

ウェブスクレイピングには、どのプログラミング言語を使うべきでしょうか? それは、プロジェクト次第です。しかも、選び方を間違えて、開発者がキレて途中離脱する場面も何度も見てきました。
ウェブスクレイピングソフトウェア市場は、2024年に10億1000万ドル規模に達し、2032年までに2倍以上に拡大すると予測されています 。適切な言語を選べば、結果を早く出せて、保守の手間も減ります。逆に間違えると、壊れたスクレイパーと無駄になった週末が残るだけです。
私は長年、さまざまな自動化ツールを作ってきました。ここでは、スクレイピングで使ってきた7つの言語を、コード例や率直なトレードオフ、そして「そもそもコーディングをやめて Thunderbit を使うべき場面」も含めて紹介します。
ウェブスクレイピングに最適な言語の選び方
ウェブスクレイピングでは、すべてのプログラミング言語が同じではありません。私はいくつかの重要な要素によって、プロジェクトが大成功したり、逆に失敗したりするのを見てきました。
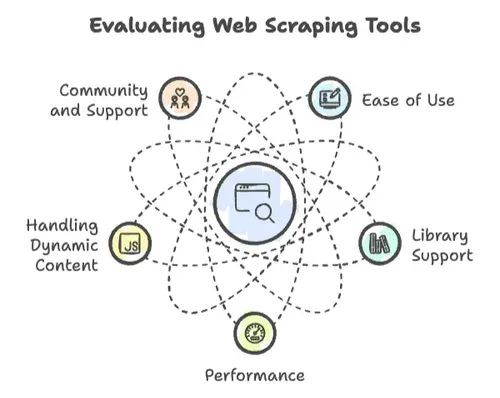
- 使いやすさ: どれくらいすぐ始められるか。構文は親しみやすいか、それとも「Hello, World」を表示するだけでコンピューターサイエンスの博士号が必要か?
- ライブラリの充実度: HTTPリクエスト、HTML解析、動的コンテンツ処理のための強力なライブラリがあるか。それとも車輪の再発明をしているだけか?
- パフォーマンス: 数百万ページのスクレイピングに耐えられるか。それとも数百ページで息切れするか?
- 動的コンテンツへの対応: 現代のサイトはJavaScriptだらけです。言語側が追いつけるか?
- コミュニティとサポート: 壁にぶつかったとき、そして必ずぶつかりますが、助けてくれるコミュニティがあるか?
これらの基準と、夜遅くまで続けた検証の結果、今回取り上げる7つの言語は次のとおりです。
- Python: 初心者にもプロにも定番。
- JavaScript & Node.js: 動的コンテンツの王者。
- Ruby: きれいな構文で、素早く書ける。
- PHP: サーバーサイドの手軽さ。
- C++: とにかく速度が必要なときに。
- Java: エンタープライズ向けで拡張性も高い。
- Go (Golang): 高速で並列処理が得意。
「Shuai、私はそもそもコードを書きたくない」と思っているなら、最後のThunderbitまでぜひ読み進めてください。
Pythonでのウェブスクレイピング:初心者にやさしい万能選手
まずは人気No.1のPythonから。データ系の人が集まる部屋で「ウェブスクレイピングに最適なプログラミング言語は?」と聞くと、Taylor Swiftのライブ会場みたいにPythonの名前が一斉に返ってきます。
なぜPythonなのか?
- 初心者にやさしい構文: Pythonのコードは、ほとんど英語のように読めます。
- 比類ないライブラリの充実: HTML解析なら BeautifulSoup、大規模クロールなら Scrapy、HTTPなら Requests、ブラウザ自動化なら Selenium と、何でも揃っています。
- 巨大なコミュニティ: ウェブスクレイピングだけでも33,000件以上のStack Overflow質問があります。
Pythonのサンプルコード:ページタイトルを取得する
import requests
from bs4 import BeautifulSoup
response = requests.get("<https://example.com>")
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.title.string
print(f"Page title: {title}")
強み:
- 開発と試作が速い。
- チュートリアルやQ&Aが豊富。
- データ分析と相性が良い。Pythonでスクレイピングして、pandasで分析し、matplotlibで可視化できます。
- ライブラリも進化し続けています。Scrapyの2.14リリース(2026年1月)では、フレームワーク全体でネイティブな
async/awaitが使えるようになり、非同期対応はもはやSeleniumやPlaywrightだけの話ではなくなりました。
弱み:
- 大規模処理ではコンパイル言語より遅い。
- 超動的なサイトの扱いはやや面倒になりがち(とはいえSeleniumやPlaywrightが助けになります)。
- 数百万ページを超高速で処理する用途にはあまり向きません。
結論:
スクレイピングが初めてなら、あるいはとにかく素早く進めたいなら、Pythonは文句なしに最適なウェブスクレイピング言語です。なぜPythonがウェブスクレイピングを支配しているのか、詳しくはこちら。
JavaScript & Node.js:動的サイトを手軽にスクレイピング
Pythonが万能ナイフだとすると、JavaScript(とNode.js) は電動ドリルです。特に、現代的でJavaScript依存の強いサイトをスクレイピングするなら最適です。
なぜJavaScript/Node.jsなのか?
- 動的コンテンツにネイティブ対応: ブラウザ上で動くので、ページがReact、Angular、Vueで作られていても、ユーザーが見ている内容をそのまま取得できます。
- 標準で非同期: Node.jsは何百ものリクエストを同時にさばけます。
- Web開発者に馴染み深い: Webサイトを作ったことがあるなら、すでにJavaScriptの基礎は身についています。
主要ライブラリ:
- Playwright: 複数ブラウザ(Chromium、Firefox、WebKit)対応で、自動待機とコンテキストごとのプロキシを備えています。2026年に新しくNodeスクレイパーを始めるなら、これが標準の選択肢です。
- Puppeteer: Chrome DevTools Protocol経由で操作するヘッドレスChrome。Chrome専用の作業や、依存関係を軽くしたい場合には今でも十分有力です。
- Cheerio: 実ブラウザが不要なときに使う、Node向けのjQuery風HTMLパーサーです。
Node.jsのサンプルコード:Puppeteerでページタイトルを取得する
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('<https://example.com>', { waitUntil: 'networkidle2' });
const title = await page.title();
console.log(`Page title: ${title}`);
await browser.close();
})();
強み:
- JavaScriptでレンダリングされるコンテンツをそのまま扱える。
- 無限スクロール、ポップアップ、インタラクティブなサイトに強い。
- 大規模な並列スクレイピングに効率的。
弱み:
- 非同期プログラミングは初心者には少し難しい。
- ヘッドレスブラウザは、同時に増やしすぎるとメモリを消費します。
- Pythonに比べるとデータ分析向けのツールは少なめです。
JavaScript/Node.jsがウェブスクレイピングに最適なのはどんなとき?
対象サイトが動的なとき、またはブラウザ操作を自動化したいときです。動的コンテンツのスクレイピングにNode.jsが向いている理由はこちら。
Ruby:高速なウェブスクレイピングスクリプトに合うきれいな構文
RubyはRailsアプリや美しいコードだけのための言語ではありません。ウェブスクレイピングにも十分使えます。特に、コードが俳句みたいに読めるのが好きな人には向いています。
なぜRubyなのか?
- 読みやすく表現力のある構文: Rubyのスクレイパーは、買い物リストと同じくらい読みやすく書けます。
- 試作に強い: すばやく書けて、修正もしやすい。
- 主要ライブラリ: 解析には Nokogiri、ナビゲーションの自動化には Mechanize が使えます。
Rubyのサンプルコード:ページタイトルを取得する
require 'open-uri'
require 'nokogiri'
html = URI.open("<https://example.com>")
doc = Nokogiri::HTML(html)
title = doc.at('title').text
puts "Page title: #{title}"
強み:
- とにかく読みやすく、簡潔。
- 小規模プロジェクト、単発スクリプト、Rubyをすでに使っている場合に最適。
弱み:
- 大規模処理ではPythonやNode.jsより遅い。
- スクレイピング用ライブラリやコミュニティの厚みはやや薄め。
- JavaScriptが多用されたサイトにはあまり向きません(WatirやSeleniumは使えますが)。
向いている人:
Rubyが好きな人、またはさっとスクリプトを書きたい人には最高です。大規模で動的なスクレイピングには別の選択肢を検討しましょう。
PHP:ウェブデータ抽出のためのサーバーサイドの手軽さ
PHPは初期のWeb時代の遺物のように見えるかもしれませんが、今でも現役です。特に、サーバー上で直接データをスクレイピングしたいなら便利です。
なぜPHPなのか?
- どこでも動く: ほとんどのWebサーバーにはすでにPHPが入っています。
- Webアプリと統合しやすい: スクレイピングして、そのままサイトに表示できます。
- 主要ライブラリ: HTTP用の cURL、リクエスト用の Guzzle、ヘッドレスブラウザ自動化用の Symfony Panther があります。
PHPのサンプルコード:ページタイトルを取得する
<?php
$ch = curl_init("<https://example.com>");
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$html = curl_exec($ch);
curl_close($ch);
$dom = new DOMDocument();
@$dom->loadHTML($html);
$title = $dom->getElementsByTagName("title")->item(0)->nodeValue;
echo "Page title: $title\n";
?>
強み:
- Webサーバーへのデプロイが簡単。
- Webワークフローの一部としてスクレイピングしやすい。
- 単純なサーバーサイド処理なら高速。
弱み:
- 高度なスクレイピング向けのライブラリは限られる。
- 高い並列性や大規模スクレイピングには向いていない。
- JavaScriptが多いサイトの扱いは難しい(Pantherが助けになります)。
向いている人:
すでにPHP中心のスタックを使っている場合や、サイト上に表示するためにデータを取得したい場合には、PHPは現実的な選択です。スクレイピングにおけるPHPとPythonの比較はこちら。
C++:大規模プロジェクト向けの高性能ウェブスクレイピング
C++は、プログラミング言語界のマッスルカーです。生の速度と制御性が必要で、少し手作業が増えても構わないなら、C++は強力です。
なぜC++なのか?
- 圧倒的に速い: CPU集約型の処理では、多くの言語を上回ります。
- 細かい制御ができる: メモリ、スレッド、パフォーマンス調整を自在に扱えます。
- 主要ライブラリ: HTTP用の libcurl、解析用の htmlcxx があります。
C++のサンプルコード:ページタイトルを取得する
#include <curl/curl.h>
#include <iostream>
#include <string>
size_t WriteCallback(void* contents, size_t size, size_t nmemb, void* userp) {
std::string* html = static_cast<std::string*>(userp);
size_t totalSize = size * nmemb;
html->append(static_cast<char*>(contents), totalSize);
return totalSize;
}
int main() {
CURL* curl = curl_easy_init();
std::string html;
if(curl) {
curl_easy_setopt(curl, CURLOPT_URL, "<https://example.com>");
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &html);
CURLcode res = curl_easy_perform(curl);
curl_easy_cleanup(curl);
}
std::size_t startPos = html.find("<title>");
std::size_t endPos = html.find("</title>");
if(startPos != std::string::npos && endPos != std::string::npos) {
startPos += 7;
std::string title = html.substr(startPos, endPos - startPos);
std::cout << "Page title: " << title << std::endl;
} else {
std::cout << "Title tag not found" << std::endl;
}
return 0;
}
強み:
- 大量スクレイピングで比類ない速度。
- 高性能システムにスクレイピングを組み込むのに最適。
弱み:
- 学習曲線が急です(コーヒーを用意しましょう)。
- メモリ管理を自分で行う必要がある。
- 高レベルなライブラリは少なめで、動的コンテンツにはあまり向きません。
向いている人:
数百万ページをスクレイピングしたい場合や、性能が絶対に重要な場合です。そうでなければ、スクレイピングよりデバッグに時間を取られるかもしれません。
Java:エンタープライズ向けのウェブスクレイピングソリューション
Javaはエンタープライズ領域の働き者です。とにかく長く動き、大量のデータを扱い、ゾンビ・アポカリプスが来ても生き残るようなものを作るなら、Javaは頼れる相棒です。
なぜJavaなのか?
- 堅牢で拡張性が高い: 大規模で長期稼働するスクレイピング案件に向いています。
- 強い型付けとエラーハンドリング: 本番環境での想定外が少ない。
- 主要ライブラリ: 解析用の Jsoup、ブラウザ自動化用の Selenium WebDriver、HTTP用の Apache HttpClient があります。
Javaのサンプルコード:ページタイトルを取得する
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class ScrapeTitle {
public static void main(String[] args) throws Exception {
Document doc = Jsoup.connect("<https://example.com>").get();
String title = doc.title();
System.out.println("Page title: " + title);
}
}
強み:
- 高性能で並列処理に強い。
- 大規模で保守しやすいコードベースに最適。
- SeleniumやHtmlUnitを使えば、動的コンテンツにも対応しやすい。
弱み:
- 冗長な構文で、スクリプト言語よりセットアップが多い。
- 単発の小さなスクリプトにはやや大げさ。
向いている人:
エンタープライズ規模のスクレイピング、あるいは非常に堅牢な信頼性と拡張性が必要な場合です。
Go (Golang):高速で並列なウェブスクレイピング
Goは比較的新しい言語ですが、すでに大きな存在感があります。特に、高速で並列なスクレイピングでは力を発揮します。
なぜGoなのか?
- コンパイル済みの速度: C++にかなり近い速さです。
- 標準の並列処理: Goroutineのおかげで、並列スクレイピングがとても楽です。
- 主要ライブラリ: スクレイピング用の Colly、解析用の Goquery があります。
Goのサンプルコード:ページタイトルを取得する
package main
import (
"fmt"
"github.com/gocolly/colly"
)
func main() {
c := colly.NewCollector()
c.OnHTML("title", func(e *colly.HTMLElement) {
fmt.Println("Page title:", e.Text)
})
err := c.Visit("<https://example.com>")
if err != nil {
fmt.Println("Error:", err)
}
}
強み:
- 大規模スクレイピングでも非常に高速で効率的。
- デプロイが簡単(単一バイナリで済む)。
- 並列クロールに強い。
弱み:
- PythonやNode.jsよりコミュニティは小さめ。
- 高レベルなスクレイピングライブラリは少なめ。
- JavaScriptが多いサイトの処理には追加設定が必要(ChromedpやSeleniumなど)。
向いている人:
大規模にスクレイピングしたいとき、またはPythonでは速度が足りないときです。スクレイピングにおけるGoとPythonの性能比較はこちら。
ウェブスクレイピングに最適なプログラミング言語の比較
ここまでをまとめましょう。2026年に最適なウェブスクレイピング言語を選ぶための比較表です。
| 言語/ツール | 使いやすさ | パフォーマンス | ライブラリの充実度 | 動的コンテンツへの対応 | 最適な用途 |
|---|---|---|---|---|---|
| Python | とても高い | 中程度 | 非常に充実 | 良い(Selenium/Playwright) | 汎用、初心者、データ分析 |
| JavaScript/Node.js | 中程度 | 高い | 強い | 非常に良い(ネイティブ) | 動的サイト、非同期スクレイピング、Web開発者 |
| Ruby | 高い | 中程度 | まずまず | 限定的(Watir) | արագなスクリプト、試作 |
| PHP | 中程度 | 中程度 | まあまあ | 限定的(Panther) | サーバーサイド、Webアプリ統合 |
| C++ | 低い | 非常に高い | 限定的 | 非常に限定的 | 性能重視、大規模処理 |
| Java | 中程度 | 高い | 良い | 良い(Selenium/HtmlUnit) | エンタープライズ、長期稼働サービス |
| Go (Golang) | 中程度 | 非常に高い | 増加中 | 中程度(Chromedp) | 高速、並列スクレイピング |
コーディングを飛ばすなら:ノーコードのウェブスクレイピング解決策としてのThunderbit
Thunderbit AI Web Scraper を試す ビジネスユーザー、マーケター、営業チーム向けの、ノーコードでAI搭載のウェブスクレイピング。 Get Started Free
率直に言いましょう。ときには、コーディングもデバッグも「なんでこのセレクタが動かないんだ」も全部なしで、ただデータだけ欲しいことがあります。そんなときに役立つのが Thunderbit です。
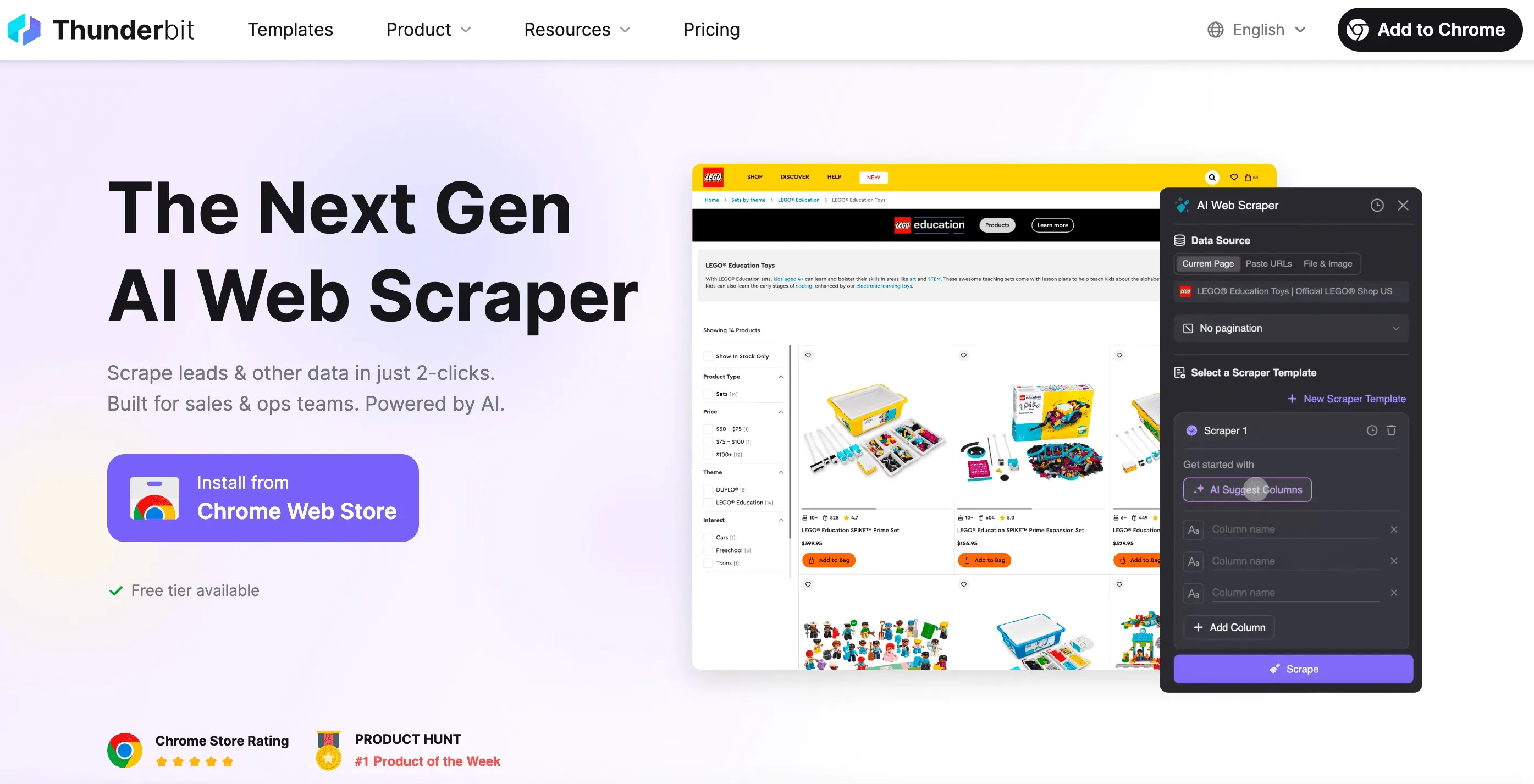
Thunderbitの共同創業者として、私はウェブスクレイピングを出前を頼むくらい簡単にしたいと思ってこのツールを作りました。Thunderbitの特徴は次のとおりです。
- 2クリックで設定完了: 「AIで項目を提案」と「スクレイプ」をクリックするだけ。HTTPリクエスト、プロキシ、ボット対策の小細工は不要です。
- スマートテンプレート: 1つのスクレイパーテンプレートで複数のページ構成に対応できます。サイトが変わるたびにスクレイパーを書き直す必要はありません。
- ブラウザとクラウドの両対応: ブラウザ内でのスクレイピング(ログイン必須サイトに最適)と、クラウドでのスクレイピング(公開データに超高速)を選べます。
- 動的コンテンツに対応: ThunderbitのAIは実際のブラウザを操作するので、無限スクロール、ポップアップ、ログインなども扱えます。
- どこへでもエクスポート: Excel、Google Sheets、Airtable、Notionにダウンロードでき、クリップボードにコピーするだけでもOKです。
- 保守不要: サイトが変わっても、AIの項目提案を再実行するだけ。深夜のデバッグ作業とはもうお別れです。
- スケジュール実行と自動化: cronジョブもサーバー設定もなしで、定期実行を組めます。
- 特化型エクストラクター: メールアドレス、電話番号、画像が必要ですか? それならワンクリックの抽出機能があります。
しかも一番いいのは、コードを1行も知らなくていいことです。Thunderbitは、ビジネスユーザー、マーケター、営業チーム、不動産関係の方など、素早くデータが欲しい人のために作られています。
Thunderbitの動作を見てみたいですか? Chrome拡張機能をダウンロード するか、デモはYouTubeチャンネルをご覧ください。
Thunderbit AI Web Scraper を無料で試す
まとめ:2026年に最適なウェブスクレイピング言語を選ぶ
データスクレイピングとは何か、どうやるのか Get Started Free
2026年のウェブスクレイピングは、これまで以上に手軽で、しかも強力です。自動化の現場で何年も働いてきて、私は次のことを学びました。
- Python は、すぐに始められて、豊富な情報源を使いたいなら、今でも最有力のウェブスクレイピング言語です。
- JavaScript/Node.js は、動的でJavaScript中心のサイトに対して無敵です。
- Ruby と PHP は、短いスクリプトやWeb統合に向いており、すでに使っているなら特に便利です。
- C++ と Go は、速度とスケールが必要なときの味方です。
- Java は、エンタープライズや長期プロジェクトの定番です。
- そして、そもそもコーディングを避けたいなら? Thunderbit が切り札になります。
始める前に、次のことを自問してみてください。
- プロジェクトの規模はどれくらいか?
- 動的コンテンツに対応する必要があるか?
- 自分の技術レベルはどのくらいか?
- 自分は作りたいのか、それともデータが欲しいだけなのか?
上のコード例を試してみるのもいいですし、次のプロジェクトでThunderbitを使ってみるのもおすすめです。もっと深く知りたいなら、Thunderbitブログで、さらに多くのガイド、ヒント、実例ベースのスクレイピング記事をチェックしてください。
楽しくスクレイピングしましょう。データがいつもクリーンで、構造化されていて、ワンクリックで手に入ることを願っています。
追伸:もし深夜2時にウェブスクレイピングの迷路で行き詰まっても、Thunderbitがあることを思い出してください。あるいはコーヒー。もしくは両方です。
Thunderbit AI Web Scraper を今すぐ試す Get Started Free
よくある質問
1. 2026年に最適なウェブスクレイピング言語は何ですか?
読みやすい構文、強力なライブラリ(BeautifulSoup、Scrapy、Seleniumなど)、そして大きなコミュニティのおかげで、Pythonが今でも第一候補です。初心者にもプロにも向いており、特にスクレイピングとデータ分析を組み合わせるときに最適です。
2. JavaScriptが多いサイトをスクレイピングするなら、どの言語が最適ですか?
動的サイトにはJavaScript(Node.js)が最有力です。PuppeteerやPlaywrightのようなツールを使えばブラウザを完全に制御でき、React、Vue、Angularで読み込まれるコンテンツともやり取りできます。
3. ノーコードのウェブスクレイピング手段はありますか?
あります。Thunderbit は、動的コンテンツからスケジュール実行まで対応する、ノーコードのAIウェブスクレイパーです。「AIで項目を提案」をクリックして、すぐにスクレイピングを始められます。営業、マーケティング、オペレーションの各チームが、構造化データを素早く必要とするときに最適です。
4. AIのコーディングエージェントがスクレイパーを書いてくれるなら、まだ言語を選ぶ必要はありますか?
2026年なら、かなり妥当な疑問です。Claude Code、Cursor、OpenAI Codexのようなツールは、1段落の指示からでもScrapyのスパイダー、Playwrightスクリプト、Go + Collyのクローラーを難なく生成できます。そのため、「最初にどの言語を学ぶべきか」という悩みは、2年前より確実に小さくなっています。とはいえ、エージェントは結局どれかの言語でコードを出力しますし、あなた(または引き継ぐ人)はそれを読む、直す、デプロイすることになります。なので、言語選びは今でも重要です。ただし、最初の30行よりも保守性に大きく関わる、という意味で重要性が変わってきています。もしコードに一切触れたくないなら、Thunderbit の出番です。言語選び自体を丸ごと飛ばせます。
さらに詳しく:




