
मेरे पहले स्क्रैपिंग प्रोजेक्ट में एक हाथ से लिखा गया Python स्क्रिप्ट, एक साझा proxy, और थोड़ी-सी प्रार्थना शामिल थी। वह हर तीन दिन में टूट जाता था।
2026 में, scraping APIs मुश्किल काम संभाल लेते हैं — proxies, rendering, CAPTCHAs, retries — ताकि आपको न करना पड़े। ये price monitoring से लेकर AI training data pipelines तक, हर चीज़ की रीढ़ हैं।
लेकिन एक मोड़ है: Thunderbit जैसे AI-driven tools अब non-developers के लिए कई API use cases को अनावश्यक बना रहे हैं। इसके बारे में नीचे और बात करेंगे।
यहाँ 10 scraping APIs हैं जिन्हें मैंने इस्तेमाल किया है या परखा है — हर एक क्या अच्छा करता है, कहाँ कमज़ोर पड़ता है, और कब आपको API की ज़रूरत ही नहीं होती।
पारंपरिक Web Scraping APIs की बजाय Thunderbit AI पर क्यों विचार करें?
API सूची में जाने से पहले, आइए कमरे में खड़े हाथी की बात करें: AI-powered automation। मैंने वर्षों तक टीमों को नीरस काम automate करने में मदद की है, और मैं बता सकता हूँ — एक वजह है कि ज़्यादातर businesses अब code-heavy APIs छोड़कर सीधे Thunderbit जैसे AI agents अपना रहे हैं।
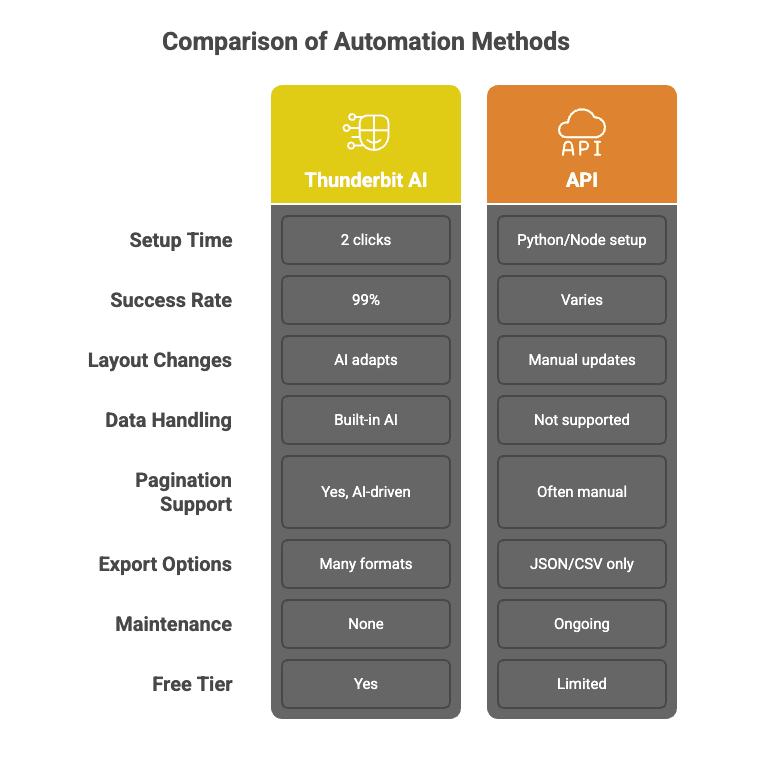
Thunderbit को पारंपरिक web scraping APIs से अलग क्या बनाता है:
-
99% सफलता के लिए Waterfall-Style API Calls
Thunderbit का AI बस एक API call करके सबसे अच्छे नतीजे की उम्मीद नहीं करता। यह waterfall pattern का उपयोग करता है — हर काम के लिए अपने-आप सबसे उपयुक्त scraping method चुनता है, ज़रूरत पड़ने पर retry करता है, और 99% success rate की गारंटी देता है। आपको data मिलता है, सिरदर्द नहीं।
-
No-Code, दो-क्लिक सेटअप
Python scripts लिखना या API docs में उलझना भूल जाइए। Thunderbit में बस “AI Suggest Fields” और “Scrape” पर क्लिक करना होता है। बस इतना ही। मेरी माँ भी इसे इस्तेमाल कर सकती हैं (और वह अभी भी मानती हैं कि “cloud” बस खराब मौसम होता है)।
-
Batch Scraping: तेज़ और सटीक
Thunderbit का AI model हज़ारों अलग-अलग websites को parallel में process कर सकता है, और हर layout के अनुसार तुरंत खुद को ढाल लेता है। यह interns की सेना रखने जैसा है — बस उन्हें coffee break नहीं चाहिए।
-
बिना रखरखाव के
Websites हर समय बदलती रहती हैं। पारंपरिक APIs? वे टूट जाते हैं। Thunderbit? AI हर बार page को नए सिरे से पढ़ता है, इसलिए site का layout बदलने या नया button जुड़ने पर आपको code अपडेट नहीं करना पड़ता।
-
व्यक्तिगत Data Extraction और Post-Processing
क्या आपको data साफ़, label, translate या summarize करना है? Thunderbit extraction के हिस्से के रूप में यह सब कर सकता है — इसे ऐसे समझिए जैसे 10,000 web pages को ChatGPT में डालकर एकदम व्यवस्थित dataset वापस पाना।
-
Subpage और Pagination Scraping
Thunderbit का AI links follow कर सकता है, pagination संभाल सकता है, और subpages से data लेकर आपकी table को enrich भी कर सकता है — वह भी बिना custom code के।
-
मुफ़्त Data Export और Integrations
Excel, Google Sheets, Airtable, Notion में export करें, या CSV/JSON के रूप में डाउनलोड करें — कोई paywall नहीं, कोई बेकार की झंझट नहीं।
इसे और स्पष्ट करने के लिए एक त्वरित तुलना:
इसे काम करते देखना चाहते हैं? देखें।
Data Scraping API क्या है?
थोड़ी देर के लिए बुनियादी बातों पर लौटते हैं। एक data scraping API ऐसा tool है जो आपको websites से programmatically data निकालने देता है — बिना अपने scrapers शुरू से बनाने के। इसे ऐसे समझिए जैसे एक robot जिसे आप भेजते हैं ताज़ा prices, reviews, या listings लाने के लिए, और वह data एक साफ़-सुथरे, structured format में वापस लाता है (आमतौर पर JSON या CSV)।
यह काम कैसे करते हैं? ज़्यादातर scraping APIs गंदे हिस्से संभाल लेते हैं — rotating proxies, CAPTCHAs सुलझाना, JavaScript rendering — ताकि आप उस चीज़ पर ध्यान दे सकें जिसकी आपको सच में ज़रूरत है: data। आप एक request भेजते हैं (आमतौर पर URL और कुछ parameters के साथ), और API content वापस दे देता है, आपके business workflow के लिए तैयार।
मुख्य फ़ायदे:
- गति: APIs मिनटों में हज़ारों pages scrape कर सकती हैं।
- Scalability: 10,000 products monitor करने हैं? कोई समस्या नहीं।
- Integration: अपने CRM, BI tool, या data warehouse से कम झंझट में जोड़ सकते हैं।
लेकिन जैसा कि हम देखेंगे, हर API एक जैसी नहीं होती — और हर एक उतनी “set and forget” भी नहीं होती जितना वह दावा करती है।
मैंने इन APIs का मूल्यांकन कैसे किया
मैंने काफ़ी समय मैदान में बिताया है — testing, breaking, और कभी-कभी गलती से अपने ही servers पर DDoS कर दिया (मेरी पुरानी IT team को मत बताइए)। इस सूची के लिए मैंने इन बातों पर ध्यान दिया:
- Reliability: क्या यह सच में काम करती है, मुश्किल websites पर भी?
- Speed: बड़े पैमाने पर नतीजे कितनी जल्दी देती है?
- Pricing: क्या यह startups के लिए किफ़ायती और enterprises के लिए scalable है?
- Scalability: क्या यह लाखों requests संभाल सकती है, या 100 पर ही लड़खड़ा जाती है?
- Developer-Friendliness: क्या documentation साफ़ है? क्या SDKs और code samples हैं?
- Support: जब चीज़ें गड़बड़ होती हैं (और होती ही हैं), क्या मदद मिलती है?
- User Feedback: असली दुनिया की reviews, सिर्फ़ marketing की बातें नहीं।
मैंने hands-on testing, review analysis, और Thunderbit community की feedback पर भी बहुत भरोसा किया (हम काफ़ी picky लोग हैं)।
2026 में विचार करने लायक 10 APIs
मुख्य आकर्षण के लिए तैयार हैं? यहाँ business users और developers के लिए 2026 की सबसे अच्छी web scraping APIs और platforms की मेरी updated सूची है।
1. Oxylabs
 Overview:
Overview:
Oxylabs enterprise-grade web data extraction का heavyweight champ है। विशाल proxy pool और SERPs से लेकर e-commerce तक हर चीज़ के लिए specialized APIs के साथ, यह Fortune 500 कंपनियों और scale पर reliability चाहने वाले हर व्यक्ति की पहली पसंद है।
Key Features:
- 195+ देशों में विशाल proxy network (residential, datacenter, mobile, ISP)
- anti-bot, CAPTCHA solving, और headless browser rendering वाली Scraper APIs
- geotargeting, session persistence, और उच्च data accuracy (95%+ success rates)
- OxyCopilot: AI assistant जो auto-generated parsing code और API queries बनाता है
Pricing:
एक single API के लिए लगभग $49/month से शुरू, all-in-one access के लिए $149/month। 7-day free trial शामिल है, जिसमें 5,000 requests तक मिलती हैं।
User Feedback:
G2 पर रेटिंग, reliability और support के लिए सराही गई। मुख्य कमी? काफ़ी महँगी है, लेकिन जैसा पैसा वैसा दम।
2. ScrapingBee
 Overview:
Overview:
ScrapingBee developer का सबसे अच्छा दोस्त है — सरल, किफ़ायती, और focused। आप एक URL भेजते हैं, यह headless Chrome, proxies, और CAPTCHAs संभालता है, और rendered page या सिर्फ़ आपको चाहिए data वापस देता है।
Key Features:
- Headless browser rendering (JavaScript support)
- Automatic IP rotation और CAPTCHA solving
- मुश्किल sites के लिए stealth proxy pool
- न्यूनतम सेटअप — बस एक API call
Pricing:
लगभग 1,000 calls/month के साथ free tier। Paid plans लगभग $29/month से शुरू, 5,000 requests के लिए।
User Feedback:
लगातार G2 पर रेटिंग। Developers को इसकी simplicity पसंद आती है; non-coders को यह थोड़ा बहुत barebones लग सकता है।
3. Apify
 Overview:
Overview:
Apify web scraping का Swiss army knife है। आप JavaScript या Python में custom scrapers (“Actors”) बना सकते हैं, या लोकप्रिय sites के लिए उनके विशाल pre-built actors library का उपयोग कर सकते हैं। यह उतना ही flexible है जितना आपको चाहिए।
Key Features:
- लगभग किसी भी site के लिए custom और pre-built scrapers (Actors)
- Cloud infrastructure, scheduling, और proxy management शामिल
- JSON, CSV, Excel, Google Sheets, और अधिक में data export
- सक्रिय community और Discord support
Pricing:
$5/month क्रेडिट के साथ forever free plan। Paid plans $39/month से शुरू।
User Feedback:
G2/Capterra पर । Developers को इसकी flexibility पसंद आती है; beginners को सीखने की काफ़ी ढलान का सामना करना पड़ता है।
4. Decodo (पहले Smartproxy)
 Overview:
Overview:
Decodo (Smartproxy से rebranded) का ध्यान value और ease पर है। यह मजबूत proxy infrastructure को general web, SERPs, e-commerce, और social media के लिए scraping APIs के साथ जोड़ता है — सब एक ही subscription में।
Key Features:
- सभी endpoints के लिए unified scraping API (अलग add-ons की ज़रूरत नहीं)
- Google, Amazon, TikTok, और अधिक के लिए specialized scrapers
- playground और code generators के साथ user-friendly dashboard
- 24/7 live chat support
Pricing:
25,000 requests के लिए लगभग $50/month से शुरू। 1,000 requests के साथ 7-day free trial।
User Feedback:
“पैसे की पूरी वसूली” और responsive support के लिए सराही गई। G2 पर ।
5. Octoparse
 Overview:
Overview:
Octoparse no-code का champion है। अगर आपको code से नफ़रत है लेकिन data से प्यार है, तो यह point-and-click desktop app (cloud features के साथ) आपको visual तरीके से scrapers बनाने और उन्हें local या cloud में चलाने देती है।
Key Features:
- Visual workflow builder — data fields चुनने के लिए बस क्लिक करें
- Cloud extraction, scheduling, और automatic IP rotation
- लोकप्रिय sites के लिए templates और custom scrapers के लिए marketplace
- Octoparse AI: data cleaning और workflow automation के लिए RPA और ChatGPT को जोड़ता है
Pricing:
10 local tasks तक free plan। Paid plans $119/month से शुरू (cloud features, unlimited tasks)। premium features के लिए 14-day free trial।
User Feedback:
G2 पर । non-coders इसे पसंद करते हैं, लेकिन advanced users को सीमाएँ दिख सकती हैं।
6. Bright Data
 Overview:
Overview:
Bright Data सबसे बड़ा खिलाड़ी है — अगर आपको scale, speed, और हर संभव feature चाहिए, तो यही platform है। दुनिया के सबसे बड़े proxy network और एक शक्तिशाली scraping IDE के साथ, यह enterprise के लिए बनाया गया है।
Key Features:
- 150M+ IPs (residential, mobile, ISP, datacenter)
- Web Scraper IDE, pre-built data collectors, और तैयार datasets
- उन्नत anti-bot, CAPTCHA solving, और headless browser support
- compliance और legal focus (Ethical Web Data initiative)
Pricing:
Pay-as-you-go: लगभग $1.05 प्रति 1,000 requests, proxies $3–$15/GB से। ज़्यादातर products के लिए free trials।
User Feedback:
Performance और features के लिए सराहा गया, लेकिन pricing और complexity छोटी teams के लिए बाधा बन सकती है।
7. WebAutomation
 Overview:
Overview:
WebAutomation एक cloud-based platform है, जो non-developers के लिए बनाया गया है। pre-built extractors के marketplace और no-code builder के साथ, यह business users के लिए बिल्कुल सही है जिन्हें code नहीं, data चाहिए।
Key Features:
- लोकप्रिय sites (Amazon, Zillow, आदि) के लिए pre-built extractors
- point-and-click UI के साथ no-code extractor builder
- cloud-based scheduling, data delivery, और maintenance शामिल
- row-based pricing (जितना extract करें, उतना भुगतान)
Pricing:
Project plan $74/month पर (~400k rows/year), pay-as-you-go $1 प्रति 1,000 rows। 10 million credits के साथ 14-day free trial।
User Feedback:
Users को इसका ease of use और transparent pricing पसंद है। Support मददगार है, और maintenance टीम संभालती है।
8. ScrapeHero
 Overview:
Overview:
ScrapeHero की शुरुआत एक custom scraping consultancy के रूप में हुई थी और अब यह self-service cloud platform भी देता है। आप लोकप्रिय sites के लिए pre-built scrapers इस्तेमाल कर सकते हैं या पूरी तरह managed projects की मांग कर सकते हैं।
Key Features:
- ScrapeHero Cloud: Amazon, Google Maps, LinkedIn, और अधिक के लिए pre-built scrapers
- No-code operation, scheduling, और cloud delivery
- अनोखी ज़रूरतों के लिए custom solutions
- programmatic integration के लिए API access
Pricing:
Cloud plans $5/month जितने कम से शुरू। Custom projects $550 प्रति site से (one-time)।
User Feedback:
Reliability, data quality, और support के लिए सराहा गया। DIY से managed solutions तक scale करने के लिए बढ़िया।
9. Sequentum
 Overview:
Overview:
Sequentum enterprise का Swiss army knife है — compliance, auditability, और भारी scale के लिए बनाया गया। अगर आपको SOC-2 certification, audit trails, और team collaboration चाहिए, तो यह आपका tool है।
Key Features:
- Low-code agent designer (point-and-click + scripting)
- Cloud-based SaaS या on-premise deployment
- Built-in proxy management, CAPTCHA solving, और headless browsers
- Audit trails, role-based access, और SOC-2 compliance
Pricing:
Pay-as-you-go ($6/hour runtime, $0.25/GB export), Starter plan $199/month पर। साइनअप पर $5 free credit।
User Feedback:
Enterprises को compliance features और scalability पसंद है। सीखने की प्रक्रिया है, लेकिन support और training बेहतरीन हैं।
10. Grepsr
 Overview:
Overview:
Grepsr एक managed data extraction service है — बस उन्हें बताइए आपको क्या चाहिए, और वे आपके लिए scrapers बनाएँगे, चलाएँगे, और उनका रखरखाव भी करेंगे। उन businesses के लिए बिल्कुल सही है जो technical झंझट के बिना data चाहते हैं।
Key Features:
- Managed extraction (“Grepsr Concierge”) — वे सबकुछ सेट अप और maintain करते हैं
- Scheduling, monitoring, और data डाउनलोड करने के लिए cloud dashboard
- कई output formats और integrations (Dropbox, S3, Google Drive)
- प्रति data record भुगतान (per request नहीं)
Pricing:
Starter pack $350 पर (one-time extraction), recurring subscriptions custom-quoted होते हैं।
User Feedback:
Clients को इसका hands-off अनुभव और responsive support पसंद है। non-technical teams और उन लोगों के लिए बढ़िया जो tinkering से ज़्यादा समय को महत्व देते हैं।
शीर्ष Web Scraping APIs की त्वरित तुलना तालिका
यहाँ सभी 10 platforms की cheat sheet है:
| प्लेटफ़ॉर्म | समर्थित डेटा प्रकार | प्रारंभिक कीमत | मुफ़्त ट्रायल | उपयोग में आसानी | सपोर्ट | उल्लेखनीय विशेषताएँ |
|---|---|---|---|---|---|---|
| Oxylabs | वेब, SERP, e-com, रियल एस्टेट | $49/mo | 7 दिन/5k req | डेवलपर-केंद्रित | 24/7, enterprise | OxyCopilot AI, विशाल proxy pool, geo-targeting |
| ScrapingBee | सामान्य वेब, JS, CAPTCHA | $29/mo | 1k calls/mo | सरल API | Email, forums | Headless Chrome, stealth proxies |
| Apify | कोई भी वेब, pre-built/custom | मुफ़्त/$39/mo | Forever free | flexible, complex | Community, Discord | Actor marketplace, cloud infra, integrations |
| Decodo | वेब, SERP, e-com, social | $50/mo | 7 दिन/1k req | user-friendly | 24/7 live chat | Unified API, code playground, great value |
| Octoparse | कोई भी वेब, no-code | मुफ़्त/$119/mo | 14 दिन | visual, no-code | Email, forum | Point-and-click UI, cloud, Octoparse AI |
| Bright Data | सभी वेब, datasets | $1.05/1k req | हाँ | शक्तिशाली, जटिल | 24/7, enterprise | सबसे बड़ा proxy net, IDE, तैयार datasets |
| WebAutomation | structured, e-com, रियल एस्टेट | $74/mo | 14 दिन/10M rows | no-code, templates | Email, chat | Pre-built extractors, row-based pricing |
| ScrapeHero | e-com, maps, jobs, custom | $5/mo | हाँ | no-code, managed | Email, tickets | Cloud scrapers, custom projects, Dropbox delivery |
| Sequentum | कोई भी वेब, enterprise | $0/$199/mo | $5 credit | low-code, visual | High-touch | Audit trails, SOC-2, on-prem/cloud |
| Grepsr | कोई भी structured, managed | $350 one-time | Sample run | पूरी तरह managed | Dedicated rep | Concierge setup, pay per data, integrations |
अपने व्यवसाय के लिए सही Web Scraping Tool कैसे चुनें
तो, आपको कौन-सा tool चुनना चाहिए? मैं जिन teams को सलाह देता हूँ, उनके लिए मैं इसे ऐसे तोड़कर समझाता हूँ:
-
अगर आपको no code, तुरंत नतीजे, और AI-powered data cleaning चाहिए:
चुनिए। यह “मुझे data चाहिए” से “मेरे पास data है” तक जाने का सबसे तेज़ रास्ता है — और आपको scripts या APIs की देखरेख भी नहीं करनी पड़ती।
-
अगर आप developer हैं और control व flexibility पसंद करते हैं:
Apify, ScrapingBee, या Oxylabs आज़माइए। ये आपको सबसे ज़्यादा शक्ति देते हैं, लेकिन setup और maintenance आपको संभालना होगा।
-
अगर आप business user हैं और visual tool चाहते हैं:
WebAutomation point-and-click scraping के लिए शानदार है, खासकर e-commerce और lead gen के लिए।
-
अगर आपको compliance, auditability, या enterprise features चाहिए:
Sequentum आपके लिए बनाया गया है। यह महँगा है, लेकिन regulated industries के लिए काफ़ी उपयोगी है।
-
अगर आप बस चाहते हैं कि कोई और सब संभाल ले:
Grepsr या ScrapeHero की managed services सही रास्ता हैं। आप थोड़ा ज़्यादा भुगतान करेंगे, लेकिन आपका तनाव कम रहेगा।
और अगर आप अभी भी सुनिश्चित नहीं हैं, तो इनमें से ज़्यादातर platforms free trials देते हैं — तो बेझिझक आज़माइए!
मुख्य निष्कर्ष
- Web scraping APIs अब data-driven business के लिए ज़रूरी हैं — market के 2030 तक तक पहुँचने का अनुमान है।
- Manual scraping अब पीछे छूट चुका है — anti-bot tech, proxies, और site changes के बीच, scale करने का व्यावहारिक तरीका APIs और AI tools ही हैं।
- हर API/platform की अपनी ताकत है:
- scale और reliability के लिए Oxylabs और Bright Data
- flexibility के लिए Apify
- value के लिए Decodo
- no-code के लिए WebAutomation
- compliance के लिए Sequentum
- hands-off managed data के लिए Grepsr
- AI-powered automation (जैसे Thunderbit) खेल बदल रही है — यह ज़्यादा success rates, zero maintenance, और built-in data processing देती है, जिसकी बराबरी पारंपरिक APIs नहीं कर पातीं।
- सबसे अच्छा tool वही है जो आपके workflow, budget, और technical skills के अनुकूल हो। प्रयोग करने से न डरें!
अगर आप टूटे हुए scripts और endless debugging को पीछे छोड़ने के लिए तैयार हैं, तो आज़माइए — या पर जाकर Amazon, Google, PDFs, और बहुत कुछ scrape करने की गहराई वाली guides देखें।
और याद रखिए: web data की दुनिया में, websites खुद जितनी तेज़ी से बदलती हैं, उनसे भी तेज़ बदलने वाली चीज़ वह technology है जिसका हम उन्हें scrape करने के लिए इस्तेमाल करते हैं। जिज्ञासु बने रहें, automate करते रहें, और आपकी proxies कभी block न हों।