オンラインで公開されるニュース記事は、毎日200万〜300万本ほどあります。見出し、日付、配信元、本文まで構造化して集めようとすると、説明書なしで家具を組み立てるくらい、かなり骨が折れます。
私はThunderbitで長年、自動化ツールの開発と検証に携わってきましたが、2026年のニューススクレイピング市場は、驚くほどの可能性と強いストレスが入り混じる、なかなかやっかいな世界です。Googleは2011年に公式のNews APIを終了し、ニュースサイト側もCloudflareやCAPTCHA、JavaScriptレンダリングの壁など、より強力なボット対策を次々に導入しています。レイアウト変更も頻繁で、月曜に動いていたスクレイパーが水曜には壊れている、なんてことも珍しくありません。一方で、広報、営業、学術研究者、AIエンジニアまで、ビジネスチームが必要とする構造化ニュースデータの重要性は、むしろ増しています。
そこで私は、API、ノーコードプラットフォーム、オープンソースライブラリを横断して、15個のニューススクレイピングツールをテストしました。価格、保守負担、クリーンな本文抽出、実際の用途への適合性を、ほかのガイドとは少し違う切り口で比較するのが目的です。
2026年に優れたニューススクレイパーを見分けるポイント
「おすすめニューススクレイパー」系の記事は、評価基準をまるごと飛ばしがちです。そこで、私が実際に何を基準に検証したのかを先に共有します。多くの記事は機能を並べて終わりですが、長年スクレイピング基盤を作ってきて分かったのは、ビジネスユーザーが重視する基準は具体的で、しかも見落とされやすいということです。
私が使った評価フレームは次のとおりです。
| 評価基準 | 見たポイント |
|---|---|
| アプローチ | API、ノーコードのブラウザツール、オープンソースライブラリのどれか |
| ボット対策への対応 | プロキシローテーション、CAPTCHA解決、ヘッドレスブラウザ対応 |
| クリーンな本文抽出 | 広告、サイドバー、ナビゲーションを除去して本文だけ返せるか |
| メタデータ出力 | 著者、日付、画像、ソースURL、カテゴリ |
| エクスポート形式 | CSV、JSON、Google Sheets、Airtable、Notionなど |
| ページネーション / 一括対応 | 複数ページの結果やバッチURLを扱えるか |
| 保守負担 | サイトのレイアウト変更で壊れやすいか。AI適応型かセレクタ型か |
| 1,000件あたりの正規化コスト | 同一条件での価格比較(無料枠込み) |
| 最適な用途 | PR監視、リード獲得、学術研究、LLMパイプラインなど |
特に補足したい基準が2つあります。1,000件あたりの正規化コストは重要です。というのも、各ベンダーが提示する価格の単位がバラバラだからです。クレジット課金、リクエスト課金、検索課金、行数課金など、まちまちです。正規化しないと、リンゴと潜水艦を比べるようなものになってしまいます。そして保守負担は、ユーザーから聞く悩みの中で最も大きいものです。どの掲示板を見ても、訴えは同じです。「ニュースサイトは毎週火曜になると、うちのクローラーを壊したがる」。私は各ツールを3段階で評価しました。
- 🟢 保守負担が低い: AI適応型、または完全管理型API。レイアウト変更でワークフローが壊れません
- 🟡 保守負担が中程度: ボット対策には強いが、抽出ロジックは壊れることがある
- 🔴 保守負担が高い: セレクタ型。サイトが変わったら手作業で修正が必要
あなたの役割に合うニューススクレイパーは? 判断マトリクス
スクレイパーのおすすめ記事は、たいてい全読者を同じように扱います。でも、それこそが核心の問題です。ブランド言及を追うPRマネージャーと、RAGパイプラインを組むPython開発者では、必要なものがまったく違います。そこで、一覧の前に簡単な判断フレームを置いておきます。
| 用途 | 最適なアプローチ | おすすめツール |
|---|---|---|
| 毎日のニュースブリーフィング(非技術者向け) | ノーコードのブラウザツール、またはRSS | Thunderbit、Octoparse、ParseHub |
| 大規模なPR / メディア監視 | アラート付きニュースAPI | Newscatcher、Webz.io、Newsdata.io |
| ニュースからの営業リード抽出 | サブページ拡張付きAIスクレイパー | Thunderbit(サブページスクレイピング+メール/電話抽出)、Apify |
| 学術研究 / コーパス構築 | オープンソースライブラリ | Newspaper4k |
| LLMパイプライン / RAG取り込み | Markdown変換API | Thunderbit API、ScraperAPI |
| 競合分析 / 価格調査 | 定期スクレイピング | Thunderbit(スケジュールスクレイパー)、Bright Data |
もう用途は決まっていますか? それなら先へ進んでください。まだなら、下の詳細比較が役に立つはずです。
15のニューススクレイパーを一覧で比較
以下が総合比較です。価格は最安の有料プランで1,000件あたりに正規化し、保守性は3段階で評価しています。
| ツール | 種類 | 無料枠 | 1,000件あたりのコスト(推定) | ボット対策 | クリーンテキスト | 保守性 | 最適な用途 |
|---|---|---|---|---|---|---|---|
| Thunderbit | ノーコードAI(Chrome拡張+クラウド) | 月6ページ無料 | 約3〜15ドル | 強い(ブラウザ+クラウドモード) | はい(AI+サブページ) | 🟢 低 | ビジネスチーム、リード獲得、日次監視 |
| SerpApi | API | 月250検索 | 約15ドル | 強い(SERP特化) | いいえ(スニペットのみ) | 🟢 低 | GoogleニュースSERPダッシュボード |
| ScraperAPI | API | 月1,000クレジット | 約1〜5ドル | 強い(プロキシ+JSレンダリング) | いいえ(生HTML) | 🟡 中 | ボット対策基盤が欲しい開発者 |
| Newsdata.io | ニュースAPI | 1日200リクエスト | 約5〜15ドル | 該当なし(管理型API) | 一部(有料) | 🟢 低 | 構造化されたニュースメタデータ |
| Apify | クラウドプラットフォーム | 5ドル分の無料クレジット | 約1〜6ドル | 強い | アクター次第 | 🟡 中 | カスタムクラウドワークフロー |
| Oxylabs | エンタープライズAPI | 2,000件の試用 | 約0.50〜2ドル | 非常に強い | 一部 | 🟢 低 | エンタープライズ規模のSERP+Web |
| ScrapingBee | API | 試用クレジット | 約2〜5ドル | 強い(ヘッドレスChrome) | 一部(基本機能) | 🟡 中 | JavaScriptが多いニュースサイト |
| Scrapingdog | SERP API | 1,000クレジット | 約0.10〜0.50ドル | 強い | いいえ(SERPデータのみ) | 🟢 低 | 低予算のSERP監視 |
| Bright Data | エンタープライズプラットフォーム | 1,000リクエスト試用 | 約0.30〜0.50ドル | 非常に強い | はい(News Scraper) | 🟢 低 | 大規模なエンタープライズニュースデータ |
| Octoparse | ノーコードのデスクトップ+クラウド | 制限付き無料プラン | 約5〜10ドル(償却後) | 強い | はい(テンプレート使用時) | 🟡 中 | 画面操作型のノーコードスクレイピング |
| ParseHub | ノーコードのデスクトップ | 5プロジェクト、1回200ページ | 約5〜12ドル(償却後) | 中程度 | はい(設定次第) | 🔴 高 | 初心者、小規模プロジェクト |
| Newscatcher | ニュースAPI | 公開無料枠なし | 要問い合わせ(エンタープライズ) | 該当なし(管理型API) | はい(NLP拡張) | 🟢 低 | PR / メディア監視 |
| Webz.io | ニュースデータプラットフォーム | 自己完結型の無料枠なし | 要問い合わせ(エンタープライズ) | 該当なし(管理型フィード) | はい(全文+メタデータ) | 🟢 低 | 過去アーカイブ、LLM学習 |
| Newspaper4k | オープンソースPython | 無料 | 0ドル(+サーバー費用) | なし | はい(専用設計) | 🔴 高 | 開発者、コーパス構築 |
| HasData | SERP API | 無料クレジットあり | 約0.25〜0.60ドル | 強い | いいえ(SERPデータのみ) | 🟢 低 | 低予算のニュースSERPエンドポイント |
ざっくり言うと、Scrapingdog と HasData は、1リクエストあたりのコストが最も安いAPIです。クリーンな記事本文では Thunderbit と Newspaper4k が強く、ただし方向性はかなり違います。エンタープライズ層は Bright Data と Oxylabs が押さえています。保守の手間を減らしたいなら、🟢のツールを選ぶのが安全です。
1. Thunderbit — ビジネスチーム向けの最強ノーコードAIニューススクレイパー
 は、「このサイトからデータが欲しいけど、コードもセレクタ管理もしたくない」という問題を解決するために、私たちのチームが作ったツールです。ニューススクレイピングの流れは驚くほど簡単です。ニュースページを開き、AIで項目を提案をクリックし、Thunderbitが提案する列(見出し、日付、配信元、URL、要約など。ページ構造を読み取って中身を判断します)を確認して、最後にスクレイプを押すだけです。
は、「このサイトからデータが欲しいけど、コードもセレクタ管理もしたくない」という問題を解決するために、私たちのチームが作ったツールです。ニューススクレイピングの流れは驚くほど簡単です。ニュースページを開き、AIで項目を提案をクリックし、Thunderbitが提案する列(見出し、日付、配信元、URL、要約など。ページ構造を読み取って中身を判断します)を確認して、最後にスクレイプを押すだけです。
ニュース用途で特に強い理由はいくつかあります。
- AI適応型抽出: CSSセレクタを自分で書く必要も、保守する必要もありません。AIが毎回その時点のページレイアウトを読み取るので、ニュースサイトがリニューアルしてもスクレイパーが壊れにくいです。
- サブページスクレイピング: 記事リンク一覧を取得したあと、サブページをスクレイプを使えば、各記事にアクセスして本文、著者、公開日、画像まで抽出できます。見出しだけでなく、きれいな記事本文を取れるのが強みです。
- フィールドAIプロンプト: 列ごとにAIへ指示できます。たとえば「本文のみを抽出し、ナビゲーションと広告は除外」とか、「この記事の感情をポジティブ、ニュートラル、ネガティブに分類」などです。ノーコードツールとしては珍しく、ニュース分析で非常に役立ちます。
- ブラウザスクレイピング vs クラウドスクレイピング: ブラウザモードは自分のセッションを使うため、クラウドIPをブロックするサイトに向いています。一方、クラウドモードは最大50ページを一度に処理でき、速度面で有利です。
- 定期スクレイパー: 自然言語の時間間隔で、毎日や毎週の実行を設定できます。継続的なニュース監視に最適です。
- どこへでもエクスポート: Excel、CSV、Google Sheets、Airtable、Notionに対応しています。
価格と制限
Thunderbitには無料枠(月6ページ)と10ページの試用があります。有料プランは、500クレジットで年払い月約9ドルからです(1クレジット=1行)。ブラウザモードにはChrome拡張のインストールが必要です。AI機能はクレジットを消費するため、何千本もの記事を大量に扱う場合は有料プランが必要になります。ただし、日次監視や週次調査を行う多くのビジネスチームにとっては、コストは十分に手頃です。
保守性: 🟢 低。AIが毎回ページを読み直します。
おすすめ: コードを書かずに、毎日のニュースデータを扱いたい非技術系の営業、PR、オペレーションチーム。
Thunderbitのの詳しい使い方は、こちらのガイドもぜひご覧ください。
2. SerpApi — 構造化されたGoogleニュースSERPデータに最適
 は、Googleニュースの結果を構造化JSONで返すSERP特化APIです。用途が「キーワードに対するGoogleニュース上位結果を、ダッシュボードにそのまま使える形で欲しい」なら、かなり相性が良いです。見出し、配信元、日付、スニペット、サムネイルは返しますが、全文は返しません。実際の本文が必要なら、別のステップ(または別ツール)が必要です。
は、Googleニュースの結果を構造化JSONで返すSERP特化APIです。用途が「キーワードに対するGoogleニュース上位結果を、ダッシュボードにそのまま使える形で欲しい」なら、かなり相性が良いです。見出し、配信元、日付、スニペット、サムネイルは返しますが、全文は返しません。実際の本文が必要なら、別のステップ(または別ツール)が必要です。
主な機能:
- GoogleニュースSERPから構造化JSONを出力
- ボット検知対策は先方で対応(SERP特化)
- 複数のGoogleニュースロケールと言語に対応
価格: 無料枠は月250検索。有料は月75ドルで5,000検索から。1,000件あたり約15ドルです。
制限: 返るのはスニペットのみ。全文が必要なら、SerpApiは最初の一歩であって、パイプライン全体ではありません。
保守性: 🟢 低(管理型APIなので、Google側の変更は先方が吸収)。
おすすめ: ニュース監視ダッシュボードを作る開発者、またはSERPデータを分析ツールへ流し込みたい人。
3. ScraperAPI — プロキシローテーション付きの低予算スクレイピングAPI
 はニュース特化ではなく汎用スクレイピングAPIですが、ニュースページの取得には十分有効です。核となる価値は、プロキシローテーション、JavaScriptレンダリング、CAPTCHA対応です。つまり、本来なら自分で構築しなければならないボット対策基盤を、まとめて任せられるわけです。
はニュース特化ではなく汎用スクレイピングAPIですが、ニュースページの取得には十分有効です。核となる価値は、プロキシローテーション、JavaScriptレンダリング、CAPTCHA対応です。つまり、本来なら自分で構築しなければならないボット対策基盤を、まとめて任せられるわけです。
主な機能:
- 住宅用IPとデータセンターIPを使ったプロキシローテーション
- 動的なニュースサイト向けのJavaScriptレンダリング
- CAPTCHA対応
- 生HTMLを返すので、本文抽出は自分で行う必要あり
価格: 無料枠は月1,000クレジット(試用クレジット別)。JavaScriptレンダリングはリクエストあたり多くのクレジットを消費します。有料は月49ドルから。正規化コストは、JS使用量に応じて1,000リクエストあたり約1〜5ドルです。
制限: 記事のパース機能は標準搭載ではありません。返るのはHTMLで、きれいな本文ではありません。記事抽出にはNewspaper4kや自前パーサーと組み合わせるのがよいでしょう。
保守性: 🟡 中(ボット対策は任せられるが、抽出ロジックは自分で保守)。
おすすめ: 自前のプロキシネットワークを組まずに、ボット対策基盤だけ欲しい開発者。
4. Newsdata.io — 構造化メタデータに強い専用ニュースAPI
 は、150以上の国・5万以上のソースをカバーする、ニュース専用のAPIです。タイトル、説明文、配信元、日付、カテゴリ、感情分析などの構造化データを返し、プレミアムプランでは全文も取得できます。
は、150以上の国・5万以上のソースをカバーする、ニュース専用のAPIです。タイトル、説明文、配信元、日付、カテゴリ、感情分析などの構造化データを返し、プレミアムプランでは全文も取得できます。
主な機能:
- キーワード、カテゴリ、言語、国で検索
- 感情分析を標準搭載
- 過去ニュースアーカイブ(有料プラン)
- 取得基盤の保守が不要
価格: 無料枠は1日200リクエストで、項目に制限あり。有料プランで全文と過去データが解放されます。1,000件あたりのコストはプラン次第ですが、おおむね5〜15ドルです。
制限: 自社インデックスのソースが対象なので、任意のURLを指定して「これをスクレイプして」とはできません。ニッチな媒体がインデックスに入っていなければ、ここでは見つかりません。
保守性: 🟢 低(完全管理型ニュースAPI)。
おすすめ: 構造化されたニュースメタデータが必要で、スクレイピング基盤の管理は避けたいチーム。
5. Apify — カスタムニューススクレイピングワークフローに最適なクラウドプラットフォーム
 は、あらかじめ作られたGoogleニュース向けスクレイパー、特定媒体向けスクレイパー、一般的な記事抽出アクターを備えた、アクターベースのクラウドプラットフォームです。ノーコードとフルスクラッチ開発の中間にある、ちょうどよい立ち位置です。
は、あらかじめ作られたGoogleニュース向けスクレイパー、特定媒体向けスクレイパー、一般的な記事抽出アクターを備えた、アクターベースのクラウドプラットフォームです。ノーコードとフルスクラッチ開発の中間にある、ちょうどよい立ち位置です。
主な機能:
- Googleニュース、記事抽出などの事前構築済みアクター
- JavaScriptレンダリングとヘッドレスブラウザ実行に対応
- スケジューリング付きクラウド実行
- JSON、CSV、Excel、XMLなどへエクスポート
価格: 付きの無料プランあり。有料は月49、499、999ドル。1,000件あたりのコストはアクター次第で、ニューススクレイピング用では約1〜6ドルです。
制限: 事前構築済みアクターはコミュニティ管理なので、ニュースサイト側の変更で壊れることがあります。純粋なノーコードツールより設定は多めです。
保守性: 🟡 中(サイト変更時にアクターの更新が必要になることがある)。
おすすめ: クラウド実行を使いたくて、マーケットプレイスのアクターを選んで設定するのが苦にならないチーム。
6. Oxylabs — エンタープライズ級のスクレイピング基盤に最適
 は、1億以上のプロキシプール、CAPTCHA解決、ブラウザレンダリングを備えたエンタープライズ向けスクレイピングサービスです。SERP Scraper APIはジオターゲティング付きでGoogleニュース結果を扱え、Web Scraper APIは任意のニュースページに使えます。
は、1億以上のプロキシプール、CAPTCHA解決、ブラウザレンダリングを備えたエンタープライズ向けスクレイピングサービスです。SERP Scraper APIはジオターゲティング付きでGoogleニュース結果を扱え、Web Scraper APIは任意のニュースページに使えます。
主な機能:
- ジオターゲティング付きの大規模プロキシ基盤
- Googleニュース向けSERP Scraper API
- 任意URL向けWeb Scraper API
- JSON/CSV出力、大量並列リクエスト
価格: SERPデータは月49ドルから。高ボリューム向けはエンタープライズの個別見積もり。2,000件までの無料試用あり。
制限: 小規模チームには高価です。主に大規模運用向けに設計されています。
保守性: 🟢 低(完全管理型のエンタープライズAPI)。
おすすめ: 大量かつ地域別に最適化されたニュースデータを、エンタープライズ級の信頼性で必要とする企業。
7. ScrapingBee — JavaScriptが重いニュースサイトに最適
 は、実ブラウザ実行を伴うJavaScriptレンダリング重視のスクレイピングAPIです。必要なニュースサイトがクライアントサイドのJSでコンテンツを読み込むタイプなら(最近はかなり多いです)、ScrapingBeeはうまく対応してくれます。
は、実ブラウザ実行を伴うJavaScriptレンダリング重視のスクレイピングAPIです。必要なニュースサイトがクライアントサイドのJSでコンテンツを読み込むタイプなら(最近はかなり多いです)、ScrapingBeeはうまく対応してくれます。
主な機能:
- プロキシローテーション付きヘッドレスChrome
- CAPTCHA対応
- 一部ページ向けの基本的な「記事抽出」機能
- 生HTML、JSON、またはMarkdown風の出力を返す
価格: から。クレジット制で、JSレンダリングはより多くのクレジットを消費します。試用クレジットあり。
制限: 記事抽出機能は、AIベースの代替手段と比べると基本的です。主にHTMLを返すため、ほとんどのワークフローではやはりパースが必要です。
保守性: 🟡 中(ボット対策は任せられるが、抽出の設定はユーザー側)。
おすすめ: ヘッドレスブラウザの管理なしで、レンダリング済みHTMLを取りたい、JSが多いニュースサイトを扱う開発者。
8. Scrapingdog — ニュース向けの低価格SERP API
 は、Googleニュース専用エンドポイントを備えた低価格のSERP APIです。応答速度は速く、テストでは1リクエストあたり約2秒で、API系オプションの中では最も競争力のある価格設定です。
は、Googleニュース専用エンドポイントを備えた低価格のSERP APIです。応答速度は速く、テストでは1リクエストあたり約2秒で、API系オプションの中では最も競争力のある価格設定です。
主な機能:
- Googleニュース専用エンドポイント
- 構造化JSON出力(見出し、配信元、日付、スニペット)
- 高速レスポンス
価格: 月40ドルで40万リクエストから。つまり、1,000件あたり約0.10ドルで、驚くほど安いです。無料枠は1,000クレジット。
制限: 返るのはSERPデータのみ(見出し、スニペット)で、全文はありません。SerpApiと同じトレードオフですが、価格はかなり低いです。
保守性: 🟢 低(管理型SERP API)。
おすすめ: GoogleニュースのSERPデータを大規模に、できるだけ安く取りたい予算重視の開発者。
9. Bright Data — エンタープライズ向け大規模ニュースデータの本命
 は、まさにエンタープライズの重鎮です。専用のNews Scraper製品、大規模プロキシ基盤、CAPTCHA解決、ブラウザレンダリング、さらにS3やSnowflakeなどへの下流配信まで備えています。
は、まさにエンタープライズの重鎮です。専用のNews Scraper製品、大規模プロキシ基盤、CAPTCHA解決、ブラウザレンダリング、さらにS3やSnowflakeなどへの下流配信まで備えています。
主な機能:
- 専用News Scraper製品
- 事前構築済みデータセットとリアルタイム収集
- 自動プロキシ管理とCAPTCHA解決
- 定期収集とアラート
- JSON、CSV、NDJSON、S3、Snowflake、GCS、Azure、SFTPへエクスポート
価格: 従量課金で、から。エンタープライズ向けの個別プランもあります。1,000リクエストの無料試用あり。
制限: 最低契約を含む複雑な料金体系です。基本的にはエンタープライズ予算向けです。
保守性: 🟢 低(エンタープライズ管理で信頼性が高い)。
おすすめ: 大量で信頼性の高いニュースデータパイプラインを必要とする大企業。
10. Octoparse — ニュースページ向けの最強ビジュアルノーコードスクレイパー
 Octoparseは、画面上でクリックしながらワークフローを作るデスクトップアプリです。よくあるニュースサイト向けの事前構築テンプレートがあり、ページネーションや無限スクロールにも対応し、定期実行のためのクラウド実行も提供しています。
Octoparseは、画面上でクリックしながらワークフローを作るデスクトップアプリです。よくあるニュースサイト向けの事前構築テンプレートがあり、ページネーションや無限スクロールにも対応し、定期実行のためのクラウド実行も提供しています。
主な機能:
- 画面操作型のワークフロービルダー
- 事前構築済みのニュースサイトテンプレート
- スケジューリング付きクラウド実行
- IPローテーションと自動CAPTCHA解決
- Excel、CSV、JSON、データベース、Google Sheetsへエクスポート
価格: 10タスクと月5万エクスポートまでの無料プランあり。有料は月約89ドルから。
制限: セレクタベースの抽出なので、ニュースサイトがレイアウトを更新するとスクレイパーが壊れます。手動修正が必要ですが、ニュースサイトはレイアウト変更が非常に多いです。
保守性: 🟡 中(テンプレートは助けになるが、セレクタは壊れることがある)。
おすすめ: 画面で操作できるノーコードビルダーを使いたくて、たまのテンプレート保守なら許容できる人。
11. ParseHub — 初心者向けの無料ノーコード最有力候補
 ParseHubは、たっぷり使える無料プランを備えた、画面操作型のスクレイパーです。JavaScriptレンダリングされたコンテンツにも対応しており、一回限りの調査や小規模なニュース抽出に向いています。
ParseHubは、たっぷり使える無料プランを備えた、画面操作型のスクレイパーです。JavaScriptレンダリングされたコンテンツにも対応しており、一回限りの調査や小規模なニュース抽出に向いています。
主な機能:
- 画面上で要素を選択(コーディング不要)
- JavaScriptレンダリングページに対応
- CSV/JSONへエクスポート
- 無料枠: 5プロジェクト、1回200ページ
価格: 無料プランは5プロジェクト、1回200ページ。有料は月189ドルから。
制限: CSSセレクタベースなので、レイアウト変更で頻繁に壊れます。拡張性も限定的で、API系ツールより遅めです。Redditやフォーラムのユーザーは、学習コストと壊れやすさを一貫して指摘しています。
保守性: 🔴 高(セレクタが壊れやすく、AI適応もない)。
おすすめ: 無料の入り口から始めたい、初心者の小規模な一回限りのニュース調査。
12. Newscatcher — PRとメディア監視向けの最適なニュースAPI
 は、7万以上のソースをカバーする専用のニュース集約APIです。メディア監視、PRトラッキング、トレンド分析向けに作られており、感情、要約、エンティティ抽出などのNLP拡張フィールドを備えています。
は、7万以上のソースをカバーする専用のニュース集約APIです。メディア監視、PRトラッキング、トレンド分析向けに作られており、感情、要約、エンティティ抽出などのNLP拡張フィールドを備えています。
主な機能:
- 7万以上のソースをカバー
- NLP拡張: 感情、要約、エンティティ抽出、重複排除、クラスタリング
- キーワード、トピック、配信元、言語、国で検索
- 過去アーカイブへのアクセス
価格: エンタープライズ価格(個別見積もり)。テスト用の公開無料枠はありませんが、依頼に応じて試用を出す場合があります。
制限: エンタープライズ寄りの価格帯は、小規模チームには手が届きにくいかもしれません。自己完結型の無料枠もありません。
保守性: 🟢 低(完全管理型API)。
おすすめ: 中規模〜大規模企業のPR・メディア監視チーム。
13. Webz.io — 過去ニュースアーカイブとLLM学習データに最適
 は、何年もさかのぼれる数十億本規模の過去記事アーカイブを持つニュースデータプラットフォームです。リアルタイムフィードと過去データの両方を提供し、全文、メタデータ、拡張情報を含む構造化JSONを返します。
は、何年もさかのぼれる数十億本規模の過去記事アーカイブを持つニュースデータプラットフォームです。リアルタイムフィードと過去データの両方を提供し、全文、メタデータ、拡張情報を含む構造化JSONを返します。
主な機能:
- 過去アーカイブに数十億本の記事
- リアルタイムフィードと過去データアクセス
- 構造化メタデータ付きの全文記事
- 学習データやRAGパイプライン用途でAI/MLチームに人気
価格: エンタープライズ/個別見積もり(データ量ベース)。ニュース用途の自己完結型無料枠はありません。
制限: カジュアルユーザー向けではありません。エンタープライズ価格のみです。
保守性: 🟢 低(完全管理型データフィード)。
おすすめ: 学習データを作るAI/MLチームや、深い過去ニュースアーカイブを必要とするエンタープライズチーム。
14. Newspaper4k — 記事抽出に最適なオープンソースライブラリ
 は、きれいな記事本文を抽出するために作られたPythonライブラリです(Newspaper3kの後継)。広告、サイドバー、ナビゲーションを取り除き、タイトル、本文、著者、公開日、画像、キーワード、要約だけを返します。
は、きれいな記事本文を抽出するために作られたPythonライブラリです(Newspaper3kの後継)。広告、サイドバー、ナビゲーションを取り除き、タイトル、本文、著者、公開日、画像、キーワード、要約だけを返します。
主な機能:
- ノイズを除去してクリーンな本文を抽出
- タイトル、著者、公開日、画像、キーワード、要約を返す
- 完全に無料でオープンソース
- 静的HTMLページでは軽量で高速
価格: 無料。ただし、自前のサーバー、プロキシ基盤、開発工数が必要です。
制限: ボット対策は標準搭載ではありません。JavaScriptが多い動的サイトでは壊れます。Pythonの知識と、基本抽出を超える用途には独自パイプラインが必要です。サイトのHTML構造が変わったら、自分で直す必要があります。
保守性: 🔴 高(サイトHTMLの変更で壊れ、手動修正が必要)。
おすすめ: 記事パースを最大限コントロールしたいPython開発者向けの、独自ニュース抽出パイプライン。
15. HasData — ニュースエンドポイント付きの低予算SERP API
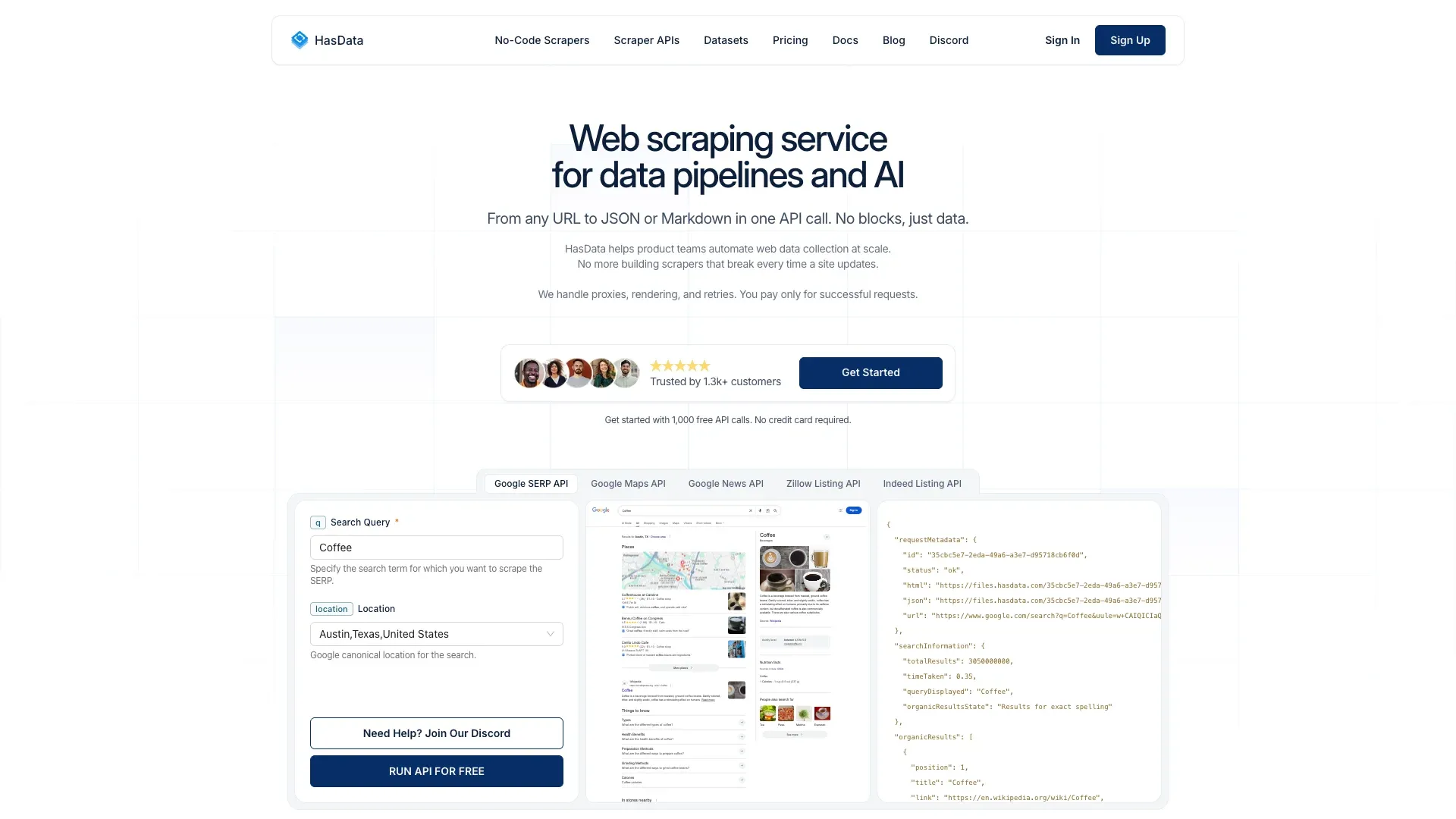 は、Googleニュース専用エンドポイントを備えたSERP APIです。競争力のある価格で、ニュース結果を構造化JSONで返します。
は、Googleニュース専用エンドポイントを備えたSERP APIです。競争力のある価格で、ニュース結果を構造化JSONで返します。
主な機能:
- Googleニュース専用エンドポイント
- 構造化JSON出力
- 1リクエストあたりの応答時間は約3〜4秒
- テスト用の無料クレジットあり
価格: から(ニュース1リクエストは5クレジット=4万リクエスト)。1,000件あたり約0.25〜0.60ドルです。
制限: SERPデータ(見出し、スニペット)のみで、全文はありません。
保守性: 🟢 低(管理型SERP API)。
おすすめ: SerpApiほど高価でなく、GoogleニュースのSERPデータが欲しい予算重視のチーム。
注目すべきパターン
15個すべてを見ていくと、いくつかの傾向がはっきり見えてきます。
SERP API(SerpApi、Scrapingdog、HasData)は、構造化された見出しデータには強いものの、全文が必要になると途端に物足りなくなります。専用ニュースAPI(Newsdata.io、Newscatcher、Webz.io)はメタデータの問題をきれいに解決してくれますが、任意URLのスクレイピングはできません。ノーコードツール(Thunderbit、Octoparse、ParseHub)は、どのページでも柔軟にスクレイピングできる一方で、保守性はかなりバラつきがあります。そしてNewspaper4kは、パイプラインを自分で構築・保守する覚悟があるなら、最もクリーンな記事抽出を実現できます。
API vs ノーコード vs オープンソース:記事1,000本あたりの実コスト
この比較を全カテゴリ横断で正規化している記事は、ほかにありません。計算してみましょう。
| 方式 | セットアップ時間 | 記事1,000本あたりのコスト | 保守性 | 向いている人 |
|---|---|---|---|---|
| オープンソース(Newspaper4k) | 数時間〜数日 | 0ドル(ただしサーバー+開発工数あり) | 🔴 高 | 独自要件を持つ開発者 |
| ニュースAPI(Newsdata.io、Newscatcher、Webz.io) | 数分 | 5〜50ドル以上 | 🟢 低 | 構造化データ、過去アーカイブ |
| スクレイピングAPI(ScraperAPI、ScrapingBee、Oxylabs) | 30分 | 1〜5ドル | 🟡 中 | ボット対策込みで使いたい開発者 |
| ノーコードAI(Thunderbit、Octoparse、ParseHub) | 2分 | 3〜15ドル | 🟢〜🟡 | ビジネスユーザー、非技術チーム |
「無料」のオープンソースツールに隠れているコストは、開発者の時間です。シニア開発者が毎月4時間、壊れたNewspaper4kパイプラインの修正に費やしているとしたら? それは無料ではなく、かなり高くつきます。
逆に、Webz.ioやNewscatcherのようなエンタープライズAPIは保守が楽ですが、使う意味が出るのは規模が大きい場合に限られます。
私が話す多くのビジネスチームにとっての最適点は、柔軟なアドホックスクレイピングにはノーコードAIツール(Thunderbitのようなもの)、継続的で構造化された監視には専用ニュースAPI、という組み合わせです。
保守問題:なぜ多くのニューススクレイパーは壊れるのか、そして壊れないのはどれか
ここは独立した章にする価値があります。
これは、フォーラム、サポートチケット、ユーザーとの会話で、私が最もよく目にする不満です。ニュースサイトは頻繁に、時には毎週のようにレイアウトを変えます。CSSセレクタやXPathで作られたスクレイパーは、今日は完璧に動いても、明日にはゴミを返すことがあります。
15個のツールを保守性の観点で並べると、次のようになります。
| 保守レベル | ツール | サイトが変わったときに起こること |
|---|---|---|
| 🟢 低(AI適応型または管理型API) | Thunderbit、SerpApi、Newsdata.io、Newscatcher、Webz.io、Scrapingdog、HasData、Oxylabs、Bright Data | AIがページを読み直すか、API提供側が吸収します。あなたは何も触りません。 |
| 🟡 中(テンプレート+プロキシ) | ScraperAPI、ScrapingBee、Apify、Octoparse | ボット対策は処理されますが、抽出ロジックやアクター/テンプレートの更新が必要になることがあります。 |
| 🔴 高(セレクタ型) | ParseHub、Newspaper4k | サイトが変わるとスクレイパーが壊れます。セレクタやパース規則を手動で直す必要があります。 |
Thunderbitのアプローチは特に強調する価値があります。スクレイプを実行するたびにAIが現在のページ構造を読み取るため、固定のセレクタを保守する必要がありません。実際、ニュースソース側がレイアウト変更を入れたあとでも、ユーザーが何も更新せずに何か月も同じサイトを取り続けているのを見てきました。毎日のニュースブリーフィングや週次の競合レポートを回すときに重要なのは、まさにこうした信頼性です。
クリーンな記事本文:ノイズを本当に除去できるニューススクレイパーはどれか
「データは取れたけど、広告、ナビゲーションメニュー、サイドバーのゴミだらけだった」。ニューススクレイピングに関するサポート質問の、だいたい5件中3件はこれです。
正直な整理は次のとおりです。
| クリーンテキスト性能 | ツール |
|---|---|
| 最初からクリーンな本文を返す | Newspaper4k、Thunderbit(サブページスクレイピング+フィールドAIプロンプト使用時)、Newsdata.io(プレミアム)、Webz.io、Bright Data(News Scraper)、Newscatcher |
| 見出し/スニペットのみを返す(全文なし) | SerpApi、Scrapingdog、HasData、Oxylabs(SERPモード) |
| 生HTMLを返す(自分でパースが必要) | ScraperAPI、ScrapingBee |
| 設定次第で変わる | Apify、Octoparse、ParseHub |
Newspaper4kは、標準的なニュースページからノイズを取り除く基準点です。まさにそのために作られました。ただしPythonが必要で、JSが重いサイトでは壊れます。
ThunderbitのフィールドAIプロンプトは、ノーコード版の同等手段です。列ごとにAIへ「本文のみを抽出し、ナビゲーションと広告は除外」と指示でき、抽出時にラベリング、分類、要約までできます。コードを書かずにクリーンな記事本文が必要なチームにとって、私が見つけた中ではこれが最も実用的です。
AIベースの抽出と従来手法の違いに興味があるなら、についての解説記事でさらに詳しく紹介しています。
ニュースを責任ある形でスクレイプする:法務と倫理の基本
この点に触れている競合記事は、私が見つけた限りありません。特にエンタープライズ読者向けには、埋める価値のある抜けです。
robots.txt: 必ず確認してください。主要なニュースサイトの多くは、特定パスのスクレイピングを明示的に禁止しています。責任あるツール(Thunderbitを含む)は、セッション文脈を尊重するブラウザベースのスクレイピングに対応していますが、大規模ジョブの前にはサイトのrobots.txtを確認すべきです。
利用規約: 社内調査のためにメタデータ(タイトル、日付、URL)を抽出するのと、著作権のある全文記事を再公開するのとでは、リスクが大きく違います。前者は一般に低リスクですが、後者は実際の法的リスクを伴う可能性があります。最近のやのような事例が示す通り、法的環境はまだ変化の途中です。
ベストプラクティス: 公式APIがあるなら使いましょう(GoogleニュースRSS、Newsdata.io、Newscatcher)。キャッシュは適切に扱い、リクエストにはレート制限をかけ、ペイウォールは絶対に回避しないでください。この一覧のツールの中には、Thunderbit、ScraperAPI、Bright Dataのように、レート制限や倫理的なスクレイピング機能を内蔵しているものもあり、適切な運用を助けてくれます。
この記事は情報提供を目的としており、法的助言ではありません。エンタープライズ規模でスクレイピングを行う場合は、法務チームに相談してください。
Thunderbitはあなたのニューススクレイピング業務にどう組み込めるか
私たちのチームがThunderbitを作っているので、ニューススクレイピングでの強みと限界は誰よりもよく知っています。実際の流れはこんな感じです。
ビジネスユーザーの典型的なワークフローは次のとおりです。
- ニュースページを開く(Googleニュースの結果、媒体のトップページ、トピック検索ページなど)をChromeで表示します。
- Thunderbit拡張機能をクリックして、AIで項目を提案を押します。Thunderbitがページを読み取り、見出し、日付、配信元、URL、スニペット、画像などの列を提案します。
- 必要なら列を調整します。感情分類が欲しければ、フィールドAIプロンプトで「感情をポジティブ、ニュートラル、ネガティブに分類」といった列を追加します。特定カテゴリの記事だけ欲しければ、フィルタ用プロンプトを追加します。
- スクレイプをクリックします。ブラウザモード(自分のセッションを使うので、クラウドIPをブロックするサイトに向いています)か、クラウドモード(速く、最大50ページを一度に処理可能)を選びます。
- サブページをスクレイプして、各記事URLを訪問し、本文、著者、公開日、画像を抽出します。
- エクスポートして、Excel、CSV、、Airtable、Notionへ出力します。
継続監視には、定期スクレイパーで自然言語の間隔(たとえば「平日毎日午前8時」)を使って日次・週次の実行を設定できます。また、Thunderbitはに対応しているので、国際ニュースの監視も簡単です。
Thunderbitがやや不向きなのは、できるだけ低い単価で月数百万記事を扱うようなケースです。その場合は、Bright DataやWebz.ioのようなエンタープライズAPIのほうが費用対効果に優れます。また、エンティティ抽出、クラスタリング、重複排除といった深いNLP拡張がAPIレスポンスに最初から組み込まれている必要があるなら、Newscatcherがその用途に特化しています。
Thunderbitはから無料で試せます。クレジットカードは不要です。
適切なニューススクレイパーの選び方
15個すべてを試してまとめた、私の早見表です。
- 非技術系のビジネスユーザーで、毎日のニュースデータが欲しい? Thunderbitから始めましょう。2クリック、コード不要、レイアウト変更もAIが吸収します。
- 監視パイプラインを作る開発者? SERPデータならSerpApiかScrapingdog。生HTMLとボット対策の両方が欲しいならScraperAPIかScrapingBee。
- 規模と信頼性が必要なエンタープライズチーム? Bright DataかOxylabs。
- 何千ものソースにまたがるブランド言及を追いたいPRチーム? NewscatcherかNewsdata.io。
- テキストコーパスを作る研究者? Pythonに慣れているならNewspaper4k、そうでなければThunderbitのサブページスクレイピング。
- RAGパイプラインへ入力するAIエンジニア? Thunderbit APIかWebz.ioで、きれいで構造化された記事本文を取得。
- 予算が厳しい? APIならScrapingdog、ノーコードならThunderbitの無料枠、オープンソースならNewspaper4k。
適切なツールは、保守にどれだけ時間を割けるか、予算、技術レベルで決まります。迷うなら、まずは無料枠から始めてみてください。ほとんどのツールには無料枠があり、実際の運用に合うかを確かめられます。
ほかの選択肢や比較を見たいなら、の総まとめで、より広い選択肢を紹介しています。また、ツールを選ぶ前にを理解したいなら、そのガイドがよい出発点になります。
結論
2026年のニューススクレイピングは、すでに「解ける問題」です。自分の状況に合ったツールを選べば、データは流れ始めます。万人向けのおすすめはもうありません。SERP APIは見出しには強いですが、記事本文は取れません。専用ニュースAPIは構造化メタデータに優れていますが、任意URLのスクレイピングはできません。ThunderbitのようなノーコードAIツールは柔軟性と低い保守負担を提供し、オープンソースライブラリは週末を差し出す代わりにコントロールを与えてくれます。
私の率直なおすすめは、見出しが必要なのか、全文が必要なのか、拡張されたメタデータが必要なのかを先に決めることです。そのうえで、維持できる保守レベルと予算に合わせて選んでください。そして、コードを一行も書かずに、現代的なAI適応型ニューススクレイピングがどう動くのか見てみたいなら、。数クリックでここまでできるのかと、きっと驚くはずです。
スクレイピングを楽しんでください。記事本文がいつもクリーンで、セレクタが壊れず、エクスポートがちゃんと正しいスプレッドシートに入りますように。
FAQ
1. 非技術者に最適なニューススクレイパーは?
非技術者にはThunderbitが最有力です。AIベースの2クリックワークフローで、コーディングもCSSセレクタも不要です。AIが自動でページ構造を読み取り、抽出項目を提案し、レイアウト変更にも適応するため、保守はほぼ必要ありません。Google Sheets、Airtable、Notionへの直接エクスポートにも対応しています。
2. ニューススクレイパーで全文を取れますか? それとも見出しだけですか?
ツールによります。SerpApi、Scrapingdog、HasDataのようなSERP APIは、見出しとスニペットのみを返します。Newsdata.ioやWebz.ioのような専用ニュースAPIは、有料プランで全文を返します。Thunderbitのようなノーコードツールは、サブページスクレイピングで全文を抽出できますし、Newspaper4kはPythonでクリーンな記事抽出を行うために作られています。導入前に、そのツールが生HTML、スニペット、クリーンな本文のどれを返すのかは必ず確認してください。
3. ニューススクレイパーは、サイトのレイアウトが変わると壊れますか?
セレクタベースのツール(ParseHub、Octoparse、Newspaper4k、独自のScrapyパイプライン)は、ニュースサイトがレイアウトを更新すると頻繁に壊れます。しかもニュースサイトはよく更新します。ThunderbitのようなAI適応型ツールは、毎回ページ構造を読み直すため、レイアウト変更でワークフローが壊れません。管理型API(SerpApi、Newsdata.io、Newscatcher)は、変更を提供側で吸収します。保守が心配なら、比較表で🟢 低に分類されているツールを優先してください。
4. 大規模にニュースをスクレイプする一番安い方法は?
APIベースでは、Scrapingdogが最も低いリクエスト単価です(1,000件あたり約0.10ドルから)。ノーコードでは、Thunderbitの無料枠で小規模プロジェクトをカバーでき、有料プランは月約9ドルからです。オープンソースではNewspaper4kが無料ですが、開発者の時間とサーバー費用は忘れずに見積もってください。積み上がると意外と大きくなります。
5. ニュースサイトをスクレイプするのは合法ですか?
公開データを社内調査のためにスクレイプするのは一般に低リスクですが、著作権のある全文記事を再公開すると法的リスクが生じる可能性があります。スクレイプ前には必ずサイトのrobots.txtと利用規約を確認してください。可能なら公式APIを使い、レート制限を尊重し、ペイウォールは回避しないでください。hiQ対LinkedInやMeta対Bright Dataのような最近の事例が示す通り、法的環境はまだ動いています。エンタープライズ規模で行う場合は、法務チームに相談してください。
さらに詳しく