

Amazon はもはや一店舗の枠を超えています。日用品から家電まで、世界の購買行動の縮図がここに集まる。営業や EC、オペレーションの現場にいれば、Amazon の動向が自社の価格戦略・在庫計画・次に投入する商品の設計にまで波及することは肌で理解しているはず。問題は、判断に効く商品情報、価格、評価、レビューといったデータが消費者向けに最適化された画面の奥にしまい込まれていること。週末を潰してコピペを続けない限り取り出せない、というのが従来の常識でした。
本記事では、その常識を覆す 2 つの方法を順に解説します。ひとつは Python で自分のスクレイパーを組む昔ながらのやり方。もうひとつは、コード不要の AI ウェブスクレイパー Thunderbit に作業を任せる新しいやり方です。Python のコード例は、つまずきやすい落とし穴と対処法も含めて具体的に紹介。そのうえで、同じデータを Thunderbit ならどれほど短い手順で取得できるか比較します。エンジニアも、現場のアナリストも、コピペ作業に消耗している方も、自分の状況に合った選択肢が見えてくるはずです。
Amazon の商品データを抽出する価値(amazon scraper python、pythonでのウェブスクレイピング)
Amazon は世界最大級のオンライン小売プラットフォームであると同時に、競合インテリジェンスの宝庫でもあります。商品数は6億点超、アクティブセラーは約200万。次のような取り組みを進めるチームにとって、これほど豊富な情報源はそうありません。

- 価格モニタリング(リアルタイムで自社価格を調整する)
- 競合分析(新商品、評価、レビュー傾向を追跡する)
- リード獲得(セラー、サプライヤー、提携候補を発掘する)
- 需要予測(在庫状況や売れ筋ランキングの動きを読む)
- 市場トレンド発見(レビューと検索結果を読み解く)
ここで紹介するのは理屈の話ではありません。実際の企業が、具体的な ROI を出しています。家電量販のある事業者は Amazon の価格データを取得して利益率を15%改善しました。別のブランドは競合価格の追跡を自動化し、売上4%増・アナリスト工数30%削減を達成しています。
代表的なユースケースと期待できる効果を整理しておきます。
| 用途 | 使う人 | 一般的なROI / 効果 |
|---|---|---|
| 価格監視 | eコマース、オペレーション | 利益率15%以上の向上、売上4%増、アナリスト作業時間30%削減 |
| 競合分析 | 営業、プロダクト、オペレーション | 価格調整の高速化、競争力向上 |
| 市場調査(レビュー) | プロダクト、マーケティング | 製品改善の高速化、広告コピーの改善、SEOインサイト獲得 |
| リード獲得 | 営業 | 月3,000件超のリード、担当者1人あたり週8時間以上の削減 |
| 在庫・需要予測 | オペレーション、サプライチェーン | 過剰在庫を20%削減、欠品の減少 |
| トレンド把握 | マーケティング、経営層 | 売れ筋商品やカテゴリの早期発見 |
決定的な数字をひとつ。90%超の組織が、データ分析から測定可能な価値を得ていると回答しています。Amazon を取得対象から外しているということは、その分のインサイトと売上機会をそのまま競合に渡しているのと同じです。
全体像:Amazon スクレイパー Python vs. コード不要のウェブスクレイパー
ブラウザ上に表示されている Amazon のデータを、業務で使えるスプレッドシートやダッシュボードに落とすルートは大きく 2 つあります。
-
Amazon スクレイパー Python(pythonでのウェブスクレイピング):
Requests や BeautifulSoup などの Python ライブラリを組み合わせ、自前でスクリプトを書く方法です。柔軟性は最大ですが、コーディングスキル、ボット対策への対応、Amazon の頻繁な仕様変更に追随する保守体制が必要になります。
-
コード不要のウェブスクレイパーツール(Thunderbit など):
クリック操作だけでデータ抽出を完結させるツールを使う方法。プログラミングはいりません。Thunderbit のような最新世代は、AI が取得対象を自動で判断し、サブページやページ送りに対応し、Excel や Google Sheets へワンクリックで吐き出します。
両者を並べると、輪郭がはっきりします。
| 比較項目 | Pythonスクレイパー | コード不要(Thunderbit) |
|---|---|---|
| セットアップ時間 | 長い(インストール、コーディング、デバッグ) | 短い(拡張機能を入れるだけ) |
| 必要スキル | コーディング必須 | 不要(ポイント&クリック) |
| 柔軟性 | 無制限 | 一般的な用途では高い |
| 保守 | 自分で修正 | ツール側で自動更新 |
| ボット対策対応 | プロキシやヘッダーを自分で管理 | 内蔵機能で自動対応 |
| 拡張性 | 手動(スレッド、プロキシ) | クラウドスクレイピング、並列処理 |
| データ出力 | 自由設計(CSV、Excel、DB) | ワンクリックでExcel、Sheetsへ |
| コスト | 無料(自分の時間+プロキシ代) | フリーミアム、規模に応じて課金 |
| 向いている人 | 開発者、細かな要件がある人 | ビジネスユーザー、すぐ結果がほしい人 |
次のセクションから、まず Python で Amazon スクレイパーを組む手順を実コード付きで解説し、その後 Thunderbit を使った場合の流れを示します。
Amazon スクレイパー Python の始め方:前提条件とセットアップ
コードに入る前に、足場を整えます。
必要なもの:
- Python 3.x(python.org から入手)
- コードエディタ(私は VS Code を使っていますが、好みのもので問題ありません)
- 次のライブラリ:
requests(HTTP リクエスト用)beautifulsoup4(HTML 解析用)lxml(高速 HTML パーサ)pandas(データ整形・出力)re(正規表現、標準モジュール)
ライブラリをインストール:
pip install requests beautifulsoup4 lxml pandas
プロジェクトを準備する:
- 専用フォルダを新規作成します。
- エディタで Python ファイルを作成します(例:
amazon_scraper.py)。 - これで下準備は終わりです。
ステップ別:Python で Amazon の商品データをウェブスクレイピングする方法
最初は Amazon の商品ページ 1 件を対象に進めましょう。(複数商品・複数ページの扱いは後段で説明します。)
1. リクエスト送信と HTML 取得
商品ページの HTML を取得するところから始めます。URL は任意の Amazon 商品ページに置き換えてください。
import requests
url = "<https://www.amazon.com/dp/B0ExampleASIN>"
response = requests.get(url)
html_content = response.text
print(response.status_code)
注意: この素朴なリクエストは、ほぼ確実に Amazon にブロックされます。商品ページの代わりに 503 や CAPTCHA 画面が返ってくる場合もあります。理由はシンプルで、Amazon 側はあなたが本物のブラウザではないと即座に見抜くからです。
Amazon のボット対策をどう乗り越えるか
Amazon はボットを歓迎していません。ブロック回避には次の対応が必要です。
- User-Agent ヘッダーを付与する(Chrome や Firefox を装う)
- User-Agent をローテーションする(同じ値を使い続けない)
- リクエスト間隔を空ける(ランダムな待機時間を入れる)
- プロキシを利用する(大規模スクレイピング向け)
ヘッダー付与の最小サンプルはこちらです。
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)... Safari/537.36",
"Accept-Language": "en-US,en;q=0.9",
}
response = requests.get(url, headers=headers)
凝った使い方をするなら User-Agent のリストを用意し、リクエストごとに切り替えます。大量取得が前提ならプロキシサービスは必須ですが、小規模なら適切なヘッダーと待機時間で十分なケースも多いです。
主要な商品フィールドを抽出する
HTML が取れたら BeautifulSoup で解析します。
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_content, "lxml")
ここから必要な情報を取り出します。
商品タイトル
title_elem = soup.find(id="productTitle")
product_title = title_elem.get_text(strip=True) if title_elem else None
価格
Amazon の価格は複数の場所に表示されるため、段階的に試します。
price = None
price_elem = soup.find(id="priceblock_ourprice") or soup.find(id="priceblock_dealprice")
if price_elem:
price = price_elem.get_text(strip=True)
else:
price_whole = soup.find("span", {"class": "a-price-whole"})
price_frac = soup.find("span", {"class": "a-price-fraction"})
if price_whole and price_frac:
price = price_whole.text + price_frac.text
評価とレビュー数
rating_elem = soup.find("span", {"class": "a-icon-alt"})
rating = rating_elem.get_text(strip=True) if rating_elem else None
review_count_elem = soup.find(id="acrCustomerReviewText")
reviews_text = review_count_elem.get_text(strip=True) if review_count_elem else ""
reviews_count = reviews_text.split()[0] # 例: "1,554 ratings"
メイン画像 URL
Amazon は HTML 内の JSON に高解像度画像 URL を埋め込んでいることがあります。正規表現で取り出す例です。
import re
match = re.search(r'"hiRes":"(https://.*?.jpg)"', html_content)
main_image_url = match.group(1) if match else None
メイン画像タグから直接拾うルートもあります。
img_tag = soup.find("img", {"id": "landingImage"})
img_url = img_tag['src'] if img_tag else None
商品仕様
ブランド、重量、サイズなどはたいてい表に並んでいます。
details = {}
rows = soup.select("#productDetails_techSpec_section_1 tr")
for row in rows:
header = row.find("th").get_text(strip=True)
value = row.find("td").get_text(strip=True)
details[header] = value
「detailBullets」形式の場合はこちら。
bullets = soup.select("#detailBullets_feature_div li")
for li in bullets:
txt = li.get_text(" ", strip=True)
if ":" in txt:
key, val = txt.split(":", 1)
details[key.strip()] = val.strip()
最後に結果を表示します。
print("Title:", product_title)
print("Price:", price)
print("Rating:", rating, "based on", reviews_count, "reviews")
print("Main image URL:", main_image_url)
print("Details:", details)
複数商品とページ送りに対応する
1 件取れたら、次はまとめて取りに行きたくなるはずです。検索結果や複数ページの処理パターンを紹介します。
検索結果ページから商品リンクを取得する
search_url = "<https://www.amazon.com/s?k=bluetooth+headphones>"
res = requests.get(search_url, headers=headers)
soup = BeautifulSoup(res.text, "lxml")
product_links = []
for a in soup.select("h2 a.a-link-normal"):
href = a['href']
full_url = "<https://www.amazon.com>" + href
product_links.append(full_url)
ページ送りを処理する
Amazon の検索 URL は &page=2、&page=3 と続きます。
for page in range(1, 6): # 最初の5ページをスクレイピング
search_url = f"<https://www.amazon.com/s?k=bluetooth+headphones&page={page}>"
res = requests.get(search_url, headers=headers)
if res.status_code != 200:
break
soup = BeautifulSoup(res.text, "lxml")
# ... 上と同様に商品リンクを抽出 ...
商品ページを巡回して CSV に出力する
取得したデータを辞書のリストにまとめ、pandas で書き出します。
import pandas as pd
df = pd.DataFrame(product_data_list) # dictのリスト
f.to_csv("amazon_products.csv", index=False)
Excel にしたい場合はこちら。
df.to_excel("amazon_products.xlsx", index=False)
Amazon スクレイパー Python プロジェクトのベストプラクティス
実情として、Amazon は頻繁にサイトを変え、スクレイパー対策も継続的にアップデートしています。スクリプトを長く運用するためのコツを並べておきます。
- ヘッダーと User-Agent をローテーション(
fake-useragentのようなライブラリを活用) - 大規模ならプロキシを必ず使う
- リクエストにランダムな
time.sleep()を挟む - エラーを丁寧にハンドリング(503 は再試行、ブロック時は待機を延ばす)
- 解析ロジックを柔軟に(各フィールドに代替セレクタを用意)
- HTML 変更を監視(全部
Noneになったらページを目視確認) - robots.txt を尊重する(Amazon は多くの領域でスクレイピングを禁止しています。節度を守って運用)
- 取得しながらデータを整形(通貨記号、カンマ、空白を除去)
- コミュニティと繋がる(フォーラム、Stack Overflow、Reddit の r/webscraping など)
スクレイパー保守のチェックリスト:
- User-Agent とヘッダーをローテーション
- 大規模ならプロキシを導入
- ランダムな遅延を挿入
- 保守しやすいモジュール構成にする
- BAN や CAPTCHA を監視
- 定期的にデータを書き出す
- セレクタとロジックをドキュメント化
さらに体系的に学びたい方は、Python でのウェブスクレイピングガイドも合わせてご覧ください。
コード不要の選択肢:Thunderbit AI ウェブスクレイパーで Amazon を取得する
AIでAmazonの商品データをスクレイピング Get Started Free
Python での手順は見てきた通りです。では「コードは書きたくない」「2 クリックでデータが欲しい」というニーズには何が応えるのか。答えが Thunderbit です。
Thunderbit は AI ウェブスクレイパーの Chrome 拡張機能で、Amazon の商品データ(ほぼあらゆる Web サイトのデータ)をコーディングなしで抽出できます。私が普段から推している理由は次の通りです。
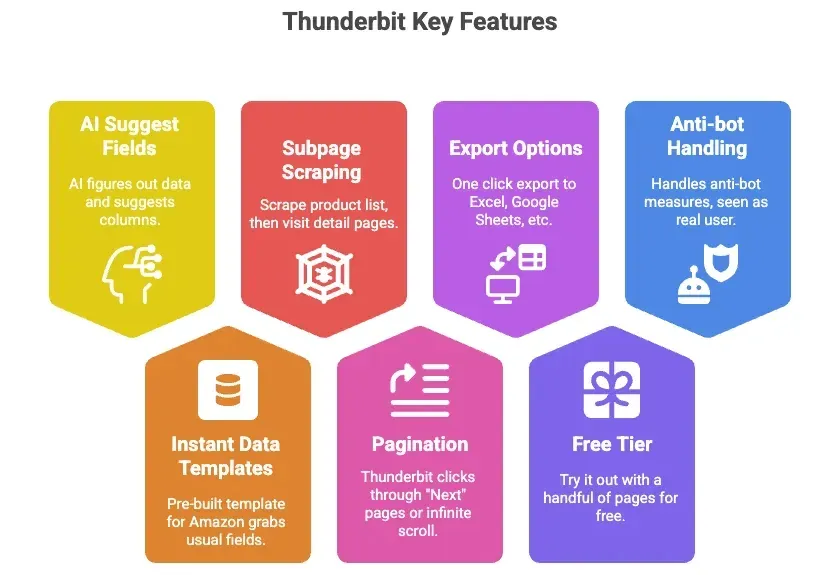
- AI が項目を自動提案: ボタンをひとつ押せば、Thunderbit の AI がページ構造を読み、タイトル・価格・評価などの列候補を提示します。
- すぐ使えるテンプレート: Amazon 向けには、よく使う項目を事前定義したテンプレートが用意されています。セットアップ作業は不要。
- サブページ取得: 商品一覧を取った後、Thunderbit に詳細ページを巡回させて追加情報を自動収集できます。
- ページ送り対応: 「次へ」リンクや無限スクロールも内部で処理されます。
- Excel / Google Sheets / Airtable / Notion へ書き出し: ワンクリックで業務にそのまま使える形に。
- 無料枠あり: まずは数ページで試せます。
- ボット対策も内部処理: ブラウザまたはクラウドで動くため、Amazon からは実ユーザーのリクエストとして扱われます。
ステップ別:Thunderbit で Amazon の商品データを取得する
操作はとてもシンプルです。
-
Thunderbit をインストール:
Thunderbit Chrome 拡張機能をダウンロードしてログインします。
-
Amazon を開く:
取得したい Amazon ページに遷移します(検索結果でも商品詳細でも OK)。
-
「AI で項目を提案」をクリック、またはテンプレートを使う:
Thunderbit が抽出列を提案します(Amazon 商品テンプレートを選んでも構いません)。
-
列を確認する:
必要に応じて列を編集します(項目追加・削除、名前変更など)。
-
「スクレイプ」をクリック:
Thunderbit がページからデータを抽出し、表として表示します。
-
サブページとページ送りを処理:
一覧から取得した場合は「サブページをスクレイプ」を押し、各商品の詳細ページから追加情報を収集します。「次へ」リンクも自動でクリック処理されます。
-
データを書き出す:
「Excel に出力」または「Google Sheets に出力」をクリックすれば完成です。
-
(任意)定期実行を設定:
日次でデータが欲しい場合は、Thunderbit のスケジューラで自動化できます。
ここまでです。コードも、デバッグも、プロキシも、ストレスも要りません。動画で見たい方は、Thunderbit の YouTube チャンネルか、Amazon 商品スクレイパーテンプレートのページを覗いてみてください。
Amazon スクレイパー Python vs. コード不要のウェブスクレイパー:比較
全体像を一表にまとめます。
| 比較項目 | Pythonスクレイパー | Thunderbit(コード不要) |
|---|---|---|
| セットアップ時間 | 長い(インストール、コーディング、デバッグ) | 短い(拡張機能を入れるだけ) |
| 必要スキル | コーディング必須 | 不要(ポイント&クリック) |
| 柔軟性 | 無制限 | 一般的な用途では高い |
| 保守 | 自分で修正 | ツール側で自動更新 |
| ボット対策対応 | プロキシやヘッダーを自分で管理 | 内蔵機能で自動対応 |
| 拡張性 | 手動(スレッド、プロキシ) | クラウドスクレイピング、並列処理 |
| データ出力 | 自由設計(CSV、Excel、DB) | ワンクリックでExcel、Sheetsへ |
| コスト | 無料(自分の時間+プロキシ代) | フリーミアム、規模に応じて課金 |
| 向いている人 | 開発者、細かな要件がある人 | ビジネスユーザー、すぐ結果がほしい人 |
細部までチューニングしたい開発者、独自要件が多いケースでは Python が強い。速度と手軽さ、コード不要を重視するなら Thunderbit がフィットします。
Amazon データで Python / コード不要 / AI ウェブスクレイパーを選ぶ判断軸
Python を選ぶ場面:
- カスタムロジックが必要、バックエンドに組み込みたい
- 数万件規模の超大量取得が前提
- スクレイピングの仕組み自体を学びたい
Thunderbit(コード不要 AI ウェブスクレイパー)を選ぶ場面:
- コードなしですぐデータが欲しい
- ビジネスユーザー、アナリスト、マーケターである
- チームメンバーに自走してもらいたい
- プロキシ、ボット対策、保守の苦労を避けたい
両方使うのが正解な場面:
- まず Thunderbit で素早く検証し、その後 Python で本番実装に落とす
- 収集は Thunderbit、整形と分析は Python に分担する
実際のところ、ビジネスユーザーの 9 割の用途は Thunderbit が短時間でカバーします。残りの 1 割、つまり超カスタム要件、超大規模、深い連携が必要な領域では、Python が引き続き王道です。
まとめと重要ポイント
2025年版:AIを使ってAmazonの商品とレビューをスクレイピングする方法 Get Started Free
Amazon の商品データを取得できる体制は、営業・EC・オペレーションのどの部門にとっても強力な武器になります。価格追跡、競合分析、あるいはチームをコピペ地獄から解放したい、どの目的にも適した解があります。
- Python でのスクレイピングは完全な自由度と引き換えに、学習コストと継続保守が必要です。
- Thunderbit のようなコード不要のウェブスクレイパーは、Amazon データ抽出を全員の手の届く作業に変えます。コードなし、悩みなし、結果だけが残ります。
- 最適解は、自分のスキル、納期、ビジネス目標に合った道具を選ぶことに尽きます。
気になった方はぜひ Thunderbit を試してみてください。無料で始められて、必要なデータが手元に届くまでの速さに驚くはずです。開発者の方も組み合わせ運用を恐れないでください。面倒な部分を AI に任せるのが、最短ルートになる場面は意外と多いものです。
FAQ
1. 企業が Amazon の商品データをスクレイピングする理由は?
価格モニタリング、競合分析、製品リサーチ向けのレビュー収集、需要予測、営業リード獲得に直結します。6 億点超の商品と約 200 万のセラーを抱える Amazon は、競合インテリジェンスの巨大な情報源です。
2. Python と Thunderbit のようなコード不要ツールの違いは?
Python スクレイパーは柔軟性が最大ですが、コーディングスキル、初期構築、継続保守のコストが伴います。Thunderbit はコード不要の AI ウェブスクレイパーで、Chrome 拡張から Amazon データを即時抽出可能。ボット対策内蔵、Excel や Sheets への直接出力にも対応します。
3. Amazon データをスクレイピングするのは合法?
Amazon の利用規約では一般にスクレイピングは禁止されており、ボット対策も積極的に運用されています。一方で、公開データをレート制限を守りながら適切に取得する事業者は数多く存在します。責任ある運用が前提です。
4. ウェブスクレイピングで Amazon から取得できるデータは?
商品タイトル、価格、評価、レビュー数、画像、仕様、在庫状況、セラー情報など多岐にわたります。Thunderbit はサブページ取得とページ送り処理にも対応するため、複数の一覧やページにまたがるデータも一度に集められます。
5. Python と Thunderbit、どう使い分ければよい?
完全な制御、独自ロジック、バックエンドへの組み込みが必要なら Python。コードなしで素早く結果が欲しい、簡単にスケールしたい、保守の手間を抑えたいビジネスユーザーには Thunderbit が向いています。
さらに深掘りしたい方はこちらも参考にしてください。
- Thunderbitブログ
- データスクレイピングとは何か、2025年にどう行うか
- 2025年版:AIを使ってAmazonの商品とレビューをスクレイピングする方法
- Pythonによるウェブスクレイピングガイド
軽快なスクレイピングを。そして、あなたのスプレッドシートが常に最新でありますように。
Amazon向けThunderbit AIウェブスクレイパーを試す Get Started Free




