

GitHubで「amazon scraper」と検索すると、約3,515件のリポジトリがヒットします。これを「過去6か月以内に更新されたもの」に絞ると約727件、つまり全体の20%未満まで減ります。残りには、更新が止まったチュートリアル、古いラッパー、Amazon側の対策変更後に動かなくなったスクリプトが多く含まれます。
私はこの数ヶ月、Amazonスクレイパー系リポジトリを時間をかけて調べ、GitHubのissueに加えてReddit/Stack Overflowのスレッドも追ってきました。そこで繰り返し見られたのは、人気リポジトリをセットアップしても、最初の実行でCAPTCHAや503エラーに直面するという状況です。2026年のAmazonの対ボットスタックは2年前から変化しており、TLSフィンガープリント、行動分析、積極的なCAPTCHA配信が組み合わされています。そのため、User-Agentの切り替えだけで安定運用するのは難しくなっています。
本稿では、GitHubリポジトリを使ってAmazonデータを継続的に取得したい開発者、EC運用担当者、リサーチ担当者に向けて、リポジトリの鮮度を監査する方法、ブロックリスクを抑える設定、障害時に備える代替策を整理します。
GitHub上のAmazonスクレイパーの仕組みと、多くが動かなくなる理由
GitHubのAmazonスクレイパーリポジトリは、基本的にオープンソースのスクリプト群です。多くはPython、Node.js、またはScrapyをベースに、Amazonページから構造化データを抽出します。主な対象は、商品タイトル、価格、ASIN、評価、レビュー数、在庫状況、出品者情報、検索結果カード、レビュー本文などです。
基本的な構成は次のとおりです。
- HTTPクライアントまたはヘッドレスブラウザでページを取得する。
- HTMLまたはJSONパーサーで必要な項目を抽出する。
- データをCSV、JSON、データベースに保存する。
リポジトリは、おおむね4タイプに分類できます。
- 軽量Pythonライブラリ(例:amzpy)
- Scrapyスパイダー(例:amazon-python-scrapy-scraper)
- Selenium/Playwrightによるブラウザ自動化
- APIラッパー系プロジェクト。実態は商用スクレイピングサービスのフロントエンド(例:oxylabs/amazon-scraper)
動かなくなる理由にも共通点があります。
- Amazonがページレイアウトや断片化されたHTMLを変更する
- 実データの代わりに503やCAPTCHAが返る
- スクレイパーのTLSやHTTPフィンガープリントが、ブラウザの挙動と一致しなくなる
- ロケール、言語、ヘッダーの不整合が検出要因になる
- 当初の用途を満たした後、メンテナーが更新を停止する
スター数の多さだけでは、現在も動作するか判断できません。本稿のために行った監査では、広く流通する8リポジトリのうち、2026年時点で明らかにアクティブと判断できたのは3つほどでした。
2026年版の鮮度監査:Amazonスクレイパー系GitHubリポジトリをクローンする前に
この監査は、Amazonを対象にする場合には特に重要です。Amazon側の対策は一般的なECサイトより変化が速いとされ、紹介時には動いていたリポジトリでも、数週間後に利用できなくなる可能性があります。一方、「best amazon scraper github」系の一覧記事では、現在も動作するかを検証せずにリポジトリが紹介されることがあります。その結果、利用者が動かないツールのセットアップに長い時間を費やす場合があります。
GitHubリポジトリがまだ生きているかの確認手順
git cloneを実行する前に、次の項目を調べます。
- 最終コミット日: Amazon向けでは、6か月以上更新がない場合は慎重に評価します。
- 未解決issueと応答率: Issuesタブで「captcha」「503」「blocked」「not working」を検索します。障害報告が積み上がり、メンテナーから返信がない場合は、別の候補も比較します。
- 依存関係の健全性:
requirements.txtやpackage.jsonを調べます。最新のTLS対応を想定していない古いライブラリは、更新や置き換えが必要になる可能性があります。 - Amazonページ種別の対応範囲: 商品ページ、検索結果、レビューのすべてに対応するのか、1種類だけなのかをREADMEとコード例で照合します。
- 対ボット対策の方針: プロキシを使わず、ハードコードしたヘッダーだけに依存する構成は2023年頃の発想であり、2026年の運用では追加対策が必要になる場合があります。
Amazonスクレイパー系GitHub鮮度チェックリスト

| 鮮度のシグナル | 確認ポイント | 危険信号 🚩 |
|---|---|---|
| 最終コミット日 | コミットフィードまたはリポジトリの push 日 | 6か月以上前 |
| 未解決 issue | Issues タブ — 「captcha」「503」「blocked」で絞り込み | メンテナーの返信なしで障害報告が繰り返される |
| 依存関係の健全性 | requirements.txt / package.json | 廃止済みライブラリ、最新の TLS 対応なし |
| Amazon ページの対応範囲 | README + コード例 | 1種類のページしか扱えない(例: 商品ページのみで検索やレビューは不可) |
| 対ボット対策 | ソースコード、プロキシ設定 | ハードコードされたヘッダーと UA 文字列のみ |
| メンテナンス形態 | スクレイパー本体か、チュートリアルか、商用 API ラッパーか | 実態は有料サービスのフロントエンド |
実際に監査して見えたこと
代表的なAmazonスクレイパーリポジトリ8件を、上の基準で調べました。結果は次のとおりです。
| リポジトリ / ツール | スター数 | 最終コミットの目安 | スコープ | 2026年の状態 | メモ |
|---|---|---|---|---|---|
| oxylabs/amazon-scraper | 約2,872 | 2026-04-02 | 管理型スクレイピング API ラッパー | 生存しているが DIY ではない | 新しいが、実際には管理サービスのフロントエンド |
| omkarcloud/amazon-scraper | 約214 | 2026-02-25 | 検索、詳細、レビュー用の管理 API | 生存しているが DIY ではない | 対応範囲は広いが、純粋なスクレイパーではなく API 製品 |
| theonlyanil/amzpy | 約110 | 2026-02-26 | 軽量な Python ライブラリ | 生存 | curl_cffi を使う、GitHub 上で直接使えるスクレイパーとして最も明快 |
| philipperemy/amazon-reviews-scraper | 約134 | 2024-11-21 | レビュー専用 | 狭いが使用可能 | 古く、レビュー特化がかなり強い |
| python-scrapy-playbook/amazon-python-scrapy-scraper | 約74 | 最終コミット 2023年; repo pushed 2024-08-20 | Scrapy スパイダー + プロキシミドルウェア | チュートリアル級で古い | 学習用には有用だが、2026年の即戦力スタックではない |
| drawrowfly/amazon-product-api | 約744 | 2022-11-13 | 検索、詳細、レビュー用の Node CLI | 高リスク | 対応範囲は広いが、メンテナンスが古すぎる |
| tducret/amazon-scraper-python | 約881 | 2020-10-13 | 検索結果を CSV に出力 | 2026年には事実上終了 | 歴史的には人気だが、明らかに古い |
| scrapehero-code/amazon-scraper | 約432 | 2020-06-21 | 検索 / 商品のチュートリアル | 2026年には事実上終了 | 実質的にアーカイブ |
公開issueにも同じ傾向が見られます。drawrowfly/amazon-product-apiには「All requests receive captcha response.」というissue、theonlyanil/amzpyには「Doesn't seem to be working.」、python-scrapy-playbookのスクレイパーには「Bypass Amazon protection.」が並びます。これらは、利用開始時からCAPTCHAやブロックへの対応が必要になる可能性を示しています。
GitHub上のAmazonスクレイパーでブロックリスクを抑えるための運用
ブロック対策は、amazon scraper github系プロジェクトを運用する際の主要な課題です。プロキシとUser-Agentの切り替えだけでは、十分に対応できない場合があります。Amazonの2025〜2026年対ボットスタックには、TLSフィンガープリント、行動分析、積極的なCAPTCHA配信が含まれるとされます。そのため、通信特性、セッション、アクセス頻度を組み合わせて設計する必要があります。
TLSフィンガープリント整合:素のrequestsが検出要因になる理由
TLSフィンガープリントは、Amazon向けクライアントを設計する際の重要な確認点です。スクリプトがAmazonと安全な接続を確立すると、サーバー側は「提示された暗号スイート」「拡張順序」「HTTP/2設定」などからクライアント実装の特徴を推定できます。ブラウザのTLS/HTTP/2設定には一定の傾向があり、JA3やAkamai HTTP/2フィンガープリントのような手法で識別されます。
素のrequestsや通常のhttpxでは、ヘッダーを合わせても、Chromeに近いTLS/HTTP/2の挙動まで再現できません。この差異が判定材料になる可能性があります。
curl_cffiは、ブラウザ偽装機能を提供しており、対応プロファイルにはchrome136、safari184、firefox133などがあります。これにより、HTTPクライアントのTLSフィンガープリントを実在するブラウザプロファイルに近づけられます。ドキュメントでは、ランダムなJA3文字列を自作するのではなく、実在するブラウザのフィンガープリントを利用するよう案内されています。
コミュニティでも関連する報告があります。curl_cffi+Amazon関連のRedditスレッドでは、impersonate引数でブラウザプロファイルを切り替えながらヘッダーとの整合性を保てる点が評価されています。別のRedditスレッドでは、投稿者が「1〜2か月後」にTLSフィンガープリントを根拠としてブロックされたと述べています。Stack Overflowのスレッドでも、Amazonがpython-requestsをフィンガープリントしている可能性が議論されています。
Amazon向けクライアントに素のrequestsを使っている場合は、他の設定を調整する前に、通信方式を見直すことが優先されます。
適切なプロキシローテーション(「プロキシを使う」だけでは不十分)
プロキシ運用では、頻繁な切り替えよりも、IP、Cookie、ヘッダー、閲覧動線をセッション単位で整合させることが重要です。
住宅用 vs データセンター用: データセンタープロキシは比較的安価ですが、検出されやすいとされています。住宅用は割高な一方、Amazonへのアクセスで選択肢になる場合があります。Bright Dataの住宅用プロキシ価格は従量課金で4.00ドル/GB〜、上位プランで3.50ドル/GBまで下がります。Oxylabsの住宅用プロキシは6ドル/GB〜。Amazon向けの運用では、必要な成功率とデータ量を踏まえて追加コストを評価します。
リクエスト毎 vs セッション毎の切り替え: Cookieやヘッダーを維持したまま、リクエストごとにプロキシだけを切り替えると、セッションの整合性が崩れます。運用例は次のとおりです。
- 可能な限り、検索→商品→レビューの動線は同じstickyセッションで通す
- 新しい検索動線を始めるときにセッションを切り替える(毎リクエストではない)
- 1セッション内でランダム切り替えするのではなく、セッション間でローテーションする
あるRedditのコメントでは、一般的なISPのIPは人気ECサイトに対してモバイルIPほど有効でない可能性が指摘されています。別のスレッドでは、User-Agentの切り替えと住宅用プロキシを併用してもブロックされた事例が報告されています。プロキシだけでなく、通信特性やアクセス頻度も合わせて見直す必要があります。
リクエスト間隔、バックオフ、レート制限
Amazonから503ページが返った場合は、アクセス条件を見直す合図として扱います。
500以上のASINをスクレイピングする話を扱ったStack Overflowの投稿では、sleepを入れていても毎回同じ地点、ASIN 101前後で503が出ると報告されています。事例自体は古いものの、同一IPやフィンガープリントから大量にアクセスすると、防御機構に検出される可能性があることを示しています。
DIY系GitHubスクレイパーで配速を設定する際の目安は次のとおりです。
- リクエスト間にランダムな遅延を入れる(固定間隔だけに依存しない)
- 単純なHTTPクライアントでは、公開商品ページのリクエスト間を2〜5秒とし、応答状況に応じて調整する
- 503やCAPTCHA後は指数バックオフを使う(即時再試行せず、段階的に間隔を広げる)
- 必要以上に同時実行数を増やさない
- 再試行を無制限に繰り返さず、失敗内容をログに残して次の処理へ進む
多くのamazon scraper github系リポジトリには、レート制限が組み込まれていません。対象サイトの応答と運用要件に合わせて、自分で制御を追加します。
ヘッダー統制:User-Agentだけでは終わらない
AmazonはUser-Agentだけでなく、ヘッダー全体を見ています。
現実的なブラウザヘッダーセットには次の項目を含めるべきです。
User-AgentAcceptAccept-LanguageAccept-Encoding- 必要に応じた
Sec-CH-*ヒント - 選択したブラウザプロファイルと整合する接続挙動
ヘッダーはマーケットプレイスのロケールに合わせる必要があります。10個のAmazonロケールをスクレイピングしていたRedditユーザーは、同じボット設定でも一部ロケールでしか検出されず、別のコメントではAccept-Languageのような地域関連ヘッダーが原因では、と推測されていました。
原則は明確です。ヘッダー、TLS/ブラウザプロファイル、プロキシの地理情報は、互いに矛盾してはいけません。ChromeヘッダーをFirefox UAと一緒に送るのは禁物、Accept-Language: de-DEに米国プロキシも禁物、ということです。
CAPTCHA対応:解くべきタイミングと、処理を止めるタイミング
CAPTCHAが表示された場合は、セッションやアクセス条件が不審と判定されている可能性があります。CAPTCHAを解決しても、フィンガープリント、アクセス履歴、IP評価まで初期化されるとは限りません。
単発・低頻度のCAPTCHA:
amazoncaptchaのPyPIパッケージは、Python製のAmazonテキストCAPTCHAソルバー。ただし最新リリースが2023年5月なので、長期運用の基盤ではなく限定的な補助手段として扱う。- 2Captchaでは、Amazon Captchaの解決が1,000件あたり1.45ドル。
CAPTCHAが繰り返し表示される場合:
- 解決を繰り返さず、処理を止めて間隔を空ける
- セッション履歴、フィンガープリント、IP評価を見直し、新しいセッションで再設計する
- CAPTCHAが特定のプロキシサブネットに集中する場合は、パーサーだけでなくネットワーク層も調べる
ヘッドレスブラウザが必要なケースと、HTTPクライアントで足りるケース
すべての処理をPlaywrightで実行すると、用途によっては処理時間とリソース消費が大きくなります。ページの状態に応じて方式を選びます。
ブラウザを使うべきケース:
- JavaScriptレンダリングやロケール依存の状態に左右される検索結果
- ログイン/サインインページへリダイレクトされるレビュー動線
- Cookieやブラウザコンテキストの重要度が、速度より上回るワークフロー
ブラウザを使わなくてよいケース:
- 通常の公開商品ページ
- ブラウザ風のHTTPクライアントで足りる、静的な商品詳細抽出
- 計算効率が重要な大規模一括取得
まず、要件を満たす最も軽量なクライアントから検証します。大規模スクレイピングについてのRedditスレッドでは、requests→curl_cffi→失敗時のみフルブラウザ、という段階的アプローチが紹介されています。Amazon商品ページの取得では、ヘッドレスブラウザはHTTPクライアントより遅く、リソース消費も大きくなる傾向があります。
Amazonスクレイパー系GitHubプロジェクト向け:BAN回避判断マトリクス
| シナリオ | 推奨アプローチ | 理由 |
|---|---|---|
| 公開商品ページ(小規模) | curl_cffi + sticky な住宅用セッション | 比較的低コストで、ブラウザに近い通信特性を持たせやすい |
| 検索結果ページ | まず curl_cffi、レンダリングや状態で HTTP が崩れる場合のみ Playwright | 検索は状態依存が強く、ロケールの影響も受けやすい |
| レビュー(ログイン必須) | 実Cookie / セッションを使ったブラウザモード | ログインと動的なレビューの流れは、素の HTTP では再現しにくい |
| 大規模(1日5,000件以上) | 管理型スクレイピング API、アンロッカー、またはノーコードツール | 処理量が増えると、DIY の GitHub コードではインフラ運用が中心課題になりやすい |
Amazonスクレイパー系GitHubプロジェクトが壊れたとき:ノーコードを含む代替手段を用意する
継続運用する場合は、GitHubリポジトリが動かなくなったときの代替経路を事前に決めておく必要があります。
Amazon側の変更によってスクレイパーが停止すると、ECチームでは価格変更の見落とし、競合データの陳腐化、ダッシュボードの欠損につながります。
「amazon scraper github」と検索する人には、開発者だけでなく、EC運用担当者、マーケター、FBAリサーチャーなどのビジネスユーザーも含まれます。コード以外の選択肢が要件に合わず、GitHubリポジトリを検討するケースもあります。フォーラムには、Amazon公式のProduct Advertising APIについて、アクセス制限や取得可能なデータ、登録要件に関する不満も見られます。
GitHubのAmazonスクレイパーが継続的なメンテを必要とする理由
上の監査結果から、継続運用で必要になる作業が分かります。
- 古いリポジトリでは、動作不良の報告が修正されないまま蓄積する
- 現在動くリポジトリでも、READMEで対ボット対策への対応が説明されるようになっている
- コミュニティの関心は、CSSセレクターだけでなく、TLSフィンガープリント、CAPTCHAループ、プロキシ品質にも広がっている
ビジネスユーザーにとっては、この保守作業も運用コストに含まれます。リポジトリ自体が無料でも、障害調査、依存関係の更新、再実行に担当者の時間が必要です。
実用的なAmazonスクレイパーの代替としてのThunderbit
Thunderbitは、コードを書かずにタイトル、価格、ASIN、評価、ブランド、在庫、出荷元、元URLを抽出できるAmazon Products Scraperテンプレートを提供しています。GitHubコードを自社で保守せず、定型的な商品情報を表形式で取得したい場合の選択肢です。
主な機能は次のとおりです。
- Python環境、依存関係、プロキシ設定を整える代わりに、2クリックでスクレイピング
- Amazon向けテンプレートをそのまま利用 — AIの下準備不要、1クリック抽出のみ
- ログインが必要なページ(GitHub系利用者を悩ませるレビュー画面など)向けのブラウザスクレイピングモード
- 公開商品ページを高速取得するクラウドスクレイピング(一度に50ページ)
- Google Sheets、Airtable、Notion、Excelへの無料エクスポート(CSV/JSONだけではない)
- 継続的な価格監視のためのスケジュールスクレイパー
- AIによる抽出設定の支援 — レイアウト変更時のメンテナンス負担を抑える
一方、コードレベルで抽出処理を細かく制御したい場合や、独自のインフラ・API連携が必要な場合は、GitHubリポジトリや管理型APIも比較対象になります。
GitHubのAmazonスクレイパーとThunderbitの使い分け

| 要素 | GitHub スクレイパー(例: AmzPy) | Thunderbit |
|---|---|---|
| セットアップ時間 | 15〜60分(Python、依存関係、プロキシ) | 約2分(Chrome 拡張機能 を入れるだけ) |
| メンテナンス | 壊れたら自分で直す | AI による抽出設定でレイアウト変更への対応を支援 |
| 対ボット対策 | 自前対応(プロキシ、ヘッダー、TLS) | クラウド + ブラウザモードを利用 |
| レビュー抽出(ログイン済み) | 複雑なセッション管理 | ブラウザスクレイピングモード |
| データ出力 | CSV/JSON のみ | Sheets、Airtable、Notion、Excel、CSV、JSON |
| スケジューリング | 自前(cron、Airflow など) | 標準搭載のスケジュールスクレイパー |
| カスタマイズ性 | 高い | 低い |
| コスト | 無料(プロキシ費用は別) | 無料プランあり;クレジット制 |
GitHubリポジトリは、抽出処理を細かく制御し、独自の連携を組み込みたい場合に向いています。Thunderbitは、セットアップや保守の負担を抑えて定型データを取得したいチームの候補です。柔軟性と運用負荷のどちらを優先するかで選択が変わります。
定期的・継続的なAmazonスクレイピングのベストプラクティス
多くのamazon scraper github系プロジェクトはワンショット実行を想定しています。一方、価格監視、在庫追跡、競合分析などでは、定期的な実行が必要になる場合があります。GitHubリポジトリにスケジューリング機能が含まれていない場合は、cron、Airflow、n8nなどを組み合わせて実行環境を構築します。
GitHubのAmazonスクレイパーをDIYで定期実行する方法
最小構成は次のとおり。
- LinuxまたはmacOS上のcronジョブでスクリプトをスケジュール実行する
- 後から失敗原因を追えるよう、追記型ログを残す
- 既存データの重複保存を避けるため、ASIN+タイムスタンプで重複排除する
- 失敗に気付けるよう、失敗通知を入れる(非ゼロ終了時の簡易メールでも可)
より複雑な体制を取るチームには、以下の選択肢があります。
- 軽量なワークフロー自動化にはn8n(コミュニティスレッドでも頻出)
- 重めの定期パイプラインにはAirflow
- 差分と履歴が必要ならデータベースで状態管理
肝はスケジューラ自体ではなく状態管理です。最後に成功した実行、最後に取得したASIN集合、価格の変化、失敗URLを追跡する設計を入れてください。
Thunderbitで定期実行を設定する方法
Thunderbitのウェブスクレイパーの作り方:ステップごとのチュートリアルでは、実行間隔を自然な日本語で記述し、URLを入力して「スケジュール」を押すことで設定できます。AIが自然言語をcronスケジュールに変換するため、cron環境を自分で用意せずに始められます。価格や競合商品の発売を追う非エンジニアのECチームが、定期実行の運用工数を抑えたい場合の選択肢です。
継続的Amazonスクレイピングのベストプラクティス
どのツールを使う場合でも、以下は共通です。
- ASIN+タイムスタンプの窓で重複排除する — 同じ商品を1回の実行で2度保存しない
- 価格は生文字列ではなく数値として保存する — 後処理が楽になる
- 各行にスクレイプ時刻を付与する — トレンド分析に必須
- 現在値だけでなく差分を追う — 「先週より12%下落」は「価格24.99ドル」より情報価値が高い
- 意味のある変化だけ通知する — 競合が15%値下げした通知には価値があり、0.5%の変動はノイズ
- データ保存方法を設計する — 小規模ならフラットファイルで足りるが、1日5,000ASIN超ならDBやクラウドスプレッドシートを検討
Amazonスクレイパー系GitHubアプローチの出力品質を比較する
amazon scraper github系リポジトリについて、実際の出力品質を同じ観点で比較した情報は限られています。一方、利用者にとっては、取得件数だけでなく、データの欠損、型、画像品質、後処理の必要性も重要です。ここでは、各リポジトリのREADME、公開例、文書化された出力形式をもとに、取得できる項目とトレードオフを整理します。
人気GitHubリポジトリが実際に抽出できるもの/取りこぼすもの
READMEのサンプル、公開例、文書化された出力形式から整理すると、次のとおり。
| アプローチ | 明確に抽出できるもの | よくある欠落 / トレードオフ |
|---|---|---|
| amzpy | タイトル、価格、通貨、画像 URL、評価、レビュー、バリエーション、ASIN | 商品ページ寄り。レビュー全文や仕様セクションはやや弱い |
| tducret/amazon-scraper-python | タイトル、評価、レビュー数、商品 URL、画像 URL、ASIN を含む CSV | 古く、リスティング中心で、対ボット対策が弱い |
| python-scrapy-playbook scraper | 検索結果、商品ページ、レビュー、CSV/JSON パイプライン | チュートリアル級。外部プロキシミドルウェアに依存し、後処理が必要になりやすい |
| omkarcloud/amazon-scraper | 検索、カテゴリ、詳細、トップレビュー、多数の画像 / 動画 / 仕様 | 純粋なスクレイパーではなく、管理型 API サービスです |
| Thunderbit Amazon template | タイトル、価格、ASIN、ブランド、評価、レビュー、在庫、出荷元、サブページ補完 | カスタムスクリプトほどのコードレベル制御はない |
出力品質比較表
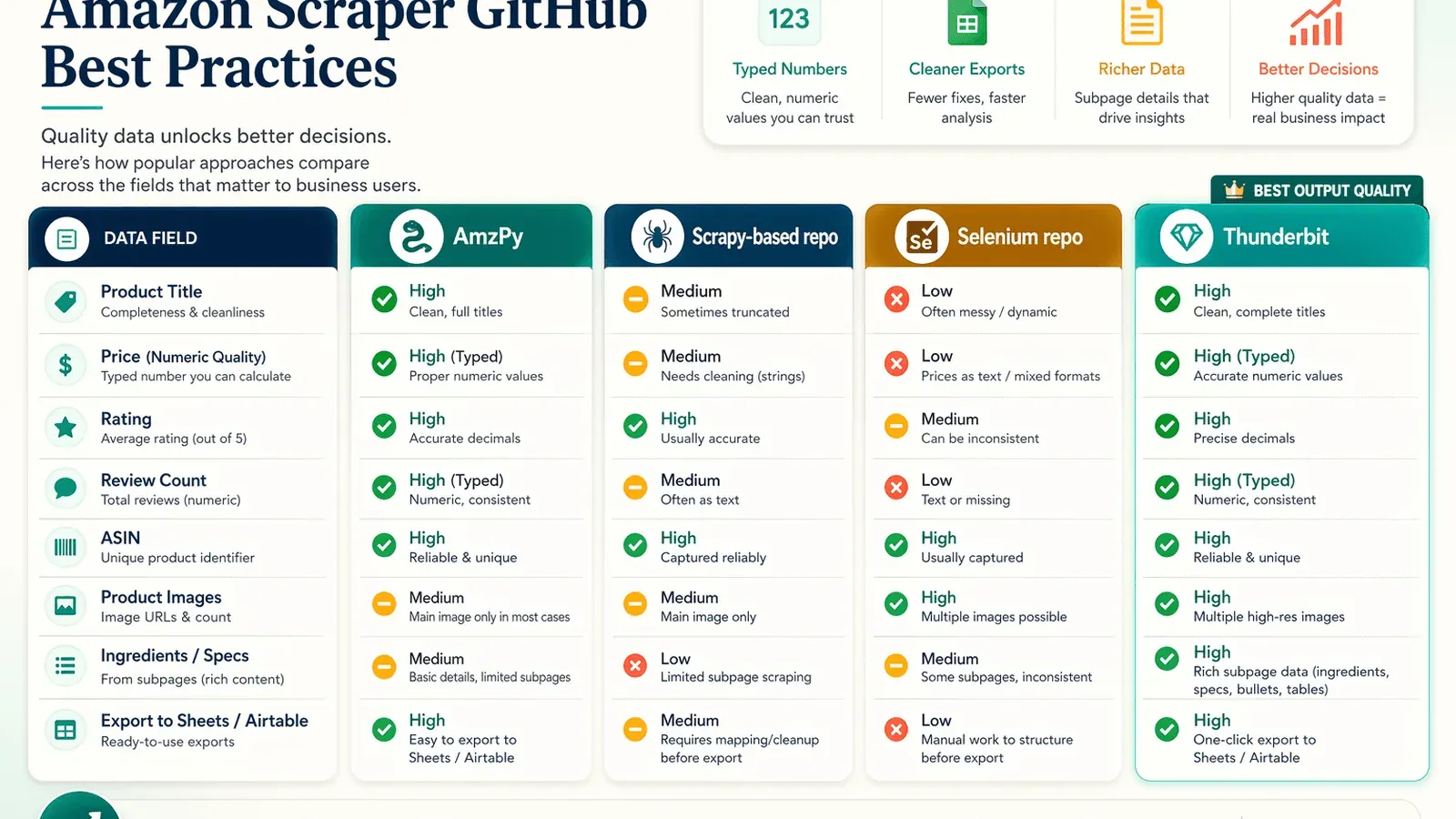
| データ項目 | AmzPy | Scrapy ベースのリポジトリ | Selenium リポジトリ | Thunderbit |
|---|---|---|---|---|
| 商品タイトル | ✅ | ✅ | ✅ | ✅ |
| 価格(数値) | ⚠️ 文字列 | ✅ | ⚠️ 文字列 | ✅(数値型) |
| 評価 | ✅ | ✅ | ✅ | ✅ |
| レビュー数 | ❌ | ✅ | ✅ | ✅ |
| ASIN | ✅ | ✅ | ✅ | ✅ |
| 商品画像 | ❌ | ⚠️ サムネイルのみ | ✅ | ✅(高解像度、エクスポート可) |
| 原材料 / 仕様 | ❌ | ❌ | ❌ | ✅(サブページスクレイピング + AI 経由) |
| Sheets/Airtable へのエクスポート | ❌ | ❌ | ❌ | ✅ 無料 |
なぜビジネスユーザーにとってデータ形式が重要なのか
スクレイパーが動作していても、出力形式が業務要件に合わなければ、後処理の工数が増えます。たとえば、次のような状態です。
- 価格が通貨記号付き文字列で、きれいな数値になっていない
- 欠損値の表現がバラバラ(空文字、null、"N/A"が混在)
- 画像が低解像度サムネイルしか取れていない
- 分析前にレビュー項目や仕様を後処理する必要がある
EC運用では、データ型と欠損値の表現を揃えることで、集計や比較に移るまでの時間を短縮できます。Thunderbitは、数値、日付、URLなどを型に合わせて整形する機能を備えています。GitHub系リポジトリは出力仕様が異なるため、導入時には取得項目だけでなく、必要な後処理も比較することが重要です。
Amazonスクレイパー系GitHubの運用チェックリスト
- クローン前に最終コミット日を調べる。Amazon向けでは、6か月以上更新がない場合は慎重に評価する。
- セットアップ前に、issueで「captcha」「503」「blocked」「not working」を検索する。
- 素の
requestsより、curl_cffiなどのブラウザ偽装HTTPクライアントを優先する。 - ヘッダー、TLSプロファイル、言語、プロキシ地理情報を整合させる。
- ブラウジング動線ではstickyセッションを使い、毎リクエストで機械的に切り替えない。
- ランダム間隔と指数バックオフを入れる。
- CAPTCHAが繰り返し表示されたら、解決を続けず、セッションやネットワーク条件を見直す。
- ヘッドレスブラウザは、HTTPクライアントでは再現できない場合だけ使う。
- 失敗した実行を安全に再開できるよう、チェックポイントと状態を保存する。
- 代替手段を用意する。 管理型APIでも、Thunderbitのようなノーコードツールでも構わない。
2026年のAmazonスクレイピングにおける法務・倫理面の注意点
Amazonデータを自動取得する前に、現在の規約、技術的なアクセス制限、利用目的を照合する必要があります。関連する情報は次のとおりです。
- Amazon自身のヘルプページは現在、403ページを返し、「Amazonデータへの自動アクセスについては api-services-support@amazon.com まで連絡してください」と案内しています。
- Amazonのrobots.txtでは、動的ページ、レビュー、プロフィール、ほしい物リスト、出品一覧の多数パスが制限対象として列挙されています。
- Amazonは2025年10月31日のPerplexity宛て差し止め書簡で、秘密裏または偽装されたエージェントアクセス、セキュリティ対策回避、エージェントをGoogle Chromeと誤認させる行為に異議を表明しています。Amazonはこの件について公開声明も出しています。
- Amazonは2025年後半に、OpenAIのクローラーに対してボット除外を拡大しました。
公開商品ページの取得と比べ、認証が必要な情報へのアクセス、ブラウザを偽装する自動化、大量の商用抽出では、契約・技術・法務上のリスクが高くなる可能性があります。本稿は法的助言ではありません。具体的な状況は、自社の法務チームに相談してください。
まとめ:Amazonデータ取得を安定運用するための要点
優先順に整理します。
- クローン前に監査する。 最終コミット、未解決issue、依存関係、対応ページを調べ、現在の要件を満たすか判断する。
- 通信設定の整合性を先に検証する。 TLSフィンガープリント、ヘッダー、セッション、ロケールを一体として見直す。
- プロキシを使う場合はセッション単位で管理する。 リクエストごとの無秩序な切り替えを避け、用途に応じてstickyな住宅用セッションを検討する。
- アクセス頻度を制御する。 対象サイトの応答と利用条件を踏まえ、ランダム遅延、同時実行数の制限、指数バックオフを設定する。
- CAPTCHAが繰り返されたら処理を止める。 解決を続けるのではなく、セッション、IP、アクセス方法を見直す。
- 代替手段を持っておく。 GitHubリポジトリが停止した場合に備え、Thunderbitのような保守済みノーコードツールや管理型APIを比較しておく。
- 出力品質を評価する。 取得速度だけでなく、欠損、データ型、画像品質、後処理の工数まで含めて判断する。
コードの保守より運用のしやすさを重視する場合、Thunderbitは比較候補になります。Amazon Products Scraperテンプレートで対象ページの取得項目を試すか、Thunderbit YouTubeチャンネルのチュートリアルを参照できます。独自の制御が必要な開発者はGitHubリポジトリを選べますが、いずれの場合も対象サイトの規約、現在のリポジトリ状態、取得データの品質を検証してから運用範囲を広げることが重要です。
FAQ
GitHubのスクレイパーでAmazonの商品データを取得するのは合法ですか?
合法性は、取得対象、アクセス方法、Amazonとの契約、適用される法令、データの利用目的によって異なります。Amazonの利用規約は自動データ収集を制限しており、Amazonは差し止め通知や技術的対抗策を通じて執行しています(特に2025〜2026年)。公開商品ページと比べ、ログイン後の情報を取得することや、ボットを実ブラウザに偽装することではリスクが高くなる可能性があります。本稿は法的助言ではありません。具体的な用途については法務チームに相談してください。
Amazonのスクレイパー系GitHubリポジトリは、どのくらいの頻度で壊れますか?
頻度は、対象ページ、実装方式、メンテナンス状況によって異なります。Amazonはページレイアウトを変更し、対ボット層を追加し、エンドポイントを廃止することがあります。本稿の監査では、広く流通する8件のうち、2026年に明確に機能していると判断できたのは約3件でした。「動く」とされるリポジトリでも、CAPTCHAや503エラーに関するissueが残っている場合があります。運用時は、数週間〜数か月単位で状態を見直し、必要に応じて設定や依存関係を更新する前提を置きます。
2026年にGitHubで最良のAmazonスクレイパーはどれですか?
唯一の正解はありません。用途と技術的な慣れ次第です。軽量な直接型のPythonスクレイパーならamzpyが比較的新しい選択肢の一つ。管理型API経由で広いカバレッジが欲しいならomkarcloud/amazon-scraperが使えますが、完全なDIYではありません。どのリポジトリでも、クローン前に本稿の鮮度チェックリストで自分で評価してください。
Thunderbitはコードなしでも Amazonをスクレイピングできますか?
可能です。ThunderbitのAmazon Products Scraperテンプレートを使うと、商品タイトル、価格、ASIN、評価、ブランド、在庫などをワンクリックで抽出できます。ログイン必須ページ向けのブラウザスクレイピングモード、公開ページ向け高速クラウドスクレイピング、定期ジョブ向けのスケジュールスクレイピング、Google Sheets、Airtable、Notion、Excelへの無料エクスポートに対応しています。Thunderbit Chrome拡張機能を導入し、まず対象ページで取得項目と出力形式を試すことができます。
AmazonをスクレイピングするときにIPをBANされないようにするには?
ブロックを完全に避けられる方法はありません。リスクを抑えるには、複数の層を一貫して設計します。(1) 素のrequestsからcurl_cffiのようなTLS偽装クライアントへの切り替えを検討する、(2) プロキシを使う場合は、ランダムなデータセンター切り替えではなく、stickyセッション付きの住宅用プロキシを候補にする、(3) ランダムな配速と指数バックオフを加える、(4) ヘッダー一式をブラウザプロファイルとマーケットプレイスのロケールに揃える、(5) CAPTCHAが繰り返されたら処理を止め、セッション、IP、アクセス頻度を見直す。対象サイトの利用規約と許容されるアクセス方法も事前に照合してください。詳細は本稿前半のBAN回避判断マトリクスを参照してください。




