
「商品名と価格を全部取って」——いまWebからデータを集めるのに必要なのは、たったこの一文です。あとはAIが引き受けます。2026年から振り返ると、2015年あたりはまるで別世界でした。当時スクレイピングをやるなら、開発者にPythonスクリプトを書いてもらうか、週末をXPath学習に捧げるか、その二択しかなかったのです。
しかもこの転換は一気に押し寄せました。いまやウェブスクレイピングを業務に取り入れる企業は200万社超。市場も2024年に10億ドルの大台を突破し、2030年には倍増する見込みです。
その勢いの中心にいるのがAIウェブクローラー。レイアウトが変わっても自分で適応し、HTMLタグだけでなくページの中身そのものを読み取り、コードを書いたことのない人でも扱えます。
ここ数か月、私は15製品を片っ端から触りました。そこで見えてきたものをまとめます。共同創業者のThunderbitをなぜ1位に置いたのか、その理由も包み隠さずお話しします。
なぜAIがWebページのスクレイピングを変えるのか:新時代のWebスクレイパーツール
AIであらゆるウェブサイトからデータを抽出 Get Started Free
身も蓋もない話、これまでのウェブスクレイピングは普通のビジネスユーザー向けではありませんでした。コードやセレクターと格闘し、レイアウトが変わってもスクリプトが壊れないことを祈る——そういう代物です。ところがAIとLLMが、その前提を根本から覆しました。
実際の仕組みを並べると、こうなります。
- 自然言語で指示できる: コードをいじる代わりに、欲しいものをそのまま伝えるだけ。Thunderbitのようなツールは、平易な英語の指示を読み解き、抽出設定までやってのけます(出典)。
- 適応学習: AIスクレイパーはWebサイトのレイアウト変更に適応できるので、保守の手間が減ります。
- 動的コンテンツへの対応: 最近のサイトはJavaScriptや無限スクロールが当たり前。AI搭載ツールはこれらも操作でき、従来型では取り逃しがちなデータも取れます。
- AIパースによる構造化出力: LLMベースのスクレイパーはページ内容を実際に理解し、きれいに構造化されたデータとして出力します。
- 自動のボット対策回避: AIスクレイパーはスクレイピング対策を回避し、プロキシやヘッドレスブラウザでIPブロックを避けられます。
- 統合されたデータワークフロー: 優れたツールはデータを取るだけでなく、Google Sheets、Airtable、Notionなどへワンクリックでエクスポートし、必要な場所へ届けます(出典)。
こうしてウェブスクレイピングは、クリックひとつ、チャットを打つ感覚の作業に様変わりしました。開発者の専有物ではなくなり、営業やマーケティング、オペレーションの担当者までもがWebデータを使いこなせる時代です。
2026年に注目すべきAIウェブクローラー15選
トップ15を、Thunderbitを皮切りに見ていきます。各ツールの主な機能、想定ユーザー、価格、「何が優れているのか」を整理。得意なところもそうでないところも正直に書きます。
1. Thunderbit:誰でも使えるAIウェブスクレイパー
多少のひいき目はあると認めます。それでもThunderbitは、私が何年も「こういうのが欲しかった」と思い続けたAIウェブスクレイパーそのもの。頂点に置いた根拠を挙げます。
- 自然言語で抽出できる: Thunderbitとは“会話”する感覚。「このページの商品名と価格をすべて抽出して」と伝えれば、あとはAIが処理します(出典)。コードもセレクターも不要です。
- サブページ・多階層クロール: Thunderbitはリンクをたどってサブページもスクレイピングできます。商品一覧を取ったあと各商品ページに入って詳細を取る、といった処理を一気に行えます。
- 即座に構造化出力: AIがその場でデータを整形・クレンジングし、項目提案、形式の正規化、テキストの要約や分類まで行います。
- 幅広いソースに対応: ThunderbitはHTML専用ではなく、内蔵のOCRとビジョンAIでPDFや画像からも抽出できます(出典)。
- 業務ツールとの連携: Google Sheets、Airtable、Notion、Excelへワンクリックでエクスポート(出典)。スケジュール実行で、データをそのままチームの業務フローへ流せます。
- テンプレートを事前搭載: Amazon、LinkedIn、Zillowなど向けに、Thunderbitは用意されたスクレイピング「レシピ」を提供し、ワンクリックで抽出できます。
- 使いやすく、導入しやすい: 直感的なアシスタントを備えたクリック操作中心のUIで、数分で使い始められると評価されています。

Thunderbitは、Accenture、Grammarly、Pumaを含む世界30,000人以上のユーザーに支持されています。営業チームはリストを組み立て、不動産エージェントは物件情報をまとめ、マーケターは競合の動きを追う。しかも全部、コード一行なしです。
価格: 無料プランあり(月100ステップまで抽出可能)。有料プランは月額14.99ドルから。上位プランでも、個人や小規模チームには十分手頃です。
Thunderbitは、私が見てきた中で“ウェブをデータベースに変える”に最も近い存在です。そして、エンジニアだけでなく、誰でも使えるように作られています。
2. Crawl4AI
対象ユーザー: カスタムパイプラインを構築する開発者や技術チーム。
Crawl4AIは、速度と大規模クロールに最適化されたオープンソースのPythonフレームワークで、LLM連携を前提に設計されています。非常に高速で、動的コンテンツ向けのヘッドレスブラウザに対応し、抽出データをAIワークフローへ流しやすい形に整えます。
- 最適: 強力で自由度の高いクロールエンジンが必要な開発者。
- 価格: 無料(MITライセンス)。自分でホストして運用する必要があります。
3. ScrapeGraphAI
対象ユーザー: AIエージェントや複雑なデータパイプラインを構築する開発者やアナリスト。
ScrapeGraphAIは、プロンプト駆動のオープンソースPythonライブラリ。LLMでWebサイトを構造化データの“グラフ”に変えます。「最初の5ページから商品名、価格、評価を抽出して」と書けば、スクレイピングのワークフローを組み立てます(出典)。
- 最適: 柔軟でプロンプトベースのスクレイピングを求める技術者。
- 価格: オープンソースライブラリは無料。クラウドAPIは月額20ドルから。
4. Firecrawl
対象ユーザー: AIエージェントや大規模データパイプラインを構築する開発者。
Firecrawlは、サイト全体を“LLM対応”データに変える、AI中心のクロールプラットフォーム兼APIです(出典)。MarkdownかJSONで出力し、動的コンテンツに対応、LangChainやLlamaIndexとも連携します。
- 最適: ライブのWebデータをAIモデルに流し込みたい開発者。
- 価格: オープンソースのコアは無料。クラウドプランは月額19ドルから。
5. Browse AI
対象ユーザー: ビジネスユーザー、グロースハッカー、アナリスト。
Browse AIは、クリック操作中心のインターフェースを備えたノーコードプラットフォーム。欲しいデータをクリックして“ロボット”を訓練すると、AIがパターンを一般化して次回以降に活かします。ログイン、無限スクロール、サイト変更の監視にも対応します。
- 最適: データ収集と監視を自動化したい非エンジニア。
- 価格: 無料プラン(月50クレジット)。有料プランは月額19ドルから。
6. LLM Scraper
対象ユーザー: パースをAIに任せたい開発者。
LLM ScraperはオープンソースのJavaScript/TypeScriptライブラリ。データスキーマを定義すれば、LLMに任せて任意のWebページからそのデータを抽出できます。Playwright上に構築され、複数のLLMプロバイダーに対応、再利用可能なコードも生成できます。
- 最適: LLMを使って任意のWebページを構造化データに変えたい開発者。
- 価格: 無料(MITライセンス)。
7. Reader(Jina Reader)
対象ユーザー: LLMアプリ、チャットボット、要約ツールを構築する開発者。
Jina Readerは、Webページ(さらにPDFや画像まで)からきれいなテキストと構造化データを抽出し、LLM対応のMarkdownかJSONを返すAPI。独自のAIモデルで動き、画像にキャプションを付けることもできます。
- 最適: LLMやQ&Aシステム向けに、読みやすいクリーンなコンテンツを取得したい場合。
- 価格: 無料API(基本利用はキー不要)。
8. Bright Data
対象ユーザー: 大規模運用、コンプライアンス、信頼性を求める企業やプロユーザー。
Bright Dataは、巨大なプロキシネットワークとAI駆動のスクレイピングツールを擁する、Webデータ業界の大手。既製スクレイパー、汎用Web Scraper API、“LLM対応”データフィードを提供します。
- 最適: 大規模で安定したWebデータが必要な組織。
- 価格: 従量課金のプレミアム。無料トライアルあり。
9. Octoparse
対象ユーザー: 非技術者から中級者。
Octoparseは、ビジュアルなワークフローデザイナーとAI自動検出を備えた、定評あるノーコードツール。ログインや無限スクロールに対応し、さまざまな形式でエクスポートできます。
- 最適: アナリスト、中小企業の経営者、研究者。
- 価格: 無料プランあり。有料プランは月額119ドルから。
10. Apify
対象ユーザー: カスタムスクレイピングや自動化が必要な開発者や技術チーム。
Apifyは、スクレイピングスクリプト("actors")を実行するクラウドプラットフォームで、事前構築済みactorsのストアも備えます。拡張性が高く、AI連携やプロキシ管理にも対応します。
- 最適: カスタムスクリプトをクラウドで実行したい開発者。
- 価格: 無料プランあり。従量課金の有料プランは月額49ドルから。
11. Zyte(Scrapy Cloud)
対象ユーザー: エンタープライズ級のスクレイピングが必要な開発者や企業。
ZyteはScrapyの開発元で、クラウドプラットフォームとAIによる自動抽出を提供しています。スケジューリング、プロキシ、大規模案件を処理できます。
- 最適: 長期のスクレイピング案件を運用する開発チーム。
- 価格: 無料トライアルから、個別見積もりのエンタープライズプランまで。
12. Webscraper.io
対象ユーザー: 初心者、ジャーナリスト、研究者。
Webscraper.ioは、クリック操作でデータを抽出できる人気のChrome拡張機能。シンプルでローカル利用は無料、大規模向けにはクラウドサービスもあります。
- 最適: すぐ終わる単発のスクレイピング作業。
- 価格: 拡張機能は無料。クラウドプランは月額約50ドルから。
13. ParseHub
対象ユーザー: 基本ツール以上の機能を求める非技術者。
ParseHubはデスクトップアプリで、地図やフォームを含む動的コンテンツをスクレイピングできるビジュアルワークフローを備えます。プロジェクトはクラウドで実行でき、APIも用意されています。
- 最適: デジタルマーケター、アナリスト、ジャーナリスト。
- 価格: 無料プラン(1回200ページ)。有料プランは月額189ドルから。
14. Diffbot
対象ユーザー: 大規模な構造化Webデータを必要とする企業やAI企業。
DiffbotはコンピュータービジョンとNLPを使って、任意のWebページからデータを自動抽出し、記事、商品、巨大なナレッジグラフ向けのAPIを提供しています。
- 最適: 市場インテリジェンス、金融、AI学習データ。
- 価格: プレミアム。月額約299ドルから。
15. DataMiner
対象ユーザー: 非技術者、特に営業、マーケティング、ジャーナリズム分野。
DataMinerは、手早くクリック操作でWebデータを抽出できるChrome拡張機能。「レシピ」のライブラリが用意され、Google Sheetsへ直接エクスポートできます。
- 最適: 表やリストをスプレッドシートに出力するような素早い作業。
- 価格: 無料プラン(1日500ページ)。Proは月額約19ドルから。
上位AIウェブスクレイパーツールの比較:どれがあなたに合うか?
選ぶ手がかりに、ざっと並べた比較表をどうぞ。
| ツール | AI/LLMの活用 | 使いやすさ | 出力/連携 | 最適な用途 | 価格 |
|---|---|---|---|---|---|
| Thunderbit | 自然言語UI。AIが項目を提案 | 最も簡単(ノーコードチャット) | Sheets、Airtable、Notionへ出力 | 非技術系チーム | 無料プランあり。Proは約30ドル/月 |
| Crawl4AI | AI対応クロール。LLM連携可 | 難しい(Pythonで記述) | ライブラリ/CLI。コードで連携 | 高速なAIデータパイプラインが必要な開発者 | 無料 |
| ScrapeGraphAI | LLMプロンプトでスクレイピングパイプライン | 中程度(ある程度のコーディングまたはAPI利用) | API/SDK。JSON出力 | AIエージェントを作る開発者/アナリスト | 無料OSS。APIは月20ドル〜 |
| Firecrawl | LLM対応のMarkdown/JSONへクロール | 中程度(API/SDK利用) | Py、NodeなどのSDK。LangChain連携 | ライブWebデータをAIに統合したい開発者 | 無料+有料クラウド |
| Browse AI | AI支援のクリック操作型 | 簡単(ノーコード) | 7,000以上のアプリ連携(Zapier) | Web監視を自動化したい非技術者 | 無料50回。有料は月19ドル〜 |
| LLM Scraper | LLMでページをスキーマにパース | 難しい(TS/JSで記述) | コードライブラリ。JSON出力 | AIにパースを任せたい開発者 | 無料(自分のLLM APIを使用) |
| Reader (Jina) | AIモデルがテキスト/JSONを抽出 | 簡単(シンプルなAPI呼び出し) | REST APIがMarkdown/JSONを返す | Web検索/コンテンツをLLMに追加する開発者 | 無料API |
| Bright Data | AI強化スクレイピングAPI。大規模プロキシ網 | 難しい(API、技術者向け) | API/SDK。データストリームまたはデータセット | エンタープライズ規模 | 従量課金 |
| Octoparse | AIによるリスト自動検出 | 中程度(ノーコードアプリ) | CSV/Excel、結果用API | 中級ユーザー | 無料制限あり。有料は59〜166ドル/月 |
| Apify | 一部AI機能(Actors、AIチュートリアル) | 難しい(コードでスクリプト作成) | 高機能API。LangChainと連携 | クラウドでカスタムスクレイピングしたい開発者 | 無料プラン。従量課金 |
| Zyte (Scrapy) | MLベースの自動抽出。Scrapyフレームワーク | 難しい(Pythonで記述) | API、Scrapy Cloud UI。JSON/CSV | 開発チーム、長期案件 | 個別価格設定 |
| Webscraper.io | AIなし(手動テンプレート) | 簡単(ブラウザ拡張) | CSVダウンロード、Cloud API | 初心者、短時間の単発スクレイピング | 拡張機能は無料。Cloudは約50ドル/月 |
| ParseHub | 明示的なLLMなし。ビジュアルビルダー | 中程度(ノーコードアプリ) | JSON/CSV。クラウド実行用API | 複雑なサイトをスクレイピングする非開発者 | 200ページ無料。有料は189ドル/月〜 |
| Diffbot | どのページでも使えるAIビジョン/NLP。ナレッジグラフ | 簡単(API呼び出しのみ) | API(Article/Prod/...)+Knowledge Graph検索 | エンタープライズ、構造化Webデータ | 月299ドル前後から |
| DataMiner | LLMなし。コミュニティレシピ | 最も簡単(ブラウザUI) | Excel/CSV出力。Google Sheets | スプレッドシートに出したい非技術者 | 無料制限あり。Proは約19ドル/月 |
ツールのカテゴリ:開発者向けの高機能ツールから、ビジネス向けのWebスクレイパーまで
15製品を見通しやすくするため、いくつかのグループに切り分けます。
1. 開発者向け・オープンソースの高機能ツール
- 例: Crawl4AI、LLM Scraper、Apify、Zyte/Scrapy、Firecrawl
- 強み: 高い柔軟性、拡張性、カスタマイズ性。独自パイプラインやAIモデル連携に最適。
- 注意点: コーディングスキルとある程度の設定が要ります。
- 用途: カスタムデータパイプライン、複雑なサイトのスクレイピング、社内システム連携。
2. AI統合型のスクレイピングエージェント
- 例: Thunderbit、ScrapeGraphAI、Firecrawl、Reader(Jina)、LLM Scraper
- 強み: スクレイピングとデータ理解のギャップを埋めます。自然言語インターフェースで使いやすい。
- 注意点: 発展途上の製品もあり、細かな制御には向かない場合があります。
- 用途: すぐ答えやデータセットが欲しいとき、自律エージェント構築、ライブデータをLLMへ。
3. ノーコード/ローコードのビジネス向けスクレイパー
- 例: Thunderbit、Browse AI、Octoparse、ParseHub、Webscraper.io、DataMiner
- 強み: 使いやすく、ほぼコード不要。日常業務に向いています。
- 注意点: 非常に複雑なサイトや超大規模処理では苦戦することがあります。
- 用途: リード獲得、競合モニタリング、調査プロジェクト、単発のデータ抽出。
4. エンタープライズ向けデータプラットフォームとサービス
- 例: Bright Data、Diffbot、Zyte
- 強み: フルスタックのソリューション、マネージドサービス、コンプライアンス、大規模での信頼性。
- 注意点: コストが高く、導入にも時間がかかります。
- 用途: 大規模で常時稼働のデータパイプライン、市場インテリジェンス、AI学習データ。
Webページのスクレイピング要件に合ったAIウェブクローラーの選び方
データスクレイピングとは何か、どう行うか Get Started Free
選択肢が多いと、自分に合う一本を選ぶのは意外と迷います。私が普段たどる手順を共有します。
- 目的とデータ要件を明確にする: どのサイトから、どんなデータが必要か。頻度は? 量は? 取得後に何をする?
- 技術力を見極める: ノーコードならThunderbit、Browse AI、Octoparse。少しスクリプトを書けるならLLM ScraperやDataMiner。開発に強いならCrawl4AI、Apify、Zyteです。
- 頻度と規模を考える: 単発なら無料ツールで十分。定期実行ならスケジューリング、大規模ならエンタープライズ向けやオープンソースのスケール運用が向きます。
- 予算と価格モデル: 無料プランは検証に最適。サブスク型か従量課金型かは用途次第です。
- 試用とPoC: 実データでいくつか試しましょう。ほとんどのツールに無料枠があります。
- 保守とサポート: サイトが変わったとき誰が直すのか。AI付きノーコードなら軽微な変更を自動修正することもありますが、オープンソースは自分かコミュニティ頼みです。
- 用途別にツールを当てはめる: リード抽出ならThunderbitかBrowse AI。ツイート収集ならDataMinerかWebscraper.io。ニュース記事ならJina ReaderかZyte。比較サイトならApifyかZyte。
- 代替案を用意する: サイトによっては1つのツールがうまく動かないことがあります。バックアップを持っておきましょう。
“正しい”ツールとは、必要なデータを最小限の手間と予算で取れるもの。複数ツールの組み合わせになることもあります。
Thunderbit vs. 従来型Webスクレイパーツール:何が違うのか?
Thunderbitがどこで一線を画すのか、具体的に並べます。
- 自然言語インターフェース: コードもクリック操作の細かい手順も不要。欲しいものを伝えるだけです(出典)。
- 設定不要+テンプレート提案: ページネーションやサブページを自動検出し、よくあるサイト向けのテンプレートまで提案します(出典)。
- AIによるデータクレンジングと拡張: スクレイピングしながら、要約、分類、翻訳、データ拡張までこなせます(出典)。
- 保守の手間が少ない: ThunderbitのAIはサイトの小さな変更に強く、壊れにくい設計です。
- 業務ツール連携: Google Sheets、Airtable、Notionへ直接エクスポートでき、CSVの面倒は不要です(出典)。
- 価値を出すまでが速い: アイデアからデータ取得まで、数日でなく数分です。
- 学習コスト: Webを見て必要なことを説明できれば、Thunderbitは使えます。
- 柔軟性: Webサイト、PDF、画像を同じツールでまとめて扱えます。
つまりThunderbitは、ただのスクレイパーではありません。営業、マーケティング、EC、不動産——どんな業務フローにも溶け込むデータアシスタントです。
AIウェブスクレイパーツールを使う際のWebページスクレイピングのベストプラクティス
AIウェブスクレイパーを最大限に活用するコツを並べます。
- 必要なデータを明確にする: どの項目が欲しいか、何ページ分か、どんな形式かをはっきりさせましょう。
- AIの提案を活用する: フィールド検出やAI提案で、見落としそうな重要データを拾いましょう(出典)。
- 小さく始めて検証する: 少量のサンプルでテストし、出力を確認し、必要に応じて調整します。
- 動的コンテンツに対応する: ページネーション、無限スクロールなどの動的要素に対応しているか確認しましょう。
- サイトのポリシーを尊重する: robots.txtを確認し、機微なデータは避け、レート制限を守りましょう。
- 自動化のために連携する: エクスポートやWebhookで、抽出データをそのまま業務フローへつなぎます。
- データ品質を保つ: 目視確認し、後処理を行い、エラーを監視しましょう。
- プロンプトは簡潔に: AI駆動ツールでは、明確で具体的な指示ほど良い結果につながります。
- コミュニティから学ぶ: フォーラムやコミュニティで、コツやトラブル解決法を学びましょう。
- 最新情報を追う: AIツールは進化が速いので、新機能や改善を定期的に確認しましょう。
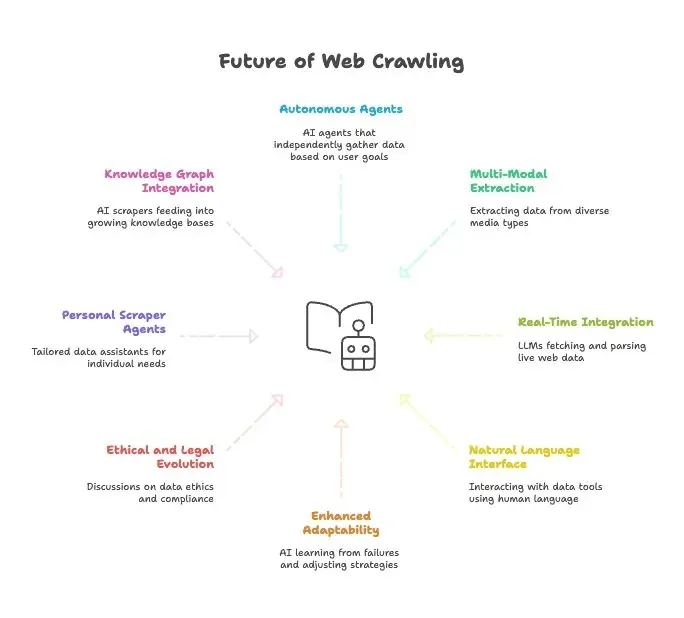
Webスクレイピングの未来:AI、LLM、そして自然言語型Webスクレイピングエージェントの台頭
この先、AIとウェブスクレイピングの距離はますます縮まります。
- 完全自律型のスクレイピングエージェント: 近いうちに、AIエージェントへ最終目標を伝えるだけで、取り方を自分で考えるようになります。
- マルチモーダルなデータ抽出: スクレイパーはテキスト、画像、PDF、さらには動画からもデータを取り出します。
- AIモデルとのリアルタイム連携: LLMに、ライブWebデータを取得・パースする標準モジュールが組み込まれていくでしょう。
- すべてが自然言語化: データツールを人と話す感覚で扱えるようになり、収集や変換が誰にでも使いやすくなります。
- 適応力の向上: AIスクレイパーは失敗から学び、戦略を自動で調整します。
- 倫理と法規制の進化: データ倫理、コンプライアンス、公正利用をめぐる議論はさらに増えるはずです。
- 個人向けスクレイピングエージェント: ニュースや求人情報を自分向けに集めるパーソナルデータアシスタントを想像してみてください。
- ナレッジグラフとの統合: AIスクレイパーは成長し続ける知識ベースへデータを供給し、より賢いAIを支えます。
つまるところ、Webスクレイピングの未来はAIの未来と地続きです。ツールは日ごとに賢く、自律的に、扱いやすくなっています。
まとめ:適切なAIウェブクローラーでビジネス価値を引き出す
AIの登場で、Webスクレイピングは一部の人だけが扱える技術スキルから、ビジネスの土台となる能力へ姿を変えました。ここまでの15ツールは、開発者向けの高機能なものからビジネスに寄り添うアシスタントまで、2026年にできることの最前線を示しています。
本当の決め手はどこか。ツール選びひとつでWebデータから引き出せる価値が大きく変わる点です。非技術チームにとって、Thunderbitはウェブを構造化された分析可能なデータベースへ作り替える、いちばん手軽な手段。コードも手間もいらず、残るのは結果だけです。
リード収集、競合監視、次世代AIモデルへのデータ供給——目的が何であれ、まず要件を書き出し、いくつか試し、手に馴染むものを見つけてください。Webスクレイピングの未来を今この瞬間に味わいたいなら、Thunderbitをぜひ。欲しいインサイトは、プロンプトひとつで手に入ります。
さらに深掘りしたい方は、解説記事やチュートリアル、AI搭載データ抽出の最新動向がそろうThunderbit Blogものぞいてみてください。
参考記事:
AIウェブスクレイパーを試す Get Started Free
FAQ
1. AIウェブクローラーとは何ですか?従来のWebスクレイパーとどう違いますか?
AIウェブクローラーは、自然言語処理と機械学習でWebデータを理解し、抽出し、構造化します。手動コーディングやXPathセレクターが要る従来型スクレイパーと違い、動的コンテンツに対応し、レイアウト変更にも適応し、平易な英語の指示を解釈できます。
2. ThunderbitのようなAIウェブスクレイピングツールは誰が使うべきですか?
Thunderbitは、非技術者にも技術者にも向けて作られています。営業、マーケティング、オペレーション、リサーチ、ECの担当者が、コードなしでWebサイト、PDF、画像から構造化データを抽出したいときに最適です。
3. Thunderbitが他のAIウェブクローラーと比べて優れている点は何ですか?
Thunderbitは、自然言語インターフェース、多階層クロール、自動データ構造化、OCR対応、Google SheetsやAirtableへのシームレスなエクスポートを備えます。AIによる項目提案や、人気サイト向けの事前構築テンプレートも含まれます。
4. 2026年に無料で使えるAIウェブスクレイピングの選択肢はありますか?
はい。Thunderbit、Browse AI、DataMinerなど、制限付きの無料プランを提供するツールは多くあります。開発者向けには、Crawl4AIやScrapeGraphAIのようなオープンソース製品が、技術的なセットアップは要るものの無料でフル機能を使えます。
5. 自分の用途に合ったAIウェブクローラーはどう選べばよいですか?
まず、データの目的、技術力、予算、規模の要件を整理しましょう。ノーコードで使いやすいものなら、ThunderbitやBrowse AIが有力。大規模運用やカスタム要件があるなら、ApifyやBright Dataがより適しています。




