

Web上のデータは、営業・マーケティング・オペレーションの基本入力になっています。まだコピペで集めているなら、もう遅れています。
ただし、「無料」のスクレイピングツールには落とし穴があります。実際には多くが完全無料ではなく、使える機能が大きく制限されたお試し版だったり、本当に必要な機能が有料の壁の向こうに隠されていたりします。
そこで今回は、無料プランでも実務に使えるツールを見極めるため、12製品を検証しました。Google Mapsの店舗情報、ログイン後の動的ページ、PDFまで実際に取得し、ちゃんと使えたものもあれば、午後の時間を無駄にしたものもありました。
ここでは、正直ベースでおすすめ順に紹介していきます。
なぜ無料スクレイパーの重要性がこれまで以上に高まっているのか
はっきり言うと、2026年のWebスクレイピングは、もはやハッカーやデータサイエンティストだけのものではありません。今や多くの企業にとって必須の業務になっており、統計データもそれを裏付けています。Webスクレイピングソフトウェア市場は2024年に10.1億ドルに達し、2032年までには倍以上に拡大すると見込まれています。なぜか? 営業チームから不動産会社まで、あらゆる業種がWebデータを使って競争優位を作っているからです。
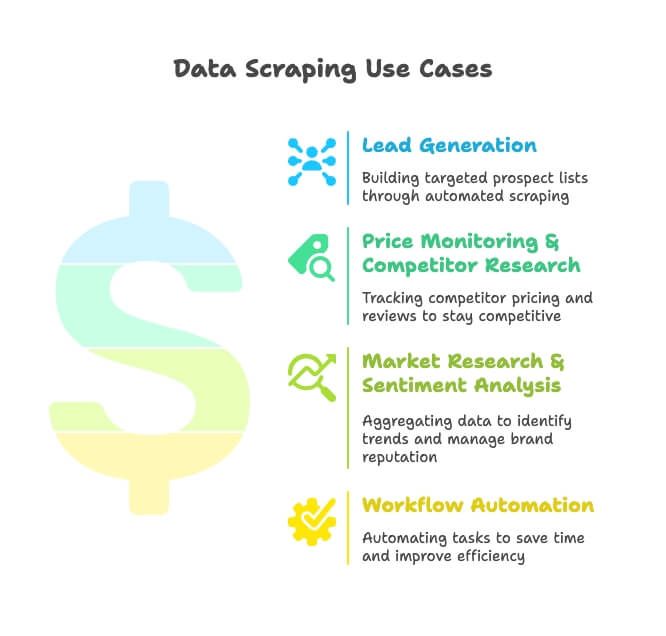
- リード獲得:営業チームはディレクトリ、Google Maps、SNSをスクレイピングして、狙いを絞った見込み客リストを作成します。もう手作業で探す必要はありません。
- 価格モニタリングと競合調査:ECや小売のチームは、競合のSKU、価格、レビューを追跡し、動向を素早く把握します(実際、EC企業の82%がこの目的でスクレイピングを行っています)。
- 市場調査と感情分析:マーケターはレビュー、ニュース、SNS上の会話を集約し、トレンド把握やブランド評価の管理に活用します。
- 業務自動化:運用チームは在庫確認から定期レポートまでを自動化し、毎週何時間も節約しています。
さらに面白いデータとして、AI搭載のWebスクレイパーを使う企業は、手作業と比べて30〜40%の時間を削減しています。これはちょっとした時短ではなく、18時に帰れるか21時まで残るかの違いです。
上位の無料データスクレイパーをどう選んだか
「ベストWebスクレイパー」系の記事には、マーケティング文句の焼き直しが多いですよね。今回は違います。このリストでは、以下の観点を重視しました。
- 無料プランの実用性:無料枠で本当に作業できるのか、それとも単なるお試しなのか。
- 使いやすさ:エンジニアでなくても数分で結果が出るのか、それともRegexの博士号が必要なのか。
- 対応サイトの種類:静的ページ、動的ページ、ページネーション、ログイン必須、PDF、SNSなど、現実のケースに対応できるか。
- データ出力の柔軟性:Excel、Google Sheets、Notion、Airtableに手間なく出力できるか。
- 追加機能:AI抽出、スケジュール実行、テンプレート、後処理、連携機能。
- 利用者との相性:ビジネスユーザー向けか、分析担当向けか、開発者向けか。
さらに、各ツールのドキュメントを確認し、初期設定の流れを実際に試し、無料プランの制限も比較しました。というのも、「無料」が本当に無料とは限らないからです。
ひと目でわかる:12個の無料データスクレイパー比較
用途に合うツールを素早く絞り込めるよう、一覧で比較しました。
| ツール | プラットフォーム | 無料プランの制限 | 最適な用途 | 出力形式 | 主な特徴 |
|---|---|---|---|---|---|
| Thunderbit | Chrome拡張機能 | 月6ページ | ノーコード利用者、ビジネスユーザー | Excel、CSV | AIプロンプト、PDF/画像スクレイピング、サブページ巡回 |
| Browse AI | クラウド | 月50クレジット | ノーコード利用者 | CSV、Sheets | クリック操作でボット作成、スケジュール実行 |
| Octoparse | デスクトップ | 10タスク、月5万行 | ノーコード、準技術者 | CSV、Excel、JSON | 視覚的ワークフロー、動的サイト対応 |
| ParseHub | デスクトップ | 5プロジェクト、1回200ページ | ノーコード、準技術者 | CSV、Excel、JSON | 視覚的操作、動的サイト対応 |
| Webscraper.io | Chrome拡張機能 | ローカル実行は無制限 | ノーコード、簡単な作業向け | CSV、XLSX | サイトマップ方式、コミュニティテンプレート |
| Apify | クラウド | 月5ドル分のクレジット | チーム、準技術者、開発者 | CSV、JSON、Sheets | Actorマーケットプレイス、スケジュール実行、API |
| Scrapy | Pythonライブラリ | 無制限(オープンソース) | 開発者 | CSV、JSON、DB | 完全なコード制御、拡張性が高い |
| Puppeteer | Node.jsライブラリ | 無制限(オープンソース) | 開発者 | 任意(コード実装) | ヘッドレスブラウザ、動的JavaScript対応 |
| Selenium | 多言語対応 | 無制限(オープンソース) | 開発者 | 任意(コード実装) | ブラウザ自動化、複数ブラウザ対応 |
| Zyte | クラウド | スパイダー1つ、1ジョブ1時間、7日保存 | 開発者、運用チーム | CSV、JSON | ホスト型Scrapy、プロキシ管理 |
| SerpAPI | API | 月100検索 | 開発者、アナリスト | JSON | 検索エンジンAPI、ブロック回避 |
| Diffbot | API | 月1万クレジット | 開発者、AIプロジェクト | JSON | AI抽出、ナレッジグラフ |
Thunderbit:AI搭載で使いやすいデータスクレイピングの最有力候補
AIを使ってあらゆるサイトからデータを抽出 Get Started Free
私のリストでThunderbitが1位なのはなぜか、説明します。チームの一員だからという理由ではありません。純粋に、Thunderbitは「話をちゃんと聞いてくれるAIインターン」に最も近い存在だと本気で思っているからです(しかもコーヒーブレイクを要求しません)。
Thunderbitは、よくある「ツールを覚えてからスクレイピングする」タイプではありません。むしろ、優秀なアシスタントに指示を出す感覚に近いです。たとえば「このページから商品名、価格、リンクを全部取って」と伝えるだけで、残りはThunderbitのAIが処理します。XPathもCSSセレクタもRegexの悩みも不要です。さらに、商品詳細ページや会社の連絡先リンクのようなサブページも、ボタンを押すだけで自動巡回して表を拡張できます。
そしてThunderbitの真価は、取得後にこそ発揮されます。要約、翻訳、分類、クリーニングが必要ですか? 内蔵AIの後処理機能が対応します。単なる生データではなく、CRM、スプレッドシート、次のプロジェクトですぐ使える構造化データとして手に入ります。
無料プラン:Thunderbitの無料トライアルでは、PDF、画像、SNSテンプレートも含めて最大6ページまで取得できます(トライアルブーストで10ページまで可能)。ExcelまたはCSVへの出力は無料で使え、メール・電話番号・画像の抽出機能も試せます。大規模な用途では、有料プランでページ数が増え、Google Sheets・Notion・Airtableへの直接出力、定期スクレイピング、Amazon・Google Maps・Instagramなど人気サイト向けの即利用テンプレートが使えるようになります。
Thunderbitの動作を見たい方は、Thunderbit Chrome拡張機能をチェックするか、YouTubeチャンネルでクイックスタート動画をご覧ください。
Thunderbitの注目機能
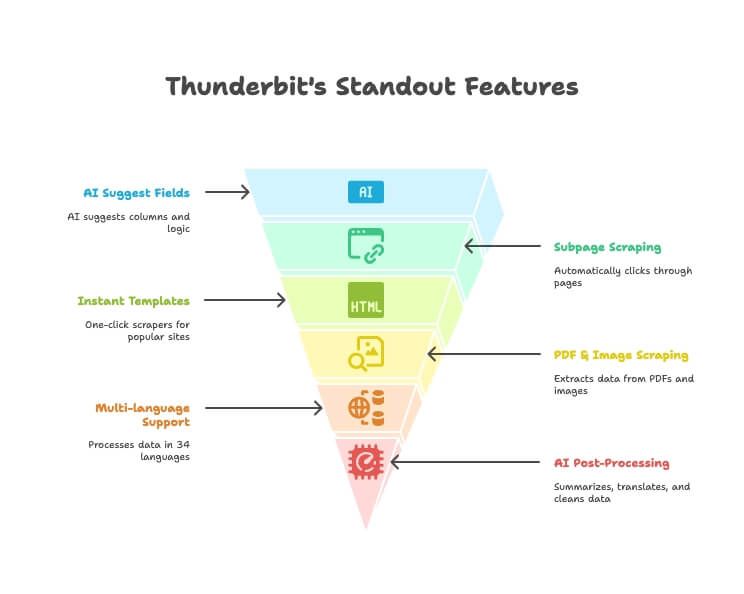
- AIによる項目提案:欲しいデータを説明するだけで、AIが適切な列と抽出ロジックを提案します。
- サブページスクレイピング:詳細ページやリンクを自動で巡回し、メイン表を拡張します。手動設定は不要です。
- 即時テンプレート:Amazon、Google Maps、Instagramなど向けのワンクリックスクレイパー。
- PDF・画像スクレイピング:AIを使ってPDFや画像から表やデータを抽出。追加ツールは不要です。
- 多言語対応:34言語でスクレイピングとデータ処理が可能です。
- 直接エクスポート:データをExcel、Google Sheets、Notion、Airtableへそのまま送信できます(有料プラン)。
- AI後処理:スクレイピングと同時に要約、翻訳、分類、クリーニングができます。
- メール・電話・画像の無料抽出:どのサイトからでも、連絡先情報や画像をワンクリックで取得できます。
Thunderbitは、「データを取るだけ」と「実際に使えるデータを得る」の間にある壁を取り払います。ビジネスユーザーにとって、本物のAIデータアシスタントに最も近いツールです。
残りの12選:無料データスクレイパーを比較レビュー
それでは、他のツールも「誰に向いているか」を軸に見ていきましょう。
ノーコード・ビジネスユーザー向け
Thunderbit
上で紹介した通りです。AI機能と即時テンプレートを備えた、非エンジニア向けの最も入りやすい選択肢です。
Webscraper.io
- プラットフォーム:Chrome拡張機能
- 最適な用途:シンプルな静的サイト。多少の試行錯誤をいとわないノーコードユーザー。
- 主な機能:サイトマップ方式のスクレイピング、ページネーション対応、CSV/XLSX出力。
- 無料プラン:ローカル実行は無制限。ただしクラウド実行とスケジュール実行は不可。手動操作のみ。
- 制限:ログイン、PDF、複雑な動的コンテンツへの標準対応はなし。サポートはコミュニティ中心。
ParseHub
- プラットフォーム:デスクトップアプリ(Windows、Mac、Linux)
- 最適な用途:学習に時間をかけられるノーコード利用者と準技術者。
- 主な機能:視覚的なワークフロービルダー、動的サイト、AJAX、ログイン、ページネーションに対応。
- 無料プラン:公開プロジェクト5件、1回200ページ、手動実行のみ。
- 制限:無料プランではプロジェクトが公開されるため、機密データは要注意。スケジュール実行不可、抽出速度はやや遅め。
Octoparse
- プラットフォーム:デスクトップアプリ(Windows/Mac)、クラウド(有料)
- 最適な用途:パワーと柔軟性を求めるノーコード利用者やアナリスト。
- 主な機能:視覚的なポイント&クリック操作、動的コンテンツ対応、人気サイト向けテンプレート。
- 無料プラン:10タスク、月最大5万行、デスクトップのみ(クラウド・スケジュールなし)。
- 制限:無料枠ではAPI、IPローテーション、スケジュール実行は不可。複雑なサイトでは習熟に時間がかかります。
Browse AI
- プラットフォーム:クラウド
- 最適な用途:シンプルなスクレイピングと監視を自動化したいノーコード利用者。
- 主な機能:ポイント&クリックのロボット記録、スケジュール実行、SheetsやZapierとの連携。
- 無料プラン:月50クレジット、1サイト、最大5ロボット。
- 制限:実行量が少ないため、複雑なサイトでは初期学習が少し必要です。
開発者・技術者向け
Scrapy
- プラットフォーム:Pythonライブラリ(オープンソース)
- 最適な用途:完全な制御と拡張性が欲しい開発者。
- 主な機能:高いカスタマイズ性、大規模クロール対応、ミドルウェア、パイプライン。
- 無料プラン:無制限(オープンソース)。
- 制限:GUIなし。Pythonのコーディングが必要で、非エンジニア向けではありません。
Puppeteer
- プラットフォーム:Node.jsライブラリ(オープンソース)
- 最適な用途:動的でJavaScript依存の強いサイトをスクレイピングしたい開発者。
- 主な機能:ヘッドレスブラウザ自動化、ナビゲーションと抽出を細かく制御可能。
- 無料プラン:無制限(オープンソース)。
- 制限:JavaScriptのコーディングが必要で、GUIはありません。
Selenium
- プラットフォーム:多言語対応(Python、Javaなど)、オープンソース
- 最適な用途:スクレイピングやテストのためにブラウザ操作を自動化したい開発者。
- 主な機能:複数ブラウザ対応、クリック、スクロール、ログイン操作を自動化。
- 無料プラン:無制限(オープンソース)。
- 制限:ヘッドレス系ライブラリより遅め。スクリプト作成が必要です。
Zyte(Scrapy Cloud)
- プラットフォーム:クラウド
- 最適な用途:Scrapyスパイダーを大規模に運用する開発者や運用チーム。
- 主な機能:ホスト型Scrapy、プロキシ管理、ジョブのスケジュール実行。
- 無料プラン:同時実行スパイダー1つ、1ジョブ1時間、データ保存7日間。
- 制限:無料プランでは高度なスケジューリングは不可。Scrapyの知識が必要です。
チーム・エンタープライズ向け
Apify
- プラットフォーム:クラウド
- 最適な用途:既製品または自作スクレイパーを使いたいチーム、準技術者、開発者。
- 主な機能:Actorマーケットプレイス(事前構築ボット)、スケジュール実行、API、各種連携。
- 無料プラン:月5ドル分のクレジット(小規模ジョブには十分)、データ保存7日間。
- 制限:多少の学習コストがあり、利用量はクレジットで上限管理されます。
SerpAPI
- プラットフォーム:API
- 最適な用途:検索エンジンのデータ(Google、Bing、YouTube)が必要な開発者やアナリスト。
- 主な機能:検索API、ブロック回避、構造化JSON出力。
- 無料プラン:月100検索。
- 制限:任意のWebサイトには使えません。API利用専用です。
Diffbot
- プラットフォーム:API
- 最適な用途:大規模な構造化Webデータを必要とする開発者、AI/MLチーム、企業。
- 主な機能:AI抽出、ナレッジグラフ、記事・商品向けAPI。
- 無料プラン:月1万クレジット。
- 制限:API専用で、技術スキルが必要。処理速度にはレート制限があります。
無料プランの制限:各データスクレイパーで「無料」が意味するもの
率直に言えば、「無料」といっても、その意味は「趣味用途なら無制限」から「課金前のお試し」までさまざまです。実際に何が使えるのかを整理すると、こうなります。
| ツール | 月間ページ数/行数 | 出力形式 | スケジュール実行 | APIアクセス | 無料枠の主な制限 |
|---|---|---|---|---|---|
| Thunderbit | 6ページ | Excel、CSV | なし | なし | AI項目提案に制限、無料枠ではSheets/Notionへの直接出力なし |
| Browse AI | 50クレジット | CSV、Sheets | あり | あり | 1サイト、5ロボット、保存期間15日 |
| Octoparse | 5万行 | CSV、Excel、JSON | なし | なし | デスクトップのみ、クラウドなし、スケジュールなし |
| ParseHub | 1回200ページ | CSV、Excel、JSON | なし | なし | 公開プロジェクト5件、速度は遅め |
| Webscraper.io | ローカル実行は無制限 | CSV、XLSX | なし | なし | 手動実行のみ、クラウドなし |
| Apify | 5ドル分のクレジット(少量) | CSV、JSON、Sheets | あり | あり | 保存7日、クレジット上限あり |
| Scrapy | 無制限 | CSV、JSON、DB | なし | N/A | コーディング必須 |
| Puppeteer | 無制限 | 任意(コード実装) | なし | N/A | コーディング必須 |
| Selenium | 無制限 | 任意(コード実装) | なし | N/A | コーディング必須 |
| Zyte | スパイダー1つ、1時間/ジョブ | CSV、JSON | 制限あり | あり | 保存7日、同時実行1件 |
| SerpAPI | 100検索 | JSON | なし | あり | 検索APIのみ |
| Diffbot | 1万クレジット | JSON | なし | あり | API専用、レート制限あり |
結論として、実務で使うなら、Thunderbit、Browse AI、Apifyが、ビジネスユーザーにとって最も使いやすい無料トライアルを提供しています。継続的な運用や大規模スクレイピングでは、すぐに制限に達するため、有料化するか、オープンソースやコードベースの手段に切り替えることになるでしょう。
あなたに最適なデータスクレイパーツールは?(ユーザータイプ別ガイド)
役割と技術レベルに応じて、どれを選ぶべきかを簡単に整理しました。
| ユーザータイプ | 最適なツール(無料) | 理由 |
|---|---|---|
| ノーコード利用者(営業/マーケ) | Thunderbit、Browse AI、Webscraper.io | 習得が早い、ポイント&クリック、AIサポートあり |
| 準技術者(運用/アナリスト) | Octoparse、ParseHub、Apify、Zyte | 高機能で複雑なサイトに対応しやすく、一部スクリプトも可能 |
| 開発者/エンジニア | Scrapy、Puppeteer、Selenium、Diffbot、SerpAPI | 完全制御、無制限、APIファースト |
| チーム/エンタープライズ | Apify、Zyte | 共同作業、スケジューリング、連携機能 |
実際のWebスクレイピングシナリオでの対応力比較
よくある5つのスクレイピングシナリオで、各ツールを比較してみましょう。
| シナリオ | Thunderbit | Browse AI | Octoparse | ParseHub | Webscraper.io | Apify | Scrapy | Puppeteer | Selenium | Zyte | SerpAPI | Diffbot |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ページネーション付き一覧 | 簡単 | 簡単 | 普通 | 普通 | 普通 | 簡単 | 簡単 | 簡単 | 簡単 | 簡単 | N/A | 普通 |
| Google Mapsの店舗情報 | 簡単* | 難しい | 普通 | 普通 | 難しい | 簡単 | 難しい | 難しい | 難しい | 難しい | 簡単 | N/A |
| ログイン必須ページ | 簡単 | 普通 | 普通 | 普通 | 手動 | 普通 | 簡単 | 簡単 | 簡単 | 簡単 | N/A | N/A |
| PDFデータ抽出 | 簡単 | なし | なし | なし | なし | 普通 | 難しい | 難しい | 難しい | 難しい | なし | 限定的 |
| SNSコンテンツ | 簡単* | 一部対応 | 難しい | 難しい | 難しい | 簡単 | 難しい | 難しい | 難しい | 難しい | YouTube | 限定的 |
- ThunderbitとApifyは、Google MapsやSNSのスクレイピング向けに事前構築テンプレート/Actorを用意しているため、非技術者でもかなり簡単に扱えます。
プラグイン vs. デスクトップ vs. クラウド:最も使いやすいWebスクレイパー体験はどれ?
- Chrome拡張機能(Thunderbit、Webscraper.io)
- メリット:すぐ使い始められる、ブラウザ内で動作、セットアップが最小限。
- デメリット:手動操作が中心、サイト変更の影響を受けやすい、自動化は限定的。
- Thunderbitの強み:AIが構造変更、サブページ移動、PDF/画像スクレイピングまで対応するため、従来の拡張機能よりはるかに堅牢です。
- デスクトップアプリ(Octoparse、ParseHub)
- メリット:高機能、視覚的なワークフロー、動的サイトやログインに対応。
- デメリット:学習コストが高め、無料プランではクラウド自動化不可、OS依存。
- クラウドプラットフォーム(Browse AI、Apify、Zyte)
- メリット:スケジューリング、チームでの共同利用、拡張性、連携機能。
- デメリット:無料プランはクレジット制限が多く、初期設定が必要な場合がある。APIの知識が求められることもあります。
- オープンソースライブラリ(Scrapy、Puppeteer、Selenium)
- メリット:無制限、カスタマイズ自在、開発者に最適。
- デメリット:コーディング必須で、ビジネスユーザー向けではありません。
2026年のWebスクレイピングトレンド:現代ツールを分けるもの
2026年のWebスクレイピングは、AI、自動化、連携がキーワードです。新しく加わったポイントは次の通りです。
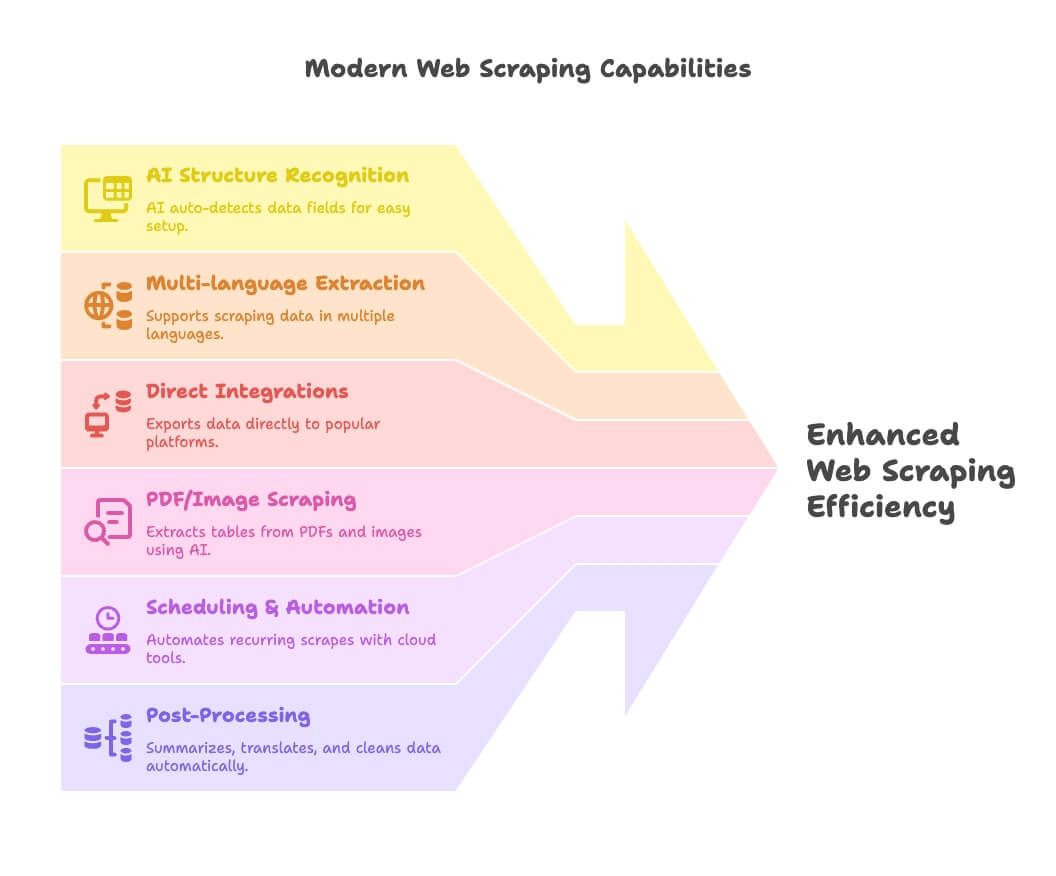
- AIによる構造認識:ThunderbitのようなツールはAIでデータ項目を自動判別するため、ノーコードでも簡単に設定できます。
- 多言語抽出:Thunderbitをはじめ、数十言語でのスクレイピングとデータ処理に対応するツールが増えています。
- 直接連携:取得したデータをGoogle Sheets、Notion、Airtableへそのまま出力でき、CSVの扱いに悩まされません。
- PDF/画像スクレイピング:Thunderbitはこの分野をリードしており、AIでPDFや画像から表を抽出できます。
- スケジューリングと自動化:クラウド型ツール(Apify、Browse AI)なら、定期スクレイピングを設定して放置できます。
- 後処理:スクレイピングと同時に、要約、翻訳、分類、クリーニングまで完了。面倒なスプレッドシート作業を減らせます。
これらのトレンドの最前線にいるのはThunderbit、Apify、SerpAPIですが、誰でもAIスクレイピングを使えるようにした点では、Thunderbitが特に際立っています。
スクレイピングの先へ:データ処理と付加価値機能
重要なのは、データを取ることだけではありません。使える形にすることです。後処理の面で各ツールを比べるとこうなります。
| ツール | クリーニング | 翻訳 | 分類 | 要約 | 備考 |
|---|---|---|---|---|---|
| Thunderbit | あり | あり | あり | あり | AI後処理を標準搭載 |
| Apify | 一部 | 一部 | 一部 | 一部 | 利用するActor次第 |
| Browse AI | なし | なし | なし | なし | 生データのみ |
| Octoparse | 一部 | なし | 一部 | なし | 一部の項目処理のみ |
| ParseHub | 一部 | なし | 一部 | なし | 一部の項目処理のみ |
| Webscraper.io | なし | なし | なし | なし | 生データのみ |
| Scrapy | あり* | あり* | あり* | あり* | 開発者がコードで実装した場合 |
| Puppeteer | あり* | あり* | あり* | あり* | 開発者がコードで実装した場合 |
| Selenium | あり* | あり* | あり* | あり* | 開発者がコードで実装した場合 |
| Zyte | 一部 | なし | 一部 | なし | 一部の自動抽出機能あり |
| SerpAPI | なし | なし | なし | なし | 構造化された検索データのみ |
| Diffbot | あり | あり | あり | あり | AI搭載だがAPI専用 |
- 処理ロジックは開発者が実装する必要があります。
Thunderbitは、非技術者でも生のWebデータをそのまま実用的な構造化インサイトに変えられる、数少ないツールです。しかもすべて1つのワークフローで完結します。
コミュニティ、サポート、学習リソース:すばやく使いこなすために
ドキュメントと導入支援はかなり重要です。各ツールを比べると次のようになります。
| ツール | ドキュメント・チュートリアル | コミュニティ | テンプレート | 学習コスト |
|---|---|---|---|---|
| Thunderbit | 非常に充実 | 拡大中 | あり | とても低い |
| Browse AI | 良い | 良い | あり | 低い |
| Octoparse | 非常に充実 | 大きい | あり | 中程度 |
| ParseHub | 非常に充実 | 大きい | あり | 中程度 |
| Webscraper.io | 良い | フォーラム | あり | 中程度 |
| Apify | 非常に充実 | 大きい | あり | 中〜高 |
| Scrapy | 非常に充実 | 非常に大きい | N/A | 高い |
| Puppeteer | 良い | 大きい | N/A | 高い |
| Selenium | 良い | 非常に大きい | N/A | 高い |
| Zyte | 良い | 大きい | あり | 中〜高 |
| SerpAPI | 良い | 中規模 | N/A | 高い |
| Diffbot | 良い | 中規模 | N/A | 高い |
初心者にとってはThunderbitとBrowse AIが最も始めやすいです。OctoparseとParseHubは資料が充実していますが、慣れるまで少し時間がかかります。Apifyや開発者向けツールは学習コストが高い一方で、ドキュメントはしっかり整っています。
結論:2026年に最適な無料データスクレイパーの選び方
2026年版ベストWebスクレイピングツールを見る Get Started Free
結論をひと言でまとめると、「無料」をうたうデータスクレイパーがすべて同じように使えるわけではありません。選ぶべきツールは、あなたの役割、技術的な得意・不得意、そして実際のスクレイピング要件によって変わります。
- ビジネスユーザーやノーコード派で、できるだけ早くデータを取りたい人、特に扱いが難しいサイト、PDF、画像から取得したい人には、Thunderbit が最適です。AIベースのアプローチ、自然言語プロンプト、後処理機能により、本物のAIデータアシスタントに最も近い存在です。まずはThunderbit Chrome拡張機能を無料で試して、「このデータがほしい」から「はい、スプレッドシートです」までの速さを体感してください。
- 開発者で、無制限かつ自由度の高いスクレイピングが必要なら、Scrapy、Puppeteer、Seleniumのようなオープンソースツールが有力です。
- チームや準技術者向けには、ApifyとZyteが、拡張性と共同作業に優れたソリューションを提供しており、小規模用途なら無料枠も十分です。
どんな業務フローでも、自分のスキルと目的に合ったツールから始めるのが正解です。そして覚えておきたいのは、2026年にはコードが書けなくてもWebデータの力を活用できるということ。必要なのは、適切なアシスタントだけです(そして、ロボットに先を越されても笑える余裕が少しあると理想です)。
さらに深掘りしたい方は、Thunderbit Blog のガイドや比較記事もどうぞ。たとえば以下があります。
AIウェブスクレイパーを試す Get Started Free




