

Is web scraping illegal? That's the million-dollar question I hear from founders, marketers, and data geeks every week.
With 51% of all internet traffic now coming from bots—the first time automated traffic has surpassed human activity—and a huge chunk of that being web scraping for business intelligence, sales, and AI training, it's no wonder everyone's trying to figure out where the legal lines are drawn.
One day, you'll see a headline about a court ruling that scraping public data is fair game. The next, regulators are warning about "unlawful" data harvesting from social media. It's confusing, even for folks like me who spend their days building AI web scraping tools at Thunderbit.
So, is web scraping illegal? The answer isn't a simple yes or no. It depends on what you're scraping, where you're scraping from, how you use the data, and what the law says in your country.
In this deep dive, I'll break down the legal landscape, bust some common myths, and share practical tips (plus a few war stories) for staying compliant—whether you're a solo founder or a Fortune 500 data team.
Web Scraping and the Law: Is There a Clear Line?
If you're hoping for a one-sentence answer, I'll save you some time: the law hasn't drawn a bright, clear line on web scraping.
Instead, it's a patchwork of overlapping rules—data ownership, privacy, intellectual property, anti-hacking laws, and those infamous Terms of Service (ToS). Each can come into play, and the answer often depends on your specific scenario (multilogin.com).
Let's break down the three big legal buckets:
- Data Ownership: Generally, facts and public info (like prices or phone numbers) aren't copyrightable. But creative content (articles, images) and proprietary databases can be protected—especially in the EU, where "database rights" are a thing (cliffordchance.com).
- Privacy: Modern privacy laws (think GDPR in Europe, PIPL in China) treat personal data as a regulated asset—even if it's posted publicly. Scraping names, emails, or social profiles without a lawful basis can get you in hot water (ico.org.uk).
- Contracts (Terms of Service): Many sites explicitly forbid scraping in their ToS. While ToS aren't laws, courts can treat them as binding contracts. Violating them can mean lawsuits, and in some cases, even trigger anti-hacking statutes if you bypass technical blocks (cliffordchance.com).
So, is web scraping illegal? Sometimes yes, sometimes no, and often "it depends." The devil's in the details.
Comparing Legal Perspectives: US, EU, UK, China
Here's a quick table to show how major regions approach web scraping:
| Region | Public Data Scraping | Personal/Private Data Scraping | Enforcement & Notable Points |
|---|---|---|---|
| US | Generally allowed for public data (see hiQ v. LinkedIn). Violating ToS can mean civil suits. | Restricted/illegal if you breach logins or misuse personal data. State laws (like CCPA) may apply. | Cease-and-desist letters, IP blocking, lawsuits. CFAA applies if you bypass technical barriers. |
| EU | Conditionally allowed for non-personal, public data. Database rights can apply. EU AI Act (2026) adds transparency requirements for AI training data. | Heavily regulated under GDPR—even public personal data needs a legal basis. | Data Protection Authorities can fine for privacy breaches. Copyright/database rights also enforced. EU AI Act bans facial image scraping for AI. |
| UK | Similar to EU. Public, non-personal data can be scraped, but must respect data rights and contracts. | Strict on personal data—UK GDPR applies. Computer Misuse Act criminalizes unauthorized access. | ICO can penalize for data protection violations. Courts may enforce ToS. |
| China | Tightly controlled. Public, non-personal data may be scraped for internal use, but environment is cautious. | Highly restricted—PIPL requires consent for personal data. Anti-unfair competition laws apply. | Criminal cases for large-scale scraping. Courts use unfair competition law to stop unauthorized scraping. |
Is Web Scraping Illegal? Key Legal Factors to Consider
So, what actually determines if your scraping project is legal or risky? Here are the big factors:
- Public vs. Private Data: Scraping data anyone can see on the open web is generally safer. Scraping anything behind a login, paywall, or technical barrier? That's likely illegal (thunderbit.com).
- Nature of the Data: Personal data (names, emails, profiles) triggers privacy laws. Copyrighted content (articles, images) can't be copied wholesale. Pure facts (prices, weather) are usually fair game (oxylabs.io).
- Intended Use: Internal analysis or research is viewed more leniently than republishing or selling scraped data. Using scraped data to compete directly with the source? That's a lawsuit waiting to happen (thunderbit.com).
- Compliance with Website Rules: Always check robots.txt and ToS. Robots.txt isn't legally binding, but it's best practice to respect it. ToS violations can mean civil suits or worse (promptcloud.com).
- Technical Measures: Scraping at human-like speeds and not bypassing security measures is key. Hammering a server or dodging CAPTCHAs can cross the line into hacking (cliffordchance.com).
What Changed in 2024–2026: Key Court Cases and Regulations
The legal landscape for web scraping has shifted dramatically since 2023. Here are the developments that every scraper needs to know:
Major Court Rulings
-
Meta v. Bright Data (2024): A U.S. federal court ruled that Meta's Terms of Service do not prohibit scraping public data by non-logged-in users. The judge found that "a visitor is not considered a 'user' unless they have an account." Meta dropped the remaining claims shortly after. This is a landmark win for public data scraping.
-
X Corp v. Bright Data (2024): Twitter (now X) lost a similar lawsuit, reinforcing the same principle: scraping publicly accessible data without logging in is not a ToS violation, because the scraper never agreed to those terms.
-
Reddit v. Perplexity AI (October 2025): Reddit sued Perplexity AI and several scraping providers, invoking the DMCA and alleging circumvention of anti-bot systems. This signals a new legal strategy: platforms are turning to copyright and anti-circumvention claims instead of the CFAA.
-
NYT v. OpenAI (March 2025): A federal judge allowed the New York Times' copyright case against OpenAI to proceed, rejecting OpenAI's motion to dismiss. This could set a major precedent on whether scraping content to train AI models counts as "fair use."
-
Anthropic Settlement (September 2025): Anthropic agreed to pay $1.5 billion to settle a U.S. copyright class action over the use of copyrighted texts to train its AI model—signaling that the costs of scraping-for-AI are very real.
The Big Trend: From CFAA to Contract and Copyright Law
The pattern is clear: the CFAA (Computer Fraud and Abuse Act) is losing power as a weapon against scrapers of public data. Companies that tried to use the CFAA against public data scraping—Meta, X, LinkedIn—have largely failed. Instead, the legal battlefield is shifting to:
- Contract law (ToS violations—but courts are saying non-users aren't bound by ToS)
- Copyright claims (especially for AI training data)
- Anti-circumvention statutes (DMCA Section 1201)
For scrapers, this means the legal risk hasn't disappeared—it's just moved.
Regulatory Changes
- CCPA 2026 Updates: California's revised CCPA regulations took effect January 1, 2026, adding new rules for automated decision-making technology (ADMT), risk assessments, and data broker obligations.
- New U.S. State Privacy Laws: Indiana, Kentucky, and Rhode Island enacted comprehensive privacy laws effective in 2026.
- EU AI Act: Full enforcement begins August 2, 2026—requiring AI developers to disclose training data sources, respect copyright opt-outs, and banning facial image scraping for AI systems.
- AI Accountability for Publishers Act (February 2026): A proposed U.S. law that would require AI companies to get permission and pay publishers before scraping their content.
Scraping Policies of Major Platforms: What You Need to Know
Not all websites treat scraping the same way. Here's a platform-by-platform breakdown of what the biggest sites allow, what they block, and what courts have said:
| Platform | ToS on Scraping | Technical Defenses | Legal Enforcement | What's Practically Safe |
|---|---|---|---|---|
| Google (Search & Maps) | Prohibits automated access in ToS. Maps Platform has an explicit "No Scraping" clause. | SearchGuard JS challenges, CAPTCHAs, rate limiting. Updated robots.txt in 2025 to block AI crawlers. | Sued scrapers in Dec 2025 using DMCA. Actively blocks AI crawlers (Anthropic, Meta, OpenAI). | Scraping public Google Maps business data is legally defensible (hiQ precedent), but expect technical blocks. Use official APIs where possible. |
| Amazon | Explicitly bans all scraping in Conditions of Use ("no robot, spider, scraper, or other automated means"). | Aggressive bot detection, CAPTCHA, IP blocking. robots.txt blocks all bots except Googlebot/Bingbot. Explicitly blocks AI crawlers since 2025. | Sued Perplexity AI in Nov 2025. Sends cease-and-desist letters regularly. Updated BSA in March 2026 with AI agent rules. | Public product data (prices, listings) is factual and scrapeable under U.S. law, but Amazon fights back hard. Throttle requests and avoid personal data. |
| Prohibits scraping in ToS; requires user agreement to access services. | Login walls for most profile data, anti-bot detection, rate limiting. | hiQ case confirmed public profile scraping is not a CFAA violation, but LinkedIn won on contract/unfair competition claims when fake accounts were used. | Public profiles (visible without login) are legally defensible to scrape. Never create fake accounts or scrape logged-in data. | |
| Meta (Facebook & Instagram) | ToS prohibit scraping; separate rules for logged-in vs. logged-off data. | Login walls for most content, advanced bot detection. | Lost to Bright Data in 2024—court ruled ToS don't apply to non-logged-in scrapers. Dropped remaining claims. | Public data (business pages, public posts) visible without login is on safer ground. Never scrape private profiles or data behind login. |
| X (Twitter) | Updated ToS in 2023 to ban all scraping and crawling without written consent. Eliminated the old robots.txt exception. | robots.txt blocks all crawlers (Disallow: /). Cloudflare Turnstile challenges. Strict rate limits (300 req/hr). IP reputation scoring. | Lost to Bright Data on public data, but aggressively limits technical access. | Public tweets and profiles are legally defensible, but X's technical barriers are among the toughest in 2026. Expect blocks without premium proxy infrastructure. |
The bottom line: Courts have consistently ruled that scraping publicly visible data without logging in does not violate the CFAA. But platforms can still pursue you on contract law, copyright, or anti-circumvention grounds—and they will make your life difficult with technical barriers. Always scrape responsibly.
AI Training Data and Web Scraping: The New Legal Frontier
If you're paying attention to the news in 2026, you know that scraping data to train AI models has become the hottest legal battleground. Here's what's happening:
- Copyright lawsuits are piling up. The New York Times, authors, and publishers have sued OpenAI, Anthropic, and others, alleging that mass scraping of copyrighted content to train LLMs is not "fair use." Anthropic settled a major class action for $1.5 billion in 2025—signaling that the costs of scraping-for-AI are very real.
- The "fair use" defense is shaky. U.S. courts have not yet issued a definitive ruling on whether training AI on scraped data is fair use. Early decisions suggest it depends heavily on how the data was obtained and what is done with the AI output.
- New legislation is coming. The AI Accountability for Publishers Act (introduced February 2026) aims to require AI companies to get permission and pay publishers before scraping their content.
- The EU AI Act (full enforcement August 2026) requires AI developers to disclose training data sources, respect machine-readable copyright opt-outs (under the Copyright Directive's TDM exception), and label AI-generated content. It also bans AI systems that scrape facial images from the internet.
- AI/LLM crawlers are exploding. AI crawlers quadrupled their share of web traffic from 2.6% to 10.1% in just eight months. OpenAI's GPTBot alone grew by 305%. In response, major sites (Amazon, Reddit, the NYT) are updating robots.txt to explicitly block AI crawlers.
What this means for you: If you're scraping data for traditional business purposes (lead gen, price monitoring, market research), these AI-specific rules may not apply directly. But if you're feeding scraped data into AI models, tread very carefully—and get legal advice.
Web Scraping Laws Around the World: A Quick Comparison
Let's zoom out and see how the rules shake out globally:
- United States: No blanket ban. Scraping public-facing sites is generally lawful (hiQ v. LinkedIn), and the 2024 Meta and X Corp rulings have further strengthened the case for public data scraping. But scraping behind logins or technical blocks can still trigger the CFAA. The trend is now toward companies using contract law and copyright claims instead. Privacy laws are expanding fast: CCPA received major updates effective January 1, 2026, including new rules for automated decision-making and data broker obligations. Indiana, Kentucky, and Rhode Island also enacted comprehensive privacy laws in 2026.
- European Union: Stringent privacy laws. GDPR applies even to public personal data. Database rights can block large-scale scraping of structured data (cliffordchance.com). NEW: The EU AI Act enters full enforcement on August 2, 2026, requiring AI developers to disclose training data sources and respect copyright opt-outs. The Act bans scraping facial images from the internet for AI systems.
- United Kingdom: Mirrors EU rules post-Brexit. Public data can be scraped, but personal info scraping is tightly regulated. Computer Misuse Act can criminalize unauthorized access.
- China: Very restrictive. PIPL and Data Security Law require consent for personal data. Courts use unfair competition law to block scraping that harms businesses (malwarebytes.com).
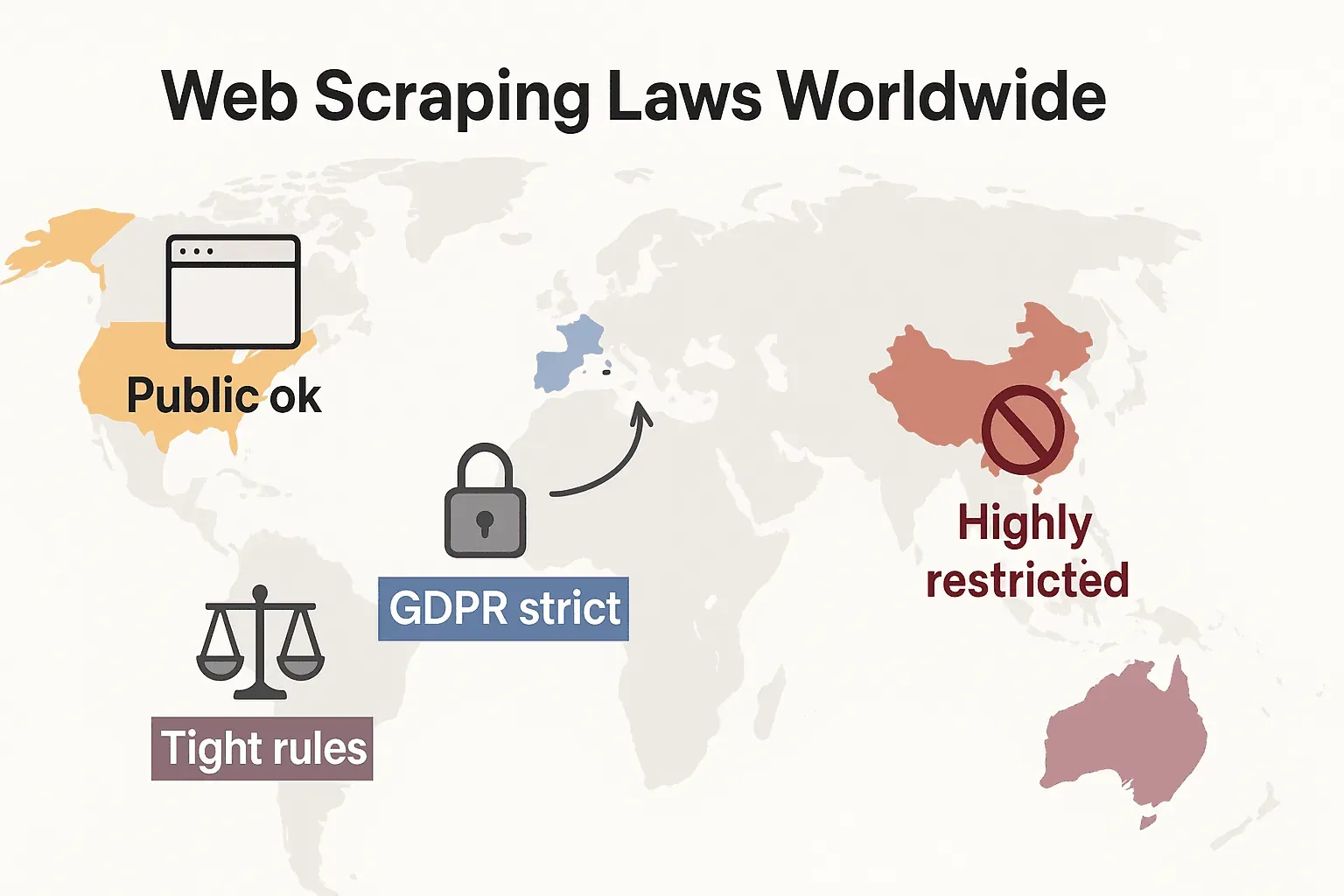
Bottom line: scraping public, non-personal data for internal use is generally safest. Anything else? Check the local laws and tread carefully.
Common Myths About Web Scraping Legality
Let's bust a few myths I hear all the time:
- Myth 1: "Web scraping is illegal, full stop."
False. There's no law that bans all web scraping. It's how and what you scrape that matters (oxylabs.io). - Myth 2: "If data is public, I can do whatever I want with it."
Not quite. Public data can still be protected by privacy or copyright laws, and ToS may restrict certain uses (ico.org.uk). - Myth 3: "Web scraping is the same as hacking."
Nope. Scraping public web pages is not hacking. Bypassing logins or technical barriers is a different story (calawyers.org). - Myth 4: "If I don't get caught, it's fine."
Risky thinking. Many sites use anti-bot tech and will notice. Silence isn't consent. - Myth 5: "Giving credit or using data internally makes it okay."
Attribution doesn't override copyright or privacy law. Internal use is safer, but not a free pass. - Myth 6: "All web scraping violates privacy."
Not all scraping involves personal data. But scraping large volumes of personal info without safeguards is almost always illegal (oxylabs.io). - Myth 7: "If a website's ToS bans scraping, it's always illegal to scrape."
Not necessarily. In 2024, courts ruled in Meta v. Bright Data and X Corp v. Bright Data that ToS cannot bind users who never agreed to them—i.e., if you're scraping without logging in or creating an account, the site's ToS may not apply to you. This is still a developing area, but it's a significant shift.
How to Scrape Data Legally: Best Practices for Compliance
Here's my go-to checklist for legal, ethical web scraping:
- Read and respect the site's Terms of Service. If they say "no scraping," consider stopping or ask for permission (ql2.com).
- Stick to public data. If you need a password, it's restricted—don't scrape it (thunderbit.com).
- Check robots.txt and crawl politely. Not legally binding, but good etiquette. Don't hammer servers—space out your requests (promptcloud.com).
- Avoid personal data unless you have a lawful basis. If you must collect it, comply with GDPR/CCPA and minimize what you collect.
- Don't republish scraped content wholesale. Add value or analysis, or get permission (thunderbit.com).
- Don't feed scraped content into AI models without checking copyright. The legal landscape is shifting fast—get advice if this is your use case.
- Use official APIs or data exports when available. They're designed for this purpose and usually safer (thunderbit.com).
- Be transparent and accountable. If you collect personal data, inform people and keep a log of your activities.
- Minimize and secure your data. Only collect what you need, keep it accurate, and store it safely.
- Stay informed and seek legal advice for edge cases. Laws and court rulings are changing rapidly—especially the EU AI Act and U.S. state privacy laws. When in doubt, ask a pro.
Try Thunderbit Chrome Extension for Compliant Scraping
Using Web Scraping Tools Legally: What Businesses Need to Know
Web scraping tools like Thunderbit make data collection accessible to non-coders, but you still need to use them responsibly:
- Pick compliance-focused tools. Thunderbit, for example, only scrapes what you can see in your browser—no sneaky API hacks or unauthorized access (thunderbit.com).
- Stick to legitimate use cases. Internal analytics, market research, and competitive price monitoring are generally safe. Republishing or selling scraped data? Much riskier.
- Configure tools for compliance. Set crawl delays, obey robots.txt, and use templates that collect only what you need.
- Keep it in-house. Using scraped data internally is safer than republishing it.
- Educate your team. Make sure everyone understands the rules and best practices.
- Leverage built-in compliance features. Thunderbit warns users about risky sites, scrapes at human-like speeds, and doesn't store your data on their servers.
- Don't force it. If a tool can't scrape a site, don't try to hack around it. Not all data is obtainable without risk.
Thunderbit's Approach: Enabling Compliant AI Web Scraping
At Thunderbit, we've spent a lot of time thinking about compliance. Here's how our AI Web Scraper helps users stay on the right side of the law:
- Scrapes only what you can see. Thunderbit works in your browser session, so it can't access data you couldn't manually copy.
- Guides users with warnings. If you try to scrape a site with strict anti-scraping policies, Thunderbit will alert you.
- Human-like scraping speeds. Whether you're scraping locally or in the cloud, Thunderbit avoids hammering servers.
- Customizable data selection. Our AI suggests relevant columns, helping you collect only what you need.
- Subpage and pagination handling. Thunderbit navigates sites like a real user, respecting their structure.
- Privacy and security. Your data stays with you—Thunderbit doesn't store or reuse it.
- Compliance-friendly exports. Export directly to Google Sheets, Airtable, Notion, or CSV for secure, internal use.
- Scheduling and automation. Set up recurring scrapes at responsible intervals.
- Multi-language support. Thunderbit's UI supports 34 languages, making compliance accessible globally.
- Regular template updates. Our instant templates for popular sites are kept current with legal and technical changes.
By baking compliance into the product, Thunderbit helps teams collect the data they need—without the legal headaches.
Staying Ahead: Adapting to Legal and Technical Changes in Web Scraping
Explore More Web Scraping Guides Get Started Free
Web scraping isn't a set-and-forget game. Laws and website structures are always evolving. Here's how to stay ahead:
- Monitor legal developments. The pace of change accelerated in 2024–2026—follow tech law news, regulator updates, and industry blogs (like Thunderbit's). Keep an eye on the EU AI Act enforcement (August 2026), new U.S. state privacy laws, and ongoing AI copyright cases.
- Adapt to technical changes. Sites update their layouts and anti-bot defenses all the time. Major platforms (Amazon, X, Google) tightened their defenses significantly in 2025–2026. Thunderbit's AI and templates are designed to adapt automatically.
- Embrace official APIs when available. If a site moves to a paid API model, consider switching for reliability and compliance.
- Audit your scraping regularly. Document your sources, check for ToS or policy changes, and adjust your strategy as needed.
- Leverage Thunderbit's template updates. Our team keeps templates current, so you don't have to worry about breaking changes or new compliance requirements.
- Stay flexible. If a data source becomes too risky, pivot to another or seek a partnership.
With the right tools and mindset, you can keep your data pipeline flowing—without stepping on legal landmines.
Conclusion: Navigating the Legal Landscape of Web Scraping
Web scraping isn't inherently illegal—it's a powerful tool for business, research, and innovation. But like any tool, it comes with rules. The key is understanding what you're scraping, how you're scraping, and what you'll do with the data. Respect local laws, honor website policies, and use compliance-focused tools like Thunderbit to keep your operations above board.
The 2024–2026 court rulings (Meta v. Bright Data, X Corp v. Bright Data) have strengthened the case for scraping public data, but new risks are emerging around AI training data, copyright claims, and the EU AI Act. Platform-specific policies vary widely—Google, Amazon, LinkedIn, Meta, and X each enforce their rules differently—so know the landscape before you scrape.
If you're ever unsure, seek legal advice—especially for big or sensitive projects. And remember: the legal landscape is always changing, so stay informed and agile.
Want to learn more about web scraping, compliance, and automation? Check out the Thunderbit Blog for more guides, or try Thunderbit's Chrome Extension for yourself.
Start Compliant Web Scraping with Thunderbit
FAQs
1. Is web scraping illegal everywhere?
No. Web scraping is not inherently illegal, but its legality depends on what you scrape, how you scrape it, and where you are. Scraping public, non-personal data for internal use is generally allowed in most regions, but scraping personal or copyrighted data, or violating site terms, can be illegal (oxylabs.io).
2. Does robots.txt make scraping illegal if I ignore it?
Robots.txt is not legally binding, but it's best practice to respect it. Ignoring robots.txt won't get you sued by itself, but it can make you look like a "bad actor" if there's a dispute (promptcloud.com).
3. Can I scrape Google, Amazon, or LinkedIn?
It's complicated. All three prohibit scraping in their ToS, but courts have ruled that ToS may not bind non-logged-in users (see Meta v. Bright Data and X Corp v. Bright Data, both 2024). Scraping publicly visible data (product prices, business listings, public profiles) is generally legally defensible in the U.S. However, each platform enforces its rules differently: Amazon is the most aggressive with legal action (it sued Perplexity AI in November 2025); LinkedIn relies on technical barriers and contract claims; Google is increasingly using DMCA-based enforcement. Always scrape responsibly and expect technical countermeasures.
4. Can I scrape Facebook or Instagram?
After Meta v. Bright Data (2024), scraping public data from Facebook and Instagram without logging in is on stronger legal ground. The court ruled Meta's ToS don't apply to non-users. But never create fake accounts or scrape data behind login walls—that crosses the line.
5. Can I scrape X (Twitter)?
X updated its ToS in 2023 to ban all scraping without written consent and has deployed aggressive technical defenses (Cloudflare Turnstile, rate limits of 300 requests/hour, IP reputation scoring). However, Bright Data won in court on similar grounds—public data scraped without an account is not bound by X's ToS. Technically, X is one of the hardest platforms to scrape in 2026.
6. Is scraping data to train AI models legal?
This is the biggest open question in 2026. Major lawsuits (NYT v. OpenAI, Anthropic's $1.5B settlement) suggest significant legal risk. The EU AI Act requires disclosure of training data sources and respect for copyright opt-outs. The proposed AI Accountability for Publishers Act would require permission and payment. If you're scraping to train AI, get legal advice before proceeding.
7. What's the safest way to use web scraping tools like Thunderbit?
Stick to scraping public data, respect site terms, avoid personal info unless you have a lawful basis, and use the data internally. Thunderbit is designed to help you stay compliant by scraping only what's visible in your browser and warning you about risky sites (thunderbit.com).
8. Can I scrape data for commercial use?
It depends. Using scraped data for internal analytics or research is generally safer. Republishing or selling scraped data, especially if it's copyrighted or personal, is much riskier and may require permission or a license.
9. How do I keep up with legal and technical changes in web scraping?
Follow tech law news, monitor your target sites for ToS or policy changes, and use tools like Thunderbit that update their templates and compliance features regularly. Key things to watch in 2026: EU AI Act enforcement (August), ongoing AI copyright cases, and new U.S. state privacy laws. When in doubt, consult a legal professional.
Try AI Web Scraper Get Started Free




