क्या वेब स्क्रैपिंग अवैध है? यही वह करोड़ों का सवाल है जो मुझे हर हफ्ते संस्थापकों, मार्केटर्स और डेटा-प्रेमियों से सुनने को मिलता है।
आज —पहली बार जब स्वचालित ट्रैफ़िक ने मानव गतिविधि को पीछे छोड़ा है—और इसका बड़ा हिस्सा बिज़नेस इंटेलिजेंस, सेल्स और एआई प्रशिक्षण के लिए वेब स्क्रैपिंग है। ऐसे में यह समझना मुश्किल नहीं कि हर कोई कानूनी सीमाएँ कहाँ खींची जाती हैं, यह जानने की कोशिश क्यों कर रहा है।
एक दिन आपको ऐसी हेडलाइन दिखती है कि अदालत ने सार्वजनिक डेटा को स्क्रैप करना वैध माना। अगले ही दिन नियामक सोशल मीडिया से "अवैध" डेटा इकट्ठा करने पर चेतावनी दे रहे होते हैं। यह उलझन भरा है, उन लोगों के लिए भी जो मेरे जैसे Thunderbit में बनाने में दिन बिताते हैं।
तो, क्या वेब स्क्रैपिंग अवैध है? जवाब सीधा हाँ या नहीं नहीं है। यह इस पर निर्भर करता है कि आप क्या स्क्रैप कर रहे हैं, कहाँ से कर रहे हैं, डेटा का उपयोग कैसे करते हैं, और आपके देश का कानून क्या कहता है।
इस गहन विश्लेषण में, मैं कानूनी परिदृश्य को तोड़कर समझाऊँगा, कुछ आम भ्रांतियाँ दूर करूँगा, और अनुपालन बनाए रखने के व्यावहारिक सुझाव साझा करूँगा—चाहे आप एकल संस्थापक हों या Fortune 500 की डेटा टीम।
वेब स्क्रैपिंग और कानून: क्या कोई स्पष्ट सीमा है?
अगर आप एक ही वाक्य में जवाब चाहते हैं, तो मैं आपका समय बचा देता हूँ: कानून ने वेब स्क्रैपिंग पर कोई साफ़, स्पष्ट रेखा नहीं खींची है।
इसके बजाय, नियमों का एक मिश्रित जाल है—डेटा स्वामित्व, गोपनीयता, बौद्धिक संपदा, एंटी-हैकिंग कानून, और बदनाम Terms of Service (ToS)। इनमें से हर एक लागू हो सकता है, और जवाब अक्सर आपकी विशिष्ट परिस्थिति पर निर्भर करता है ().
आइए तीन बड़े कानूनी खांचों को समझें:
- डेटा स्वामित्व: सामान्यतः तथ्य और सार्वजनिक जानकारी (जैसे कीमतें या फ़ोन नंबर) कॉपीराइट के दायरे में नहीं आते। लेकिन रचनात्मक सामग्री (लेख, चित्र) और स्वामित्व वाले डेटाबेस संरक्षित हो सकते हैं—खासकर यूरोपीय संघ में, जहाँ "डेटाबेस अधिकार" एक वास्तविक चीज़ है ().
- गोपनीयता: आधुनिक प्राइवेसी कानून (जैसे यूरोप में GDPR, चीन में PIPL) व्यक्तिगत डेटा को एक विनियमित संपत्ति मानते हैं—भले ही वह सार्वजनिक रूप से पोस्ट किया गया हो। नाम, ईमेल या सोशल प्रोफ़ाइल को वैध आधार के बिना स्क्रैप करना आपको कानूनी मुसीबत में डाल सकता है ().
- अनुबंध (Terms of Service): कई साइटें अपनी ToS में साफ़ तौर पर स्क्रैपिंग पर रोक लगाती हैं। ToS कानून नहीं होते, लेकिन अदालतें इन्हें बाध्यकारी अनुबंध मान सकती हैं। इन्हें तोड़ने पर मुकदमे हो सकते हैं, और कुछ मामलों में, अगर आप तकनीकी अवरोधों को पार करते हैं, तो एंटी-हैकिंग कानून भी लागू हो सकते हैं ().
तो, क्या वेब स्क्रैपिंग अवैध है? कभी हाँ, कभी नहीं, और अक्सर जवाब होता है: "परिस्थिति पर निर्भर करता है।" असली खेल बारीकियों में है।
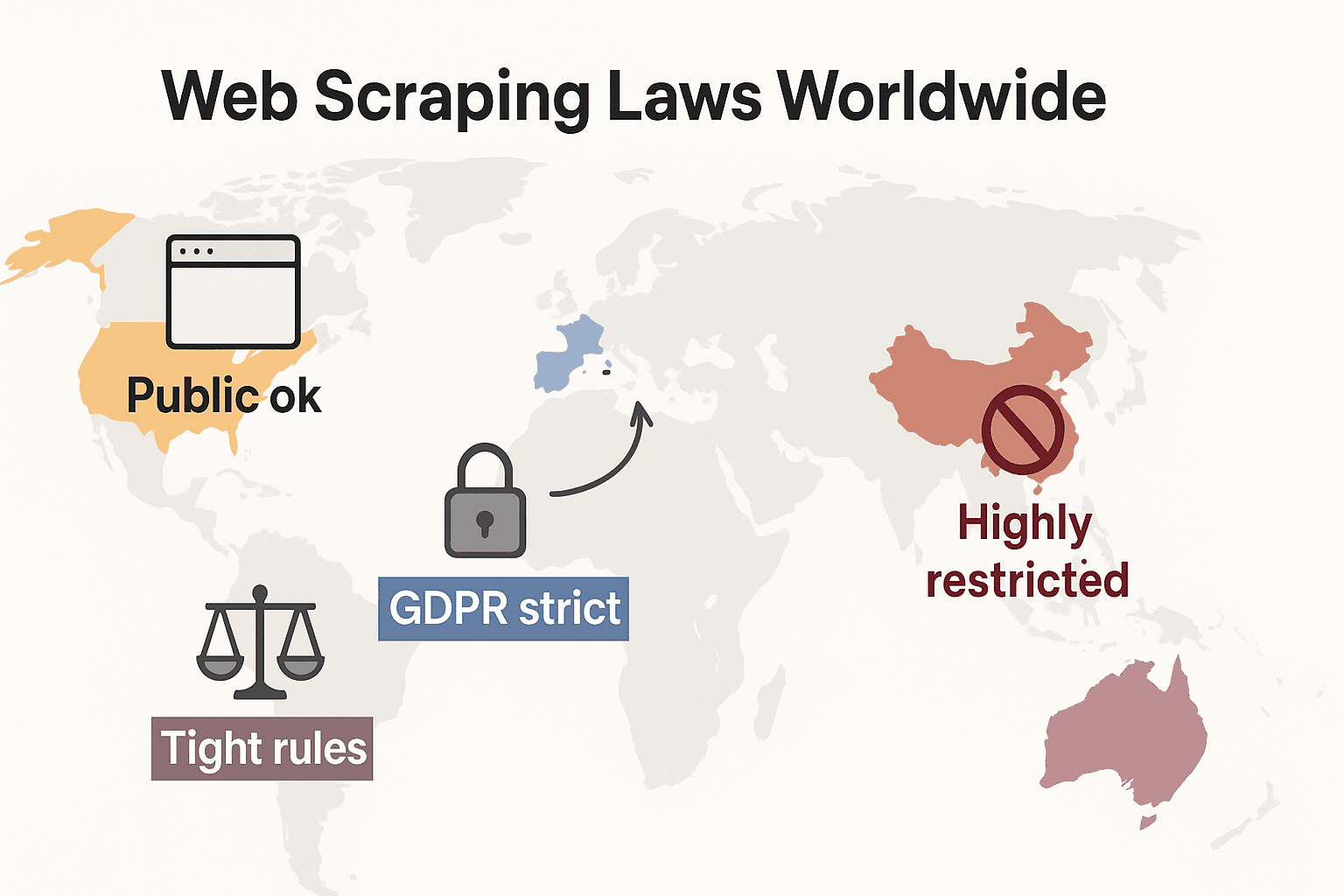
कानूनी दृष्टिकोणों की तुलना: अमेरिका, यूरोपीय संघ, यूके, चीन
यहाँ एक त्वरित तालिका है, जो दिखाती है कि प्रमुख क्षेत्र वेब स्क्रैपिंग को कैसे देखते हैं:
| क्षेत्र | सार्वजनिक डेटा की स्क्रैपिंग | व्यक्तिगत/निजी डेटा की स्क्रैपिंग | प्रवर्तन और महत्वपूर्ण बिंदु |
|---|---|---|---|
| अमेरिका | सामान्यतः सार्वजनिक डेटा के लिए अनुमति है (देखें hiQ v. LinkedIn). ToS तोड़ने पर सिविल मुकदमे हो सकते हैं। | अगर आप लॉगिन बायपास करते हैं या व्यक्तिगत डेटा का दुरुपयोग करते हैं, तो प्रतिबंधित/अवैध। राज्य कानून (जैसे CCPA) लागू हो सकते हैं। | सीज़-एंड-डिसिस्ट पत्र, IP ब्लॉकिंग, मुकदमे। तकनीकी बाधाएँ पार करने पर CFAA लागू होता है। |
| EU | गैर-व्यक्तिगत, सार्वजनिक डेटा के लिए शर्तों के साथ अनुमति। डेटाबेस अधिकार लागू हो सकते हैं। EU AI Act (2026) AI प्रशिक्षण डेटा के लिए पारदर्शिता की माँग जोड़ता है। | GDPR के तहत कड़ी निगरानी—सार्वजनिक व्यक्तिगत डेटा के लिए भी वैध आधार चाहिए। | डेटा संरक्षण प्राधिकरण गोपनीयता उल्लंघन पर जुर्माना लगा सकते हैं। कॉपीराइट/डेटाबेस अधिकार भी लागू किए जाते हैं। EU AI Act AI के लिए चेहरे की छवि स्क्रैपिंग पर प्रतिबंध लगाता है। |
| यूके | EU जैसा। सार्वजनिक, गैर-व्यक्तिगत डेटा स्क्रैप किया जा सकता है, लेकिन डेटा अधिकारों और अनुबंधों का सम्मान ज़रूरी है। | व्यक्तिगत डेटा पर सख्ती—UK GDPR लागू होता है। Computer Misuse Act अनधिकृत पहुँच को अपराध मानता है। | ICO डेटा संरक्षण उल्लंघनों पर दंड दे सकता है। अदालतें ToS लागू कर सकती हैं। |
| चीन | कड़ी निगरानी। सार्वजनिक, गैर-व्यक्तिगत डेटा को आंतरिक उपयोग के लिए स्क्रैप किया जा सकता है, लेकिन माहौल सतर्क है। | बहुत सख्त—PIPL व्यक्तिगत डेटा के लिए सहमति की माँग करता है। अनुचित प्रतिस्पर्धा के कानून लागू होते हैं। | बड़े पैमाने की स्क्रैपिंग पर आपराधिक मामले। अदालतें अनधिकृत स्क्रैपिंग रोकने के लिए अनुचित प्रतिस्पर्धा कानून का उपयोग करती हैं। |
(, )
क्या वेब स्क्रैपिंग अवैध है? ध्यान देने योग्य मुख्य कानूनी कारक
तो वास्तव में क्या तय करता है कि आपका स्क्रैपिंग प्रोजेक्ट वैध है या जोखिम भरा? यहाँ मुख्य कारक हैं:
- सार्वजनिक बनाम निजी डेटा: ओपन वेब पर जो डेटा कोई भी देख सकता है, उसे स्क्रैप करना आम तौर पर सुरक्षित होता है। लेकिन जो कुछ लॉगिन, पेवॉल या तकनीकी बाधा के पीछे है, उसे स्क्रैप करना? वह संभवतः अवैध है ().
- डेटा का स्वरूप: व्यक्तिगत डेटा (नाम, ईमेल, प्रोफ़ाइल) गोपनीयता कानूनों को सक्रिय करता है। कॉपीराइट वाली सामग्री (लेख, चित्र) को पूरी तरह कॉपी नहीं किया जा सकता। शुद्ध तथ्य (कीमतें, मौसम) आम तौर पर खुले उपयोग में माने जाते हैं ().
- उपयोग का उद्देश्य: आंतरिक विश्लेषण या शोध की तुलना में स्क्रैप किए गए डेटा को दोबारा प्रकाशित करना या बेचना अधिक संवेदनशील माना जाता है। अगर आप स्क्रैप डेटा का उपयोग सीधे स्रोत से प्रतिस्पर्धा करने के लिए कर रहे हैं, तो मुकदमा लगभग तय समझिए ().
- वेबसाइट नियमों का पालन: हमेशा robots.txt और ToS जाँचें। robots.txt कानूनी रूप से बाध्यकारी नहीं है, लेकिन उसका सम्मान करना अच्छी प्रथा है। ToS उल्लंघन से सिविल मुकदमे या उससे भी बुरा हो सकता है ().
- तकनीकी उपाय: मानव जैसी गति से स्क्रैप करना और सुरक्षा उपायों को बायपास न करना बेहद अहम है। सर्वर पर ज़रूरत से ज़्यादा अनुरोध भेजना या CAPTCHAs को चकमा देना, हैकिंग की सीमा तक जा सकता है ().
2024–2026 में क्या बदला: अहम अदालत के फैसले और नियम
2023 के बाद से वेब स्क्रैपिंग का कानूनी परिदृश्य काफी बदल गया है। हर स्क्रैपर को ये विकास जानने चाहिए:
प्रमुख अदालत के फैसले
-
Meta v. Bright Data (2024): एक अमेरिकी संघीय अदालत ने . न्यायाधीश ने माना कि "जब तक किसी के पास खाता नहीं है, उसे 'user' नहीं माना जाएगा।" कुछ ही समय बाद Meta ने शेष दावे वापस ले लिए। यह सार्वजनिक डेटा स्क्रैपिंग के लिए एक ऐतिहासिक जीत है।
-
X Corp v. Bright Data (2024): Twitter (अब X) भी इसी तरह का मुकदमा हार गया, जिससे यही सिद्धांत और मज़बूत हुआ: बिना लॉगिन किए सार्वजनिक रूप से उपलब्ध डेटा की स्क्रैपिंग ToS उल्लंघन नहीं है, क्योंकि स्क्रैपर ने उन शर्तों को कभी स्वीकार ही नहीं किया।
-
Reddit v. Perplexity AI (अक्तूबर 2025): Reddit ने , DMCA का हवाला देते हुए और एंटी-बॉट सिस्टम को दरकिनार करने का आरोप लगाते हुए। यह एक नई कानूनी रणनीति का संकेत है: प्लेटफ़ॉर्म अब CFAA की बजाय कॉपीराइट और anti-circumvention दावों का सहारा ले रहे हैं।
-
NYT v. OpenAI (मार्च 2025): एक संघीय न्यायाधीश ने , OpenAI की dismissal याचिका खारिज करते हुए। यह इस प्रश्न पर एक बड़ा precedent बन सकता है कि AI मॉडल प्रशिक्षण के लिए सामग्री की स्क्रैपिंग "fair use" मानी जाएगी या नहीं।
-
Anthropic समझौता (सितंबर 2025): Anthropic ने अपने AI मॉडल को प्रशिक्षित करने के लिए कॉपीराइटेड टेक्स्ट के उपयोग से जुड़ी अमेरिकी कॉपीराइट class action के निपटारे के लिए $1.5 billion देने पर सहमति जताई—यह संकेत है कि AI के लिए स्क्रैपिंग की लागत बहुत वास्तविक है।
बड़ा रुझान: CFAA से अनुबंध और कॉपीराइट कानून की ओर
रुझान साफ़ है: सार्वजनिक डेटा स्क्रैपर्स के खिलाफ हथियार के रूप में CFAA (Computer Fraud and Abuse Act) की ताकत घट रही है। Meta, X, LinkedIn जैसी कंपनियाँ सार्वजनिक डेटा स्क्रैपिंग के खिलाफ CFAA का उपयोग करना चाहती थीं, लेकिन अधिकांश मामलों में असफल रहीं। इसके बजाय, कानूनी मोर्चा अब इन दिशाओं में जा रहा है:
- अनुबंध कानून (ToS उल्लंघन—लेकिन अदालतें कह रही हैं कि गैर-उपयोगकर्ता ToS से बंधे नहीं हैं)
- कॉपीराइट दावे (खासकर AI प्रशिक्षण डेटा के लिए)
- Anti-circumvention कानून (DMCA धारा 1201)
स्क्रैपर्स के लिए इसका मतलब है कि कानूनी जोखिम खत्म नहीं हुआ है—बस उसने जगह बदल ली है।
नियामकीय परिवर्तन
- CCPA 2026 अपडेट: कैलिफ़ोर्निया के संशोधित CCPA नियम , जिनमें स्वचालित निर्णय लेने वाली तकनीक (ADMT), जोखिम आकलन, और डेटा ब्रोकर दायित्वों के नए नियम जोड़े गए।
- नए अमेरिकी राज्य गोपनीयता कानून: Indiana, Kentucky, और Rhode Island ने 2026 में व्यापक प्राइवेसी कानून लागू किए।
- EU AI Act: पूरी तरह लागू होना से शुरू होगा—जिसमें AI डेवलपर्स को प्रशिक्षण डेटा स्रोत बताने, copyright opt-outs का सम्मान करने, और चेहरे की छवि स्क्रैपिंग पर रोक की आवश्यकता होगी।
- AI Accountability for Publishers Act (फ़रवरी 2026): एक प्रस्तावित अमेरिकी कानून, जो AI कंपनियों को उनकी सामग्री स्क्रैप करने से पहले अनुमति लेने और भुगतान करने के लिए बाध्य करेगा।
प्रमुख प्लेटफ़ॉर्म की स्क्रैपिंग नीतियाँ: आपको क्या जानना चाहिए
हर वेबसाइट स्क्रैपिंग को एक जैसा नहीं देखती। यहाँ प्लेटफ़ॉर्म के हिसाब से विवरण है कि कौन-सी बड़ी साइटें क्या अनुमति देती हैं, क्या ब्लॉक करती हैं, और अदालतें क्या कह चुकी हैं:
| प्लेटफ़ॉर्म | ToS में स्क्रैपिंग | तकनीकी सुरक्षा | कानूनी प्रवर्तन | व्यावहारिक रूप से क्या सुरक्षित है |
|---|---|---|---|---|
| Google (Search & Maps) | ToS में स्वचालित पहुँच पर रोक। Maps Platform में स्पष्ट "No Scraping" क्लॉज है। | SearchGuard JS चुनौतियाँ, CAPTCHAs, rate limiting। 2025 में robots.txt अपडेट कर AI crawlers को ब्लॉक किया। | दिसंबर 2025 में DMCA का उपयोग करके स्क्रैपर्स पर मुकदमा। AI crawlers (Anthropic, Meta, OpenAI) को सक्रिय रूप से ब्लॉक करता है। | सार्वजनिक Google Maps business data को स्क्रैप करना कानूनी रूप से बचाव योग्य है (hiQ precedent), लेकिन तकनीकी ब्लॉक की उम्मीद रखें। संभव हो तो आधिकारिक APIs का उपयोग करें। |
| Amazon | Conditions of Use में सभी स्क्रैपिंग पर स्पष्ट प्रतिबंध ("कोई robot, spider, scraper, या अन्य स्वचालित साधन नहीं"). | आक्रामक bot detection, CAPTCHA, IP blocking। robots.txt Googlebot/Bingbot को छोड़कर सभी bots को ब्लॉक करता है। 2025 से AI crawlers को स्पष्ट रूप से ब्लॉक किया। | नवंबर 2025 में Perplexity AI पर मुकदमा किया। नियमित रूप से सीज़-एंड-डिसिस्ट पत्र भेजता है। मार्च 2026 में AI agent नियमों के साथ BSA अपडेट किया। | सार्वजनिक प्रोडक्ट डेटा (कीमतें, listings) तथ्यात्मक है और अमेरिकी कानून के तहत स्क्रैप किया जा सकता है, लेकिन Amazon कड़ी प्रतिक्रिया देता है। अनुरोधों की गति कम रखें और व्यक्तिगत डेटा से बचें। |
| ToS में स्क्रैपिंग निषिद्ध; सेवाओं तक पहुँच के लिए उपयोगकर्ता सहमति आवश्यक। | अधिकांश प्रोफ़ाइल डेटा के लिए login wall, anti-bot detection, rate limiting। | hiQ मामले ने पुष्टि की कि सार्वजनिक प्रोफ़ाइल स्क्रैपिंग CFAA उल्लंघन नहीं है, लेकिन नकली खातों के उपयोग पर contract/unfair competition दावों में LinkedIn जीता। | बिना लॉगिन दिखने वाली सार्वजनिक प्रोफ़ाइलों को स्क्रैप करना कानूनी रूप से बचाव योग्य है। कभी भी नकली खाते न बनाएँ और लॉगिन किए हुए डेटा को स्क्रैप न करें। | |
| Meta (Facebook & Instagram) | ToS स्क्रैपिंग पर रोक; लॉगिन किए हुए बनाम लॉगआउट डेटा के लिए अलग नियम। | अधिकांश सामग्री के लिए login wall, उन्नत bot detection। | 2024 में Bright Data से हार गया—अदालत ने कहा ToS गैर-लॉगिन स्क्रैपर्स पर लागू नहीं होते। शेष दावे वापस ले लिए। | बिना लॉगिन दिखाई देने वाला सार्वजनिक डेटा (business pages, public posts) अपेक्षाकृत सुरक्षित है। निजी प्रोफ़ाइल या login के पीछे का डेटा कभी न स्क्रैप करें। |
| X (Twitter) | 2023 में ToS अपडेट कर लिखित सहमति के बिना सभी स्क्रैपिंग और crawling पर रोक। पुराने robots.txt अपवाद को हटा दिया। | robots.txt सभी crawlers को ब्लॉक करता है (Disallow: /)। Cloudflare Turnstile चुनौतियाँ। सख्त rate limits (300 req/hr)। IP reputation scoring। | सार्वजनिक डेटा पर Bright Data से हार गया, लेकिन तकनीकी पहुँच पर कड़े प्रतिबंध लगाता है। | सार्वजनिक tweets और profiles कानूनी रूप से बचाव योग्य हैं, लेकिन 2026 में X की तकनीकी बाधाएँ सबसे कठिन में से हैं। प्रीमियम proxy infrastructure के बिना ब्लॉक मिलने की उम्मीद रखें। |
निचोड़: अदालतों ने लगातार यह माना है कि बिना लॉगिन किए सार्वजनिक रूप से दिखाई देने वाले डेटा की स्क्रैपिंग CFAA का उल्लंघन नहीं करती। लेकिन प्लेटफ़ॉर्म फिर भी अनुबंध कानून, कॉपीराइट, या anti-circumvention आधारों पर आपके खिलाफ जा सकते हैं—और तकनीकी बाधाओं से आपकी मुश्किलें बढ़ा सकते हैं। हमेशा ज़िम्मेदारी से स्क्रैप करें।
AI प्रशिक्षण डेटा और वेब स्क्रैपिंग: नया कानूनी मोर्चा
अगर आप 2026 की खबरों पर नज़र रख रहे हैं, तो जानते होंगे कि AI मॉडल को प्रशिक्षित करने के लिए डेटा स्क्रैप करना सबसे गरम कानूनी मोर्चा बन गया है। यहाँ क्या हो रहा है:
- कॉपीराइट मुकदमे बढ़ रहे हैं। New York Times, लेखक, और प्रकाशकों ने OpenAI, Anthropic और अन्य पर मुकदमा दायर किया है, यह आरोप लगाते हुए कि LLMs को प्रशिक्षित करने के लिए कॉपीराइटेड सामग्री की बड़े पैमाने पर स्क्रैपिंग "fair use" नहीं है। Anthropic ने 2025 में $1.5 billion के एक बड़े class action का निपटारा किया—यह संकेत कि AI के लिए स्क्रैपिंग की लागत बहुत वास्तविक है।
- "fair use" रक्षा कमजोर है। अमेरिकी अदालतों ने अभी तक यह स्पष्ट निर्णय नहीं दिया है कि स्क्रैप किए गए डेटा पर AI प्रशिक्षण fair use है या नहीं। शुरुआती फैसले बताते हैं कि यह काफी हद तक इस बात पर निर्भर करता है कि डेटा कैसे हासिल किया गया और AI आउटपुट के साथ क्या किया गया।
- नया कानून आने वाला है। (फ़रवरी 2026 में पेश किया गया) का उद्देश्य AI कंपनियों को उनकी सामग्री स्क्रैप करने से पहले अनुमति लेने और भुगतान करने के लिए बाध्य करना है।
- EU AI Act (पूर्ण प्रवर्तन ) AI डेवलपर्स से प्रशिक्षण डेटा स्रोत उजागर करने, मशीन-पठनीय copyright opt-outs (Copyright Directive के TDM अपवाद के तहत) का सम्मान करने, और AI-जनित सामग्री को लेबल करने की माँग करता है। यह इंटरनेट से चेहरे की छवियाँ स्क्रैप करने वाले AI सिस्टम्स पर भी रोक लगाता है।
- AI/LLM crawlers तेज़ी से बढ़ रहे हैं। AI crawlers ने सिर्फ़ आठ महीनों में वेब ट्रैफ़िक में अपनी हिस्सेदारी 2.6% से बढ़ाकर 10.1% कर ली। अकेले OpenAI का GPTBot 305% बढ़ा। जवाब में, बड़े साइट्स (Amazon, Reddit, NYT) robots.txt अपडेट कर AI crawlers को स्पष्ट रूप से ब्लॉक कर रहे हैं।
आपके लिए इसका मतलब: अगर आप पारंपरिक व्यावसायिक उद्देश्यों (लीड जेनरेशन, कीमत निगरानी, बाज़ार शोध) के लिए डेटा स्क्रैप कर रहे हैं, तो ये AI-विशिष्ट नियम सीधे लागू न भी हों। लेकिन अगर आप स्क्रैप डेटा को AI मॉडल में फ़ीड कर रहे हैं, तो बहुत सावधानी बरतें—और कानूनी सलाह लें।
दुनिया भर में वेब स्क्रैपिंग कानून: एक त्वरित तुलना
चलिए व्यापक रूप से देखते हैं कि दुनिया भर में नियम कैसे बनते हैं:
- संयुक्त राज्य: कोई पूर्ण प्रतिबंध नहीं। सार्वजनिक-facing साइट्स को स्क्रैप करना आम तौर पर वैध है (), और 2024 के Meta तथा X Corp फैसलों ने सार्वजनिक डेटा स्क्रैपिंग के पक्ष को और मज़बूत किया है। लेकिन लॉगिन के पीछे या तकनीकी ब्लॉकों को तोड़कर स्क्रैप करना अब भी CFAA को सक्रिय कर सकता है। रुझान अब कंपनियों के अनुबंध कानून और कॉपीराइट दावों की ओर मुड़ने का है। प्राइवेसी कानून तेज़ी से बढ़ रहे हैं: CCPA में 1 जनवरी 2026 से प्रभावी बड़े अपडेट हुए, जिनमें automated decision-making और data broker दायित्वों के नए नियम शामिल हैं। Indiana, Kentucky, और Rhode Island ने भी 2026 में व्यापक गोपनीयता कानून लागू किए।
- यूरोपीय संघ: कड़े प्राइवेसी कानून। GDPR सार्वजनिक व्यक्तिगत डेटा पर भी लागू होता है। Database rights संरचित डेटा की बड़े पैमाने पर स्क्रैपिंग को रोक सकते हैं (). नया: 2 अगस्त 2026 को पूरी तरह लागू होता है, जिसमें AI डेवलपर्स को प्रशिक्षण डेटा स्रोत उजागर करने और copyright opt-outs का सम्मान करने की आवश्यकता होगी। यह कानून AI सिस्टम्स के लिए इंटरनेट से चेहरे की छवियाँ स्क्रैप करने पर रोक लगाता है।
- यूनाइटेड किंगडम: Brexit के बाद EU नियमों जैसा। सार्वजनिक डेटा स्क्रैप किया जा सकता है, लेकिन व्यक्तिगत जानकारी की स्क्रैपिंग पर कड़ी निगरानी है। Computer Misuse Act अनधिकृत पहुँच को आपराधिक बना सकता है।
- चीन: बहुत सख्त। PIPL और Data Security Law व्यक्तिगत डेटा के लिए सहमति माँगते हैं। अदालतें व्यवसायों को नुकसान पहुँचाने वाली स्क्रैपिंग रोकने के लिए अनुचित प्रतिस्पर्धा कानून का उपयोग करती हैं ().
निष्कर्ष: आंतरिक उपयोग के लिए सार्वजनिक, गैर-व्यक्तिगत डेटा की स्क्रैपिंग आम तौर पर सबसे सुरक्षित है। बाकी सब? स्थानीय कानून जाँचें और सावधानी बरतें।
वेब स्क्रैपिंग की वैधता से जुड़े आम मिथक
आइए कुछ ऐसी भ्रांतियाँ दूर करें जो मैं अक्सर सुनता हूँ:
- मिथक 1: "वेब स्क्रैपिंग पूरी तरह अवैध है।"
गलत। ऐसा कोई कानून नहीं है जो हर तरह की वेब स्क्रैपिंग पर रोक लगाता हो। असल मायने इस बात के हैं कि आप क्या स्क्रैप करते हैं और कैसे करते हैं (). - मिथक 2: "अगर डेटा सार्वजनिक है, तो मैं उसके साथ जो चाहूँ कर सकता हूँ।"
इतना सरल नहीं। सार्वजनिक डेटा पर भी गोपनीयता या कॉपीराइट कानून लागू हो सकते हैं, और ToS कुछ उपयोगों को सीमित कर सकते हैं (). - मिथक 3: "वेब स्क्रैपिंग और हैकिंग एक ही चीज़ हैं।"
नहीं। सार्वजनिक वेब पेज स्क्रैप करना हैकिंग नहीं है। लॉगिन या तकनीकी बाधाओं को बायपास करना अलग मामला है (). - मिथक 4: "अगर पकड़ में नहीं आए, तो सब ठीक है।"
यह जोखिम भरी सोच है। कई साइटों में anti-bot तकनीक होती है और वे ध्यान देती हैं। चुप्पी सहमति नहीं होती। - मिथक 5: "क्रेडिट देना या डेटा का आंतरिक उपयोग करना इसे ठीक बना देता है।"
attribution, कॉपीराइट या गोपनीयता कानून को रद्द नहीं कर देता। आंतरिक उपयोग सुरक्षित है, लेकिन यह खुली छूट नहीं है। - मिथक 6: "सभी वेब स्क्रैपिंग गोपनीयता का उल्लंघन करती है।"
हर स्क्रैपिंग में व्यक्तिगत डेटा शामिल नहीं होता। लेकिन पर्याप्त सुरक्षा के बिना भारी मात्रा में व्यक्तिगत जानकारी स्क्रैप करना लगभग हमेशा अवैध होता है (). - मिथक 7: "अगर वेबसाइट की ToS स्क्रैपिंग पर रोक लगाती है, तो स्क्रैप करना हमेशा अवैध है।"
ज़रूरी नहीं। 2024 में Meta v. Bright Data और X Corp v. Bright Data में अदालतों ने माना कि ToS उन उपयोगकर्ताओं पर बाध्यकारी नहीं हो सकतीं, जिन्होंने उन्हें कभी स्वीकार ही नहीं किया—यानी अगर आप बिना लॉगिन या खाता बनाए स्क्रैप कर रहे हैं, तो साइट की ToS आप पर लागू न भी हो। यह क्षेत्र अभी विकसित हो रहा है, लेकिन यह एक बड़ा बदलाव है।
कानूनी तरीके से डेटा स्क्रैप कैसे करें: अनुपालन के सर्वोत्तम अभ्यास
कानूनी और नैतिक वेब स्क्रैपिंग के लिए मेरी भरोसेमंद चेकलिस्ट:
- साइट की Terms of Service पढ़ें और उनका सम्मान करें। अगर वे "no scraping" कहते हैं, तो रुकने या अनुमति माँगने पर विचार करें ().
- सिर्फ सार्वजनिक डेटा तक सीमित रहें। अगर पासवर्ड चाहिए, तो वह प्रतिबंधित है—उसे स्क्रैप न करें ().
- robots.txt देखें और शिष्टता से crawl करें। कानूनी रूप से बाध्यकारी नहीं, लेकिन अच्छा व्यवहार है। सर्वरों पर ज़ोर न डालें—अपने अनुरोधों के बीच अंतर रखें ().
- जब तक वैध आधार न हो, व्यक्तिगत डेटा से बचें। अगर इसे इकट्ठा करना ही पड़े, तो GDPR/CCPA का पालन करें और जितना संभव हो उतना कम डेटा लें।
- स्क्रैप की गई सामग्री को पूरी तरह दोबारा प्रकाशित न करें। उसमें अपना मूल्य जोड़ें या विश्लेषण करें, या अनुमति लें ().
- कॉपीराइट जाँचे बिना स्क्रैप सामग्री को AI मॉडल में न डालें। कानूनी परिदृश्य तेज़ी से बदल रहा है—अगर यही आपका उपयोग-मामला है, तो सलाह लें।
- जहाँ उपलब्ध हों, आधिकारिक APIs या डेटा एक्सपोर्ट का उपयोग करें। इन्हें इसी उद्देश्य से बनाया गया है और ये आम तौर पर अधिक सुरक्षित होते हैं ().
- पारदर्शी और जवाबदेह रहें। अगर आप व्यक्तिगत डेटा इकट्ठा करते हैं, तो लोगों को सूचित करें और अपनी गतिविधियों का रिकॉर्ड रखें।
- डेटा को न्यूनतम रखें और सुरक्षित रखें। केवल वही लें जिसकी आपको ज़रूरत है, उसे सही रखें, और सुरक्षित संग्रहीत करें।
- अपडेट रहें और सीमांत मामलों में कानूनी सलाह लें। कानून और अदालत के फैसले तेज़ी से बदल रहे हैं—खासकर EU AI Act और अमेरिकी राज्य गोपनीयता कानून। संदेह हो तो विशेषज्ञ से पूछें।
वेब स्क्रैपिंग टूल्स का कानूनी उपयोग: व्यवसायों को क्या जानना चाहिए
जैसे वेब स्क्रैपिंग टूल्स डेटा इकट्ठा करना गैर-कोडर्स के लिए आसान बनाते हैं, लेकिन आपको इनका उपयोग फिर भी जिम्मेदारी से करना होगा:
- अनुपालन-केंद्रित टूल्स चुनें। उदाहरण के लिए, Thunderbit केवल वही स्क्रैप करता है जो आप अपने ब्राउज़र में देख सकते हैं—कोई छिपी हुई API हैकिंग या अनधिकृत पहुँच नहीं ().
- वैध उपयोग-मामलों तक सीमित रहें। आंतरिक विश्लेषण, बाज़ार शोध, और प्रतिस्पर्धी मूल्य निगरानी आम तौर पर सुरक्षित हैं। स्क्रैप डेटा को दोबारा प्रकाशित करना या बेचना? कहीं अधिक जोखिम भरा।
- उपकरणों को अनुपालन के लिए कॉन्फ़िगर करें। crawl delay सेट करें, robots.txt का पालन करें, और ऐसे टेम्पलेट्स इस्तेमाल करें जो सिर्फ़ ज़रूरी डेटा लें।
- इसे अंदर ही रखें। स्क्रैप डेटा का आंतरिक उपयोग, उसे दोबारा प्रकाशित करने से अधिक सुरक्षित है।
- अपनी टीम को शिक्षित करें। सुनिश्चित करें कि हर कोई नियम और सर्वोत्तम अभ्यास समझता हो।
- अंतर्निहित अनुपालन सुविधाओं का लाभ लें। Thunderbit जोखिम भरी साइटों के बारे में चेतावनी देता है, मानव जैसी गति से स्क्रैप करता है, और आपका डेटा अपने सर्वरों पर स्टोर नहीं करता।
- ज़बरदस्ती न करें। अगर कोई टूल किसी साइट को स्क्रैप नहीं कर सकता, तो उसे किसी हैक से पार करने की कोशिश न करें। हर डेटा बिना जोखिम के उपलब्ध नहीं होता।
Thunderbit का तरीका: अनुपालक AI वेब स्क्रैपिंग को सक्षम करना
में, हमने अनुपालन पर बहुत समय सोचा है। हमारा AI Web Scraper उपयोगकर्ताओं को कानून की सही सीमा में रहने में इस तरह मदद करता है:
- सिर्फ वही स्क्रैप करता है जो आप देख सकते हैं। Thunderbit आपके ब्राउज़र सत्र में काम करता है, इसलिए वह उस डेटा तक नहीं पहुँच सकता जिसे आप मैन्युअली कॉपी न कर सकें।
- चेतावनियों के साथ मार्गदर्शन करता है। अगर आप कड़ी स्क्रैपिंग नीतियों वाली साइट को स्क्रैप करने की कोशिश करते हैं, तो Thunderbit आपको सतर्क करेगा।
- मानव जैसी स्क्रैपिंग गति। चाहे आप लोकली स्क्रैप करें या क्लाउड में, Thunderbit सर्वरों पर अत्यधिक दबाव नहीं डालता।
- अनुकूलन योग्य डेटा चयन। हमारी AI प्रासंगिक कॉलम सुझाती है, जिससे आप सिर्फ़ ज़रूरी डेटा लेते हैं।
- सबपेज और पेजिनेशन संभालना। Thunderbit साइटों को एक वास्तविक उपयोगकर्ता की तरह नेविगेट करता है, उनकी संरचना का सम्मान करते हुए।
- गोपनीयता और सुरक्षा। आपका डेटा आपके पास ही रहता है—Thunderbit उसे स्टोर या पुनः उपयोग नहीं करता।
- अनुपालन-अनुकूल एक्सपोर्ट। सुरक्षित, आंतरिक उपयोग के लिए सीधे Google Sheets, Airtable, Notion या CSV में एक्सपोर्ट करें।
- शेड्यूलिंग और ऑटोमेशन। ज़िम्मेदार अंतराल पर बार-बार होने वाली स्क्रैपिंग सेट करें।
- बहुभाषी समर्थन। Thunderbit का UI 34 भाषाओं का समर्थन करता है, जिससे अनुपालन वैश्विक स्तर पर सुलभ हो जाता है।
- नियमित टेम्पलेट अपडेट। लोकप्रिय साइटों के लिए हमारे इंस्टेंट टेम्पलेट्स कानूनी और तकनीकी बदलावों के अनुसार अद्यतन रहते हैं।
अनुपालन को उत्पाद में ही शामिल करके, Thunderbit टीमों को उनकी ज़रूरत का डेटा जुटाने में मदद करता है—बिना कानूनी झंझटों के।
आगे बने रहें: वेब स्क्रैपिंग में कानूनी और तकनीकी बदलावों के अनुसार ढलना
वेब स्क्रैपिंग कोई सेट-इट-एंड-फॉरगेट-इट खेल नहीं है। कानून और वेबसाइट संरचनाएँ लगातार बदलती रहती हैं। आगे बने रहने का तरीका यह है:
- कानूनी विकास पर नज़र रखें। बदलाव की गति 2024–2026 में तेज़ हुई—टेक-कानून समाचार, नियामक अपडेट, और उद्योग ब्लॉग (जैसे ) फ़ॉलो करें। EU AI Act के प्रवर्तन (अगस्त 2026), नए अमेरिकी राज्य प्राइवेसी कानूनों, और चल रहे AI कॉपीराइट मामलों पर ध्यान रखें।
- तकनीकी बदलावों के अनुसार ढलें। साइटें अपना लेआउट और anti-bot सुरक्षा हमेशा अपडेट करती रहती हैं। प्रमुख प्लेटफ़ॉर्म (Amazon, X, Google) ने 2025–2026 में अपनी सुरक्षा काफी कड़ी कर दी। Thunderbit की AI और टेम्पलेट्स इन्हीं बदलावों के साथ स्वतः ढलने के लिए बनाए गए हैं।
- जहाँ उपलब्ध हों, आधिकारिक APIs अपनाएँ। अगर कोई साइट paid API मॉडल पर चली जाए, तो विश्वसनीयता और अनुपालन के लिए वहाँ शिफ्ट होने पर विचार करें।
- अपनी स्क्रैपिंग का नियमित ऑडिट करें। अपने स्रोतों का दस्तावेज़ बनाएँ, ToS या नीति परिवर्तनों की जाँच करें, और ज़रूरत के अनुसार अपनी रणनीति बदलें।
- Thunderbit के टेम्पलेट अपडेट का लाभ लें। हमारी टीम टेम्पलेट्स को अद्यतन रखती है, ताकि आपको breaking changes या नई अनुपालन आवश्यकताओं की चिंता न करनी पड़े।
- लचीले रहें। अगर कोई डेटा स्रोत बहुत जोखिम भरा हो जाए, तो किसी दूसरे स्रोत पर जाएँ या साझेदारी तलाशें।
सही टूल्स और सोच के साथ, आप अपनी डेटा पाइपलाइन को चालू रख सकते हैं—बिना कानूनी खतरों पर पैर रखे।
निष्कर्ष: वेब स्क्रैपिंग के कानूनी परिदृश्य में रास्ता बनाना
वेब स्क्रैपिंग स्वाभाविक रूप से अवैध नहीं है—यह व्यवसाय, शोध और नवाचार के लिए एक शक्तिशाली टूल है। लेकिन हर टूल की तरह इसके भी नियम हैं। मुख्य बात है यह समझना कि आप क्या स्क्रैप कर रहे हैं, कैसे स्क्रैप कर रहे हैं, और डेटा का क्या करेंगे। स्थानीय कानूनों का सम्मान करें, वेबसाइट नीतियों का पालन करें, और जैसे अनुपालन-केंद्रित टूल्स का उपयोग करें ताकि आपका काम नियमों के भीतर रहे।
2024–2026 के अदालत के फैसलों (Meta v. Bright Data, X Corp v. Bright Data) ने सार्वजनिक डेटा स्क्रैपिंग के पक्ष को मज़बूत किया है, लेकिन AI प्रशिक्षण डेटा, कॉपीराइट दावों, और EU AI Act को लेकर नए जोखिम उभर रहे हैं। प्लेटफ़ॉर्म-विशिष्ट नीतियाँ बहुत अलग-अलग हैं—Google, Amazon, LinkedIn, Meta और X सभी अपने नियम अलग तरह से लागू करते हैं—इसलिए स्क्रैपिंग से पहले परिदृश्य जान लें।
अगर कभी संदेह हो, तो कानूनी सलाह लें—खासकर बड़े या संवेदनशील प्रोजेक्ट्स के लिए। और याद रखें: कानूनी परिदृश्य लगातार बदल रहा है, इसलिए सूचित और चुस्त बने रहें।
वेब स्क्रैपिंग, अनुपालन और ऑटोमेशन के बारे में और जानना चाहते हैं? और गाइड्स के लिए देखें, या खुद आज़माएँ।
सामान्य प्रश्न
1. क्या वेब स्क्रैपिंग हर जगह अवैध है?
नहीं। वेब स्क्रैपिंग अपने-आप में अवैध नहीं है, लेकिन इसकी वैधता इस पर निर्भर करती है कि आप क्या स्क्रैप करते हैं, कैसे करते हैं, और आप कहाँ हैं। सार्वजनिक, गैर-व्यक्तिगत डेटा को आंतरिक उपयोग के लिए स्क्रैप करना अधिकांश क्षेत्रों में आम तौर पर अनुमति है, लेकिन व्यक्तिगत या कॉपीराइटेड डेटा की स्क्रैपिंग, या साइट की शर्तों का उल्लंघन, अवैध हो सकता है ().
2. अगर मैं robots.txt को अनदेखा करूँ, तो क्या स्क्रैपिंग अवैध हो जाएगी?
Robots.txt कानूनी रूप से बाध्यकारी नहीं है, लेकिन उसका सम्मान करना सर्वोत्तम अभ्यास है। इसे अनदेखा करने से अपने-आप मुकदमा नहीं हो जाता, लेकिन किसी विवाद में आप "bad actor" जैसे दिख सकते हैं ().
3. क्या मैं Google, Amazon, या LinkedIn को स्क्रैप कर सकता हूँ?
यह जटिल है। तीनों अपनी ToS में स्क्रैपिंग पर रोक लगाते हैं, लेकिन अदालतों ने कहा है कि ToS उन उपयोगकर्ताओं पर बाध्यकारी नहीं हो सकतीं जिन्होंने लॉगिन नहीं किया (देखें Meta v. Bright Data और X Corp v. Bright Data, दोनों 2024)। सार्वजनिक रूप से दिखाई देने वाला डेटा (प्रोडक्ट कीमतें, business listings, सार्वजनिक प्रोफ़ाइल) अमेरिका में सामान्यतः कानूनी रूप से बचाव योग्य है। हालांकि, हर प्लेटफ़ॉर्म अपने नियम अलग तरह से लागू करता है: Amazon कानूनी कार्रवाई में सबसे आक्रामक है (उसने नवंबर 2025 में Perplexity AI पर मुकदमा किया); LinkedIn तकनीकी बाधाओं और अनुबंध दावों पर निर्भर करता है; Google बढ़ती हुई मात्रा में DMCA-आधारित प्रवर्तन कर रहा है। हमेशा ज़िम्मेदारी से स्क्रैप करें और तकनीकी प्रतिकार की उम्मीद रखें।
4. क्या मैं Facebook या Instagram को स्क्रैप कर सकता हूँ?
Meta v. Bright Data (2024) के बाद, Facebook और Instagram से सार्वजनिक डेटा को बिना लॉगिन स्क्रैप करना कानूनी रूप से अधिक मज़बूत स्थिति में है। अदालत ने कहा कि Meta की ToS गैर-उपयोगकर्ताओं पर लागू नहीं होती। लेकिन कभी भी नकली खाते न बनाएँ या login walls के पीछे का डेटा स्क्रैप न करें—वहाँ सीमा पार होती है।
5. क्या मैं X (Twitter) को स्क्रैप कर सकता हूँ?
X ने 2023 में अपनी ToS अपडेट कर लिखित सहमति के बिना सभी स्क्रैपिंग पर रोक लगाई है और कड़ी तकनीकी सुरक्षा (Cloudflare Turnstile, 300 requests/hour की rate limit, IP reputation scoring) तैनात की है। हालांकि, Bright Data ने समान आधारों पर अदालत में जीत हासिल की—बिना खाते के स्क्रैप किया गया सार्वजनिक डेटा X की ToS से बंधा नहीं है। तकनीकी रूप से, 2026 में X सबसे कठिन प्लेटफ़ॉर्म्स में से एक है।
6. क्या AI मॉडल प्रशिक्षित करने के लिए डेटा स्क्रैप करना कानूनी है?
2026 में यह सबसे बड़ा खुला प्रश्न है। बड़े मुकदमे (NYT v. OpenAI, Anthropic का $1.5B समझौता) महत्वपूर्ण कानूनी जोखिम दिखाते हैं। EU AI Act प्रशिक्षण डेटा स्रोतों के प्रकटीकरण और कॉपीराइट opt-outs के सम्मान की माँग करता है। प्रस्तावित AI Accountability for Publishers Act अनुमति और भुगतान को अनिवार्य करेगा। अगर आप AI प्रशिक्षण के लिए स्क्रैप कर रहे हैं, तो आगे बढ़ने से पहले कानूनी सलाह लें।
7. Thunderbit जैसे वेब स्क्रैपिंग टूल्स का सबसे सुरक्षित उपयोग क्या है?
सार्वजनिक डेटा स्क्रैप करें, साइट की शर्तों का सम्मान करें, जब तक वैध आधार न हो व्यक्तिगत जानकारी से बचें, और डेटा का उपयोग आंतरिक रूप से करें। Thunderbit आपको केवल आपके ब्राउज़र में दिखाई देने वाली चीज़ों को स्क्रैप करके और जोखिम भरी साइटों के बारे में चेतावनी देकर अनुपालन में रहने में मदद करने के लिए बनाया गया है ().
8. क्या मैं व्यावसायिक उपयोग के लिए डेटा स्क्रैप कर सकता हूँ?
यह निर्भर करता है। स्क्रैप डेटा का आंतरिक विश्लेषण या शोध के लिए उपयोग सामान्यतः अधिक सुरक्षित है। स्क्रैप डेटा को दोबारा प्रकाशित करना या बेचना, खासकर अगर वह कॉपीराइटेड या व्यक्तिगत है, बहुत अधिक जोखिम भरा है और इसके लिए अनुमति या लाइसेंस की आवश्यकता हो सकती है।
9. वेब स्क्रैपिंग में कानूनी और तकनीकी बदलावों के साथ कैसे बने रहें?
टेक-कानून समाचार फ़ॉलो करें, अपने लक्ष्य साइटों पर ToS या नीति परिवर्तनों की निगरानी करें, और Thunderbit जैसे टूल्स का उपयोग करें जो अपने टेम्पलेट्स और अनुपालन सुविधाओं को नियमित रूप से अपडेट करते हैं। 2026 में जिन चीज़ों पर नज़र रखनी चाहिए: EU AI Act का प्रवर्तन (अगस्त), चल रहे AI कॉपीराइट मामले, और नए अमेरिकी राज्य प्राइवेसी कानून। संदेह हो तो किसी कानूनी विशेषज्ञ से सलाह लें।