

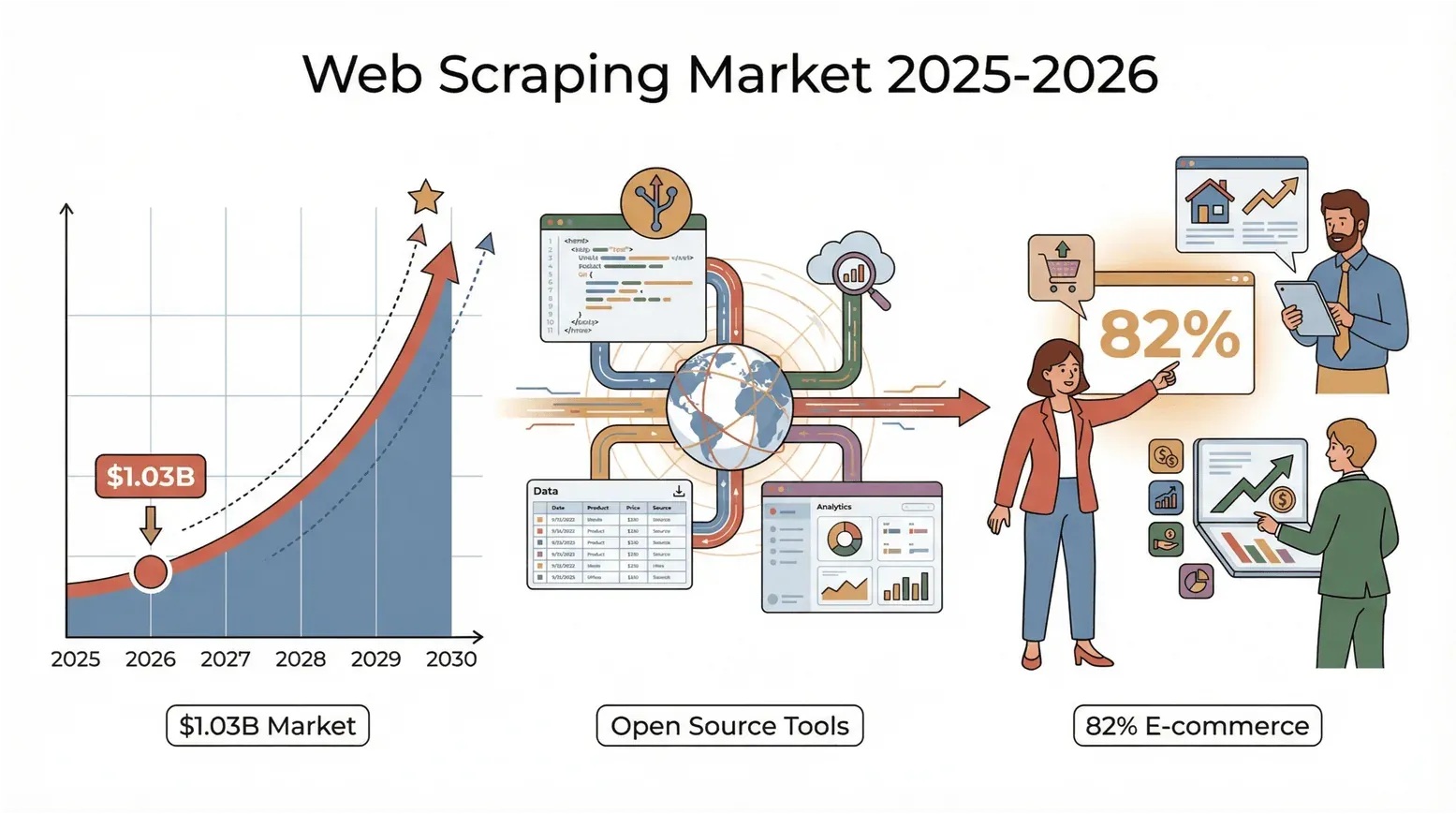
ウェブには膨大なデータが眠っていて、2026年はその混沌を洞察に変える競争が、これまで以上に激しくなっています。営業、EC、不動産に携わる方はもちろん、私のようなデータ好きでも、昔ながらの「コピペ」ではもう追いつかないと痛感しているはずです。ひとつ驚きの数字を挙げると、Mordor Intelligenceによれば世界のウェブスクレイピング市場は2025年に10億3,000万ドルに達し(PromptCloudの2026年版ウェブスクレイピング現状レポートでも引用されています)、2030年までにおよそ倍増すると見込まれています。
しかも、使っているのは巨大テック企業だけではありません。Browsercatによると、EC企業の82%、そして投資会社の3分の1超が、リード獲得、価格調査、市場調査のためにウェブをスクレイピングしています。要するに、ウェブスクレイピングツールをまだ使っていないなら、お金もインサイトも取りこぼしている可能性が高いということです。
ここで朗報です。オープンソースのウェブスクレイピングツールは、いまや以前にも増して高性能で、使いやすく、コミュニティ主導で進化を続けています。Pythonのプロでも、JavaScript好きでも、あるいは手間をかけずにデータだけ欲しいビジネスユーザーでも、自分に合う1本がきっと見つかります。私はSaaSと自動化の世界で長年働きながら、このエコシステムが育っていく様子をずっと見守ってきました。そこで本記事では、2026年に注目したいオープンソースのウェブスクレイパーツール5選を、用途に応じた選び方とあわせて紹介します。
なぜオープンソースのウェブスクレイパーツールを選ぶのか?
データスクレイピングとは?2026年のやり方も解説 Get Started Free
オープンソースのウェブスクレイパーツールは、データの世界における万能ツールのような存在です。コスト効率が高く(ライセンス料がかかりません)、柔軟性があり(思いどおりにカスタマイズできます)、透明性も高い(仕組みをそのまま確認できます)からです。でも、本当にすごいのはコミュニティの底力です。オープンソースには、プラグイン、チュートリアル、修正方法を惜しみなく共有してくれる何千人もの開発者やユーザーがいます。だから、ひとりで行き詰まることはありません(Oreate AI)。
商用ツールと比べると、オープンソースは自分のペースで進めやすいのが魅力です。ベンダーのロードマップや料金体系に縛られず、ウェブサイトの変更に合わせてスクレイパーを自分で調整できます。さらに言えば、多くの商用スクレイピングサービスは、実はこうしたオープンソースエンジンの上に成り立っています。それなら、最初から本家を直接使わない手はありません。
最適なオープンソースのウェブスクレイパーツールの選び方
選択肢が多いので、今回は次のポイントを重視しました。
- 使いやすさ: 非エンジニアでもすぐ始められるか。ビジュアル操作やAI駆動の選択肢はあるか。
- 拡張性: 単発案件だけでなく、大規模プロジェクトにも耐えられるか。
- 言語とプラットフォームの対応: Python、JavaScript、ブラウザ型、デスクトップ型など、幅広い環境に対応しているか。
- コミュニティと保守状況: 継続的に更新されているか。フォーラム、ドキュメント、プラグインは充実しているか。
- 独自機能: AIによる項目検出、サブページスクレイピング、スケジューリング、クラウド対応などがあるか。
あわせて、実際のユーザーフィードバックやビジネスでの活用シーンも踏まえています。結局のところ、いちばん優れたツールとは、現場の悩みを実際に解決してくれるツールだからです。
注目すべきオープンソースのウェブスクレイパーツール5選
では本題に入りましょう。AIの手軽さから開発者向けの本格派まで、私が厳選した5本を紹介します。
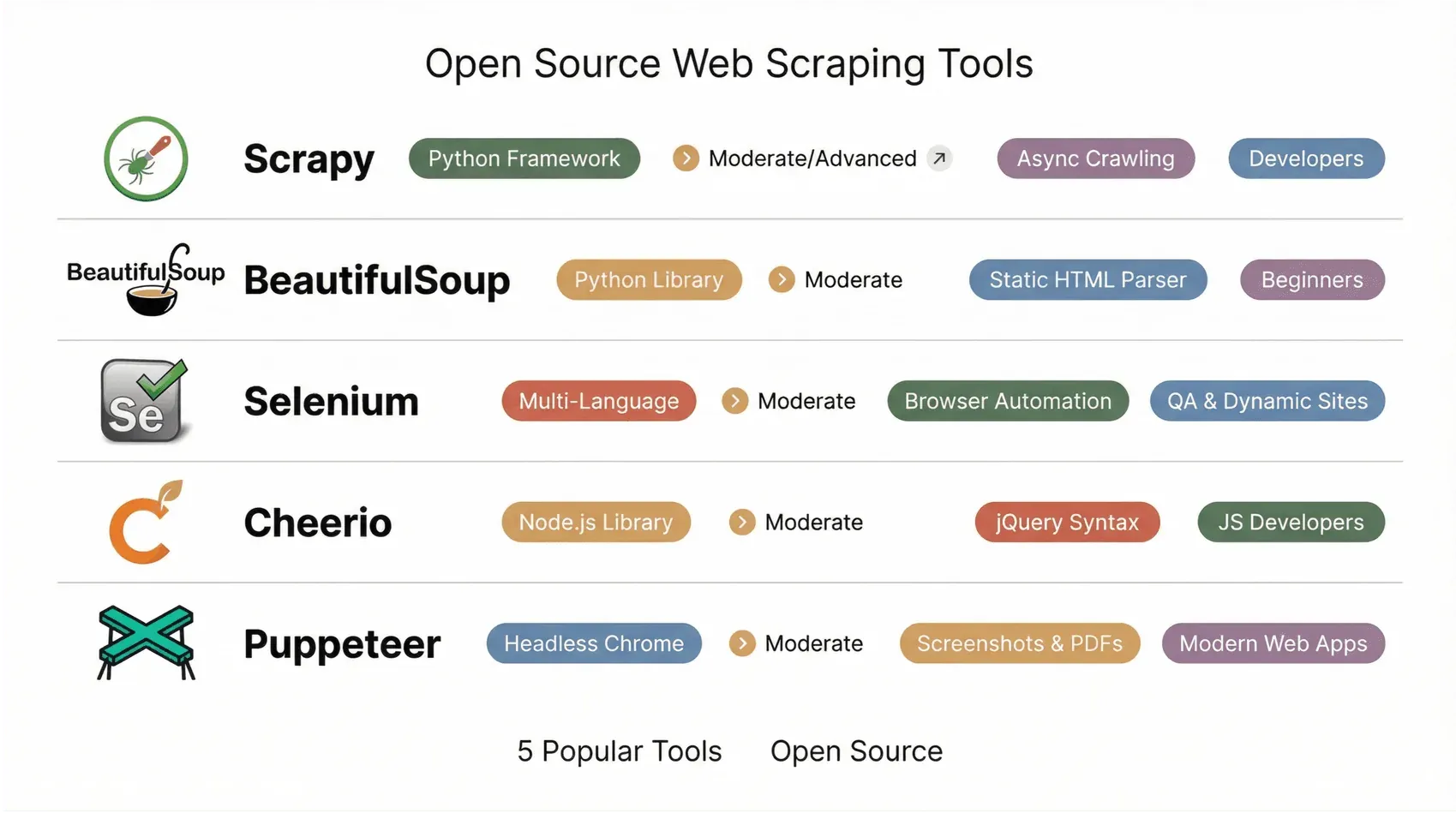
1. Scrapy
Scrapyは、Python開発者にとって夢のような存在です。大規模でカスタマイズ性の高いクローラーやデータパイプラインを組むための、実績十分なフレームワークです。Pythonで「spider」を定義すれば、キュー管理、スロットリング、JSON・CSV・XMLへの出力まで、あとはScrapyが面倒を見てくれます。2.14リリース(2025年10月)と2.14.1パッチ(2026年1月)では、ScrapyのTwisted-Deferred内部の大部分がネイティブのasyncioコルーチンへ書き直され、新しいAsyncCrawlerProcessエントリポイントも加わりました。これにより最新のPython非同期エコシステムと自然に噛み合うようになり、新規生成プロジェクトではasyncio reactorが標準になっています。なお、Scrapy 2.14以降はPython 3.10以上が必要です。
プラグインのエコシステムも非常に厚く、プロキシ、Cookie、さらには動的サイト向けのヘッドレスブラウザ統合まで一通り用意されています。Scrapyは、ECサイト全体をクロールしたり、ニュースを大規模に集約したりするときに、多くのチームがまず手に取るフレームワークです。非エンジニアには学習コストが高めですが、パワーと柔軟性を求めるなら十分に応えてくれます(Octoparse)。
2. Beautiful Soup
Beautiful Soupは、手早くHTMLを解析したいときの定番Pythonライブラリです。学習しやすく、パーサーも扱いやすいので、初心者にも上級者にも愛されています。かなり崩れたHTMLでも難なく処理できるのが心強いところです。ページを取得し(たいていはrequestsを使います)、Beautiful Soupに読み込ませ、シンプルなメソッドで要素を探して抜き出すだけです。
小規模なプロジェクト、プロトタイプ、学習用途にぴったりです。ただしJavaScriptは実行できないため、使えるのは静的HTMLに限られます。動的サイトを扱うなら、Seleniumやrequests_htmlなどと組み合わせる必要があります(ProsperaSoft)。
3. Selenium
Seleniumは、ブラウザ自動化の元祖ともいえるツールです。もとはテスト用に生まれましたが、いまではJavaScriptの多い動的サイトをスクレイピングする定番のひとつになっています。SeleniumはChromeやFirefoxなどの実ブラウザを起動し、クリック、スクロール、ログインといった人間の操作をそっくり再現します。人間が見られるものなら、Seleniumもスクレイピングできるわけです。
Python、Java、JS、C#など複数言語に対応し、ログイン後のページや操作フローのあるサイトを扱うのに向きます。Selenium 4ではWebDriver BiDiの統合も着実に進み、スクリプトがブラウザイベント(ネットワークリクエスト、コンソールログ、DOMの変化)を購読し、通信を横取りできるようになりました。こうした機能は、以前ならPuppeteerやPlaywrightのほうが扱いやすいとされていた領域です。2026年1月の4.40、2月の4.41では、Python、Java、.NET、Rubyの各バインディングでBiDi対応がさらに広がっています。とはいえ弱点もあります。Seleniumは純粋なHTTPスクレイパーより遅く重く、ブラウザドライバの管理も手間です。それでも、難易度の高いサイトや、すでにテスト自動化でSeleniumを標準採用しているチームにとっては、2026年でも十分に有力なスクレイピング手段です(ScrapeHero)。
4. Cheerio
Cheerioは、Node.js界のjQueryのような存在です。おなじみのjQuery風シンタックスで、サーバー側でHTMLを解析できます。動作はとても速く、静的ページの処理に最適です。HTMLを取得し(AxiosやFetchを使います)、Cheerioに読み込ませ、セレクターで必要な要素を抜き出すだけです。
CheerioはJavaScriptを実行しないため、向いているのは静的コンテンツです。ただし他のNode.jsツールとの相性は抜群で、すべてをJavaScriptでまとめたい開発者に好まれています(Cheerio Docs)。
5. Puppeteer
Puppeteerは、Node.jsからChromeまたはChromiumをヘッドレスモードで操作するためのライブラリです。実ブラウザでの描画が必要な最新のWebアプリやシングルページアプリのスクレイピングで人気があります。スクリーンショット、PDF生成、ネットワークの横取りなどを、すっきりしたasync/await APIで扱えます。GoogleのChromeチームが今もPuppeteerを保守しており、新しいChromeのバージョンやDevTools Protocolの更新に合わせて調整を続けています。
2026年に押さえておきたい背景もあります。Puppeteerのリリースは、新機能の追加というよりChrome互換性や依存関係の更新が中心になっており、もともとPuppeteerの最も野心的な機能を作っていたチームは、その後MicrosoftでPlaywrightを開発しました。すでにPuppeteerを使い込んでいて、Chrome自動化だけで足りるなら、今でも安定した選択肢です。一方、これから始めるなら、クロスブラウザ対応、組み込みのテストランナー、自動待機するlocator、トレースビューアを備えたPlaywrightを、2026年の多くのチームはまず第一候補に挙げます(Firecrawl — Playwright vs Puppeteer、Autonoma — Playwright vs Puppeteer 2026)。
オープンソースのウェブスクレイパーツール比較表
| ツール | 使いやすさ | プラットフォーム/言語 | 動的コンテンツ | こんな人に最適 | 主な強み |
|---|---|---|---|---|---|
| Scrapy | 中級〜上級(コード) | Pythonフレームワーク | 部分対応 | 開発者、データサイエンティスト | 非同期クロール、プラグイン、巨大なコミュニティ |
| BeautifulSoup | 中級(シンプルなコード) | Pythonライブラリ | いいえ | 初心者、手早い解析 | クセのないパーサー、静的HTMLに強い |
| Selenium | 中級(スクリプト) | 複数言語対応 | はい | QA、動的サイトのスクレイピング | 実ブラウザ自動化、ログインやユーザー操作に対応 |
| Cheerio | 中級(JSコード) | Node.jsライブラリ | いいえ | JS開発者、静的ページ | jQuery構文、高速なHTML解析 |
| Puppeteer | 中級(JSコード) | Node.js(ヘッドレスChrome) | はい | 開発者、最新Webアプリ | スクリーンショット、PDF、SPAスクレイピング、async/await API |
自分に合ったオープンソースのウェブスクレイパーツールの選び方
AIであらゆるウェブサイトをスクレイピングする方法 Get Started Free
ツール選びの簡単な指針をまとめました。
- 技術レベル: 非エンジニアなら、Thunderbit、Octoparse、ParseHub、WebHarvyあたりから始めるのがおすすめです。開発者なら、Scrapy、Cheerio、Puppeteer、Apifyが有力です。
- 案件規模: 単発や小規模なら、Beautiful Soup、Cheerio、WebHarvy。大規模または継続運用なら、Scrapy、Apify、Thunderbit(スケジューリング対応)。
- データの種類: 静的HTMLなら、Cheerio、Beautiful Soup、WebHarvy。動的・JavaScript主体なら、Puppeteer、Selenium、Thunderbit、Octoparse。
- 連携: Sheets、Notion、データベースに出力したいなら、ThunderbitとOctoparseが便利です。APIや独自パイプラインが要るなら、ScrapyとApifyが頼れます。
- コミュニティとサポート: 活発なフォーラム、最近の更新、豊富なチュートリアルがあるか確認しましょう。Scrapy、Cheerio、Seleniumはコミュニティが非常に大きく、ThunderbitとOctoparseもユーザーが増えていてガイドが充実しています。
まずは小さな案件でいくつか試し、ワークフローや使い心地に合うものを見極めてください。組み合わせるのもおすすめです。たとえば、最初はビジュアルツールで素早く取得し、そのあとコードベースのフレームワークで深くクロールする、という使い分けがいちばん速いこともあります。
オープンソースのスクレイピングにおけるコミュニティと継続サポートの価値
オープンソース最大の利点のひとつは、やはりコミュニティです。活発なフォーラム、GitHubリポジトリ、Stack Overflowのタグがあるので、ひとりで頭を抱える必要はありません。つまずいても、すでに誰かが解決済みか、助けてくれる可能性が高いのです。コミュニティ主導のツールは更新や新機能の追加も頻繁で、チュートリアル、プラグイン、ベストプラクティスも豊富に出回っています(Oreate AI)。
ですから、ThunderbitやOctoparseのようなビジュアルツールでは、ユーザーフォーラムやテンプレート共有がまさに宝の山になります。開発者向けツールでは、GitHubのIssueやDiscord/Slackのグループこそが頼れる現場です。オープンソースツールを選ぶというのは、世界中の問題解決者のネットワークに加わるということ。これは何ものにも代えがたい価値があります。
Thunderbit:誰でも使える、より簡単なノーコードのウェブスクレイピングソリューション
たしかにオープンソースは魅力的です。とはいえ実際には、データを取るためだけにスクレイパーを作り、調整し、保守し続けたいわけではない、ということもあります。しかも、すべてのスクレイピング課題がオープンソースコードだけで片づくわけでもありません。そこでThunderbitの出番です。ここまで読んで「ツールとしては面白いけれど、作ったり保守したりせずにデータだけ欲しい」と感じたなら、Thunderbitは自然な次の一手になります。
Thunderbitは、インフラよりも成果を優先するビジネスユーザーのために作られたAI搭載のChrome拡張機能です。セレクターやスクリプトを書く代わりに、まずAIで項目を提案をクリックします。AIがページ構造を理解して列を提案し、2回目のクリックでスクレイピングが終わります。ページ送り、サブページ、一覧から詳細への流れも自動でさばけます。
Thunderbitの大きな強みのひとつは、人の意図と構造化データをうまく橋渡しできる点です。たとえば「商品名、価格、評価を集めて」と自然な言葉で伝えるだけで、Thunderbitがきれいな表に整えてくれます。サブページスクレイピングを使えば、詳細ページを自動で巡回して、よりリッチなデータも難なく取れます。Excel、Google Sheets、Notion、Airtableへのエクスポートも標準搭載なので、取得したデータをそのまますぐ活かせます。
Thunderbitは、信頼できるデータが必要でも、オープンソースのパイプラインまで保守したくはない営業、マーケティング、EC、不動産チームに、特に支持されています。数十言語に対応し、動的サイトでも快適に動き、始めやすい無料枠も用意されています。オープンソースではありませんが、オープンソースツールとの相性は抜群です。エンジニアリングの負担をかけずに、アイデアの検証や定期的な業務スクレイピングを最速で回す手段、と考えると分かりやすいでしょう。
まとめ:最適なオープンソースツールでウェブデータを解き放つ
ウェブスクレイピングは、もはや開発者や大企業だけのものではありません。今のオープンソースツールがあれば、誰でもウェブを構造化された実用的なデータへ変えられます。リードリストの作成、価格監視、次のAIプロジェクトのデータ収集など、用途はさまざまです。大切なのは、自分の目的に合ったツールを選ぶこと。スピードと手軽さを求めるならAI搭載のビジュアルツール、パワーと拡張性を求めるならコードベースのフレームワークです。
では次に何をすればいいか。この一覧からひとつ選び、実際の業務で試して、どれだけ時間と手間が浮くか確かめてください。手早く成果を出したいなら、Thunderbitをダウンロードして、ウェブスクレイピングがどれだけ簡単か体感してみてください。ウェブはあなたのもの。データという真珠を取りに行きましょう。
さらに詳しい解説やチュートリアルは、Thunderbit Blogをご覧ください。スクレイピングを楽しんでください!
Thunderbit AIウェブスクレイパーを無料で試す Get Started Free
よくある質問
1. 商用ツールと比べたとき、オープンソースのウェブスクレイパーツールの最大の利点は何ですか?
オープンソースツールはコスト効率が高く、柔軟で、活発なコミュニティに支えられています。自由にカスタマイズでき、ベンダーロックインを避けられ、共有知識や頻繁な更新の恩恵も受けられます。
2. 非技術系のビジネスユーザーに最適なオープンソースツールはどれですか?
Thunderbit、Octoparse、ParseHub、WebHarvyは、いずれもノーコード利用に向いています。中でもThunderbitは、AIによる2クリックのワークフローと直接エクスポート機能が際立っています。
3. オープンソースツールは、JavaScriptが多い動的サイトにも対応できますか?
はい。Thunderbit、Selenium、Puppeteer、Octoparse、ParseHubのようなツールなら、実ブラウザやヘッドレスブラウザでページを描画しながら動的コンテンツを取得できます。
4. ツールが継続的に保守・サポートされているかは、どう判断すればよいですか?
GitHubで最近のコミット、未解決Issue、コントリビューターの活動を確認してください。あわせて、活発なフォーラム、最近のブログ投稿、ユーザーが作ったプラグインやテンプレートの多さもチェックしましょう。
5. 初めてウェブスクレイピングを始めるなら、いちばん良い方法は何ですか?
ThunderbitやOctoparseのようなビジュアルまたはAI搭載のツールから始めるのがおすすめです。小さなデータセットをスクレイピングして、ExcelやSheetsに出力しながら試してみてください。慣れてきたら、より高度な案件に向けてコードベースのツールも検討できます。
Thunderbitの動きを見てみたいですか?Chrome拡張機能をダウンロードして、コード不要でウェブをデータに変えている3万人以上のユーザーの仲間入りをしましょう。
もっと詳しく知る




