

Amazon ha quasi 2 milioni di partner di vendita e centinaia di milioni di articoli nel suo catalogo. Se hai mai provato a copiare a mano titoli dei prodotti, prezzi, valutazioni e ASIN in un foglio di calcolo, sai bene quanto sia frustrante — e quanto il problema esploda in fretta.
Lavoro in Thunderbit, dove sviluppiamo un Estrattore Web AI, quindi passo molto tempo a ragionare su come le persone estraggono dati dai siti web. Ma per questo articolo volevo fare qualcosa che non sembra fare nessun’altra rassegna: mettere a confronto sette vere estensioni Chrome che puoi installare e usare su Amazon, provarle sulle stesse pagine e darti una risposta diretta su cosa funziona, cosa no e dove si colloca ciascuno strumento. Ho valutato ogni estensione in base a otto criteri che riflettono esattamente le frustrazioni che vedo nei forum e tra i nostri utenti — cose come il rilevamento dei campi con AI, lo scraping delle sottopagine, il rischio di blocco, i piani gratuiti e le opzioni di esportazione. Che tu sia un venditore Amazon, un marketer o semplicemente una persona stanca del copia e incolla, questa guida fa per te.
Prova Thunderbit per lo scraping di Amazon
Perché estrarre dati dei prodotti Amazon, prima di tutto?
Quindi, chi usa davvero lo scraping di Amazon e perché?
La risposta breve è: quasi tutti quelli che vendono, fanno marketing o analizzano prodotti online. Amazon afferma che oltre il 60% delle vendite nel suo store proviene da venditori indipendenti, e questi venditori si osservano costantemente a vicenda. Ecco i casi d’uso più comuni che vedo:
| Caso d’uso | Chi lo fa | Cosa ottengono |
|---|---|---|
| Monitoraggio dei prezzi dei concorrenti | Venditori, team pricing, agenzie | Dati in tempo reale su prezzi e disponibilità dei prodotti rivali |
| Ricerca prodotto e monitoraggio dei trend | Venditori Amazon, ricercatori di mercato | Individuare categorie in crescita, nuovi ingressi e variazioni della domanda |
| Analisi del sentiment delle recensioni | Venditori private label, team brand | Reclami ricorrenti, lacune nelle funzionalità e opportunità |
| Generazione di lead (contatti dei venditori) | Team wholesale, agenzie | Nomi dei venditori, store e informazioni di contatto |
| Monitoraggio catalogo e inventario | Operazioni ecommerce, protezione del brand | Tracciare livelli di stock, modifiche alle inserzioni e venditori non autorizzati |
| Ottimizzazione di keyword e inserzioni | Proprietari di brand, operatori marketplace | Dati sulle query di ricerca, testi delle inserzioni e keyword dei concorrenti |
Il ROI è tangibile. I case study di Amazon mostrano che le vendite trimestrali di thefitguy sono aumentate di oltre il 40% dopo l’ottimizzazione per i termini di ricerca principali usando dati strutturati. E un sondaggio di Parseur ha rilevato che i lavoratori trascorrono più di 9 ore alla settimana in inserimenti dati ripetitivi. Se riesci ad automatizzare anche solo una parte di tutto questo, liberi davvero tanto tempo per prendere decisioni concrete.
Cosa rende davvero valida un’estensione Chrome per Amazon Scraper (i miei criteri di test)
Non tutte le estensioni Chrome sono uguali — e la maggior parte degli articoli comparativi mette nello stesso calderone API, app desktop ed estensioni browser come se fossero intercambiabili. Non lo sono. Ecco il framework che ho usato e perché ogni criterio conta:
- Facilità di configurazione — un utente non tecnico riesce a ottenere risultati in meno di 5 minuti? (I forum confermano che questa è una delle principali preoccupazioni.)
- Rilevamento dei campi con AI — lo strumento identifica automaticamente i campi del prodotto o devi configurare manualmente i selettori? (Nessun altro articolo tratta nemmeno questa categoria.)
- Scraping di sottopagine / pagine di dettaglio — puoi arricchire i dati dell’inserzione con informazioni della pagina prodotto in un unico flusso di lavoro?
- Gestione anti-bot / rischio di blocco — come affronta il rilevamento aggressivo dei bot di Amazon? (Il problema n. 1 nei forum degli utenti.)
- Supporto alla paginazione — riesce a estrarre automaticamente dati da più pagine di risultati?
- Piano gratuito / prezzi — cosa ottieni davvero senza pagare? (Gli utenti chiedono esplicitamente delle opzioni gratuite, e nessun concorrente dà una risposta pratica.)
- Opzioni di esportazione — CSV, Excel, Google Sheets, Airtable, Notion?
- Pianificazione e automazione — puoi impostarlo per eseguirsi in modo ricorrente?
Ho testato ogni estensione sui risultati di ricerca Amazon US e sulle pagine prodotto, con le stesse query e le stesse condizioni.

Scraping basato su AI vs. scraping basato su selettori: perché conta su Amazon
C’è una distinzione che nessun altro riepilogo di Amazon Scraper mette in evidenza — ed è il fattore più importante per capire quanta manutenzione richiederà il tuo scraper.
La maggior parte delle estensioni Chrome per lo scraping funziona mappando selettori CSS sui campi dati. Tu (o il template dello strumento) indichi l’elemento HTML per “prezzo” o “titolo”, e lo scraper prende ciò che trova. Il problema? Amazon modifica il suo HTML e CSS sottostante ogni giorno proprio per mandare in crisi gli scraper. Gli utenti dei forum descrivono nomi di classi hashati o variabili come una modalità di errore molto comune.
Ecco come si confrontano i tre approcci principali:
| Approccio | Come funziona | Quando cambia il layout di Amazon |
|---|---|---|
| Basato su selettori (tradizionale) | L’utente mappa manualmente i selettori CSS sui campi | Si rompe - l’utente deve riconfigurare |
| Basato su template | Ricette predefinite per le pagine Amazon | Si rompe finché lo sviluppatore non aggiorna il template |
| Basato su AI (es. Thunderbit) | L’AI legge il contenuto della pagina e rileva automaticamente i campi | Si adatta automaticamente - nessuna manutenzione |
Solo una delle sette estensioni che ho testato — Thunderbit — usa il rilevamento dei campi con AI come percorso di configurazione predefinito. Le altre si affidano a selettori o template, il che significa più manutenzione quando Amazon modifica inevitabilmente le proprie pagine. Capire questa differenza ti risparmierà molta frustrazione nel tempo.
1. Thunderbit - L’estensione Chrome AI per Amazon Scraper
Thunderbit è lo strumento che abbiamo costruito nella nostra azienda, quindi lo dico chiaramente. Ma credo anche davvero che sia la scelta migliore per gli utenti non tecnici che vogliono dati Amazon rapidi e accurati senza dover combattere con selettori o codice.
Il differenziatore principale è AI Suggest Fields. Quando apri una pagina risultati Amazon e fai clic sul pulsante, l’AI di Thunderbit legge la pagina e propone i nomi delle colonne — titolo, prezzo, valutazione, ASIN, numero di recensioni, URL del prodotto e altro ancora. Non devi configurare nulla. L’AI capisce cosa c’è nella pagina e suggerisce i campi e i tipi di dati corretti.
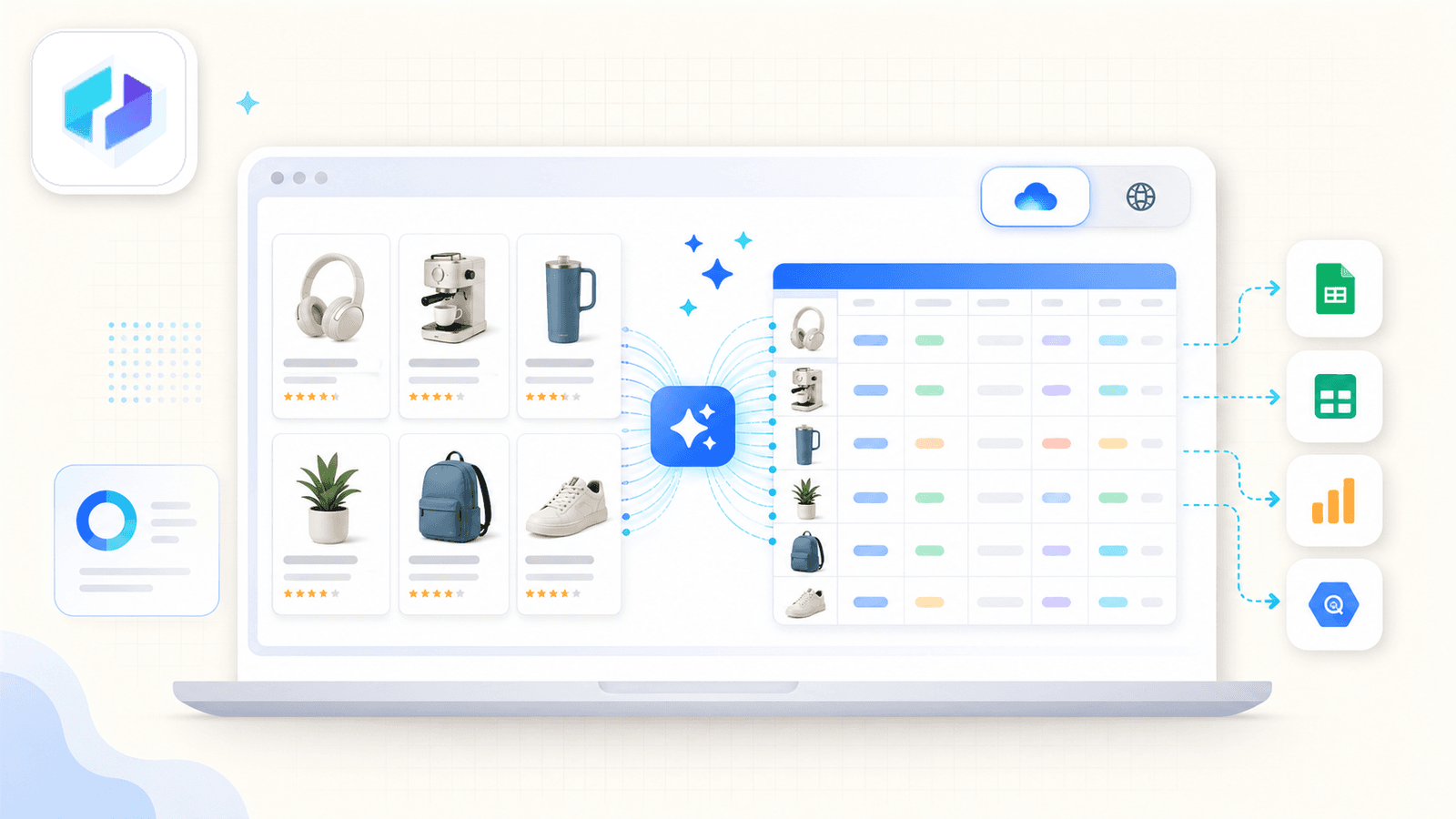
Ecco come appare in genere una sessione di scraping Amazon:
- Installa la Thunderbit Chrome Extension, apri una pagina risultati di ricerca Amazon.
- Fai clic su AI Suggest Fields — l’AI rileva e propone le colonne.
- Fai clic su Scrape — i dati vengono popolati all’istante.
- Per le pagine Amazon più popolari, puoi anche usare il modello Amazon Scraper già pronto per una vera esperienza a 1 clic.
Ciò che distingue davvero Thunderbit è lo scraping delle sottopagine. Dopo aver estratto la pagina elenco, fai clic su Scrape Subpages — Thunderbit visita ogni URL del prodotto e aggiunge campi di dettaglio (descrizioni complete, punti elenco, informazioni sul venditore, URL delle immagini) alla stessa tabella. La maggior parte delle estensioni concorrenti semplicemente non offre questa funzione.
C’è anche un toggle cloud vs browser. La modalità cloud estrae fino a 50 pagine contemporaneamente per inserzioni pubbliche. La modalità browser usa la tua sessione Chrome — ideale quando sei connesso a Seller Central o vuoi passare più inosservato.
La pianificazione si esprime in linguaggio naturale: descrivi l’intervallo di tempo e l’AI lo converte in una programmazione.
Le opzioni di esportazione includono Excel, Google Sheets, Airtable, Notion, CSV e JSON — tutto incluso nel piano gratuito.
Pro e contro di Thunderbit
Pro:
- L’AI rileva automaticamente i campi — nessuna configurazione di selettori, nessuna manutenzione quando Amazon cambia layout
- Arricchimento delle sottopagine con un clic
- Toggle cloud/browser per flessibilità e minor rischio di blocco
- La gamma più ampia di opzioni di esportazione (Sheets, Airtable, Notion, Excel, CSV, JSON)
- Pianificazione con linguaggio naturale
- Modello Amazon già pronto per risultati immediati
Contro:
- Il sistema a crediti significa che gli utenti intensivi avranno bisogno di un piano a pagamento
- Il rilevamento dei campi con AI aggiunge un breve passaggio di elaborazione (pochi secondi)
- Strumento più recente, quindi con meno documentazione della community rispetto alle opzioni più datate
Prezzi di Thunderbit
- Piano gratuito: 6 pagine (10 con il boost di prova), include funzioni AI e tutti i formati di esportazione
- Piani a pagamento: da circa $9/mese (annuale) per 500 crediti; 1 credito = 1 riga di output
- Vedi Prezzi Thunderbit per i dettagli più aggiornati
Estrai pagine Amazon con l’AI Get Started Free
2. Instant Data Scraper - L’opzione gratuita, semplice e senza fronzoli
Instant Data Scraper è un’estensione Chrome che rileva automaticamente i dati tabellari nelle pagine web usando algoritmi euristici. Esiste da anni ed è ancora uno degli scraper gratuiti più scaricati dal Chrome Web Store.
Su Amazon, attivi l’estensione su una pagina risultati di ricerca e provi a rilevare automaticamente la tabella dati. A volte dovrai fare clic su “try another table” se il primo rilevamento non centra il bersaglio. Per scraping semplici e occasionali, funziona abbastanza bene.
C’è però un avviso importante per il 2026: la pagina ufficiale ora indica che Instant Data Scraper non è più di proprietà, sviluppato o supportato da Web Robots. Questo significa niente aggiornamenti, niente correzioni di bug e nessuna nuova funzionalità. In un thread Reddit, un utente ha segnalato che gestiva le pagine di riepilogo ma si bloccava quando servivano clic a livello di dettaglio.
Pro e contro di Instant Data Scraper
Pro:
- 100% gratuito, non serve account
- Leggero e veloce per tabelle semplici
- Supporta la paginazione di base (clic sul pulsante “Next”)
Contro:
- Nessun rilevamento dei campi con AI (si basa sul pattern matching, che può interpretare male il layout complesso di Amazon)
- Nessuno scraping di sottopagine
- Solo esportazione CSV/Excel
- Nessuna pianificazione, nessuna opzione cloud
- Non più mantenuto — si rompe quando Amazon cambia layout e nessuno lo sistema
3. Web Scraper - L’estensione storica per la configurazione manuale
Web Scraper è uno degli scraper per estensioni Chrome più consolidati, costruito attorno a un visual sitemap builder. Apri DevTools, crei una “sitemap” indicando e facendo clic per definire i selettori, configuri la paginazione e puoi seguire i link alle pagine di dettaglio prodotto.
Web Scraper offre anche un template Amazon Products Listings Scraper nel suo marketplace, che gestisce navigazione, paginazione ed estrazione delle pagine prodotto. La guida passo passo accompagna l’utente in un processo di configurazione in 8 passaggi — installazione, generazione dei selettori, configurazione della paginazione, follow dei link prodotto, esecuzione in locale o nel cloud.
La versione cloud aggiunge pianificazione, accesso API, rotazione dei proxy, bypass CAPTCHA e integrazione con Google Sheets.

Pro e contro di Web Scraper
Pro:
- Maturo, ben documentato e supportato dalla community
- Estensione browser gratuita (uso locale illimitato)
- Template marketplace per Amazon
- Opzione cloud per scalabilità (pianificazione, rotazione IP, integrazioni)
- Supporta il follow dei link alle pagine di dettaglio prodotto (arricchimento parziale delle sottopagine)
Contro:
- Richiede configurazione manuale dei selettori — curva di apprendimento più ripida per utenti non tecnici
- Nessun rilevamento automatico dei campi con AI
- I template possono rompersi quando Amazon aggiorna il layout
- Le funzioni avanzate sono bloccate dietro piani cloud a pagamento
Prezzi di Web Scraper
- Gratis: estensione Chrome, scraping locale illimitato
- Piani cloud: da $50/mese (Project), $100/mese (Professional), da $200/mese (Scale)
4. Octoparse - La piattaforma ricca di funzioni (con una precisazione sull’estensione Chrome)
Octoparse è una potente piattaforma di scraping no-code con template Amazon predefiniti per dettagli prodotto, ricerca per keyword e recensioni. Supporta scraping cloud, pianificazione e workflow multi-passaggio.
C’è però una precisazione importante: l’estensione del Chrome Web Store di Octoparse è attualmente elencata come Octoparse AI Web Automation, e indica esplicitamente che funziona solo insieme a Octoparse AI Bot su Windows. Quindi l’esperienza reale di scraping è prima di tutto basata sulla piattaforma, non sull’estensione. Se cerchi un flusso puro “installa e usa in Chrome”, Octoparse è più simile a un’app desktop con un assistente browser.
Detto questo, i template sono eccellenti. Inserisci un URL di ricerca, Octoparse estrae automaticamente i dati del prodotto e puoi costruire workflow personalizzati con selettori point-and-click, paginazione e follow dei link per le pagine di dettaglio.
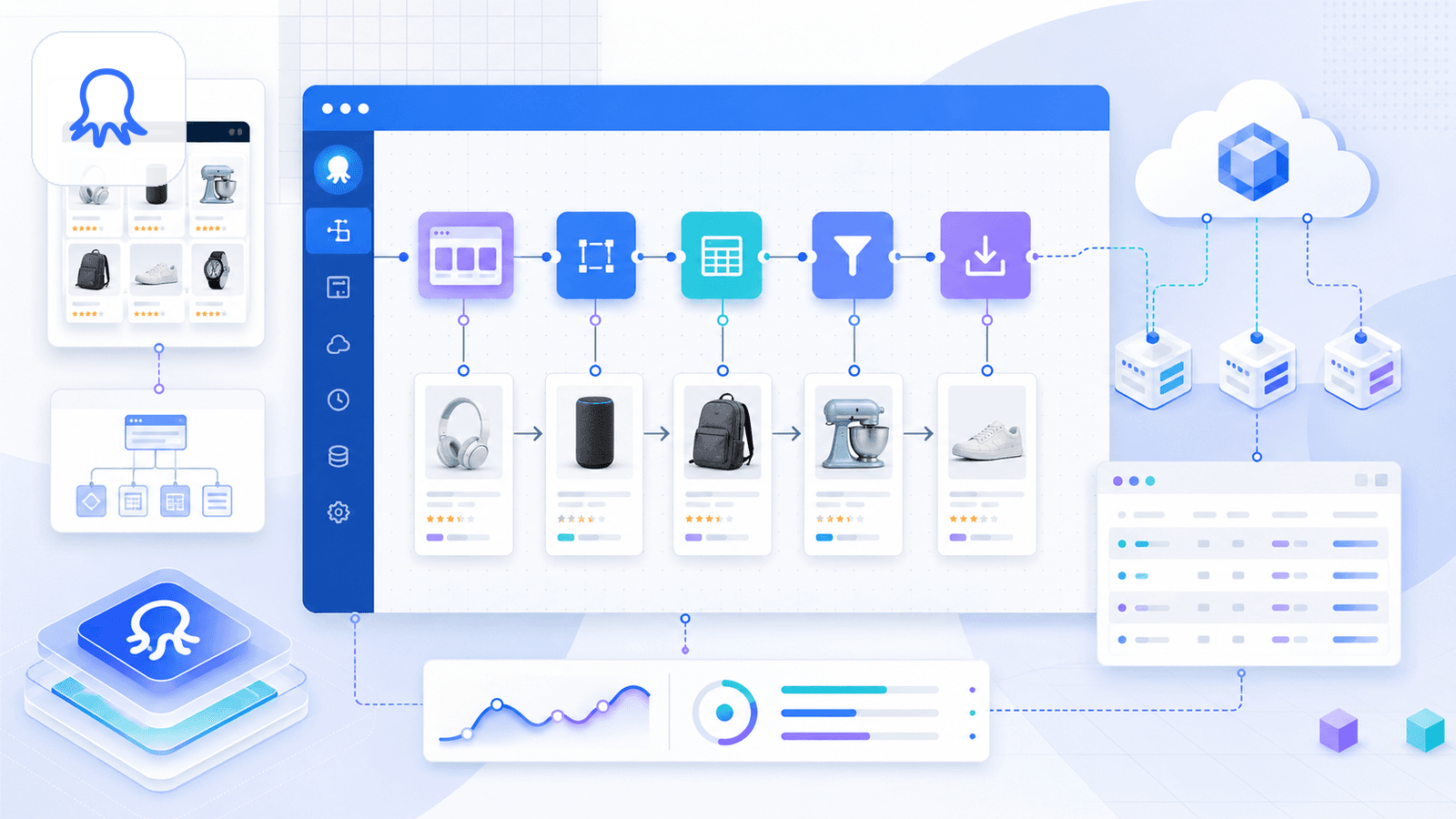
Pro e contro di Octoparse
Pro:
- Set di funzioni robusto con template Amazon
- Nodi cloud per velocità, pianificazione ed estrazione delle sottopagine tramite workflow
- Gestisce bene la paginazione
- Buono per pipeline di scraping complesse e multi-step
Contro:
- La piena potenza richiede l’app desktop — non è una pura esperienza da estensione Chrome
- Nessun campo auto-suggerito con AI (esiste un prodotto separato, Chat4Data, ma è un’estensione diversa)
- Il piano gratuito limita l’esportazione a circa 50K dati/mese, 10.000 righe per export
- L’interfaccia può sembrare complessa ai principianti
Prezzi di Octoparse
- Gratis: limitato (estrazione locale, tetto export 50K)
- Standard: circa $75-$83/mese
- Professional: circa $208-$249/mese
- Add-on: rotazione IP a $3/GB, risoluzione CAPTCHA a $2-$2.50 per 1.000
5. Axiom.ai - Il generatore di bot no-code
Axiom.ai è un’estensione Chrome per creare bot di automazione del browser con un builder visivo no-code. È più uno strumento di automazione generale che uno scraper dedicato, ma ha template per lo scraping Amazon e guide per l’estrazione degli ASIN.
Crei un bot (o parti da un template) che scorre gli URL dei prodotti in un Google Sheet, visita ogni pagina, estrae i dati tramite selettori point-and-click e scrive i risultati di nuovo nel foglio. La pianificazione è disponibile nei piani a pagamento, e ora sono offerte anche esecuzioni cloud: da 1 bot cloud su Starter e Pro fino a 20 bot cloud simultanei su Ultimate.
Pro e contro di Axiom.ai
Pro:
- Automazione no-code versatile (non solo scraping)
- Integrazione nativa con Google Sheets
- Pianificazione ed esecuzioni cloud nei piani a pagamento
- Template per Amazon
- Ottimo per workflow multi-step oltre l’estrazione dati
Contro:
- Configurazione più pesante per uno scraping semplice (richiede progettazione del bot, configurazione del Google Sheet, test del ciclo)
- Nessun rilevamento dei campi con AI
- Nessun arricchimento delle sottopagine con un clic (devi costruire un passaggio separato del bot)
- Esportazione limitata a Google Sheets o CSV
Prezzi di Axiom.ai
- Gratis: 2 ore di runtime
- Starter: $15/mese
- Pro: $50/mese
- Pro Max: $150/mese
- Ultimate: $250/mese
6. Data Miner - L’estensione basata su ricette
Data Miner è un’estensione Chrome focalizzata sull’estrazione dei dati usando “ricette” — template di scraping predefiniti o personalizzati. Puoi cercare una ricetta Amazon esistente nella libreria pubblica o crearne una tua selezionando gli elementi della pagina.
Data Miner supporta la paginazione tramite la funzione Next Page Automation e offre anche un flusso Crawl Scrape per visitare URL di dettaglio e applicare una seconda ricetta. Quindi non è corretto dire che non supporti lo scraping delle sottopagine — ma si tratta di un processo manuale e multi-step, non di un arricchimento con un clic.
Il limite principale è il piano gratuito: 500 pagine/mese, e alcuni domini sono limitati nella versione free. Le ricette sono specifiche per il sito, e la documentazione di Data Miner avverte che se il sito cambia e cambia anche il codice HTML di riferimento, la ricetta non funzionerà.
Pro e contro di Data Miner
Pro:
- Facile da eseguire con una ricetta esistente
- Libreria di ricette della community
- Supporta paginazione e crawling delle pagine di dettaglio (configurazione manuale)
- Interfaccia semplice
Contro:
- Piano gratuito limitato a 500 pagine/mese
- Nessun rilevamento dei campi con AI
- Le ricette si rompono quando Amazon cambia layout
- Niente scraping cloud, niente pianificazione nella documentazione pubblica
- Esportazione: CSV, Excel, clipboard; Google Sheets nei piani a pagamento
Prezzi di Data Miner
- Gratis: 500 pagine/mese
- A pagamento: $19.99, $49, $99, $200/mese con limiti e funzioni crescenti
7. Helium 10 - La suite di intelligence per venditori Amazon
Helium 10 è una suite completa per venditori Amazon, non uno scraper web generico. La sua estensione Chrome (Xray) sovrappone dati direttamente ai risultati di ricerca Amazon — mostrando stime di vendite, ricavi, trend delle recensioni, BSR e altro ancora. È progettata per i venditori Amazon che fanno ricerca di prodotto, non per estrarre dati grezzi dalle pagine.
Helium 10 nel 2026 offre anche un piano gratuito, anche se l’accesso all’estensione Chrome è limitato nella versione free. L’estensione può esportare i risultati in CSV o Excel e supporta flussi di lavoro basati su clipboard.
Pro e contro di Helium 10
Pro:
- Approfondimenti molto dettagliati specifici per Amazon (stime di vendita, dati keyword, trend BSR)
- Usato da venditori professionisti
- Dati cloud e pianificazione per il monitoraggio di keyword/ranking
- Piano gratuito disponibile (limitato)
Contro:
- Non è uno scraper generico — non può estrarre campi dati personalizzati da pagine arbitrarie
- Costoso rispetto agli strumenti focalizzati sullo scraping
- Formati di esportazione limitati (CSV, Excel)
- Nessun rilevamento dei campi con AI, nessun arricchimento delle sottopagine nel senso classico dello scraping
Prezzi di Helium 10
- Gratis: accesso limitato, inclusa l’estensione Chrome
- Starter: $49/mese
- Platinum: $229/mese
- Diamond: $359/mese
Confronto tra le estensioni Chrome per Amazon Scraper: il confronto completo
Ecco la tabella di confronto onesta. Ho corretto alcune ipotesi delle bozze precedenti dopo i test pratici e la verifica del 2026:
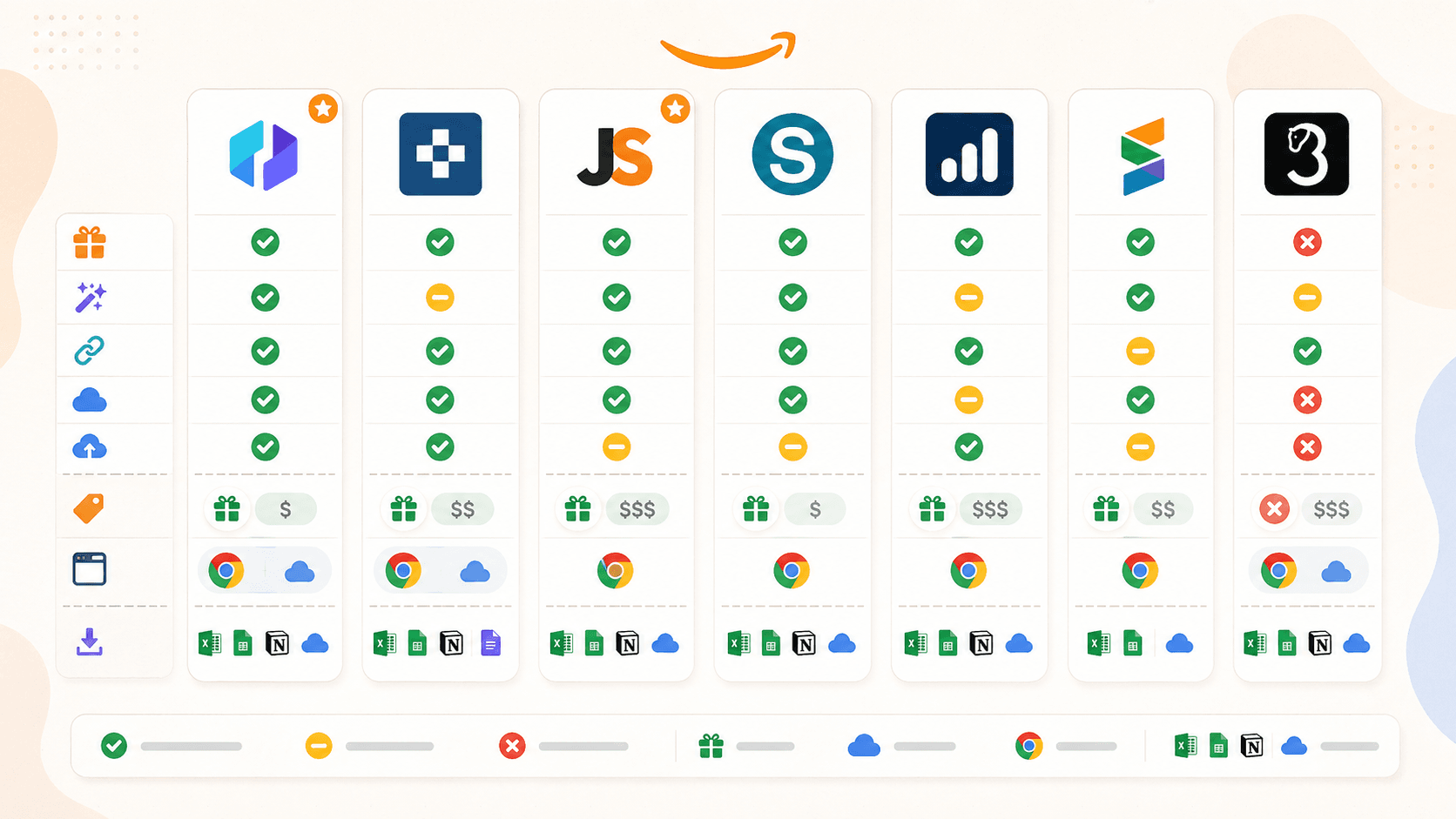
| Funzione | Thunderbit | Instant Data Scraper | Web Scraper | Octoparse | Axiom.ai | Data Miner | Helium 10 |
|---|---|---|---|---|---|---|---|
| Categoria principale | Estensione scraper AI | Scraper euristico gratuito | Scraper basato su selettori/template | Piattaforma di scraping no-code | Generatore di bot per automazione browser | Estensione scraper basata su ricette | Overlay di ricerca per venditori |
| Campi auto-suggeriti dall’AI | Sì | No | No | No (Chat4Data separato) | No | No | No |
| Arricchimento delle sottopagine | Sì (1 clic) | No | Sì (sitemap manuale) | Sì (workflow) | Sì (passaggio bot manuale) | Sì (crawl manuale) | N/D |
| Scraping cloud | Sì | No | Sì (a pagamento) | Sì (a pagamento) | Sì (a pagamento) | No | Analisi supportata dal cloud |
| Pianificazione | Sì | No | Sì (a pagamento) | Sì (a pagamento) | Sì (a pagamento) | No | Sì (monitoraggio keyword/ranking) |
| Piano gratuito | Sì (6-10 pagine) | Sì (totalmente gratuito) | Sì (solo browser) | Sì (limitato) | Sì (2 ore runtime) | Sì (500 pagine/mese) | Sì (limitato) |
| Template Amazon predefinito | Sì | No | Sì | Sì | Sì (guide) | Libreria di ricette | N/D |
| Esportazione in Sheets/Airtable/Notion | Sì (tutti) | Solo CSV/Excel | CSV, Excel, JSON; Sheets via cloud | CSV, Excel, JSON, altro | Google Sheets, CSV | CSV, Excel; Sheets nei piani a pagamento | CSV, Excel |
Saltano subito all’occhio alcune cose. Thunderbit è l’unica estensione con rilevamento dei campi tramite AI e con le opzioni di esportazione più ampie nel piano gratuito. Instant Data Scraper è l’opzione gratuita più semplice, ma non è più mantenuta. Web Scraper e Octoparse sono potenti per chi è disposto a investire nella configurazione, ma nessuno dei due offre una vera esperienza “installa e vai” da estensione. Axiom.ai è il migliore per automazioni multi-step oltre lo scraping. Data Miner è facile per eseguire ricette esistenti, ma il piano gratuito è stretto. Helium 10 è uno strumento di intelligence per venditori, non uno scraper generico.
Scraping cloud vs browser per Amazon: cosa devi sapere sul rischio di blocco
Questo è il grande elefante nella stanza. Amazon rileva e blocca attivamente lo scraping automatizzato. Gli utenti su Reddit segnalano CAPTCHA che compaiono persino per scraper a basso volume, e le stesse Conditions of Use di Amazon dicono esplicitamente che la licenza non include “any use of data mining, robots, or similar data gathering and extraction tools.”
Quindi, qual è la differenza pratica tra scraping browser e cloud?
- Scraping browser gira nella tua sessione Chrome reale — cookie reali, stato di login reale, comportamento di navigazione naturale. A basso volume sembra più umano, ma occupa il browser.
- Scraping cloud usa server remoti per la velocità (Thunderbit gestisce 50 pagine alla volta in modalità cloud), ma richiede limitazione delle richieste e rotazione dei proxy per evitare il rilevamento.
Ecco una matrice decisionale che uso:
| Scenario | Modalità consigliata | Perché |
|---|---|---|
| Estrarre 20 pagine prodotto per ricerca | Browser | Volume basso, comportamento naturale |
| Monitorare 500 SKU concorrenti ogni settimana | Cloud | Conta la velocità, dati pubblici |
| Estrarre dati mentre sei connesso a Seller Central | Browser | Serve la tua sessione di login |
| Esportazione bulk una tantum di una categoria | Cloud | Scraping parallelo per velocità |
Tra le sette estensioni, lo scraping cloud è disponibile in Thunderbit, Web Scraper (a pagamento), Octoparse (a pagamento), Axiom.ai (a pagamento) e Helium 10 (per la sua analytics). Instant Data Scraper e Data Miner funzionano solo nel browser.
Consigli pratici per ridurre il rischio di blocco: mantieni ragionevoli gli intervalli tra le richieste, evita di fare scraping nelle ore di punta e ruota gli user agent se lo strumento lo supporta. E non prometterti mai “rischio zero” — gestiscilo semplicemente nel modo migliore possibile.
Dalla pagina elenco alla pagina prodotto: come funziona lo scraping delle sottopagine su Amazon
Questo flusso di lavoro è sottovalutato — e nessun articolo concorrente lo dimostra end-to-end.
Quando estrai una pagina risultati di Amazon, ottieni dati riassuntivi: titoli dei prodotti, prezzi, valutazioni, ASIN e URL dei prodotti. Ma spesso servono anche i dati della pagina di dettaglio — descrizioni complete, punti elenco, URL delle immagini, informazioni sul venditore, suddivisione delle recensioni. È qui che entra in gioco lo scraping delle sottopagine.
Con Thunderbit, il flusso è:
- Estrai la pagina risultati Amazon -> ottieni una tabella di prodotti (titolo, prezzo, valutazione, ASIN, URL del prodotto).
- Fai clic su “Scrape Subpages” -> Thunderbit visita ogni URL del prodotto e aggiunge campi di dettaglio (descrizione, numero di recensioni, nome del venditore, URL delle immagini, ecc.) alla stessa tabella.
- Esporta la tabella arricchita in Google Sheets, Airtable, Notion o Excel.
L’AI rileva la struttura della sottopagina e arricchisce automaticamente la tabella — senza configurazione manuale. Per esperienza, questo fa risparmiare almeno un’ora per batch rispetto all’aprire ogni pagina prodotto e copiare i campi a mano.
Anche gli altri strumenti possono farlo, ma con più fatica:
- Web Scraper: configuri una sitemap per seguire i link ai prodotti e definisci i selettori per ogni campo di dettaglio. Funziona, ma è un processo manuale multi-step.
- Octoparse: costruisci un workflow con passaggi di link-following. Potente, ma non a un clic.
- Axiom.ai: progetti un loop del bot che visita ogni URL ed estrae i dati. Flessibile, ma richiede competenze di costruzione bot.
- Data Miner: usi la funzione Crawl Scrape per visitare gli URL salvati e applicare una seconda ricetta. Manuale e dipendente dalla ricetta.
- Instant Data Scraper e Helium 10: nessun flusso di arricchimento delle sottopagine.
Se ti servono regolarmente sia dati a livello di elenco sia dati a livello di dettaglio su Amazon, lo strumento che scegli dovrebbe rendere questo flusso semplice — non solo possibile.
Ripartizione onesta del piano gratuito: cosa ottieni davvero senza pagare
Gli utenti dei forum chiedono questa cosa più di ogni altra, e nessun articolo concorrente la spiega in modo trasparente.
| Estensione | Piano gratuito | Cosa ottieni gratis | Quando devi passare a un piano superiore |
|---|---|---|---|
| Thunderbit | Sì (6 pagine, 10 con trial) | Suggerimento dei campi con AI, tutti i formati di esportazione (Excel, Sheets, Airtable, Notion), estrattori email/telefono | Quando ti servono più pagine o scraping pianificato |
| Instant Data Scraper | Sì (totalmente gratuito) | Rilevamento base delle tabelle, esportazione CSV/Excel | N/D (nessun piano a pagamento, ma nemmeno aggiornamenti) |
| Web Scraper | Sì (solo browser) | Scraping nel browser, esportazione CSV | Scraping cloud, pianificazione, integrazioni |
| Octoparse | Sì (limitato) | Circa 50K export/mese, estrazione locale | Più record, nodi cloud |
| Axiom.ai | Sì (2 ore di runtime) | Automazioni di base, Google Sheets | Più esecuzioni, pianificazione, cloud |
| Data Miner | Sì (500 pagine/mese) | Ricette, CSV/Excel, Next Page Automation | Più pagine, Sheets, funzioni di crawl |
| Helium 10 | Sì (limitato) | Accesso limitato all’estensione Chrome | Xray completo, strumenti keyword, pianificazione |
L’insight chiave: il piano gratuito di Thunderbit include funzioni AI e tutti i formati di esportazione — la maggior parte dei concorrenti blocca esportazioni avanzate o AI dietro piani a pagamento. Instant Data Scraper è completamente gratuito ma non offre AI, sottopagine né pianificazione (ed è anche non più mantenuto). Helium 10 ha un piano free, ma l’accesso all’estensione è limitato e non è uno scraper generico.
La mia raccomandazione per scenario:
- “Sto solo testando” -> Instant Data Scraper (totalmente gratuito) o piano gratuito Thunderbit
- “Mi serve scraping regolare e affidabile” -> Thunderbit o piani a pagamento di Web Scraper
- “Venditore Amazon che ha bisogno di intelligence di mercato” -> Helium 10
Quale estensione Chrome Amazon Scraper dovresti scegliere?
Dopo averle testate tutte e sette, ecco il mio giudizio sincero:
- La migliore per utenti non tecnici che vogliono risultati rapidi con AI: Thunderbit. L’AI rileva automaticamente i campi, arricchimento delle sottopagine con un clic, le opzioni di esportazione più ampie, toggle cloud/browser. Se vuoi passare da una pagina Amazon a un foglio di calcolo in meno di due minuti, questa è la scelta giusta.
- La migliore opzione completamente gratuita per scraping rapidi e occasionali: Instant Data Scraper. Nessun costo, nessun account, ma funzioni limitate e non più mantenuta.
- La migliore per utenti a proprio agio con la configurazione manuale: Web Scraper. Builder sitemap flessibile, buona opzione cloud, ben documentato.
- La migliore per pipeline di scraping complesse e multi-step: Octoparse (desktop + estensione) o Axiom.ai (bot browser). Entrambi sono potenti, ma nessuno dei due è una pura estensione Chrome “installa e usa”.
- La migliore per estrazioni semplici basate su ricette: Data Miner. Facile usare ricette esistenti, ma piano gratuito limitato e niente AI.
- La migliore per l’intelligence dei venditori Amazon, non per lo scraping generico: Helium 10. Progettato per questo scopo, con dati proprietari approfonditi, ma costoso e non un vero scraper generico.
Se vuoi vedere come si presenta davvero lo scraping Amazon con AI, prova il piano gratuito di Thunderbit. Credo che rimarrai sorpreso da quanto puoi ottenere in pochi clic. E se Thunderbit non è la soluzione perfetta, prova anche un paio degli altri strumenti di questa lista — non c’è mai stato momento migliore per smettere di copiare e incollare e iniziare a fare scraping in modo più intelligente.
Per altri consigli sullo scraping Amazon, consulta le nostre guide su come estrarre prodotti e recensioni Amazon, estrarre i prezzi Amazon e estrarre e analizzare i dati di vendita Amazon. Puoi anche guardare i tutorial sul canale YouTube di Thunderbit.
Prova lo scraping AI di Amazon con Thunderbit Get Started Free
FAQ
1. È legale estrarre dati dei prodotti Amazon?
Estrarre dati visibili pubblicamente è in genere consentito, ma le Conditions of Use di Amazon vietano esplicitamente il data mining e l’estrazione automatizzata senza consenso scritto. Questo articolo non costituisce consulenza legale — verifica sempre i termini di Amazon prima di fare scraping su larga scala.
2. Amazon può rilevare e bloccare gli scraper delle estensioni Chrome?
Sì. Amazon ha sistemi anti-bot che possono attivare CAPTCHA, limitare le richieste o bloccare gli IP. Usare tassi di richiesta ragionevoli, lo scraping via browser per lavori piccoli e lo scraping cloud con limitazione del ritmo per lavori più grandi può ridurre il rischio. Vedi la sezione cloud vs browser sopra per una matrice decisionale pratica.
3. Quali dati puoi estrarre da Amazon con un’estensione Chrome?
I campi più comuni includono titoli dei prodotti, prezzi, valutazioni, numero di recensioni, ASIN, nomi dei venditori, descrizioni, URL delle immagini, disponibilità e informazioni sulla spedizione. Strumenti con AI come Thunderbit possono rilevare e suggerire automaticamente questi campi senza configurazione manuale.
4. Servono competenze di programmazione per usare un’estensione Chrome Amazon Scraper?
No — tutti e sette gli strumenti testati sono pensati per utenti non tecnici. Alcuni richiedono più configurazione (Web Scraper, Octoparse, Axiom.ai), mentre altri sono quasi senza setup (Thunderbit, Instant Data Scraper). Il compromesso è di solito tra flessibilità e facilità d’uso.
5. Quale estensione Chrome Amazon Scraper ha il piano gratuito migliore?
Il piano gratuito di Thunderbit include il rilevamento dei campi con AI e tutti i formati di esportazione (Sheets, Airtable, Notion, Excel, CSV, JSON), che la maggior parte dei concorrenti blocca dietro i piani a pagamento. Instant Data Scraper è completamente gratuito ma non ha AI, sottopagine né pianificazione. Data Miner offre 500 pagine gratuite al mese. Il piano gratuito di Helium 10 è limitato e orientato alla ricerca per venditori, non allo scraping generico.
Scopri di più




