
ひとつ、秘密をお話ししましょう。私は以前、ウェブスクレイピングはパーカーを着たハッカーや、やたらとモニターの多いデータサイエンティストだけのものだと思っていました。でも今では、Webサイトからデータを抽出することは、朝のコーヒーを買うのと同じくらい、ビジネスでは当たり前になっています。しかもありがたいことに、Pythonを覚える必要も、昼までにエスプレッソを3杯飲む必要もありません。実際、AIウェブスクレイパーの台頭によって、「HTMLってサブウェイの新しいサンドイッチ?」と思っている人でさえ、Web上のデータを構造化して取り出せるようになりました。
Webサイトの製品情報、営業リード、価格表をスプレッドシートにコピペした経験があるなら、それはあなただけではありません。現在、約73%の企業が、市場分析や競合追跡のためにウェブスクレイピングを活用しています。そして、ウェブスクレイピングソフトウェア市場は2032年までに24.9億ドルに達すると予測されています。つまり、Webデータ抽出はもはやテック業界だけの特権ではありません。営業担当でも、マーケターでも、単純作業のデータ入力をやめたい人でも、このガイドは役に立ちます。基本から、従来型とAI活用型の違いまで、そして始め方まで、フード付きパーカーなしでご案内します。
ウェブスクレイパーの基本:Webサイトからデータをスクレイピングするとはどういうことか?
まずはシンプルにいきましょう。ウェブスクレイパーとは、Webサイトからデータを自動で収集するツール(またはスクリプト、Chrome拡張機能)のことです。繰り返し作業を文句ひとつ言わずにこなす、超高速のインターンのようなものだと思ってください。あなたが1行ずつコピー&ペーストする代わりに、ウェブスクレイパーは数秒で全部やってくれます。しかも、コーヒーブレイクを要求することもありません。
データには、主に次の2種類があります。
- 構造化データ:製品名、価格、メールアドレスの一覧のような、きれいに整理されていてスプレッドシートにそのまま使えるデータです。ラベル付きで整理されているため、分析しやすいのが特徴です。
- 非構造化データ:ブログ記事、レビュー、画像など、行や列にきれいに収まらない自由度の高いデータです。多くのウェブスクレイピング案件は、この非構造化データを構造化データに変えることを目的としています。そうすることで、実際に活用できるようになります。
Webサイトの表をExcelにコピーしたことがあるなら、おめでとうございます。それは手作業のウェブスクレイピングをやったということです。では、それを1万ページ分やると想像してみてください。(実際にはやらないでください。それこそウェブスクレイパーの出番です。)
なぜWebサイトからデータをスクレイピングするのか? 重要なビジネス上のメリット
では、そもそもなぜデータをスクレイピングするのでしょうか。答えはシンプルです。ビジネスはデータで動き、Webは世界最大のデータベースだからです。 営業、マーケティング、EC、不動産のどれでも、Webデータ抽出は大きな武器になります。
代表的な活用例を見てみましょう。
| 用途 | 説明 | ROI/メリットの例 |
|---|---|---|
| リード獲得 | ディレクトリやSNSから連絡先、メールアドレス、企業リストを収集する | 営業チームの工数を削減し、より有望な見込み客を見つけられる |
| 価格モニタリング | 競合の価格、在庫、プロモーションをリアルタイムで追跡する | 小売業者が動的に価格を調整し、売上を4%向上 |
| 市場調査 | レビュー、ニュース、SNSの反応を集約してトレンドを把握する | マーケターがリアルタイムの消費者インサイトに合わせて施策を最適化できる |
| 競合分析 | 競合の製品カタログ、新製品、コンテンツを監視する | 企業が市場変化により素早く対応できる |
| 不動産インテリジェンス | 物件情報、価格、空室状況をスクレイピングする | 仲介業者や投資家が市場より先に好機をつかめる |
実際、英国とヨーロッパでは25〜30%の小売業者が、競合価格のスクレイピングを活用したダイナミックプライシング戦略を採用しています。John LewisやASOSのような企業も、Webデータを賢く活用することで、目に見える売上向上を実現しています。
従来型ウェブスクレイパーツール:どう動くのか?
AIが本領を発揮する前の、いわば「昔ながら」のデータスクレイピングに戻ってみましょう。従来型のウェブスクレイパーは、通常、Pythonで書かれたスクリプトやブラウザ拡張機能で、決められたルールに従って欲しいデータを取得します。
一般的な流れは次のとおりです。
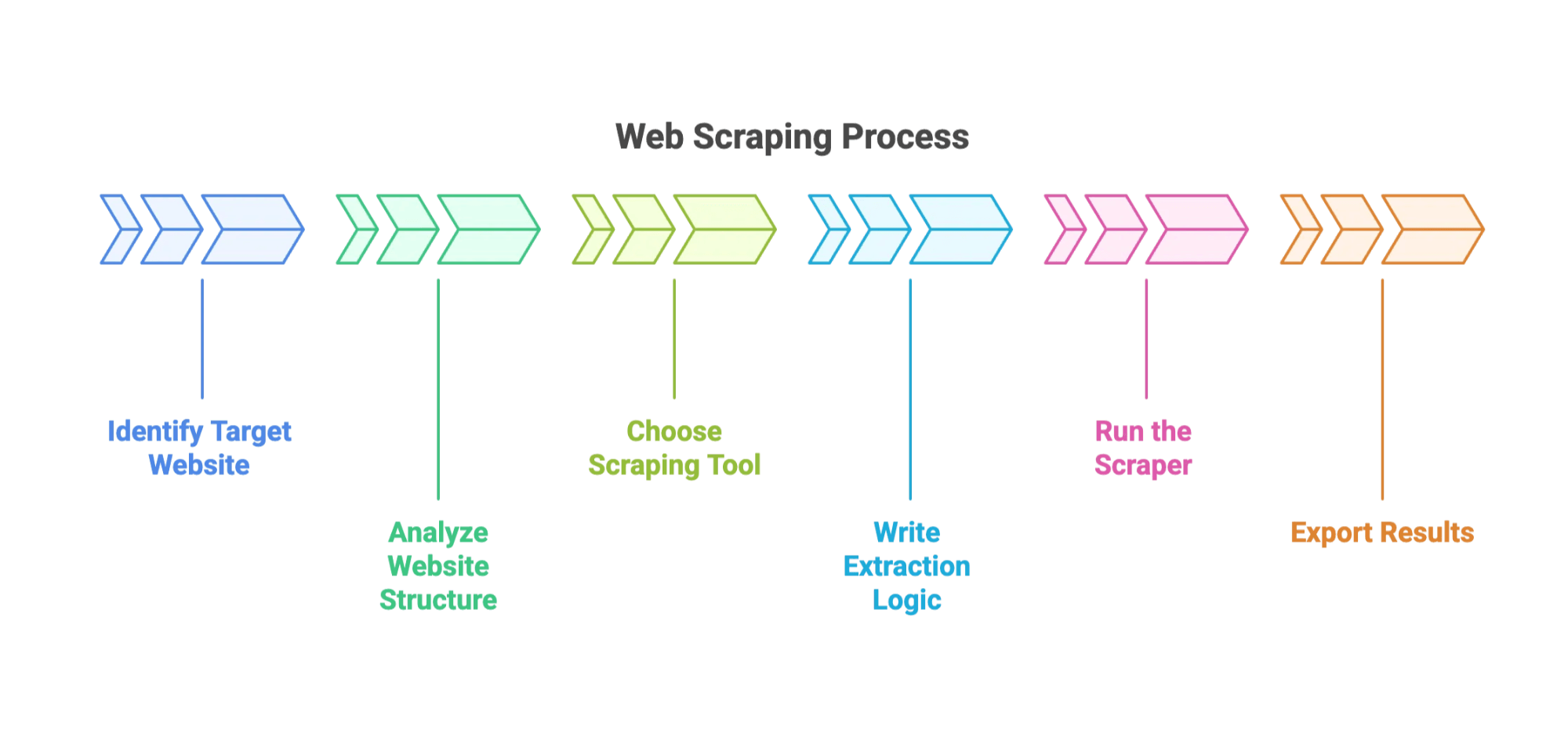
- 対象のWebサイトとデータ項目を特定する。
- Webサイトの構造を分析する。 (ブラウザの開発者ツールを使ってHTMLを調べる作業です。まるでデジタル考古学のようなものです。)
- ツールを選ぶ: 代表的な選択肢にはBeautifulSoup、Scrapy、ブラウザ向けプラグインがあります。
- 抽出ロジックを書く: CSSセレクターやXPathを指定して、ツールにデータの見つけ方を教えます。
- スクレイパーを実行する: 複数ページにわたってデータを収集します。
- 結果をエクスポートする: 通常はCSV、JSON、またはそのままExcelに出力します。
ステップごとの解説:従来型ウェブスクレイパーでデータを抽出する方法
たとえば、ECサイトの商品一覧をスクレイピングしたいとしましょう。初心者向けに、流れを見てみます。
- ステップ1: PythonとBeautifulSoupライブラリをインストールする。
- ステップ2: ブラウザで商品ページを調べ、商品名と価格が入っているHTMLタグを見つける。
- ステップ3: ページを取得し、HTMLを解析して、必要な項目を取り出す短いスクリプトを書く。
- ステップ4: 複数ページをループで処理する(ページネーションに対応する)。
- ステップ5: データをCSVファイルに書き出す。
やり方は単純そうに見えますが、最初のスクリプトはたいてい一度は壊れます。私の最初の試みでは、クラス名のスペルを間違えたせいで、「None」が500行も取れました。やれやれ。
従来型ウェブスクレイパーでよくある課題
ここからが少し難しくなります。
- Webサイトの変更: ほんの小さなレイアウト変更でも、スクレイパーが動かなくなることがあります。10〜15%のスクレイパーは、変更のたびに毎週どこかしら壊れています。
- ボット対策: CAPTCHA、IPブロック、レート制限によって、処理が止まることがあります。プロキシや待機時間の調整が必要で、場合によってはCAPTCHAを解く必要もあります。
- 必要な技術スキル: コーディングとHTML/CSSの知識が求められます。
- 保守: スクレイパーは定期的な見守りと更新が必要です。
- 汚れたデータ: 形式の不一致、欠損値、文字化けの処理に時間がかかります。
初心者にとっては、レシピが頻繁に変わり、ときどきオーブンに締め出される状態でケーキを焼くようなものに感じるでしょう。
AIウェブスクレイパーの登場:データ抽出を誰でも使えるものにする
AIを使ってあらゆるWebサイトからデータをスクレイピング Get Started Free
ここからが本題です。AIウェブスクレイパーは、データ抽出の常識を変えています。(おっと、言ってはいけないフレーズを使いそうになりました。)コードを書く代わりに、セレクターをいじる代わりに、欲しいものを普通の英語で伝えるだけで大丈夫です。あとはAIが判断してくれます。
Thunderbit(そう、私たちです!)は、その新しい世代の代表例です。Thunderbit を使えば、自然言語であらゆるWebサイトから構造化データを抽出できます。コーディングは不要です。営業でも、マーケティングでも、ECでも、必要なデータを数日ではなく、数分で集められます。
ThunderbitのAIウェブスクレイパー:データ抽出をどう簡単にするのか
Thunderbitがどれほど便利か、順にご紹介します。
- AIによる項目提案: 「AI Suggest Fields」をクリックするだけで、ThunderbitがWebサイトを読み取り、列名を提案し、各項目の抽出方法まで示してくれます。
- サブページスクレイピング: さらに詳しい情報が必要ですか? Thunderbitは各サブページ(個別の商品ページなど)を訪れて、データ表を自動で充実させます。
- 即時テンプレート: AmazonやZillowのような人気サイトには、あらかじめ用意されたテンプレートを使えます。設定は不要です。
- 無料データエクスポート: データはExcel、Google Sheets、Airtable、Notionに出力できます。CSVやJSONでのダウンロードも可能です。追加料金はありません。
- 定期スクレイピング: 繰り返し実行を設定して、データを常に最新に保てます。価格モニタリングやリード更新に最適です。
- AI自動入力: AIにオンラインフォームを入力させることもできます。(はい、10ページあるベンダー登録フォームでも大丈夫です。)
- メール、電話番号、画像の抽出: 連絡先情報や画像をワンクリックで取得できます。
しかも一番いいのは、コードを少しも知る必要がないことです。ThunderbitのChrome拡張機能はこちらから利用でき、公式サイトでも詳しくご覧いただけます。
従来型とAIウェブスクレイパーの比較
2つのアプローチを比べてみましょう。
| 項目 | 従来型ウェブスクレイパー | AIウェブスクレイパー(Thunderbit) |
|---|---|---|
| 使いやすさ | コーディングや複雑な設定が必要 | ノーコード、自然言語のインターフェース |
| 柔軟性 | サイト変更に弱い | レイアウト変更にAIが自動対応 |
| 保守性 | 高い。頻繁な更新が必要 | 低い。多くの変更をAIが処理 |
| 技術スキル | プログラミングとHTMLの知識が必要 | ビジネスユーザー向けに設計 |
| セットアップ速度 | 数時間〜数日 | 数分 |
| データ処理 | 手動でのクリーニングが必要 | AIが自動でデータを整形・構造化 |
| コスト | 無料(オープンソース)だが、時間コストが大きい | 手頃なプランと無料エクスポートあり |
多くのビジネスユーザー、特に初心者にとっては、ThunderbitのようなAIウェブスクレイパーが、速さ、シンプルさ、信頼性の面で明らかな勝者です。従来型ツールにも、非常にカスタム性の高い大規模案件では出番がありますが、95%の用途ではAIを選ぶのが正解です。
初心者向けステップガイド:Webサイトからデータをスクレイピングする方法
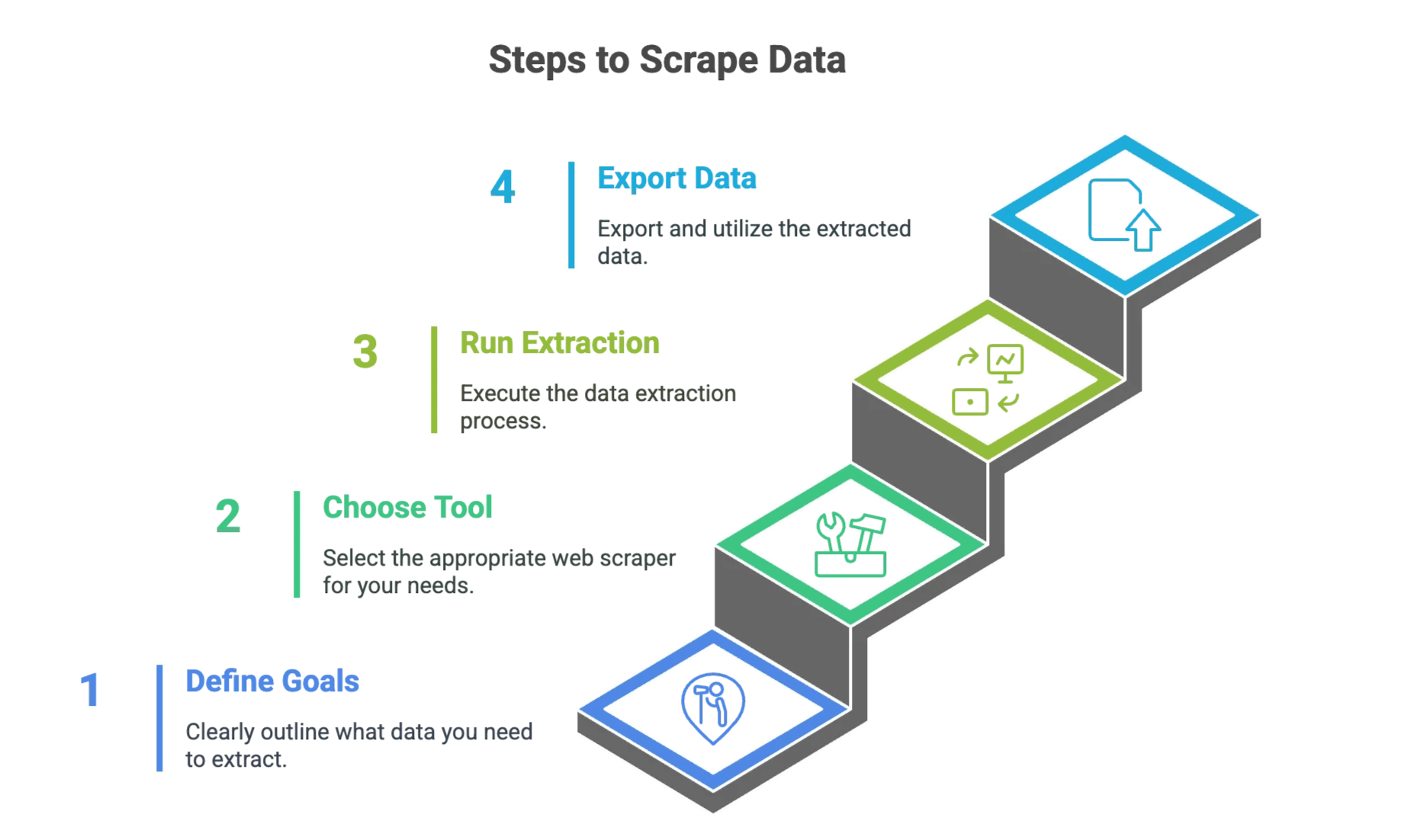
ステップ1:データ抽出の目的を明確にする
始める前に、必要なものをはっきりさせましょう。自分に次の質問をしてみてください。
- どのWebサイトをスクレイピングしたいか?
- どのデータ項目が重要か?(例:商品名、価格、メールアドレス、電話番号)
- どのくらいの頻度でこのデータが必要か?(一度きりか、定期的か)
チェックリストを作りましょう。たとえば、「XYZ.com の最初の5ページから、商品名、価格、評価を集めたい」といった具合です。
ステップ2:適切なウェブスクレイパーツールを選ぶ
簡単な判断フローはこちらです。
- コードに慣れていて、完全にコントロールしたいですか? BeautifulSoupやScrapyのような従来型ツールを試しましょう。
- 速さ、使いやすさ、ノーコードを重視しますか? Thunderbit のようなAIウェブスクレイパーを選びましょう。
迷ったら、まずはAIから始めるのがおすすめです。あとから深く掘り下げることもできます。
ステップ3:データ抽出を設定して実行する
従来型アプローチ
- ツールをインストールする: Pythonと必要なライブラリをセットアップします。
- Webサイトを調べる: ブラウザのDevToolsを使ってHTML構造を確認します。
- スクリプトを書く: 各データ項目をどう見つけて抽出するかを定義します。
- 1ページでテストする: 正しいデータが取れているか確認します。
- 規模を広げる: ページネーションやループを追加して、より多くのページを対象にします。
- データをエクスポートする: CSVまたはJSONとして保存します。
AIアプローチ(Thunderbit)
- Thunderbit Chrome拡張機能をインストールする: こちらからダウンロードできます。
- 対象のWebサイトを開く: スクレイピングしたいページに移動します。
- 「AI Suggest Fields」をクリックする: Thunderbitがページを読み取り、列を提案します。
- プレビューを確認する: データが正しく表示されているかチェックします。必要に応じて列を調整します。
- 「Scrape」をクリックする: Thunderbitがデータを収集してくれます。
- データをエクスポートする: Excel、Google Sheets、Airtable、Notionにダウンロードします。
操作の流れを映像で見たい方は、ThunderbitのYouTubeチャンネルをご覧ください。
ステップ4:データをエクスポートして活用する
データを取得したら、次のように使えます。
- お好みのツールにエクスポートする: Excel、Google Sheets、Airtable、Notion、CSV、JSONなど。
- 業務フローに組み込む: 営業アプローチ、価格分析、市場調査など、業務に合わせて活用できます。
- クリーニングと検証を行う: AIを使っていても、精度確認のためにサンプルを目視チェックするのが賢明です。
データ抽出を成功させるコツ:よくある落とし穴を避ける
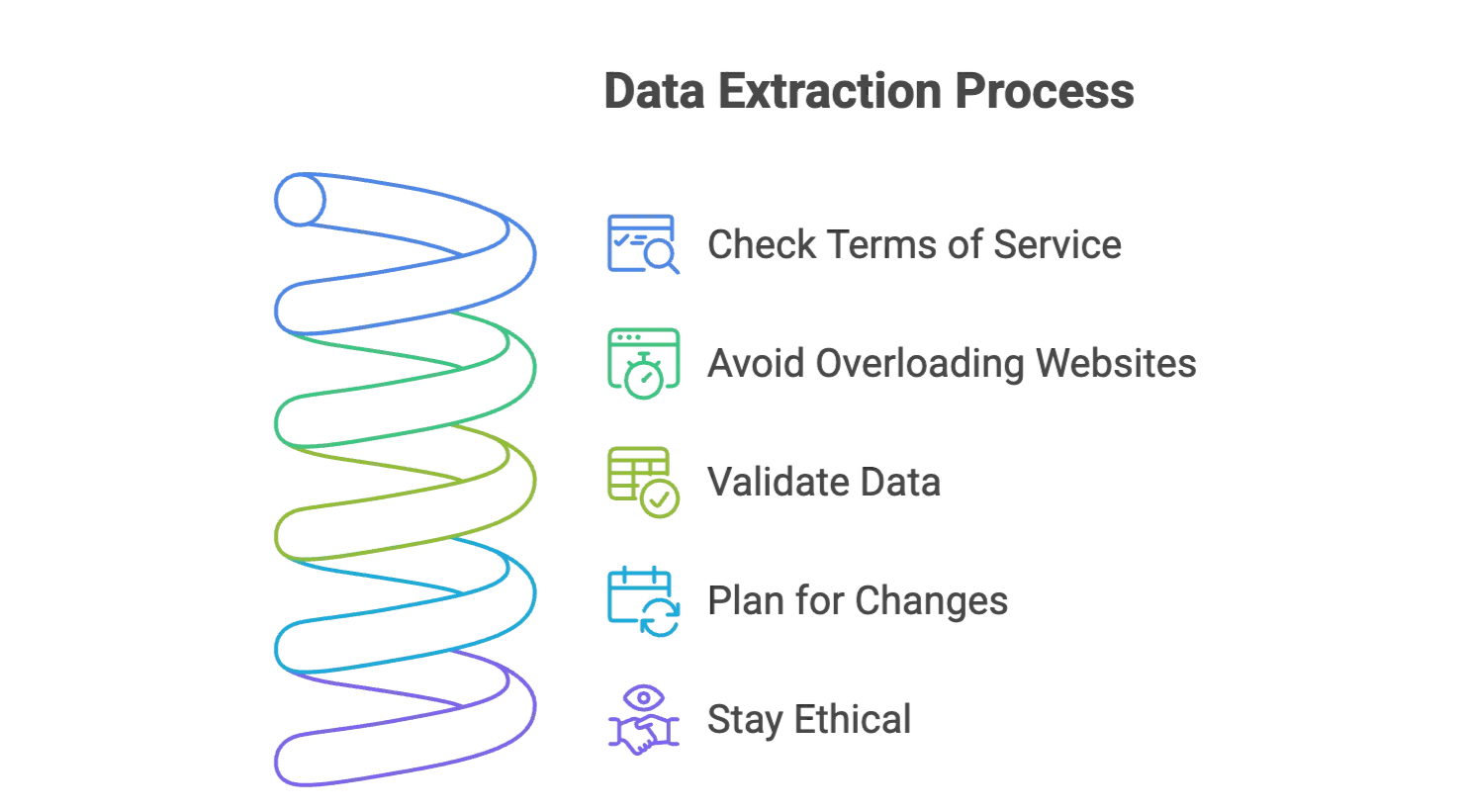
- Webサイトの利用規約を確認する: データをスクレイピングしてよいか必ず確認しましょう。公開情報に限定し、機微な個人データは避けてください。
- Webサイトに負荷をかけすぎない: 従来型ツールではリクエストの間隔を空けるか、Thunderbitに任せましょう。
- データを検証する: 結果の一部は必ずサンプル確認して、正確性をチェックしてください。
- 変更に備える: Webサイトは常に更新されます。ThunderbitのようなAIスクレイパーは自動で適応しますが、大きな変更がないか監視するのは有効です。
- 倫理を守る: 必要なものだけをスクレイピングし、レポートや記事で使う場合は出典を明示しましょう。
さらに詳しいヒントは、データスクレイピングとは?2025年版のやり方 と AIを使ってあらゆるWebサイトをスクレイピングする方法 もご覧ください。
まとめと重要ポイント
ウェブスクレイピングは、手書きのスクリプトでやっていた時代から、今日のAI搭載で初心者にも使いやすいツールの時代へと大きく進化しました。主な違いは次のとおりです。

- 従来型スクレイパー は柔軟に制御できますが、コーディング、保守、忍耐が必要です。
- AIウェブスクレイパー のThunderbit のようなツールなら、自然言語の指示、即時プレビュー、サブページや定期スクレイピングなどの強力な機能によって、誰でもデータ抽出を使えるようになります。
ウェブスクレイピングが初めてでも、怖がる必要はありません。今ほどツールが使いやすい時代はなく、ビジネス上の価値も明らかです。リード獲得、価格モニタリング、あるいは単純なコピペ作業から解放されたいだけでも、AIウェブスクレイパーは頼れる相棒になります。
次にWebデータの山を前にして立ち尽くしたら、思い出してください。コンピューターサイエンスの博士号も、パーカーも必要ありません。必要なのは、明確な目的、適切なツール、そしておいしいコーヒーくらいです。
準備はできましたか? Thunderbitをインストールして、Webデータ抽出がどれほど簡単か体験してみてください。
もっと知りたい方は、Thunderbit Blog で、Amazon、Google、PDFなどのスクレイピングを詳しく解説した記事をご覧ください。スクレイピングを楽しみましょう!
Thunderbit AIウェブスクレイパーを今すぐ試す Get Started Free
よくある質問
Q1: ウェブスクレイピングは合法ですか? A: はい。公開データのスクレイピングは、多くの国で一般的に合法です。ただし、必ずWebサイトの利用規約を確認し、機微な個人データや個人情報のスクレイピングは避けてください。
Q2: ログインが必要なWebサイトもスクレイピングできますか? A: はい、可能ですが、より複雑でサイトのポリシーに抵触する場合があります。セッション管理や認証済みスクレイピングツールが必要になり、法的な影響も確認することが重要です。
Q3: JavaScriptが多用されたWebサイトからデータをスクレイピングするにはどうすればよいですか? A: ヘッドレスブラウザのような動的レンダリング対応ツールや、人の操作を再現してJavaScriptで描画された内容を解析できるAIスクレイパーを使いましょう。
Q4: ブロックされないためのベストプラクティスは何ですか? A: レート制限、ランダムな待機時間、ユーザーエージェントの切り替えを活用し、過度に攻撃的なスクレイピングは避けましょう。AIベースのスクレイパーは、こうした対策を自動で処理することが多いです。
さらに読む
-
ウェブスクレイピングの合法性を理解する:世界の知見と統計 法的ガイドライン、業界統計、倫理的なベストプラクティスの概要。
-
ウェブスクレイピングの現状 2025 トレンド、市場成長、Webデータ抽出におけるAIの役割(2024〜2025年)。
-
robots.txtファイルとは? ベストプラクティスと構文のガイド robots.txtファイルの読み方を学び、倫理的かつ合法的なスクレイピングに役立てましょう。




