
機械学習の現場では、今まで以上に高品質なラベル付きデータが求められています。AIモデルを新しく作ろうとするチームと話すと、ほぼ必ず「データラベリングが遅い」「コストがかかる」「精神的にもしんどい」といった悩みが出てきます。十分なラベル付きデータが集まらず、プロジェクトが何週間、時には何ヶ月も止まってしまうことも珍しくありません。しかも、ラベルの質がバラバラだと、モデルの精度もガクッと落ちてしまいます。
でも、ここで嬉しいニュース。最近はAIを活用した自動データラベリングが登場し、こうした悩みがどんどん解消されつつあります。AIにラベリングを任せれば、作業スピードが一気に上がるだけでなく、精度や一貫性もグッとアップ。これらは機械学習プロジェクトの成否を左右する超重要ポイントです。この記事では、自動データラベリングの仕組みやその大切さ、さらにのようなツールを使ってノーコードで自動ラベリングワークフローを作る方法まで、分かりやすく紹介します。
機械学習による自動データラベリングって何?
まずは基本から。機械学習による自動データラベリングは、AIやアルゴリズムを使って、生データに「スパム/非スパム」「猫/犬」「ポジティブ/ネガティブ」などのラベルを自動で付ける仕組みです。イメージとしては、何千枚もの旅行写真を手作業でタグ付けする代わりに、顔認識や位置情報を使って自動で分類してくれる感じ。
昔ながらの手作業ラベリングは、人が一つひとつデータを見てラベルを付ける方法。正確だけど、時間もお金もかかるし、データ量が増えると現実的じゃありません。一方、自動ラベリングは、少しだけ手作業でラベル付けしたデータを使って機械学習モデルを訓練し、残りの大量データにラベルを自動で付けていきます。これで、スピーディーかつ一貫性のあるラベリングが実現できるんです()。
ビジネスの現場では、これによってモデル開発のスピードが大幅アップ。手作業の負担もグッと減ります。データ活用が勝負の分かれ目になる今、これはかなり大きな武器です。
高品質な機械学習モデルに自動データラベリングが欠かせない理由
ラベル付きデータの質は、機械学習モデルの性能に直結します。「ゴミデータを入れれば、ゴミしか出てこない」とよく言われる通り、ラベルが不正確・バラバラだと、モデルは間違ったパターンを学習してしまい、予測精度が大きく下がります()。
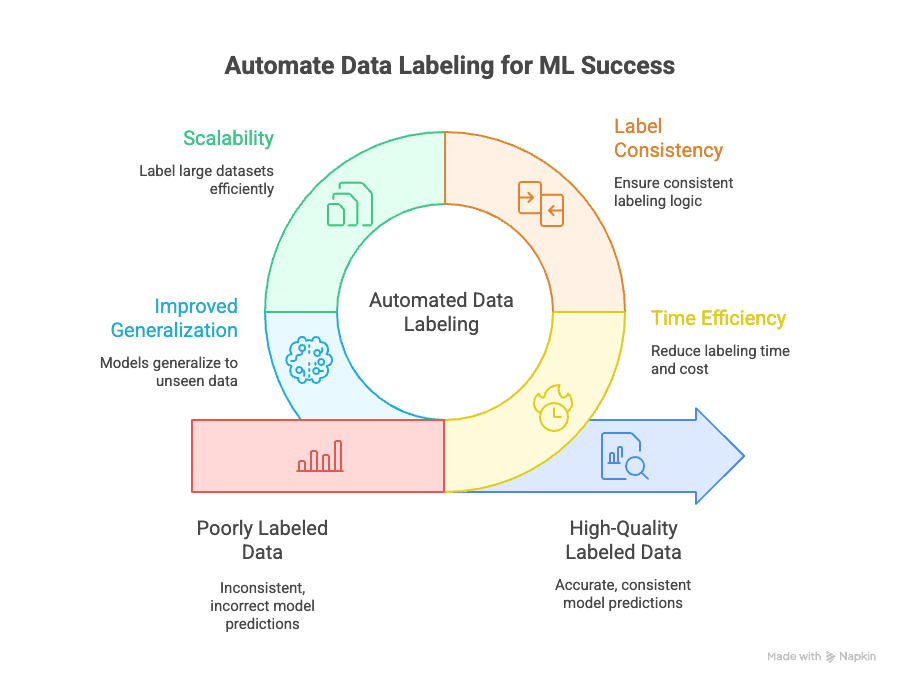
自動データラベリングは、こんな課題を解決してくれます:
- 時間短縮: 手作業ラベリングは、MLプロジェクト全体のを占めることも。自動化すれば、これを大幅にカットして、モデル開発のサイクルを加速できます。
- ラベルの一貫性: 機械は疲れ知らず。自動ラベリングなら、いつでも同じ基準でラベル付けできて、人為的なミスやバイアスも減らせます()。
- スケーラビリティ: 1万件、10万件、100万件といった大規模データも、人手を増やさずにラベリング可能()。
- 汎化性能の向上: 一貫性のある高品質なラベルは、未知のデータに対するモデルの適応力(汎化性能)も高めてくれます()。
ビジネスへのインパクトも大きく、ラベル品質が悪いとモデル精度がする一方、自動化された高品質ラベリングなら、開発・運用スピードも大幅にアップします。
手作業ラベリングと自動ラベリングの違い
違いをざっくりまとめると:
| 要素 | 手作業ラベリング | 機械学習による自動ラベリング |
|---|---|---|
| スピード | 遅い(大規模データは数週間〜数ヶ月) | 速い(大規模データも数分〜数時間) |
| 精度 | 高いが人為的ミスやバラつきが発生 | 高精度かつ一貫性が高い |
| 拡張性 | 人手に依存し規模拡大が困難 | 数百万件規模も容易に対応 |
| コスト | 高コスト(人件費が大きい) | 長期的にはコスト削減(Keylabs) |
| 適したケース | 小規模・複雑・曖昧なデータ | 大規模・反復的・明確なデータ |
もちろん、特殊なケースや曖昧なデータには手作業も必要ですが、ビジネス用途の多くは自動化がベストです。
機械学習による自動データラベリングの基本ステップ
実際の自動ラベリングは、だいたい次の流れで進みます:
- データ収集と前処理
- 特徴量の抽出と準備
- 機械学習による自動ラベリング
- 品質管理と人による確認
それぞれ詳しく見ていきましょう。
ステップ1:データ収集と前処理
まずはラベリング対象のデータを集めて、不要なノイズを除去します。たとえば、ウェブサイトから商品情報をスクレイピングしたり、顧客レビューをエクスポートしたり、社内DBから画像を集めたり。ここで大事なのは「データの質」。質の悪いデータは、どんなに頑張っても良いラベルやモデルにはつながりません()。
ポイント:
- 重複や関係ないデータを除去
- フォーマット(日時・通貨など)を統一
- 欠損値や不完全なデータをしっかり処理
ステップ2:特徴量の抽出と準備
次に、ラベリングに必要な特徴量(属性)を抽出します。たとえば商品データなら「価格」「ブランド」「カテゴリ」「説明文」など。営業やマーケなら、会社名や連絡先、メールの感情なども対象です。
ビジネス例: を使えば、ウェブページから商品スペックやレビュー、連絡先などの構造化データをノーコードで抽出できます。
ステップ3:機械学習による自動ラベリング
ここが自動化の本番。少量の手作業ラベル付きデータでモデルを訓練し、残りのデータにラベルを自動付与します。主なやり方は:
- 教師ありモデル: ラベル付きデータで分類器を訓練し、新しいデータにラベルを付与
- ルールベース: 「価格が1000ドル超なら“高級”」みたいなシンプルなルールで自動ラベル
- アクティブラーニング: モデルが自信のないデータだけ人に確認を依頼し、徐々に精度を高める()
- 転移学習: 既存の学習済みモデルを活用し、新しい分野のラベリングを効率化()
これで、大量データでも一貫性のある高品質なラベル付けができます。
ステップ4:品質管理と人による確認
どんなに優秀なモデルでも、定期的な人のチェックは欠かせません。特に例外的なケースや曖昧なデータ、モデルの精度低下(ドリフト)を見逃さないために、
- ランダムにサンプルを抽出して手作業で確認
- 自動ラベルと「正解データ」を比較
- 複数人のラベラー間の一致度を指標化()
などのQAプロセスを設けましょう。
Thunderbitで機械学習による自動データラベリングをやってみよう
ここからは実践編。は、ビジネスユーザー向けに作られたAI搭載ウェブスクレイパー兼データラベリングツール。プログラミング不要で、誰でも簡単に自動ラベリングワークフローを作れます。
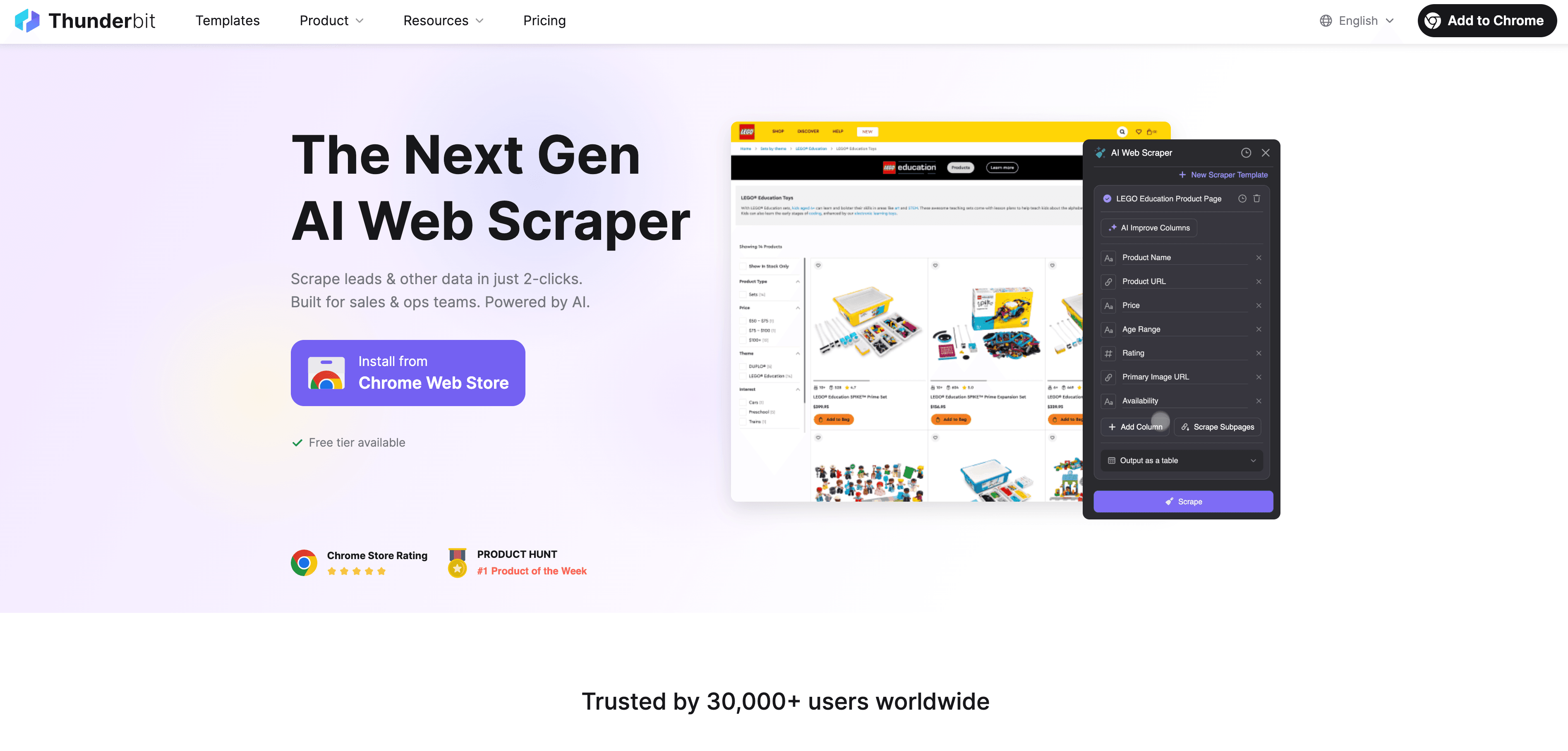
ステップバイステップガイド
- ウェブデータの収集: を使って、好きなウェブサイトから構造化データを取得。拡張機能を開いてデータソースを選ぶだけで、ThunderbitのAIが最適な抽出項目を提案してくれます。
- ラベル指示の設定: Thunderbitの自然言語プロンプトで、AIにラベル付けのルールを指示。「500ドル以上の商品は“高級”」「ポジティブなレビューにタグ付け」など、直感的に設定できます。
- 自動ラベリングの実行: Field AI Prompt機能で、複数項目や複雑なラベル付けも柔軟にカスタマイズ可能。
- ラベル付きデータのエクスポート: ラベル付けが終わったら、Excel・Google Sheets・Airtable・Notionなどにワンクリックでエクスポート。すぐにモデル学習や分析に使えます。
Thunderbitは、営業・マーケ・オペレーションなど非エンジニアの人でも使いやすい設計。コードや難しいテンプレートは一切不要です。
Thunderbitの自然言語プロンプト&Field AI機能
特に便利なのが、ラベル付けのロジックを日本語や英語でそのまま指示できる点。地域ごとにリードを分類したり、商品カテゴリごとにタグ付けしたり、緊急度の高いメールを自動でフラグ付けしたりも簡単です。
プロンプト例:
- 「メールアドレスが.eduの連絡先は“教育機関”セグメントに分類」
- 「“配送が早い”と書かれたレビューは“配送満足”でタグ付け」
- 「ブランドと価格帯ごとに商品をグループ化」
Field AI Promptを使えば、列ごとに細かくルールを設定したり、複数条件を組み合わせたり、多言語ラベルにも対応できます。
サブページスクレイピング&複数項目ラベリング
複雑なデータ構造もThunderbitならラクラク。サブページスクレイピング機能で、商品詳細や著者情報など階層化されたページからもデータを抽出・ラベル付けし、1つのテーブルにまとめられます。複数項目の同時ラベリングもOKで、作業効率がグンと上がります。
実例: ECサイトの商品一覧をスクレイピングし、各商品ページに飛んでスペック・レビュー・販売者情報を抽出&ラベル付け。これらを一括で管理できます。
複数のデータラベリングツールを組み合わせて精度と効率を最大化
Thunderbitだけでも多くの用途をカバーできますが、画像アノテーションや動画ラベリングなど、より専門的な作業にはやのような専用ツールが役立ちます。
活用のコツ: Thunderbitでウェブデータの抽出と初期ラベリングを行い、そのデータをLabel StudioやSuperviselyにエクスポートして、画像のバウンディングボックスや動画のフレームごとのタグ付けなど高度なアノテーションを追加。各ツールの強みを活かすことで、精度と効率を両立できます()。
Thunderbitと他ツールを併用するべきケース
- 画像アノテーション: 物体検出やセグメンテーションにはSuperviselyやLabel Studioが最適
- 動画ラベリング: フレームごとのタグ付けやトラッキングは専用ツールが便利
- 複雑な多重ラベル: Thunderbitで構造化データを抽出し、さらに高度なアノテーションを追加
ベストプラクティス: まずThunderbitで構造化・半構造化データのラベリングを高速化し、必要に応じて専門ツールで詳細なアノテーションを追加しましょう。
機械学習による自動データラベリングのベストプラクティス
自動ラベリングの効果を最大化するためのポイント:
- 明確なラベル基準を定義: 曖昧なラベルはデータの一貫性を損なうので、意味をはっきりさせる
- 高品質なシードデータから開始: まずは少量でも代表的なデータを手作業でラベル付けし、初期モデルを訓練
- 継続的な改善: アクティブラーニングで難しいケースを重点的に人が確認し、モデルをアップデート
- 定期的な検証: ランダムサンプルでラベル精度やドリフトをチェック
- 統合と自動化: Thunderbitのようなツールで、データ収集・ラベリング・エクスポートを一気通貫で自動化
よくある課題とその解決策
自動データラベリングにも課題はありますが、以下のように対策できます:
- 曖昧なデータ: ラベル定義を明確にし、例外ケースのサンプルも用意
- モデルドリフト: 新しい手作業ラベルデータで定期的に再学習
- 例外ケース: 不明確なデータは人がレビューする仕組みを用意
- 連携の問題: Thunderbitのように主要プラットフォームへのエクスポートが簡単なツールを選ぶ
まとめ・重要ポイント
機械学習による自動データラベリングは、現代AIモデルの成功を支える“縁の下の力持ち”です。時間とコストを大幅に削減し、何よりモデルの精度を左右する高品質なラベルを安定して供給できます。のようなツールと専門アノテーションプラットフォームを組み合わせれば、技術的な知識がなくても、誰でも高速・高精度・大規模なラベリングワークフローを作れます。
実際にその効果を体感したい人は、して、次のプロジェクトで自動ラベリングを試してみてください。さらに詳しいノウハウや事例はでも紹介しています。
よくある質問(FAQ)
1. 機械学習による自動データラベリングって何?
AIや機械学習モデルを使って、データに自動でラベルを付ける仕組みです。手作業よりもスピーディーで一貫性があり、大規模データにも対応できます。
2. ラベル品質が機械学習に重要な理由は?
高品質で一貫性のあるラベルは、正確なモデルを作るために不可欠。ラベルが不十分だと、モデル精度が最大80%も下がり、信頼できない予測につながります。
3. Thunderbitは自動データラベリングにどう役立つ?
Thunderbitは、AIと自然言語プロンプトを活用してウェブデータの抽出・ラベル付けをノーコードで実現。営業・マーケ・オペレーションなどビジネス現場で直感的に使えます。
4. Thunderbitと他のラベリングツールを組み合わせられる?
もちろんOK。Thunderbitで構造化データの抽出・初期ラベリングを行い、Label StudioやSuperviselyで画像・動画の高度なアノテーションを追加できます。
5. 自動データラベリングのベストプラクティスは?
明確なラベル基準の設定、高品質なシードデータからのスタート、アクティブラーニングによる継続的改善、定期的な検証、統合ツールの活用がポイントです。
データラベリングを自動化して、機械学習プロジェクトの生産性と精度を一気に高めましょう。Thunderbitをぜひ試してみてください。
さらに詳しく知りたい人はこちら: