
先月、友人のStripe連携が金曜の午後11時に、何の前触れもなく503を返し始めました。誰も気づかず、翌土曜の朝になってようやく発覚。するとサポートの受信箱には、決済に失敗した顧客からの怒りのメールが200通以上も届いていました。
こうした話は珍しくありません。 では、平均ダウンタイムは1分あたり5,600ドルとされ、。実際の損失額は、トラフィック、コンバージョン率、注文単価、SLAの対象範囲、復旧コストによって変わります。とはいえ、本質は明白です。監視されていないAPIは、単なるエンジニアのストレス源ではなく、ビジネス上のリスクなのです。、以上、もはや監視は任意ではありません。このガイドで私がやりたかったのは、他ではあまり見かけない切り口でツールを整理することでした。つまり、あなたのユースケースごとに分類し、アラートの有無ではなく質を評価し、2026年時点の実際の価格を示し、どれくらい早く本当に使い始められるかを測ることです。単なるロゴの平らな一覧ではありません。
もうひとつ。API業務にウェブデータ収集、LLMへのデータ供給、RAGシステム構築、競合ページの監視、あるいはWebサイトからの価格・商品データ抽出が含まれるなら、「APIツール」の話はアップタイム監視だけで終わるべきではありません。扱いの難しいWebページを、構造化データに変換する信頼できる方法も必要です。そこでこのガイドに登場するのがです。これはアップタイム監視ツールではありませんが、WebサイトをAPI経由でクリーンなMarkdownやスキーマベースのJSONに変換する最速級の方法のひとつです。
API監視とは何か、そしてなぜチームは気にすべきなのか?
API監視とは、APIエンドポイントが利用可能か、速く応答するか、正しいデータを返しているかを継続的に確認することです。単に「サーバーが稼働しているか」だけではありません。優れた監視では、HTTPステータスコード、レスポンス本文、レイテンシ、SSL証明書、ログイン→検索→購入のような複数ステップのワークフロー、さらにはスキーマの正しさまで検証します。
これは一般的なウェブサイト監視(ページが読み込めるかを確認する)とも、APM(Application Performance Monitoring、アプリケーション性能監視)とも異なります。APMはコードレベルのトレース、データベースクエリ、実行時内部に踏み込みます。API監視はその境界にあり、ユーザー、パートナー、連携先が実際にエンドポイントを呼び出したときに何を体験しているかをテストします。
関連するカテゴリーとして、ぜひ触れておきたいのがWebデータAPIです。これは自社APIの健全性を監視するものではなく、製品や業務フローが外部のWebデータを安定して収集するのを助けます。たとえばなら、WebページをクリーンなMarkdownに変換し、構造化フィールドをJSONとして抽出し、多数のURLに対してバッチ処理を実行できます。もしあなたの「API」プロジェクトが、最新のベンダーデータ、商品ページ、公開一覧、ドキュメントページ、調査ソースに依存しているなら、こうしたデータ抽出APIは、アップタイムチェックと同じくらい運用上重要です。
では、なぜ非エンジニアにも関係あるのでしょうか。 ており、からです。決済ゲートウェイ、認証サービス、配送APIが落ちれば、それは抽象的なインフラ問題ではありません。売上損失、パートナー契約の破綻、サポート件数の急増、信頼の低下です。プロダクトマネージャー、営業、運用、カスタマーサクセスの各チームにとっても、無関係ではありません。
注目すべき主要指標:
- 稼働率: エンドポイントが利用可能だった時間の割合
- 応答時間 / レイテンシ: 応答にかかる時間(平均、p95、p99)
- エラー率: 5xx、タイムアウト、アサーション失敗を返したリクエストの割合
- スループット: 1秒または1分あたりのリクエスト数
- 正しさ: APIが200 OKを返すだけでなく、期待どおりのデータを返しているか
2026年版のベストAPI監視ツールをどう評価したか
「ベストAPI監視ツール」の記事の多くは、ベンダー名と機能を並べるだけです。私はもう少し慎重に選定基準を決めたかったのです。開発者フォーラムをかなり読み込んだこともありますし、Thunderbitチームの協力で、ベンダーサイトからして、実際に比較表を作ったからでもあります(そのワークフローは後ほど詳しく触れます)。
重視したポイントは以下です。
| 評価基準 | 重要な理由 |
|---|---|
| 導入のしやすさ / 初回アラートまでの速さ | 小規模チームには、プラットフォーム導入プロジェクトの後ではなく「今日」必要だから |
| アラートの賢さとノイズ削減 | ノイズが多いとアラートは無視され、本当の障害を見逃すから |
| 無料プランの充実度 | 個人プロジェクトや初期スタートアップは無料から始めることが多いから |
| 価格の透明性 | 可観測性の請求額は、ホスト数、席数、ログ、合成テスト、データ取り込みで膨らみやすいから |
| 連携の広さ | アラートは、チームがすでに使っている場所(Slack、PagerDutyなど)に届く必要があるから |
| 拡張性とデータの深さ | 成熟したチームには、トレース、ログ、APM、RBAC、SSO、保持期間が必要だから |
| コミュニティとサポート品質 | オープンソース勢はリリース頻度が、エンタープライズ勢はSLAが重要だから |
| Webデータ抽出機能 | AIアプリ、RAGワークフロー、市場調査ツールは、単なるエンドポイント稼働状況ではなく、クリーンな外部データを必要とすることが多いから |
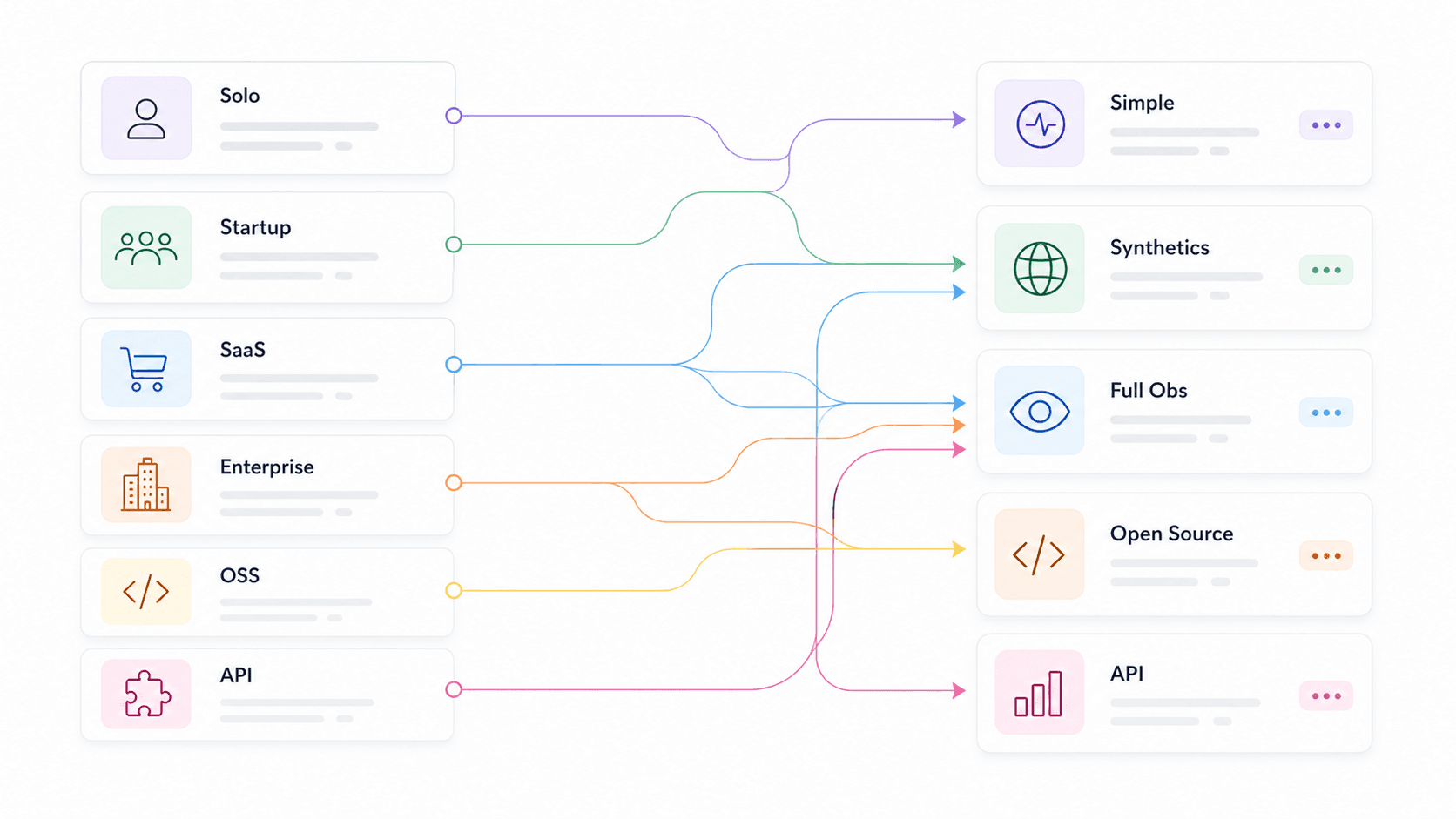
また、ソロ開発者、スタートアップ、Eコマース/SaaS、エンタープライズ、オープンソース原理主義者、APIプロダクトチーム、Webデータ/AIアプリチームといったユースケースごとにおすすめを分けました。14個のツール概要を全部読んで、どれが自分向きか当てずっぽうで探す必要はありません。 では、を、を選定基準に挙げており、こうした観点が単なる「あれば便利」ではないことが分かります。
ユースケース別のベストAPI監視ツール: クイックピック表
これがショートカットです。自分の行を見つけたら、下の各ツール解説に進んでください。
| ユースケース | おすすめツール | 主な差別化ポイント |
|---|---|---|
| Webデータ / AIアプリチーム | Thunderbit Open API, Moesif, Apitally | WebサイトをクリーンなMarkdownや構造化JSONに変換し、LLM、RAG、価格調査、リサーチ業務に活用できる |
| ソロ開発者 / 個人プロジェクト | UptimeRobot, Uptime Kuma, Gatus | 無料またはセルフホスト、最小限の設定、素早い導入 |
| スタートアップ(5〜15人) | Checkly, Better Stack, Postman | 賢いアラート、迅速な導入、手頃な価格、ステータスページ |
| Eコマース / SaaS | Datadog, New Relic, Moesif, Checkly | ビジネス指標、APM/トレース、SDKの深さ、複数ステップの合成テスト |
| エンタープライズ / マルチクラウド | Datadog, New Relic, Splunk, Grafana Cloud | 分散トレース、コンプライアンス、ハイブリッド、RBAC/SSO |
| オープンソース原理主義者 | Prometheus + Grafana, Uptime Kuma, Gatus, Uptrace | 完全な制御、OTelネイティブ、ベンダーロックインなし |
| APIプロダクトチーム | Moesif, Apitally, New Relic | 顧客別の利用状況、エンドポイント傾向、異常アラート |
最も大きな傾向は、導入が速いツールほど分析機能は軽めで、より深いプラットフォームほど設定とコスト管理が必要になることです。これは欠点ではなく、認識しておくべきトレードオフです。Thunderbitは少し違う立ち位置にあります。ダウンタイムをエンジニアに通知することではなく、WebページをAPI対応のデータに変換する作業で最速を発揮するのです。
Thunderbit Open API: Webサイトを構造化APIデータに変換するのに最適
は、「監視」やリサーチのワークフローが外部Webデータに依存しているチームに、私なら最初に勧めるAPIです。ChecklyやUptimeRobotのような従来型のアップタイム監視ツールではありません。その代わりに、ThunderbitはあらゆるWebページを、アプリ、エージェント、ダッシュボード、LLMパイプラインが実際に使えるクリーンで構造化されたデータへ変換します。
このAPIには3つのコアワークフローがあります。Distill はページをクリーンでLLM向けのMarkdownに変換します。Extract はスキーマを与えると、商品名、価格、在庫状況、企業規模、資金調達ステージ、レビュー評価などの構造化JSONフィールドを返します。Batch はWebhook付きで最大100個のURLを非同期処理でき、価格ページ、競合カタログ、ベンダードキュメント、ニュースソース、大規模な調査リストの監視に便利です。
これがAPIツールのガイドに入る理由は、多くのチームが「このページをスクレイプするだけ」でどれだけのインフラが要るかを過小評価しがちだからです。JavaScriptが多いサイトにはレンダリングが必要です。ページによっては地域分岐も必要です。HTMLは、LLMにとって役立つ形にする前に、ナビバー、広告、モーダル、定型文を取り除く必要があります。レイアウトが変わるとセレクタは壊れます。プロキシのローテーション、ボット対策、リトライ、キュー、結果ポーリングまで考えると、小さなデータ業務が保守プロジェクトに化けることもあります。Thunderbitは、その多くをひとつのAPIの裏側で吸収します。
こんな人に最適: AIアプリ開発者、RAGチーム、Eコマース運用、営業運用、グロースチーム、市場調査担当、そしてスクレイピング基盤を自前で作って保守することなく、WebサイトのデータをAPIで取り込みたい開発者。
価格: があり、Distillページ最大600件またはExtractページ30件まで、同時リクエスト2件に対応します。Starterは年払いで月16ドル相当で、年間60,000 APIユニットと同時リクエスト30件。Proは年払いで月40ドル相当で、年間600,000 APIユニットと同時リクエスト50件です。
導入速度: APIキー取得から、やcURL、SDKで最初のDistillまたはExtractリクエストを実行するまで、約5〜15分。
弱み: Thunderbitは、アップタイムチェック、インシデントエスカレーション、トレース、ログ、当番ルーティングの代わりにはなりません。それらはDatadog、New Relic、Better Stack、Checklyの役目です。Thunderbitは、ベンダー価格、ドキュメント、競合ページ、商品一覧、公開データセットなどを含むWebデータを収集・構造化するためのAPIだと考えてください。オンコール担当者に通知を飛ばすシステムではありません。
Datadog: フルスタック可視化に最適
Datadogは、エンタープライズやミッドマーケットのSaaSスタックでよく見かけるツールです。それには理由があります。単なるAPI監視ではなく、合成APIテストを分散トレース、ログ、インフラ指標、実ユーザーモニタリングにつなげ、ひとつの画面で見られるフル可観測性プラットフォームだからです。
API監視に限っても、DatadogはHTTP、SSL、DNS、WebSocket、TCP、UDP、ICMP、gRPC、そしてをサポートします。は期待されるパターンを学習し、固定閾値ではなく逸脱を通知します。これは「レイテンシが500msを超えたら通知」のような単純な仕組みより、かなり実用的な進歩です。さらに、指標がしきい値を超えるタイミングを予測するや、複数条件を組み合わせる複合モニターもあります。
こんな人に最適: API、インフラ、ログ、トレースをひとつの画面で横断して見たいEコマース、SaaS、エンタープライズのチーム。
価格: 無料枠の詳細は製品ごとに異なります。、APIの合成テストは1万実行あたり5ドル。800以上の連携があります。
導入速度: エージェント導入と基本的な合成テストで約15〜30分。
弱み: 大規模になると高額になりがちです。Hacker NewsやRedditでも「請求ショック」はよく話題になります。ホスト、ログ、カスタムメトリクス、合成テスト、ユーザーなどSKUが多いため、ダッシュボードを見るだけでなく請求額も追う担当者が必要です。プラットフォーム全体の学習曲線も確かにあります。
Checkly: 開発者ファーストの合成チェックに最適
Checklyは、APIチェックをコードの近くに置きたいスタートアップのエンジニアリングチームに渡したいツールです。中核となる考え方は「モニタリング・アズ・コード」。APIチェックやブラウザチェックをプログラムで定義し、グローバルロケーションから実行し、CI/CDパイプラインと連携し、すべてをGitで管理します。
アラートの品質という観点でも強みがあります。Checklyのは、明確に誤検知に対する「最初の防衛線」と位置づけられており、固定・線形・指数のリトライ、同一ロケーションまたは別ロケーションでの再試行、アラート発火前の最大リトライ時間を設定できます。また、劣化、失敗、復旧の状態を区別できるため、不要な通知を減らしやすくなっています。
こんな人に最適: プログラム可能なAPIチェック、、CI/CD連携、素早い導入を求めるスタートアップや開発チーム。
価格: 直近の公開情報では、10個のアップタイムモニター、1,000回のブラウザチェック、10,000回のAPIチェックを含む無料プランがあります。Starterは年払いで月24ドル前後ですが、購入前にを確認してください。
導入速度: 最初のAPIチェックと通知先設定まで約10〜20分。
弱み: 合成チェックに特化しています。深いAPM、ログ分析、分散トレースの代替にはなりません。API障害をデータベースのボトルネックと結び付けて原因分析したいなら、別のツールを併用する必要があります。
UptimeRobot: シンプルで安価なアップタイム追跡に最適
UptimeRobotは、API監視界のHonda Civicのような存在です。やることはひとつで、それをうまくやります。HTTP、キーワード、ping、ポート、SSL、heartbeatのモニターを作成し、間隔を決め、失敗したら通知を受ける。それだけです。
こんな人に最適: ソロ開発者、小規模チーム、代理店、複雑さなしで基本的な稼働確認とレイテンシ追跡が必要な人。
価格: 。有料のSoloプランは年払いで月約7ドル。無料利用にクレジットカードは不要です。導入速度: 約2〜5分で、この一覧では最速です。
弱み: アラートの賢さは限定的です。基本的なしきい値アラートのみで、異常検知、分散トレース、深い分析はありません。エンドポイントが遅い「理由」を知りたいのであって、単に「遅い」ことを知りたいわけではないなら、UptimeRobotでは足りません。
Uptime Kuma: 最良の無料セルフホスト型API監視ツール
Uptime Kumaはセルフホスティング界隈の人気者です。GitHubの数値がそれを裏付けています。に加え、2026年5月時点のリリースは2.3.2です。MITライセンスで、HTTP(s)、キーワード、JSONクエリ、WebSocket、TCP、ping、DNS、push、Docker、複数のステータスページ、90以上の通知サービスをサポートしています。
こんな人に最適: サーバーがあり、完全な制御、プライバシー、継続課金ゼロを求めるソロ開発者やチーム。
価格: 無料です。実際のコストは、VMやコンテナ、バックアップ、更新作業、そしてモニター自体の稼働維持にかかる費用です。導入速度: Dockerで基本チェックなら約5〜15分、通知とステータスページの調整まで含めると15〜30分。
弱み: 保守は自分で担う必要があります。さらに重要な落とし穴として、Uptime Kumaを監視対象と同じインフラ上で動かすと、クラウド障害やDNS障害が起きたときにアプリも監視も一緒に落ちます。外部でホストするか、SaaSチェックと組み合わせてください。
Better Stack: インシデント対応の速さに最適
Better Stack(ユーザーの間では今でもBetter Uptimeと呼ばれることが多い)は、アップタイム監視、インシデント管理、オンコールスケジューリング、エスカレーションポリシー、ステータスページをひとつのプラットフォームにまとめています。強みは分析ツールというより、監視を包み込むインシデント業務フローにあります。
では、誰に、どの順番で、どれだけの遅延を挟んで通知するかを、受諾されるまで定義できます。メタデータベースのルーティングで、重大度や担当に応じてインシデントを振り分けます。Slack、Teams、webhook、Zapierと連携します。
こんな人に最適: 監視+インシデント対応+ステータスページを、3つの別ツールをつなぎ合わせずに使いたいスタートアップや中堅チーム。
価格: 。Teamは年払いで月29ドル前後。導入速度: GUIウィザードで約5〜10分。
弱み: Datadog、New Relic、Moesifと比べると、APIペイロード分析、分散トレース、ビジネスKPI分析の深さは控えめです。
Prometheus + Grafana: 最良のオープンソースAPI監視スタック
これは業界標準のオープンソースの組み合わせです。が時系列メトリクスを収集・保存します。(GitHubスター73,705、コントリビューター3,010)がダッシュボードとアラートを提供します。がルーティング、グルーピング、重複排除、抑制、ミュートを担当します。APIエンドポイントのチェックには、HTTP、HTTPS、DNS、TCP、ICMP、gRPCのプローブ用にを追加するのが一般的です。
こんな人に最適: オープンソース原理主義者、Kubernetes/SREチーム、すでにPrometheusメトリクスで標準化している組織。
価格: セルフホストなら無料。には無料枠(APIテスト実行10万回/月)と、従量課金の有料プランがあります。
導入速度: 基本的なBlackbox + Prometheus + Grafana + Alertmanagerなら1〜4時間。本番向けの高可用性構成とアラート調整は数日かかります。
弱み: PromQL、YAML、relabeling、ダッシュボード設計、保持、ストレージ、高可用性、アラート調整は、実際に手間のかかる運用作業です。よくあるトレードオフは「UIが少ないぶんYAMLが増える」こと。このスタックは、すでにメトリクス思考で、ひとつの制御プレーンを望むチーム向けであって、昼までに監視を稼働させたいチーム向けではありません。
New Relic: SaaSアプリケーション性能に最適
New Relicは、APM、インフラ監視、ログ、分散トレース、合成監視、アラート、ダッシュボード、AI支援のインシデント分析を組み合わせています。無料枠は、で、小規模チームには本当に寛大です。
アラート疲れの話でNew Relicが光るのは、アラートの賢さです。には、イベント相関、異常検知、予測アラート、根本原因分析、フラッピング抑制が含まれます。New Relicはを公開しており、ノイズ削減の具体例として分かりやすいです。
こんな人に最適: API監視を、アプリケーショントレース、エラー、スループット、ユーザー影響と密接に結び付けたいSaaSチームやEコマース基盤。
価格: 無料: 100GB/月、フルユーザー1人。有料はユーザー単位とデータ量ベースの課金です。
導入速度: エージェント導入とガイド付きセットアップで約15〜30分。
弱み: 大規模になると価格体系が複雑になりがちです。アラート設定にも学習コストがあり、強力ではあるものの直感的ではありません。
Moesif: API分析とビジネスメトリクスに最適
Moesifは従来型のアップタイム監視ツールではありません。API分析とプロダクトインテリジェンスのツールです。顧客、エンドポイント、コホート、企業、地域、SDK、プラン、行動別にAPI利用状況を理解するためのものです。「エンドポイントは生きているか」ではなく「どの顧客に影響があるのか」が知りたいなら、Moesifはそのために作られています。
APIメトリクスに対して、の両方をサポートします。トラフィックの急増・急減、レイテンシ、行動変化などを検知できます。動的アラートはモデル構築に数日分のAPI挙動が必要ですが、一度学習すると静的ルールでは見逃す変化を捉えられます。
こんな人に最適: APIプロダクトチーム、SaaS企業、API性能を売上、エンゲージメント、継続率と結び付けたいEコマース基盤。
価格: 。有料プランはAPIイベント量に応じて拡張します。セルフサービスの金額は私の調査では十分に取得できなかったため、最新ページを確認してください。
導入速度: 約20〜45分(SDK/プロキシ/ゲートウェイ連携が外部pingより深いため)。
弱み: 従来のアップタイム監視より分析寄りです。外部可用性チェックには、Checkly、UptimeRobot、Datadogの合成監視などを併用するのがよいでしょう。
Splunk: エンタープライズのログ分析とコンプライアンスに最適
Splunkは、ログ集約、検索、相関分析、コンプライアンス対応の監査性、ハイブリッド/マルチクラウド対応が必須のときに使うツールです。は、インフラ、APM、合成監視、実ユーザーモニタリング、ログ、インシデント対応をカバーします。は、注目すべきイベントをエピソードとしてまとめ、監視サイロ横断のノイズを減らせます。
Splunk自身のは示唆的です。し、、。
こんな人に最適: 厳格なコンプライアンス、セキュリティ、監査、ログ検索要件を持つエンタープライズおよびマルチクラウドのチーム。
価格: 従量課金で見積もり中心。単純な本番向け無料枠はありません。
導入速度: クラウド導入は早いこともありますが、エンタープライズ導入は通常数日から数週間かかります。
弱み: 大規模になると高価です。設定も複雑です。ソロ開発者や小規模スタートアップには過剰です。
Postman: すでにAPIをテストしているチームに最適
Postmanは主にAPI開発・テストのプラットフォームですが、を使えば、Postmanコレクションをスケジュール実行し、クラウドのロケーションから走らせられます。最大の強みは再利用性です。QAチームや開発チームがすでにアサーション付きのPostmanコレクションを持っているなら、それをモニター化するのは自然な次の一歩です。
こんな人に最適: すでにPostmanコレクションを使っていて、別の合成監視ツールを買わずに定期チェックしたい開発・QAチーム。
価格: 無料枠あり。 。50,000コールの追加ブロックは月20ドル。を確認してください。Postmanはプラン構成が変わることがあります。
導入速度: すでにコレクションがあれば約10分。
弱み: 監視機能はCheckly、Datadog、New Relicのような専用ツールより軽めです。アラートの選択肢も基本的です。
そのほか注目に値するAPI監視ツール
: 軽量なセルフホスト型、設定駆動のヘルスダッシュボード。を持ち、HTTP、ICMP、TCP、DNS、Prometheus向けメトリクス、稼働バッジをサポートします。Prometheusよりシンプルなものが欲しいが、Uptime KumaのUIよりYAML/設定コードを好むソロ開発者に最適です。
: スタートアップ向けにAPIトラフィック分析と品質追跡に焦点を当てた比較的新しいツール。できると主張しており、14の指標にまたがるカスタムアラートを備えます。フル可観測性プラットフォームを導入せずに軽量なAPI分析をしたい場合に向いています。
: ログ、合成監視、インフラ可視化を備えたフルスタック監視。 。中堅チーム向けの低コストなDatadog代替候補です。
: OpenTelemetryネイティブのAPM、トレーシング、メトリクス、ログのバックエンド。を持ちます。純粋なアップタイムチェッカーではありませんが、OTelを標準化していて、オープンソース寄りのトレース基盤が欲しいチームに理想的です。
自作か購入か: API監視は自分で作るべきか?
「単にエンドポイントをpingするスクリプトを書けば十分? それとも専用ツールを使うべき?」
この質問は開発者フォーラムで本当によく出ます。Redditのスレッドをかなり読んだので、パターンははっきり見えました。チームは最初、curl + cronで始めます。しばらくはうまく動きます。そして、ダッシュボード、履歴データ、マルチリージョンチェック、信頼できる通知ルーティング、チーム横断の可視化が必要になったタイミングで乗り換えるのです。
率直な判断マトリクスは次のとおりです。
| 要素 | 自作スクリプト | 専用ツール |
|---|---|---|
| 初期設定時間 | 1〜4時間(基本)、数日(堅牢) | 5〜30分 |
| 保守 | 永久に自分で担う | ベンダーが更新を担当 |
| アラート品質 | 基本的(up/down) | 賢い(レイテンシ傾向、異常、リトライ) |
| コスト | 無料(ただし自分の時間) | 月0〜500ドル以上 |
| ダッシュボード | ゼロから作る | 既製、カスタマイズ可能 |
| 向いている条件 | エンドポイント3本以下、開発者中心、趣味プロジェクト | 5本以上、運用/プロダクトチーム、売上がかかっている |
フォーラムから見える重要な教訓は、自作派の多くが、ダッシュボードや履歴データ、チーム横断の可視化が必要になった時点で後悔することです。さらにメタな問題として、「監視そのものを監視する必要がある」ということもあります。セルフホストのモニター、データベース、バックアップ、ネットワーク経路、アラート提供先まで、すべて信頼できなければなりません。
エンドポイントが2本しかなく、試行錯誤が好きなら自作でもよいでしょう。出すべき製品があるなら、買ったほうが早いです。
同じ理屈はWebデータ抽出にも当てはまります。スクレイパーを書き、ヘッドレスブラウザを動かし、プロキシをローテーションし、セレクタを保守し、HTMLを整形し、キューを作ることはできます。でも、仕事が「Webデータを安定してAPIプロダクト、AIエージェント、リサーチワークフローに流し込むこと」なら、を使うほうが、自前でスクレイピング基盤を組むよりたいてい速いです。
アラート疲れ: なぜアラートの数より質が大事なのか
API監視ツールを選ぶうえで、これは最も見落とされがちな基準かもしれません。アラート疲れとは、チームがノイズの多い、重複した、行動に結びつかないアラートを大量に受け取り、最終的に全部無視するようになり、結果として本当の障害を見逃してしまう状態です。
数字は衝撃的です。では、組織の中央値でとが生成されていました。中央値のインシデント実用性はわずかで、アラートから派生したインシデントの5件に1件未満しか実際には使えないという意味です。では、、。
最良の監視ツールとは、アラートを本当に信頼できるものです。各ツールのアラートの賢さを比べると次のようになります。
| ツール | アラートの種類 | ノイズ削減の方法 | アラートチャネル |
|---|---|---|---|
| Datadog | ML異常、予測、複合 | 過去の異常帯、動的ベースライン、Watchdog AI | Slack、PagerDuty、Opsgenie、Teams、20以上 |
| Checkly | 閾値+劣化ベース | 発火前リトライ、同一/別ロケーション再試行 | Slack、PagerDuty、Opsgenie、Teams、incident.io |
| New Relic | AIによる課題グルーピング、異常、予測 | イベント相関、フラッピング抑制、根本原因コンテキスト | Slack、PagerDuty、Teams、webhook |
| Moesif | 挙動異常 | 数日分の挙動を学習した動的モデル | Slack、PagerDuty、メール、SMS |
| Better Stack | 稼働/インシデント/オンコール | エスカレーションポリシー、担当ルーティング、遅延設定 | Slack、Teams、webhook、Zapier |
| Prometheus + Alertmanager | PromQLルールアラート | グルーピング、重複排除、抑制、inhibition | メール、PagerDuty、Opsgenie、webhook |
| Splunk | イベント、エピソード、サービス健全性 | ITSI Event Analytics、エピソードグルーピング、チケット連携 | Splunk On-Call、ServiceNow、webhook |
| Thunderbit Open API | アラートプラットフォームではない | 独自のスケジューラー、ワークフローツール、監視スタックと併用 | バッチジョブ向けWebhook。アラートは外部で処理 |
実践アドバイス: 少数で、確度の高いアラートから始めてください。発火前リトライ、マルチリージョン確認、SLOバーンレートアラート、重複排除、担当ルーティングを使いましょう。ユーザー影響やビジネス上クリティカルなフロー(購入失敗、認証失敗、支払いの5xx)にだけアラートを出し、内部症状すべてには出さないでください。
2026年の無料枠と価格: 実際にいくら払うのか
価格ページは変わります。無料枠も動きます。隠れコスト(ホスト、席数、ログ、合成実行、データ取り込み)は意外に大きくなりがちです。この記事で毎回あってほしいと思うのが、このセクションです。2026年時点のスナップショットは以下のとおりです。
| ツール | 無料枠 | 有料開始価格 | クレジットカード必須? | 無料で最適な用途 |
|---|---|---|---|---|
| Thunderbit Open API | 600回分の一度きりAPIユニット | 年払いで約月16ドル | いいえ | LLM、RAG、価格調査、リサーチ向けのWebデータ抽出 |
| Uptime Kuma | 無制限(セルフホスト) | — | いいえ | 完全な監視、自前サーバー |
| UptimeRobot | 50モニター、5分間隔 | 約月7ドル | いいえ | 基本的な稼働チェック |
| Better Stack | 10モニター、ステータスページ1つ | 約月29ドル | いいえ | スタートアップの稼働監視+ステータスページ |
| Checkly | 10アップタイム、1万APIチェック | 約月24ドル | はい | 合成APIチェック |
| Postman | 無料アカウント+監視枠 | 約月14ドル/ユーザー | いいえ | 既存コレクションの再利用 |
| Prometheus + Grafana | 無制限(セルフホスト) | — | いいえ | メトリクス+可視化 |
| Grafana Cloud | APIテスト実行10万回/月 | プラットフォーム月29ドル+従量課金 | 確認要 | マネージド合成監視の試用 |
| New Relic | 100GB/月、フルユーザー1人 | ユーザー単位+データ量 | 一部プランで必要 | APM+基本的な可観測性 |
| Datadog | トライアル/製品により変動 | $15/ホスト/月(Infra Pro) | 多くの場合はい | フルスタック評価 |
| Moesif | 無料/トライアルあり | 量ベース | 確認要 | API分析の評価 |
| Splunk | トライアルあり | 見積もり制 | 営業フロー | エンタープライズのPoC |
| Gatus | 無制限(セルフホスト) | — | いいえ | YAML駆動のステータスダッシュボード |
| Apitally | 無料/トライアルあり | 確認要 | 確認要 | 軽量なAPI分析 |
| Sematext | トライアル/無料は変動 | HTTPモニター約2ドル | 確認要 | 低コストな合成監視/ログ |
| Uptrace | 無料セルフホスト | クラウド階層は変動 | 確認要 | OTel APMの評価 |
隠れコストの注意: Uptime Kuma、Prometheus、Gatusのようなセルフホスト型ツールは、ライセンス上は「無料」ですが、小さなVM、バックアップ、保守時間、外部フェイルオーバーが実際のコストになります。WebデータAPIの場合、隠れコストは少し違います。ヘッドレスブラウザ、壊れたセレクタ、プロキシプール、ボット対策、HTML整形の維持が主な負担です。
小規模チームの目安: APIエンドポイント10本、チームメンバー3人なら、最安のSaaS構成は通常、UptimeRobotの無料または低価格プラン、Better Stackの無料/Team、あるいは実行量が合えばChecklyです。DatadogやNew Relicは評価用途としては手が届きますが、実際の請求額はホスト、ユーザー、ログ、トレース、合成実行量で決まります。プロジェクトにWebサイトデータをAPIとして取り込む必要があるなら、Thunderbitの無料APIユニットで、有料プランに移る前にワークフローを試せます。
設定の難しさスコアカード: 初回アラートまでの速さ
私が見つけた競合記事で、初回の意味あるアラートを受け取るまでの時間、つまりサインアップから価値を得るまでの時間を評価しているものはありませんでした。小規模チームにとっては、これは機能の深さより重要です。
| ツール | 初回アラートまでの時間 | 必要な技術レベル | 設定方法 |
|---|---|---|---|
| Thunderbit Open API | 約5〜15分 | 低〜中 | APIキー、cURL/SDK/CLI |
| UptimeRobot | 約2〜5分 | 低 | GUI、クリックで追加 |
| Better Stack | 約5〜10分 | 低 | GUIウィザード |
| Checkly | 約10〜20分 | 低〜中 | コードまたはGUI |
| Postman | 約10分(コレクションがある場合) | 低〜中 | コレクションスケジューラー |
| Uptime Kuma | 約5〜30分 | 中 | Docker+GUI |
| Gatus | 約15〜45分 | 中 | YAML+Docker |
| Datadog | 約15〜30分 | 中 | エージェント導入+GUI |
| New Relic | 約15〜30分 | 中 | エージェント+ガイド付き設定 |
| Moesif | 約20〜45分 | 中 | SDK/プロキシ連携 |
| Grafana Cloud Synthetics | 約15〜45分 | 中 | GUI、Terraformは任意 |
| Prometheus + Grafana | 1〜4時間 | 中〜高 | YAML、PromQL |
| Uptrace | 30〜90分 | 中〜高 | OTel SDK連携 |
| Splunk | 数時間〜数週間 | 高 | エンタープライズ導入 |
もし今日中に監視を立ち上げる必要があるなら、この表の上半分から始めてください。目標が耐久性のあるプラットフォーム可観測性なら、下半分は別プロジェクトとして計画しましょう。そして最初のマイルストーンが「この100個のWebページからクリーンなデータをアプリに入れること」なら、自前のスクレイピング基盤を作る前にThunderbitから始めるべきです。
ベストAPI監視ツールを横並びで比較
決める前に、ひと目で見られる総覧です。
| ツール | 最適な用途 | 無料枠 | アラートの賢さ | 導入時間 | ホスティング | 際立つ機能 |
|---|---|---|---|---|---|---|
| Thunderbit Open API | Webデータ抽出/APIデータパイプライン | 600 APIユニット | アラートツールではない | 5〜15分 | クラウド | ページをMarkdown化、またはスキーマベースJSONを抽出 |
| Datadog | フルスタックのエンタープライズ/SaaS | トライアル/変動 | 異常、予測、AI | 15〜30分 | クラウド | 合成監視をログ/トレース/インフラと相関 |
| Checkly | 開発者ファーストの合成監視 | 寛大なチェックベース | リトライ、劣化検知 | 10〜20分 | クラウド | モニタリング・アズ・コード+Playwright |
| UptimeRobot | シンプルな稼働監視 | 50モニター | 基本しきい値 | 2〜5分 | クラウド | 最速の低コスト基本モニター |
| Uptime Kuma | 無料セルフホスト | 無制限 | 基本ステータス/しきい値 | 5〜30分 | セルフホスト | きれいなUI、SaaS費用なし |
| Better Stack | インシデント対応/ステータスページ | 10モニター | エスカレーション、ルーティング | 5〜10分 | クラウド | 監視+オンコール+ステータスページ |
| Prometheus + Grafana | オープンソースのメトリクススタック | 無制限(セルフホスト) | Alertmanagerのグルーピング | 1〜4時間 | セルフホスト/クラウド | PromQLエコシステムの深さ |
| New Relic | SaaS APM+APIチェック | 100GB/月、ユーザー1人 | AIグルーピング、フラッピング抑制 | 15〜30分 | クラウド | 強力なAPMと合成監視を同時に利用可 |
| Moesif | API分析/ビジネスメトリクス | 無料/トライアル | 挙動異常 | 20〜45分 | クラウド | 顧客別API行動分析 |
| Splunk | エンタープライズのログ/コンプライアンス | トライアル | ITSIエピソード、AIOps | 数日以上 | クラウド/自社管理 | エンタープライズ向けログ検索とガバナンス |
| Postman | すでにAPIをテストしているチーム | 無料アカウント | 基本的な監視アラート | 10分 | クラウド | APIテストコレクションを再利用 |
ThunderbitがAPIツール評価をどう加速できるか
明確にしておくと、はAPI監視ツールではありません。AIウェブスクレイパーであり、WebページをクリーンなMarkdownや構造化JSONへ変換するです。つまり、監視ツール選定の別の段階で役立ちます。つまり、プラットフォームを選ぶ前に、ベンダーの価格、プラン上限、機能説明、ドキュメントの詳細、連携一覧を集める作業です。
10社以上のベンダー価格ページを手で開き、プラン名、モニター数、チェック間隔、連携、クレジットカード要否をスプレッドシートに打ち込む代わりに、私たちはを使って、各ツールの価格・機能ページから構造化データを抽出しました。ThunderbitのAIが各ページを読み、プラン名、無料枠の詳細、有料価格、対応連携などのフィールドを提案し、その出力をエクスポート可能なスプレッドシートに整形します。
開発者向けのワークフローでも、なら同じことをプログラムで行えます。LLMやRAG向けのクリーンなMarkdownが欲しいときはDistillを使いましょう。特定のフィールドをJSONで返したいときはExtractを使います。価格ページ、ドキュメントURL、商品ページ、競合ページの一覧をまとめて処理し、非同期で結果を受け取りたいときはBatchを使います。
ワークフローは次のとおりです。
- ベンダーの価格ページ(Datadog、Checkly、UptimeRobotなど)を開く
- 「AIでフィールド提案」をクリック — ページ内容に基づいてThunderbitが列を提案します
- 「スクレイプ」をクリック — データが構造化テーブルに入ります
- サブページスクレイピングで、各ベンダーの価格、機能、ドキュメントページを取得する
- Google Sheets、Excel、Airtable、Notion、CSVにエクスポートする
APIファーストのチームなら、APIワークフローも同じくらい直接的です。
- Thunderbitで無料APIキーを取得する
- 公開ページからクリーンなMarkdownを取得するためにDistillエンドポイントを呼ぶ
- スキーマ説明を付けて構造化JSONを返すExtractエンドポイントを呼ぶ
- 大きなURLリストにはBatchエンドポイントとWebhookを使う
- 出力をアプリ、スプレッドシート、データウェアハウス、ベクターデータベース、監視ワークフローへ流し込む
10社以上を比較する場合、価格のサブページ、ドキュメント、連携ページまで含めると、手作業のコピペは簡単に2〜3時間かかります。Thunderbitなら、初回抽出は約15〜30分に短縮でき、残りは検証と判断に充てられました。運用、調達、リサーチ、AIプロダクトチームが時間に追われてツール評価をしているなら、実用的な近道です。この種のワークフローについては、のガイド、、またはの解説動画もご覧ください。
チームに最適なAPI監視ツールの選び方
「最適な」API監視ツールは、チームの規模、技術力、予算、そして製品にとって失敗が何を意味するかで変わります。
ソロ開発者にSplunkは不要です。規制の厳しいエンタープライズがcronジョブ頼みで済ませるべきではありません。APIプロダクトチームは、アップタイムpingよりもMoesifのような顧客分析を必要とするかもしれません。Eコマースチームは、ログイン、検索、カート追加、購入、決済承認のクリティカルパスを優先すべきです。AIやデータ製品チームは、フル可観測性より先に、ThunderbitのようなWebデータ抽出を必要とするかもしれません。
私の調査を通して一貫していた原則は3つです。
- ツールをユースケースに合わせること。 クイックピック表があるのには理由があります。まずそこから始めてください。
- 量より質を優先すること。 チームがアラートを無視するなら、監視はありません。あるのはノイズだけです。
- 導入速度を過小評価しないこと。 今日から稼働し、信頼できるアラートを出すモニターのほうが、完璧なプラットフォーム計画よりも価値があります。後者では、購入フローがさらに1か月も監視されないかもしれません。
複数ツールを同時に比較していて、調査を加速したいなら、でベンダーデータを一括抽出して、ひとつのスプレッドシートにまとめてみてください。APIプロダクト、RAGパイプライン、AIエージェント、市場インテリジェンスのワークフローを構築していて、クリーンなWebデータが必要なら、から始めましょう。監視ツールを代わりに選んでくれるわけではありませんが、意思決定を早め、あなた自身のプロダクトに信頼できるWebデータ層を与えてくれます。
ベストAPI監視ツールに関するFAQ
2026年に最も良い無料のAPI監視ツールは?
SaaSとして手軽なのは、UptimeRobotです。クレジットカード不要で、5分間隔のモニターを50個無料で使えます。セルフホストで自由度を求めるなら、Uptime Kumaがオープンソースで無制限、しかも90以上の通知サービスを備えた見やすいUIを持っています。メトリクスの深さが必要で、しかも技術力があるチームには、Prometheus + Grafana + Alertmanagerが最良のオープンソーススタックです。ただし、導入には分単位ではなく時間単位が必要です。
目的がアップタイム監視ではなく、API経由でWebデータを抽出することなら、Thunderbit Open APIには600回分の一度きりAPIユニットがある無料枠があり、ページをMarkdownに変換するか、スキーマベースのJSON抽出を試すには十分です。
API監視とAPMの違いは何ですか?
API監視は、外側からエンドポイントの可用性、応答時間、エラー、正しさを確認します。つまり、ユーザーや連携先が体験することをシミュレーションします。APM(Application Performance Monitoring、アプリケーション性能監視)は、アプリ内部にさらに深く入り、コードレベルのトレース、データベースクエリ、実行時エラー、キュー遅延、サービス依存関係を見ます。DatadogやNew Relicのようなツールは両方を提供しますが、UptimeRobotやUptime Kumaは外部からのアップタイムチェックに特化しています。
Thunderbit Open APIはそのどちらとも異なります。これはWebデータ抽出APIであり、外部WebサイトをMarkdownや構造化JSONに変換するのに役立ちます。LLMアプリ、リサーチワークフロー、価格インテリジェンス、データパイプラインに便利です。
APIはどのくらいの頻度で監視すべきですか?
本番で売上に直結するAPI(購入、認証、決済)は、通常1分ごとにチェックすべきです。社内向け、または低トラフィックのAPIは、5分ごとでも十分なことが多いです。ただし、頻度だけでは不十分です。リトライ、複数リージョン、意味のあるアサーションを使って、各チェックを速く、かつ信頼できるものにしてください。1分ごとでも誤警報だらけのチェックは、信頼できる5分チェックより悪いです。
Webデータ抽出のワークフローでは、頻度はソースがどれだけ変わるかによります。価格ページは毎日または毎週の抽出で足りるかもしれません。変化の速い在庫、旅行、マーケットプレイスのデータは、1時間ごと、あるいはそれ以上の頻度が必要です。ThunderbitのBatch APIとWebhookは、多数のURLをスケジュール処理したいときに役立ちます。
コードを書かずにAPI監視はできますか?
はい。UptimeRobot、Better Stack、Uptime Kumaは、すべてGUIだけで使えます。ChecklyはGUIとコードベースの両方の設定に対応しています。PostmanはコレクションベースのUIを使います。Prometheus/Grafanaは通常、YAMLとPromQLが必要です。DatadogとNew Relicはガイド付き設定から始められますが、深い計装でさらに強力になります。
コードを書かずにWebサイトのデータを抽出したいなら、ThunderbitのChrome拡張機能がノーコードの道です。アプリケーションから同じワークフローを自動化したいなら、でDistill、Extract、Batchエンドポイントを使えます。
API監視のアラート疲れをどう減らせばいいですか?
賢いアラートを持つツールを選びましょう。異常検知(Datadog、New Relic)、発火前リトライ(Checkly)、挙動異常(Moesif)、グルーピング/抑制(Prometheus Alertmanager)などです。ユーザーに見える影響に絞って、少数で確度の高いアラートから始めてください。静的しきい値ではなくSLOバーンレートアラートを使い、サービス間で重複排除し、担当に応じてルーティングし、行動可能性を測定しましょう。アラートの20%未満しか実際の対応につながっていないなら、まずノイズを減らしてください。
さらに詳しく