

インターネット上のトラフィックのほぼ半分はいまやボットが占めています。その大半は、リンク・データ・URLを大規模に収集しているものです。もしまだ手作業でやっているなら、確実に後れを取っています。
今回は、AI搭載のChrome拡張からPythonライブラリまで、12種類のリンク抽出ツールを実際に試し、何千件ものURLを素早く取得したい場面で本当に使えるのはどれかを検証しました。
結論からお伝えします。
リンク抽出ツールが重要な理由
正直に言って、Web上にはデータがあふれています。企業はその混沌を、すぐに使えるインサイトへ変えるために競争しています。リンク抽出ツール や URL抽出ツール は、いまや次のような目的を持つチームにとって欠かせない存在です。
- リード獲得: 営業チームは、ディレクトリやLinkedInから企業プロフィールのリンクを数分で集め、そのURLを連絡先情報の抽出ツールに渡せます。もう、延々とクリックし続ける必要はありません。
- コンテンツ収集とSEO強化: マーケティング担当者は、ブログ内の全記事URLを集めたり、競合の被リンクを追跡したり、サイト構造を点検してリンク切れを洗い出したりできます。
- 競合監視と市場調査: オペレーションチームは、新商品ページ、価格ページ、プレスリリースへのリンクを自動収集し、手間をかけずに競合の動きを追えます。
- 業務の自動化と時間削減: 現代のリンクスクレイパーは、大量のURL処理、サブページの巡回、CSV・Excel・Google Sheets・Notionなどへの構造化エクスポートに対応しています。つまり、コピペ地獄や、ぐちゃぐちゃなテキストファイルの整理から解放されるということです。
毎日、何十億ものWebページがクロールされている ことを考えると、手作業で対応するのは現実的ではありません。優れたリンク抽出ツールは、疲れ知らずで、リンクを見落とさず、休憩も要求しない超優秀なアシスタントのようなものです。
最適なリンク抽出ツールの選び方
選択肢が多すぎると、どのリンク抽出ツールを選ぶべきか、まるでテック系カンファレンスでのスピードデートのように感じるかもしれません。誰もが「これが最適」と言いますが、本当に役立つものは一部だけです。そこで、上位12ツールを次の観点で絞り込みました。
- 使いやすさ: 正規表現の博士号がなくても、非エンジニアが使えるか。ノーコード/ローコードの製品は高評価にしました。
- 一括処理・多層スクレイピング: 何百ものURLをまとめて扱えるか。サブページを巡回し、リンクを自動で辿れるか。
- エクスポートと連携: CSV、Excel、Google Sheets、Notion、Airtable、APIなどに出力できるか。手作業が少ないほど高評価です。
- 利用者タイプと柔軟性: ビジネスユーザー向けか、分析担当者向けか、開発者向けか。万人向けのものもあれば、用途が限定されるものもあります。
- 高度な機能: AIによる認識、スケジューリング、クラウドでの拡張、データクリーニング、よく使うサイト向けテンプレートなど。
- 価格と拡張性: 無料枠、従量課金、エンタープライズ向けなど、費用に見合う価値があるかを確認しました。
ブラウザ拡張からエンタープライズ向けプラットフォームまで幅広く紹介しているので、ひとり起業家でもFortune 500のデータチームでも、きっと合うツールが見つかるはずです。
Thunderbit: ビジネスユーザー向けで最も賢いリンク抽出ツール
まず最初に、最有力候補から紹介します。Thunderbit は、リンク抽出における私の第一推奨です。単に自分が開発に関わったからではありません。Thunderbit は、結果を素早く出したいビジネスユーザー向けに作られたAI搭載のWebスクレイパーChrome拡張機能です。
Thunderbit の何が優れているのでしょうか。まるで、ちゃんと話を聞いてくれるAIアシスタントを雇ったような感覚です。「このページから商品リンクと価格を全部取って」と自然言語で伝えるだけで、あとはThunderbit のAIが処理してくれます。セレクターをいじったり、スクリプトを書いたりする必要はありません。
それだけでは終わりません。
- 大量URLに対応: 1件のURLでも、何百件ものリストでも、そのまま一括で処理できます。
- サブページ巡回: 一覧ページからリンクを抽出し、各詳細ページまで辿って、さらにURLを取りたいですか? Thunderbit の多層スクレイピングで対応できます。
- 構造化エクスポート: 抽出したリンクは、項目名の変更、分類、Google Sheets・Notion・Airtable・Excel・CSVへの直接出力が可能です。後処理のストレスはありません。
AIであらゆるWebサイトからリンクを抽出 Get Started Free
Thunderbit は、営業チーム、不動産エージェント、個人運営のEC事業者まで、世界中で3万人以上に利用されています。しかも無料プランもあり(6ページまで、試用ブーストで10ページまで)、リスクなく試せます。
Thunderbit の注目機能
Thunderbit を特別な存在にしているポイントを詳しく見ていきましょう。
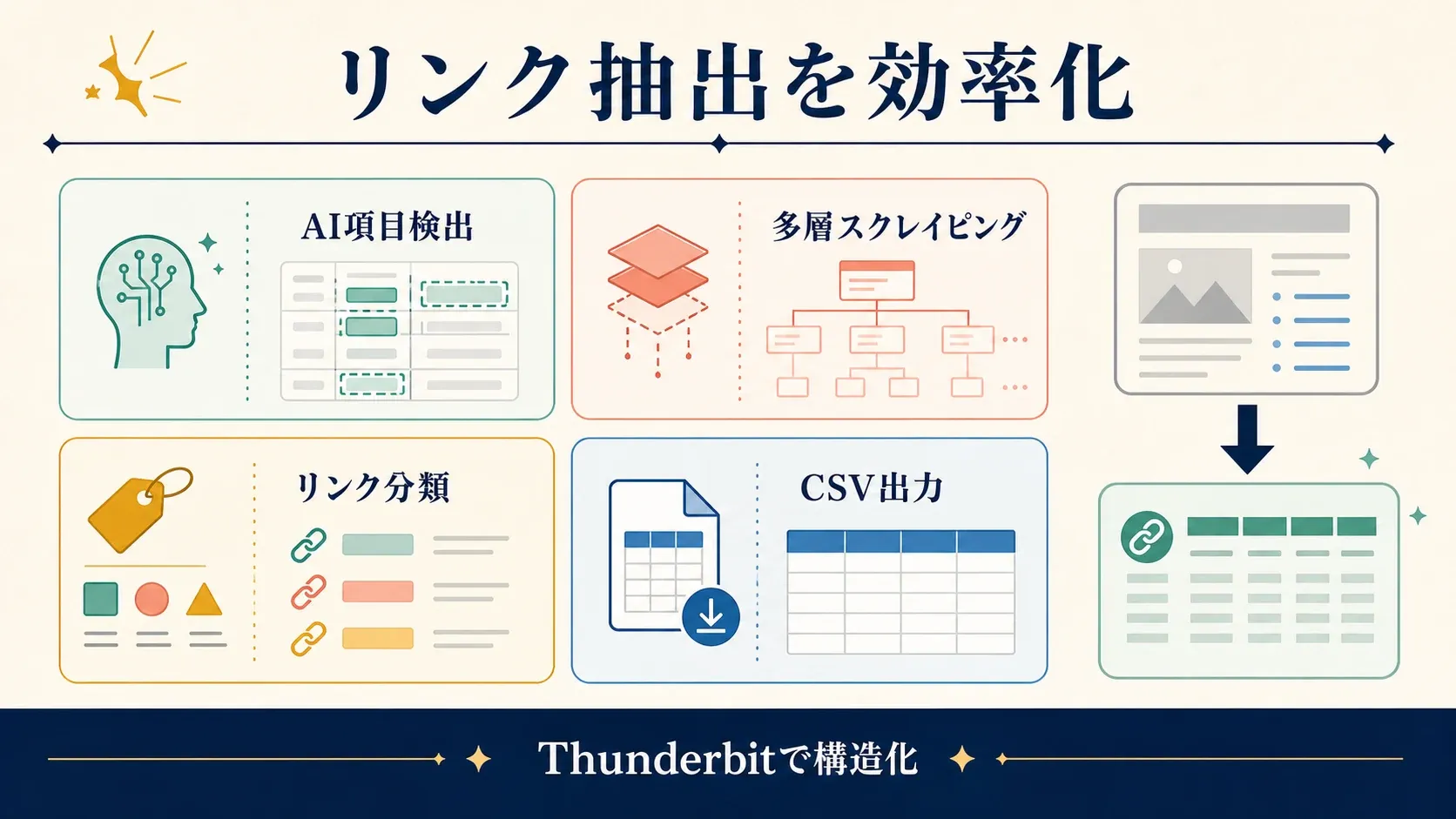
- AIによる項目自動検出: 「AI Suggest Fields」をクリックするだけで、Thunderbit がページ内容を読み取り、「商品リンク」「PDF URL」「連絡先メール」などの列を提案し、各項目の抽出プロンプトまで作成します。
- 多層スクレイピング: メインページからサブページ(商品詳細ページやPDFダウンロードなど)へ辿り、さらにリンクを取得して、すべてを1つの表にまとめられます。
- 一括リンク抽出: 1ページでも1000ページでも、インポートと一括抽出をスムーズに処理できます。
- 業務フローへの直接連携: 結果は Google Sheets、Notion、Airtable にエクスポート、または CSV/Excel でダウンロード可能。チームが必要とする場所に、そのままデータを届けられます。
- AIによるデータ整形・拡張: Thunderbit は抽出しながら翻訳、分類、重複除去、さらにはデータ補完まで行えます。生データの山ではなく、すぐ使える結果が手に入ります。
- クラウド実行+ローカル実行+スケジュール設定: 高速処理ならクラウド、ログインが必要なサイトならブラウザ上で実行できます。定期ジョブを設定して、常に最新データを保てます。
- 保守いらず: Thunderbit のAIはサイト変更に適応するため、壊れたスクレイパーを直す時間を減らし、成果を得る時間を増やせます。
Octoparse: 誰でも使いやすいノーコードリンクスクレイパー
Octoparse は、ノーコードスクレイピング界の定番です。Windows/Mac対応のデスクトップアプリで、視覚的なポイント&クリック操作が中心。ページを開いて、取りたいリンクをクリックするだけで、残りはOctoparse が処理します。
- 初心者に最適: コーディングは不要。クリックして抽出するだけです。
- ページネーションと動的コンテンツに対応: 「次へ」ボタンのクリック、スクロール、サイトへのログインにも対応しています。
- クラウドスクレイピングとスケジューリング: 有料プランではクラウド実行と定期実行が使えます。
- 出力形式が豊富: CSV、Excel、JSON でダウンロード、またはデータベースへ送信できます。
無料プランは小規模用途には十分寛大で、最大10タスク、月50,000行まで使えます。ただし、より重い用途では有料プランが必要で、料金は月額約75ドルからです。
Apify: 柔軟なワークフロー向けURL抽出ツール
Apify は、Webスクレイピングのスイスアーミーナイフのような存在です。あらかじめ用意された「actors」(スクレイピングツール)のマーケットプレイスに加え、JavaScriptやPythonで自分のスクリプトを作ることもできます。
- 既製品もカスタムも可能: コミュニティ製 actor を一般的な用途に使うことも、自分用のワークフローを構築することもできます。
- 一括・定期スクレイピング: URLをまとめて投入し、並列で実行し、定期的に再取得できます。
- APIファースト: JSON、CSV、Excel、Google Sheets に出力でき、データパイプラインへ組み込めます。
- 従量課金: 毎月の無料クレジットの後は、利用量に応じて課金されます。
Apify は、柔軟性と拡張性を重視する準技術者チームや開発者に最適です。
Bright Data URL Scraper: エンタープライズ向けの本格リンク抽出
Bright Data は、大規模スクレイピングを必要とする企業向けに設計されています。Data Collector には、高ボリューム処理向けの既定URLスクレイパーが用意されています。
- 超大規模対応: 何千、何百万ページでも処理可能で、ブロック回避のための堅牢なプロキシ基盤を備えています。
- テンプレートが豊富: EC、SNS、不動産など向けの完成済みスクレイパーがあります。
- エンタープライズ機能: コンプライアンス対応、専門サポート、高度なブロック回避機能。
- 価格: 10万ページ読み込みで約350ドルから。完全に大企業向けです。
スタートアップにはやや大げさかもしれませんが、ミッションクリティカルな大量スクレイピングには非常に強力です。
WebHarvy: クリック操作で使えるビジュアルリンク抽出ツール
WebHarvy は、内蔵ブラウザ上でリンクをクリックするだけで抽出できる、Windows向けデスクトップアプリです。
- とにかく簡単: リンクをクリックすると、WebHarvy が同様の要素をまとめて抽出対象としてハイライトします。
- 正規表現に対応: よくある用途向けのパターンが組み込まれており、コーディングは不要です。
- Excel、CSV、JSON、XML、SQL に出力: おなじみの形式でデータが欲しいビジネスユーザーに向いています。
- 買い切りライセンス: 一度購入すれば、ずっと使えます。
小規模事業者、研究者、あるいはコードを書かずに素早くリンクを取得したい人にぴったりです。
Web Scraper(Chrome拡張): ブラウザで手早くリンクを抽出
Web Scraper Chrome Extension は、ブラウザをそのままスクレイパーに変える無料のオープンソースツールです。
- サイトマップを定義: どう巡回し、何を抽出するかを指定できます。
- ページネーションと多層クロールに対応: カテゴリ、サブカテゴリ、詳細ページまで巡回可能です。
- CSV/XLSX に出力: ブラウザから直接データをダウンロードできます。
- コミュニティテンプレート: 人気サイト向けの共有サイトマップが豊富です。
一回限りの作業や、予算が限られている学生・小規模チームに最適です。
ScraperAPI: 開発者向けのスケーラブルなリンクスクレイパー
ScraperAPI は、プロキシ、ブロック、CAPTCHA を気にせず、大規模にWebページを取得したい開発者向けです。
- API駆動: URLを送ると、HTML または抽出済みデータが返ってきます。
- 大規模処理と対ボット対策に対応: プロキシローテーション、JavaScriptレンダリング、CAPTCHA解決が標準搭載です。
- コードに組み込みやすい: Python、Node.js、その他任意の言語で使えます。
- 価格: 約1000回のAPI呼び出しが使える無料枠の後、リクエスト単位で課金されます。
独自クローラーや、大規模でも速度と安定性が必要な場合に最適です。
ParseHub: 高度な選択操作ができるビジュアルリンクスクレイパー
ParseHub は、Windows、Mac、Linux 対応のデスクトップアプリで、視覚的にスクレイピングプロジェクトを作成できます。
- 高度な選択とナビゲーション: クリック、ループ、条件分岐を使ってリンクを抽出でき、動的要素や非表示要素にも対応します。
- ネストされたページに対応: カテゴリから詳細ページへ進み、さらにリンクを抽出できます。
- CSV、Excel、JSON に出力: 有料プランではクラウド実行とAPI利用が可能です。
- 無料プランあり: 5プロジェクト、1回の実行につき最大200ページまで対応。
ParseHub は、コードを書かずにパワーを求めるマーケターや研究者に人気です。
Scrapy: 開発者向けのPythonリンク抽出ツール
Scrapy は、Python開発者が完全な制御を求めるときの定番です。
- コードファースト: 独自のスパイダーを作成し、あらゆる規模でリンクを巡回・抽出できます。
- 分散クロールに対応: 効率的で非同期、かつ高いカスタマイズ性を持ちます。
- CSV、JSON、XML、データベースに出力: 出力先を自由に制御できます。
- オープンソースで無料: ただし、実行環境は自分で管理する必要があります。
Pythonに慣れているなら、Scrapy は非常に強力です。
Diffbot: 構造化データ向けのAI搭載リンクスクレイパー
Diffbot は、Webスクレイピング界の「AI脳」のような存在です。ページを解析し、リンクを含む構造化データを自動で返してくれます。手作業での設定は不要です。
- コンテンツを自動認識: URLを渡すだけで、記事、商品、リンクなどの構造化データが返ってきます。
- Crawlbot と Knowledge Graph: サイト全体をクロールすることも、巨大なWebインデックスを検索することもできます。
- API駆動: BIツールやデータパイプラインに統合できます。
- エンタープライズ価格: 月額約299ドルからですが、価格相応の価値があります。
スクレイパーの管理なしで、きれいに整った構造化データが欲しい企業に最適です。
Cheerio: Node.js向けの軽量リンクスクレイパー
Cheerio は、Node.js向けの高速な jQuery ライクHTMLパーサーです。
- とても高速: HTMLを数ミリ秒で解析します。
- なじみやすい構文: jQuery を知っていれば、Cheerio もすぐ使えます。
- 静的ページに最適: JavaScriptはレンダリングしませんが、サーバーサイド生成コンテンツにはぴったりです。
- オープンソースで無料: リクエストには axios や fetch と組み合わせて使えます。
速度とシンプルさを重視する、自作スクリプト開発者に向いています。
Puppeteer: 高度なリンク抽出のためのブラウザ自動化
Puppeteer は、ヘッドレスモードでChromeを操作するためのNode.jsライブラリです。
- 完全なブラウザ自動化: ページ読み込み、クリック、スクロール、操作を人間のように行えます。
- 動的コンテンツやログインに対応: JavaScriptが多いサイトや複雑なワークフローに最適です。
- 細かな制御が可能: 要素の待機、スクリーンショット撮影、通信の傍受などができます。
- オープンソースで無料: ただし、リソース消費が大きく、軽量ツールより遅めです。
基本的なスクレイパーでは太刀打ちできないサイトからリンクを抽出したいときに使いましょう。
一目でわかる比較: どのリンク抽出ツールが自分に合うか?
12ツールをざっと比較すると、次のようになります。
| ツール | 最適な用途 | 一括処理・サブページ対応 | 出力形式 | 価格 |
|---|---|---|---|---|
| Thunderbit | 非エンジニア、ビジネス | はい(AI、多層対応) | Excel、CSV、Sheets、Notion、Airtable | 無料トライアル、約$9/月〜 |
| Octoparse | ノーコード利用者、分析担当者 | はい | CSV、Excel、JSON、クラウドストレージ | 無料枠、約$75/月〜 |
| Apify | 準技術者、開発者 | はい | CSV、JSON、API経由でSheets | 無料クレジット、従量課金 |
| Bright Data | エンタープライズ | はい(大規模) | CSV、JSON、NDJSON(API経由) | 約$350/10万ページ |
| WebHarvy | 非エンジニア、デスクトップ利用 | はい | Excel、CSV、JSON、XML、SQL | 買い切りライセンス |
| Web Scraper Extension | 誰でも、手早く無料で | はい | CSV、XLSX | 無料、オープンソース |
| ScraperAPI | 開発者、API利用者 | はい | JSON(API経由でHTML取得可) | 無料1kリクエスト、有料プラン |
| ParseHub | 非エンジニア、高機能志向 | はい | CSV、Excel、JSON、API | 5プロジェクトまで無料、有料あり |
| Scrapy | 開発者、Python | はい | CSV、JSON、XML、DB | 無料、オープンソース |
| Diffbot | エンタープライズ、AI | はい(AIクロール) | JSON(API経由の構造化データ) | 約$299/月〜 |
| Cheerio | 開発者、Node.js | はい(カスタムコード) | カスタム(JSONなど) | 無料、オープンソース |
| Puppeteer | 開発者、複雑なサイト | はい(完全自動化) | カスタム(スクリプト出力) | 無料、オープンソース |
事業に合ったリンクスクレイパーの選び方
では、どう選ぶべきでしょうか。私の簡易ガイドはこちらです。
- コーディング不要? Thunderbit、Octoparse、ParseHub、WebHarvy、Web Scraper 拡張機能から始めましょう。
- 独自のワークフローが必要? Apify、ScraperAPI、Cheerio は開発者に向いています。
- エンタープライズ規模? Bright Data や Diffbot が有力です。
- Python または Node.js の開発者? Scrapy(Python)や Cheerio/Puppeteer(Node.js)なら、完全にコントロールできます。
- Google Sheets / Notion へ直接出力したい? Thunderbit が最有力です。
自分の技術レベル、データ量、連携要件に合わせて選びましょう。多くのツールに無料トライアルがあるので、気軽に試して問題ありません。
さらに多くのWebスクレイピングガイドを見る Get Started Free
2026年におけるThunderbitのリンク抽出の独自価値
改めて、Thunderbit が本当に違う理由を整理します。
- AIでシンプル: やりたいことを自然な英語で伝えるだけで、残りはThunderbit のAIが対応します。
- 多層スクレイピング: メインページからリンクを抽出し、サブページへ進み、さらにURLを取得する——この一連の流れを1回で完結できます。
- 一括インポートとバッチ処理: 何百ものURLを貼り付け、まとめて抽出し、構造化データを即座に出力できます。
- ワークフロー連携: Google Sheets、Notion、Airtable に直接エクスポートするか、CSV/Excel でダウンロードできます。
- 保守ゼロ: Thunderbit のAIがサイト変更に適応するため、壊れたスクレイパーを延々と直す必要がありません。
Thunderbit は、「ただデータを取る」ことと「実際に使えるデータを手に入れる」ことの間をつなぐ存在です。昔、手作業のデータ作業に追われていた頃に、こんなツールがあればよかったと本気で思います。
まとめ: より賢くリンクを抽出して、業務効率を上げよう
Webデータは、ビジネス成長の燃料です。そして、適切なリンク抽出ツールはそのエンジンです。リードリスト作成、競合監視、リサーチの自動化など、どんな用途でも、あなたのニーズとスキルに合うツールがここにはあります。
最新のリンク抽出がどんなものか見てみたいなら、Thunderbit の無料トライアルをぜひ試してみてください。数クリックでどれだけのことができるか、きっと驚くはずです。もしThunderbit が完全に合わなくても、このリストの他のツールをいくつか試してみてください。面倒な作業を自動化して、本当に重要なことに集中するには、これ以上ない時代です。
快適なスクレイピングを。あなたのリンクがいつでも整然としていて、構造化され、すぐに使える状態でありますように。Webスクレイピングをさらに深く学びたい方は、Thunderbit Blog で他のガイドやヒントもぜひご覧ください。
Thunderbit リンク抽出を無料で試す Get Started Free
FAQ
1. なぜリンク抽出ツールは重要なのですか?
インターネットトラフィックのほぼ半分がボットによるもので、企業は積極的にデータを収集しています。リンク抽出ツールは、Web上の混乱を実用的なインサイトへ変えるうえで不可欠です。リード獲得、コンテンツ収集、SEO監査、競合監視などを自動化し、大幅な時間と労力を節約できます。
2. Thunderbit が他のリンク抽出ツールと比べて優れている点は何ですか?
Thunderbit はAIでスクレイピングを簡単にします。やりたいことを平易な言葉で伝えるだけで、あとは自動で処理します。大量URL入力、多層スクレイピング、スマートな項目検出、Google Sheets や Notion へのシームレスな出力に対応しています。技術的な手間をかけずに高い成果を求める非エンジニアやビジネスユーザーに最適です。
3. 開発者やカスタムワークフロー向けのリンク抽出ツールはありますか?
はい。Apify、ScraperAPI、Cheerio、Puppeteer、Scrapy などは開発者向けです。スクリプト作成、API連携、複雑なスクレイピング、大規模処理、高度な自動化に必要な柔軟性を備えています。
4. コーディング経験がない人に最適なツールはどれですか?
Thunderbit、Octoparse、ParseHub、WebHarvy、そして Web Scraper Chrome拡張機能は、非技術者に特におすすめです。視覚的なインターフェース、事前作成テンプレート、AI機能により、誰でもリンク抽出を始めやすくなっています。
5. 自分に合うリンク抽出ツールはどう選べばよいですか?
技術スキル、データ量、出力先を基準に考えましょう。非エンジニアなら Thunderbit や Octoparse、開発者なら Scrapy や Puppeteer が向いています。大規模運用なら Bright Data や Diffbot が候補になります。まずは無料トライアルで、自分に合うか確認するのが一番です。




