

リンク切れ。孤立ページ。なぜか Google にインデックスされた 2019 年の「test」ページ。サイト運営をしている人なら、思わずため息が出るはずです。
優秀なクローラーがあれば、こうした問題をまとめて洗い出し、サイト全体を見える化して、実際に手を打てるようになります。ただし、多くの人が「ウェブクローラー」と「ウェブスクレイパー」をごちゃ混ぜにしがちです。この 2 つは同じではありません。
今回は、実際のサイトで 10 個の無料クローラーを試しました。SEO監査に強いものもあれば、データ抽出に向いているものもあります。何が良くて、何がいまいちだったのかを紹介します。
ウェブサイトクローラーとは?基本をわかりやすく解説
まず最初に整理しておきましょう。ウェブサイトクローラーは、ウェブスクレイパーとは別物です。どちらも似た文脈で語られますが、役割はまったく違います。クローラーはサイトの地図を作る測量士のような存在です。あちこちのページを巡回し、リンクをたどり、サイト内の構造を把握します。主な役割は 発見 です。URL を見つけ、サイト構造を整理し、コンテンツをインデックス化します。Google などの検索エンジンがボットでやっているのも、SEOツールがサイト診断に使うのもこの動きです(Thunderbit Blog: What Is a Web Crawler?)。
一方で、ウェブスクレイパーはデータを掘り出すための道具です。サイト全体の地図にはあまり興味がなく、欲しいのは商品価格、会社名、レビュー、メールアドレスなど、特定の情報だけです。スクレイパーは、クローラーが見つけたページから必要な項目を抜き出します(Thunderbit Blog: How to Web Crawl a Site?)。
たとえ話で言うと:
- クローラー: スーパーの棚を全部回って、商品一覧を作る人
- スクレイパー: コーヒー売り場にまっすぐ行って、オーガニックブレンドの値段を片っ端からメモする人
なぜこれが大事なのか。たとえば、SEO監査のためにサイト内の全ページを把握したいだけなら、必要なのはクローラーです。競合サイトの商品価格を丸ごと集めたいなら、必要なのはスクレイパーです。理想は、その両方をこなせるツールです。
オンラインのウェブクローラーを使う理由とは?ビジネス上のメリット
では、なぜわざわざウェブクローラーを使うのでしょうか。答えはシンプルで、Web はどんどん大きくなっているからです。実際、54%以上の企業ブランドが専用のクローリングプラットフォームを利用してサイト最適化を行っており、SEOツールの中には 1日あたり70億ページ をクロールするものもあります(martechvibe、martechvibe)。
クローラーでできることは、たとえばこんな感じです。
- SEO監査: リンク切れ、タイトル欠落、重複コンテンツ、孤立ページなどを見つける(SEO.ai)。
- リンクチェック & QA: ユーザーが気づく前に 404 やリダイレクトループを見つける(Screaming Frog)。
- サイトマップ生成: 検索エンジン向けの XML サイトマップを自動で作る(PowerMapper)。
- コンテンツ棚卸し: 全ページ、階層、メタデータを一覧化する。
- コンプライアンス & アクセシビリティ: すべてのページで WCAG、SEO、法令順守を確認する(SiteOne Crawler)。
- パフォーマンス & セキュリティ: 表示が遅いページ、重すぎる画像、セキュリティ上の問題を洗い出す(SiteOne Crawler)。
- AI・分析用データ: クロールしたデータを分析ツールや AI に渡す(Thunderbit Blog: Crawl4AI Review)。
用途と担当者の対応を、ざっくり表にするとこんな感じです。
| 用途 | 向いている人 | メリット / 成果 |
|---|---|---|
| SEO・サイト監査 | マーケター、SEO担当、中小企業オーナー | 技術的な問題を見つけ、構造を最適化し、順位改善につなげる |
| コンテンツ棚卸し & QA | コンテンツ担当、Web管理者 | コンテンツ移行や監査を効率化し、リンク切れや画像欠落を見つける |
| リード獲得(スクレイピング) | 営業、事業開発 | 見込み客獲得を自動化し、CRM に新しいリードを補充する |
| 競合調査 | EC、プロダクトマネージャー | 競合価格、新商品、在庫変動を追跡する |
| サイトマップ・構造の複製 | 開発者、DevOps、コンサルタント | リニューアルやバックアップ用にサイト構造を複製する |
| コンテンツ収集 | 研究者、メディア、アナリスト | 複数サイトからデータを集め、分析やトレンド把握に使う |
| 市場調査 | アナリスト、AI学習チーム | 分析や AI モデル学習のために大規模データを集める |
(Thunderbit Blog: How to Web Crawl a Site?)
最適な無料ウェブサイトクローラーツールの選定基準
私は何度も夜更かししながら(コーヒーもかなり飲みながら)、クローラーツールを調べ、ドキュメントを読み、実際にテストクロールを重ねました。チェックしたポイントは以下です。
- 技術力: JavaScript、ログイン、動的コンテンツなど、今どきのサイトに対応できるか
- 使いやすさ: 非エンジニアでも扱えるか、コマンドラインの知識が必要か
- 無料プランの制限: 本当に無料なのか、それともお試し程度なのか
- オンライン利用可否: クラウドツールか、デスクトップアプリか、コードライブラリか
- 独自機能: AI抽出、ビジュアルサイトマップ、イベント駆動クロールなど、何か特別な機能があるか
それぞれを試し、ユーザーレビューを確認し、機能を横並びで比較しました。使っていてノート PC を窓の外に投げたくなるようなツールは、当然ながら候補から外しています。
ひと目でわかる比較表:無料ウェブクローラー10選
| ツール & 種別 | 主な機能 | 最適な用途 | 必要な技術レベル | 無料プランの内容 |
|---|---|---|---|---|
| BrightData(クラウド/API) | 企業向けクロール、プロキシ、JSレンダリング、CAPTCHA解決 | 大規模データ収集 | 多少の技術知識があると便利 | 無料トライアル: 3スクレイパー、各100レコード(合計約300件) |
| Crawlbase(クラウド/API) | APIクロール、アンチボット、プロキシ、JSレンダリング | バックエンドのクロール基盤が必要な開発者 | API連携 | 無料: 7日間で約5,000 APIコール、その後は月1,000回 |
| ScraperAPI(クラウド/API) | プロキシローテーション、JSレンダリング、非同期クロール、既製エンドポイント | 開発者、価格監視、SEOデータ取得 | 導入が簡単 | 無料: 7日間で5,000 APIコール、その後は月1,000回 |
| Diffbot Crawlbot(クラウド) | AIクロール + 抽出、ナレッジグラフ、JSレンダリング | 大規模な構造化データ、AI/ML | API連携 | 無料: 月10,000クレジット(約1万ページ) |
| Screaming Frog(デスクトップ) | SEO監査、リンク/メタ解析、サイトマップ、カスタム抽出 | SEO監査、サイト管理 | デスクトップアプリ、GUI | 無料: 1クロール500 URL、基本機能のみ |
| SiteOne Crawler(デスクトップ) | SEO、パフォーマンス、アクセシビリティ、セキュリティ、オフライン書き出し、Markdown | 開発者、QA、移行、ドキュメント化 | デスクトップ/CLI、GUI | 無料 & オープンソース、GUIレポートは1,000 URLまで(設定可) |
| Crawljax(Java、オープンソース) | JavaScript中心サイト向けのイベント駆動クロール、静的出力 | 開発者、動的WebアプリのQA | Java、CLI/設定 | 無料 & オープンソース、制限なし |
| Apache Nutch(Java、オープンソース) | 分散型、プラグインベース、Hadoop連携、独自検索 | 独自検索エンジン、大規模クロール | Java、コマンドライン | 無料 & オープンソース、必要なのはインフラコストのみ |
| YaCy(Java、オープンソース) | P2Pクロール & 検索、プライバシー、Web/社内サイトのインデックス化 | プライベート検索、分散化 | Java、ブラウザUI | 無料 & オープンソース、制限なし |
| PowerMapper(デスクトップ/SaaS) | ビジュアルサイトマップ、アクセシビリティ、QA、ブラウザ互換性 | 代理店、QA、可視化 | GUI、簡単 | 無料トライアル: 30日、1回のスキャンでデスクトップは100ページ / オンラインは10ページ |
BrightData: エンタープライズ級のクラウドウェブクローラー

BrightData は、ウェブクロール界の“重機”です。巨大なプロキシネットワーク、JavaScript レンダリング、CAPTCHA 解決、カスタムクロール用の IDE を備えたクラウドプラットフォームです。何百もの EC サイトを対象に価格監視をするような大規模データ収集なら、BrightData の基盤はかなり頼りになります(aimultiple.com)。
強み:
- アンチボット対策が厳しいサイトにも強い
- エンタープライズ用途に合わせて拡張しやすい
- よくあるサイト向けのテンプレートがある
弱み:
- 継続的な無料枠はない(試用は 3 スクレイパー、各 100 レコードのみ)
- 単純な監査用途にはやや大げさ
- 非技術者には少し学習コストがある
大規模に Web をクロールしたいなら、BrightData はまるで F1 マシンをレンタルするようなものです。ただし、試乗後も無料だと思わないほうがいいでしょう(BrightData Pricing)。
Crawlbase: 開発者向けの API 主導型無料ウェブクローラー

Crawlbase(旧 ProxyCrawl)は、プログラム経由のクロールに特化しています。URL を API に投げるだけで HTML が返ってきて、裏側ではプロキシ、地域指定、CAPTCHA 処理まで面倒を見てくれます(Capterra)。
強み:
- 成功率が高い(99% 以上)
- JavaScript が多いサイトにも対応
- 自作アプリやワークフローに組み込みやすい
弱み:
- API か SDK の連携が必要
- 無料プランは 7日間で約5,000 APIコール、その後は月1,000回
プロキシ管理なしで、開発者として大規模クロール(必要ならスクレイピングも)をしたいなら、Crawlbase はかなり有力です(Crawlbase Pricing)。
ScraperAPI: 動的サイトのクロールをシンプルにする

ScraperAPI は「とりあえず取ってきてくれる」API です。URL を渡すだけで、プロキシ、ヘッドレスブラウザ、アンチボット対策を処理し、HTML を返してくれます(一部サイトでは構造化データも取得可能)。動的ページとの相性が特に良く、無料枠もかなり太っ腹です(ScraperAPI Pricing)。
強み:
- 開発者にはとにかく簡単(API を叩くだけ)
- CAPTCHA、IP ブロック、JavaScript に対応
- 無料: 7日間で5,000 APIコール、その後は月1,000回
弱み:
- 画面で確認できるクロールレポートはない
- リンクをたどる処理は自分でスクリプトを書く必要がある
コードにすぐ組み込みたいなら、ScraperAPI はかなり迷いにくい選択肢です。
Diffbot Crawlbot: サイト構造を自動で見つけ出す

Diffbot Crawlbot は、ここから一気に賢くなります。ただクロールするだけではなく、AI を使ってページを分類し、記事、商品、イベントなどの構造化データを JSON に抽出します。まるで、読んだ内容をちゃんと理解してくれるロボットのインターンがいるようなものです(Diffbot Free Plan)。
強み:
- 単なるクロールではなく AI による抽出ができる
- JavaScript や動的コンテンツに対応
- 無料: 月10,000クレジット(約1万ページ)
弱み:
- 開発者向け(API 連携が前提)
- 見た目重視の SEO ツールではなく、データプロジェクト向け
特に AI や分析用途で、大量の構造化データが必要なら、Diffbot はかなり強力です。
Screaming Frog: 無料で使えるデスクトップ SEO クローラー

Screaming Frog は、SEO監査の定番デスクトップクローラーです。無料版でも 1 回のスキャンで最大 500 URL までクロールでき、リンク切れ、メタタグ、重複コンテンツ、サイトマップなどを一通り確認できます(Screaming Frog User Guide)。
強み:
- 速くて詳細、SEO業界での信頼も厚い
- コーディング不要。URL を入れて開始するだけ
- 1クロール500 URL まで無料
弱み:
- デスクトップ専用(クラウド版なし)
- JavaScript レンダリングやスケジュール実行などの高度機能は有料ライセンスが必要
SEO に本気なら、Screaming Frog は持っておきたい一本です。ただし、1万ページのサイトを無料でクロールできると思わないほうがいいでしょう。
SiteOne Crawler: 静的サイトの書き出しとドキュメント化

SiteOne Crawler は、技術系の監査に使える万能ツールです。オープンソースで、複数 OS に対応し、クロール・監査だけでなく、サイトを Markdown に書き出してドキュメント化やオフライン利用にも活用できます(SiteOne Crawler)。
強み:
- SEO、パフォーマンス、アクセシビリティ、セキュリティまでカバー
- アーカイブや移行のためにサイトを書き出せる
- 無料 & オープンソースで、利用制限なし
弱み:
- 一部の GUI ツールより技術寄り
- GUI の監査レポートは既定で 1,000 URL まで(変更可)
開発者、QA、コンサルタントで、深く分析したい人、しかもオープンソース好きなら、SiteOne はかなりの掘り出し物です。
Crawljax: 動的ページ向けのオープンソース Java クローラー
Crawljax は専門特化型です。クリックやフォーム入力など、ユーザー操作を再現しながら、JavaScript の多い最新 Web アプリをクロールするために作られています。イベント駆動型で、動的サイトを静的版として出力することもできます(Wikipedia: Crawljax)。
強み:
- SPA や AJAX 多用サイトのクロールに非常に強い
- オープンソースで拡張可能
- 利用制限なし
弱み:
- Java とある程度のプログラミング/設定が必要
- 非技術者向けではない
React や Angular のアプリを、実ユーザーみたいにクロールしたいなら、Crawljax は頼れる相棒です。
Apache Nutch: 大規模分散型ウェブクローラー

Apache Nutch は、オープンソースクローラーの大御所です。大規模・分散クロール向けに設計されていて、自前の検索エンジン構築や、数百万ページのインデックス化に向いています(Martechvibe)。
強み:
- Hadoop と組み合わせれば数十億ページ規模まで拡張可能
- 柔軟な設定と拡張性
- 無料 & オープンソース
弱み:
- 学習コストが高い(Java、コマンドライン、設定ファイル)
- 小規模サイトやライトユーザー向けではない
大規模に Web をクロールしたくて、コマンドライン操作を苦にしないなら、Nutch は有力候補です。
YaCy: 分散型の P2P ウェブクローラー兼検索エンジン
YaCy は、かなりユニークな分散型クローラー兼検索エンジンです。各インスタンスがサイトをクロールしてインデックス化し、P2P ネットワークに参加して他の利用者とインデックスを共有できます(TechRadar: YaCy)。
強み:
- 中央サーバー不要でプライバシー重視
- 社内検索やプライベート検索の構築に向いている
- 無料 & オープンソース
弱み:
- 結果はネットワークのカバレッジに左右される
- ある程度のセットアップが必要(Java、ブラウザUI)
分散化に興味がある人や、自分専用の検索エンジンを作りたい人には、YaCy はかなり面白い選択肢です。
PowerMapper: UX と QA のためのビジュアルサイトマップ生成ツール

PowerMapper は、サイト構造を見える化することに特化しています。サイトをクロールしてインタラクティブなサイトマップを生成し、アクセシビリティ、ブラウザ互換性、SEO の基本項目もチェックできます(Slickplan Review)。
強み:
- 代理店やデザイナーにとって便利なビジュアルサイトマップ
- アクセシビリティとコンプライアンスも確認できる
- GUI がわかりやすく、技術知識がなくても使いやすい
弱み:
- 無料はトライアルのみ(30日、1回のスキャンでデスクトップは100ページ / オンラインは10ページ)
- 本格利用は有料
クライアントにサイトマップを見せたい、あるいはコンプライアンスを確認したいなら、PowerMapper はかなり便利です。
自分に合った無料ウェブクローラーの選び方
選択肢が多いと、何を基準に決めればいいのか迷いますよね。ざっくりいうと、こんな選び方がおすすめです。
- SEO監査向け: Screaming Frog(小規模サイト)、PowerMapper(見える化重視)、SiteOne(深掘り監査)
- 動的Webアプリ向け: Crawljax
- 大規模クロールや独自検索向け: Apache Nutch、YaCy
- API 連携したい開発者向け: Crawlbase、ScraperAPI、Diffbot
- ドキュメント化やアーカイブ向け: SiteOne Crawler
- 試用前提のエンタープライズ向け: BrightData、Diffbot
確認したいポイント:
- 拡張性: 対象サイトやクロール規模はどれくらいか
- 使いやすさ: コードを書きたいのか、クリック操作で済ませたいのか
- データ出力: CSV、JSON、他ツール連携が必要か
- サポート: つまずいたときに頼れるコミュニティやドキュメントがあるか
ウェブクロールとウェブスクレイピングが交わるとき:Thunderbit が賢い理由
AI を使って、あらゆるサイトからデータを抽出 Get Started Free
現実には、ほとんどの人はきれいな地図を作るためだけにサイトをクロールしているわけではありません。最終的に欲しいのは、商品一覧、連絡先、コンテンツ一覧のような構造化データであることが多いはずです。そこで登場するのが Thunderbit です。
Thunderbit は、単なるクローラーでもスクレイパーでもありません。両方を兼ね備えた AI 搭載の Chrome 拡張機能です。仕組みはこんな感じです。
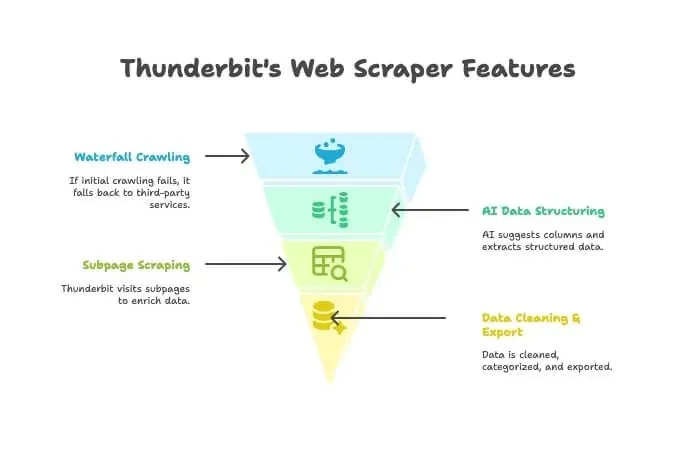
- AI クローラー: Thunderbit が、クローラーのようにサイトを巡回します。
- ウォーターフォール型クロール: Thunderbit 独自エンジンでページを取得できない場合(強いアンチボット対策がある場合など)は、自動的に外部のクロールサービスに切り替えます。手動設定は不要です。
- AI によるデータ構造化: HTML を取得したあと、Thunderbit の AI が適切な列を提案し、名前、価格、メールアドレスなどを選択なしで抽出します。
- サブページ抽出: すべての商品詳細ページから情報を取りたい場合も、自動で各サブページを巡回して表を充実させます。
- データ整理 & エクスポート: 要約、分類、翻訳を行い、Excel、Google Sheets、Airtable、Notion にワンクリックで出力できます。
- ノーコードの手軽さ: ブラウザが使えれば OK。コードもプロキシ設定も不要で、面倒な作業はいりません。
従来のクローラーではなく Thunderbit を使うべき場面は?
- 欲しいのが URL の一覧ではなく、すぐ使えるきれいなスプレッドシートのとき
- クロール、抽出、整理、出力までを一か所で自動化したいとき
- 時間とストレスを節約したいとき
Thunderbit の Chrome 拡張機能をこちらからダウンロードして、多くのビジネスユーザーが乗り換えている理由をぜひ体感してください。
Thunderbit を無料で試す – AI Web Scraper
まとめ:無料ウェブクローラーを最大限活用するには
データスクレイピングとは?やり方も解説 Get Started Free
ウェブクローラーは、ここ数年でかなり進化しました。マーケター、開発者、あるいはサイトを健全に保ちたい人まで、無料または試用可能なツールはしっかりあります。BrightData や Diffbot のようなエンタープライズ向けから、SiteOne や Crawljax のようなオープンソースの名品、PowerMapper のような可視化ツールまで、選択肢はこれまでになく豊富です。
ただし、「このデータがほしい」という状態から「はい、ここにスプレッドシートがあります」という状態までを、もっとスマートに一気通貫で進めたいなら、Thunderbit をぜひ試してみてください。レポート作成だけでなく、成果を求めるビジネスユーザー向けに作られています。
さあ、クロールを始めましょう。ツールをダウンロードしてスキャンを実行すれば、今まで見落としていたものが見えてきます。そして、クロールから実用データへの変換を 2 クリックで済ませたいなら、Thunderbit をチェックしてください。
より詳しい解説や実践ガイドは、Thunderbit Blog からどうぞ。
AI Web Scraper を試す Get Started Free
FAQ
ウェブサイトクローラーとウェブスクレイパーの違いは?
クローラーはサイト内の全ページを見つけて、全体構造を把握します(目次を作るイメージです)。スクレイパーは、そのページから価格、メール、レビューなどの特定データを抜き出します。クローラーは見つける役、スクレイパーは掘り出す役です(Thunderbit Blog: What Is a Web Crawler?)。
非技術者にとって使いやすい無料ウェブクローラーはどれ?
小規模サイトの SEO監査なら Screaming Frog が扱いやすいです。見た目で把握したいなら、PowerMapper もトライアル中は便利です。構造化データが目的で、ノーコードかつブラウザベースで使いたいなら、Thunderbit がいちばん簡単です。
ウェブクローラーをブロックするサイトはありますか?
はい。robots.txt を使ったり、CAPTCHA や IP ブロックなどのアンチボット対策を入れているサイトはあります。ScraperAPI、Crawlbase、Thunderbit(ウォーターフォール型クロール付き)のようなツールなら回避できる場合がありますが、必ずサイトのルールを尊重し、責任あるクロールを心がけてください(BrightData Pricing)。
無料のウェブクローラーにはページ数や機能の制限がありますか?
多くのツールにあります。たとえば Screaming Frog の無料版は 1クロール500 URL まで、PowerMapper のトライアルは 100ページまでです。API 系ツールは月ごとのクレジット制が多いです。SiteOne や Crawljax のようなオープンソースツールは基本的に制限がありませんが、実際には PC の性能が上限になります。
ウェブクローラーの使用は合法で、プライバシー的にも問題ないですか?
一般的に、公開ページをクロールすることは合法です。ただし、必ずサイトの利用規約と robots.txt は確認してください。許可なく非公開データやパスワード保護されたデータをクロールしてはいけませんし、個人データを抽出する場合はプライバシー法にも注意が必要です(Crawlbase Guide)。




