

Temu は現在、50以上の市場で月間アクティブユーザー数が 4億1,600万人 を超えています。商品カタログは、キッチングッズからペット用品、LEDテープまで、かなり幅広いです。EC、ドロップシッピング、競合調査に関わっているなら、Temu のデータをスプレッドシートに取り込みたいと思ったことがあるはずです。ところが、Temu はそれをあまり歓迎していない、という現実にもすぐ気づくでしょう。
私はこれまで、保護されたECサイト向けのスクレイピングツールをかなり調査・検証してきました。その中でも Temu は特に手強い対象です。ネット上のガイドの多くは、1週間ももたずに壊れる Python チュートリアルを紹介するか、月々の広告費より高い企業向け API を勧めるだけです。
実際、多くのビジネスユーザー——ドロップシッパー、個人事業主、マーケティングチーム——が欲しいのは、商品名、価格、画像、評価、販売者情報が整理されたきれいなスプレッドシートです。深夜2時に Playwright のスクリプトをデバッグしたいわけではありません。
この記事は、そのギャップを埋めるためのものです。2026年に実際に使える Temu スクレイパーを、スキルレベル別に実用的に整理し、さらに生のスクレイピング結果を継続的な競合インテリジェンスへ変えるベストプラクティスまでまとめました。完全初心者でも、データパイプラインを構築する開発者でも、ここに合う内容があります。
なぜ Temu をスクレイピングするのか? ビジネスチームでの主な活用例
Temu のデータは、単に面白いだけではありません。戦略的にも非常に有用です。
このプラットフォームは、低価格帯から中価格帯の商品カテゴリにおける価格決定力を持つ存在になっています。Temu で販売していなくても、顧客はそこで見た価格と自社価格を比較しています。チームごとに、Temu データは次のように使えます。
| ユースケース | 必要なデータ | 重要な理由 |
|---|---|---|
| ドロップシッピングの商品調査 | タイトル、価格、画像、評価、レビュー数、販売数、バリエーション | Amazon、Shopify、AliExpress、TikTok Shop との比較に使える、需要シグナルのある低コスト商品を見つけられる |
| 競争力のある価格設定 | 現在価格、元価格、割引率、通貨、送料、タイムスタンプ | 価格戦略と販促計画の基準値を作れる |
| 商品の仕入れ先探索 | 仕様、画像、バリエーション、販売者/ショップ、商品ID、カテゴリ | より深い検証に値する商品タイプや、サプライヤー型の掲載を特定できる |
| 市場トレンド分析 | 検索キーワード、カテゴリ、販売数、レビュー数、評価 | どの商品が各カテゴリで勢いを増しているか分かる |
| マーケティング・クリエイティブ調査 | タイトル、画像、レビュー数、評価、説明文、カテゴリラベル | 大量掲載商品で使われる訴求、ビジュアルのフック、セット販売、主張内容が見えてくる |
| 在庫・販売可否の監視 | 商品URL、在庫状況、発送見込み、価格、タイムスタンプ | 欠品、現地倉庫の変化、価格変動を時系列で把握できる |
「Temu スクレイパー」で検索する人は、だいたい3つの層に分かれます。非技術系ユーザーは、スプレッドシートを出力できる Chrome 拡張を求めます。半技術系の運用担当は、テンプレートとスケジューリングがあるビジュアルツールを求めます。開発者は、API、Playwright スクリプト、プロキシ戦略を求めます。
この記事ではその3つすべてを扱いますが、まずは一番大きな層——コードではなくデータが欲しい人——から始めます。
2026年に優れた Temu スクレイパーを見分けるポイント
Amazon や Shopify で動くスクレイパーでも、Temu では通用しないことがあります。この記事では、次の基準で評価しています。
- Temu での安定性 — 実際にきれいなデータが取れるのか、それともブロックされるのか、空行しか返らないのか、レイアウト変更で壊れるのか。
- 使いやすさ — 非技術系のビジネスユーザーでも、コードなしで始められるのか。
- データの完全性 — サブページの補完に対応しているか(各商品詳細ページへアクセスして仕様、バリエーション、販売者情報を取得できるか)。
- 保守負担 — Temu がページ構造を変更したときに、どれだけ追従できるか。
- スケジュール実行と監視 — 繰り返しスクレイプを実行し、継続的に使えるデータ先へ出力できるか。
- 出力先 — CSV、Excel、Google Sheets、Airtable、Notion、JSON に対応しているか。
- コストの分かりやすさ — 現実的な Temu スクレイピング運用で、月額いくらかかるのか。
Reddit の r/webscraping では、Temu はスクレイピングが最も難しいECサイトの1つだという報告が一貫して見られます。あるユーザーは「購入者として価格すら取得できない」と書き、別のユーザーは Temu と Shopee がボット対策を継続的に強化していると指摘しました。Temu 専用の失敗率ベンチマークは公開されていませんが、2025 Imperva Bad Bot Report によると、自動化トラフィックは人間のトラフィックを上回り、全インターネットトラフィックの 51% をボットが占めていました。Temu が防御しているのは、その規模の自動化です。
Temu のボット対策:多くのスクレイパーが失敗する理由
Temu のスクレイピング記事の多くは、ボット対策についてたった一文しか触れません。「Temu はボット対策を使っている」。これでは何の役にも立ちません。
ツールを選ぶなら、Temu がどの防御を使っていて、どのツール機能がそれを突破するのかを知る必要があります。実用的な対応表は次のとおりです。
| Temu の防御 | 仕組み | 必要なツール機能 | 例 |
|---|---|---|---|
| Cloudflare WAF / ブラウザチェック | 自動化されたユーザーエージェントを遮断し、ボット指紋を検出し、チャレンジページを返す | ローテーション可能な住宅IPと、実ブラウザの指紋を持つクラウド基盤 | Thunderbit(クラウドスクレイピング)、Bright Data、Oxylabs、ScraperAPI |
| 重い JavaScript レンダリング | 商品データが JS で読み込まれ、元の HTML は空に近い | ヘッドレスブラウザまたは完全なブラウザレンダリング | Thunderbit(ブラウザスクレイピングモード)、Playwright、Selenium、ParseHub、Apify のブラウザ actor |
| 動的 CSS セレクタ | デプロイごとにクラス名が変わり、CSS ベースのスクレイパーが壊れる | 固定セレクタに依存しない AI ベースの項目検出 | Thunderbit(AI が毎回ページを読み直す)、Bright Data の AI スクレイパービルダー |
| レート制限 | 短時間の連続リクエストを制限する | インテリジェントなスロットリングを備えた同時実行クラウドリクエスト | Thunderbit(クラウド経由で最大50ページ同時)、ScraperAPI、Bright Data |
| CAPTCHA チャレンジ | 不審な挙動の後にセッションを中断する | CAPTCHA 自動解決、またはトリガーを抑える戦略 | Bright Data、Oxylabs、ScraperAPI の premium/ultra-premium |
| 無限スクロール / 遅延読み込み | 何もしないと最初の商品しか表示されない | スマートスクロール、ページネーション検出、操作自動化 | Thunderbit のページネーション、Apify のスマートスクロール、Octoparse のワークフロービルダー |
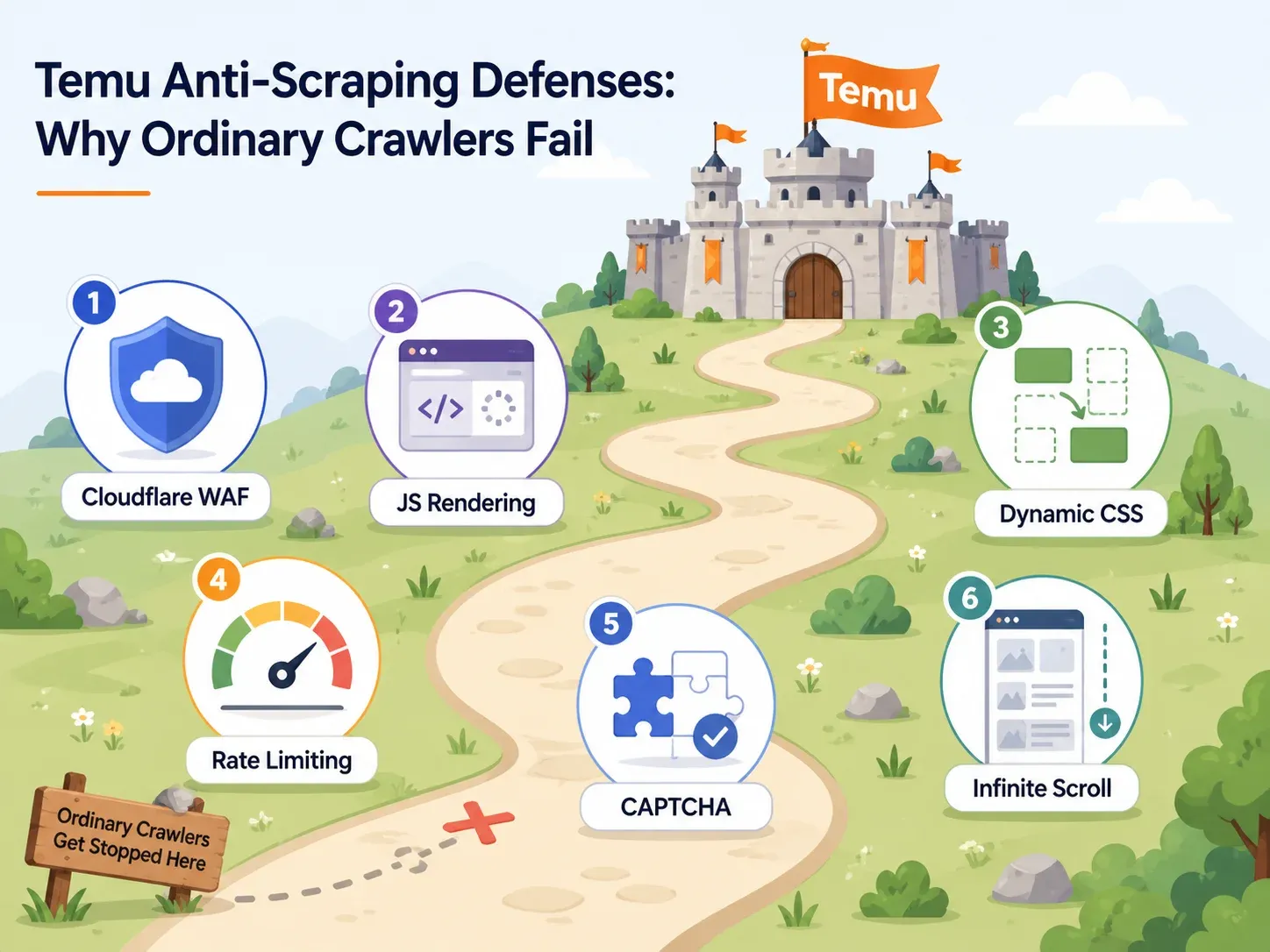
Cloudflare WAF と IP ブロック
Temu の玄関口は、Cloudflare 系のブラウザ整合性チェックで守られています。単純な Python の requests.get() のような基本的な HTTP リクエストは、チャレンジを返されるか、403 エラーになるか、不完全なデータしか返されません。
ここで機能するツールには、ローテーション可能な住宅IPまたはモバイルIPと、本物のブラウザ指紋が必要です。Cloudflare の 2025 Radar レビュー によると、2025年の初めには非AIボットが HTML ページリクエストのおよそ半分を占めていました。Temu が防御している自動化の規模は、まさにそのレベルです。
JavaScript レンダリングと動的セレクタ
ここで初心者向けスクレイパーの多くは、失敗しても気づかれないまま終わります。
Temu のページソースを見ると、しばしば空の骨組みしかありません。実際の商品カード、価格、画像は、ページ読み込み後に JavaScript で差し込まれます。生の HTML しか読まないスクレイパーでは、何も役に立つものは取れません。さらに、Temu の CSS クラス名や DOM 構造はデプロイごとに変わります。.product-card__price のような固定 CSS セレクタに依存するスクレイパーは、今日は動いても明日には空の列を返すことがあります。
Thunderbit のような AI ベースのスクレイパーは、毎回ページを意味ベースで読み取るため、特定のクラス名が同じままである必要がありません。
レート制限と CAPTCHA チャレンジ
1つのIPから Temu に短時間で何度もアクセスすると、レート制限や CAPTCHA チャレンジが発生します。ツールによっては、インテリジェントなスロットリングや CAPTCHA 自動解決で対応します。そうでないものはユーザー任せです。非技術系ユーザーにとっては、ほぼ行き止まりです。
クラウドスクレイピングでは、重要なのはクリーンなIPに分散した同時リクエストと、自動リトライロジックです。
スキルレベル別・最適な Temu スクレイパー完全ガイド
自分に合う行を見つけて、そのセクションへ進んでください。
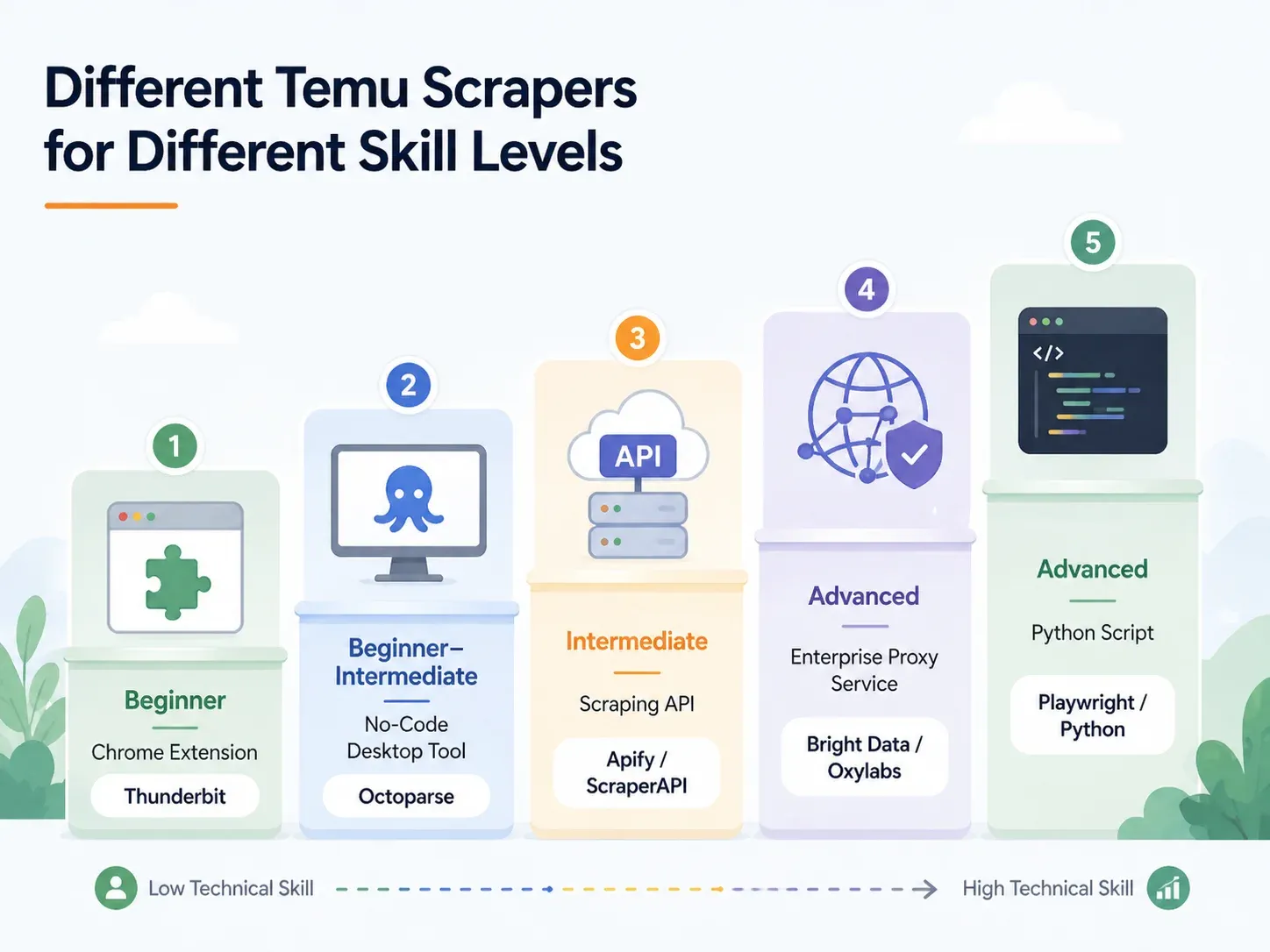
| アプローチ | スキルレベル | セットアップ時間 | ボット対策への対応 | 最適な用途 |
|---|---|---|---|---|
| AI Chrome 拡張(例:Thunderbit) | 初心者 | 2分未満 | 対応済み(クラウドまたはブラウザ) | ドロップシッパー、マーケター、EC運用 |
| ノーコードのデスクトップツール(例:Octoparse、ParseHub) | 初心者〜中級 | 10〜60分 | 一部対応(プロキシ設定が必要) | テンプレートを使った定期スクレイピング |
| スクレイピング API / サービス(例:ScraperAPI、Apify) | 中級 | 15〜45分 | 組み込み対応 | パイプラインに組み込む開発者向け |
| マネージドプロキシ / エンタープライズ(例:Bright Data、Oxylabs) | 上級 / 企業向け | 数時間〜数日 | フルインフラ | 大量取得、倉庫連携 |
| カスタム Python スクリプト(Playwright / Selenium) | 上級 | 1〜4時間以上 | 手動対応(プロキシ + CAPTCHA 設定) | 完全な制御、特殊ケースのカスタマイズ |
Thunderbit:非技術系ユーザーに最適な Temu スクレイパー
Thunderbit は、営業チーム、EC運用担当、ドロップシッパー、マーケターなど、コードを書かずにウェブサイトから構造化データを取り出したいビジネスユーザー向けに作られた AI 搭載の Chrome 拡張です。私は Thunderbit チームで働いているので、製品をよく知っています。何ができて、どこに向いているかを率直にお伝えします。
基本の流れは2クリックです。Temu のページを開き、AI Suggest Fields をクリックし、提案された列(商品名、価格、画像、評価など)を確認したら、Scrape をクリックします。
Thunderbit の AI はページ構造を読み取り、列名とデータ型を自動で提案します。固定 CSS セレクタには依存しないので、Temu がクラス名やカードのレイアウトを変更しても、スクレイパーが追従します。
Temu 向けの主な機能:
- クラウドスクレイピングモード: 公開ページの取得が速く、一度に最大50ページまで処理できます。カテゴリページ、検索結果、ログイン不要の商品一覧に最適です。
- ブラウザスクレイピングモード: Cookie、地域設定、ログイン状態を含む、現在の Chrome セッションを使います。地域差、ポップアップ、ログイン済みコンテンツが表示内容に影響する場合に最適です。
- サブページのスクレイピング: 一覧ページを取得したあとに「Scrape Subpages」をクリックすると、各商品詳細ページへアクセスし、詳細説明、バリエーション、販売者情報、送料見込み、仕様などの列を追加できます。追加設定は不要です。
- Field AI Prompts: スクレイプ中にデータの分類、翻訳、整形ができます。たとえば、「この商品を Kitchen Utensils、Small Appliances、Storage、Other のいずれかに分類してください」のように指定できます。
- スケジュールスクレイピング: 「毎週月曜9時」のように自然文でスケジュールを設定し、URL を入力すると、Thunderbit がクラウドでスクレイプを実行し、Google Sheets、Airtable、その他の保存先へ出力します。
- 無料エクスポート: Excel、CSV、Google Sheets、Airtable、Notion、JSON に、エクスポート時の有料壁はありません。画像は Airtable と Notion で実際の添付ファイルとして出力されます。
価格:無料枠は最大6ページ(トライアル増量時は10ページ)まで。有料プランは 月額15ドル前後(年払いなら9ドル前後) からで、500クレジット、1クレジット=出力1行です。
AI で Temu データをスクレイピング Get Started Free
同じ Temu ページでの比較:Thunderbit と Python スクリプト
その差は一目瞭然です。
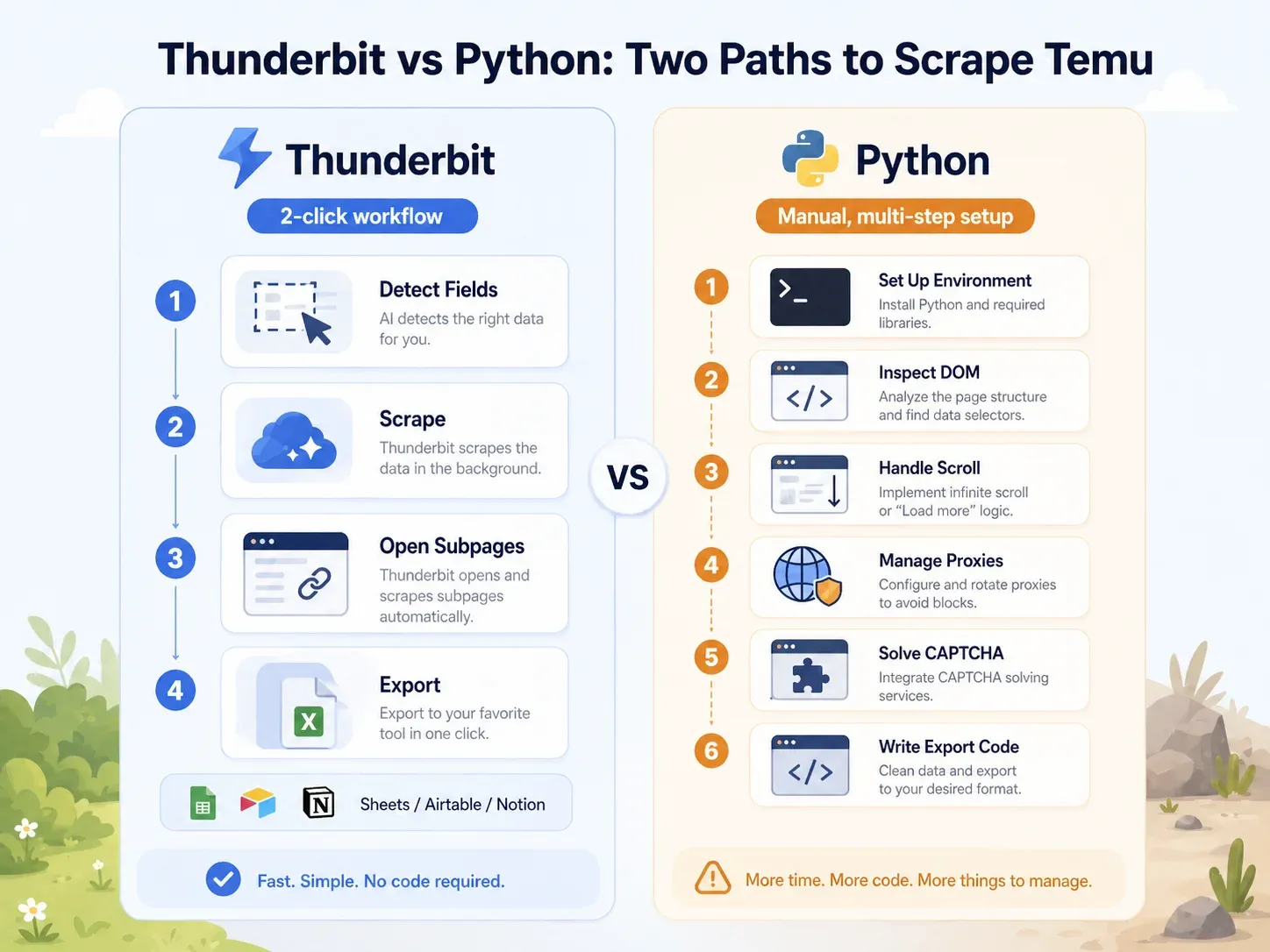
| 作業 | Thunderbit | Python(Playwright) |
|---|---|---|
| Temu のカテゴリページを開く | Chrome でページを開く | Python 環境を用意し、Playwright をインストールし、ブラウザを入れる |
| 項目を特定する | 「AI Suggest Fields」をクリック | DOM、ネットワークリクエスト、JSON ペイロードを確認する |
| 動的読み込みに対応する | ブラウザ / クラウドモード + ページネーション | スクロール / 待機ロジックを書く、リクエストを傍受する |
| ブロックに対応する | クラウドモードまたはブラウザモードを試す | プロキシ、ヘッダー、指紋、リトライ、CAPTCHA を追加する |
| 一覧項目を抽出する | 「Scrape」をクリック | セレクタまたは API 解析ロジックを書く |
| 商品ページを補完する | 「Scrape Subpages」をクリック | 別の PDP クローラを作る |
| エクスポートする | Sheets / Airtable / Notion / Excel をクリック | CSV / JSON / Sheets 連携コードを書く |
| ビジネスユーザー向けの典型的な準備 | 2分未満 | 最低1〜4時間、以後も保守が必要 |
Temu に対する最小限の Playwright プロトタイプは、こんな感じになります(擬似コードで、本番向けではありません)。
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("https://www.temu.com/search_result.html?search_key=kitchen+organizer")
page.wait_for_load_state("networkidle")
for _ in range(8):
page.mouse.wheel(0, 2000)
page.wait_for_timeout(1200)
cards = page.locator("[data-product-id], a[href*='goods.html']")
# 本番コードでは、セレクタ、プロキシ、リトライ、
# CAPTCHA 対応、PDP のクロール、エクスポート処理がまだ必要です。
print(cards.count())
単一の項目を1つ抽出する前に、これだけで10行以上あります。しかも、プロキシ、CAPTCHA、PDP の補完、エクスポートにはまだ触れていません。非技術系ユーザーにとっては、Thunderbit はこの一連の作業を数クリックに圧縮してくれます。開発者にとっては、Python ルートの方が制御性は高いですが、そのぶん保守コストがかなり大きくなります。
Octoparse と ParseHub:ノーコードのデスクトップ型 Temu スクレイパー
Chrome 拡張よりも細かく制御したいが、コードは書きたくない——そんな場合の主な選択肢が Octoparse と ParseHub です。
Octoparse には、公開されている Temu Details Scraper テンプレートがあります。サンプル出力には、商品ID、タイトル、価格、販売者/ショップ情報、画像 URL、割引、ショップ URL、詳細仕様が含まれます。これは大きな利点で、ワークフローをゼロから作るのではなくテンプレートから始められます。Octoparse はクラウド抽出、スケジューリング、ビジュアルなワークフロー構築にも対応しています。
Temu での注意点:
- ボット対策用の追加機能(3ドル/GB の住宅プロキシ、1000件あたり1〜1.50ドルの CAPTCHA 解決など)は、積み上がると高くなります。
- Temu がレイアウトを変えると、テンプレートが壊れることがあります。セレクタを更新するか、Octoparse 側のテンプレート更新を待つ必要があります。
- 設定には、ページの複雑さに応じて10〜60分かかります。
Octoparse の価格は、無料プランが10タスクと月間50Kデータ出力まで。Standard は年払いで月約75ドル、Professional は年払いで月約108ドルです。プロキシ、CAPTCHA、マネージドサービスの追加費用は別です。
ParseHub は、動的ページに強いビジュアル型のデスクトップ/ウェブスクレイパーです(完全な Chromium ブラウザで動作します)。ただし、有料プランは月189ドルからで、個人運用にはかなり高めです。私の調査では、Temu 専用の強い公開テンプレートは見つかりませんでした。ParseHub は、すでにビジュアルなスクレイピングプロジェクト構築に慣れているチームに向いています。
| ツール | Temu での強み | Temu での弱み | 価格 |
|---|---|---|---|
| Octoparse | 公開 Temu テンプレート、ビジュアルワークフロー、クラウド抽出、スケジューリング | テンプレート保守が必要、ボット対策の追加費用がかかる | 無料;Standard は年払いで約75ドル/月;Pro は年払いで約108ドル/月;追加機能は別料金 |
| ParseHub | 動的ページ処理、プロジェクトワークフロービルダー、有料プランで IP ローテーション | 初期価格が高い、公開 Temu テンプレートが見つからない | 有料プランは月189ドルから |
スクレイピング API:Temu 向けの ScraperAPI、Apify、Bright Data
API ベースのスクレイピングサービスは、プロキシ、レンダリング、ボット対策ロジックを処理してくれるので、開発者は解析と保存に集中できます。一度限りのスプレッドシート出力ではなく、パイプラインを構築する場合に向いています。
ScraperAPI は、プロキシローテーションとレンダリングのための開発者向け API です。価格ページには、7日間の無料トライアルで 5,000クレジット、Hobby が月49ドルで 100,000クレジット、以降上位プランがあると記載されています。Temu での注意点は、JavaScript レンダリングとプレミアムプロキシプールが、プランに応じて1リクエストあたり10〜75クレジットかかることです。つまり、クレジット倍率のせいで、実質的な1行あたりコストは表示価格よりかなり高くなる可能性があります。
Apify は、あらかじめ作られた「actor」(スクレイパー)のマーケットプレイスを持つプラットフォームです。Temu 用 actor は複数存在します。コミュニティ管理の Temu Scraper の1つには、無料枠で1,000商品あたり約5ドルの従量課金が記載されています。別の Temu Products Scraper では、1,000結果あたり4ドルとされています。リスクは、actor の品質にばらつきがあり、保守はコミュニティ依存で、Temu 更新時に deprecated になったり壊れたりするものもあることです。導入前には必ず「最終更新日」とユーザー評価を確認してください。
Bright Data はエンタープライズ向けの選択肢です。Temu scraper のページでは、ジョブが Bright Data のインフラ上で動作し、プロキシローテーション、地理ターゲティング、CAPTCHA / ブロック解除ロジック、自動スケールに対応していると説明されています。出力形式は JSON、CSV、Parquet のほか、S3、GCS、Azure Blob、BigQuery、Snowflake へ直接配送できます。業界レビューでは、Web Scraper API の従量課金が1,000レコードあたり約2.5ドル、契約プランは月約499ドルからとされています。強力ですが、予算のあるチーム向けの価格です。
Oxylabs にも、Temu 専用の Scraper API ページがあります。プランは月49ドルからで、最大2,000結果までの無料トライアルがあります。API 経由で構造化された Temu データを取りたい開発チームには、Bright Data の有力な代替です。
| API / プラットフォーム | Temu 固有の根拠 | 強み | 弱み | 最適な用途 |
|---|---|---|---|---|
| ScraperAPI | Temu 専用ページは見つからないが、EC向けボット対策機能は文書化されている | シンプルなエンドポイント、JS レンダリング、プレミアムプロキシ | 高機能ほどクレジット倍率がかかる;開発者がデータ解析を行う必要がある | 開発者のパイプライン |
| Apify | マーケットプレイスに複数の Temu actor がある | actor が適合し保守されていれば、開発者の最短ルート | actor の品質にばらつき、deprecated もある | actor マーケットプレイス + スケジューリングを使いたい開発者 |
| Bright Data | Temu 専用 scraper ページあり | エンタープライズ基盤、ブロック解除、倉庫連携 | 高価;Web Scraper の概念理解も必要 | エンタープライズ規模のデータチーム |
| Oxylabs | Temu 専用 Scraper API ページあり | 明確な従量課金、JS 対応、IP/CAPTCHA 対応の主張 | 開発者向け API ワークフロー | Temu API アクセスが必要な開発チーム |
カスタム Python スクリプト(Playwright / Selenium):完全な制御、重い労力
カスタム Python スクレイパーは、最大限の柔軟性を提供します。それが利点です。Temu には、一般的に Selenium より Playwright の方が良い出発点になります。自動待機の仕組みがあり、JavaScript が多いページの扱いも優れているからです。
ただし、代償はかなり大きいです。
試作には1〜4時間かかります。本番用スクレイパーには、プロキシローテーション、現実的なブラウザ指紋、CAPTCHA 対策、リトライ、スキーマ検証、出力保存、監視、アラート、法務確認が必要です。
しかも壊れます。Reddit のスクレイピングコミュニティでは、Cloudflare、JavaScript レンダリング、ボット指紋を使う現代のECスクレイピングは不安定だと繰り返し語られています。
| 失敗パターン | 典型的な原因 | 対策 | |---|---|---|---| | 空の HTML / 商品がない | 初期 HTML の後で JS が商品カードを読み込む | Playwright を使い、ネットワークと DOM を待つ | | 最初の数件しか取れない | 無限スクロール / 遅延読み込み | スクロールループ、network idle 待機、カード数のしきい値 | | 価格がない、または不安定 | 地域 / セッション / 通貨状態、またはボット対策応答 | ロケール、Cookie、地理対応プロキシを設定する | | 403 / チャレンジ / CAPTCHA | IP 評価、ヘッドレス指紋、リクエスト頻度 | 住宅プロキシ、ステルスブラウザ、低レート化 | | セレクタの破損 | DOM / クラス変更、A/Bテスト | 意味ベース抽出、または可能なら API 解析 |
カスタムスクリプトは「無料」ではありません。サブスクリプション費用を、開発者の工数、プロキシ代、CAPTCHA コスト、保守リスクに置き換えているだけです。社内にスクレイピングエンジニアがいて、特殊なロジックが必要なら、これが正しい選択です。それ以外の人にとっては、実質的に最も高くつく選択肢です。
ベストプラクティス:Temu 商品データを完全に取るためのサブページスクレイピング
この記事で最も重要なベストプラクティスがこれです。しかも、ほとんどの他の記事はこれを扱っていません。
Temu のカテゴリページや検索ページで見えるのは、基本情報——タイトル、サムネイル、価格、ざっくりした評価——だけです。しかし、実際に行動につながる列、たとえば詳細説明、バリエーション一覧、完全なレビュー数、発送見込み、販売者名、仕様表は、商品詳細ページ(PDP)にあります。
一覧ページだけをスクレイプしているなら、手元のデータは不完全です。
2段階のワークフローは次のとおりです。
- STEP 1 — 一覧ページ(PLP)をスクレイプする: Temu の検索ページやカテゴリページから、商品名、価格、サムネイル、評価を抽出します。
- STEP 2 — サブページスクレイピングで補完する: 各商品の PDP にアクセスし、詳細説明、レビュー数、バリエーション、発送時間、販売者情報などの列を追加します。
前後でデータがどう変わるかは次のとおりです。
| 項目 | PLP から(STEP 1) | PDP から追加(STEP 2) |
|---|---|---|
| 商品タイトル | ✅ | — |
| 価格 | ✅ | ✅(検証済み / 割引率) |
| サムネイル | ✅ | — |
| 星評価 | ✅ | ✅(レビュー数付き) |
| 詳細説明 | ❌ | ✅ |
| バリエーション(サイズ、色) | ❌ | ✅ |
| 販売者名 | ❌ | ✅ |
| 発送見込み | ❌ | ✅ |
| 詳細仕様 | ❌ | ✅ |
Thunderbit では、これは1クリックです。最初のスクレイプの後に「Scrape Subpages」をクリックするだけで、AI が各商品 URL を巡回し、追加の列を付け加えます。追加設定も、別のスパイダーも、セレクタ保守も必要ありません。Octoparse の Temu Details テンプレートや Apify の Temu actor も PDP レベルの項目に対応していますが、その分だけ設定と保守が増えます。Python では、別の PDP クローラを作り、セレクタを保守し、詳細ページ内のページネーションにも対応する必要があり、大きな追加工数になります。
ベストプラクティス:継続的な価格・在庫監視のための Temu スクレイピングのスケジュール実行
1回限りのスクレイプは、商品発掘には便利です。しかし、競合インテリジェンスには繰り返しの観察が必要です。
価格は変わり、商品は欠品し、新商品は毎日増え、セールに合わせて割引の深さも変わります。週次や日次のスクレイプを行えば、チームが実際に使える履歴テーブルができます。
自動化する価値があるユースケースは3つあります。
- 価格監視: 競合の Temu 上位50SKUを毎週追跡します。更新された価格を自動で Google Sheets に出力し、自社価格と一目で比較できるようにします。
- 在庫・販売可否の監視: 注目商品の欠品、新しいバリエーションの追加、発送見込みの変化を検知します。
- 新商品 / トレンド検知: Temu の「New Arrivals」や優先カテゴリページを毎日スクレイプするように設定します。販売数やレビュー数で並べ替え、伸び始めた商品を早めに見つけます。
Thunderbit では、間隔を自然文(「毎週月曜9時」など)で書き、対象 URL を入力して、「Schedule」をクリックするだけです。スクレイプはクラウドで実行され、選んだ保存先へ出力されます。AI が毎回ページを新しく読み取るため、Temu のレイアウト変更にもスケジュールスクレイプは自動追従します。Temu が商品カードを再設計しても、セレクタを更新する必要はありません。
代替案は、cron ジョブを組み、Python スクリプトを保守し、プロキシローテーションを設定し、出力パイプラインを作り、Temu のレイアウト変更のたびにセレクタを修正することです。非技術系チームにとっては現実的ではありません。開発者にとっても、継続的な負荷です。Apify と Bright Data もスケジュール実行に対応していますが、より技術的な設定と高い最低料金が必要です。
ベストプラクティス:スクレイプ → 整形 → 出力 → 活用 の Temu データ運用フロー
多くのスクレイピングガイドは「CSV をダウンロード」で終わります。
しかし、ビジネスユーザーが必要とするのは、実際に使うツールの中にあるデータです。共同作業には Google Sheets、商品データベースには Airtable、チームダッシュボードには Notion。真のベストプラクティスは、エンドツーエンドのワークフローです。
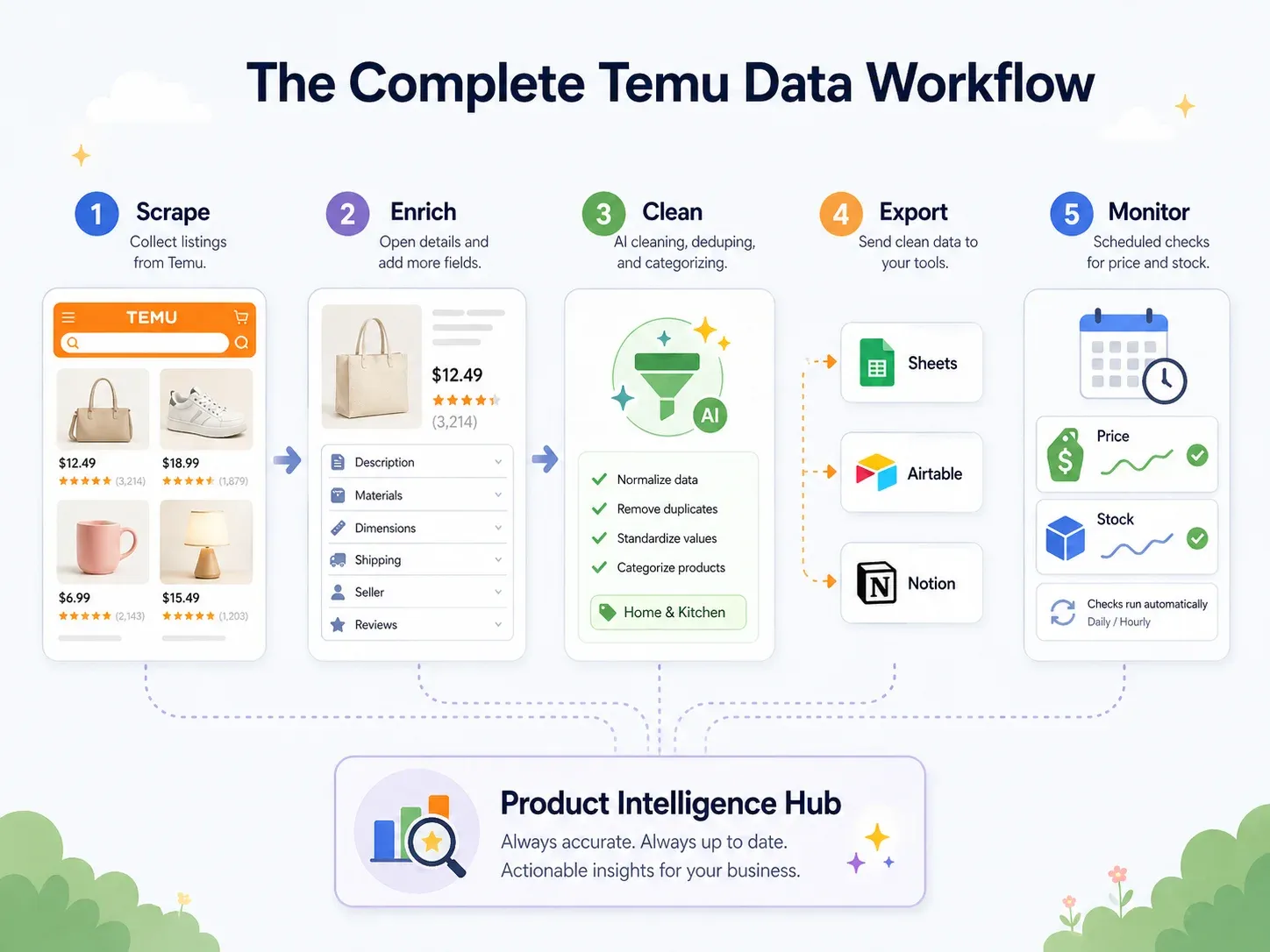
| ワークフローのステップ | 起きること | Thunderbit の機能 |
|---|---|---|
| スクレイプ | Temu ページからデータを抽出する | AI Suggest Fields → Scrape(2クリック) |
| 補完 | 各商品の詳細ページを訪問する | Scrape Subpages(1クリック) |
| 整形・ラベル付け | 商品を分類し、価格を正規化し、タイトルを翻訳する | Field AI Prompt — スクレイプ中にラベル付け、整形、翻訳 |
| 出力 | データを業務ツールへ送る | Excel、Google Sheets、Airtable、Notion へ無料出力;CSV / JSON をダウンロード |
| 監視 | 時間経過による変化を追う | 自然文の間隔指定ができる Scheduled Scraper |
具体例を挙げると、Temu のキッチン用品を200件スクレイプします。スクレイプ中に Field AI Prompt を使って、各商品を「Utensils / Small Appliances / Storage / Cleaning / Decor」のいずれかへ自動分類します。価格は数値の USD に正規化され、中国語の商品タイトルは英語に翻訳されます。データは、画像を保持したまま Airtable のベースへ直接出力されます(URL だけではなく、Thunderbit の画像スクレイピングガイド にあるように、実際の画像添付ファイルとして保存されます)。その後、スケジュールスクレイプで毎週データを更新します。
Temu データに使える Field AI Prompt の例:
- 「この商品を Kitchen Utensils、Small Appliances、Storage、Cleaning、Decor、Other のいずれかに分類してください。カテゴリのみ返してください。」
- 「ブランド名、数量、サイズ、型番を保持しつつ、商品タイトルを簡潔な英語に翻訳してください。」
- 「通貨記号を含めず、価格を数値として正規化してください。」
- 「評価、レビュー数、販売数に基づいて需要を High、Medium、Low のいずれかでラベル付けしてください。データがない場合は Unknown を返してください。」
このワークフローにより、単なる生データのスクレイプが、開発者なしで運用できる生きた商品インテリジェンスデータベースに変わります。
Temu スクレイパー比較表:一覧で見る
| ツール | スキルレベル | セットアップ時間 | ボット対策対応 | サブページスクレイピング | スケジューリング | 出力先 | 価格帯 | 最適な用途 |
|---|---|---|---|---|---|---|---|---|
| Thunderbit | 初心者 | 数分 | ブラウザモード、クラウドモード、AI 項目検出 | あり(Scrape Subpages) | あり(自然文スケジュール) | Excel、CSV、Google Sheets、Airtable、Notion、JSON | 無料6ページ;有料は500クレジットで月額約9〜15ドルから | 非技術系のECチーム、ドロップシッパー |
| Octoparse | 初心者〜中級 | 10〜60分 | クラウド抽出、プロキシ / CAPTCHA 追加機能 | あり(テンプレートワークフロー) | あり(有料 / クラウドプラン) | Excel、CSV、JSON、HTML、XML、データベース、Google Sheets | 無料;Standard は年払いで月約75ドル;追加機能は別料金 | ビジュアルワークフローと Temu テンプレートが欲しい運用担当 |
| ParseHub | 初心者〜中級 | 30〜60分 | 動的レンダリング、有料の IP ローテーション | あり(プロジェクトフロー) | 有料プラン | CSV / JSON、有料で Dropbox / S3 | 月189ドルから | 動的サイト向けのビジュアルプロジェクトを作るチーム |
| ScraperAPI | 開発者 | 数時間 | プロキシローテーション、JS レンダリング、プレミアムプール | カスタム実装 | DataPipeline / スケジューラー | HTML / JSON / CSV | 5K クレジットのトライアル;Hobby は月49ドル;上位プランあり | Temu 向けのカスタムパイプラインを作る開発者 |
| Apify | 中級 | actor が合えば10〜30分 | actor ごとのブラウザ / プロキシロジック | actor 依存 | あり | JSON、CSV、Excel、API / データセット | プラットフォームは無料;Temu actor は1,000商品あたり約4〜5ドル | actor の品質を見極められる開発者 / 運用担当 |
| Bright Data | 上級 / 企業向け | 数時間〜数日 | 完全なプロキシ、CAPTCHA、ブロック解除、自動スケール | API / scraper 経由でカスタム | あり | JSON、CSV、Parquet、S3、GCS、Azure、BigQuery、Snowflake | 従量課金で1,000レコードあたり約2.5ドル;契約は月約499ドルから | エンタープライズのデータチーム、大量抽出 |
| Oxylabs | 上級 | 数時間 | JS 対応、IP / CAPTCHA 対応の主張 | API 経由でカスタム | あり | JSON / API 出力 | 月49ドルから;最大2,000結果のトライアル | Temu API アクセスが必要な開発チーム |
| カスタム Python(Playwright) | 上級 | 1〜4時間以上;継続保守あり | 手動のプロキシ、CAPTCHA、指紋対応 | 完全カスタム | cron / キュー / 手動 | カスタム | 開発工数 + プロキシ / CAPTCHA / ホスティング費用 | 特殊ケース、スクレイピングエンジニアがいるチーム |
どの Temu スクレイパーを選ぶべきか? すばやいおすすめ
- すぐに商品調査をしたいドロップシッパー? まずは Thunderbit の無料枠 を試してください。「Temu データが欲しい」から「スプレッドシートができた」までの最短ルートです。対象ページで動くなら(公開カテゴリページや商品ページの多くでは動くはずです)、それで終わりです。
- ビジュアル操作と再利用可能なテンプレートが欲しい運用担当? Octoparse には公開 Temu Details テンプレートとビジュアルワークフロービルダーがあります。セットアップは10〜30分程度を見込み、ある程度のプロキシ / CAPTCHA 設定も必要です。
- データパイプラインや社内ツールを作る開発者? ScraperAPI か Apify なら、コードやスケジュールジョブと連携できる API / actor ワークフローが使えます。Apify の actor は保守状況とユーザー評価をしっかり確認してください。
- 大量の Temu データと倉庫連携が必要な企業チーム? Bright Data はインフラ寄りの選択です。高価ですが、スケール、ブロック解除、S3 / BigQuery / Snowflake への配送を扱えます。
- 特殊なロジックが必要なスクレイピングエンジニア? カスタム Playwright / Selenium なら完全な制御が可能です。ただし、継続保守、プロキシ代、CAPTCHA 対応の予算は確保してください。
多くの非技術系ビジネスユーザーには、まず Thunderbit の無料枠を試すことをおすすめします。最初に確認すべきは常に「この Temu の具体的なページから必要な行を取れるか?」です。しかも、それはお金を使わず2分以内に確かめられます。開発者なら、予算を決める前に Apify、ScraperAPI、そして小さな Playwright プロトタイプで、成功1行あたりのコストを比較してください。
Temu スクレイピングで Thunderbit を無料で試す
Temu のスクレイピングに関する FAQ
Temu をスクレイピングするのは合法ですか?
管轄地域、収集するデータ、アクセス方法、データの使い方によって異なります。Temu の 利用規約 では、ページやデータのクロール、スクレイピング、スパイダー化を含む自動アクセスが明確に制限されています。米国の裁判所には、公開データへのアクセスに有利な前例(第9巡回区の hiQ v. LinkedIn 判決)もありますが、その後の判決 では契約違反や不法侵入の主張も認められています。要するに、公開されている商品データを調査目的でスクレイプすることは、状況によっては正当化できる場合がありますが、利用規約、プライバシー法、著作権、そしてデータの使い方がすべて重要です。これは法的助言ではありません。商用利用では弁護士に相談してください。
Temu のウェブサイト構成はどのくらいの頻度で変わりますか?
公開された一定のサイクルはありません。コミュニティ報告やツールのエコシステムは、Temu を動的で頻繁に更新される対象として扱っています。CSS セレクタはいつ壊れてもおかしくない前提で、固定セレクタよりも AI / 意味ベース抽出や、積極的に保守されているテンプレートを優先してください。
ブロックされずに Temu をスクレイピングできますか?
少量の公開ページを適切な速度で取得するなら、可能です。特に、本物のブラウザレンダリング、セッション対応、スロットリングを備えたツールを使う場合は有効です。ただし、どのツールも万能の保証ではありません。ローテーションIPを使うクラウドスクレイピングは公開カタログページに向いており、現在のセッションを使うブラウザスクレイピングは、地域、ログイン、ポップアップがデータに影響する場合により適しています。
Temu の商品ページからどんなデータを抽出できますか?
一般的な公開項目には、商品タイトル、URL、現在価格、元価格、割引率、画像 URL、星評価、レビュー数、販売数、販売者/ショップ名、配送情報、カテゴリ、商品仕様、バリエーション(色、サイズ)、スクレイプ時刻があります。取得可能な正確な項目は、ページの種類(一覧か詳細か)と地域によって異なります。
Temu をスクレイピングするにはプロキシが必要ですか?
少量のブラウザモードによる手動的な取得(数ページずつ)なら、必須ではないかもしれません。クラウド、スケジュール実行、大量取得では、通常プロキシまたはマネージドのブロック回避基盤が必要です。Thunderbit、Bright Data、ScraperAPI のようなツールは、プロキシ管理をプラットフォームに組み込んでいるため、別途設定する必要がありません。
関連トピックをさらに深く知りたい方は、価格比較のための Web スクレイピング、おすすめのEC向け Web スクレイパー、ウェブサイトのデータを Excel にスクレイプする方法、Google Sheets にスクレイプする方法 もご覧ください。さらに、Thunderbit の YouTube チャンネル で解説動画も視聴できます。
Temu スクレイピングに Thunderbit を試す Get Started Free
さらに詳しく知る




