

もしウェブページやスプレッドシート、PDFが山のようにあって「もっとサクッとデータ集められないの?」と感じたことがあるなら、それはあなただけじゃないよ。自分も長年自動化ツールを作ってきて、手作業のコピペにうんざりしてるビジネスチームとたくさん話してきた。2025年の今、世の中には非構造化データが溢れていて、新しく生まれる企業データの8〜9割が非構造化データなんだけど、実際にそれをちゃんと活用できてる会社はほんの一部だけ(Docsumo)。手作業でデータを集めるのは、ただ面倒なだけじゃなくて、コストもかかるしミスも多いし、仕事の効率もガクッと下がるんだよね。

AIであらゆるウェブサイトからデータを抽出 Get Started Free
そこで頼りになるのがデータエクストラクター。営業やオペレーション、EC、リサーチなど、どんな現場でもピッタリのツールを使えば、何時間もかかる作業が一気に短縮できて、しかも精度もアップ。チームは本当に大事な仕事に集中できる。だけど、AI搭載のChrome拡張からノーコードのプラットフォーム、開発者向けのフレームワークまで選択肢が多すぎて、どれが自分に合うのか迷う人も多いはず。そこで2025年注目のデータエクストラクター12選を徹底比較して、それぞれの特徴やおすすめの使い方をまとめてみたよ。
なんでビジネスにデータエクストラクターが必要なの?
現実として、94%の会社が手作業の繰り返し作業に悩んでる(ServiceNow)。しかも、失うのは時間だけじゃない。手作業でデータを集めると、1人あたり月1,500ドルもコストがかかるって言われてる(ResolvePay)。データエクストラクターを使えば、こういう単純作業を自動化できて、
- データ収集の時間を最大77%カット(ServiceNow)
- 業務効率が40%アップ(PerfectDataEntry)
- 処理時間が50%以上短縮(Docsumo)
- 書類データの抽出精度が最大99.9%まで向上(Docsumo)
みたいな効果が期待できる。結果的に、意思決定も早くなるし、データの質も上がる。チームの満足度もグッと上がるよ。リード獲得や競合価格のチェック、BIツールへのデータ連携など、データエクストラクターは「疲れ知らずのデジタルアシスタント」って感じで大活躍してくれる。
最適なデータエクストラクターを選ぶコツ
全部のデータエクストラクターが同じってわけじゃない。自分がツールを選ぶときに大事にしてるポイントはこんな感じ:
- 使いやすさ:エンジニアじゃなくてもすぐ使える?AIやクリックだけでセットアップできる?
- カスタマイズ性・柔軟性:複雑なサイトやログイン、動的コンテンツも対応できる?スクリプトで細かく調整できる?
- 対応データタイプ:テキスト、数値、画像、メール、電話番号、PDFなど幅広く抽出できる?
- スケーラビリティ・パフォーマンス:大量ページの処理やクラウド・マルチスレッド対応は?
- 連携・自動化:Excel、Google Sheets、Airtable、Notionに直接エクスポートやAPI連携できる?
- 価格・コスパ:無料プランはある?有料プランは用途に見合った価格?
- サポート・コミュニティ:ドキュメントやチュートリアル、サポート体制はしっかりしてる?
どこを重視するかはチームによって違う。たとえば営業チームなら「使いやすさ」と「すぐエクスポートできること」が大事だし、開発者なら「カスタマイズ性」や「API連携」が重要になるよ。
EC・市場調査向けデータエクストラクター
eコマースや市場調査チームにとって、最新データのキャッチは命。価格追跡や商品レビュー分析、競合モニタリングなど、大規模なスクレイピングやアンチボット対策、スケジューリングが求められる。
- Octoparse: ノーコードで使える強力なインターフェースと、AmazonやeBayなど主要サイト向けテンプレートが豊富。価格監視やレビュー収集にピッタリ。
- Import.io: ウェブデータをBIツールに連携しやすく、スケジューリングや変更検知機能も搭載。継続的なデータ収集が必要な市場調査におすすめ。
- Dexi.io: エンタープライズ向けで、ワークフロー自動化やデータ変換も可能。大手小売業者の競合分析や価格追跡に使われてる。
これらのツールは大規模なデータ収集や、ECサイト特有のアンチスクレイピング対策にも強いのが特徴。
技術者・カスタムワークフロー向けデータエクストラクター
開発者がいるチームや、コードに抵抗がない人には、もっと柔軟なツールがオススメ:
- Scrapy: Pythonベースの定番フレームワーク。オープンソースでカスタマイズ性バツグン。独自クローラーやアプリ連携に最適。
- ParseHub: ビジュアルワークフローで動的なJavaScriptサイトにも対応。条件分岐やカスタムJS、API連携もOK。
- Apify: JavaScriptやPythonでカスタムスクリプト(Actor)をクラウド実行。ワークフロー連携やヘッドレスブラウザ自動化、大規模処理に強い。
複雑なサイトのスクレイピングや多段階の自動化、シンプルなツールじゃ難しい要件にピッタリ。
データ連携・ワークフロー自動化向けデータエクストラクター
ただデータを抜くだけじゃなく、分析やシステム連携まで自動化したいなら:
- Import.io: ウェブデータを分析・BIダッシュボードに連携しやすく、スケジューリングやAPI配信も可能。
- Dexi.io: データのクレンジングや変換、CRMやデータベース連携まで一括自動化。
- Content Grabber: スクリプトやエラー処理、深いシステム連携ができるエンタープライズ向けプラットフォーム。
複数工程の自動化や、既存システムへのデータ連携が必要なときにおすすめ。
主要12ツールの比較表
主要なデータエクストラクターを一覧で比較したよ:
| ツール名 | 使いやすさ | 主な用途 | 価格 | カスタマイズ性 | 対応データタイプ |
|---|---|---|---|---|---|
| Thunderbit | ⭐ めちゃ簡単 | 全業種・非エンジニア向け | 無料&有料 | ローコードAIプロンプト | テキスト、数値、日付、URL、メール、電話、画像、PDF |
| Octoparse | 🙂 普通 | EC、マーケットリサーチ | 無料&有料 | 高(ビジュアル・正規表現) | テキスト、数値、URL、画像 |
| ParseHub | 🙂 普通 | 動的サイト、技術者向け | 有料 | 高(JS・ロジック) | テキスト、数値、URL、画像 |
| Import.io | 😀 簡単 | データ連携、BI | 有料(エンタープライズ) | 中 | テキスト、テーブル、リスト |
| Scrapy | 😐 難しい | カスタム開発、大規模 | 無料(OSS) | 超高(コード) | 任意(開発者定義) |
| Apify | 😐 難しい | ワークフロー自動化、開発者 | 無料&有料 | 超高(コード) | あらゆるウェブコンテンツ |
| Dexi.io | 🙂 普通 | エンタープライズ、ワークフロー | 有料(エンタープライズ) | 高(ビジュアル・スクリプト) | テキスト、画像、ファイル |
| WebHarvy | 😀 簡単 | 小規模ビジネス、静的サイト | 買い切り | 低〜中 | テキスト、数値、URL、画像 |
| Data Miner | 😀 簡単 | クイック抽出、営業 | 無料&有料 | 中(レシピ) | テキスト、テーブル、リスト |
| Visual Web Ripper | 🙂 普通 | 大規模静的、複雑ロジック | 買い切り | 高(テンプレ・API) | テキスト、画像、ファイル |
| Helium Scraper | 🙂 普通 | カスタムロジック、リレーショナル | 買い切り | 高(JS・SQL) | テキスト、URL、画像、ファイル |
| Content Grabber | 🙂 普通 | エンタープライズ、自動化 | 有料(エンタープライズ) | 超高(スクリプト) | あらゆるコンテンツ、構造化エクスポート |
凡例: 😀 簡単(非エンジニア向け)、🙂 普通(やや学習必要)、😐 難しい(コーディング必須)
1. Thunderbit
 Thunderbitは、エンジニアじゃなくても最大限の効率化を目指したい人にピッタリなAI 웹 스크래퍼。AI搭載のChrome拡張として、営業やオペレーション、不動産、ECなど「とにかくデータが欲しい!」って現場に超おすすめ。
Thunderbitは、エンジニアじゃなくても最大限の効率化を目指したい人にピッタリなAI 웹 스크래퍼。AI搭載のChrome拡張として、営業やオペレーション、不動産、ECなど「とにかくデータが欲しい!」って現場に超おすすめ。
主な特徴:
- AIによる列提案: ワンクリックでAIがページを解析して、最適な抽出項目を自動で提案。手動設定いらず。
- 2クリック抽出: 項目を確認して「抽出」ボタンを押すだけ。パソコン苦手でもOK。
- サブページ自動抽出: 商品やプロフィールなど詳細ページも自動で巡回してデータをしっかり集める。
- 無料データエクスポート: Excel、Google Sheets、Airtable、Notionにワンクリックで出力。
- メール・電話・画像も一括抽出: リード獲得や連絡先集めに最適。
- クラウド/ブラウザ両対応: 公開サイトは高速クラウド抽出、ログインページはブラウザモードで対応。
- 34言語対応: グローバルチームにもバッチリ。
メリット: 圧倒的な手軽さ、ノーコード、非構造化データにも強く、サイト構造の変化にも自動対応。小規模なら無料、大規模でもコスパ良し。
デメリット: 超複雑なサイトには開発者向けツールほどの柔軟性はない。大量利用はクレジット制。
おすすめ: 営業、EC運用、不動産、すぐに「データ→スプレッドシート化」したい人。 Thunderbitを無料で試す
2. Octoparse
 Octoparseは、ECや市場調査チーム向けの強力なノーコードデスクトップアプリ(Windows)。ビジュアルワークフローとAmazon、eBay、Zillowなど主要サイト向けテンプレートが豊富。
Octoparseは、ECや市場調査チーム向けの強力なノーコードデスクトップアプリ(Windows)。ビジュアルワークフローとAmazon、eBay、Zillowなど主要サイト向けテンプレートが豊富。
主な特徴:
- クリック操作で抽出設定: ページ上の要素をクリックして抽出タスクを作成。
- クラウド抽出&スケジューリング: 有料プランでクラウド実行や定期抽出が可能。
- IPローテーション&アンチボット: プロキシやキャプチャ対策も内蔵。
- 500以上のテンプレート: 主要サイト向けテンプレートが充実。
- 多階層・ページネーション対応: 複雑なナビゲーションや詳細ページも抽出可能。
メリット: 大規模な価格監視やレビュー分析、ECモニタリングに最適。ほとんどの作業はノーコードでOK。
デメリット: デスクトップ専用、ヘビーユーザーにはやや高価、高度なワークフローは学習が必要。
おすすめ: ECアナリスト、市場調査担当、大量の商品や競合を監視したい人。
3. ParseHub
 ParseHubは、動的でJavaScriptが多用されたサイトにも強い柔軟なビジュアルスクレイパー。Windows/Mac/Linux対応のデスクトップアプリで、条件分岐やカスタムJS、API連携も可能。
ParseHubは、動的でJavaScriptが多用されたサイトにも強い柔軟なビジュアルスクレイパー。Windows/Mac/Linux対応のデスクトップアプリで、条件分岐やカスタムJS、API連携も可能。
主な特徴:
- 動的コンテンツ対応: SPAやAJAX、インタラクティブなサイトもOK。
- ワークフロー&スクリプト: 多段階フローやカスタムJS、正規表現で細かく制御。
- クラウド&ローカル実行: PCでもクラウドでも実行可能(クラウドは有料)。
- API連携: 独自アプリやWebhookで自動化。
メリット: 技術者向けに高いカスタマイズ性、複雑なサイトにも対応。
デメリット: 大規模処理はやや遅め、学習コストあり、クラウド実行は追加料金。
おすすめ: 技術系アナリスト、開発者、インタラクティブなサイトを抽出したい人。
4. Import.io
 Import.ioは、ウェブデータをビジネスインテリジェンスに活用したい人向けのウェブベースプラットフォーム。クリック操作で抽出設定できて、スケジューリングやAPI連携も強力。
Import.ioは、ウェブデータをビジネスインテリジェンスに活用したい人向けのウェブベースプラットフォーム。クリック操作で抽出設定できて、スケジューリングやAPI連携も強力。
主な特徴:
- テーブル自動検出: URLを貼るだけで構造化データを自動抽出。
- スケジューリング&変更検知: 定期実行やデータ変化のアラートも可能。
- API連携: プログラムからデータ取得やBIツール連携。
- データ変換: プラットフォーム内でデータ整形も可能。
メリット: 分析担当者に使いやすく、分析ツールとの連携もスムーズ。
デメリット: エンタープライズ価格、動的サイトにはやや弱い、高度な制御は限定的。
おすすめ: 市場調査、ビジネスアナリスト、継続的なデータ収集が必要なチーム。
5. Scrapy
 Scrapyは、開発者に人気のオープンソースPythonフレームワーク。完全な制御、大規模処理、独自クローラー構築に最適。
Scrapyは、開発者に人気のオープンソースPythonフレームワーク。完全な制御、大規模処理、独自クローラー構築に最適。
主な特徴:
- 非同期クロール: 高速・効率的で大規模案件向け。
- フルコード制御: Pythonで自由にカスタマイズ、あらゆるシステムと連携可能。
- ミドルウェア&プラグイン: プロキシやログイン処理、拡張も簡単。
- 構造化出力: JSON、CSV、DBなど多様な形式にエクスポート。
メリット: 無料、柔軟性バツグン、コミュニティも活発。
デメリット: Python知識必須、GUIなし、保守は自己責任。
おすすめ: 開発者、データエンジニア、自社アプリやパイプラインに組み込みたい人。
6. Apify
 Apifyは、JavaScriptやPythonで作ったスクリプト(Actor)をクラウド上で実行・共有できるプラットフォーム。自動化やワークフロー連携、大規模処理に強い。
Apifyは、JavaScriptやPythonで作ったスクリプト(Actor)をクラウド上で実行・共有できるプラットフォーム。自動化やワークフロー連携、大規模処理に強い。
主な特徴:
- Actor&SDK: カスタムスクリプトやストアの既製Actorを利用可能。
- ヘッドレスブラウザ自動化: 動的サイトやログイン処理も対応。
- ワークフロー連携: 複数Actorを連携し多段階自動化。
- API&外部連携: Zapier、Make、Google Drive、AWSなどと連携。
メリット: 開発者向けに強力、スケーラブル、複雑な自動化も可能。
デメリット: コーディング必須、従量課金でコスト増も、学習コストあり。
おすすめ: スタートアップ、開発チーム、大規模なクラウド自動化が必要な人。
7. Dexi.io
 Dexi.io(旧CloudScrape)は、データ収集から変換・連携まで自動化できるエンタープライズ向けプラットフォーム。
Dexi.io(旧CloudScrape)は、データ収集から変換・連携まで自動化できるエンタープライズ向けプラットフォーム。
主な特徴:
- ビジュアルロボットデザイナー: クリック操作で多段階ワークフローを構築。
- クラウド実行&スケジューリング: クラウド上で大量処理や定期実行。
- データ処理&連携: クレンジングや変換、CRMやDB、API連携も。
- エンタープライズ機能: ユーザー管理、コンプライアンス、オンプレ対応。
メリット: スケーラブル、複雑なワークフローも自動化、連携力も強い。
デメリット: エンタープライズ価格、初心者には難しい、高度な利用にはトレーニング必要。
おすすめ: 大企業、小売インテリジェンスチーム、多段階データパイプラインの自動化。
8. WebHarvy
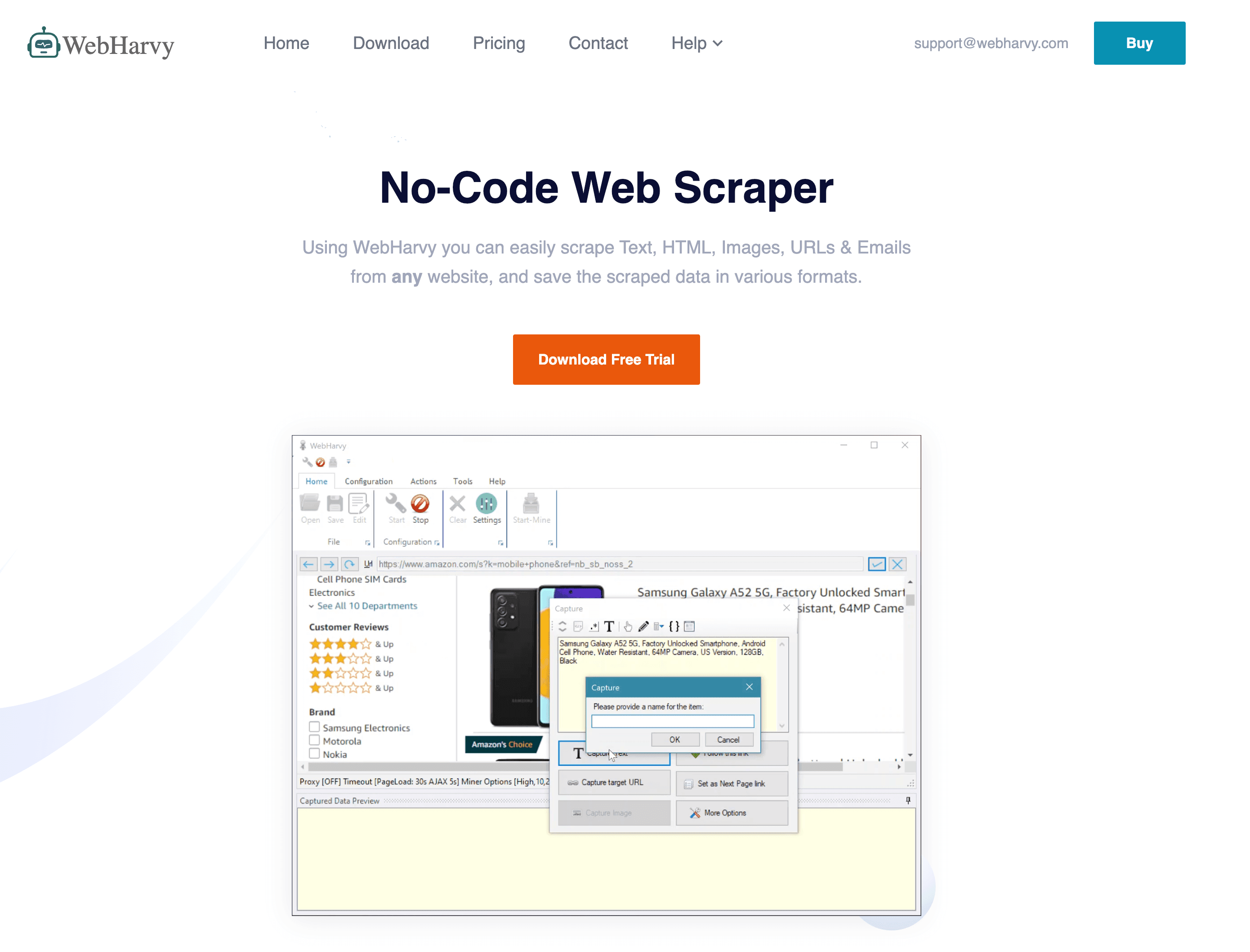 WebHarvyは、クリック操作だけで使えるWindows用デスクトップスクレイパー。買い切り型でコスパも良好。
WebHarvyは、クリック操作だけで使えるWindows用デスクトップスクレイパー。買い切り型でコスパも良好。
主な特徴:
- ビジュアル選択: 内蔵ブラウザで要素をクリックして抽出項目を指定。
- パターン自動検出: リストやテーブルも自動認識。
- 画像・ファイルダウンロード: テキストだけでなく画像やドキュメントも抽出。
- スケジューリング: Windowsタスクスケジューラで自動実行。
メリット: 買い切りで安価、シンプルなサイトに最適、オフラインでも利用可。
デメリット: JavaScriptやアンチボット対策サイトには弱い、Windows専用、高度なカスタマイズは限定的。
おすすめ: 小規模ビジネス、研究者、静的サイト向けの手軽なスクレイパーを探す人。
9. Data Miner
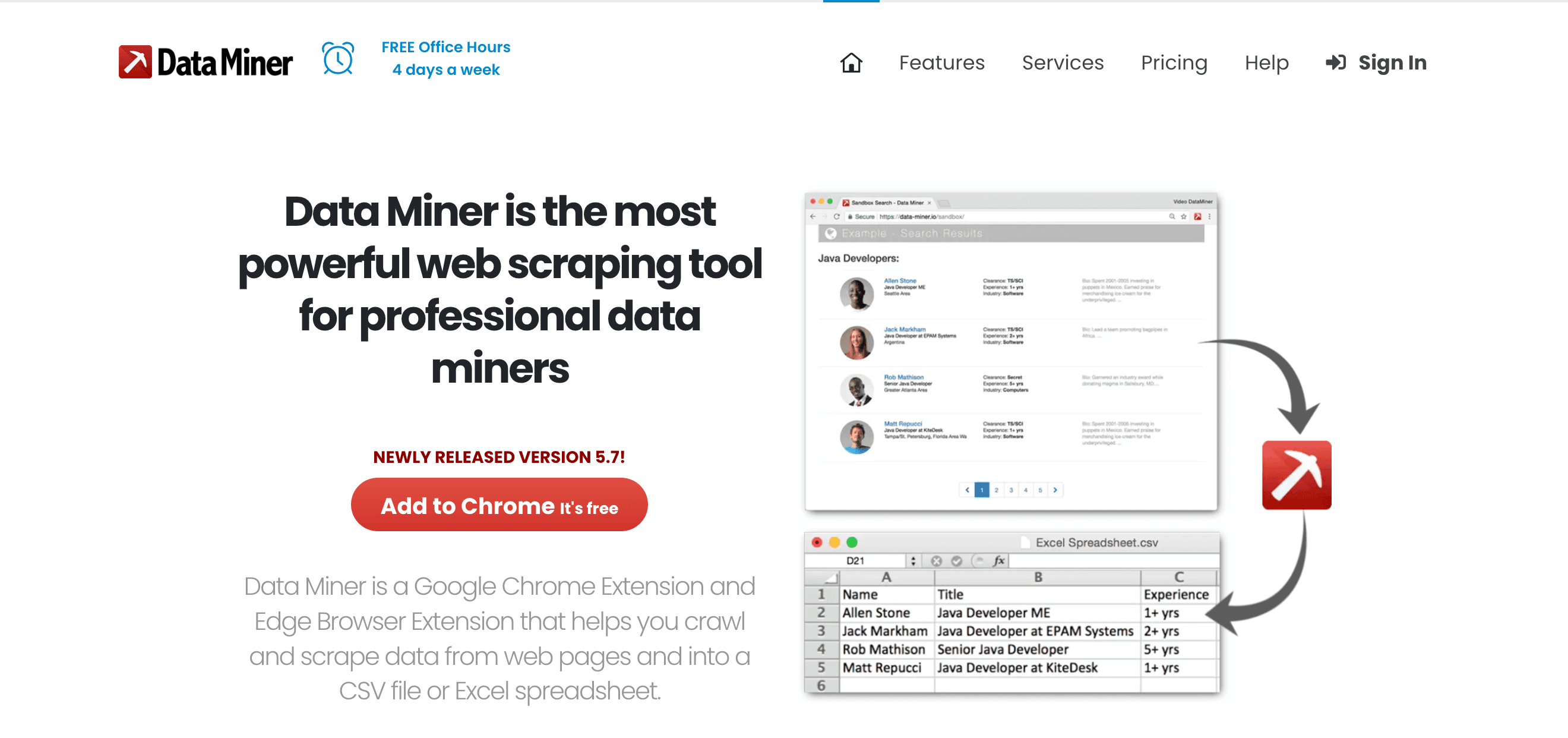 Data Minerは、Chrome/Edge拡張機能で、テンプレートベースのウェブデータ抽出に最適。営業やオペレーションチームに人気。
Data Minerは、Chrome/Edge拡張機能で、テンプレートベースのウェブデータ抽出に最適。営業やオペレーションチームに人気。
主な特徴:
- 60,000以上の公開レシピ: 人気サイト向けのワンクリック抽出。
- クリック操作でレシピ作成: 独自の抽出ルールも簡単作成。
- 即時テーブル抽出: HTMLテーブルやリストを数秒で取得。
- 直接エクスポート: Google Sheets、Excel、CSVに出力。
メリット: 高速、ブラウザベース、ノーコード、ログインサイトにも対応。
デメリット: ブラウザ速度に依存、無料/有料プランでページ数制限、大規模処理には不向き。
おすすめ: 営業リスト作成、クイックリサーチ、ウェブの「Excelにエクスポート」ボタンが欲しい人。
10. Visual Web Ripper
 (https://strapi.thunderbit.com/uploads/helium_1d0161c406.png)
Visual Web Ripperは、大規模なウェブデータ抽出やテンプレートベースの自動化に強いデスクトップソリューション。
(https://strapi.thunderbit.com/uploads/helium_1d0161c406.png)
Visual Web Ripperは、大規模なウェブデータ抽出やテンプレートベースの自動化に強いデスクトップソリューション。
主な特徴:
- テンプレート&プロジェクト管理: 多階層クロールもテンプレートで設計。
- 高度なオプション: 正規表現、XPath、デバッグツールも充実。
- DBエクスポート: SQL、Excel、XMLなど多様な形式に直接出力。
- 自動化: スケジューリングやマルチスレッド抽出も可能。
メリット: 複雑な静的サイトに強い、買い切り型、高度なロジックも対応。
デメリット: インターフェースがやや古い、Windows専用、動的サイト対応は限定的。
おすすめ: コンサルタント、代理店、大規模・構造化スクレイピングを管理したい人。
11. Helium Scraper
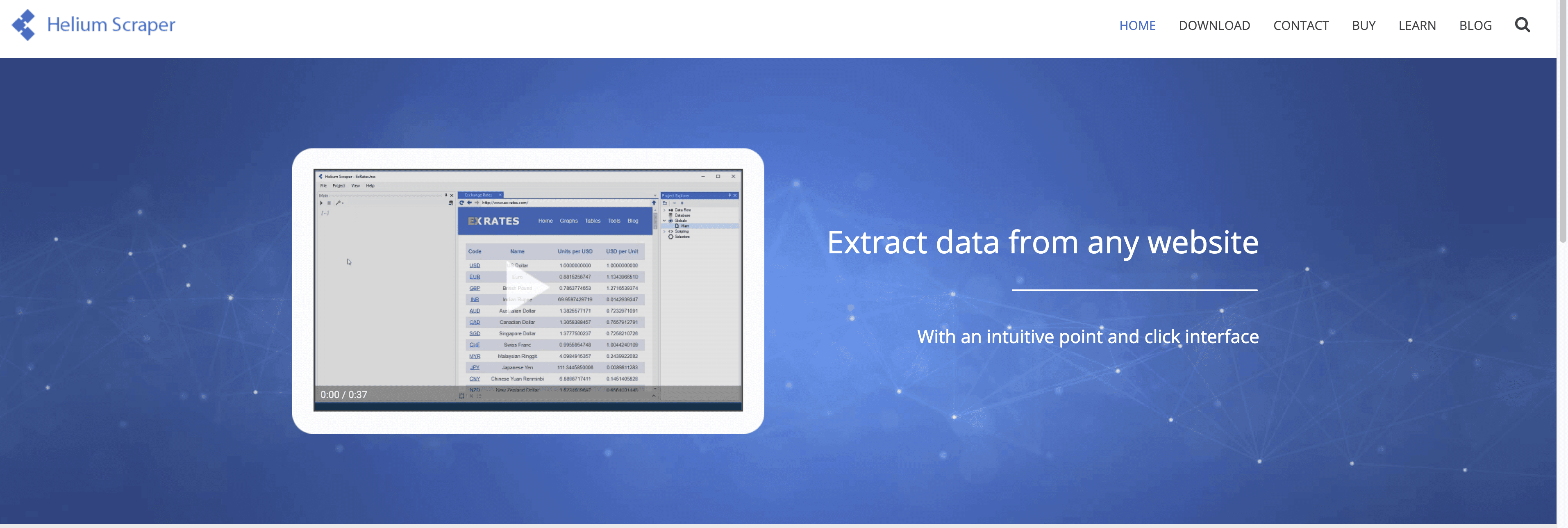 Helium Scraperは、ドラッグ&ドロップの手軽さと高度なカスタマイズ性を両立したWindowsアプリ。
Helium Scraperは、ドラッグ&ドロップの手軽さと高度なカスタマイズ性を両立したWindowsアプリ。
主な特徴:
- Kinds&Actionsモデル: データパターンをビジュアルで定義し、抽出アクションを設定。
- 多階層・リレーショナルデータ: 親子関係の出力やSQLクエリも可能。
- カスタムスクリプト: JavaScriptやSQLで高度なロジックも実装。
- マルチスレッド: 複数ページを並列抽出し高速化。
メリット: 柔軟性が高く、複雑なデータ構造にも対応、買い切りでコスパ良好。
デメリット: 「Kinds」概念の学習が必要、Windows専用、サポートはやや限定的。
おすすめ: 分析担当や技術好きで、シンプルなツール以上のパワーが欲しい人。
12. Content Grabber
 Content Grabberは、大規模・自動化・連携重視のエンタープライズ向けプラットフォーム。
Content Grabberは、大規模・自動化・連携重視のエンタープライズ向けプラットフォーム。
主な特徴:
- ビジュアルエージェントエディタ: クリック操作でエージェント作成、C#やVB.NETでカスタムロジックも追加可能。
- エンタープライズスケジューリング&監視: 一元管理、エラー処理、通知機能も充実。
- オンプレミス導入: データを社内で完結しコンプライアンス対応。
- API&連携: DB、API、メッセージキューへの出力も可能。
メリット: 圧倒的なパワーとスケーラビリティ、ミッションクリティカルな業務にも対応。
デメリット: 高価で複雑、ITリソースがある組織向け。
おすすめ: 大企業、データプロバイダー、ウェブデータ抽出を基幹業務とする人。
どのデータエクストラクターが自分に合う?用途別おすすめ
- 営業リード獲得: Thunderbit(AI・簡単エクスポート)、Data Miner(ブラウザ型・即時レシピ)
- ECモニタリング: Octoparse(テンプレ・スケジューリング)、Dexi.io(エンタープライズ・連携)
- 技術カスタマイズ: Scrapy(Python・OSS)、Apify(クラウド・自動化)、ParseHub(ビジュアル・動的サイト)
- データ連携・自動化: Import.io(BIワークフロー)、Content Grabber(エンタープライズ・オンプレ)
- クイック・小規模作業: WebHarvy(クリック型・買い切り)、Helium Scraper(ドラッグ&ドロップ・カスタムロジック)
ワンポイント: ほとんどのツールは無料トライアルやフリープランがあるから、実際のデータ課題でいくつか試してみるのがオススメ!
2025年版データスクレイピングの基礎と実践 Get Started Free
まとめ:最適なデータエクストラクターで業務効率を最大化
手作業でのデータ収集は、もう時代遅れ。最適なデータエクストラクターを使えば、単純作業は自動化できて、精度もグッと上がる。個人事業主から大企業のオペレーション担当まで、意思決定のスピードも質も大きく変わるよ。大事なのは、自分の用途・スキル・予算に合ったツールを選ぶこと。
「データが欲しい」から「スプレッドシートに反映」まで最速で実現したいなら、Thunderbitは最初の一歩にピッタリ。どんなニーズでも、このリストの中にきっと最適なツールが見つかるはず。
データ活用を次のレベルへ。いくつかのエクストラクターを試して、どれだけ時間と手間が省けるか体感してみて!
よくある質問
1. データエクストラクターって何?なんで必要なの?
データエクストラクターは、ウェブサイトやドキュメント、データベースから構造化情報を自動で集めてくれるツール。時間短縮やミス防止、分析業務に集中したいときに役立つよ。
2. 非エンジニア向けでおすすめのデータエクストラクターは?
Thunderbitは、AIによる2クリック設定や自然言語プロンプトで、コード不要・複雑な設定なしで使えるのが特長。
3. 動的・JavaScriptが多いサイトも抽出できる?
うん。ParseHub、Apify、Scrapy(ヘッドレスブラウザ対応)などが動的コンテンツやインタラクティブなサイトに強い。
4. 無料と有料のデータエクストラクター、どう選ぶ?
小規模・単発なら無料ツールで十分。継続的・大規模・重要業務には有料プランが機能・上限・サポート面で有利。まずは無料トライアルで実際に試してみるのがオススメ。
5. データエクストラクターの利用は合法?
基本的に公開データの抽出は合法だけど、各サイトの利用規約やプライバシー法は必ずチェックしよう。個人情報や機密データはGDPRなど法令遵守が必要。
ウェブスクレイピングや自動化、生産性アップのヒントはThunderbitブログで最新情報やチュートリアルをチェック!
さらに詳しく
AIウェブスクレイパーを試す Get Started Free




