
ウェブは、もはや単なるデジタルの遊び場ではありません。世界最大級のデータ倉庫であり、営業チームから市場アナリストまで、あらゆる人が活用を急いでいます。とはいえ、ウェブデータを手作業で集めるのは、説明書なしでIKEAの家具を組み立てるようなものです。しかも、余ったネジはその倍あります。
企業がリアルタイムの市場インテリジェンス、競合価格の把握、リード獲得にますます依存するなかで、効率的で信頼できるデータクロールツールの重要性はこれまでになく高まっています。実際、現在では企業の約とされ、世界のウェブスクレイピング市場は見込みです。
コピペにうんざりしている方、新鮮なリードを取りこぼしたくない方、あるいは自動化に面倒な作業を任せたときに何ができるのか見てみたい方には、まさにこのページがぴったりです。私は何年もウェブ抽出ツールを作り、テストしてきましたし(もちろん、 のチームを率いていたこともあります)、適切なツールがどれほど面倒な作業を2クリックの快適さに変えてくれるかを身をもって知っています。すぐに結果がほしいノーコード派でも、細部まで制御したい開発者でも、この「データクロールツール ベスト10」は最適な選択肢を見つける助けになるはずです。
適切なデータクロールツールを選ぶことが重要な理由
率直に言うと、優れたデータクロールツールと平凡なツールの差は、単なる便利さではありません。ビジネス成長に直結するかどうかです。ウェブ抽出を自動化すれば、時間を節約できるだけでなく(あるG2のレビュアーはと報告しています)、ミスを減らし、新しい機会を引き出し、チームが常に最新かつ正確なデータで仕事できるようになります。手作業のリサーチは遅く、ミスも起きやすく、終わるころには情報が古くなっていることも少なくありません。適切なツールがあれば、競合の監視、価格追跡、リードリスト作成を、数日ではなく数分で行えます。
実例を挙げると、ある美容小売業者は競合の在庫と価格を監視するためにウェブスクレイピングを活用し、という成果を上げました。スプレッドシートと根性だけでは、こうしたインパクトはなかなか出せません。
最適なデータクロールツールをどう評価したか
選択肢が多すぎると、適切なデータクロールツールを選ぶのは、テックカンファレンスでスピードデートしているような気分になるかもしれません。そこで、私が「良いもの」と「それ以外」を見分けるために使った基準は以下のとおりです。
- 使いやすさ: Pythonの博士号がなくても始められるか。ノーコード向けのビジュアルUIやAI支援はあるか。
- 自動化機能: ページネーション、サブページ、動的コンテンツ、スケジュール実行に対応しているか。大規模案件をクラウドで動かせるか。
- 価格と拡張性: 無料枠や手頃な入門プランはあるか。データ量が増えたとき、コストはどう伸びるか。
- 機能と連携: Excel、Google スプレッドシート、APIに出力できるか。テンプレート、スケジュール、組み込みのデータクリーニング機能はあるか。
- 最適な利用者: 実際には誰向けのツールなのか。ビジネスユーザー、開発者、それともエンタープライズチームか。
最後に簡単な比較表も載せているので、各ツールの違いをひと目で確認できます。
それでは、2026年に効率的なウェブ抽出を実現するデータクロールツール ベスト10を見ていきましょう。
1. Thunderbit
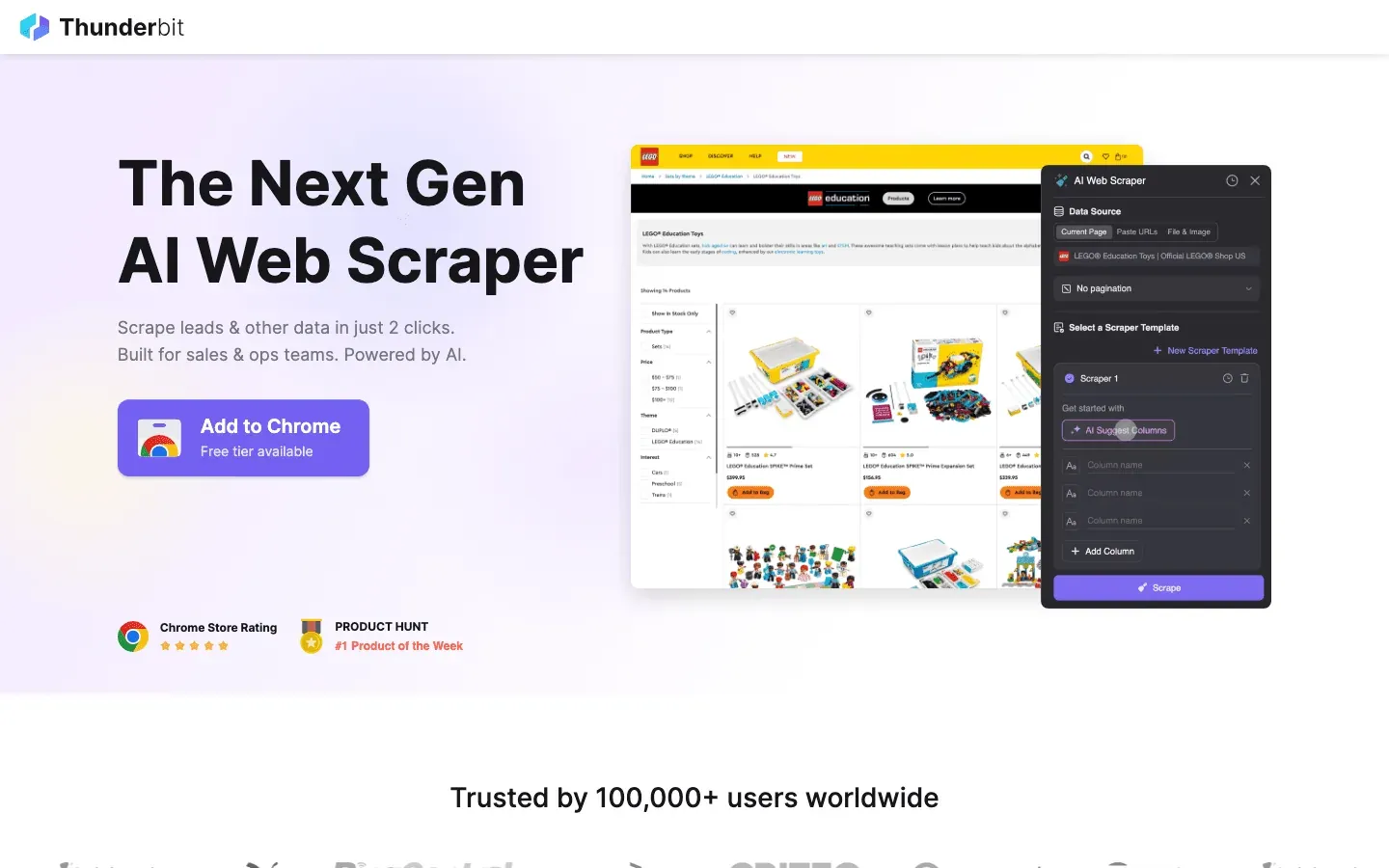 は、データクロールを出前を頼むくらい簡単にしたい人に、私が最初にすすめるツールです。AI搭載のChrome拡張機能として設計されており、Thunderbitの魅力は2クリックでのスクレイピングにあります。「AIで項目を提案」を押せば、AIがページ上の内容を理解し、そのあと「スクレイプ」をクリックするだけでデータを取得できます。コーディングもセレクタ調整も不要で、すぐに結果が得られます。
は、データクロールを出前を頼むくらい簡単にしたい人に、私が最初にすすめるツールです。AI搭載のChrome拡張機能として設計されており、Thunderbitの魅力は2クリックでのスクレイピングにあります。「AIで項目を提案」を押せば、AIがページ上の内容を理解し、そのあと「スクレイプ」をクリックするだけでデータを取得できます。コーディングもセレクタ調整も不要で、すぐに結果が得られます。
Thunderbitが営業、マーケティング、ECチームに支持される理由は、実際の業務フローに合わせて作られているからです。
- AIで項目を提案: AIがページを読み取り、抽出すべき最適な列を提案します。名前、価格、メールアドレスなど、必要な項目をすぐ把握できます。
- サブページスクレイピング: さらに詳しい情報が必要ですか。Thunderbitは各サブページ(商品詳細やLinkedInプロフィールなど)を自動で巡回し、表を拡充できます。
- 即時エクスポート: データをそのままExcel、Google スプレッドシート、Airtable、Notionに送れます。出力はすべて無料です。
- ワンクリックテンプレート: Amazon、Zillow、Instagramなどの人気サイトなら、即時テンプレートでさらに素早く使えます。
- 無料データ出力: データを書き出す際に有料壁はありません。
- **