高品質なラベル付きデータへの機械学習の需要は、これまでになく高まっています。新しいAIモデルを構築しているチームと話すたびに、営業予測、商品レコメンド、顧客感情分析のどれでも、必ず同じ課題が出てきます。データに手作業でラベルを付けるのは遅く、高コストで、正直かなり消耗します。十分なラベル付きサンプルが集まるまで何週間、時には何か月もプロジェクトが止まってしまうのを、私は何度も見てきました。しかもラベルに一貫性がないとしたら? まあ、私の縦列駐車の試みと同じくらい、予測の信頼性もあやしい、とでも言っておきましょう。
でも、良いニュースがあります。機械学習を使ったデータラベリングの自動化が、状況を大きく変えつつあります。AIに重い作業を任せることで、企業はラベリングのスピードを上げるだけでなく、精度と一貫性も高められます。これは、機械学習プロジェクトの成否を左右する重要な要素です。このガイドでは、自動データラベリングの仕組み、堅牢なモデル構築にそれがなぜ重要なのか、そして のようなツールを使って、自分専用の自動ラベリングワークフローをどう組み立てるかを、コーディング不要で解説します。
機械学習を使った自動データラベリングとは?
まずは整理しましょう。機械学習を使った自動データラベリングとは、アルゴリズムやAIツールを使って、元データにラベル(「スパム」「スパムではない」、「猫」「犬」、「ポジティブ」「ネガティブ」など)を付けることです。人が一件ずつクリックしてラベル付けする必要はありません。何千枚もの旅行写真に手作業でタグを付けるのと、顔認識を使って人物、場所、さらには気分ごとに自動で仕分けするのとの違いだと考えると分かりやすいでしょう。
従来の手動ラベリングは、文字どおりその名の通りです。人がデータを一件ずつ確認し、正しいラベルを付けていきます。正確なこともありますが、遅く、高価で、拡張もしにくい方法です。一方、自動ラベリングは、少量の手動ラベル付きデータで学習した機械学習モデルを使い、データセットの残りに対するラベルを予測します。結果として、より速く、より一貫性があり、より拡張しやすいラベリングが実現します()。
ビジネスユーザーにとっては、より良いモデルを、より早く、しかも手作業の負担を減らして構築できるということです。データ主導の今の時代では、これは大きな競争優位になります。
自動データラベリングが高品質な機械学習モデルの鍵となる理由
重要なのは、ラベル付きデータの品質が機械学習モデルの性能に直接影響するという点です。よく言われるように、「ゴミを入れれば、ゴミしか出てこない」です。ラベルに一貫性がなかったり誤っていたりすると、モデルは間違ったパターンを学習し、予測精度も落ちてしまいます()。
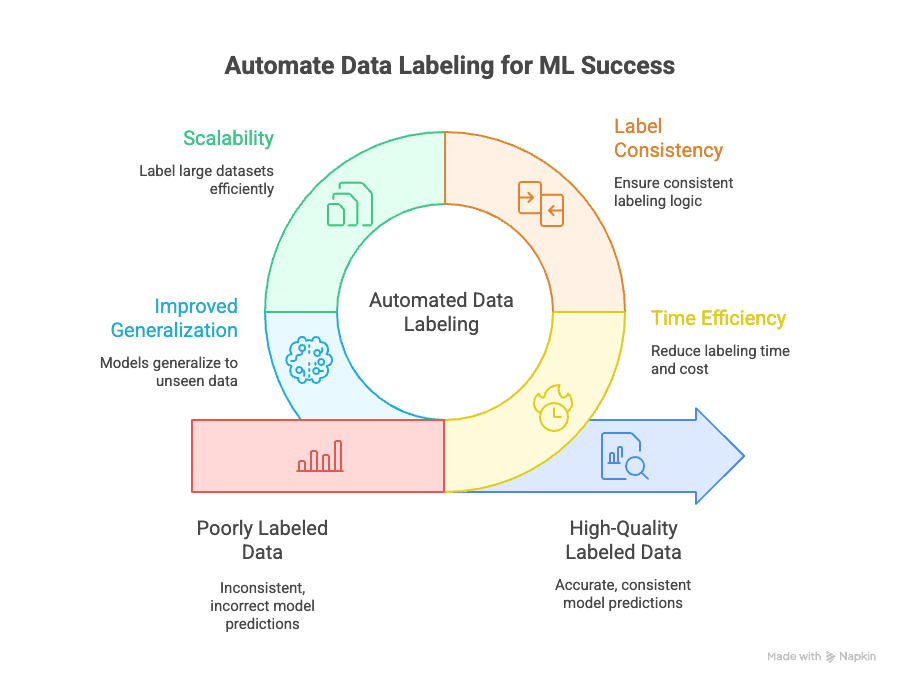
自動データラベリングは、次のような主要課題を解決します。
- 時間効率: 手動ラベリングは、MLプロジェクト全体の時間とコストのを食ってしまうことがあります。自動化すればその負担を大幅に削減でき、モデルの反復やデプロイをより速く進められます。
- ラベルの一貫性: 機械は疲れもしなければ気も散りません。自動ラベリングなら、すべてのデータポイントに同じロジックでラベルを付けられるため、人為的ミスやバイアスを減らせます()。
- 拡張性: 1万件、10万件、あるいは100万件のデータにラベルを付ける必要がありますか? 自動化なら、それが可能です。大量のアノテーターを雇う必要もありません()。
- 汎化性能の向上: 一貫性があり高品質なラベルは、モデルが未知の新しいデータにもよりよく汎化する助けになります。これこそが機械学習の最終目標です()。
ビジネスへの影響も明確です。ラベル品質が低いとモデル精度は最大で低下する一方、高品質な自動ラベリングはモデル開発と展開のスピードを高めます。
手動ラベリングと自動ラベリングの比較
並べて見てみましょう。
| 要素 | 手動ラベリング | MLを使った自動ラベリング |
|---|---|---|
| 速度 | 遅い(大規模データでは数週間〜数か月) | 速い(大規模データでも数分〜数時間) |
| 精度 | 高いが、人為的ミスや不一致が起こりやすい | 高い。ロジックが一貫しており、エラーも少ない |
| 拡張性 | 人的リソースに制約される | 数百万件のデータにも容易に対応可能 |
| コスト | 高い(労働集約的) | 長期的なコストは低い(Keylabs) |
| 最適な用途 | 小規模、複雑、または曖昧なデータセット | 大規模、反復的、または明確に定義されたデータセット |
手動ラベリングにも出番はあります。特に例外ケースや曖昧なデータでは有効です。ただし、ほとんどのビジネス用途では、自動化のほうが適しています。
機械学習を使った自動データラベリングの基本ステップ
では、自動データラベリングは実際にはどう進むのでしょうか? 私がおすすめする、そして実際に使っているエンドツーエンドのワークフローは次の4ステップです。
- データ収集と前処理
- 特徴量の抽出と準備
- 機械学習による自動ラベリング
- 品質保証と人によるレビュー
それぞれ見ていきましょう。
ステップ1: データ収集と前処理
何かにラベルを付ける前に、まずはデータを集めて整える必要があります。たとえば、Webサイトから商品一覧をスクレイピングしたり、顧客レビューをエクスポートしたり、社内データベースから画像を集めたりします。ここで大事なのは品質です。質の悪いデータは質の悪いラベルを生み、ひいては質の悪いモデルにつながります()。
ベストプラクティス:
- 重複や不要なレコードを削除する
- 形式を標準化する(日付、通貨など)
- 欠損値や不完全なデータを処理する
ステップ2: 特徴量の抽出と準備
次に、ラベリングタスクに重要な特徴量を特定します。たとえば商品一覧にラベルを付けるなら、価格、ブランド、カテゴリ、説明文などを抽出します。営業やマーケティングでは、メールから会社名、連絡先情報、感情などを取り出すことになるでしょう。
ビジネス例: を使えば、商品仕様、レビュー、連絡先などの構造化データを、1行のコードも書かずにWebページから抽出できます。
ステップ3: 機械学習による自動ラベリング
ここが“魔法”の部分です。少量の手動ラベル付きデータで学習した機械学習モデルを使って、残りのデータにラベルを予測します。代表的な手法には次のようなものがあります。
- 教師ありモデル: ラベル付きサンプルで分類器を学習させ、新しいデータに適用する
- ルールベースのラベリング: 単純なケースでは、あらかじめ定義したルール(例: 「価格が1000ドル超なら『高級』とする」)を使う
- アクティブラーニング: モデルが不確かなケースについて人の入力を求め、学習しながら改善していく()
- 転移学習: 事前学習済みモデルを使って、新しい領域でのラベリングを素早く立ち上げる()
結果として得られるのは、大規模でも一貫性のある高品質なラベルです。
ステップ4: 品質保証と人によるレビュー
どんなに優れたモデルでも、最終確認は必要です。定期的な人によるレビューは、例外ケース、曖昧なデータ、モデルドリフトの検出に役立ちます。実践的なQA手順には次のようなものがあります。
- ラベル付きデータをランダムサンプリングして手動レビューする
- 自動ラベルを「ゴールドスタンダード」セットと比較する
- アノテーター間一致率の指標を使って一貫性を測定する()
Thunderbit を使って機械学習による自動データラベリングを行う方法
では、実際に使ってみましょう。 は、ビジネスユーザー向けに設計されたAI搭載のウェブスクレイパー兼データラベリングツールです。コーディングは不要です。これを使って、データラベリングのワークフローを自動化する方法を紹介します。
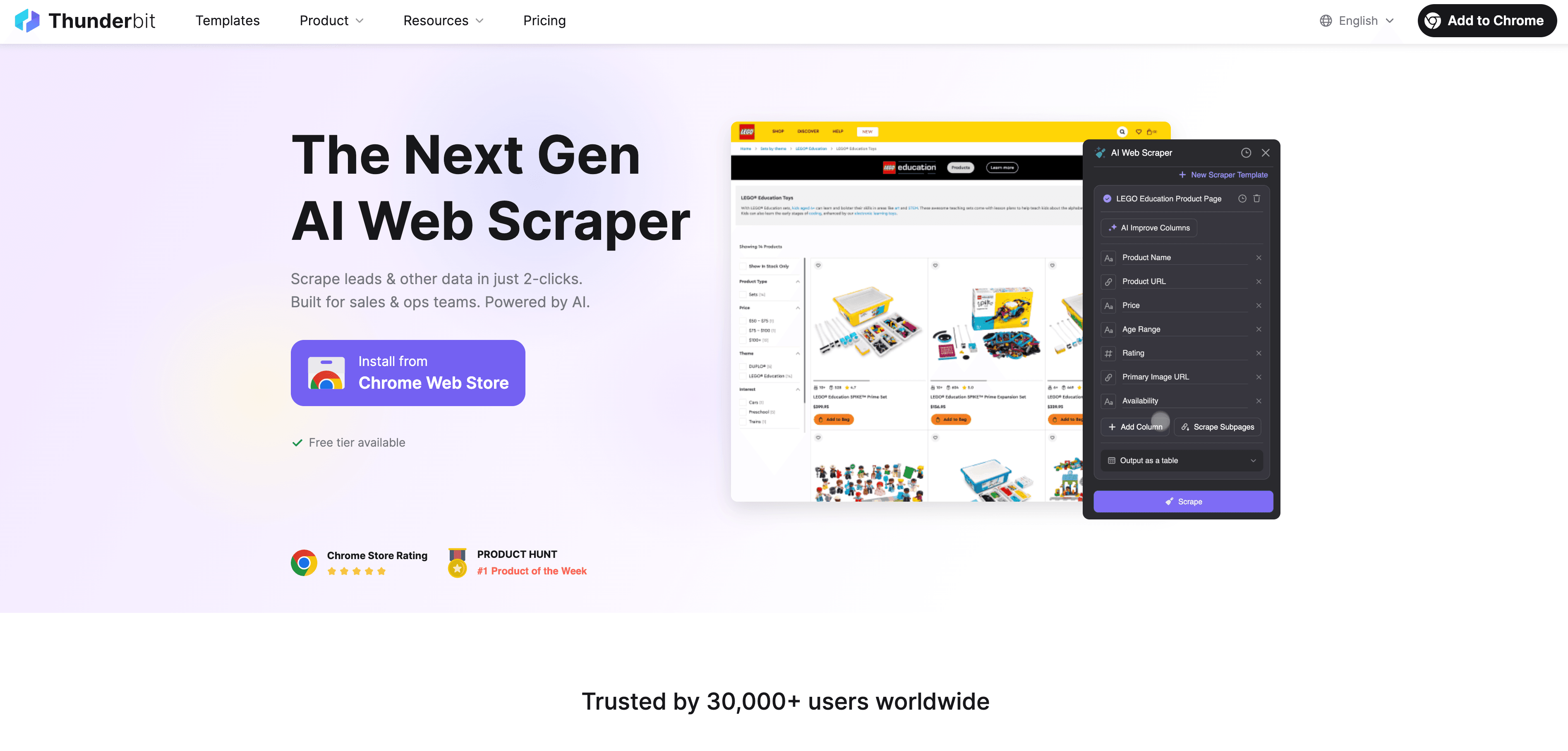
手順ガイド
- Webサイトのデータをスクレイピングする: を使って、あらゆるWebサイトから構造化データを収集します。拡張機能を開き、データソースを選ぶだけで、ThunderbitのAIが抽出に最適な項目を提案してくれます。
- ラベル付けの指示を定義する: Thunderbitの自然言語プロンプトを使って、AIにデータのラベル付け方法を指示します。たとえば「500ドルを超える商品をすべて『高級』とラベル付けする」「レビューにポジティブな感情があるものにタグを付ける」といった形です。
- 自動ラベリングを適用する: ThunderbitのField AI Prompt機能を使うと、ラベルの付け方を細かくカスタマイズ・調整できます。複数フィールドや複雑なラベリングタスクに最適です。
- ラベル付きデータを書き出す: ラベル付けが終わったら、Excel、Google Sheets、Airtable、Notionへ直接エクスポートできます。モデル学習や分析の準備はこれで完了です。
何よりの魅力は、Thunderbitが営業、マーケティング、オペレーションなど、非エンジニアのユーザー向けに作られていることです。1行もコードを書く必要はなく、複雑なテンプレートに悩まされることもありません。
Thunderbit の自然言語プロンプトとField AI機能
私のお気に入り機能のひとつは、ラベル付けのロジックを平易な英語で定義できることです。リードを地域ごとに分類したい、商品をカテゴリ別にタグ付けしたい、あるいは緊急性の高い文面のメールをフラグ付けしたい。そんなときも、やりたいことをそのまま書けば、あとはThunderbitのAIが処理してくれます。
プロンプト例:
- 「
.eduのメールアドレスを持つ連絡先はすべて『教育』セグメントとしてラベル付けする」 - 「レビューに『迅速な発送』という表現があれば、『ポジティブな配送体験』としてタグ付けする」
- 「商品をブランドと価格帯でグループ分けする」
ThunderbitのField AI Promptを使えば、さらに細かく設定できます。列ごとにラベルのロジックをカスタマイズしたり、ルールを組み合わせたり、ラベルを複数言語に翻訳したりすることも可能です。
サブページのスクレイピングと複数フィールドのラベリング
複雑なデータ構造でも問題ありません。Thunderbitのサブページスクレイピング機能を使えば、商品詳細や著者プロフィールのようなネストされたページからデータを抽出・ラベリングし、それらをひとつの構造化テーブルにまとめられます。複数のフィールドを一度にラベル付けできるので、さらに時間を節約できます。
実例: ECサイトの商品一覧をスクレイピングし、各商品リンクをたどって仕様、レビュー、販売者情報を抽出してラベル付けする。すべてを1つのワークフローで完結できます。
複数のデータラベリングツールを統合して精度と効率を高める
Thunderbitは幅広くカバーできますが、画像アノテーションや動画ラベリングのように、特定のデータ型には専用ツールが必要なこともあります。そこで登場するのが、 や のようなプラットフォームです。
ワンポイント: ThunderbitでWebデータの抽出と初期ラベリングを行い、その後データをLabel StudioやSuperviselyにエクスポートして、画像のバウンディングボックスや動画のフレーム単位タグ付けなど高度なアノテーションを行うのがおすすめです。このマルチツール方式なら、各プラットフォームの強みを活かせるため、精度と効率の両方が向上します()。
Thunderbit と併用するとよい専用ツールの使いどころ
- 画像アノテーション: 物体検出やセグメンテーションには、Supervisely や Label Studio を使う
- 動画ラベリング: 専用の動画ツールなら、フレームごとの注釈付けや追跡ができる
- 複雑なマルチラベルタスク: Thunderbitの構造化データ抽出と高度なアノテーションツールを組み合わせると効果的
ベストプラクティス: まずThunderbitで、構造化・半構造化データをすばやく大規模にラベル付けし、必要に応じて専用ツールで詳細なアノテーションを加えましょう。
機械学習を使った自動データラベリングのベストプラクティス
自動ラベリングのワークフローを最大限に活用したいですか? 私のおすすめは次のとおりです。
- 明確なラベルガイドラインを定義する: 曖昧なラベルは一貫性のないデータにつながります。各ラベルの意味を具体的に決めましょう。
- 高品質なシードセットから始める: 初期モデルを学習させるために、代表的なサンプルを少量手動でラベル付けします。
- 反復して改善する: アクティブラーニングを使って、特に難しいケースに人のレビューを集中させながらモデルを改善していきます。
- 定期的に検証する: ラベル付きデータをランダムに抽出して定期的に確認し、エラーやドリフトを検出します。
- 統合して自動化する: Thunderbitのようなツールを使って、データ収集、ラベリング、エクスポートを1つのワークフローにまとめます。
よくある課題とその解決方法
自動データラベリングにも課題はあります。代表的なものへの対処法は次のとおりです。
- 曖昧なデータ: 明確で詳細なラベル定義を用意し、例外ケースの例も示す
- モデルドリフト: 新しく人がレビューしたデータを使って、ラベリングモデルを定期的に再学習する
- 例外ケース: 不確かなデータや新しいデータポイントを人がレビューする仕組みを作る
- 統合の問題: 使いたいプラットフォームへ簡単にエクスポートできるツール(Thunderbitなど)を選ぶ
まとめと重要ポイント
機械学習を使った自動データラベリングは、今日の効果的なAIモデルを支える“秘密のソース”です。時間を節約し、コストを削減し、そして何より、モデルが最高の性能を発揮するために必要な一貫性のある高品質なラベルを提供します。 のようなツールと専用のアノテーションプラットフォームを組み合わせれば、技術背景に関係なく、速く、正確で、拡張性の高いラベリングワークフローを構築できます。
その違いを自分の目で確かめてみませんか? して、次のプロジェクトで自動ラベリングを試し、機械学習モデルがより賢く、より速くなるのを実感してください。さらにヒントやベストプラクティスを知りたい方は、 で詳しい解説やチュートリアルをご覧ください。
FAQ
1. 機械学習を使った自動データラベリングとは何ですか?
人が手作業でラベルを付ける代わりに、AIや機械学習モデルを使ってデータに自動でラベルを付けるプロセスです。この方法により、ラベリングが高速化し、一貫性が向上し、大規模データセットにも対応できます。
2. なぜラベリング品質が機械学習で重要なのですか?
高品質で一貫性のあるラベルは、正確なモデルを学習させるために不可欠です。ラベル品質が悪いと、モデル精度が最大80%低下し、予測の信頼性も下がります。
3. Thunderbitは自動データラベリングにどう役立ちますか?
Thunderbitを使えば、自然言語プロンプトとカスタマイズ可能なフィールドロジックで、AIによるWebデータのスクレイピングとラベリングができます。コーディングは不要で、営業、マーケティング、オペレーションのビジネスユーザーに最適です。
4. Thunderbitを他のラベリングツールと組み合わせられますか?
もちろんです。Thunderbitで構造化データの抽出と初期ラベリングを行い、その後Label StudioやSuperviselyのようなツールにエクスポートして、高度な画像や動画のアノテーションを行えます。
5. 自動データラベリングのベストプラクティスは何ですか?
明確なラベルガイドラインを定義し、品質の高いシードセットから始め、アクティブラーニングで反復改善し、定期的に検証し、統合ツールを使ってワークフローを効率化することです。
データラベリングを自動化して、機械学習プロジェクトを一気に加速させる準備はできましたか? Thunderbitを試して、どれだけ時間とストレスを減らせるか確かめてみてください。
詳細はこちら: