、エンタープライズ向けの購買導線の明確さ。
- 注意点: 気軽なセルフサービス運用を欲しがるチームには合いません。
- 料金モデル: Web Scraper API は月額49ドルから。他製品は単位と利用量で変動。
15. Zyte
Zyte は、検知回避、ブラウザ操作、JavaScript レンダリング、回転 IP を1つの API ファーストなスタックでまとめて使いたい開発者・データチームに、いまも検討する価値があります。
- 最適な用途: 繰り返し使う抽出システムを構築する技術チーム。
- 優れている点: ブラウザ操作、JS レンダリング、IP ローテーション、ボット対策が1つのスタックに収まっている点。
- 注意点: 非技術者向けというより、エンジニアが責任を持つチーム向け。
- 料金モデル: 5ドル分の無料クレジット付きトライアルと、従量課金ベースの月次契約。
完全に制御したい開発者向けのおすすめオープンソースライブラリ
スクレイパーの構成を最初から最後まで自分たちで握りたい、というチームに向けて、2026年時点でも特に頼れるのはこのあたりです。
16. Selenium
Selenium は、QA スタイルの操作忠実度、レガシーなブラウザ自動化、極めて明示的なユーザーフロー制御が必要なときに、いまも有効です。
- 最適な用途: 操作の多い自動化、QA との重なり、ブラウザ挙動がスループットより重要なサイト。
- 優れている点: 成熟したエコシステムと、広いブラウザ対応。
- 注意点: 多くのスクレイピング用途では、新しいブラウザツールに比べて重く・遅くなりがち。
- 料金モデル: 無料、オープンソース。
17. BeautifulSoup4

BeautifulSoup は完全なスクレイピング基盤ではありませんが、軽量なワークフローで扱いづらい HTML を解析する方法としては、いまも最も気楽なツールのひとつ。
- 最適な用途: 初心者、短いスクリプト、パーサー中心の作業。
- 優れている点: シンプルな API と、低い認知負荷。
- 注意点: リクエスト、ブラウザ、クローラー系のツールと組み合わせて使うのが前提。単体ではあくまでパーサー。
- 料金モデル: 無料、オープンソース。
18. Scrapy
Scrapy は、数本のスクリプトではなく、本物のクローラーフレームワークが必要なときの最有力候補です。
- 最適な用途: 本番向けのカスタムクローラー、社内管理のデータパイプライン。
- 優れている点: 高い性能、パイプライン、ミドルウェア、長期的な拡張性。
- 注意点: 実際のエンジニアリング負担あり。JS が重い対象では、補助ツールがほぼ必須。
- 料金モデル: 無料、オープンソース。
19. Puppeteer
Puppeteer は、Chromium とブラウザスクリプトを直接握りたい Node 中心のチームに、いまも非常に合う選択肢。
- 最適な用途: Node ベースのスクレイピング、スクリーンショット、ブラウザ自動化タスク。
- 優れている点: Chromium の挙動を直接、強力に制御できる点。
- 注意点: Playwright よりブラウザ対応の幅が狭く、大規模化するとリソース消費も無視できなくなります。
- 料金モデル: 無料、オープンソース。
20. Playwright
Playwright は、コードを書くチームにとって、Selenium より新しい抽象化で組みたい現代的ブラウザ自動化のデフォルト候補です。
- 最適な用途: モダンなブラウザ自動化、JS が重いサイト、開発体験を重視するチーム。
- 優れている点: 強力なマルチブラウザモデル、安定した待機挙動、すっきりした API。
- 注意点: ブラウザインフラ、並列実行、セレクタの変化、データ検証は依然として自社管理が必要。
- 料金モデル: 無料、オープンソース。
チーム別の短い推奨リスト
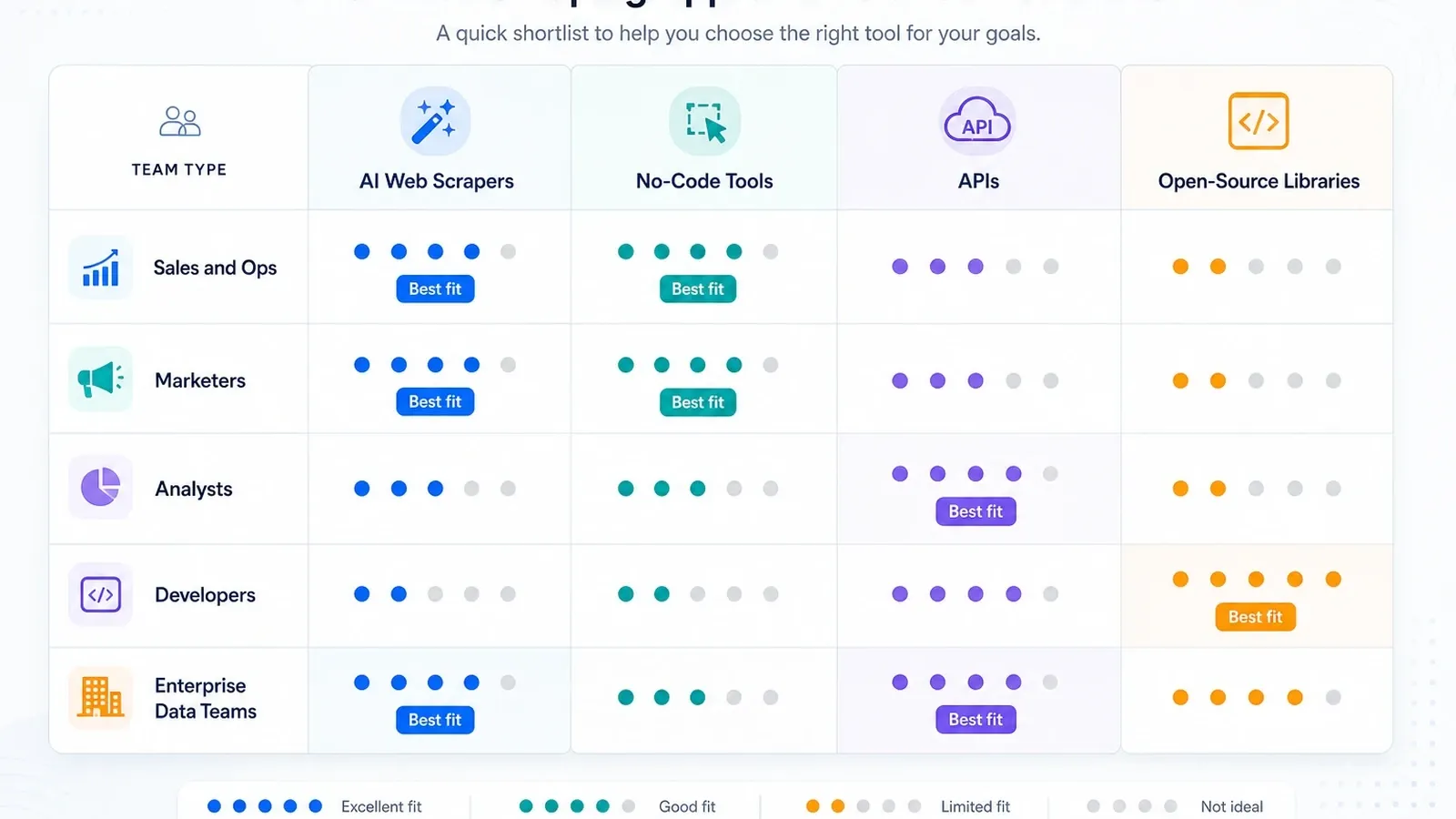
- 営業・オペレーションチーム: まずは Thunderbit。監視がサブページ補完より重要なら Browse AI を検討。
- 分析・リサーチチーム: 繰り返しジョブがブラウザ拡張の限界を超え始めたら、まずは Octoparse。
- 自動化中心の GTM チーム: スクレイピングが大きなワークフローの一工程でしかないなら Bardeen。
- 社内ツールを作る開発チーム: スタックの所有範囲をどこまで持ちたいかに応じて、Apify、Zyte、ScraperAPI、Playwright。
- エンタープライズのデータプログラム: Bright Data、Oxylabs、Diffbot、Zyte が、本格的なインフラの相談先です。
いつ下のレイヤーへ移るべきか
次のルールで考えるのがおすすめです。
- 繰り返し性や例外パターンの限界に当たるまでは、AI ツールに留まる。
- スケジュール実行、ページネーション、ブロック対策、クラウド実行が、ワンクリックの手軽さより重要になったら ノーコードツールへ。
- ブロック回避率、JS レンダリング、並列実行が本当のボトルネックになってきたら APIへ。
- ベンダーの抽象化コストが、スタック全体を自分たちで持つコストを上回ったら オープンソースライブラリへ。
多くのチームは、下のレイヤーに早く移りすぎる傾向があります。これは現場でもよく見かける、かなり典型的な失敗です。
まとめ
多くの非技術チームにとって、2026年の正解は「最強のスクレイパー」ではありません。大事なのは、最小限の保守で正確なデータを次の業務フローへ渡せるツール — これに尽きます。だからこそ、AI ファーストのツールは運用担当に選ばれ続け、API とオープンソースのスタックは、明確なスケール要件を持つ技術チームにとってよりよい選択肢であり続ける、という構図になります。
ページから構造化出力まで最短距離で進みたいなら、Thunderbit から。すでに重いインフラが必要だと分かっているなら、API 層や開発者向けレイヤーへ直接降りればよいです。とにかく、複雑さと洗練を混同しないこと。これだけは肝に銘じてください。
よくある質問
1. 2026年に非技術者に最適な Web スクレイピングツールは何ですか?
多くの非技術者にとっては、Thunderbit や Browse AI のような AI ファーストのツールが最速です。セレクタ作業、セットアップ、保守 — このあたりの負担を一気に下げてくれます。
2. サイトが JavaScript 主体だったり、リクエストを厳しくブロックしてくる場合は何を選ぶべきですか?
マネージドサービスがほしいか、直接エンジニア制御がほしいかで枝分かれしますが、ScrapingBee、ScraperAPI、Zyte、Bright Data、Oxylabs、Playwright、Selenium あたりを検討してみてください。
3. AI ウェブスクレイパーが進化した今でも、ノーコードツールは必要ですか?
はい、必要です。Octoparse や ParseHub のようなノーコードツールは、タスクロジック、クラウド実行、繰り返しジョブ管理をより明確に制御したい場面で、いまも重要です。
4. エンジニアチームに最も合うツールはどれですか?
開発者がワークフローを持つなら、Apify、Zyte、ScraperAPI、Scrapy、Playwright、Puppeteer、Selenium が自然な選択肢になります。
5. 調べすぎずに、素早く候補を絞るにはどうすればよいですか?
まずベンダーではなく、ツールの「タイプ」を決めてください。AI の手軽さが欲しいのか、ノーコードの制御が欲しいのか、API インフラが欲しいのか、オープンソースの所有権が欲しいのか — そこを決めてから、同じレイヤー内の製品を比べていく流れがよいです。
関連コンテンツ