インターネット上にはとんでもない量の情報が転がっていますが、それをビジネスで使えるデータに変えるのは、今の時代ならではの大きな課題であり、同時に大きなチャンスでもあります。僕自身、SaaSや自動化ツールの開発に関わる中で、直感頼みの意思決定からデータドリブンな経営へと、世の中がどんどんシフトしていくのを肌で感じてきました。今や大企業だけじゃなく、小さなチームでも営業やマーケ、価格戦略、商品開発のためにウェブからデータを引っ張ってくるのは当たり前。でも、ウェブがどんどん複雑&動的になってきて、クリーンでルールを守った有用なデータを効率よく集めるのは、なかなか一筋縄ではいきません。
この記事では、なぜ今ウェブサイトからのデータ抽出がビジネスに欠かせないのか、よくある悩みどころ、そしてThunderbitチームで実際に培ったベストプラクティス(法令順守・効率化・大規模運用のコツ)を、現場目線で紹介します。非構造化データの整理やGDPR対応、手作業コピペから卒業したい人にも役立つ内容です。
なぜウェブサイトからのデータ抽出が現代ビジネスに重要なのか
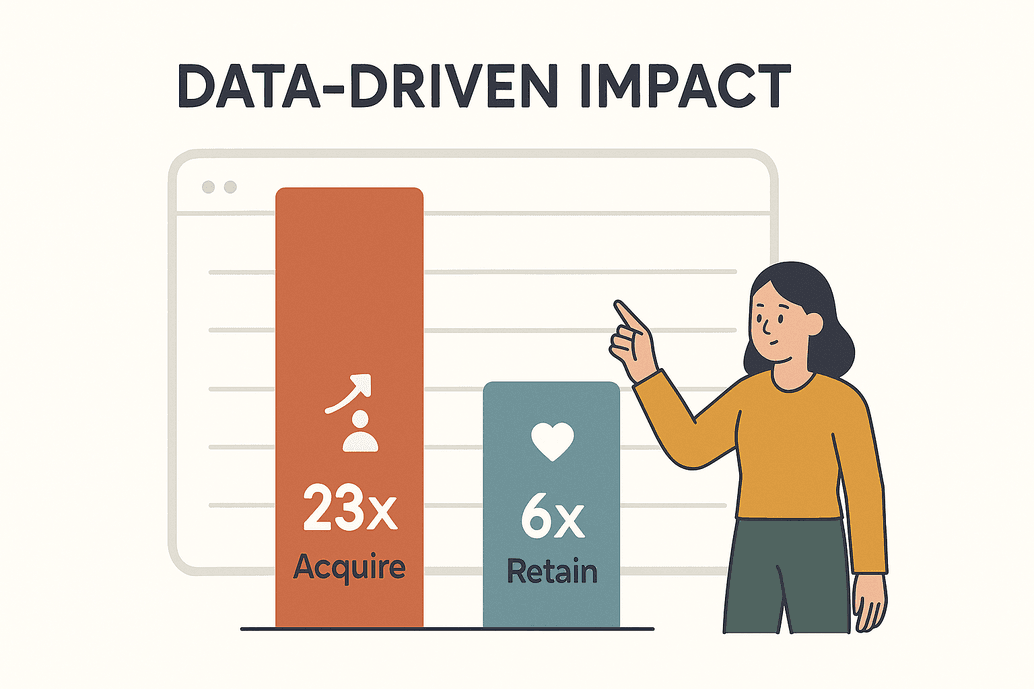 データはもはや流行り言葉じゃなく、ガチで競争力の源です。によると、データドリブンな企業は新規顧客獲得が23倍、既存顧客維持が6倍も高い確率で実現できるそう。2025年には、企業が毎日何十億ページものウェブデータを分析やAIモデル、リアルタイム意思決定のために取得する時代がやってきます()。
データはもはや流行り言葉じゃなく、ガチで競争力の源です。によると、データドリブンな企業は新規顧客獲得が23倍、既存顧客維持が6倍も高い確率で実現できるそう。2025年には、企業が毎日何十億ページものウェブデータを分析やAIモデル、リアルタイム意思決定のために取得する時代がやってきます()。
実際の現場では、例えばこんな使い方が日常茶飯事です:
| ビジネス用途 | 概要・メリット | 事例・統計 |
|---|---|---|
| 価格モニタリング | 競合の価格や在庫、プロモーションをリアルタイムで把握し、自社戦略を即時調整。 | 大手ECの80%以上が毎日競合価格をスクレイピング(kanhasoft.com)。 |
| リード獲得 | ディレクトリやSNS、レビューサイトから新規リードや連絡先を自動収集。 | 自動抽出によりCRMへの登録が手作業より圧倒的に高速化。 |
| 市場トレンド分析 | レビューやフォーラム、ニュースを集約し、トレンドや消費者の声を早期に把握。 | スクレイピングの26%がSNSからのトレンド分析目的(blog.apify.com)。 |
| コンテンツ集約 | 複数サイトからニュースや商品リスト、イベント情報をまとめて取得。 | メディアチームがオーディエンス向けに情報をキュレーション。 |
| 商品・リサーチデータ | 商品情報やレビュー、調査データを収集し分析や開発に活用。 | 投資アドバイザーの67%がウェブ由来の代替データを利用(scrap.io)。 |
| AI学習データ | AIモデルの訓練用に大量のテキストや画像、記録データを収集。 | 大規模AIモデルの約70%がウェブデータを活用(kanhasoft.com)。 |
ウェブデータを活用しない会社は、競争の土俵からどんどん置いていかれます。実際、競合価格の自動取得を導入したECチームが半年でROIを3倍に伸ばした事例も()。つまり、ウェブデータは戦略的な武器であり、うまく抽出できるかどうかが今や必須条件です。
ウェブサイトからデータ抽出する際の主な課題
もちろん、現実はそんなに甘くありません。ウェブはカオスで、データ抽出にはいろんな壁が立ちはだかります:
- 非構造化データの多さ: オンラインデータの約80%は非構造化で、HTMLの奥底や複数ページ、動的要素の中に埋もれています。これをきれいなテーブルにするのは本当に大変()。
- ウェブサイトの変化: サイトのレイアウトはしょっちゅう変わります。ターゲットサイトのデザインがちょっと変わっただけで、スクレイパーが月に15回も動かなくなったことも()。
- 大量・大規模対応: 数百・数千ページのデータを定期的に集める必要があり、手作業じゃ全然追いつきません。
- アンチスクレイピング対策: CAPTCHAやアクセス制限、ログイン壁など、サイト側もボット対策をどんどん強化。今やウェブトラフィックの3分の1以上がボットで、対策も進化中()。
- 手作業のミス: コピペ作業は遅いし、ミスも多発。セレクターを一つ間違えるだけで、全然違うデータを取ってきちゃうことも。
従来のやり方では限界があり、多くのチームがもっと賢く自動化されたソリューション(特にAI搭載ツール)に乗り換えています。
法令遵守・セキュリティ観点でのウェブデータ抽出のベストプラクティス
まず大前提として、「できる」からといって「やっていい」とは限りません。法律や倫理を無視してはいけません。ビジネスで押さえておくべきポイントは以下の通り:
- 公開データと非公開データの区別: 公開情報の取得は多くの国でOKですが、ログインが必要な情報は基本NG。認証を回避する行為はやめましょう()。
- 利用規約の確認: サイトの利用規約は必ずチェック。スクレイピング禁止の場合は訴訟やブロックのリスクも。迷ったら許可を取るか、公式APIを使いましょう。
- プライバシー法(GDPR・CCPA等): 個人情報を扱う場合は、正当な理由が必要で、収集範囲を最小限にし、削除依頼にも対応できる体制が必要。違反時の罰則も厳しいです()。
- robots.txtの尊重: 法的拘束力はないけど、マナーとしてクロールルールやリクエスト間隔は守りましょう。
- データセキュリティ: 取得したデータは機密情報として扱い、安全に保管・管理・クリーンアップを徹底しましょう。
コンプライアンス・チェックリスト:
| 観点 | ベストプラクティス |
|---|---|
| 法的アクセス | 公開データのみ取得し、ログイン回避は絶対にしない(xbyte.io)。 |
| 利用規約 | サイトのToSを確認・遵守し、禁止の場合はAPI利用を検討。 |
| 個人データ | 可能な限り回避し、必要な場合は最小限・GDPR/CCPA遵守。 |
| robots.txt & クロール間隔 | サイトルールを守り、リクエストを制御。 |
| データセキュリティ | 暗号化・アクセス制限・不要時の削除を徹底。 |
効率化の鍵:AIが変えるウェブデータ抽出
ここからが本題。AIの登場で、ウェブデータ抽出は劇的に進化しました。複雑なセレクターや壊れやすいスクリプトに悩まされることなく、AI搭載ツールがページを「理解」し、必要な情報を数クリックで抽出できるようになっています。
実際どんなメリットがあるのか?
- 初期設定が超ラク: みたいなAI 웹 스크래퍼なら、「AIフィールド提案」をクリックするだけで、最適なカラムを自動検出。コーディングや試行錯誤は一切不要。
- 変化への強さ: AIはレイアウトのパターンを認識するので、サイトが変わっても自動で適応することが多く、保守の手間が激減。
- 高精度: ノイズ除去や重複排除、データのクリーンアップもAIが自動でやってくれる。AI抽出ツールで99.5%の精度を達成した事例も()。
- 動的コンテンツ対応: JavaScriptで生成されるページや無限スクロール、画像・PDFからのテキスト抽出もAIなら余裕。
- リアルタイム処理: 抽出しながら翻訳・分類・要約なども一括で実行可能。
 AIツールに切り替えるだけで30〜40%の作業時間短縮を実現したチームも()。これは単なる効率化じゃなく、競争力の源です。
AIツールに切り替えるだけで30〜40%の作業時間短縮を実現したチームも()。これは単なる効率化じゃなく、競争力の源です。
Thunderbitは、プログラミング経験がなくても誰でも簡単・正確にデータ抽出できることを目指しています。(ちなみに、うちの母でも使えます。Netflixの操作はまだ苦戦中ですが…)
Thunderbit AI 웹 스크래퍼:ビジネスユーザー向け主な機能
Thunderbitの推しポイントをちょっと紹介させてください。Thunderbitは営業・オペレーション・マーケ・不動産など、現場で「すぐに結果が欲しい」ビジネスユーザー向けに設計されています。
- AIフィールド提案: クリック一つでAIがページを解析し、最適なカラムを自動設定。セレクター調整は不要。
- 2クリック抽出: フィールド設定後は「スクレイピング」ボタンを押すだけで、クリーンなテーブルを即取得。
- サブページ抽出: 商品やプロフィールなど詳細ページも自動巡回し、追加情報をテーブルに付加。
- テンプレート搭載: Amazon、Zillow、Instagram、Shopifyなど人気サイトはテンプレートを選ぶだけで即利用可能。
- 多様なエクスポート先: Excel、Google Sheets、Airtable、Notion、CSVに無料でエクスポート。追加料金なし。
- スケジュール抽出: 「毎週月曜8時」など、定期的な自動抽出も簡単設定。
- クラウド・ブラウザ両対応: 高速なクラウド実行と、ログインが必要なサイト向けのブラウザ実行を選択可能。
- 多言語対応: 英語・スペイン語・中国語など34言語で抽出可能。
自動化と拡張:スケジューリングと連携でデータ抽出を加速
手作業のスクレイピングはもう過去のもの。真の価値は、データ抽出を自動化し、日々の業務フローに組み込むことにあります。
- スケジュール抽出: Thunderbitで毎日・毎週など定期的に自動実行。価格監視やリード獲得、ニュース集約に最適。
- ダイレクト連携: 取得データをGoogle SheetsやExcel、Airtable、Notionに直接エクスポート。ファイルのダウンロード・アップロードは不要。
- CRM・分析ツール連携: CRMやBIツールにデータを流し込み、リアルタイムのダッシュボードや自動アラート、アウトリーチも実現。
例:自動価格モニタリングワークフロー
- Thunderbitで競合商品のページを設定。
- 「AIフィールド提案」で商品名・価格・URLを自動抽出。
- 毎朝7時に自動実行するようスケジュール設定。
- 結果をGoogle Sheetsにエクスポートし、ダッシュボードと連携。
- プライシング担当者が変動を確認し、競合より先に戦略を調整。
自動化すれば、常に最新データを手に入れられます。
非構造化データを扱うベストプラクティス
ウェブデータの多くはバラバラで一貫性がなく、時にはめちゃくちゃ扱いづらいものです。これを整理するためのコツを紹介します:
- 事前に構造を決める: AIフィールド提案やテンプレートで、抽出前にカラムやデータ型を明確に。
- フィールドAIプロンプト活用: Thunderbitでは各フィールドごとにカスタム指示が可能。商品分類や電話番号のフォーマット、説明文の翻訳など、AIに要望を伝えるだけ。
- NLPの活用: レビューやコメント、記事などはNLP機能で要約・感情分析・キーワード抽出も可能。
- データの正規化: 日付・価格・電話番号などのフォーマットは抽出時に統一。後処理より効率的です。
- 重複排除・検証: 重複データの除去やサンプルチェックで精度を担保。違和感があればプロンプトや設定を調整。
フィールドAIプロンプト:抽出精度を高めるカスタマイズ
この機能は特におすすめ。フィールドごとにAIプロンプトを設定することで、
- ラベル付け・分類: 「説明文から家電・家具・衣料品のいずれかに分類」
- フォーマット統一: 「日付はYYYY-MM-DD形式で」「価格は数値のみ抽出」
- リアルタイム翻訳: 「商品説明を英語に翻訳」
- ノイズ除去: 「ユーザープロフィールから“続きを読む”や広告を除外」
- 複数フィールドの統合: 「住所欄を一つのフィールドにまとめる」
まるでAIアシスタントが웹 스크래퍼に内蔵されている感覚です。
データ品質と一貫性を保つためのポイント
データ抽出は「エクスポート」して終わりじゃありません。信頼できるデータを維持するための工夫が大事です。
- バリデーションチェック: 範囲チェックや必須項目、ユニークキーでエラーを検出。
- サンプル監査: 抽出データの一部を元サイトと照合。特に初回やサイト変更時は必須。
- エラーハンドリング: 失敗時のログや異常検知(行数急減など)のアラート設定。
- 継続的なクリーンアップ: スプレッドシートやスクリプトで空白除去・文字コード修正・テキスト正規化。
- スキーマの一貫性: フィールド名やフォーマットを安定させ、変更履歴も記録。
データへの信頼は何より大切。最初のひと手間が後々のトラブルを防ぎます。
ツール比較:最適なウェブスクレイピングソリューションの選び方
ウェブスクレイピングツールは本当にいろいろ。選ぶときのポイントをまとめました:
| ツール | 強み | 注意点 |
|---|---|---|
| Thunderbit | 非技術者でも簡単、AIフィールド検出、サブページ抽出、テンプレート、無料エクスポート、手頃な価格(Thunderbit Blog)。 | 超大規模・開発者向け案件には不向き、クレジット制。 |
| Browse AI | ノーコード、変化監視に強い、Google Sheets連携、大量抽出。 | 初期費用が高め、設定に時間がかかる場合も。 |
| Octoparse | 高機能、動的サイト対応、技術者向けの高度な機能。 | 学習コストが高く、価格も高め。 |
| Web Scraper (webscraper.io) | 小規模案件に無料、ビジュアル設定、コミュニティ充実。 | 手動設定が複雑、AI支援は限定的。 |
| Diffbot | AI搭載、APIで非構造ページ解析、開発者向け。 | 価格が高く、非技術者には不向き。 |
アドバイス: ビジネスユーザーで素早く正確な結果が欲しいならが最適。パワーユーザーや開発者ならOctoparseやDiffbotも検討の価値あり。まずは無料プランやトライアルで試してみましょう。
まとめ:ウェブデータ抽出のベストプラクティスを実践しよう
ウェブサイトからのデータ抽出は、もはや「あると便利」じゃなく、競争力維持のための必須事項。ぜひ以下を意識してください:
- 価値の最大化: ウェブデータは迅速かつ賢い意思決定の原動力。活用しない手はありません。
- 課題克服: AI搭載ツールで非構造化データや大量処理、サイト変化にも柔軟に対応。
- 法令遵守: プライバシー法やサイトルール、データセキュリティを徹底。
- 自動化推進: 抽出をスケジューリングし、日常業務に組み込む。
- 品質重視: バリデーション・クリーンアップ・監視で信頼性を維持。
「どれだけ簡単にできるか」ぜひ体感してみてください。して、次のデータプロジェクトでお試しを。さらに詳しいガイドや実例はもチェックしてみてください。
みんなのデータがいつも整理されてて、ルールも守れて、すぐに使える状態でありますように。
よくある質問(FAQ)
1. どのウェブサイトからでもデータ抽出は合法ですか?
基本的に、公開情報のスクレイピングは多くの国で合法ですが、ログインやセキュリティを回避する行為はNG。必ず利用規約を確認し、GDPRやCCPAなどのプライバシー法も守りましょう()。
2. AIはウェブデータ抽出をどのように進化させますか?
のようなAI搭載ツールは、フィールド自動検出やレイアウト変化への適応、データのクリーンアップや動的コンテンツ・翻訳対応など、最小限の設定で高精度な抽出を実現します()。
3. 非構造化データを扱うベストプラクティスは?
事前にデータ構造を決め、フィールドごとのAIプロンプトで抽出を誘導し、フォーマットを統一しながら抽出、結果を検証しましょう。Thunderbitなら分類・フォーマット・ラベル付けも簡単です。
4. ウェブデータ抽出を自動化・拡張する方法は?
スケジューリング機能で定期実行し、Google SheetsやAirtable、CRMなどに直接連携。自動化で常に最新データを維持し、手間も削減できます。
5. 抽出データの品質と一貫性を保つには?
バリデーションチェックやサンプル監査、エラー管理、スキーマの一貫性維持が重要。継続的な改善と監視で信頼性を高めましょう。
これらのベストプラクティスを実際に体験したい人は、をぜひ試してみてください。簡単・合法・スケーラブルなウェブデータ抽出を実感できます。
さらに詳しく知りたい方へ