ウェブスクレイピングの世界に初めて飛び込んだあの頃を思い出します。2015年、ニュージャージーの小さなアパートで、コーヒー片手にPythonスクリプトと格闘していた日々。ターゲットのサイトがレイアウトを変えるたびに、Beautiful SoupやSeleniumで書いたコードがすぐ壊れてしまい、何度も修正していました。時は流れ2025年、「beautiful soup vs selenium」の論争は今も続いていますが、AIの進化によって状況は大きく変わりました。今や最新のAIウェブスクレイパーは、HTMLを読むだけでなく、ページの意味まで理解し、人間のようにリンクをたどり、自然言語で指示するだけでデータを抽出。さらに、その場でデータの整理や要約、翻訳まで自動でやってくれる時代になりました。

ウェブスクレイピングは、もはやエンジニアだけのものではありません。営業、マーケティング、EC、オペレーションなど、あらゆるビジネス部門が「新鮮で構造化されたデータ」を求めています。ウェブスクレイピング市場はすでに10億ドル規模に成長し、のようなAI搭載ツールが登場した今、「どのPythonウェブスクレイピングツールを使うか?」ではなく、「いかに手間やメンテナンス、技術的な負担を減らして必要なデータを手に入れるか?」が重要なテーマになっています。ここからはbeautifulsoup pythonとselenium web scrapingの違い、そしてAIウェブスクレイパーがもたらす新しい選択肢について、詳しく見ていきましょう。
Beautiful SoupとSeleniumの違いをざっくり解説
「python web scraper」と検索したことがある人なら、との両方に出会ったことがあるはず。では、実際に何が違うのでしょう?
Beautiful Soupは、まるで優秀な図書館司書のような存在。Pythonで書かれたライブラリで、静的なHTMLやXMLファイルからデータを抜き出すのが得意です。必要な情報がページのソースにそのまま載っていれば、Beautiful Soupがサクッと見つけて整理してくれます。動作も軽快で、ページを「人間の目で見る」必要はなく、生のHTMLを直接解析します。
一方、Seleniumは、実際にブラウザを操作できるロボットのようなもの。ボタンをクリックしたり、フォームに入力したり、ログインしたり、スクロールしたり、JavaScriptの読み込みを待ったりと、実際のブラウザ操作を自動化できます。動的なJavaScriptで生成されるデータや、何らかの操作後に表示される情報を取得したい場合はSeleniumが活躍します。
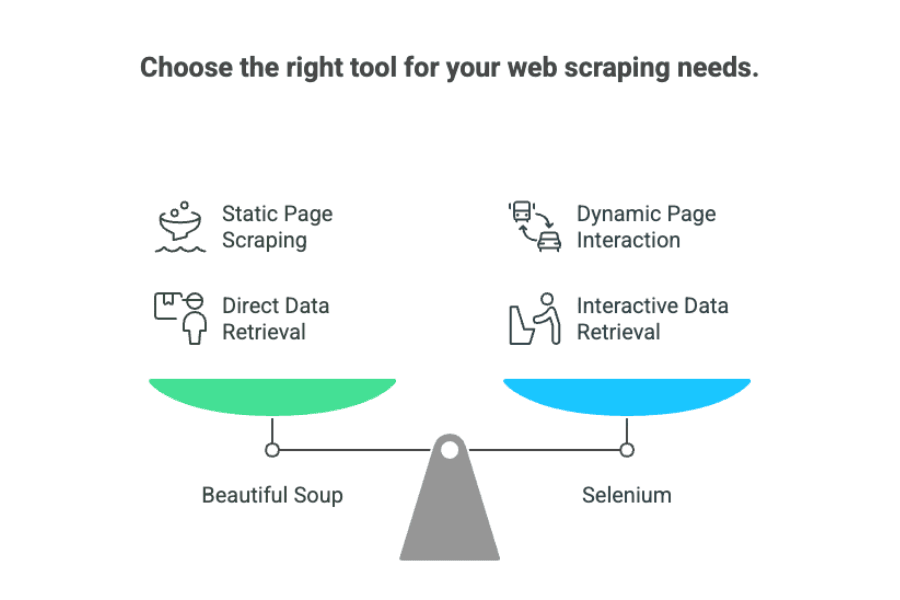
つまり、「beautiful soup vs selenium」の選択はこんな感じで整理できます:
- Beautiful Soup: 静的なページで、データがHTML内にそのままある場合に最適。
- Selenium: ユーザー操作や動的なコンテンツの読み込みが必要なサイトに最適。
ビジネスユーザー向けに例えるなら、
- Beautiful Soupは、紙のカタログから情報を写し取るイメージ。
- Seleniumは、実際にお店に行ってカタログをめくり、ボタンを押して最新の価格を調べるイメージです。
Beautiful SoupとSeleniumの「困ったポイント」
ここからは、実際に使ってみて感じる「あるあるな悩み」を正直にお伝えします。長年ウェブスクレイパーのバグ修正に悩まされてきた私が感じる主な課題は以下の通りです:
1. ウェブサイトの変更に弱い
どちらのツールも、サイト構造が少しでも変わるとすぐに動かなくなります。クラス名が変わったり、divの位置が変わるだけでスクレイパーが壊れることも。ある開発者は「メンテナンスコストは開発コストの10倍以上になることもある」と語っています。
2. 処理速度の課題
- Beautiful Soupはパース自体は速いですが、何千ページも順番に処理する場合はやはり時間がかかります。
- Seleniumはさらに遅く、ページごとにブラウザを立ち上げ、スクリプトの読み込みやUI操作を待つ必要があります。大量のページを処理するには多くのリソースが必要です。
3. コードの再利用性が低い
サイトごとに構造が異なるため、毎回カスタムのパース処理を書く必要があります。サイトが変わればまた一から書き直しです。「万能なスクリプト」は存在しません。
4. 技術的なハードルが高い
どちらもPythonの知識やHTML/CSSセレクタの理解が必要です。Seleniumの場合はブラウザドライバの扱いも求められ、非エンジニアには敷居が高いです。
5. メンテナンスの手間
スクレイパーを動かし続けるには、サイトの変更やアンチボット対策への対応など、常に監視と修正が必要です。ビジネスユーザーは開発者に頼るか、外部に委託するしかありません。
Pythonウェブスクレイパーの限界を超える:AIウェブスクレイパーの登場
ここからが本題。最近はAIを活用したウェブスクレイパーが急速に普及しています。大規模言語モデル(GPTなど)を使い、コード不要でウェブサイトからデータを抽出できるツールが続々登場しています。
Thunderbit登場:ビジネスユーザー向けAIウェブスクレイパー
は、たった2クリックでどんなウェブサイトでもデータを抽出できるChrome拡張機能。Pythonもコードも、ブラウザドライバの設定も一切不要。ページを開いてクリックするだけで、AIが自動でデータを抽出してくれます。
ThunderbitのようなAIウェブスクレイパーが注目される理由
- 完全ノーコード・手間いらず: Thunderbitは「ノーコード」を超えて「ノーエフォート」。インストールしてページを開くだけで、AIが抽出項目を提案してくれます。
- 動的コンテンツにも対応: ブラウザ上で動作するため、JavaScriptで後から表示されるデータや、クリック・ログイン後の情報も取得可能。
- 高速かつ高精度: 複数ページの一括抽出も可能で、リード獲得やEC、不動産などビジネス用途に最適化されています。
- メンテナンス不要: Thunderbitは「疲れ知らずのAIインターン」。サイトが変わってもAIが自動で対応し、コードを書き直す必要がありません。
- データの整理・翻訳・要約も自動: 抽出したデータのラベル付け、フォーマット変換、翻訳、要約までAIが自動で行います。まるで1万ページ分のデータをChatGPTに渡して、きれいなスプレッドシートにしてもらう感覚です。
その結果、ビジネスユーザーでもIT部門やPythonの知識なしで、必要なデータをすぐに手に入れられるようになりました。
Thunderbit vs Beautiful Soup vs Selenium:ビジネスユーザー向け比較表
各ツールの特徴をビジネス目線で比較してみましょう:
| 基準 | Beautiful Soup | Selenium | Thunderbit(AIウェブスクレイパー) |
|---|---|---|---|
| 導入の手間 | Pythonインストールのみ | ブラウザドライバ設定が必要 | Chrome拡張、設定不要 |
| 使いやすさ | コーダー向け | コード必須で難易度高 | ノーコード、ビジネス向け |
| 速度 | 静的ページは高速 | ブラウザ起動で遅い | 小〜中規模は高速、大量は非推奨 |
| 動的コンテンツ | JS非対応 | すべて対応 | すべて対応 |
| メンテナンス | サイト変更で壊れやすい | サイト・ドライバ更新で壊れやすい | AIが自動対応で手間なし |
| スケーラビリティ | 静的なら良好、要インフラ | 大量処理は非効率 | 小〜中規模向け、大量処理は非推奨 |
| データ整形 | 手動で後処理 | 手動で後処理 | ラベル付け・整形・翻訳・要約が自動 |
| 連携 | カスタムコード | カスタムコード | Excel・Sheets・Airtable・Notionに1クリック |
| 技術スキル | Python必須 | Python+ブラウザ知識必須 | 不要 |
Thunderbitがビジネス現場を変える5つの進化ポイント
Thunderbitが従来のウェブスクレイピングをどう変えるのか、主な特徴を紹介します:
1. AIによる自動データ抽出
ThunderbitはAIがページを「読んで」最適な抽出項目を提案。ボタン一つで抽出開始、セレクタやHTML解析は不要です。
2. サブページの自動巡回
商品一覧から各商品ページに自動でアクセスし、詳細情報をまとめて取得することも可能。追加設定は不要です。
3. データの自動整形・ラベル付け・翻訳
ThunderbitのAIは:
- ラベル付け: カテゴリやタグを自動で付与
- フォーマット変換: 電話番号や日付、価格などを統一
- 翻訳: 抽出データを即座に多言語化
- 要約: 長文から要点を自動抽出
まるでデータアナリストが内蔵されているような感覚です。
4. シームレスな外部連携
抽出データはExcel、Google Sheets、Airtable、Notionにワンクリックでエクスポート可能。CSVの手作業は不要です。
5. ノーコード・メンテナンスフリー
Thunderbitはビジネスユーザー向けに設計されており、Pythonもメンテナンスも不要。AIが自動で変化に対応し、業務が止まりません。
Thunderbitの詳細な機能比較はもご覧ください。
ビジネスユーザーにとっての最適な選択肢は?
では、beautiful soup、selenium、Thunderbitのどれを選ぶべきか?長年の経験から、実践的な判断基準をまとめました:
1. 必要なデータ量は?
- 小〜中規模(数百〜数千ページ): Thunderbitが最適。導入も早く、データ整形も自動。
- 大規模(数万〜数百万ページ): Beautiful Soup(Scrapyなどのフレームワーク併用)やエンタープライズ向けソリューション。Thunderbitは現時点で大量処理には非対応です。
2. 開発リソースはあるか?
- 開発者がいる場合: Beautiful SoupやSeleniumで細かく制御可能。
- 開発者がいない・スピード重視: ThunderbitなどAI搭載ツールが便利。
3. サイトの更新頻度は?
- 頻繁に変わる場合: ThunderbitのAIが自動で対応し、メンテナンスの手間を削減。
- あまり変わらない場合: Beautiful SoupやSeleniumでもOK。ただし変更時はスクリプト修正が必要。
4. データ整形や翻訳が必要か?
- 必要な場合: Thunderbitが自動で対応。
- 生データだけで良い場合: Beautiful SoupやSeleniumで十分。
判断チャート
| 質問 | 最適なツール |
|---|---|
| 開発者なし、今すぐデータが欲しい | Thunderbit |
| 抽出と同時にデータ整形・翻訳したい | Thunderbit |
| 大規模・カスタムパイプラインが必要 | Beautiful Soup/Scrapy |
| サイトの頻繁な変更に強くしたい | Thunderbit |
まとめ:Pythonウェブスクレイパーのこれから
私がPythonスクリプトと格闘していた頃から、ウェブスクレイピングは大きく進化しました。2025年現在、「beautiful soup vs selenium」の議論は続いていますが、ThunderbitのようなAIウェブスクレイパーの登場で、ビジネスユーザーの選択肢は大きく広がっています。
Beautiful Soupは静的HTMLの解析において今も最速・最軽量で、シンプルな用途には最適です。Seleniumは動的・インタラクティブなサイトの自動化に強みがありますが、導入やメンテナンスの手間が大きいのが難点です。
一方、コード不要・メンテナンスフリーで、きれいに整形されたデータをすぐに手に入れたいなら、ThunderbitのようなAIウェブスクレイパーが新たな主役です。「ノーコード」どころか「ノーエフォート」。営業やEC、オペレーション部門が「今すぐデータが欲しい」時代に、まさに理想的な選択肢です。
私からのアドバイスは、今のウェブスクレイピング業務を見直してみること。もし壊れやすいスクリプトや、終わらないメンテナンス、開発者待ちに疲れているなら、ぜひThunderbitを試してみてください。ウェブスクレイピングの未来は、これまで以上にスマートで速く、誰でも使えるものになっています。私自身も、これからの進化がとても楽しみです。
Thunderbitの実際の動きを見てみたい方は、するか、の他の記事もご覧ください。AmazonやTwitter、PDFなど特定サイトのスクレイピング方法も紹介しています:
みなさんのデータ収集が、いつも新鮮で整理され、ストレスフリーでありますように!