

想像してみてください。何千もの商品が並ぶウェブサイトを前にして、上司やデータ好きな自分から「全部の価格や商品名、レビューをスプレッドシートにまとめて」と頼まれたらどうしますか?手作業でコピペしていたら、気が遠くなるほど時間がかかります。でも、Pythonを使えば一瞬で終わるかもしれません。これこそがウェブスクレイピングの出番です。そして、これは一部のハッカーやエンジニアだけのものではありません。今やウェブスクレイピングは営業、マーケティング、不動産、リサーチなど、さまざまな業界で必須スキルになっています。世界のウェブスクレイピングソフトウェア市場はすでに10億ドル規模に達していて、2032年にはその2倍以上に成長すると予想されています。つまり、膨大なデータと大きなチャンスが広がっているということです。
Thunderbitの共同創業者として、私は長年にわたり企業のデータ収集自動化をサポートしてきました。AIウェブスクレイパーのThunderbitが登場する前は、Pythonの定番ツールであるbeautiful soupやrequestsを使って、何度も試行錯誤を重ねてきました。このガイドでは、beautiful soupの概要やインストール方法、基本的な使い方、そして今も多くの人に選ばれる理由をわかりやすく解説します。さらに、ThunderbitのようなAI搭載ツールがウェブスクレイピングをどう変えているのかもご紹介。Python初心者の方も、ビジネスユーザーも、スクレイピングに興味がある方も、ぜひ最後まで読んでみてください。
beautiful soupとは?Pythonで使えるウェブスクレイピングの強力な味方
まずは基本から。beautiful soup(通称BS4)は、HTMLやXMLファイルからデータを抜き出すためのPythonライブラリです。ごちゃごちゃしたウェブページのコードを渡すと、きれいに整理されたツリー構造に変換してくれます。商品名や価格、レビューなども、タグやクラス名を指定するだけで簡単に取得できます。
beautiful soup自体にはウェブページを取得する機能はありません(その役割はrequestsなどのライブラリが担当)。でも、一度HTMLを取得してしまえば、必要なデータを探して抜き出すのはとても簡単です。最近の調査では、開発者の43%以上がbeautiful soupをウェブスクレイピングの第一選択肢に挙げています。
beautiful soupは、学術研究、EC分析、リード獲得など、幅広いシーンで活躍しています。マーケティングチームがインフルエンサーリストを作ったり、採用担当者が求人情報を集めたり、ジャーナリストが調査を自動化したりと、いろんな現場で使われています。柔軟性が高く、ちょっとPythonが分かればすぐに使いこなせるのも魅力です。
beautiful soupが選ばれる理由とビジネス活用例
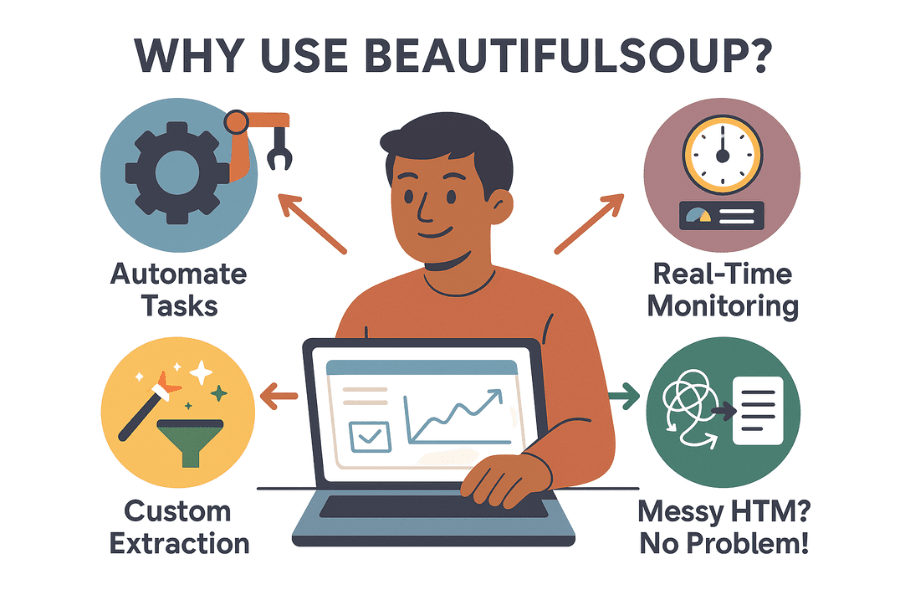
なぜ多くのビジネスやデータ担当者がbeautiful soupを使うのでしょうか?主な理由は以下の通りです:
- 面倒な作業を自動化:手作業のコピペはもう不要。beautiful soupなら数千件のデータも数分で集められ、チームの時間を有効活用できます。
- リアルタイム監視:競合の価格や在庫、ニュースの見出しなどを定期的にチェック可能。競合が値下げしたら、朝のコーヒー前に気付けます。
- カスタムデータ抽出:人気商品ランキングやレビュー付きのデータなど、欲しい情報をピンポイントで取得できます。
- 複雑なHTMLにも対応:コードがごちゃごちゃしたサイトでも、beautiful soupなら大抵解析できます。
実際の活用例をまとめると:
| ユースケース | 概要 | 得られる成果 |
|---|---|---|
| リード獲得 | 企業ディレクトリやLinkedInからメール・電話番号を抽出 | ターゲット営業リストの作成 |
| 価格モニタリング | ECサイトで競合の価格を追跡 | 自社価格をリアルタイムで調整 |
| 市場調査 | オンラインストアからレビューや商品情報を収集 | トレンド把握や商品開発に活用 |
| 不動産データ | ZillowやRealtor.comなどから物件情報を集約 | 価格動向や投資分析に利用 |
| コンテンツ集約 | ニュース記事やブログ、SNS投稿を収集 | ニュースレターや感情分析に活用 |
実際、イギリスのある小売業者はウェブスクレイピングで競合を監視し、売上を4%向上させました。ASOSは現地価格をスクレイピングしてマーケティングを最適化し、海外売上を倍増させた事例もあります。つまり、スクレイピングデータはビジネスの意思決定に直結しています。
beautiful soupの始め方:Pythonでのインストール手順
それでは、beautiful soupを使い始める手順を見ていきましょう。
ステップ1:beautiful soupのインストール
まずは最新版(beautifulsoup4、通称bs4)をインストールしましょう。古いパッケージ名に注意!
pip install beautifulsoup4
macOSやLinuxの場合はpip3やsudoが必要な場合も:
sudo pip3 install beautifulsoup4
ワンポイント:pip install beautifulsoup(「4」なし)だと古い非互換バージョンが入るので注意。
ステップ2:パーサーのインストール(推奨)
Python標準のHTMLパーサーも使えますが、lxmlやhtml5libを入れると高速かつ安定します。
pip install lxml html5lib
ステップ3:requestsのインストール(HTML取得用)
beautiful soupはHTML解析専用なので、ページ取得にはrequestsが便利です。
pip install requests
ステップ4:Python環境の確認
Python 3を使っているか確認しましょう。PyCharmやVS CodeなどのIDEではインタプリタ設定も要チェック。インポートエラーが出る場合は、パッケージのインストール先が違う可能性も。Windowsならpy -m pip install beautifulsoup4で正しい環境に入れられます。
ステップ5:動作確認
以下のコードで動作チェックしてみましょう:
from bs4 import BeautifulSoup
import requests
html = requests.get("http://example.com").text
soup = BeautifulSoup(html, "html.parser")
print(soup.title)
<title>タグが表示されればOKです。
beautiful soupの基本:主要な概念と構文
beautiful soupでよく使うオブジェクトや考え方を整理します:
- BeautifulSoupオブジェクト:解析したHTMLツリーのルート。
BeautifulSoup(html, parser)で生成。 - Tag:HTMLやXMLのタグ(例:
<div>,<p>,<span>)。属性や子要素、テキストにアクセス可能。 - NavigableString:タグ内のテキスト部分。
パースツリーのイメージ
HTMLは家系図のようなツリー構造です。<html>が祖先、<head>や<body>が子孫…というイメージ。beautiful soupはこのツリーをPythonらしい書き方で自在にたどれます。
例:
html = """
<html>
<head><title>My Test Page</title></head>
<body>
<p class="story">Once upon a time <b>there were three little sisters</b>...</p>
</body>
</html>
"""
soup = BeautifulSoup(html, "html.parser")
# titleタグにアクセス
print(soup.title) # <title>My Test Page</title>
print(soup.title.string) # My Test Page
# 最初の<p>タグとclass属性
p_tag = soup.find('p', class_='story')
print(p_tag['class']) # ['story']
# <p>タグ内のテキスト全取得
print(p_tag.get_text()) # Once upon a time there were three little sisters...
ナビゲーションと検索
- 要素アクセス:
soup.head,soup.body,tag.parent,tag.childrenなど - find() / find_all():タグ名や属性で検索
- select():CSSセレクタで複雑な検索も可能
例:
# すべてのリンクを取得
for link in soup.find_all('a'):
print(link.get('href'))
# CSSセレクタ例
for item in soup.select('div.product > span.price'):
print(item.get_text())
実践編:beautiful soupで商品データをスクレイピングしてみよう
実際にECサイト(例:Etsy)から商品タイトルと価格を取得する流れを見てみましょう。
ステップ1:ウェブページの取得
import requests
from bs4 import BeautifulSoup
url = "https://www.etsy.com/search?q=clothes"
headers = {"User-Agent": "Mozilla/5.0"} # 一部サイトはユーザーエージェント必須
resp = requests.get(url, headers=headers)
soup = BeautifulSoup(resp.text, 'html.parser')
ステップ2:データの抽出
各商品は<li class="wt-list-unstyled">内にあり、タイトルは<h3 class="v2-listing-card__title">、価格は<span class="currency-value">に入っていると仮定します。
items = []
for item in soup.find_all('li', class_='wt-list-unstyled'):
title_tag = item.find('h3', class_='v2-listing-card__title')
price_tag = item.find('span', class_='currency-value')
if title_tag and price_tag:
title = title_tag.get_text(strip=True)
price = price_tag.get_text(strip=True)
items.append((title, price))
ステップ3:CSVやExcelに保存
Python標準のcsvモジュールを使う場合:
import csv
with open("etsy_products.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow(["Product Title", "Price"])
writer.writerows(items)
pandasを使う場合:
import pandas as pd
df = pd.DataFrame(items, columns=["Product Title", "Price"])
df.to_csv("etsy_products.csv", index=False)
これで分析やレポート作成に使えるスプレッドシートが完成です。
beautiful soupの課題:保守・対策・限界
ここからは正直な話。beautiful soupは便利ですが、大規模なスクレイピングや長期運用にはいくつか課題もあります。
1. サイト構造の変化に弱い
ウェブサイトはレイアウトやクラス名、要素の順序を頻繁に変えます。beautiful soupのスクリプトは、指定したセレクタが変わると動かなくなります。しかも、エラーが出ずに静かに壊れることも。複数サイトを管理していると、保守が大変です。
2. アンチスクレイピング対策
最近のサイトはCAPTCHAやIPブロック、レート制限、JavaScriptによる動的表示など、さまざまな防御策を導入しています。beautiful soup単体ではこれらに対応できません。プロキシやヘッドレスブラウザ、CAPTCHA回避ツールなどを追加する必要があります。
3. スケーリングとパフォーマンス
beautiful soupは単発や中規模のデータ取得には最適ですが、何百万ページもの大量データや並列処理には追加の実装が必要です。エラー処理やインフラ構築も自分で行う必要があります。
4. 技術的ハードル
PythonやHTML、デバッグに慣れていないと、beautiful soupはやや敷居が高いかもしれません。経験者でも「調査→コーディング→実行→修正」の繰り返しになることが多いです。
5. 法的・倫理的な注意点
スクレイピングは、robots.txtや利用規約を無視すると法的リスクが生じる場合も。アクセス頻度の制限やサイトルールの遵守、データの適切な扱いが求められます。
beautiful soupの先へ:ThunderbitなどAI搭載ツールでウェブスクレイピングをもっと手軽に
AIであらゆるウェブサイトからデータ抽出 Get Started Free
ここからが本題です。AIの進化によって、Thunderbitのようなツールが登場し、コーディング不要で誰でもウェブスクレイピングができる時代になりました。
ThunderbitはAIを活用したChrome拡張機能で、2クリックでどんなウェブサイトからでもデータを抽出できます。Pythonもセレクタも不要、面倒な保守もありません。ページを開いて「AIでフィールド提案」をクリックすれば、AIが商品名や価格、レビュー、メールアドレス、電話番号などを自動で抽出対象として提案してくれます。あとは「スクレイプ」を押すだけで完了です。
Thunderbitとbeautiful soupの比較
| 機能 | BeautifulSoup(コーディング) | Thunderbit(ノーコードAI) |
|---|---|---|
| セットアップ難易度 | PythonやHTMLの知識・デバッグが必要 | コード不要、AIが自動でフィールド検出、直感的な操作 |
| データ取得までの速さ | コード作成・テストで数時間 | 2~3クリック、数分で完了 |
| サイト変更への対応 | HTML構造が変わると手動修正が必要 | AIが多くの変更に自動対応、人気サイトはテンプレートで保守 |
| ページ送り・サブページ | ループやリクエストを自作 | ページ送り・サブページもワンタッチで対応 |
| アンチボット対策 | プロキシやCAPTCHA対応、ブラウザ操作が必要 | 多くの対策を内部で処理、ブラウザ環境でブロック回避 |
| データ加工 | コードで自由自在だが自作が必要 | AIによる要約・分類・翻訳・クレンジングも内蔵 |
| エクスポート形式 | CSVやExcel、DBなどは自作 | CSV、Excel、Google Sheets、Airtable、Notionにワンクリック出力 |
| スケーラビリティ | インフラ構築次第で無制限だが、エラーや拡張は自力 | クラウド/拡張で並列処理やスケジューリング、大規模ジョブも対応(プラン/クレジット制限あり) |
| コスト | 無料(オープンソース)だが、時間と保守コストが発生 | 小規模は無料、大規模は有料プランだが、圧倒的な時短・省力化 |
| 柔軟性 | コード次第で何でも可能 | 標準的な用途はほぼカバー、特殊ケースはコードが必要な場合も |
さらに詳しく知りたい方はThunderbitのブログや機能ドキュメントもご覧ください。
実践比較:Thunderbitとbeautiful soupで同じデータを取得する流れ
ECサイトの商品データを例に、両者のワークフローを比較します。
beautiful soupの場合
- ブラウザの開発者ツールでHTML構造を調査
- Pythonコードでページ取得(requests)、解析(beautiful soup)、データ抽出
- セレクタ(クラス名やタグパス)を調整しながらデバッグ
- ページ送り対応はループ処理を自作
- CSVやExcel出力も追加コードが必要
- サイト構造が変わったら1~5を再度実施
所要時間:新規サイトなら1~2時間(アンチボット対策でさらに増加する場合も)
Thunderbitの場合
- Chromeで対象サイトを開く
- Thunderbit拡張機能をクリック
- 「AIでフィールド提案」をクリック(商品名・価格など自動抽出)
- 必要に応じてカラムを調整し、「スクレイプ」をクリック
- ページ送りやサブページもトグルで簡単設定
- データをプレビューし、好きな形式でエクスポート
所要時間:2~5分。コードもデバッグも保守も不要。
おまけ:Thunderbitはメールや電話番号、画像の抽出、フォーム自動入力も可能。まるで文句を言わない超高速アシスタントのようです。
まとめとポイント
2025年版データスクレイピングの基礎と実践 Get Started Free
ウェブスクレイピングは、かつては一部のハッカーの技術でしたが、今やリード獲得や市場調査などビジネスの現場で広く使われています。beautiful soupは、Pythonの知識があれば柔軟かつ細かな制御ができる入門ツールとして今も人気です。しかし、ウェブサイトが複雑化し、ビジネスユーザーがより手軽にデータを求める今、ThunderbitのようなAI搭載ツールが新たな選択肢となっています。

自分でコードを書いてカスタマイズしたい方にはbeautiful soupが最適ですが、コーディングや保守の手間を省き、すぐに結果を得たい方にはThunderbitが最適解です。AIの力で、もう何時間もかけてスクレイピングを作る必要はありません。
今すぐ試してみませんか? Thunderbit Chrome拡張機能をダウンロードしたり、Thunderbitブログで他のチュートリアルもチェックしてみてください。Pythonでbeautiful soupを極めたい方も、タイピングのしすぎで手首を痛めないようご注意を。
ハッピー・スクレイピング!
Thunderbit AIウェブスクレイパーを試す Get Started Free
おすすめ記事:
ご質問や体験談、スクレイピングの失敗談などもぜひコメントでお寄せください。私も数えきれないほどスクリプトを壊してきましたので、お気軽にどうぞ。




