
どのAIウェブスクレイパーも、製品紹介のデモでは見事に見えます。ところが、実際のサイトでCloudflare対策がかかったページを指定すると、保護画面を返しながら、「47件の商品リストを見つけた」と自信満々に言い始めるのです。
私はここ数か月、Thunderbitのチーム向けにスクレイピングツールを評価してきました。デモでの性能と本番運用での安定性の差は、コミュニティで最もよく聞く不満のひとつです。あるRedditユーザーは、これを的確にこう表現していました。[] Webスクレイピングカテゴリだけでも、そのほかにもChrome拡張、APIベンダー、アクターマーケットプレイスが何十とあります。選択肢が多すぎるという悩みは本物です。そこで私は12製品を実際に試しました。
この記事では、12のAIウェブスクレイパーツールを本番運用の基準で評価します。基準は、対ボット対応、拡張性、構造化出力の品質、コスト効率、動的サイト対応、そして開発者向けの柔軟性です。機能一覧ではありません。マーケティング用のスクリーンショットでもありません。デモが終わったあとに本当に動くものだけを見ます。
ほとんどのAIウェブスクレイパーがデモの先で失敗する理由
この市場では、いつも同じパターンが起こります。ツールの紹介ページでは、シンプルな商品一覧からきれいに列を抜き出しているように見えます。ところが実際に導入して、防御の強いECサイトで試すと、次のどれかになります。
- 実データの代わりにCloudflareの保護画面を含む
200 OKレスポンスが返る - 最初の5ページだけはきれいに取れるのに、その後は静かに失敗するか、存在しない行をでっち上げる
- 今日は完璧に抽出できても、来週に少しレイアウトが変わっただけでセレクタが壊れる
これは例外ではありません。むしろ普通です。
ある実務家が。「スクレイパーがCloudflareの保護画面に対して200を返し、エージェントがそれを解釈しようとして、ありもしない内容を作り出す。でも、なぜそうなったのかは分からない。」
根本原因はアーキテクチャにあります。多くのデモは、きれいな公開ページ上での解析レイヤーだけを見せますが、実際の作業で失敗するのは取得レイヤーです。本番サイトには、ボット対策、動的レンダリング、入れ子の詳細ページ、無限スクロール、ログイン状態、ロケール差分、変わり続けるレイアウトがあります。
ツールは製品ツアーでは素晴らしく見えても、本格的な顧客ワークフローの最初の段階で崩れることがあります。
だからこそ、この記事では機能一覧ではなく、本番対応力の観点で各ツールを評価します。私が使った6つの基準は次の通りです。
| 基準 | 重要な理由 |
|---|---|
| 対ボット/CAPTCHA対応 | 保護サイトでは、抽出品質の前にまず失敗するため |
| デモを超えた拡張性 | バッチ処理や並列実行で運用上の限界が見えるため |
| 構造化出力の品質 | ユーザーが必要とするのは、手作業で掃除が必要な生HTMLではなく、きれいなJSON/CSVだから |
| トークン/コスト効率 | AI抽出のコストが、スクレイピング自体より高くなることがあるため |
| 動的/JS多用サイトへの対応 | 現代のページには静的HTMLではなく、レンダリング済みDOMが必要だから |
| ノーコードとAPIの柔軟性 | 営業チームとデータエンジニアでは必要なものが違うため |
ここ2年でWebスクレイピングがどう変わったかをざっと把握したいなら、ツールを1つずつ比較する前に、このBrowserlessの講演が全体像をつかむのにちょうどいいです。
スクレイピングパイプラインでAIが本当に役立つ場所と、そうでない場所
この市場で根強い誤解のひとつは、「AIウェブスクレイパー」とは、AIが最初から最後まで全部やってくれるという意味だというものです。コミュニティの認識は驚くほど明確で、です。あるユーザーは率直にこう言いました。「AIはWebページのスクリーンショットを読むために使うのであって、スクレイパー自体のコードを書くために使うわけではない。」
スクレイピングのパイプラインには3つの層があり、それぞれでAIの価値は大きく異なります。
クロールと取得: 基盤レイヤー
ここでは実際にリクエストを送ります。プロキシ、ヘッドレスブラウザ、セッション管理、CAPTCHA解決、再試行などです。AIがここで役立つことはほとんどありません。必要なのは、依然としてプロキシプール、ブラウザの指紋対策、解除用のインフラです。多くのツールが本番で最初に失敗するのはここです。
解析と抽出: AIが最も活躍する場所
ページ内容をきれいに取得できれば、AIは非構造化HTMLを構造化されたフィールドに変換するのが得意です。スキーマベースの抽出、適応的なフィールド検出、レイアウト差分への対応は、壊れやすいXPathセレクタに頼らないという意味で、スクレイピングにおけるAIの得意分野です。
後処理: ラベル付け、翻訳、分類
抽出後にAIは、商品の分類、テキスト翻訳、電話番号の正規化、説明文の要約などで価値を発揮します。相性は良いですが、前提として抽出結果が正しいことが必要です。
12製品がこの3層にどう当てはまるかは次の通りです。
| ツール | クロール/取得 | 解析/抽出 | 後処理 | 最適な説明 |
|---|---|---|---|---|
| Thunderbit | 強い | 強い | 強い | フルスタックのノーコードAIスクレイパー |
| Octoparse | 強い | 中程度 | 弱い | ルールベースのビジュアルスクレイパーとクラウド基盤 |
| Browse AI | 中程度 | 中程度 | 中程度 | 監視重視のクラウドロボットプラットフォーム |
| Firecrawl | 中程度 | 強い | 弱い〜中程度 | 開発者向け抽出API |
| Apify | 強い | 中程度〜強い | 中程度 | アクターマーケットプレイスとオーケストレーション |
| Gumloop | 中程度 | 中程度 | 強い | スクレイパーノード付きワークフロー自動化 |
| Bright Data | 非常に強い | 中程度 | 弱い〜中程度 | エンタープライズ向けインフラスタック |
| Bardeen | 中程度 | 中程度 | 強い | GTMワークフロー向けブラウザ自動化 |
| Diffbot | 弱い〜中程度 | 非常に強い | 中程度 | 事前学習済み抽出とナレッジグラフ |
| ScrapingBee | 強い | 弱い〜中程度 | 弱い | 取得と解除に特化したAPI |
| Instant Data Scraper | 弱い | 中程度(シンプルなページ) | 弱い | ブラウザ内で動くヒューリスティックなクイックスクレイパー |
| ParseHub | 中程度 | 中程度 | 弱い | 複雑な操作向けのデスクトップ型ビジュアルスクレイパー |
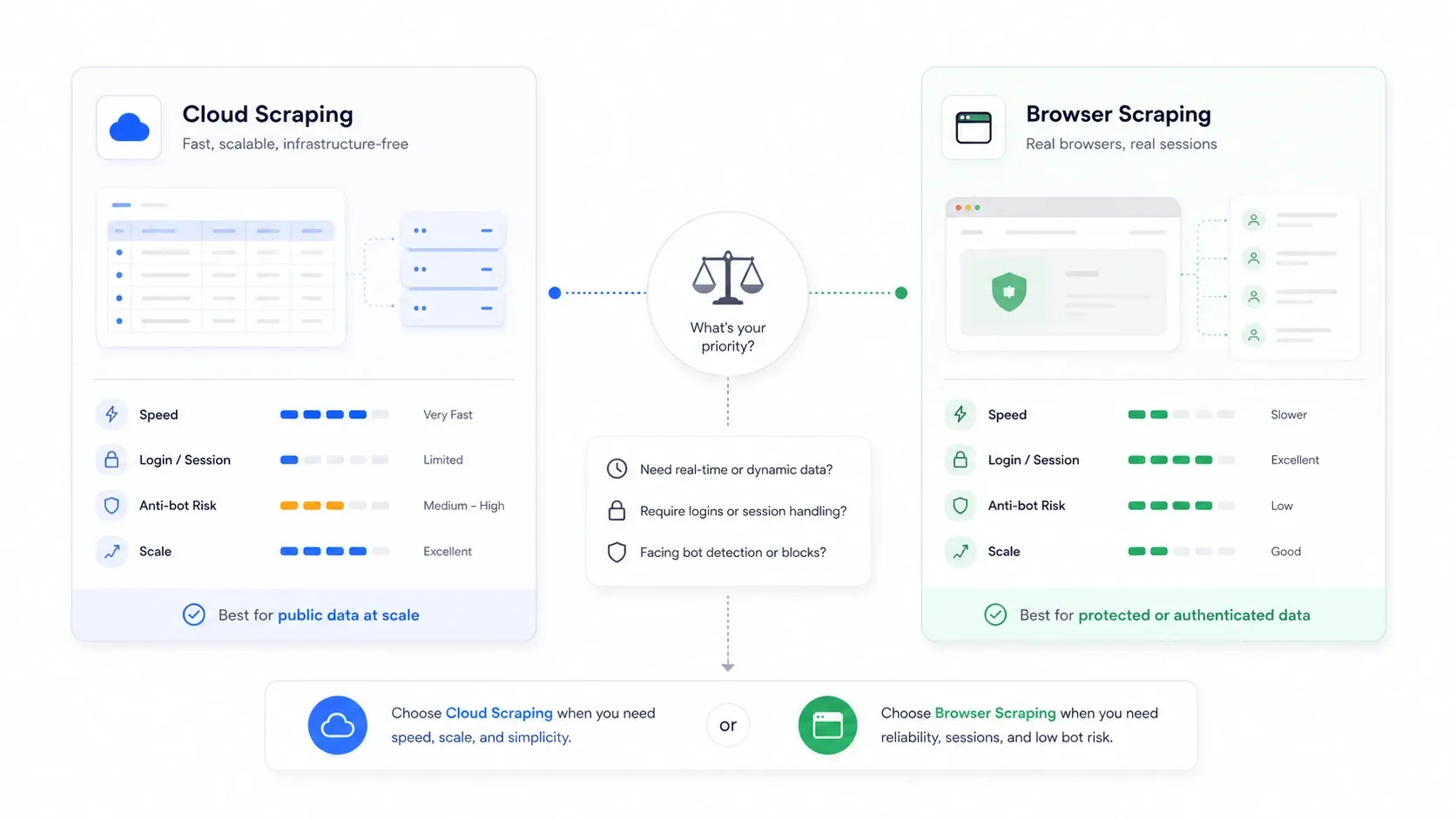
クラウドスクレイピングとブラウザスクレイピング: 誰も説明しない選択
これは多くの比較記事が完全に見落としているアーキテクチャ上の判断であり、どのツールを選ぶか以上に重要なことがよくあります。
クラウドスクレイピングとは、リモートサーバーがあなたの代わりにページを取得する方式です。ブラウザスクレイピングとは、自分のブラウザセッション、つまり自分のCookie、自分のIP、自分の認証状態を使って抽出する方式です。
| シナリオ | より適したモード | 理由 |
|---|---|---|
| 公開ECサイトや一覧サイトを大量に処理する | クラウド | 並列処理が速く、ローカルPCの制約がない |
| ログインや認証が必要なサイト | ブラウザ | 実際のセッションCookieを再利用できる |
| データセンターIPを弾くサイト | ブラウザ | 通常のユーザー通信のように見える |
| 大規模な継続監視ジョブ | クラウド | スケジューリングと継続性が容易 |
| 単発で、壊れやすく、対ボット対策に敏感なジョブ | ブラウザ | サイトが実際に何を描画したか確認しやすい |
これは経済面でも重要です。Apifyの2026年版「Web Scrapingの現状」レポートによると、、がインフラ支出の増加を報告しています。対ボット対策は、技術的な問題であるだけでなく、予算の問題でもあります。
多くのツールは1つのモードしか提供していません。内訳は次の通りです。
| ツール | クラウド | ブラウザ | 両方 |
|---|---|---|---|
| Thunderbit | ✅ | ✅ | ✅ |
| Octoparse | ✅ | ✅(ローカル) | ✅ |
| Browse AI | ✅ | 設定のみ | — |
| Firecrawl | ✅ | 対話用API | — |
| Apify | ✅ | ✅(アクター経由) | ✅ |
| Gumloop | ✅ | ✅(Web Agent) | ✅ |
| Bright Data | ✅ | ✅ | ✅ |
| Bardeen | 限定的(公開ページ) | ✅ | 部分的 |
| Diffbot | ✅ | — | — |
| ScrapingBee | ✅ | — | — |
| Instant Data Scraper | — | ✅ | — |
| ParseHub | ✅(有料) | ✅(デスクトップ) | ✅ |
12のAIウェブスクレイパーを一覧で比較
12製品をまとめて比較すると次の通りです。
| ツール | 最適用途 | 無料枠 | クラウド/ブラウザ | APIアクセス | 定期スクレイピング | 対ボット対応 |
|---|---|---|---|---|---|---|
| Thunderbit | 非技術系チーム | ✅(6ページ) | 両方 | ✅ | ✅ | 強い |
| Octoparse | テンプレート中心のスクレイピング | ✅(制限あり) | 両方 | ✅ | ✅ | 中〜強 |
| Browse AI | 変更監視 | ✅(制限あり) | 主にクラウド | ✅ | ✅ | 中程度 |
| Firecrawl | 開発者向け抽出パイプライン | ✅(月1,000クレジット) | クラウド+ブラウザAPI | ✅ | なし | 中程度 |
| Apify | 開発チーム+マーケットプレイス | ✅(5ドル分の無料利用) | 両方 | ✅ | ✅ | アドオン込みで強い |
| Gumloop | ワークフロー自動化 | ✅(月5,000クレジット) | 両方 | ✅ | ✅ | 中程度 |
| Bright Data | エンタープライズ向けデータアクセス | 試用版 / クレジット | 両方 | ✅ | 外部 | 非常に強い |
| Bardeen | 営業・オペレーション向けブラウザ自動化 | ✅(100クレジット) | ブラウザ中心 | 制限あり | ✅ | 中〜弱 |
| Diffbot | 構造化抽出API | ✅(10,000クレジット) | クラウド | ✅ | なし | 取得は弱い / 抽出は強い |
| ScrapingBee | 開発者向け取得と解除 | ✅(1,000クレジット) | クラウド | ✅ | なし | 強い |
| Instant Data Scraper | 無料の単発スクレイプ | ✅(完全無料) | ブラウザのみ | なし | なし | 弱い |
| ParseHub | 複雑なビジュアルワークフロー | ✅(5プロジェクト) | デスクトップ+クラウド | ✅ | ✅(有料) | 中程度 |
1. Thunderbit
は、コードを書いたりインフラを管理したりせずに、本番品質のデータを必要とする非技術系チームのために作ったAIウェブスクレイパーです。基本の操作は本当に2クリックです。AI Suggest Fieldsでページを読み取り、列を提案し、Scrapeでクラウドまたはブラウザモードの抽出を実行します。
他のノーコードスクレイパーと違うのはアーキテクチャです。Thunderbitは、クラウド基盤、プロキシローテーション、対ボット対策、JavaScriptレンダリングといったクロール面の処理と、HTMLを読み取って構造化された列を出力するAI抽出を分離しています。これは専門家が勧める「スクレイパーが先、LLMは後」という流れに合っていますが、Chrome拡張として営業担当やオペレーション担当が実際に使える形にまとめています。
主な強み
- 1つの画面でクラウドスクレイピングとブラウザスクレイピングの両方に対応。 対象サイトが公開ページか、認証済みセッションが必要かに応じて切り替えられます。クラウドモードは最大50ページを並列処理できます。
- AIが毎回ページ構造を読み直す。 XPathの保守は不要です。サイトのレイアウトが変わっても、Thunderbitは次回実行時に自動で適応します。
- サブページスクレイピング。 AIがリンク先の詳細ページを巡回し、手動設定なしでメインのデータ表を拡張します。
- フィールド用AIプロンプト。 抽出と同時に、カスタム分類、翻訳、カテゴリ分けを実行できます。後処理を別工程にしません。
- Google Sheets、Excel、Airtable、Notionへの無料エクスポート。
- Amazon、Zillow、LinkedInなどの人気サイト向け即席スクレイパーテンプレート。
- 自然言語によるスケジュール設定。 「毎週月曜の9時にスクレイプ」と伝えるだけで、定期スケジュールに変換します。
- オープンAPI にはDistillとExtractのエンドポイントがあり、最大100URLのバッチ処理、同時実行数は無料プランの2からPro 1の50まで公開されています。
改善の余地
- 無料枠は意図的に小さめです。
- ノーコード体験はChrome拡張中心です。API専用のワークフローを望む開発者は、Open APIを別途使う必要があります。
- 必要なのが抽出ではなく、純粋なプロキシ基盤だけなら適したツールではありません。
価格
無料枠あり。ノーコードプランは、Starterが年払いで月9ドルまたは月払いで月15ドルからです。API料金は別で、1回限りの無料枠として600ユニット、その後はStarter APIが年払いで月16ドル、Pro 1 APIが年払いで月40ドルです。詳しくはとをご覧ください。
最適用途: エンジニアの支援なしで、構造化Webデータを必要とする営業、EC、オペレーションチーム。
2. Octoparse
は、豊富なテンプレートライブラリを備えたWebスクレイピング用のビジュアルワークフロービルダーです。十分に長く提供されているためクラウド基盤も成熟しており、構造化された予測可能なWebサイトでのページネーション処理が得意です。
主な強み
- 人気サイト向けの豊富な既成テンプレート
- スケジュール実行付きのクラウド抽出
- IPローテーションとCAPTCHA解決の有料アドオン
- 上位プランでAPIアクセス
改善の余地
- AI機能はLLMネイティブなツールより軽めです。フィールド提案は、適応的な読み取りよりもテンプレート依存です。
- 複雑または特殊なレイアウトでは、ビジュアルエディタでかなり手作業の調整が必要です。
- 条件分岐ロジックやブロック回避の工夫が必要になると、学習コストが一段上がります。
価格
無料の永久プランあり。公式ヘルプセンターの料金案内では、現在Standardが年払いで月75ドルから、Professionalが年払いで月208ドルからとなっていますが、ローカライズされたページやアップグレード経路では、より高い月額換算が表示されることもあります。重要なのは、Octoparseの料金体系が、住宅用プロキシやCAPTCHA解決などの有料アドオンとサブスクリプション階層を組み合わせたものになっている点です。
最適用途: 構造化されテンプレートに合いやすいサイトを、中規模でスクレイピングする分析担当やオペレーションチーム。
3. Browse AI
は、競合価格、在庫状況、コンテンツ更新など、Webサイトの変化を継続的に監視することを主目的にしたクラウド型ノーコードプラットフォームです。スクレイピングは製品の一部ですが、本当の差別化要素は、継続監視と通知システムです。
主な強み
- 変更検知とアラートが標準搭載
- ポイント&クリックで設定できるノーコードロボット記録機能
- 人気サイト向けの既成ロボット
- 上位プランでプレミアムプロキシ対応
改善の余地
- クレジット制料金は、詳細ページを大規模に監視するとすぐ高くなる
- 単発の大量抽出では、APIファーストのツールより魅力が薄い
- 対ボット対応は中程度で、サイトによってはプレミアムプロキシや回避策が必要
価格
無料アカウントあり。有料プランは、Starterが年払いで月19ドル前後からで、上位にクレジット量や監視機能の多いプランがあります。
最適用途: 1回限りの一括抽出ではなく、競合価格、コンテンツ変更、在庫レベルの継続監視が必要なチーム。
4. Firecrawl
は、WebページをきれいなMarkdownまたは構造化JSONに変換する、開発者向けのAPIです。主に抽出レイヤーに位置し、RAGパイプラインを構築するチームや、WebコンテンツをLLMに流し込む用途に非常に向いています。
主な強み
- 下流のLLMワークフロー向けに、Markdown出力の品質が非常に高い
- scrape、crawl、map、search、extract、browser actions を備えたきれいなAPI
- バッチ処理対応
- 無料の2同時実行からGrowthの100同時実行まで対応
改善の余地
- ノーコード画面はなく、開発スキルが必要
- プロキシや対ボット支援はあるが、専用の解除ベンダーのような位置づけではない
- 定期ジョブ向けのファーストパーティのスケジューラがない
- データをスプレッドシートで欲しいだけの非開発者には、費用対効果が低い
価格
無料プランには月1,000クレジットが含まれます。有料プランは、Hobbyが年払いで月16ドルからで、クレジット、同時実行数、ブラウザ利用量が増えるにつれて上がります。ブラウザセッションはクレジットで別課金です。
最適用途: きれいなMarkdownやJSONをWebページから必要とする、LLMパイプライン、RAGシステム、カスタム抽出ワークフローを構築する開発者。
5. Apify
は、既成のスクレイピングアクターのマーケットプレイスと、カスタムアクターを作るためのツールを備えたプラットフォームです。特定サイト向けの専用スクレイパーを選ぶ、または自作し、それを単一のAPIからスケジュール実行・管理するためのオーケストレーション層だと考えると分かりやすいです。
主な強み
- 何百ものサイト向けにコミュニティが作ったスクレイパーが集まる巨大なアクターマーケットプレイス
- 開発者向けの強力なAPIとSDK
- プロキシ管理とスケジューリングが標準搭載
- 多くの下流ツールと連携可能
改善の余地
- マーケットプレイスを離れて独自ロジックが必要になると、「ノーコード」は一部だけ本当になります
- アクターの信頼性はコミュニティ保守に左右されます
- 計算資源、アクター費用、プロキシ費用が積み上がるため、価格が上がりやすいです
価格
無料枠には月5ドル分のプラットフォームクレジットが含まれます。有料プランはStarterが月39ドルからで、さらに上位のスケール向けプランがあります。
最適用途: 既製ソリューションを大量に使い回しながら、再利用可能でスケジュール実行できるスクレイピングワークフローを求める開発チーム。
6. Gumloop
は、Webスクレイピング用ノードを含むノーコードのワークフロー自動化プラットフォームです。真の価値はスクレイピング単体ではありません。抽出をLLM、Google Sheets、CRM、その他のツールと1つのビジュアルキャンバス上でつなげられる点にあります。
主な強み
- ドラッグ&ドロップ型のビジュアルワークフロービルダー
- スクレイピングとLLM、下流の業務ツールを1つのフローで統合
- 現在の無料プランは月5,000クレジットを掲示
- 定期ワークフロー向けの時間ベースのスケジューリング
- 基本のスクレイピングと対話型Web Agentモードで、シンプルな流れから豊富な流れまで対応
改善の余地
- スクレイピングエンジンは、専用のAIウェブスクレイパーツールほど堅牢ではない
- 専門ベンダーと比べると、対ボット対応とプロキシの深さが限られる
- 無料プランは同時実行数とトリガー制限が厳しめ
- 大量のスクレイピングを主目的にするには向いていない
価格
無料プランあり。Gumloopは2025年後半に旧Solo/Team構成をProプランへ統合し、それ以降はスクレイパー重視の料金体系というより、より厚い無料クレジットと統合された有料階層を前面に出しています。
最適用途: スクレイピングを、収集・分析・業務ツールへの投入まで含む広い自動化ワークフローの一部として使いたいチーム。
AIネイティブな抽出ワークフローが実際にどんな感覚かを、続きを読む前に確認したいなら、このThunderbitの解説動画が非技術系チームにとって最も近い製品デモです。
7. Bright Data
は、この一覧の中でもエンタープライズ級のインフラスタックです。もし問題が「何をしてもこのサイトのボット対策を突破できない」なら、Bright Dataが答えになる可能性が高いですが、そのぶんエンタープライズ向けの複雑さと価格が伴います。
主な強み
- 住宅用、データセンター用、モバイルIPをまたぐ業界トップ級のプロキシネットワーク
- 対ボットとCAPTCHA回避のためのWeb Unlocker
- 内蔵のブロック解除機能を備えたScraping Browser
- 事前収集済みデータセットを購入可能
- APIとSDKによる完全なプログラム制御
改善の余地
- 非技術者向けではない
- 価格はエンタープライズ向けポジションを反映している
- AI抽出は、このプラットフォームを買う主目的ではない
価格
Browser APIは従量課金で1GBあたり8ドルからで、月間契約量が大きいほどGBあたりの単価は下がります。Unlocker、Scraper API、データセット、プロキシプールなど、他のBright Data製品はそれぞれ異なる課金単位です。
最適用途: 強固に防御されたサイトを大規模にスクレイピングする必要があり、そのためのインフラを管理できる技術チームを持つエンタープライズのデータチーム。
8. Bardeen
は、クリック、フォーム入力、スクレイピングを中心にしたブラウザ自動化ツールで、その上にAIによるデータ抽出が載っています。本質的には、たまたまスクレイピングもできるGTMワークフローツールと捉えるのが正確で、逆ではありません。
主な強み
- 直感的なプレイブック型自動化で、スクレイピングはその一工程
- 人気サイト向けにBardeenチームが保守する公式スクレイパー
- CRM、Google Sheets、Slack、その他の業務ツールとの連携が強力
- リード抽出、リッチ化、CRM書き出しのワークフローに向く
改善の余地
- ブラウザ中心の設計のため、大量の無人スクレイピングには限界がある
- クラウドスクレイピングは公開ページのみで、認証が必要なページには使えない
- 対ボット対応は、基本的にブラウザセッションがすでに持っている能力に依存する
- AI抽出は、複雑または標準から外れたレイアウトで苦戦することがある
価格
無料プランには月100クレジットが含まれます。公開サポート文書では、既存ユーザー向けの旧Pro月15ドルの価格が参照されていますが、現在のBardeenの商用パッケージは、昔ながらの低価格スクレイパーというより、エンタープライズ寄りでワークフロー中心です。
最適用途: より広いブラウザ自動化ワークフローの一部としてスクレイピングを使いたい営業・オペレーションチーム。
9. Diffbot
は、コンピュータービジョンとNLPを使ってWebページを人間のように読み、記事、商品、議論、組織の構造化データを出力します。ページが事前学習済みモデルに合うなら、利用できる抽出APIの中でも最高品質のひとつです。
主な強み
- 記事、商品、議論などに対応する事前学習済み抽出モデル
- 数十億のエンティティを持つKnowledge Graphによるデータ拡張
- 対応ページ種別での高品質な構造化出力
- 公開レート制限付きの明快な開発者API
改善の余地
- ノーコード画面はない
- クロール、プロキシ管理、対ボット対応が内蔵されていない
- 小規模チームには高価
- スキーマプロンプト型の抽出ツールより、標準外ページへの柔軟性が低い
価格
無料プランには10,000クレジットが含まれます。Startupは250,000クレジットで月299ドル、Plusは1,000,000クレジットで月899ドルです。
最適用途: 標準的なページ種別から高精度な構造化抽出を必要とし、取得部分は別で扱える開発チーム。
10. ScrapingBee
は、取得と解除のレイヤーに特化したWebスクレイピングAPIです。URLを送ると、プロキシ、ヘッドレスブラウザのレンダリング、対ボット防御を処理し、HTML、またはオプションで抽出済みデータを返します。
主な強み
- 内蔵のプロキシローテーションと対ボット対応
- JavaScriptレンダリング対応
- シンプルなREST API
- Google検索スクレイピング用エンドポイント
- プランごとの公開同時実行数
改善の余地
- AI抽出機能は限定的
- ノーコード画面がない
- スケジューリングや監視は標準搭載されていない
- ブロックページを返す
200レスポンスでも、成功したリクエスト扱いになることがある
価格
無料プランには1,000 APIクレジットが含まれます。有料プランは月49ドルからで、同時実行数とリクエスト量が上がるにつれて拡張されます。
最適用途: 主に対ボット防御を越えた安定したページ取得が必要で、抽出は自分のコードか別ツールで行う開発者。
11. Instant Data Scraper
は、100万人以上のユーザーを持つ無料のChrome拡張です。ページ上のデータパターンを自動検出し、CSVまたはExcelに書き出せます。LLMの意味でのAIフィールド提案はありません。ヒューリスティックなパターン検出を使っています。
主な強み
- 完全無料で、アカウント登録も不要
- 多くの一覧ページや表ページでワンクリック検出
- 一部のサイトでページネーションに対応
- 導入のハードルが極めて低い
- 2026年もChrome Web Storeで更新が続いている
改善の余地
- AIによるフィールド提案やデータラベリングはない
- クラウドスクレイピング、スケジューリング、APIがない
- 複雑なレイアウト、動的コンテンツ、JSが多いサイトは苦手
- ブラウザが既に読み込める範囲を超える対ボット対応はない
- 書き出しはCSVとExcelに限定される
価格
無料。ずっとです。
最適用途: アカウント登録も支払いもせず、シンプルな一覧ページをすぐに一度だけスクレイプしたい人。
12. ParseHub
は、スクレイピングプロジェクトを作るための、ビジュアルでポイント&クリック式のデスクトップアプリです。複雑な入れ子データ、AJAX読み込みコンテンツ、無限スクロール、ドロップダウン操作など、シンプルな拡張機能が見落としがちな処理にも対応できます。
主な強み
- 抽出ルールを定義するためのビジュアルセレクタUI
- 入れ子データ、ドロップダウン、無限スクロール、AJAXコンテンツに対応
- 最大5プロジェクトまで使える無料枠
- JSON、CSV、Excelへのエクスポート
- 有料プランでクラウドスケジューリングとIPローテーション
改善の余地
- デスクトップ専用のワークフローで、ブラウザ拡張の手軽さがない
- クラウドネイティブなツールより実行速度が遅い
- AIによる再読込レイヤーがないため、サイトのレイアウト変更でプロジェクトが壊れる
- AI機能が限定的で、昔ながらのビジュアルスクレイパー感が強い
価格
無料プランあり。5プロジェクトと1回あたり200ページまで使えます。有料プランは月189ドルからで、スケジューリング、IPローテーション、より高い上限が含まれます。
最適用途: 複雑でインタラクティブなサイトをスクレイプしたい非技術系ユーザーで、ビジュアルなワークフロー構築に時間をかけられる人。
5ステップでAIウェブスクレイパーを始める方法
この一覧にある各ツールは、オンボーディングの流れが少しずつ違います。ここではThunderbitを具体例として使います。なぜなら、「実際のページでちゃんと動くものがほしい」という検索意図に最も近いからです。
ステップ1: インストールしてページに移動する
をインストールし、スクレイプしたいページ、たとえば商品一覧、ディレクトリ、不動産ポータルに移動します。
ステップ2: AIにデータフィールドを提案させる
AI Suggest Fieldsをクリックします。AIが現在のページを読み取り、列名とデータ型を提案します。商品ページなら、商品名、価格、評価、画像URL、説明文などが候補になります。
ステップ3: AIプロンプトでフィールドをカスタマイズする
デフォルトが少し違うと感じたら列を調整します。たとえば、「説明文をスペイン語に翻訳」「Electronics、Home、Fashionに分類」「数値の価格だけを抽出」などの変換を、Field AI Promptsで追加できます。
ステップ4: クラウドかブラウザかを選んでスクレイプする
公開サイトならクラウドスクレイピング、認証済みサイトや防御の強いサイトならブラウザスクレイピングを選びます。その後Scrapeをクリックします。
ステップ5: どこへでもデータを書き出す
結果はGoogle Sheets、Excel、Airtable、Notionへエクスポートできます。エクスポートは無料です。
サイトのレイアウトが変わったら?
これこそが、AIネイティブ抽出ツールの本番運用上の大きな利点です。ParseHubや古いOctoparseのワークフローのような従来型スクレイパーは、XPathセレクタやCSSパスに依存します。サイトがHTML構造を更新すると、そのセレクタは壊れ、手動での再設定が必要になります。
ThunderbitのようなAI搭載抽出ツールは、そのたびにページ構造を読み直します。つまり、XPathの保守も壊れやすいセレクタも不要です。AIが次回実行時に自動でレイアウト変更に適応します。
定期スクレイピングとAPIアクセス: 誰もレビューしない上級者向け機能
単発のスクレイプは調査には十分です。しかし、価格監視、リードリストの更新、在庫追跡のような本番用途では、定期抽出とプログラムからのアクセスが必要になります。これらの機能が、おもちゃと実用ツールを分けます。
スケジューリング対応
| ツール | 標準スケジューリング | 備考 |
|---|---|---|
| Thunderbit | ✅ | 自然言語で設定可能 |
| Octoparse | ✅ | クラウドの定期実行 |
| Browse AI | ✅ | コア機能 |
| Firecrawl | ❌ | 外部cronを利用 |
| Apify | ✅ | 完全なcron式に対応 |
| Gumloop | ✅ | 時間ベースのワークフロートリガー |
| Bright Data | 外部 | 通常は顧客側システムでオーケストレーション |
| Bardeen | ✅ | プレイブックのスケジューリング |
| Diffbot | ❌ | APIファーストで外部オーケストレーションが必要 |
| ScrapingBee | ❌ | APIのみ |
| Instant Data Scraper | ❌ | 手動のブラウザツール |
| ParseHub | ✅(有料) | プレミアム機能 |
開発者向けAPI比較
This paragraph contains content that cannot be parsed and has been skipped.
もしあなたの用途がより技術寄りで、どれだけのインフラを自分で持ちたいかを判断したいなら、このFirecrawlの解説は、上の製品比較を実行面で補完するのに役立ちます。
自分に合ったAIウェブスクレイパーの選び方
12製品すべてを試したうえで、私ならこう判断します。
- すぐにデータが必要な非技術系チーム: まずはThunderbitです。2クリックのワークフロー、無料エクスポート、ブラウザとクラウドの切り替えで、ほとんどの業務スクレイピング要件をエンジニアなしで満たせます。
- 継続的な監視とアラートが必要: Browse AIがこの用途に特化しています。単発抽出の最強ではありませんが、変更検知は一級の機能です。
- LLMパイプラインを作る開発者: MarkdownまたはJSON抽出ならFirecrawl、事前学習済みの構造化抽出ならDiffbotです。取得レイヤーで本格的な対ボット対応が必要なら、どちらにもScrapingBeeかBright Dataを組み合わせるとよいでしょう。
- 既成スクレイパーのマーケットプレイスが欲しい: Apifyが最大のアクターエコシステムを持っています。ただし、アクターが壊れたときの保守には備えてください。
- エンタープライズ規模で、強く防御された対象を扱う: Bright Dataです。プロキシ基盤ではこれに並ぶものはありませんが、予算と技術要員もそれに合わせる必要があります。
- より大きな自動化の一部としてスクレイピングしたい: ワークフローを自動化するならGumloop、ブラウザベースのGTMタスクを自動化するならBardeenです。
- とにかく無料で手早くスクレイプしたい: Instant Data Scraperです。設定ゼロ、コストゼロ、複雑さゼロ。ただし、スケジューリングもAIもクラウドもゼロです。
- ドロップダウンやAJAXがある複雑な対話型サイト: ParseHubは今でも多くの拡張機能よりうまく処理しますが、保守負担は現実にあります。
結論
2026年のAIウェブスクレイパー市場は、デモでは見栄えがよくても本番でがっかりするツールであふれています。「マーケティング用スクリーンショットでは動く」のと、「深夜3時に防御の強いECサイトでスケジュール実行しても動く」の差こそが、多くの購入者が時間とお金を無駄にするポイントです。
12製品を評価して見えてきた重要な洞察はシンプルです。依然として難しいのは取得レイヤーです。 AIは抽出と後処理が得意ですが、プロキシ基盤、対ボット対応、セッション管理の代わりにはなりません。最も優れたツールは、ThunderbitやBright Dataのように両方のレイヤーを解決するか、Firecrawlのように抽出レイヤー、ScrapingBeeのように取得レイヤー、と役割を正直に示しています。
コードを書かずに本番対応のAIウェブスクレイパーがどう見えるか知りたいなら、。無料枠だけでも、実際のページで一連の流れを試すには十分です。もしあなたのニーズがより開発者向けなら、抽出APIと専用の取得サービスを組み合わせて、1つのツールに何でも期待してしまうストレスから自分を解放してください。
よくある質問
なぜ多くのAIウェブスクレイパーは、デモでは問題なく動くのに実サイトで失敗するのですか?
デモは通常、保護されていないきれいなページでの抽出を見せます。実際のサイトには、Cloudflare対策、動的なJavaScriptレンダリング、ページネーション、ログイン要件、頻繁に変わるレイアウトがあります。多くのツールは解析・抽出レイヤーには強い一方で、取得レイヤーのための堅牢なインフラが足りません。
クラウドスクレイピングとブラウザスクレイピングの違いは何ですか? それぞれいつ使うべきですか?
クラウドスクレイピングはリモートサーバーでページを取得する方式で、速く、並列化しやすく、拡張性があります。ブラウザスクレイピングは自分のブラウザセッションで動き、認証が必要なサイトや強いボット検出があるサイトに向いています。Thunderbitは、同じ画面で両方のモードを提供する数少ないツールのひとつです。
価格監視のような定期タスクにAIウェブスクレイパーを使えますか?
はい。ただし、そのツールが定期スクレイピングに対応している場合に限ります。Thunderbit、Octoparse、Browse AI、Apify、Gumloop、Bardeen、そして有料プランのParseHubは、いずれもスケジューリングを提供しています。
コーディングができない場合、どのAIウェブスクレイパーが最適ですか?
Thunderbitは、非技術者が使えるデータを最短で得るのに向いています。Instant Data Scraperは完全無料ですが、シンプルなページに限られます。Browse AIとOctoparseは、より設定が必要なビジュアルUIを備えています。ParseHubは複雑な対話型サイトに強いですが、学習コストは高めです。
本番品質のAIウェブスクレイピングには、実際いくらかかりますか?
幅はかなり広いです。Instant Data Scraperは無料です。Thunderbit、Firecrawl、Browse AIには、低価格の有料プランを伴う無料の入り口があります。Octoparse、ParseHub、ScrapingBeeのような中価格帯ツールは、月49〜189ドル前後から利用できます。Bright DataやDiffbotのようなエンタープライズ向けは、はるかに高額です。