ウェブは、荒々しく、しかも常に姿を変える世界になりました。もはや「デジタル図書館」というより、「データのジャングル」と言ったほうがしっくりきます。2025年に現代的なサイトからデータをスクレイピングしようとすると、単なるJavaScriptの壁ではなく、要塞に挑むようなものです。動的コンテンツ、無限スクロール、ボット対策の防御に、従来のスクレイピングツールが次々と押しつぶされるのを私は何度も見てきました。だからこそ、python headless browser の台頭は単なる流行ではありません。信頼性が高く、拡張性のあるウェブデータ抽出を必要とするすべての人にとっての、本格的な革命なのです。
注目しているのは技術者だけではありません。2025年までに、しており、さらにしています。営業でも、eコマースでも、オペレーションでも、適切な python headless browser を使えるかどうかで、「手元ですぐ使えるデータ」になるか「届かないデータ」のままかが決まります。そこで今回は、余計な話をそぎ落として、私が実際にテストし、比較し、使い込んできたツールの中から、現代のスクレイピングに最適な10の python headless browser を紹介します。特に、AI がノーコード利用者の状況をどう変えているのかにも注目していきます。
現代のスクレイピングに Python Headless Browser が不可欠な理由
まずは用語を整理しましょう。python headless browser とは、Pythonコードで操作するウェブブラウザですが、画面に別ウィンドウを表示しないタイプのものです。ページを読み込み、JavaScript を実行し、ボタンをクリックし、フォームに入力する――そうした処理を、裏側で見えないまま行います。コーヒーを飲んでいる間に黙々と働く、幽霊のようなブラウザだと考えるとわかりやすいでしょう。
なぜ重要なのでしょうか。現代のウェブサイトは、ボットではなくユーザー向けに作られているからです。JavaScript の奥にデータを隠し、ログインを要求し、実際の人間のような操作を前提にしています。HTML を取得するだけの従来型スクレイパーは、空っぽの殻を見つめることになります。一方、ヘッドレスブラウザは実際のユーザー行動をシミュレートします。AJAX の応答を待ち、無限フィードをスクロールし、Chrome や Firefox で見えるのとまったく同じ状態のコンテンツを取得します()。
ただし、それだけではありません。
- 速度と効率: ヘッドレスブラウザは視覚レンダリングを省くため、より高速でメモリ消費も少なく、規模の大きなスクレイピングに最適です()。
- 動的コンテンツ対応: JavaScript を実行できるため、生の HTML ではなく、実際にレンダリングされたデータを取得できます。
- 自動化の強み: ログイン、ページ送り、ポップアップ対応が必要ですか? Python headless browser なら、そうした作業をすべて自動化できます。
- 拡張性: クラウド上で何百ものインスタンスを動かし、何千ものページを並列でスクレイピングしても、負荷をほとんど感じません。
ビジネスユーザーにとっては、サイトが要塞のように作られていても、リード収集、競合モニタリング、価格追跡ができるということです。そして最新のAI搭載ツールなら、コードが書けなくてもこの世界に参加できます。
最適な Python Headless Browser の選び方
私はブラウザ名のリストに適当にダーツを投げて選んだわけではありません。重視したのは次の点です。
- 性能と速度: JavaScript が多い最新サイトを、素早く安定して処理できるか
- ブラウザ対応: Chrome、Firefox、WebKit、さらには IE のような旧式エンジンにも対応しているか
- 使いやすさ: ノーコード利用者にも扱いやすいか、それとも Python の博士号が必要なくらい難しいか
- AI とノーコード機能: ビジネスユーザーがスクリプトを書かずに AI でスクレイピングを自動化できるか
- コミュニティとサポート: 活発なコミュニティ、充実したドキュメント、継続的な開発があるか
- 独自機能: 即席テンプレート、クラウドスクレイピング、サブページ移動などの特別な機能があるか
私は、セットアップに何週間も費やしたのに、サイトのレイアウト変更で行き詰まるチームを何度も見てきました。本当に優れたツールは、動くだけではありません。変化に適応し、拡張でき、使う人の負担を減らしてくれます。
現代のスクレイピングに最適な Python Headless Browser ベスト10
ここでは、各ツールの強みとつまずきやすい点を掘り下げながら、私の決定版リストを紹介します。
1. Thunderbit
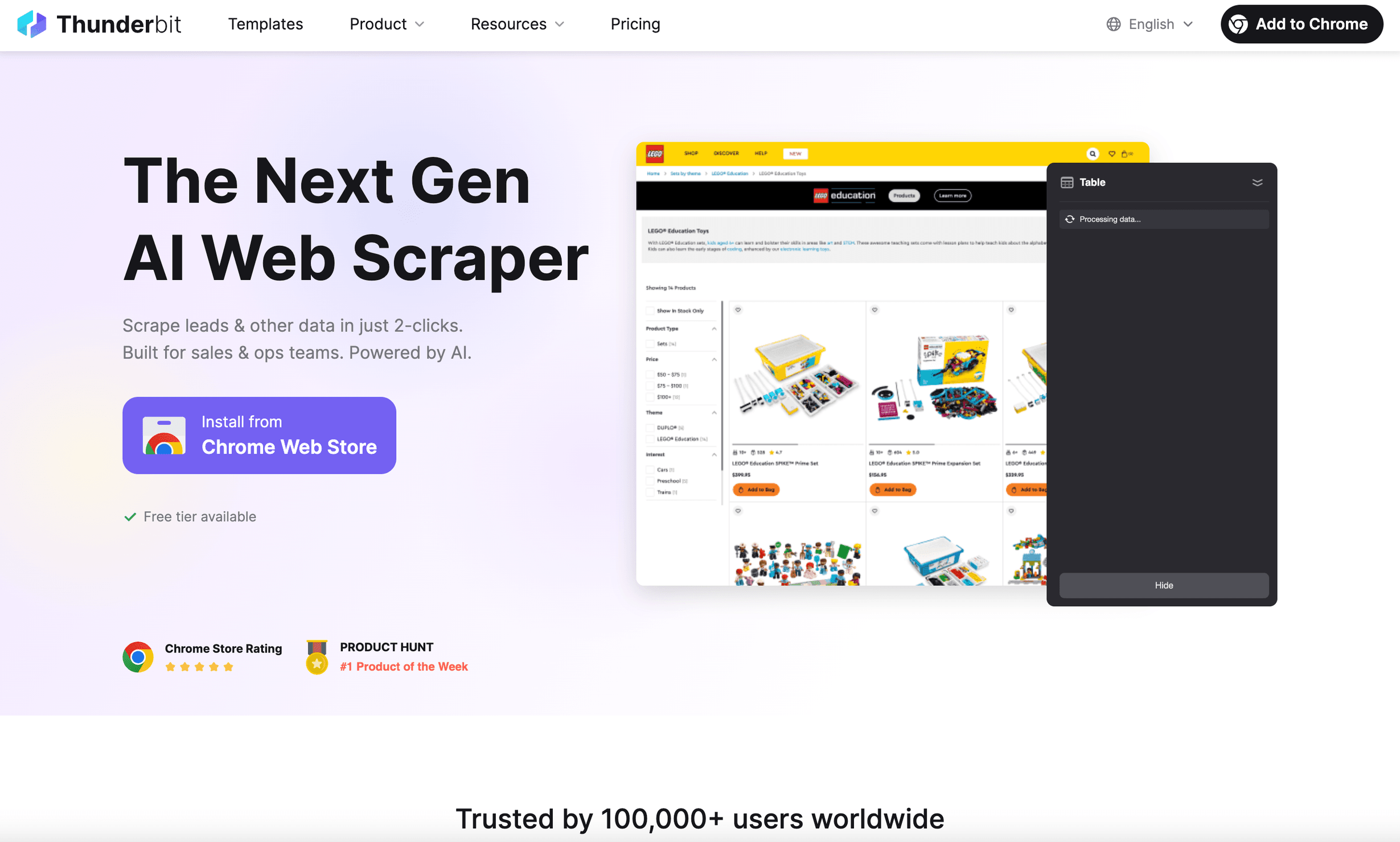 は、何年も前に欲しかったと思う python headless browser です。単なるブラウザ自動化ツールではなく、結果を求めるビジネスユーザーのために作られたAI搭載ウェブスクレイパー Chrome拡張機能です。頭を悩ませる必要はありません。
は、何年も前に欲しかったと思う python headless browser です。単なるブラウザ自動化ツールではなく、結果を求めるビジネスユーザーのために作られたAI搭載ウェブスクレイパー Chrome拡張機能です。頭を悩ませる必要はありません。
Thunderbit が際立つ理由:
- AI で項目を提案: 「AI で項目を提案」をクリックするだけで、Thunderbit の AI がページを読み取り、抽出すべきデータを提案し、スクレイパーを自動で設定してくれます()。
- 即席データテンプレート: Amazon、Zillow、LinkedIn などの人気サイトには、ワンクリックテンプレートが用意されており、セットアップは不要です。
- サブページ・ページ送りスクレイピング: Thunderbit はサブページをクリックで巡回し、無限スクロールを処理し、すべてのデータを1つの表にまとめられます。
- 自然言語プロンプト: ほしい内容を普通の英語で伝えるだけで、あとは Thunderbit の AI が処理します。
- クラウドでもブラウザでもスクレイピング可能: ローカルでもクラウドでも実行でき、速度重視なら一度に最大50ページまで処理できます。
- コーディング不要: 本当に、ブラウザが使えるなら Thunderbit は使えます。
- 無料データエクスポート: Excel、Google Sheets、Notion、Airtable へワンクリックで出力できます。
私は、Thunderbit が営業チームやオペレーションチームの作業時間を何時間も節約するのを見てきました。リードの抽出、価格監視、商品データの集約を、コードに触れずに実現できます。世界中でに信頼されており、よく聞く感想は一貫して「こんなに簡単だとは信じられない」です。
おすすめの人: 非技術系ユーザー、ビジネスチーム、AI に面倒な作業を任せたい人
2. Selenium
 は、ブラウザ自動化の草分け的存在です。もし「python headless browser」で検索したことがあるなら、Selenium WebDriver に出会ったことがあるはずです。
は、ブラウザ自動化の草分け的存在です。もし「python headless browser」で検索したことがあるなら、Selenium WebDriver に出会ったことがあるはずです。
長所:
- 主要ブラウザをすべてサポート: Chrome、Firefox、Safari、Edge、さらには Internet Explorer まで対応します(勇気があるなら)。
- 巨大なコミュニティ: チュートリアル、プラグイン、Stack Overflow の回答が豊富です。
- 柔軟性が高い: クリック、フォーム入力、移動など、ユーザーができることは何でも自動化できます。
短所:
- セットアップが大変: ブラウザドライバの管理やバージョン整合に手間がかかります。
- 最新ツールより遅い: WebDriver プロトコルのオーバーヘッドがあり、何百ものブラウザにスケールさせるのもやや扱いにくいです。
- API が冗長: Playwright や Puppeteer より多くのコードを書くことになります。
おすすめの人: 既に Selenium の知見があるチーム、クロスブラウザテスト、レガシー自動化ワークフロー
3. Puppeteer
 は、Chrome/Chromium 向けの Google 製ハイレベル自動化ライブラリです。ネイティブは Node.js ですが、Python ユーザーも Pyppeteer を通じて利用できます。
は、Chrome/Chromium 向けの Google 製ハイレベル自動化ライブラリです。ネイティブは Node.js ですが、Python ユーザーも Pyppeteer を通じて利用できます。
長所:
- Chrome 向けに最適化: 高速で効率的、Chrome DevTools とも密接に統合されています。
- 非同期 API: JavaScript が多い現代的なサイトに向いています。
- 豊富な機能: スクリーンショット、PDF 出力、ネットワークインターセプトなどに対応。
短所:
- Chromium 専用: Firefox や Safari には対応していません。
- Node.js ネイティブ: Python ユーザーは Pyppeteer を使う必要があります(ただし後述のとおり、現在は保守されていません)。
おすすめの人: 高速で信頼性の高い Chrome 自動化を求め、クロスブラウザ対応が不要な開発者
4. Playwright
 は Microsoft が開発した新進気鋭のツールで、急速に私の高度なスクレイピングの定番になりました。
は Microsoft が開発した新進気鋭のツールで、急速に私の高度なスクレイピングの定番になりました。
長所:
- マルチブラウザ対応: Chromium、Firefox、WebKit を1つのAPIで自動化できます。
- 自動待機: ページの準備ができたタイミングを推測する必要はもうありません。Playwright が待ってくれます。
- 並列実行: 複数のブラウザコンテキストを同時に動かし、驚くほど高速に処理できます。
- Python ファースト: Python 向けの公式バインディングがあり、async 版と sync 版の両方があります。
短所:
- インストールが大きめ: 複数ブラウザを同梱するため、セットアップはやや重くなります。
- それでもコーディングは必要: Thunderbit ほど非技術系ユーザーには親切ではありません。
おすすめの人: 複雑で動的なウェブアプリ向けに、堅牢で最新の自動化を必要とする開発者
5. Headless Chrome
 は、上で紹介した多くのツールを支えるエンジンです。最大限の柔軟性を求めるなら、Chrome DevTools Protocol(CDP)を通じて直接操作できます。
は、上で紹介した多くのツールを支えるエンジンです。最大限の柔軟性を求めるなら、Chrome DevTools Protocol(CDP)を通じて直接操作できます。
長所:
- 最先端のWeb対応: Chrome で動くものは、headless Chrome でも動きます。
- きめ細かな制御: ブラウザの細部までアクセスできます。
短所:
- 学習曲線が急: CDP を理解するか、ラッパーライブラリを使う必要があります。
- Chrome 専用: クロスブラウザ対応はありません。
おすすめの人: カスタム自動化パイプラインを構築する上級者、あるいは Chrome を低レベルで統合したい人
6. Pyppeteer
 は、Puppeteer の非公式 Python 版です。Python に非同期の Chrome 自動化をもたらしましたが……注意点があります。
は、Puppeteer の非公式 Python 版です。Python に非同期の Chrome 自動化をもたらしましたが……注意点があります。
長所:
- Puppeteer 風の API: Puppeteer を知っていればすぐ馴染めます。
- 高速な Chrome 自動化: 動的サイトに向いています。
短所:
- 保守されていない: 元プロジェクトは更新が止まっており、開発者も Playwright への移行を推奨しています。
- Chromium 専用: Firefox や Safari は使えません。
おすすめの人: すでに Pyppeteer を使っている既存プロジェクト。新規なら Playwright を使いましょう。
7. Splash
 は、Scrapinghub(現在の Zyte)チームが開発した、HTTP API 付きの軽量でスクリプト可能なヘッドレスブラウザです。
は、Scrapinghub(現在の Zyte)チームが開発した、HTTP API 付きの軽量でスクリプト可能なヘッドレスブラウザです。
長所:
- 軽量: QtWebKit ベースなので、Chrome よりリソース消費が少なめです。
- HTTP API: Python だけでなく、どんな言語からでも操作できます。
- Scrapy と相性が良い: JS レンダリングを Scrapy の spider とシームレスに統合できます。
短所:
- 古い WebKit エンジン: 最新の JavaScript には弱い場合があります。
- Lua スクリプトが必要: 高度な操作には Lua を学ぶ必要があります。
おすすめの人: たまに JS レンダリングが必要な Scrapy ユーザー、または軽量なサーバーサイドレンダリング作業
8. PhantomJS
 は、WebKit ベースの元祖スクリプト可能ヘッドレスブラウザです。先駆者ではありましたが、今ではかなり時代遅れです。
は、WebKit ベースの元祖スクリプト可能ヘッドレスブラウザです。先駆者ではありましたが、今ではかなり時代遅れです。
長所:
- シンプルなスクリプト: JavaScript で簡単に自動化できます。
- レガシー対応: 古くて静的なサイトなら今でも動くことがあります。
短所:
- 保守されていない: 2016年以降更新がありません。
- 古いエンジン: 現代的な JavaScript が多いサイトには対応しきれません。
- セキュリティリスク: 最近のパッチがありません。
おすすめの人: レガシースクリプトの維持。新規プロジェクトでは Playwright か Puppeteer に移行しましょう。
9. HtmlUnit
 は、ブラウザの挙動をシミュレートする Java ベースのヘッドレスブラウザです。高速で軽量ですが、真のブラウザエンジンではありません。
は、ブラウザの挙動をシミュレートする Java ベースのヘッドレスブラウザです。高速で軽量ですが、真のブラウザエンジンではありません。
長所:
- 純粋な Java: Java 中心の環境と相性が良いです。
- 静的ページに高速: フルブラウザを起動する必要がありません。
短所:
- JavaScript 対応が限定的: 現代的で動的なサイトは苦手です。
- Python ネイティブではない: 連携層が必要です(例: Selenium の HtmlUnitDriver)。
おすすめの人: Java ベースのワークフロー、レガシーアプリのテスト、シンプルなサーバーレンダリングページのスクレイピング
10. TrifleJS
 は、Windows 上のレガシー Web アプリを自動化するための、Internet Explorer(IE)向けヘッドレスブラウザです。
は、Windows 上のレガシー Web アプリを自動化するための、Internet Explorer(IE)向けヘッドレスブラウザです。
長所:
- IE 自動化: 古い社内システムや IE でしか動かないシステムを扱えます。
- PhantomJS 風 API: PhantomJS スクリプトからの変更を最小限に抑えられます。
短所:
- Windows 専用: クロスプラットフォーム対応はありません。
- 時代遅れ: IE はサポート終了済みで、TrifleJS はニッチかつ保守頻度も低いです。
おすすめの人: IE 自動化が今も必要な特殊なレガシーワークフロー
機能比較表: Python Headless Browser をひと目で比較
| ツール | ブラウザ対応 | 性能と規模 | 使いやすさ | AI/ノーコード機能 | コミュニティとサポート | おすすめ用途 |
|---|---|---|---|---|---|---|
| Thunderbit | Chrome(拡張機能/クラウド) | 高い(クラウド並列処理) | 最も簡単—コード不要 | はい(AI、テンプレート) | 成長中、活発 | ノーコード利用者、営業/オペレーション、迅速なデータ抽出 |
| Selenium | 主要ブラウザすべて | 中程度 | 中程度(セットアップ) | いいえ | 非常に大規模、成熟 | クロスブラウザ、レガシー、テスト自動化 |
| Puppeteer | Chromium/Chrome | 非常に高い | 高い(開発者向け) | いいえ | 大規模(Node.js) | Chrome 専用、開発者向け、高速自動化 |
| Playwright | Chromium、Firefox、WebKit | 非常に高い(マルチコンテキスト) | 高い(開発者向け) | いいえ | 急成長中 | 高度、マルチブラウザ、最新のスクレイピング |
| Headless Chrome | Chrome/Edge | 非常に高い | 低い(手動CDP) | いいえ | 該当なし(基盤) | カスタム、上級者、低レベル制御 |
| Pyppeteer | Chromium/Chrome | 高い | 中程度(非同期) | いいえ | 小規模、保守停止 | 既存の Pyppeteer スクリプト |
| Splash | QtWebKit | 中程度 | 中程度(API/Lua) | いいえ | ニッチ(Scrapy/Zyte) | Scrapy ユーザー、軽量な JS レンダリング |
| PhantomJS | WebKit(旧) | 低い(現在は時代遅れ) | 中程度(JS) | いいえ | 実質終了 | レガシー用途のみ |
| HtmlUnit | シミュレート(Java) | 中程度/高い(静的) | 低い(Java) | いいえ | 小規模、Java 中心 | Java ワークフロー、シンプル/静的ページ |
| TrifleJS | Internet Explorer(Trident) | 低い/中程度 | 中程度(JS、Win) | いいえ | ごく小規模、レガシー | IE 専用のレガシー自動化 |
ビジネスに最適な Python Headless Browser の選び方
ツール選びのための、私なりの早見表はこちらです。
- AI の助けを借りて、速くノーコードでスクレイピングしたい? を選びましょう。特に営業、eコマース、リサーチチームにとって、信頼できるデータを最も簡単に取得できます。
- 最大限の制御とクロスブラウザ対応が欲しい? が最有力です。堅牢で、最新で、スケールを前提に設計されています。
- すでに Selenium に投資している? を使い続けましょう。レガシー用途やマルチブラウザのワークフローでは、今でも王者です。
- 開発者として Chrome 専用の自動化を作りたい? (または Playwright)が高速で強力です。
- Java 環境で、シンプルな静的ページをスクレイピングしたい? は軽量で、統合も簡単です。
- レガシースクリプトや IE 専用アプリを保守している? と は、最後の手段として頼れる存在です。
そして覚えておいてください。最適なツールとは、あなたのワークフロー、チームのスキル、そしてビジネス要件に合うものです。場合によっては、Thunderbit で手早い作業をこなし、Playwright で重い処理を行い、Selenium でレガシーシステムを扱う、という使い分けがベストです。
FAQ
1. python headless browser とは何ですか?スクレイピングに本当に必要ですか?
python headless browser は、Pythonコードで操作するウェブブラウザですが、画面には表示されません(GUI なし)。現代的で JavaScript の多いサイトをスクレイピングするには不可欠です。スクリプトを実行し、ユーザー操作を処理し、完全にレンダリングされたコンテンツを抽出できるため、従来の HTML スクレイパーではできないことができます。
2. 非技術系ユーザーに最適な python headless browser はどれですか?
が、ノーコード利用者にとって最有力です。AI がセットアップを自動化し、即席テンプレートを用意し、ほんの数クリックでデータをスクレイピングできます。プログラミングは不要です。
3. Python ユーザーにとって Playwright と Puppeteer の違いは何ですか?
Playwright は複数のブラウザ(Chromium、Firefox、WebKit)をサポートし、堅牢な Python バインディングを備えているため、高度な自動化に最適です。Puppeteer は Chrome 専用で Node.js ネイティブですが、Python ユーザーは Pyppeteer を使えます(ただし現在は保守されていません)。新規の Python プロジェクトなら、Playwright のほうが良い選択です。
4. Selenium は現代のウェブスクレイピングでもまだ重要ですか?
はい。Selenium は今でも広く使われており、特にクロスブラウザテストやレガシー自動化では現役です。ただし、Playwright や Thunderbit のような新しいツールより遅く、セットアップも複雑で、大規模スクレイピングにはあまり効率的ではありません。
5. PhantomJS、HtmlUnit、TrifleJS のようなレガシーツールはいつ使うべきですか?
古いワークフローの維持や移行時に限って使いましょう。PhantomJS と TrifleJS は時代遅れで、HtmlUnit はシンプルなページを扱う Java 環境に向いています。新規プロジェクトでは、今も活発に保守されている最新ツールを使うべきです。
現代的でAI搭載のスクレイピングがどんなものか見てみたいなら、。ウェブ自動化についてさらに深く知りたい方は、 もぜひご覧ください。楽しくスクレイピングしましょう。データがいつも新鮮で、ブラウザがずっとヘッドレスのままでありますように。
さらに詳しく