
Google では1日あたりが行われており、推定ではに近いとも言われています。そして、その数字は今も増え続けています。こうした検索データは、SEOチーム、セールスオペレーション、ECアナリスト、そしてリアルタイムのWeb根拠を必要とするAIエージェントにとって、まさに宝の山です。問題は? 2026年にSERP APIを選ぶのは、ツール選びというより、料金ページ、クレジット制、そして「構造化JSON」に関する曖昧な約束が入り組んだ迷路を読み解く作業に近いことです。
私はこの数週間、8つのSERP APIプロバイダーを徹底的に調査してきました。応答速度をテストし、分かりにくい課金モデルを横断して料金を正規化し、各サービスがどのSERP機能を実際に構造化フィールドとして解析しているのかを確認しました。目的はただひとつ、他の記事にはない、正直で比較可能な評価をお届けすることです。この記事では、速度、実コスト(大規模利用時)、解析範囲、AIエージェント適性、本番環境での信頼性を取り上げます。「比較しているのは料金ページであって、実際の支出ではない」という不満にうんざりしているなら(これは私が見つけたで実際に見た言葉です)、まさにこの記事が役立つはずです。
2026年にSERP APIが必要な理由、そして選ぶのが難しい理由
SERP APIは、検索クエリを検索エンジンに送信し、検索結果ページを機械可読な出力、通常はJSONで返すホスト型サービスです。自前でプロキシローテーション、CAPTCHA処理、ブラウザレンダリング、パーサーを組む代わりに、エンドポイントを呼び出すだけで構造化データを取得できます。概念はシンプルですが、市場はかなり複雑です。
用途は順位計測をはるかに超えて広がっています。
- SEOチームは、順位、スニペットの占有状況、People Also Askの質問、競合の可視性を把握する必要があります。
- セールスチームとGTMチームは、SERPを使って企業、レビューサイト、ディレクトリ、購買シグナルを見つけます。
- ECチームは、Google Shopping、広告、競合価格を監視します。
- AI開発者は、SERPデータをLLMエージェント、RAGパイプライン、n8nやLangChainのようなワークフローツールに流し込みます。
は、に達し、CAGRは約13.78%で成長すると予測されています。SERP APIは、その大きな一角を占めています。
ここでの根本的な悩みは、どのプロバイダーも「構造化JSON」をうたっている一方で、実際に解析されるSERP要素、たとえばPAA、ナレッジパネル、ローカルパック、ショッピング広告、強調スニペットなどは、サービスごとに大きく異なることです。料金体系も同様に分かりづらいです。検索単位で課金するものもあれば、クレジット単位、結果単位、速度や地域によってレートが変わるものもあります。あるRedditユーザーはこう言い表していました。「SerpApiは成功した検索ごと、ScraperAPIはクレジットで包む形、Serperdevはクレジットを実際の作業量に当てはめると安く見えなくなる。」
この記事では、私が他で見つけられなかったギャップを埋めます。各APIが実際に返す内容を示す解析マトリクス、1K/10K/100Kクエリでの料金正規化、AIエージェント適性、本番対応度のデータをまとめました。
検証方法: 最適なSERP APIを選ぶための基準
本番利用者が本当に気にするポイントに直結する8つの観点から各プロバイダーを評価しました。競合比較記事の多くは、このうち2~3項目を表面的に触れるだけです。私は、8項目すべてを、根拠付きで見たかったのです。
速度と応答時間。 第三者ベンチマーク、特にと各社ドキュメントを参照しました。リアルタイムダッシュボードや、30秒も待てないツール呼び出し型のAIエージェントを作るなら、速度は重要です。
大規模時の料金(1K、10K、100Kクエリ)。 各社の料金を、成功したクエリ1,000件あたりのコストに正規化しました。クレジット制、サブスクリプションバケット制、従量課金制を公平に比べるには、これが唯一の方法です。
解析されるSERP機能(オーガニック結果以外)。 ドキュメントとサンプルレスポンスを確認し、各APIが生HTMLではなく、どのSERP要素を構造化フィールドとして返すかを検証しました。
無料枠と従量課金の有無。 初期ハードルの低さは重要です。実際の業務負荷で試す前に数百ドルを払わないと試せないなら、それは警戒サインです。
AIと自動化との統合。 2026年には、ダッシュボードよりもAIエージェントにSERP APIを流し込みたいチームのほうが増えています。スキーマの安定性、きれいな出力、Markdown変換は、下流のLLMが使ううえで重要です。
複数エンジン対応。 多くの記事はGoogleだけに焦点を当てています。私は、Bing、Yandex、DuckDuckGo、Baiduなどへの対応状況も確認しました。
レート制限と本番対応性。 他の比較記事は、レート制限、リトライポリシー、SLAを体系的に比べていません。しかし、1日数千件のクエリにスケールするチームには、これらの情報が必要です。
開発者にとっての使いやすさ。 ドキュメント品質、SDKの有無、最初の結果が出るまでの速さです。
1. Thunderbit
は、従来のSERP APIとは根本的に異なるアプローチを採っています。あらかじめ決められたSERP要素を固定エンドポイントで解析するのではなく、ThunderbitのExtract APIでは独自のJSON Schemaを定義でき、AIが検索結果ページから指定したフィールドだけを正確に抽出します。Distill APIは、あらゆるURLをきれいなLLM対応Markdownに変換します。
つまりThunderbitは、Google、Bing、Yandex、DuckDuckGo、その他どの検索エンジンでも使えます。AIが毎回ページを読み直すため、ハードコードされたセレクタに依存しません。SERPのレイアウトは常に変化します。パーサーの更新をプロバイダーが対応してくれるのを待つ必要はありません。
主な機能
- Extract API: 独自のJSON Schema(オーガニック結果、PAAの質問、ローカルパックの店舗、ショッピング商品のように、必要なもの何でも)を定義し、必要なフィールドだけを構造化データとして取得できます。
- Distill API: あらゆるSERPページをきれいなMarkdownに変換。RAGパイプラインやLLM要約に最適です。
- マルチエンジン対応が前提: Googleだけでなく、アクセス可能なあらゆる検索ページで動作します。
- バッチ処理: 複数URLを並列で処理できます。
- 組み込みのボット対策: CAPTCHA解決、JSレンダリング、プロキシローテーションが含まれています。
- ティア別レート制限: Free(10 req/min、同時2件)、Pro(100 req/min、同時10件)、Enterprise(1,000 req/min、同時50件)。
料金
クレジット制です。Distillは1ページあたり1クレジット、Extractは1ページあたり20クレジットです。テスト用の無料クレジットもあります。年額プラン換算では、Distillの限界コストは1,000ページあたり約0.80米ドルまで下がり、Extractはフル活用時に1,000ページあたり約16米ドルです。Extractの価値は、下流システムが必要とするスキーマをそのまま取得でき、後処理が不要な点にあります。
最新のパッケージはをご確認ください。
こんな方に最適
AIエージェントのワークフロー、RAGパイプライン、マルチエンジンのスクレイピング、固定出力ではなく柔軟なスキーマが必要なチーム、そして新しいSERP機能のサポート追加を待つのに疲れた方に最適です。
2. SerpApi
は、この分野の老舗で、2016年から運営されており、Google特化エンドポイントの種類が最も豊富です。Google Search、Maps、Shopping、Scholar、News、Jobs、Trends、Images、Videosなどをカバーします。
主な機能
- Google各製品向けの専用エンドポイントがあり、地理ターゲティングも成熟しています(都市レベルまで対応)。
- PAA、ナレッジパネル、ローカルパック、広告、ショッピング結果、強調スニペット、回答ボックス、関連検索を構造化フィールドとして解析します。
- ドキュメントが整備されており、複数言語のクライアントライブラリもあります。
料金
があります。Starterプランは1,000検索で月25米ドル(実質1,000件あたり25米ドル)。Popularプランは15,000検索で月130米ドル(約1,000件あたり8.67米ドル)。Big Dataは500,000検索で月2,750米ドル(約1,000件あたり5.50米ドル)。シンプルな従量課金はなく、サブスクリプションバケット方式です。
速度と信頼性
HasDataのベンチマークでは平均応答時間は約5.49秒で、最速ではありませんが安定しています。SerpApiは有料プランで99.95%の稼働率SLAを掲げており、同時リクエストの上限はプランによって異なります。
こんな方に最適
Google製品のカバー範囲が最も広いサービス(Maps、Scholar、Shopping、Jobs)を、高精度かつ安定したスキーマで使いたいチームに向いています。予算に余裕のあるエンタープライズ案件にも適しています。
3. Serper
は、速度とコストを重視した選択肢です。高速なGoogle SERPスクレイピングに特化した比較的新しいサービスで、非常に競争力のある価格設定のため、n8nやLangChainのコミュニティでAIエージェント連携用として人気があります。
主な機能
- Google Search、News、Scholar、Images、Shopping、Videos、Places、Patents、Autocomplete向けのきれいなJSON出力。
- 導入が非常に簡単で、1分以内に結果を取得できます。
- シンプルなので、AIエージェントフレームワークにネイティブ統合しやすいです。
料金
登録時に2,500件の無料クエリがあります。エントリー価格は1検索あたり約0.001米ドルで、高ボリュームでは約0.00075米ドルまで下がります。従量課金との相性が良いです。注意点として、クエリあたり10件を超える結果を要求すると2クレジット消費する場合があります(現在の挙動はダッシュボードで確認してください)。
速度と信頼性
ベンチマークでは最速クラスで、HasDataでは平均約2.87秒です。サポートはメールのみで、運営チームの公開露出は比較的少ないため、そこを気にするユーザーもいます。非常に高い同時実行数では、一部のレビューで信頼性への懸念が指摘されています。ただし、多くの用途では十分に堅実です。
こんな方に最適
予算重視のプロジェクト、スタートアップ、そして高速かつ低価格のGoogle SERPデータを必要とするAIエージェント連携に向いています。コスト/クエリが主な制約となる大量順位計測にも適しています。
4. Scrapingdog
は5年以上市場にあり、第三者ベンチマークでは一貫して最速クラスとして登場します。HasDataでは、成功率100%と測定されています。
主な機能
- Google SERP APIは、オーガニック結果、PAA、強調スニペット、広告、ローカル結果を構造化JSONで返します。
- 生HTMLと解析済みJSONの両方を選べます。
- 多言語ドキュメントと、ほとんどのプログラミング言語向けのコード例があり、導入は数時間ではなく数分で済みます。
- 24時間365日のサポートがあります。
料金
があります。有料プランは月約40米ドルから。1回あたりの料金は約0.001米ドルから始まり、大規模利用では大幅に下がります。比較によっては、最上位では0.000058米ドルまで下がるとされるものもあります。
速度と信頼性
速度の数字は本当に優秀です。レイテンシーに敏感で、高ボリュームの固定スキーマGoogle SERP抽出を行うなら、Scrapingdogは生の応答速度で非常に強いです。
こんな方に最適
低レイテンシーと低コストが必要な、高ボリュームのSEOツールや順位トラッカーに最適です。API応答の1ミリ秒単位まで気にする本番システム向けです。
5. DataForSEO
は単なるSERP APIではなく、SEO製品を構築する企業向けに設計されたAPIスイート全体です。SERP、キーワード、被リンク、ビジネスデータ、Google Ads、Trendsなどをカバーします。
主な機能
- 極めて包括的なSERP機能解析。オーガニック、広告、ローカルパック、ナレッジグラフ、PAA、強調スニペット、ショッピング、画像、動画、トップストーリーなどに対応します。
- 2つのモードがあります。Live(同期)はリアルタイムダッシュボード向け、Standard(非同期)はタスクをキューに積んで後で取得するバッチ処理向けです。
- マルチエンジン対応。Google、Bing、Yahoo、Baidu、Naver、Seznamなどをサポートします。
料金
従量課金ですが、エンドポイント、エンジン、デバイス、優先度、モードによって料金が変わります。SERP料金は通常、Googleオーガニックで1タスクあたり約0.0006~0.002米ドルです(StandardかLiveか、優先度設定によって変動)。ドキュメントは情報量が多いので、料金計算機を使う時間を確保してください。。
速度と信頼性
Standardの非同期モードはタスクをキューに積むため、やや遅くなることがあります(約10秒)。Liveや高速モードはコストが上がりますが、リアルタイムダッシュボードには適しています。長年の実績があり、安定性も高く、エンタープライズサポートも利用できます。
こんな方に最適
SEOプラットフォーム、順位計測ダッシュボード、キーワード調査ツールを作るSaaS企業に向いています。複雑なドキュメントやエンタープライズ級の基盤に慣れているチームにも適しています。
6. Bright Data
はエンタープライズ向けの有力選手です。SERP APIは、プロキシ、データセット、Web Unlocker、スクレイピングツールなど多くの製品群の一部です。価値の中心は、スケール、信頼性、インフラです。
主な機能
- Google Maps、Shopping、一般検索向けの専用エンドポイントに加え、Bing、Yahoo、Yandex、DuckDuckGoをカバーするプロキシ基盤によるマルチエンジン対応があります。
- 組み込みのブロック回避技術により、100%成功率をうたっています。
- Bright Dataが本当に強いのは、地理ターゲティング、同時実行、そしてエンタープライズ規模でのブロック回避です。
料金
エンタープライズ志向です。公開価格では従量課金とサブスクリプションの両方があり、多くの比較では月499米ドル前後の最低コミットメントが言及されています。1回あたりのコストは約0.005米ドルから始まりますが、量が増えると下がります。。試用クレジットとして5米ドル相当があります。
速度と信頼性
ベンチマークでは2~5.58秒程度がよく見られます。Bright Dataを選ぶ理由は、中央値のレイテンシーそのものではありません。エンタープライズSLA、専任サポート、そして数百万件の同時リクエストでも劣化しないインフラにあります。では、段階的に負荷を上げることが推奨されています。
こんな方に最適
月間数百万件のSERPを収集するエンタープライズチーム、Google Mapsやローカルビジネスデータを大規模に扱う組織、すでにBright Dataのプロキシ製品を使っているチームに最適です。
7. ScraperAPI
は、一般用途のWebスクレイピングAPIでありながら、構造化されたGoogle SERPエンドポイントも提供しています。あらゆる用途を1つで済ませたい方向けの選択肢で、4000万超のIPプロキシプールを備え、統合も簡単です。
主な機能
- Google Search、Shopping、News、Jobs向けの構造化データエンドポイント。
- 機械学習ベースのブロック回避とCAPTCHA解決、さらにJavaScriptレンダリングが追加料金なしで含まれます。
- ローカライズ結果向けの地理ターゲティングに対応しています。
料金
7日間の無料トライアルで5,000クレジットが付与されます。有料プランは月約49米ドルから。注意点として、SERP呼び出しは通常のスクレイピングリクエストとは異なるクレジットを消費する場合があるため、必ず実際に成功したSERPクエリ数に基づいて正規化してください。。
速度と信頼性
率直に言うと、HasDataのベンチマークではSERPクエリの平均応答時間は約33.66秒です。これは専用SERP APIと比べてかなり遅いです。成功率は高い(99.9%)ものの、レイテンシーの関係でリアルタイム用途にはやや不向きです。バッチ処理には向いています。
こんな方に最適
SERPを付加機能として使える、総合的なWebスクレイピングソリューションが必要なチーム向けです。速度より信頼性と導入のしやすさを重視する案件、または他のスクレイピング用途ですでにScraperAPIを使っていて、ベンダーを集約したい開発者に向いています。
8. Apify
は純粋なSERP APIではありません。「Actors」と呼ばれる再利用可能なスクリプトを中心にした、スクレイピングと自動化のプラットフォームです。Google検索のスクレイピング、Maps抽出、ワークフロー自動化などに使えます。必要に応じて、ぴったり合うスクレイパーを選ぶ、あるいは自分で作るマーケットプレイスのようなものだと考えてください。
主な機能
- 事前構築済みのがあり、機能範囲はさまざまです。
- 高いカスタマイズ性。独自のスクレイピングワークフローを構築し、actorを連結し、実行をスケジュールできます。
- JSONで出力し、actor設定を通じて特定のSERP機能を柔軟に解析できます。
- SERP抽出を他のスクレイピング/自動化タスクと組み合わせる用途に強いです。
料金
月間プラットフォームクレジット付きの無料枠があります(約5米ドル相当、約1,400件の結果)。有料プランは月約49米ドルから。Actorごとのコストは異なり、結果単位で課金するものもあれば、計算単位で課金するものもあります。第三者比較では、小規模利用で1検索あたり約0.003米ドルとされることが多いです。。
速度と信頼性
HasDataでは平均約8.2秒です。actorベースのアーキテクチャは、専用SERPエンドポイントに比べるとオーバーヘッドがあります。リアルタイム検索よりも、スケジュール実行やバッチ処理に向いています。
こんな方に最適
SERPデータだけでなく、カスタムスクレイピングや自動化ワークフローが必要なチーム向けです。他のWebスクレイピング作業とSERP抽出を組み合わせる案件、事前構築済みエンドポイントより最大限の柔軟性を求める開発者に向いています。
SERP機能解析マトリクス: 各APIが実際に返すもの
これは、他では見つけられなかった比較です。どのプロバイダーも「構造化JSON」と言いますが、実際に第一級フィールドとして解析されるSERP要素は大きく異なります。私はそれぞれのドキュメントとサンプルレスポンスを確認しました。
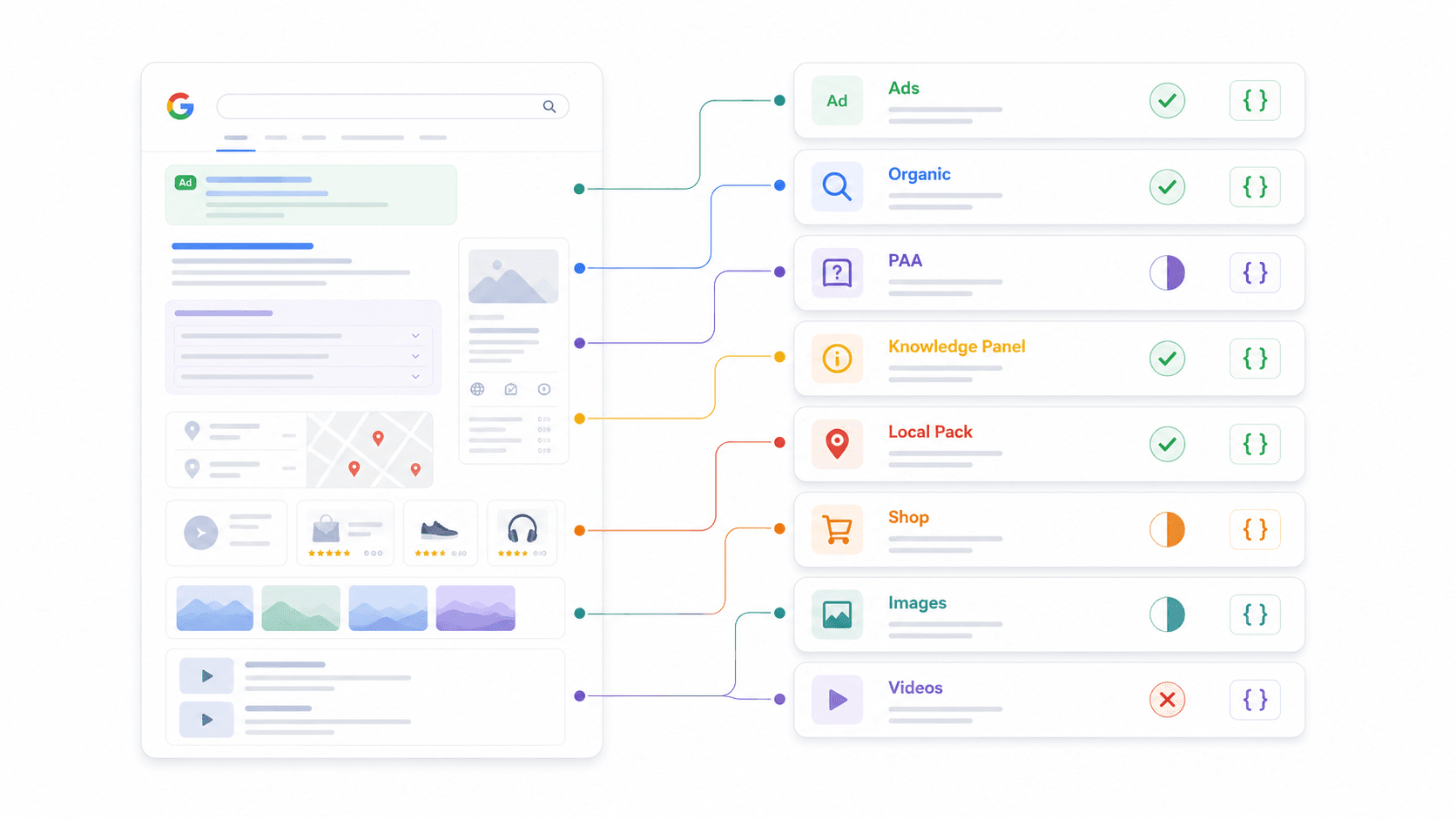
| SERP機能 | Thunderbit | SerpApi | Serper | Scrapingdog | DataForSEO | Bright Data | ScraperAPI | Apify |
|---|---|---|---|---|---|---|---|---|
| オーガニック結果 | カスタムスキーマ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | actor依存 |
| People Also Ask | カスタムスキーマ | ✅ | ✅ | ✅ | ✅ | 一部対応 | 一部対応 | actor依存 |
| ナレッジパネル | カスタムスキーマ | ✅ | 一部対応 | 一部対応 | ✅ | 一部対応 | 一部対応 | actor依存 |
| ローカルパック / Maps | カスタムスキーマ | ✅ | ✅ | 一部対応 | ✅ | ✅ | 一部対応 | actor依存 |
| ショッピング結果 | カスタムスキーマ | ✅ | ✅ | 一部対応 | ✅ | ✅ | ✅ | actor依存 |
| 強調スニペット | カスタムスキーマ | ✅ | 一部対応 | ✅ | ✅ | 一部対応 | 一部対応 | actor依存 |
| 広告(上部/下部) | カスタムスキーマ | ✅ | 一部対応 | ✅ | ✅ | 一部対応 | 一部対応 | actor依存 |
| 画像パック | カスタムスキーマ | ✅ | ✅ | ✅ | ✅ | 一部対応 | 一部対応 | actor依存 |
| 動画結果 | カスタムスキーマ | ✅ | ✅ | 一部対応 | ✅ | 一部対応 | 一部対応 | actor依存 |
Thunderbitでいう「カスタムスキーマ」とは何か: あらかじめどのSERP機能を解析するかを決め打ちするのではなく、必要なフィールドだけを抽出するJSON Schemaを自分で定義します。PAAの質問に回答要約、商業意図シグナルまで欲しいですか? そのスキーマを定義すれば、AIがそれを返します。この柔軟性があるからこそ、ThunderbitはGoogleだけでなく、あらゆる検索エンジンで使えるのです。
これがワークフローで重要な理由: コンテンツ戦略のためにPAAデータが必要なら、本当にそのプロバイダーが解析しているか確認してください。EC向けにショッピング広告を追跡するなら、構造化されたショッピング項目があるかを確認してください。「構造化JSON」という言葉だけで完全対応だと決めつけないでください。
大規模時の実コスト: 1クエリあたりの比較
サイト上の表示価格だけでは全体像は分かりません。私は、3つのボリューム帯で成功クエリ1,000件あたりのコストに正規化しました。
| プロバイダー | 1Kクエリのコスト | 10Kクエリのコスト | 100Kクエリのコスト | 従量課金あり? | 無料枠 |
|---|---|---|---|---|---|
| Thunderbit(Distill) | 約0.80~3.20米ドル | 約8~32米ドル | 約80~320米ドル | クレジットパック | 無料クレジット |
| Thunderbit(Extract) | 約16~64米ドル | 約160~640米ドル | 約1,600~6,400米ドル | クレジットパック | 無料クレジット |
| SerpApi | 25米ドル(Starter) | 約87米ドル(Popular) | 約550米ドル(Big Data) | なし(サブスク) | 月250件 |
| Serper | 約1米ドル | 約10米ドル | 約75~100米ドル | あり | 2,500クエリ |
| Scrapingdog | 約1米ドル | 約10米ドル以下 | 10米ドルを大きく下回ることも | プラン/クレジット | 1,000クレジット |
| DataForSEO | 約0.60~2米ドル | 約6~20米ドル | 約60~200米ドル | あり | 試用クレジット |
| Bright Data | 約0.50~5米ドル超 | 要見積もり | エンタープライズ規模で最適 | あり/プラン制 | 試用クレジット(5米ドル) |
| ScraperAPI | クレジット依存 | クレジット依存 | クレジット依存 | プラン/クレジット | 5,000試用クレジット |
| Apify | 約3米ドル(小規模) | actor依存 | actor依存 | プラットフォームクレジット | 月間無料クレジット |
見落としがちな追加コスト:
- Serperでは、クエリあたり10件を超える結果で2クレジットかかる可能性。
- DataForSEOでは、StandardとLive/高優先度モードの価格差。
- ScraperAPIでは、SERPと通常スクレイピングでクレジット倍率が違うこと。
- Bright Dataでは、エンタープライズの最低コミットメント。
各ティアでの価値:
- 副業・小規模案件(月50米ドル): 固定のGoogle SERP JSONならSerperまたはScrapingdog。
- 成長中のチーム(月1万~5万クエリ): 解析の深さ次第でSerper、Scrapingdog、DataForSEO。
- エンタープライズ(月10万件超): DataForSEO、Bright Data、またはSerpApi Big Data。
- AIファーストの抽出: Thunderbit。下流のエージェントが期待するスキーマに後処理なしで合わせられるからです。
2026年のAIエージェントとLLMワークフローに最適なSERP API
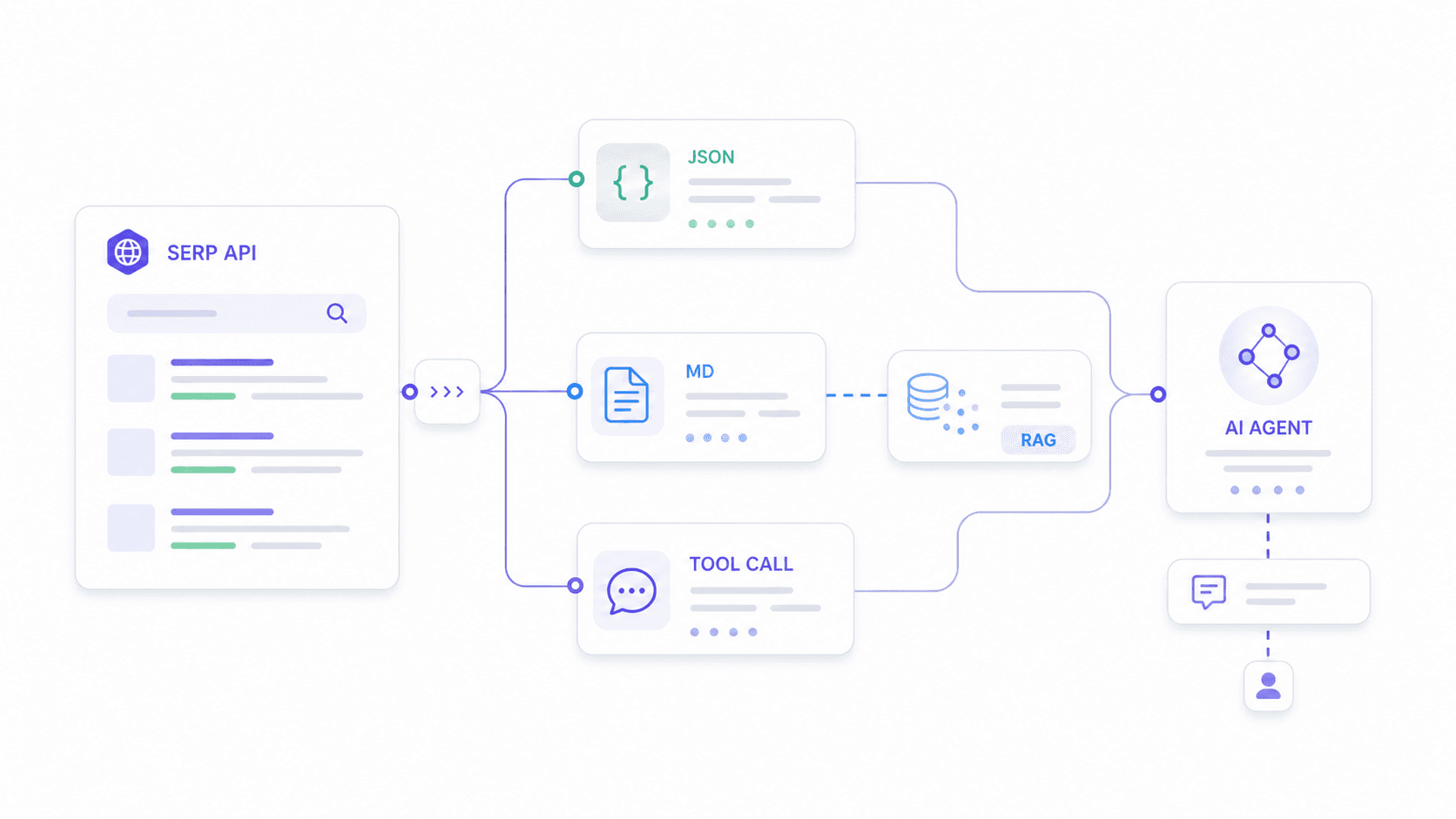
これは、他ではあまり扱われていないユースケースです。私は少なくとも3件のを見つけました。そこでは、SERP APIをn8nワークフローやAIエージェントに統合しようとしているユーザーが語られており、そのうち1件では「AIエージェントで正しく動かす方法がまだ分からない」と明言されていました。
AIエージェントが必要とするものは、順位計測ダッシュボードとは違います。必要なのは次のようなものです。
- スキーマが安定したJSON。プロバイダーが出力形式を更新しても、解析ロジックが壊れないこと。
- 下流モデルが期待するカスタム出力項目。何でもかんでも入った汎用ダンプではないこと。
- きれいなMarkdownまたはテキスト。RAGの埋め込みパイプライン向けです。
- リアルタイムのツール呼び出しに十分な低レイテンシー。
各プロバイダーのAIエージェントスタック適性
| プロバイダー | AIエージェント適性 | 理由 |
|---|---|---|
| Thunderbit | 非常に優秀 | カスタムJSON Schema(Extract API)+RAG向けMarkdown(Distill API)。エージェント向け抽出に最も柔軟。 |
| Serper | 非常に良い | 高速でJSONがきれい。n8n/LangChainコミュニティで人気。基本的な検索ツール呼び出しに安価で使いやすい。 |
| SerpApi | 良い | スキーマが安定しており、ドキュメントも充実。Googleの縦型検索(Maps、Scholar、Shopping)が必要なエージェントと相性が良い。 |
| DataForSEO | 良い | より大きなSEOデータパイプラインの一部として使う場合に最適。 |
| Scrapingdog | 良い | 高速かつ低コスト。Google SERP向けのスキーマが安定している。 |
| Bright Data | 良い | エンジンや地域をまたいだエンタープライズ規模の新鮮なデータ収集に強い。 |
| ScraperAPI | 中程度 | エージェントが一般的なWebクロールも必要とする場合に向く。 |
| Apify | 中程度~良い | 柔軟だが遅め。スケジュール実行のバッチ処理に向いている。 |
Thunderbitを使う実例: たとえば、AIエージェントが「不動産向けに最適なCRM」を検索する意図を分析する必要があるとします。オーガニック結果(タイトル、URL、スニペット、順位)、People Also Askの質問と回答要約、そして商業意図の分類を求めるスキーマを定義します。ThunderbitのExtract APIは、その構造をそのまま返します。余計なものはなく、足りないものもありません。エージェントは無関係なフィールドの解析やHTMLのごみ取りにトークンを浪費しません。
RAGパイプラインでは、ThunderbitのDistill APIがSERPページをきれいなMarkdownに変換し、埋め込み用の素材をすぐに作れます。多くの専用SERP APIは固定JSONスキーマを返しますが、Thunderbitのアプローチなら、下流モデルが期待する形に合わせて出力を調整できます。
ユースケース別の判断マトリクス: Xが必要ならYを使う
フォーラムでは、抽象的な「場合による」ではなく、自分の実際のワークフローに沿った具体的なおすすめを求める声が絶えません。そこで、この表を作りました。
| あなたの用途 | 最適候補 | 次点 | 理由 |
|---|---|---|---|
| SEO順位計測(大規模) | DataForSEO | Scrapingdog | SEO向けエンドポイント、バルク価格、包括的解析 |
| Google Maps / ローカルビジネスデータ | SerpApi | Bright Data | 成熟したMapsエンドポイント。Bright Dataはエンタープライズ規模のローカルスクレイピングに適する |
| AIエージェント / n8n自動化 | Thunderbit | Serper | カスタムスキーマ+RAG向けMarkdown。Serperはシンプルな呼び出しに高速で安価 |
| 低予算MVP / 副業(月50米ドル未満) | Serper | Scrapingdog | 充実した無料枠、従量課金、最小限の導入工数 |
| マルチエンジン(Bing、Yandex、DuckDuckGo) | Thunderbit | DataForSEO | ThunderbitはAI抽出でどの検索エンジンでも動作。DataForSEOはマルチエンジンのエンドポイントあり |
| Googleレビュー集約 | SerpApi | DataForSEO | レビュー解析向けの専用エンドポイント |
| EC / ショッピング監視 | SerpApi | DataForSEO | Google Shoppingのカバー範囲と構造化フィールドが強い |
| カスタムスクレイピングワークフロー | Apify | ScraperAPI | Actorの柔軟性。ScraperAPIは一般的なスクレイピング+SERPに使いやすい |
簡単なペルソナ別ガイド:
- SEOチーム: ダッシュボード構築ならDataForSEOから開始。Googleの縦型検索カバーやドキュメントを価格より重視するならSerpApi。
- セールスチーム: SERP、ディレクトリページ、リッチ化をまたぐワークフローならThunderbit。シンプルなリード発掘クエリならSerper。
- AIツール開発者: カスタムスキーマ/RAGにはThunderbit。安くて速い検索ならSerper。堅牢なGoogle縦型データならSerpApi。
- 個人起業家: まずはSerper、Scrapingdog、SerpApi、Thunderbitの無料枠から始めてください。本番に近い20件のクエリを同じ条件で実行してみましょう。
レート制限、信頼性、本番対応性の比較
本番ワークフロー向けにプロバイダーを評価し始めた当初、この章があればよかったと思います。1日数千件のクエリにスケールするチームには、予測可能なレート制限、自動リトライ、稼働保証が必要です。そして、それを体系的に比較している記事は他にありませんでした。
| プロバイダー | レート制限 | 同時リクエスト数 | 失敗時リトライ | SLA / 稼働率 |
|---|---|---|---|---|
| Thunderbit Free | 10 req/min | 2 | 組み込み(ボット対策、CAPTCHA) | — |
| Thunderbit Pro | 100 req/min | 10 | 組み込み | — |
| Thunderbit Enterprise | 1,000 req/min | 50 | 組み込み | 個別契約 |
| SerpApi | プランベース(検索数/時) | プランベース | プロバイダー側でプロキシ/CAPTCHA処理 | 99.95% SLA |
| Serper | アカウント/プランベース | 公開情報は少ない | クライアント側での手動リトライ推奨 | 公開SLAなし |
| Scrapingdog | プランベース | プラン条件を確認 | ブロック回避は処理済み | 常時公開ではない |
| DataForSEO | エンドポイント/モードごとに公開 | モードによって異なる | 非同期でポーリング/リトライ可 | エンタープライズサポート |
| Bright Data | 公開済み、段階的に増やす | エンタープライズ規模 | 組み込みのブロック回避 | エンタープライズSLA |
| ScraperAPI | プランベースの同時実行 | クレジット依存 | リトライ/プロキシ処理あり | 有料サポートあり |
| Apify | actor/メモリ/計算資源依存 | プラットフォーム制限あり | actorレベルの設定 | プラットフォームの信頼性 |
契約前の本番チェックリスト:
- 失敗またはブロックされたリクエストに課金されるか確認する。
- 正確な同時実行数、1分あたりのリクエスト数、バースト挙動を確認する。
- 地域ターゲティング、モバイル/デスクトップ、JSレンダリングでクレジット消費が変わるか確認する。
- 実際の20~50クエリのサンプルJSONを保存し、日ごとにフィールド名を比較してスキーマの安定性を確認する。
- SERPデータが業務の要なら、クライアント側のリトライとタイムアウト予算を追加する。
一覧でわかる要約: 8つのSERP APIを比較
| プロバイダー | 平均速度 | 1Kあたりのコスト | 無料枠 | 解析範囲 | AI適性 | マルチエンジン | 総評 |
|---|---|---|---|---|---|---|---|
| Thunderbit | 中程度(AI抽出) | 低価格(Distill)~プレミアム(Extract) | あり | カスタム(あらゆる機能) | 非常に優秀 | 非常に優秀 | AIネイティブなカスタムSERP抽出とRAGに最適 |
| SerpApi | 約5.5秒 | プレミアム | 月250件 | 非常に優秀(固定) | 良い | Googleの縦型検索を広くカバー | 成熟したGoogle対応が最強 |
| Serper | 約2~3秒 | 非常に低い | 2,500クエリ | 良い | 非常に良い | 主にGoogle | AI/MVP向けの最安・高速API |
| Scrapingdog | 約1.25秒 | 大規模では非常に低い | 1,000クレジット | 良い | 良い | 対応エンジンは要確認 | 速度とコストのバランスが最良 |
| DataForSEO | 中~遅い(Standard) | 低~中程度 | 試用クレジット | 非常に優秀 | 良い | 非常に優秀 | SEOプラットフォーム基盤として最適 |
| Bright Data | 約2~5.5秒 | エンタープライズ | 試用(5米ドル) | 良い(製品依存) | 良い | 非常に優秀 | エンタープライズ規模の収集に最適 |
| ScraperAPI | 約33秒 | クレジット依存 | 5,000試用 | 中程度 | 中程度 | Googleエンドポイント | SERPが広範なスクレイピングの一部なら最適 |
| Apify | 約8秒 | actor依存 | 月間クレジット | actor依存 | 中程度~良い | actor依存 | カスタム自動化ワークフローに最適 |
ThunderbitがSERPワークフローにどうフィットするか
ThunderbitのAPIをこのような設計にした理由を、少し補足します。従来のSERP APIモデルは、固定エンドポイント、あらかじめ決められた出力フィールド、Google専用という作りで、素直な順位計測には十分機能します。しかし、少しでも違うもの、たとえば感情分析付きのPAA回答、レビュー数付きのローカルパック結果、特定のDBスキーマに合わせたショッピングデータが必要になると、後処理するかプロバイダーを乗り換えるしかなくなります。
ThunderbitのExtract APIは、そのモデルを逆転させます。JSON Schemaで欲しいものを伝えると、AIが対象ページからどう取得するかを判断します。今日はGoogle、明日はBing、来週はニッチな縦型検索エンジンでも、APIも考え方も同じです。
Distill APIは別の問題を解決します。ごちゃついたSERPページを、HTMLのごみ、ナビゲーション要素、トラッキングスクリプトに邪魔されず、LLMがそのまま扱えるきれいなMarkdownに変換します。新鮮な検索証拠を必要とするRAGパイプラインを作るなら、「ライブSERP」から「埋め込み可能なコンテンツ」へ最短で到達できます。
どちらのエンドポイントにも、ボット対策、CAPTCHA解決、JSレンダリングが標準搭載されています。これらに追加料金はかかりません。クレジット費用に含まれています。
実際に試してみるには、ブラウザベースの抽出ならを使うか、プログラムからAPIを直接呼び出してください。コードを書く前に動きを見たいなら、に使い方の動画があります。
法的側面について
これは毎回FAQで出る話題なので、短くまとめます。SERPスクレイピングの適法性は、事実関係と管轄に左右されます。では、公開アクセス可能なデータのスクレイピングが必ずしもコンピュータ犯罪に当たるわけではないとされましたが、全面的な許可が与えられたわけではありません。GoogleはSERPスクレイピングをめぐってしており、アクセスをめぐる商業的圧力が実際に存在することを示しています。
実務上のアドバイスとしては、ベンダーAPIは利用規約に従って使い、必要がない限り個人データの収集は避け、各プロバイダーがコンプライアンスをどう扱っているかを確認してください。SERPスクレイピングが無リスクだと思い込まないことです。
結論
すべての観点で勝つ単一のプロバイダーはありません。最適解は、用途、予算、技術スタックによって変わります。料金の正規化、速度テスト、解析範囲の確認、AIエージェント適性の評価を踏まえ、私の判断フレームワークは次の通りです。
- 柔軟性とAIエージェント適性が必要? → Thunderbit
- Google製品を広くカバーしたい? → SerpApi
- 速度と最低コストを重視? → Serper または Scrapingdog
- SEOプラットフォームを構築する? → DataForSEO
- SLA付きのエンタープライズ規模が必要? → Bright Data または DataForSEO
- 一般的なスクレイピングにたまにSERPも必要? → ScraperAPI または Apify
まずは無料枠から始めてください。本番に近い20~50件のクエリを実行し、JSONレスポンスを比較し、クレジットや倍率を含めた実コストを確認してから契約しましょう。
この市場では価格が頻繁に変わります。この比較は2026年5月時点の公開ページを基に正規化しました。数か月後に読むなら、購入前に再確認してください。
のアプローチや、従来手法との違いについては、私たちが詳しく解説しています。また、を検討しているなら、ThunderbitのChrome拡張機能がその部分もカバーします。
FAQ
1. SERP APIとは何ですか?誰が必要としますか?
SERP APIは、Google、Bing、Yandexのような検索エンジンに検索クエリを送信し、結果を構造化データ(通常はJSON)として返すサービスです。SEO担当者は順位計測に、営業チームはリード発掘に、ECチームは価格監視に、AI開発者はライブ検索データをエージェントやRAGパイプラインに流し込むために使います。
2. API経由でGoogle検索結果1,000件を取得するのにいくらかかりますか?
幅はかなり広く、約0.60米ドル/1K(DataForSEOのStandardティア)から、約25米ドル/1K(SerpApi Starterプラン)まであります。大量利用の割引もプロバイダーごとに大きく異なります。表示価格ではなく、成功したクエリ1,000件あたりのコストで必ず比較してください。
3. SERP APIはLangChainやn8nのようなAIエージェントと一緒に使えますか?
はい。Serperは、シンプルな検索呼び出し用途でn8nコミュニティに人気があります。Thunderbitは、カスタムJSON SchemaやRAG向けMarkdownが必要な場合に最も強いです。SerpApiは、安定したGoogleの縦型データ(Maps、Scholar、Shopping)が必要なエージェントと相性が良いです。
4. テスト用の無料枠が最も良いSERP APIはどれですか?
純粋な件数ベースでは、Serperが登録時2,500件で最も太っ腹です。SerpApiは月250件、Scrapingdogは1,000クレジット、ScraperAPIは7日間で5,000試用クレジット、Thunderbitはプロトタイピング用の無料クレジットを含みます。Apifyには月約5米ドル相当のプラットフォームクレジットがあります。
5. 購入前に、どのSERP機能の解析対応を確認すべきですか?
「構造化JSON」だからといって完全対応とは限りません。次の項目が構造化フィールドとして返るかを確認してください。People Also Ask、ナレッジパネル、ローカルパック/Maps、ショッピング結果、強調スニペット、広告(上部と下部)、画像パック、動画結果です。この記事の解析マトリクスを出発点にして、本契約の前に実際のクエリでテストしてください。
さらに詳しく知る